neuronpedia
Neuronpedia 是一个开源的模型可解释性平台,旨在帮助人们深入理解大型语言模型内部的运作机制。它就像为 AI 模型打造的一座“透明博物馆”,让原本黑盒般的神经网络变得清晰可见。
在 AI 研究中,理解模型为何做出特定决策一直是个难题。Neuronpedia 通过可视化神经元激活、自动生成功能解释、构建电路图谱等核心功能,让用户能够轻松探索模型内部结构,分析特定神经元的触发条件,甚至尝试对模型行为进行干预和引导。
该平台特别适合 AI 研究人员、机器学习工程师以及对模型机理感兴趣的技术开发者使用。无论是需要调试模型行为的研究者,还是希望深入理解训练过程的工程师,都能从中获得直观的数据洞察。
技术亮点方面,Neuronpedia 提供了丰富的工具链:支持自动解释生成(Autointerp)、神经元相似度搜索、多维数据降维可视化(UMAP)、实时激活监控仪表盘等功能。其模块化架构允许用户灵活部署本地环境,既可进行小规模实验,也能支撑大规模分析任务。作为开源项目,它还鼓励社区贡献数据和工具,共同推动模型可解释性研究的发展。
使用场景
某 AI 安全团队正在对开源大模型进行“机械可解释性”研究,试图定位并修复模型中产生种族歧视言论的特定神经元回路。
没有 neuronpedia 时
- 黑盒摸索:研究人员只能面对数亿个权重的原始矩阵,无法直观看到哪些神经元被特定有害概念激活,排查如同大海捞针。
- 手工复现困难:想要验证某个神经元的假设,需手动编写复杂的推理代码和激活提取脚本,环境配置耗时且容易出错。
- 协作效率低下:团队成员发现的潜在“恶意神经元”散落在各自的笔记和日志中,缺乏统一平台进行标注、评分和共享验证结果。
- 解释生成缓慢:为每个候选神经元生成人类可读的功能描述(AutoInterp)需要单独调用 API 并整理数据,流程繁琐且难以规模化。
使用 neuronpedia 后
- 可视化透视:利用其内置的激活热力图和 UMAP 降维图表,团队迅速锁定了几个对歧视性词汇响应强烈的稀疏自编码器(SAE)特征。
- 一键干预验证:通过平台的 Steering(引导)功能,直接在网页端对这些神经元进行抑制测试,实时观察模型输出是否变得中立,无需重写推理代码。
- 社区协同标注:团队成员将可疑特征添加到公共 Dashboard,利用评分系统和评论功能快速对齐认知,确认了关键的“歧视回路”。
- 自动化解释:调用集成的 AutoInterp 服务,批量生成了这些神经元的自然语言解释(如“此特征专门编码针对特定族群的负面刻板印象”),大幅加速了分析报告的撰写。
neuronpedia 将原本需要数周的黑盒逆向工程,缩短为几天内可完成的可视化诊断与精准修复流程,让大模型内部机制真正变得透明可控。
运行环境要求
- 未说明
- 可选
- 支持 CUDA (NVIDIA GPU) 以加速推理
- 若无 GPU 可使用 CPU 模式运行
- 具体显存大小和 CUDA 版本未在片段中明确,但提及模型计算密集且内存占用高
未说明(但提示模型运行对内存和计算资源要求较高)

快速开始

neuronpedia.org 🧠🔍
开源可解释性平台
API · 引导 · 激活值 · 电路/图谱 · 自动解释 · 评分 · 推理 · 搜索 · 过滤 · 仪表盘 · 基准测试 · 余弦相似度 · UMAP · 嵌入 · 探针 · SAE · 列表 · 导出 · 上传
![]()

![]()
![]()
![]()
- 关于 Neuronpedia
- 设置本地环境
- 架构
- 安全
- [联系 / 支持] (#contact--support)
- 贡献
- [附录] (#appendix)
- ['Make' 命令参考] (#make-commands-reference)
- [将数据导入本地数据库] (#import-data-into-your-local-database)
- [为什么搜索解释需要 OpenAI API 密钥] (#why-an-openai-api-key-is-needed-for-search-explanations)
