ceval
C-Eval 是一套专为评估基础模型中文能力而设计的综合评测基准,由上海交通大学团队开发并发表于 NeurIPS 2023。它旨在解决当前大语言模型在中文语境下缺乏统一、权威且多维度评估标准的问题,帮助开发者准确追踪模型进步并分析其优势与短板。
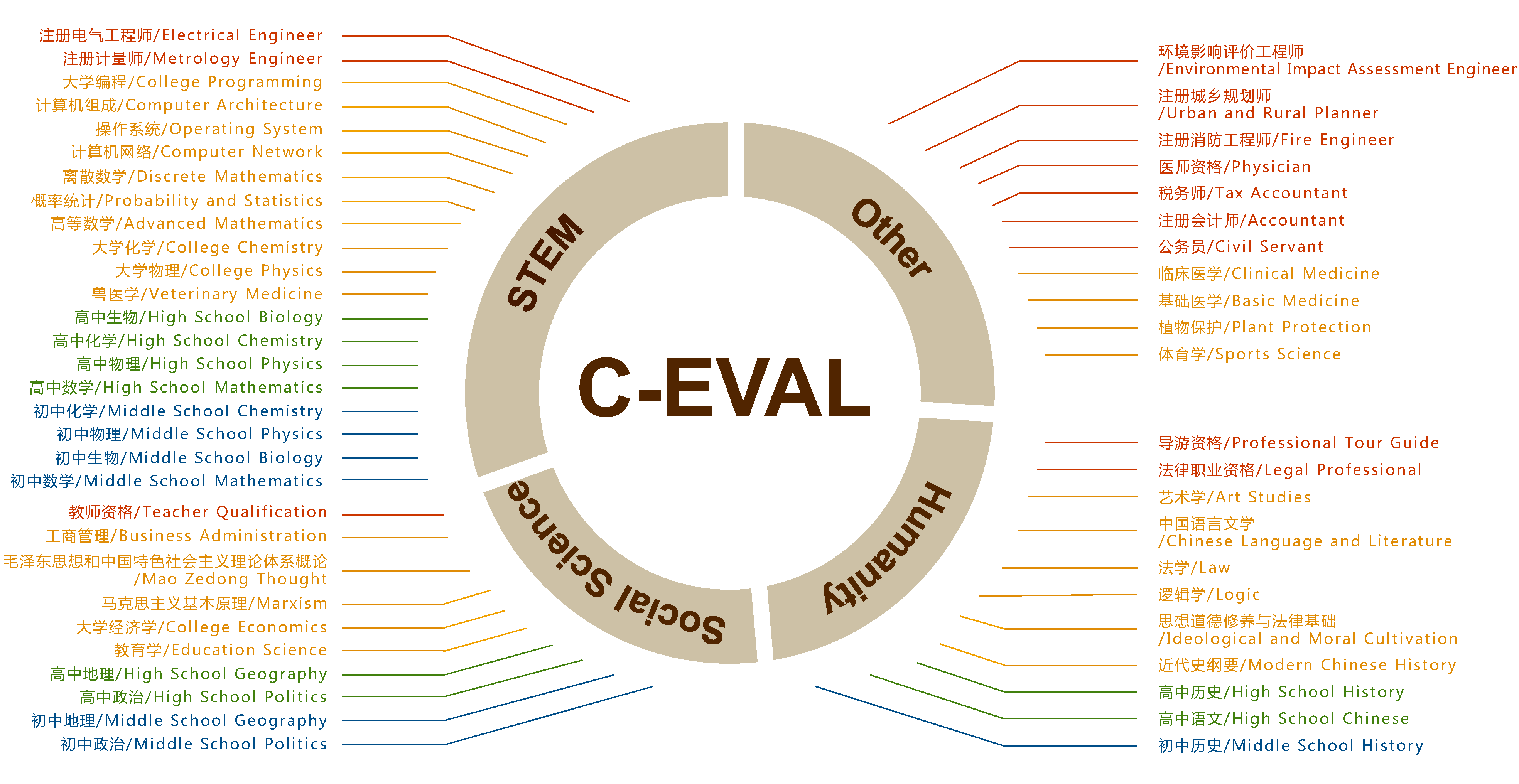
该工具非常适合人工智能研究人员、大模型开发者以及希望深入了解模型中文表现的技术团队使用。C-Eval 的独特之处在于其构建了一个涵盖 52 个不同学科领域、包含近 1.4 万道选择题的庞大题库,并细分为四个难度等级,能够全面考察模型在 STEM(科学、技术、工程、数学)、社会科学、人文学科及其他领域的知识储备与推理能力。此外,C-Eval 已集成到主流的 lm-evaluation-harness 框架中,支持零样本(zero-shot)和少样本(five-shot)等多种评估模式,方便用户快速上手测试。通过提供公开的排行榜和详细的数据集,C-Eval 已成为衡量中文大模型实力的重要标尺,助力社区共同推动中文人工智能技术的发展。
使用场景
某国内大模型初创团队在发布新版中文基座模型前,急需验证其在垂直领域的专业能力以应对投资人和客户的质询。
没有 ceval 时
- 评估维度单一:团队仅依赖通用对话测试或翻译任务,无法量化模型在医学、法律、工程等 52 个具体学科上的知识深度,导致“偏科”问题被掩盖。
- 缺乏权威对标:面对竞品宣传的“中文最强”,由于缺少统一的标准化考题和公开排行榜,难以用客观数据证明自身模型的相对优势或差距。
- 调优方向模糊:发现模型回答专业问题时表现不佳,但无法定位是逻辑推理弱还是特定领域知识缺失,导致迭代训练时资源分散,效率低下。
- 信任建立困难:在向 B 端客户交付时,只能提供主观的演示案例,缺乏类似 NeurIPS 论文背书的严谨评测报告,难以消除客户对模型“幻觉”的顾虑。
使用 ceval 后
- 全景能力画像:利用覆盖 13948 道题目的全套试题,团队迅速生成了包含 STEM、人文社科等四大维度的详细雷达图,精准锁定了模型在“临床医学”和“电路原理”上的短板。
- 确立市场坐标:通过将测试结果上传至官方 Leaderboard,团队直观看到自家模型在零样本(Zero-shot)设置下超越了同量级的开源模型,获得了有力的市场竞争背书。
- 数据驱动迭代:基于分学科的准确率反馈,算法工程师针对性地增强了理科类语料的训练权重,仅用一轮微调就将 STEM 类别的平均准确率提升了 8.5%。
- 交付信心倍增:在技术白皮书中引用 C-Eval 的标准化评测数据,成功说服了一家三甲医院客户,使其相信模型具备辅助诊疗建议生成的基础能力。
ceval 通过提供全方位、高难度的中文学科评测标准,将模糊的模型能力感知转化为可量化、可对比的硬指标,极大加速了国产大模型的精细化迭代与商业化落地。
运行环境要求
未说明(取决于具体评估的模型大小,README 中示例命令支持 --device cuda:0)
未说明

快速开始

🌐 官网 • 🤗 Hugging Face • ⏬ 数据集 • 📃 论文 📖 教程(中文)
中文 | 英文
C-Eval 是一套全面的中文基础模型评估基准,包含 13948 道多项选择题,覆盖 52 个不同学科和四个难度级别,如下所示。更多详情请访问我们的 官网 或查阅我们的 论文。
我们希望 C-Eval 能帮助开发者跟踪模型进展,并分析其关键优势与不足。
最新动态
- [2025.7.27] 我们已向社区公开完整的 C-Eval 测试集!
- [2023.10.26] C-Eval 已被 NeurIPS 2023 接收 🎉🎉🎉
