GRU4Rec
GRU4Rec 是一款专为“基于会话的推荐系统”设计的开源算法实现,旨在解决用户在未登录或无历史数据时,如何仅凭当前浏览序列精准预测其下一步兴趣的难题。它源自两篇发表于 ICLR 的重要学术论文,利用循环神经网络(RNN)中的门控循环单元(GRU)来捕捉用户行为的时间动态特征。
该工具特别适合从事推荐系统研究的研究人员以及需要构建高性能原型的专业开发者使用。其核心亮点在于极致的运行效率:代码基于 Theano 框架深度优化,专为 GPU 加速设计,在 GTX 1080Ti 上每秒可处理高达 1500 个迷你批次,且 97.5% 的计算时间均在 GPU 上完成。官方特别强调,虽然社区存在 PyTorch 或 TensorFlow 版本,但未经严格验证的非官方复现可能导致推荐准确率大幅下降或训练时间显著延长,因此建议优先使用经过验证的官方实现以确保结果的可复现性。无论是进行学术实验还是探索序列感知模型,GRU4Rec 都提供了一个高效、可靠的基准方案。
使用场景
某大型电商平台的推荐算法团队正致力于优化用户在单次浏览会话(Session)中的商品点击预测,以解决新用户无历史行为数据时的冷启动难题。
没有 GRU4Rec 时
- 忽略序列动态:传统协同过滤仅依赖用户长期历史画像,无法捕捉用户在当前会话中“从看手机到看手机壳”的实时意图流转。
- 冷启动失效:对于未登录游客或新注册用户,因缺乏历史交互数据,系统只能推送泛热门商品,转化率极低。
- 计算效率瓶颈:尝试使用未经优化的第三方 RNN 复现版本处理海量会话日志时,训练速度比理论值慢数百倍,且推荐准确率因实现缺陷暴跌近 99%。
- 资源浪费严重:模型难以在 GPU 上高效并行,97% 以上的算力时间被浪费在数据搬运而非核心计算上,导致迭代周期长达数周。
使用 GRU4Rec 后
- 精准捕捉时序:GRU4Rec 利用循环神经网络直接建模会话内的物品点击序列,精准预测用户下一秒最可能感兴趣的商品。
- 无缝覆盖匿名客:无需任何用户身份信息,仅凭当前会话的短期行为即可生成高质量推荐,显著提升游客群体的购买转化。
- 复现官方性能:采用经过验证的 Theano 官方实现(或其 PyTorch/TensorFlow 官方移植版),确保了算法逻辑的完整性,避免了非官方版本导致的精度崩塌。
- 极致训练加速:依托针对 GPU 深度优化的代码架构,在 GTX 1080Ti 上可实现每秒 1500 个迷你批次的处理速度,将模型训练时间从数周缩短至数小时。
GRU4Rec 通过专为会话设计的深度学习架构,将原本不可用的匿名流量转化为高价值的实时推荐机会,同时以工业级的运行效率保障了算法的快速落地。
运行环境要求
- 未说明
- 必需 NVIDIA GPU (代码针对 GPU 优化,CPU 运行不支持且需修改代码)
- 示例提及 GTX 1080Ti
- 需安装 CUDA (测试过 9.2,兼容 11.8 等新版) 和 libgpuarray
- 强烈建议禁用 cuDNN (因 v7+ 存在严重 Bug),或限制在 cuDNN 8.2.1
未说明 (但提到负样本缓冲区会占用大量 GPU 显存,默认 10GB 缓冲区大小)
快速开始
GRU4Rec
这是论文《基于会话的推荐系统与循环神经网络》(arXiv:1511.06939)中算法的原始 Theano 实现,并加入了论文《用于会话推荐的具有 Top-k 增益的循环神经网络》(arXiv:1706.03847)中的扩展内容。
请务必始终以最新版本作为基准,并在引用时同时注明这两篇论文!