关于 Neuronpedia
请查看我们的博客文章,了解有关 Neuronpedia 的信息、我们开源它的原因以及其他细节。此外,还有一个包含快速演示的Twitter 线程。
功能概览
一张展示截至 2025 年 3 月 Neuronpedia 主要功能的示意图。
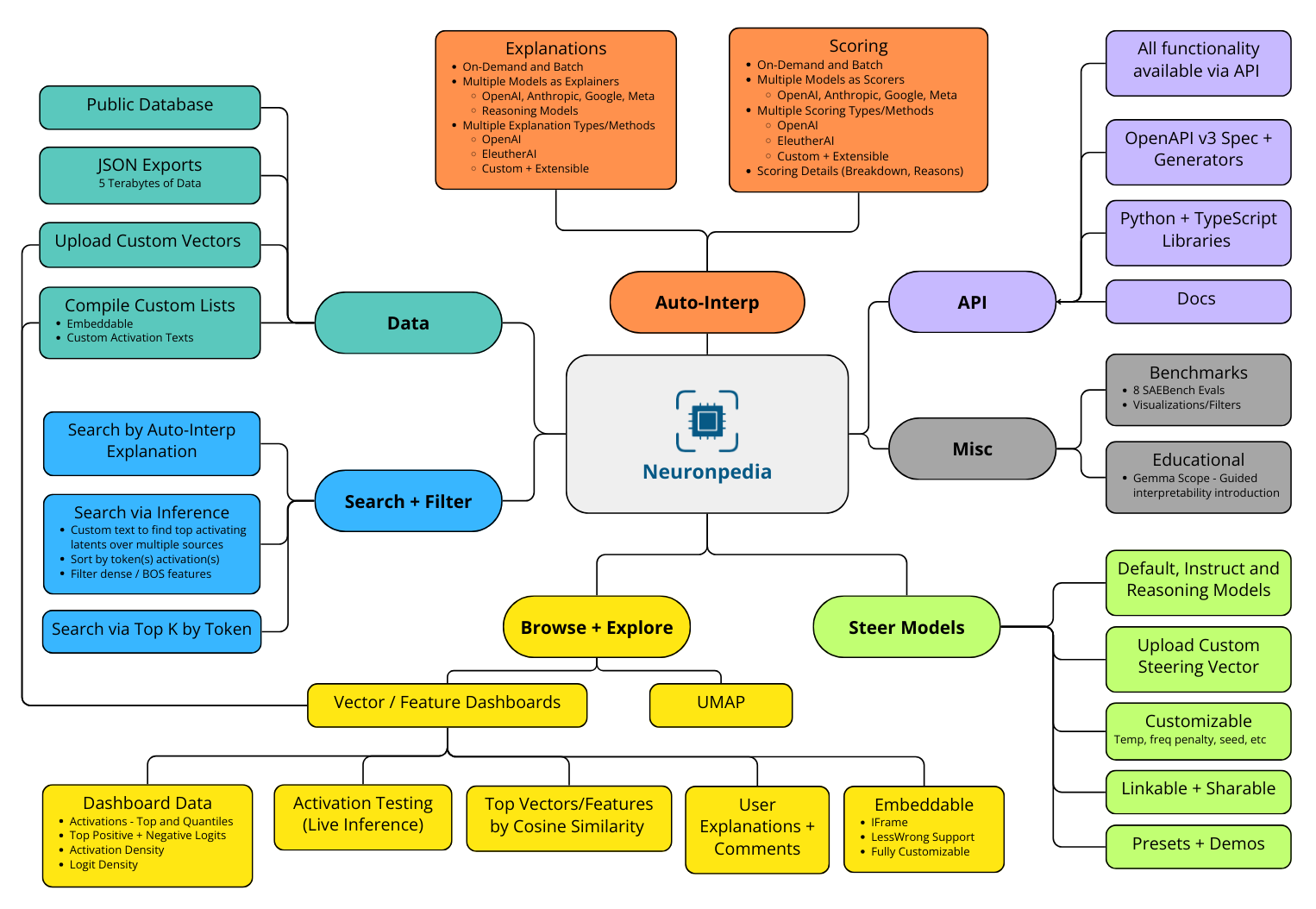
设置本地环境
首先设置你的本地数据库。
🔥 小贴士: Neuronpedia 针对 AI 代理开发进行了配置。以下是一个使用单个提示构建自定义应用(Steerify)的例子,该应用以 Neuronpedia 的推理服务器作为后端:
https://github.com/user-attachments/assets/bc82f88b-8155-4c1d-948a-ea5d987ae0f8
“我想使用本地数据库 / 导入更多 Neuronpedia 数据”
这些步骤的作用及你将获得的内容
这些步骤将指导你如何配置并连接到自己的本地数据库。随后,你可以下载自己选择的数据源/SAE:
https://github.com/user-attachments/assets/d7fbb46e-8522-4f98-aa08-21c6529424af
⚠️ 警告: 你的数据库初始为空。你需要使用管理面板来导入数据(激活值、解释等)。
⚠️ 警告: 本地数据库环境中没有连接任何推理服务器,因此你最初无法进行激活测试、引导等操作。你需要配置一个本地推理实例。
步骤
- 构建 Web 应用
make webapp-localhost-build - 启动 Web 应用
make webapp-localhost-run - 访问 localhost:3000 查看你的本地 Web 应用实例,它现已连接到你的本地数据库
- 参阅上述“警告”部分以及“后续步骤”,完成设置
后续步骤
“我想进行 Web 应用(前端 + API)开发”
这部分的作用
到目前为止,你一直在构建的 Web 应用都是 生产构建,这种构建方式虽然运行速度快,但构建过程较慢。由于生产构建速度慢且不包含调试信息,因此并不适合开发使用。
本小节会在你的本地机器上安装开发构建版本(不使用 Docker),然后将该构建挂载到你的 Docker 容器中。
你将获得什么
完成本小节后,你就可以在本地进行开发,并能快速看到代码更改的效果,同时还能看到更详细的调试信息和错误提示。如果你只是想专注于 Neuronpedia 的前端或 API 开发,那么无需再进行其他设置!
操作步骤
- 通过 Node 版本管理工具 安装 Node.js:
make install-nodejs - 安装 Web 应用的依赖项:
make webapp-localhost-install - 启动开发实例:
make webapp-localhost-dev - 打开 localhost:3000,即可查看你的本地 Web 应用实例。
在本地进行 Web 应用开发
- 自动刷新:当你修改
apps/webapp子目录中的任何文件时,localhost:3000会自动重新加载。 - 安装命令:你无需再次运行
make install-nodejs,并且只有在依赖项发生变化时才需要运行make webapp-localhost-install。
“我想在本地运行/开发推理”
这部分的作用及你将获得的内容
本小节将向你展示如何在本地运行一个推理实例,以便你可以对你下载的源数据或 SAE 集合进行引导、激活测试等操作。
⚠️ 警告: 在本地环境中,我们仅支持同时运行一个推理服务器。这是因为你在同一台机器上不太可能同时运行多个模型,因为这些模型对内存和计算资源的需求都非常高。
操作步骤
确保你已安装 Poetry。
安装推理服务器的依赖项:
make inference-localhost-install根据你的机器是否配备 CUDA 来构建镜像:
# CUDA make inference-localhost-build-gpu USE_LOCAL_HF_CACHE=1# 无 CUDA make inference-localhost-build USE_LOCAL_HF_CACHE=1➡️
USE_LOCAL_HF_CACHE=1标志会将你本地的 HuggingFace 缓存挂载到${HOME}/.cache/huggingface/hub:/root/.cache/huggingface/hub。如果你希望在容器中创建一个新的缓存,可以在此处以及下一步中省略该标志。运行推理服务器,使用
MODEL_SOURCESET参数指定你要加载的.env.inference.[model_sourceset]文件。以本示例为例,我们将运行gpt2-small,并加载配置在.env.inference.gpt2-small.res-jb文件中的res-jb源数据集/SAE 集合。你也可以查看其他预加载的推理配置,或者创建自己的配置。# CUDA make inference-localhost-dev-gpu \ MODEL_SOURCESET=gpt2-small.res-jb \ USE_LOCAL_HF_CACHE=1 # 无 CUDA make inference-localhost-dev \ MODEL_SOURCESET=gpt2-small.res-jb \ USE_LOCAL_HF_CACHE=1等待加载完成(首次启动会较慢)。当看到
Initialized: True时,本地推理服务器已在localhost:5002上准备就绪。
使用推理服务器
要与推理服务器交互,你有几种选择——请注意,这仅适用于你已加载的模型和选定的源数据:
- 加载带有本地数据库设置的 Web 应用程序,然后像在 Neuronpedia 上一样正常使用模型和选定的源数据。
- 使用位于
packages/python/neuronpedia-inference-client的预生成推理 Python 客户端(将环境变量INFERENCE_SERVER_SECRET设置为public,或者根据你在.env.localhost中的设置进行调整)。 - 使用位于
schemas/openapi/inference-server.yaml的 OpenAPI 规范,通过任何你喜欢的客户端发起调用。服务器启动后,你可以在/docs获得交互式的 Swagger 文档。详细信息请参阅apps/inference/README.md。
预加载的推理服务器配置
我们提供了一些预加载的推理配置,作为如何加载特定模型和源数据集进行推理的示例。可通过运行 make inference-list-configs 查看:
$ make inference-list-configs
可用的推理配置 (.env.inference.*)
================================================
deepseek-r1-distill-llama-8b.llamascope-slimpj-res-32k
模型:meta-llama/Llama-3.1-8B
源/SAE 集合:'["llamascope-slimpj-res-32k"]'
make inference-localhost-dev MODEL_SOURCESET=deepseek-r1-distill-llama-8b.llamascope-slimpj-res-32k
gemma-2-2b-it.gemmascope-res-16k
模型:gemma-2-2b-it
源/SAE 集合:'["gemmascope-res-16k"]'
make inference-localhost-dev MODEL_SOURCESET=gemma-2-2b-it.gemmascope-res-16k
gpt2-small.res-jb
模型:gpt2-small
源/SAE 集合:'["res-jb"]'
make inference-localhost-dev MODEL_SOURCESET=gpt2-small.res-jb
创建你自己的推理服务器配置
可参考 .env.inference.* 文件,了解如何制作这些推理服务器配置。