- [2023.07.17] C-Eval 现已加入 lm-evaluation-harness 🚀🚀🚀 详情请参阅 通过评估框架使用。
目录
排行榜
以下是我们在首次发布时评估的模型的零样本和五样本准确率。请访问我们的官方 排行榜,以获取最新模型及其各科目的详细结果。值得注意的是,对于许多指令微调模型,零样本性能优于五样本。
零样本
| 模型 | 理工科 | 社会科学 | 人文科学 | 其他 | 平均 |
|---|---|---|---|---|---|
| GPT-4 | 65.2 | 74.7 | 62.5 | 64.7 | 66.4 |
| ChatGPT | 49.0 | 58.0 | 48.8 | 50.4 | 51.0 |
| Claude-v1.3 | 48.5 | 58.6 | 47.3 | 50.1 | 50.5 |
| Bloomz-mt-176B | 39.1 | 53.0 | 47.7 | 42.7 | 44.3 |
| GLM-130B | 36.7 | 55.8 | 47.7 | 43.0 | 44.0 |
| Claude-instant-v1.0 | 38.6 | 47.6 | 39.5 | 39.0 | 40.6 |
| ChatGLM-6B | 33.3 | 48.3 | 41.3 | 38.0 | 38.9 |
| LLaMA-65B | 32.6 | 41.2 | 34.1 | 33.0 | 34.7 |
| MOSS | 31.6 | 37.0 | 33.4 | 32.1 | 33.1 |
| Chinese-Alpaca-13B | 27.4 | 39.2 | 32.5 | 28.0 | 30.9 |
| Chinese-LLaMA-13B | 28.8 | 32.9 | 29.7 | 28.0 | 29.6 |
五样本
| 模型 | 理工科 | 社会科学 | 人文科学 | 其他 | 平均 |
|---|---|---|---|---|---|
| GPT-4 | 67.1 | 77.6 | 64.5 | 67.8 | 68.7 |
| ChatGPT | 52.9 | 61.8 | 50.9 | 53.6 | 54.4 |
| Claude-v1.3 | 51.9 | 61.7 | 52.1 | 53.7 | 54.2 |
| Claude-instant-v1.0 | 43.1 | 53.8 | 44.2 | 45.4 | 45.9 |
| GLM-130B | 34.8 | 48.7 | 43.3 | 39.8 | 40.3 |
| Bloomz-mt-176B | 35.3 | 45.1 | 40.5 | 38.5 | 39.0 |
| LLaMA-65B | 37.8 | 45.6 | 36.1 | 37.1 | 38.8 |
| ChatGLM-6B | 30.4 | 39.6 | 37.4 | 34.5 | 34.5 |
| Chinese LLaMA-13B | 31.6 | 37.2 | 33.6 | 32.8 | 33.3 |
| MOSS | 28.6 | 36.8 | 31.0 | 30.3 | 31.1 |
| Chinese Alpaca-13B | 26.0 | 27.2 | 27.8 | 26.4 | 26.7 |
C-Eval Hard 排行榜
我们从 C-Eval 中选取了 8 门具有挑战性的数学、物理和化学科目,组成独立的基准 C-Eval Hard,涵盖高等数学、离散数学、概率统计、大学化学、大学物理、高中数学、高中化学和高中物理。这些科目通常涉及复杂的 LaTeX 公式,需要较强的推理能力才能解答。以下展示了零样本和五样本的准确率。
| 模型 | 零样本 | 五样本 |
|---|---|---|