该代码针对 GPU 上的快速执行进行了优化(在 GTX 1080Ti 上每秒可处理多达 1500 个 mini-batch)。根据 Theano 性能分析器的统计,训练过程中 97.5% 的时间是在 GPU 上花费的,而 CPU 上仅占 0.5%,另外 2% 用于在 CPU 和 GPU 之间传输数据。目前不支持在 CPU 上运行,但通过对代码进行一些修改是有可能实现的。
如果您对使用 Theano 感到担忧,也可以参考以下官方重实现版本:
注意: 这些版本已与原始版本进行了验证,但由于现代深度学习框架的工作方式不同,它们的运行速度比本版本慢 1.5 到 4 倍。未来可能会有其他重实现版本出现,具体取决于研究社区的兴趣程度。
重要提示! 请避免使用非官方的重实现版本。我们在论文《第三方实现对可重复性的影响》(arXiv:2307.14956)中对 6 种第三方实现(PyTorch/TensorFlow,独立实现或基于框架的实现)进行了全面评估,结果发现所有这些实现都存在缺陷和/或遗漏了重要功能,导致推荐准确率最高降低 99%,训练时间最长延长至原来的 335 倍。此后我们发现的其他实现也同样不可靠。
您可以使用 run.py 轻松地在自己的会话数据上训练和评估模型。使用说明如下。
向下滚动可查看关于在公开数据集上复现结果以及超参数调优的信息!
许可证: 详情请参阅 license.txt。主要原则如下:出于科研和教育目的,该代码始终可以免费使用。若将该代码或其部分应用于商业系统,则需要获得许可。如果您已在商业系统中使用过该代码或其衍生作品,请与我联系!
目录:
要求
Theano 配置
使用方法
使用 run.py 执行实验
示例
在代码或解释器中使用 GRU4Rec
关于序列感知与会话型模型的说明
关于参数设置的说明
训练速度
在公开数据集上复现结果
超参数调优
在 CPU 上执行
重大更新
要求
- Python --> 请使用 Python
3.6.3或更高版本。代码主要在3.6.3、3.7.6和3.8.12上进行了测试,但也简要测试过其他版本。Python 2 不受支持。 - NumPy -->
1.16.4或更高版本。 - Pandas -->
0.24.2或更高版本。 - CUDA --> Theano 的 GPU 支持需要 CUDA。据我所知,Theano 最新测试过的 CUDA 版本是
9.2。较新的版本,例如11.8,也能正常工作。 - libgpuarray --> Theano 的 GPU 支持需要此库,请使用最新版本。
- Theano -->
1.0.5(最后一个稳定版本)或更高版本(偶尔仍会更新一些小功能)。应安装 GPU 支持。 - Optuna --> (可选)用于超参数优化,代码已用
3.0.3测试过。
重要:cuDNN --> 较新版本会产生警告,但对我来说 8.2.1 仍然可用。GRU4Rec 并不严重依赖于 Theano 中利用 cuDNN 的部分。不幸的是,cuDNN v7 及更高版本中的 cudnnReduceTensor 功能存在严重 bug,这使得基于该函数的操作在使用 cuDNN 时变得缓慢,甚至偶尔不稳定(计算错误或段错误),例如 此处 所示。因此,最好避免使用 cuDNN。如果您已经安装了 cuDNN,可以轻松配置 Theano 以排除基于 cuDNN 的操作(见下文)。
此 bug 与 Theano 无关,可在 CUDA/C++ 中复现。遗憾的是,这一问题至今仍未修复超过 6 年。
Theano 配置
该代码针对 GPU 执行进行了优化。如果尝试在 CPU 上运行代码,将会失败(如果您确实想尝试,请参阅本 README 的相关部分)。因此,必须正确配置 Theano 以使用 GPU。如果您使用 run.py 来运行实验,代码会为您自动设置配置。您可能希望更改某些预设配置(例如,在指定的 GPU 上而不是 ID 最低的 GPU 上运行)。您可以通过设置 THEANO_FLAGS 环境变量或编辑 .theanorc_gru4rec 文件来完成此操作。
如果您不使用 run.py,预设配置可能不会生效(当 Theano 在 gru4rec 之前被直接或通过其他模块导入时就会发生这种情况)。在这种情况下,您必须自行设置配置,方法是编辑您的 .theanorc 文件或设置 THEANO_FLAGS 环境变量。请参考 Theano 官方文档。
重要配置参数
device--> 必须始终为支持 CUDA 的 GPU(例如cuda0)。floatX--> 必须始终为float32。mode--> 应设置为FAST_RUN以实现快速执行。optimizer_excluding--> 应设置为local_dnn_reduction:local_cudnn_maxandargmax:local_dnn_argmax,以指示 Theano 不要使用基于 cuDNN 的操作,因为其cudnnReduceTensor函数自v7以来一直存在 bug。
使用方法
使用 run.py 执行实验
run.py 是一种简便的方式来训练、评估以及保存/加载 GRU4Rec 模型。
通过 -h 参数可以查看所有可用的参数。
$ python run.py -h
输出:
用法: run.py [-h] [-ps PARAM_STRING] [-pf PARAM_PATH] [-l] [-s MODEL_PATH] [-t TEST_PATH [TEST_PATH ...]] [-m AT [AT ...]] [-e EVAL_TYPE] [-ss SS] [--sample_store_on_cpu] [-g GRFILE] [-d D] [-ik IK] [-sk SK] [-tk TK]
[-pm METRIC] [-lpm]
PATH
训练或加载一个 GRU4Rec 模型,并在指定的测试集上计算召回率和 MRR。
位置性参数:
PATH 训练数据的路径(以 TAB 分隔的文件 (.tsv 或 .txt) 或者序列化的 pandas.DataFrame 对象 (.pickle);如果未提供 --load_model 参数)或已序列化的模型路径(如果提供了 --load_model 参数)。
可选参数:
-h, --help 显示此帮助信息并退出
-ps PARAM_STRING, --parameter_string PARAM_STRING
以单个字符串形式提供的训练参数。字符串格式为 `param_name1=param_value1,param_name2=param_value2...`,例如:`loss=bpr-max,layers=100,constrained_embedding=True`。布尔类型的训练参数应设置为 True 或 False;可接受列表的参数则使用 / 作为分隔符(如 layers=200/200)。该选项与 -pf (--parameter_file) 和 -l (--load_model) 互斥,三者必选其一。
-pf PARAM_PATH, --parameter_file PARAM_PATH
或者,也可以通过此参数指定的配置文件来设置训练参数。配置文件必须包含一个名为 `gru4rec_params` 的 OrderedDict。参数需具有相应类型(如 layers = [100])。该选项与 -ps (--parameter_string) 和 -l (--load_model) 互斥,三者必选其一。
-l, --load_model 加载已训练好的模型,而非重新训练。该选项与 -ps (--parameter_string) 和 -pf (--parameter_file) 互斥,三者必选其一。
-s MODEL_PATH, --save_model MODEL_PATH
将训练好的模型保存到 MODEL_PATH。(默认:不保存模型)
-t TEST_PATH [TEST_PATH ...], --test TEST_PATH [TEST_PATH ...]
测试数据集的路径位于 TEST_PATH。可以提供多个测试集(用空格分隔)。(默认:不评估模型)
-m AT [AT ...], --measure AT [AT ...]
在指定的推荐列表长度处计算召回率和 MRR。可以提供多个值。(默认:20)
-e EVAL_TYPE, --eval_type EVAL_TYPE
设置当排序列表中多个项目具有相同预测分数时的处理方式(通常由于饱和或错误导致)。更多详情请参阅 evaluation.py 中 evaluate_gpu() 的文档。(默认:standard)
-ss SS, --sample_store_size SS
GRU4Rec 在训练过程中会使用负样本缓冲区以最大化 GPU 利用率。此参数用于设置缓冲区长度。较小的值会导致更频繁的重新计算,而较大的值则会占用更多的(GPU)内存。除非您清楚自己在做什么,否则不建议调整此参数。(默认:10000000)
--sample_store_on_cpu
如果启用此选项,样本存储将被放置在 RAM 而不是 GPU 内存中。大多数情况下不建议这样做,因为这会显著降低 GPU 利用率。此选项仅在您出于某种原因希望在 CPU 上训练模型时使用(不推荐)。请注意,您需要对代码进行修改以便使其能够在 CPU 上运行。
-g GRFILE, --gru4rec_model GRFILE
包含 GRU4Rec 类的文件名。可用于选择不同的变体。(默认:gru4rec)
-ik IK, --item_key IK
对应于商品 ID 的列名(默认:ItemId)。
-sk SK, --session_key SK
对应于会话 ID 的列名(默认:SessionId)。
-tk TK, --time_key TK
对应于时间戳的列名(默认:Time)。
-pm METRIC, --primary_metric METRIC
设置主要指标,即召回率或 MRR(例如用于超参数优化)。(默认:召回率)
-lpm, --log_primary_metric
如果启用此选项,评估将在运行结束时记录主要指标的值。此选项仅适用于单个测试文件和单一列表长度。
示例
使用参数字符串中的模型参数训练、保存并评估模型,在 1、5、10 和 20 处计算召回率和 MRR。
$ THEANO_FLAGS=device=cuda0 python run.py /path/to/training_data_file -t /path/to/test_data_file -m 1 5 10 20 -ps layers=224,batch_size=80,dropout_p_embed=0.5,dropout_p_hidden=0.05,learning_rate=0.05,momentum=0.4,n_sample=2048,sample_alpha=0.4,bpreg=1.95,logq=0.0,loss=bpr-max,constrained_embedding=True,final_act=elu-0.5,n_epochs=10 -s /path/to/save_model.pickle