MODEL_ID 是来自 transformerlens 模型表的模型 ID,而每个 SAE_SETS 则是 Neuronpedia 源 ID 中层号和连字符之后的部分——例如,如果你有一个 Neuronpedia 特征的 URL 是 http://neuronpedia.org/gpt2-small/0-res-jb/123,那么 0-res-jb 就是源 ID,而 SAE_SETS 中的条目就是 res-jb。此示例与 .env.inference.gpt2-small.res-jb 文件完全一致。
你可以在 saelens 的预训练 SAE YAML 文件中找到 Neuronpedia 源 ID,或者通过点击进入 Neuronpedia 数据集导出目录来查找。
使用 TransformerLens 官方不支持的模型
可参考 .env.inference.deepseek-r1-distill-llama-8b.llamascope-slimpj-res-32k 文件,了解如何加载 TransformerLens 官方不支持的模型。这主要用于替换蒸馏或微调后的权重。
加载非 Saelens 的源数据/SAE
- 待办事项 #2 记录了如何加载不在 saelens 预训练 YAML 文件中的 SAE 或源数据。
进行本地推理开发
- 基于 schema 的开发:若要添加新端点或更改现有端点,你需要先更新 OpenAPI schema,然后从中生成客户端,最后再更新实际的推理和 Web 应用程序代码。有关具体操作方法,请参阅 OpenAPI 说明文档:修改推理服务器。
- 无自动重载:当你更改
apps/inference子目录中的任何文件时,推理服务器不会自动重新加载,因为服务器重启非常耗时——它会重新加载模型以及所有源数据和 SAE。如果你想启用自动重载,可以在make inference-localhost-dev命令中添加AUTORELOAD=1,如下所示:make inference-localhost-dev \ MODEL_SOURCESET=gpt2-small.res-jb \ AUTORELOAD=1
‘我想在本地运行/开发图服务器’
这能做什么 + 你会得到什么
图服务器为归因图生成功能提供支持,该功能基于 Piotrowski 和 Hanna 开发的 circuit-tracer 构建。当您通过 Neuronpedia Circuit Tracer 界面创建新图时,此服务会处理后端流程。
步骤
- 确保已安装 Poetry
- 安装图服务器的依赖项:
make graph-localhost-install - 在
apps/graph目录下,创建一个包含SECRET和HF_TOKEN的.env文件(参见apps/graph/.env.example):SECRET是服务器密钥,需在x-secret-key请求头中传递。- 确保您的
HF_TOKEN具有访问 Hugging Face 上 Gemma-2-2B 模型的权限。
- 根据机器是否配备 CUDA,选择正确的命令来构建镜像:
# CUDA make graph-localhost-build-gpu USE_LOCAL_HF_CACHE=1# 无 CUDA make graph-localhost-build USE_LOCAL_HF_CACHE=1➡️
USE_LOCAL_HF_CACHE=1标志会将您本地的 Hugging Face 缓存挂载到${HOME}/.cache/huggingface/hub:/root/.cache/huggingface/hub。如果您希望在容器内创建新的缓存,则可以在此处及下一步省略此标志。 - 运行图服务器:
# CUDA make graph-localhost-dev-gpu \ USE_LOCAL_HF_CACHE=1 # 无 CUDA make graph-localhost-dev \ USE_LOCAL_HF_CACHE=1 - 等待容器启动。
有关示例请求,请参阅 图服务器 README。
‘我想在本地运行/开发自动解释器’
这能做什么 + 你会得到什么