| GPT-4 | 53.3 | 54.9 |
| Claude-v1.3 | 37.6 | 39.0 |
| ChatGPT | 36.7 | 41.4 |
| Claude-instant-v1.0 | 32.1 | 35.5 |
| Bloomz-mt | 30.8 | 30.4 |
| GLM-130B | 30.7 | 30.3 |
| LLaMA-65B | 29.8 | 31.7 |
| ChatGLM-6B | 29.2 | 23.1 |
| MOSS | 28.4 | 24.0 |
| Chinese-LLaMA-13B | 27.5 | 27.3 |
| Chinese-Alpaca-13B | 24.4 | 27.1 |
验证集结果
由于我们未公开测试集的答案标签,因此提供验证集上的零样本和五样本平均准确率,供开发者参考。验证集共包含 1346 道题目。下表报告了所有科目中仅基于答案的平均准确率。验证集的平均准确率与 排行榜 中展示的测试集平均准确率非常接近。
| 模型 | 零样本 | 五样本 |
|---|---|---|
| GPT-4 | 66.7 | 69.9 |
| Claude-v1.3 | 52.1 | 55.5 |
| ChatGPT | 50.8 | 53.5 |
| Bloomz-mt | 45.9 | 38.0 |
| GLM-130B | 44.2 | 40.8 |
| Claude-instant-v1.0 | 43.2 | 47.4 |
| ChatGLM-6B | 39.7 | 37.1 |
| LLaMA-65B | 38.6 | 39.8 |
| MOSS | 35.1 | 28.9 |
| Chinese-Alpaca-13B | 32.0 | 27.2 |
| Chinese-LLaMA-13B | 29.4 | 33.1 |
数据
下载
方法 1:下载 zip 文件(你也可以直接用浏览器打开以下链接):
wget https://huggingface.co/datasets/ceval/ceval-exam/resolve/main/ceval-exam.zip然后解压,即可使用 pandas 加载数据:
import os import pandas as pd File_Dir="ceval-exam" test_df=pd.read_csv(os.path.join(File_Dir,"test","computer_network_test.csv"))方法 2:直接使用 Hugging Face datasets 加载数据集:
from datasets import load_dataset dataset=load_dataset(r"ceval/ceval-exam",name="computer_network") print(dataset['val'][0]) # {'id': 0, 'question': '使用位填充方法,以01111110为位首flag,数据为011011111111111111110010,求问传送时要添加几个0____', 'A': '1', 'B': '2', 'C': '3', 'D': '4', 'answer': 'C', 'explanation': ''}
注意事项
为了方便使用,我们整理了 52 个科目的科目名称处理器及其对应的英文和中文名称。详细信息请参阅 subject_mapping.json。格式如下:
# 字典键是科目处理器,字典值是一个包含 (英文名称, 中文名称, 类别) 的元组
{
"computer_network": [
"Computer Network",
"计算机网络",
"STEM"
],
...