输出(基于 RetailRocket 数据集):
使用 cuDNN 版本 8201,上下文为 None
将名称 None 映射到设备 cuda0: NVIDIA A30 (0000:3B:00.0)
创建 GRU4Rec 模型
设置 layers 为 [224] (类型:list)
设置 batch_size 为 80 (类型:int)
设置 dropout_p_embed 为 0.5 (类型:float)
设置 dropout_p_hidden 为 0.05 (类型:float)
设置 learning_rate 为 0.05 (类型:float)
设置 momentum 为 0.4 (类型:float)
设置 n_sample 为 2048 (类型:int)
设置 sample_alpha 为 0.4 (类型:float)
设置 bpreg 为 1.95 (类型:float)
设置 logq 为 0.0 (类型:float)
设置 loss 为 bpr-max (类型:str)
设置 constrained_embedding 为 True (类型:bool)
设置 final_act 为 elu-0.5 (类型:str)
设置 n_epochs 为 10 (类型:int)
加载训练数据...
从 TAB 分隔文件加载数据:/path/to/training_data_file
开始训练
数据框已按 SessionId 和 Time 排序
创建了包含 4882 批次样本的样本存储(类型:GPU)
第1轮 --> 损失: 0.484484 (6.81秒) [1026.65 MB/s | 81386 e/s]
第2轮 --> 损失: 0.381974 (6.89秒) [1015.39 MB/s | 80493 e/s]
第3轮 --> 损失: 0.353932 (6.81秒) [1027.68 MB/s | 81468 e/s]
第4轮 --> 损失: 0.340034 (6.80秒) [1028.90 MB/s | 81564 e/s]
第5轮 --> 损失: 0.330763 (6.80秒) [1028.19 MB/s | 81508 e/s]
第6轮 --> 损失: 0.324075 (6.80秒) [1029.36 MB/s | 81601 e/s]
第7轮 --> 损失: 0.319033 (6.85秒) [1022.03 MB/s | 81020 e/s]
第8轮 --> 损失: 0.314915 (6.80秒) [1029.05 MB/s | 81577 e/s]
第9轮 --> 损失: 0.311716 (6.82秒) [1025.44 MB/s | 81290 e/s]
第10轮 --> 损失: 0.308915 (6.82秒) [1025.64 MB/s | 81306 e/s]
总训练时间:77.73秒
将训练好的模型保存到:/path/to/save_model.pickle
加载测试数据...
从 TAB 分隔文件加载数据:/path/to/test_data_file
开始评估(截断点=[1, 5, 10, 20],采用标准模式解决平局)
测量 Recall@1,5,10,20 和 MRR@1,5,10,20
评估耗时 4.34 秒
Recall@1: 0.128055 MRR@1: 0.128055
Recall@5: 0.322165 MRR@5: 0.197492
Recall@20: 0.518184 MRR@20: 0.217481
使用参数文件中的参数在 cuda0 上训练并保存模型。
$ THEANO_FLAGS=device=cuda0 python run.py /path/to/training_data_file -pf /path/to/parameter_file.py -s /path/to/save_model.pickle
输出(基于 RetailRocket 数据集):
使用 cuDNN 版本 8201,上下文为 None
将名称 None 映射到设备 cuda0: NVIDIA A30 (0000:3B:00.0)
创建 GRU4Rec 模型
设置 layers 为 [224] (类型:list)
设置 batch_size 为 80 (类型:int)
设置 dropout_p_embed 为 0.5 (类型:float)
设置 dropout_p_hidden 为 0.05 (类型:float)
设置 learning_rate 为 0.05 (类型:float)
设置 momentum 为 0.4 (类型:float)
设置 n_sample 为 2048 (类型:int)
设置 sample_alpha 为 0.4 (类型:float)
设置 bpreg 为 1.95 (类型:float)
设置 logq 为 0.0 (类型:float)
设置 loss 为 bpr-max (类型:str)
设置 constrained_embedding 为 True (类型:bool)
设置 final_act 为 elu-0.5 (类型:str)
设置 n_epochs 为 10 (类型:int)
加载训练数据...