自动解释器服务器提供对神经网络特征的自动解释和评分功能。它使用 eleutherAI 的 delphi 来生成解释并进行评分。
⚠️ 警告: eleuther 嵌入评分器使用的嵌入模型仅支持 CUDA(无法在 Mac MPS 或 CPU 上运行)。
步骤
- 确保已安装 Poetry
- 安装自动解释器服务器的依赖项:
make autointerp-localhost-install - 根据机器是否配备 CUDA,选择正确的命令来构建镜像:
# CUDA make autointerp-localhost-build-gpu USE_LOCAL_HF_CACHE=1# 无 CUDA make autointerp-localhost-build USE_LOCAL_HF_CACHE=1➡️
USE_LOCAL_HF_CACHE=1标志会将您本地的 Hugging Face 缓存挂载到${HOME}/.cache/huggingface/hub:/root/.cache/huggingface/hub。如果您希望在容器内创建新的缓存,则可以在此处及下一步省略此标志。 - 运行自动解释器服务器:
# CUDA make autointerp-localhost-dev-gpu \ USE_LOCAL_HF_CACHE=1 # 无 CUDA make autointerp-localhost-dev \ USE_LOCAL_HF_CACHE=1 - 等待加载完成。
使用自动解释器服务器
要与自动解释器服务器交互,您可以选择以下几种方式:
- 使用预生成的自动解释器 Python 客户端,位于
packages/python/neuronpedia-autointerp-client(将环境变量AUTOINTERP_SERVER_SECRET设置为public,或根据您在.env.localhost中的设置进行更改)。 - 使用 OpenAPI 规范文件,位于
schemas/openapi/autointerp-server.yaml,以便使用您选择的任何客户端发起调用。服务器启动后,您可以在/docs获取 Swagger 交互式规范。详细信息请参阅apps/inference/README.md。
进行本地自动解释器开发
- 基于 schema 的开发:要添加新端点或更改现有端点,您需要先更新 OpenAPI schema,然后从中生成客户端,最后再更新实际的自动解释器和 Web 应用程序代码。有关具体操作方法,请参阅 OpenAPI README:修改自动解释器服务器。
- 无自动重载:当您更改
apps/autointerp子目录中的任何文件时,默认情况下自动解释器服务器不会自动重新加载。如果您希望启用自动重载,可在make autointerp-localhost-dev命令中附加AUTORELOAD=1,如下所示:make autointerp-localhost-dev \ AUTORELOAD=1
‘我想进行高容量的自动解释说明’
本节正在建设中。
- 使用 EleutherAI 的 Delphi 库。
- 对于 OpenAI 的自动解释,可使用 utils/neuronpedia_utils/batch-autointerp.py。
‘我想生成自己的仪表板/数据,并将其添加到 Neuronpedia’
本节正在建设中。
待办事项:简化数据生成及上传至 Neuronpedia 的流程
待办事项:neuronpedia-utils 应使用 Poetry
在本示例中,我们将为一个与 SAELens 兼容的 SAE 生成仪表板/数据,并将其上传到我们自己的 Neuronpedia 实例。
确保已安装 Poetry。
将您与 SAELens 兼容的源代码/SAE 上传 至 HuggingFace。
示例 ➡️ https://huggingface.co/chanind/gemma-2-2b-batch-topk-matryoshka-saes-w-32k-l0-40
在本地克隆 SAELens。
git clone https://github.com/jbloomAus/SAELens.git打开您克隆的 SAELens,并编辑文件