"filename":[
"English Name",
"Chinese Name"
"Supercatagory Label(STEM, Social Science, Humanities or Other)"
]
}
每个科目包含三个划分:dev、val 和 test。每个科目的 dev 集由五个示例组成,并附有解释,用于少样本评估。val 集用于超参数调优。而 test 集则用于模型评估。test 划分上的标签不会公开,用户需要提交结果以自动获取测试准确率。如何提交?
以下是计算机网络的一个 dev 示例:
id: 1
question: 25 °C时,将pH=2的强酸溶液与pH=13的强碱溶液混合,所得混合液的pH=11,则强酸溶液与强碱溶液 的体积比是(忽略混合后溶液的体积变化)____
A: 11:1
B: 9:1
C: 1:11
D: 1:9
answer: B
explanation:
1. pH=13的强碱溶液中c(OH-)=0.1mol/L, pH=2的强酸溶液中c(H+)=0.01mol/L,酸碱混合后pH=11,即c(OH-)=0.001mol/L。
2. 设强酸和强碱溶液的体积分别为x和y,则:c(OH-)=(0.1y-0.01x)/(x+y)=0.001,解得x:y=9:1。
如何在 C-Eval 上进行评估
通常情况下,你可以直接提取模型生成的内容中的答案标记(即 A、B、C、D),使用简单的正则表达式即可。在少样本评估中,模型通常会遵循给定的模板,因此这很容易实现。然而,在零样本评估中,尤其是对于未经过指令微调的模型,模型可能无法很好地遵循指令生成格式良好的回答。在这种情况下,我们建议计算“A”、“B”、“C”、“D”的概率,并选择概率最高的作为答案——这是一种受限解码方法,官方的 MMLU 测试代码 中也采用了这种方法。不过,这种概率方法不适用于思维链设置。更详细的评估教程(中文)。
我们在首次发布时使用以下提示来评估模型:
仅答案提示
以下是中国关于{科目}考试的单项选择题,请选出其中的正确答案。
{题目1}
A. {选项A}
B. {选项B}
C. {选项C}
D. {选项D}
答案:A
[k-shot demo,注意在零样本情况下k为0]
{测试题目}
A. {选项A}
B. {选项B}
C. {选项C}
D. {选项D}
答案:
思维链提示
以下是中国关于{科目}考试的单项选择题,请选出其中的正确答案。
{题目1}
A. {选项A}
B. {选项B}
C. {选项C}
D. {选项D}
答案:让我们一步一步思考,
1. {解析过程步骤1}
2. {解析过程步骤2}
3. {解析过程步骤3}
所以答案是A。
[k-shot demo,注意在零样本情况下k为0]
{测试题目}
A. {选项A}
B. {选项B}
C. {选项C}
D. {选项D}
答案:让我们一步一步思考,
1.
使用评估框架进行评估
现在,你可以通过 lm-evaluation-harness 在 C-Eval 的验证集上评估模型,这是一个用于自回归语言模型少样本评估的框架。任务名称的格式为 Ceval-valid-{subject}(例如 Ceval-valid-computer_network)。例如,要评估托管在 HuggingFace Hub 上的模型(如 GPT-J-6B),可以使用以下命令:
python main.py --model hf-causal --model_args pretrained=EleutherAI/gpt-j-6B --tasks Ceval-valid-computer_network --device cuda:0
更多详情请参阅 lm-evaluation-harness。
许可证
![]()
本作品采用 MIT 许可证 许可。
![]()
C-Eval 数据集采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可。
引用
如果您使用我们的数据集,请引用我们的论文。
@inproceedings{huang2023ceval,
title={C-Eval: 一个面向基础模型的多层级、多学科中文评估套件},
author={黄宇珍、白宇卓、朱志浩、张俊磊、张景涵、苏唐军、刘俊腾、吕传成、张一凯、雷佳怡、傅瑶、孙茂松、何俊贤},
booktitle={神经信息处理系统进展},
year={2023}
}
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。