从 TAB 分隔文件加载数据:/path/to/training_data_file
开始训练
数据框已按 SessionId 和 Time 排序
创建了包含 4882 批次样本的样本存储(类型:GPU)
第1轮 --> 损失: 0.484484 (6.81秒) [1026.65 MB/s | 81386 e/s]
第2轮 --> 损失: 0.381974 (6.89秒) [1015.39 MB/s | 80493 e/s]
第3轮 --> 损失: 0.353932 (6.81秒) [1027.68 MB/s | 81468 e/s]
第4轮 --> 损失: 0.340034 (6.80秒) [1028.90 MB/s | 81564 e/s]
第5轮 --> 损失: 0.330763 (6.80秒) [1028.19 MB/s | 81508 e/s]
第6轮 --> 损失: 0.324075 (6.80秒) [1029.36 MB/s | 81601 e/s]
第7轮 --> 损失: 0.319033 (6.85秒) [1022.03 MB/s | 81020 e/s]
第8轮 --> 损失: 0.314915 (6.80秒) [1029.05 MB/s | 81577 e/s]
第9轮 --> 损失: 0.311716 (6.82秒) [1025.44 MB/s | 81290 e/s]
第10轮 --> 损失: 0.308915 (6.82秒) [1025.64 MB/s | 81306 e/s]
总训练时间:77.73秒
将训练好的模型保存到:/path/to/save_model.pickle
在 cuda1 上加载先前训练好的模型,并使用保守方法解决平局,在 1、5、10 和 20 处评估召回率和 MRR。
$ THEANO_FLAGS=device=cuda1 python run.py /path/to/previously_saved_model.pickle -l -t /path/to/test_data_file -m 1 5 10 20 -e conservative
输出(基于 RetailRocket 数据集):
使用 cuDNN 版本 8201,上下文为 None
将名称 None 映射到设备 cuda1: NVIDIA A30 (0000:AF:00.0)
从文件加载训练过的模型:/path/to/previously_saved_model.pickle
加载测试数据...
从 TAB 分隔文件加载数据:/path/to/test_data_file
开始评估(截断点=[1, 5, 10, 20],采用保守模式解决平局)
测量 Recall@1,5,10,20 和 MRR@1,5,10,20
评估耗时 4.34 秒
Recall@1: 0.128055 MRR@1: 0.128055
Recall@5: 0.322165 MRR@5: 0.197492
Recall@20: 0.518184 MRR@20: 0.217481
在代码或解释器中使用 GRU4Rec
你可以在代码或解释器中直接导入 gru4rec 模块,并使用 GRU4Rec 类来创建和训练模型。训练好的模型可以通过导入 evaluation 模块,调用 evaluate_gpu 或 evaluate_session_batch 方法进行评估。后者已被弃用,因为它无法充分利用 GPU,因此速度明显较慢。该代码的公开版本主要用于运行实验(在不同数据集上训练和评估算法),因此获取实际预测结果可能会比较繁琐且效率不高。
重要提示! 为了方便起见,gru4rec 模块会设置一些重要的 Theano 参数,这样如果你不熟悉 Theano,就不必担心这些配置。但这一设置只有在 gru4rec 先于 Theano(以及任何导入 Theano 的模块)被导入时才会生效。(因为一旦 Theano 初始化完毕,其大部分配置就无法更改。即使重新导入 Theano,GPU 也不会重新初始化。)如果顺序相反,你应该设置默认的 .theanorc 文件,或者通过 THEANO_FLAGS 环境变量提供适当的配置。
关于序列感知与会话型模型的说明
GRU4Rec 最初是为会话型推荐设计的,在这种场景下,通常较短的会话被视为相互独立的。每当用户访问网站时,系统都会将其视为新用户,即不会利用其历史记录,即便已知这些信息也是如此。(这种设定非常适合许多实际应用场景。)这意味着在评估模型时,每个测试会话的隐藏状态都会从零开始。