sae_lens/pretrained_saes.yaml。根据下方模板,在文件末尾添加一条新条目(请参阅注释以了解如何填写):gemma-2-2b-res-matryoshka-dc: # 您 SAE 集合的唯一标识符 conversion_func: null # 如果您的 SAE 配置已与 SAELens 兼容,则设为 null links: # 可选链接 model: https://huggingface.co/google/gemma-2-2b model: gemma-2-2b # TransformerLens 模型 ID - https://transformerlensorg.github.io/TransformerLens/generated/model_properties_table.html repo_id: chanind/gemma-2-2b-batch-topk-matryoshka-saes-w-32k-l0-40 # HuggingFace 仓库路径 saes: - id: blocks.0.hook_resid_post # 此 SAE 的标识符 path: standard/blocks.0.hook_resid_post # 仓库路径中指向该 SAE 的位置 l0: 40.0 neuronpedia: gemma-2-2b/0-matryoshka-res-dc # 您期望的 Neuronpedia URI - neuronpedia.org/[此_slug]。应为 [模型ID]/[层]-[与此 SAE 集相同的 slug] - id: blocks.1.hook_resid_post # 此 SAE 集中的更多 SAE path: standard/blocks.1.hook_resid_post l0: 40.0 neuronpedia: gemma-2-2b/1-matryoshka-res-dc # 注意,此处与上方条目相同,只是层号从 0 改为 1 - [...]在本地克隆 SAEDashboard。
git clone https://github.com/jbloomAus/SAEDashboard.git配置您克隆的
SAEDashboard以使用您修改后的本地SAELens,而非生产环境中的版本。cd SAEDashboard # 进入目录 poetry lock && poetry install # 安装依赖 poetry remove sae-lens # 移除生产依赖 poetry add PATH/TO/CLONED/SAELENS # 设置本地依赖为 SAE 生成仪表板。这将耗时 30 分钟至数小时不等,具体取决于您的硬件和模型规模。
cd SAEDashboard # 进入目录 rm -rf cached_activations # 清除旧的缓存数据 # 开始生成。各参数说明如下(详细信息:https://github.com/jbloomAus/SAEDashboard/blob/main/sae_dashboard/neuronpedia/neuronpedia_runner_config.py) # - sae-set = 应与 pretrained_saes.yaml 中该集合的唯一标识符匹配 # - sae-path = 应与 pretrained_saes.yaml 中该 SAE 的标识符匹配 # - np-set-name = 应与 pretrained_saes.yaml 中该 SAE 的 neuronpedia 字段所指定的 [与此 SAE 集相同的 slug] 匹配 # - dataset-path = 用于生成激活值的 HuggingFace 数据集。通常建议使用模型训练时所用的数据集。 # - output-dir = 仪表板数据的输出目录 # - n-prompts = 从数据集中测试的激活文本数量 # - n-tokens-in-prompt、n-features-per-batch、n-prompts-in-forward-pass = 保持为 128 poetry run neuronpedia-runner \ --sae-set="gemma-2-2b-res-matryoshka-dc" \ --sae-path="blocks.12.hook_resid_post" \ --np-set-name="matryoshka-res-dc" \ --dataset-path="monology/pile-uncopyrighted" \ --output-dir="neuronpedia_outputs/" \ --sae_dtype="float32" \ --model_dtype="bfloat16" \ --sparsity-threshold=1 \ --n-prompts=24576 \ --n-tokens-in-prompt=128 \ --n-features-per-batch=128 \ --n-prompts-in-forward-pass=128将这些仪表板转换为可导入 Neuronpedia 的格式。
cd neuronpedia/utils/neuronpedia-utils # 进入当前仓库的工具目录 python convert-saedashboard-to-neuronpedia.py # 启动引导式转换脚本,按照步骤操作。一旦为 Neuronpedia 生成了仪表板文件,便将其上传至全球 Neuronpedia S3 存储桶——目前您需要通过 联系我们 来完成此操作。
在本地实例上,导入您的数据。
架构
以下是 Neuronpedia 中各服务/脚本之间的连接方式。阅读此图时,建议从笔记本电脑图像(“用户”)开始。
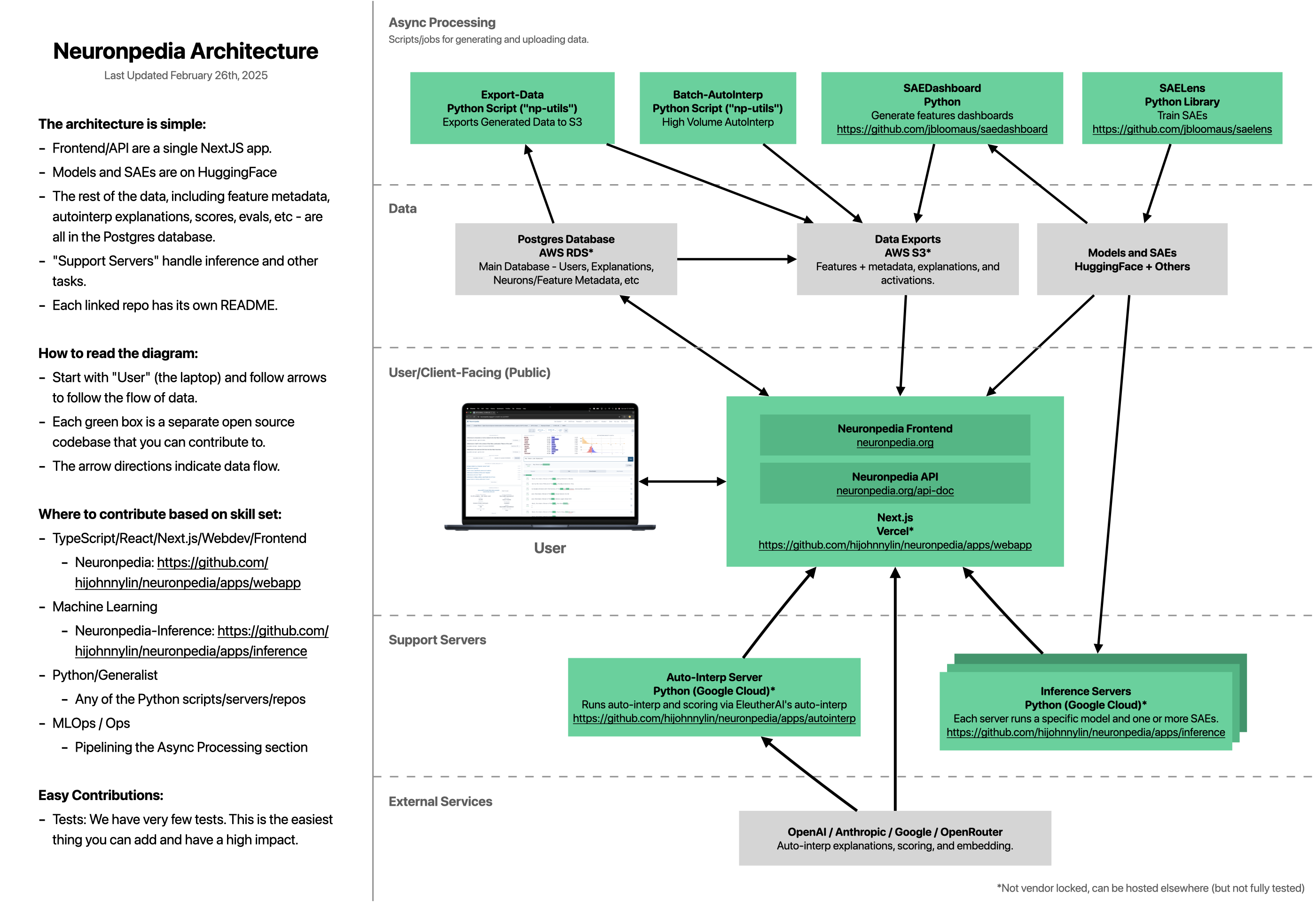
要求
您可以在任何云平台和现代操作系统上运行 Neuronpedia。Neuronpedia 的设计旨在避免供应商锁定。本指南是在 macOS 15(Sequoia)上编写并测试的,因此您可能需要针对 Windows、Ubuntu 等系统调整命令。建议至少配备 16GB 内存。
服务
| 名称 | 描述 | 技术栈 |
|---|---|---|
| webapp | 提供 neuronpedia.org 前端及 API | next.js / react |
| database | 存储特征、激活值、解释、用户、列表等信息 | postgres |
| inference | [支持服务器] 方向控制、激活测试、通过推理进行搜索、topk 等功能。每运行一个模型的推理,都需要单独的实例。 | python / torch |
| autointerp | [支持服务器] 使用 eleutherAI 的 delphi(原 sae-auto-interp)自动生成解释和评分。 |
python |
服务是独立的应用程序
根据设计,每个服务都可以作为独立的应用程序单独运行。这样做的目的是为了提高可扩展性和可分叉性。
例如,如果你喜欢 Neuronpedia 的 Web 应用前端,但想使用不同的 API 进行推理,你完全可以做到!只需确保你的替代推理服务器支持 schema/openapi/inference-server.yaml 规范,或者修改 apps/webapp/lib/utils 中调用推理的部分即可。
服务特定文档
目前在 apps/[service] 目录下有针对每个应用/服务的草稿 README,但这些文档仍在 heavily WIP 阶段。你也可以查看同一目录下的 Dockerfile 来构建自己的镜像。
OpenAPI 模式
为了让各个服务之间能够以类型安全且一致的方式进行通信,我们使用 OpenAPI 模式。当然也有一些例外情况——比如流式传输并不被 OpenAPI 规范正式支持。不过即便如此,我们仍然会尽力定义并使用相应的模式。
尤其对于推理和自动解释服务器的开发来说,理解并遵循 OpenAPI README 中的说明至关重要。
OpenAPI 模式的文件位于 /schemas 目录下。我们使用 OpenAPI 生成工具来分别生成 TypeScript 和 Python 客户端。
单仓库目录结构
apps - Neuronpedia 的三个服务:webapp、inference 和 autointerp。大部分代码都放在这里。
schemas - OpenAPI 模式。如果要修改推理和自动解释的接口,首先需要修改它们的模式——详情请参阅 OpenAPI README。
packages - 由 schemas 使用生成工具生成的客户端。通常情况下,你不需要手动修改这些文件。
utils - 各种实用工具,用于执行离线处理任务,比如大批量的自动解释、生成仪表盘或导出数据等。
安全
请将漏洞报告发送至 johnny@neuronpedia.org。
我们目前还没有正式的漏洞赏金计划,但我们会根据漏洞的严重程度尽力给予补偿——尽管对于低危漏洞,我们可能无法提供奖励。
联系方式 / 支持
- Slack: 加入 #neuronpedia
- 邮箱: johnny@neuronpedia.org
- 问题: GitHub issues
贡献
请参阅 CONTRIBUTING.md。
附录
make 命令参考
你可以通过运行 make help 查看所有可用的 make 命令及其简要说明。
将数据导入本地数据库
如果你设置了属于自己的数据库,它一开始将是空的——没有特征、解释、激活值等。要加载这些数据,可以使用内置的“管理面板”,从中下载你选择的 SAE(或“源”)的数据。
⚠️ 警告: 管理面板比较挑剔,目前不支持断点续传。如果导入过程中断,你必须手动点击“重新同步”。管理面板目前不会检查下载是否完整或是否有缺失部分——你需要自己确认数据是否完整,如果不完整则需点击“重新同步”以重新下载整个数据集。
ℹ️ 建议: 导入数据时,建议先从一个源开始(比如
gpt2-small@10-res-jb),而不是一次性下载所有数据。这样更容易验证数据是否正确导入,并能更快地开始使用 Neuronpedia。
以下步骤演示如何下载 gpt2-small@10-res-jb 的 SAE 数据。
- 打开 localhost:3000/admin。
- 向下滚动到
gpt2-small,然后展开res-jb。 - 点击
10-res-jb旁边的“下载”按钮。 - 请耐心等待——这可能会涉及大量数据,具体时间取决于你的网络连接和 CPU 速度,可能需要 30 分钟甚至一个小时。
- 下载完成后,点击“浏览”或使用导航栏尝试使用:跳转、搜索、方向控制。
- 对其他你想下载的 SAE/源数据重复上述步骤。
为什么搜索解释功能需要 OpenAI API 密钥
在 Web 应用中,“搜索解释”功能要求你设置一个 OPENAI_API_KEY。否则你将无法获得任何搜索结果。
这是因为“搜索解释”功能是通过语义相似度来查找特征的。例如,如果你搜索“猫”,它也会返回“猫科动物”、“虎斑猫”、“动物”等。要做到这一点,系统需要计算你输入“猫”的嵌入向量。我们使用 OpenAI 的嵌入 API(具体为 text-embedding-3-large,维度为 256)来计算这些嵌入向量。
版本历史
v1.0.6882026/04/04v1.0.6872026/04/04v1.0.6862026/04/04v1.0.6852026/04/04v1.0.6842026/04/04v1.0.6832026/04/04v1.0.6822026/04/04v1.0.6812026/04/04v1.0.6802026/04/04v1.0.6792026/04/04v1.0.6782026/04/04v1.0.6772026/04/03v1.0.6762026/04/03v1.0.6752026/04/03v1.0.6742026/04/03v1.0.6732026/04/03v1.0.6722026/04/03v1.0.6712026/04/03v1.0.6702026/04/01v1.0.6692026/04/01常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。