然而,基于 RNN、CNN、Transformer 等的模型也非常适合用于序列感知的个性化推荐场景——在这种场景中,用户的整个历史记录会被当作一个序列,用来预测序列中的后续项目。两者的主要区别在于:
- (1) 序列感知推荐中的序列长度通常要长得多。这也意味着 BPTT(时间反向传播)在这种情况下非常有用。而对于会话型推荐,实验表明 BPTT 并不能提升模型性能。
- (2) 在序列感知场景中,评估应从隐藏状态的最后一个值开始(即根据用户历史训练部分计算出的值)。
目前,公开代码中尚未支持上述功能。如果社区有足够的兴趣,未来可能会添加这些功能(它们存在于我的一些内部研究仓库中)。现阶段,你需要自行扩展代码来实现这些功能。
关于参数设置的说明
GRU4Rec 具有许多参数(而私有版本多年来甚至有更多的参数)。虽然你可以随意尝试调整这些参数,但我发现将以下参数保持默认值通常是最佳选择。
| 参数 | 默认值 | 备注 |
|---|---|---|
hidden_act |
tanh |
隐藏层的激活函数应设置为 tanh。 |
lmbd |
0.0 |
不需要 L2 正则化,建议使用 Dropout 进行正则化。 |
smoothing |
0.0 |
标签平滑对交叉熵损失的影响很小。 |
adapt |
adagrad |
不同优化器的表现大致相同,其中 adagrad 略优于其他优化器。 |
adapt_params |
[] |
Adagrad 没有超参数,因此此处为空列表。 |
grad_cap |
0.0 |
训练过程中无需梯度裁剪。 |
sigma |
0.0 |
权重初始化时无需指定最小/最大值;当此值为 0 时,会自动使用 ±sqrt(6.0/(dim[0] + dim[1]))。 |
init_as_normal |
False |
权重应从均匀分布中初始化。 |
train_random_order |
False |
不应对训练会话进行随机打乱,以确保最后的更新基于最近的数据。 |
time_sort |
True |
应按首次事件的时间戳升序对训练会话进行排序(最早的会话排在前面),以便最后的更新基于近期数据。 |
损失函数与最终激活函数:
- 在五种损失选项(
cross-entropy、bpr-max、top1、bpr、top1-max)中,仅应使用cross-entropy或bpr-max。其他选项在一定程度上也能工作,但容易出现梯度消失问题,因此生成的模型效果不如使用bpr-max或cross-entropy训练的模型。 cross-entropy有一个替代形式xe_logit,它需要设置不同的最终激活函数。- 始终根据所使用的损失函数选择合适的最终激活函数。对于
loss=cross-entropy,最终激活函数应始终为final_act=softmax;对于loss=xe_logit,应始终使用final_act=softmax_logit;对于loss=bpr-max,可以使用final_act=linear、final_act=relu、final_act=tanh、final_act=leaky-<X>、final_act=elu-<X>或final_act=selu-<X>-<Y>(我通常更倾向于使用elu-0.5或elu-1)。
嵌入模式: 如论文所述,共有三种嵌入模式,可通过以下方式设置。
| 嵌入模式 | 设置方法 | 描述 |
|---|---|---|
| 无嵌入 | embedding=0 且 constrained_embedding=False |
直接将物品 ID 的 one-hot 向量输入到 GRU 层。 |
| 分离嵌入 | embedding=X,其中 X>0 或 X=layersize,且 constrained_embedding=False |
在 GRU 层的输入端和用于计算得分的序列嵌入中分别使用独立的嵌入。embedding=layersize 表示嵌入维度与第一个 GRU 层的单元数相同。 |
| 共享嵌入 | constrained_embedding=True |
通常表现最好的设置。在 GRU 层的输入端和用于计算得分的序列嵌入中使用相同的嵌入。这会强制嵌入维度等于最后一个 GRU 层的大小,因此在此模式下 embedding 参数无效。 |
训练速度
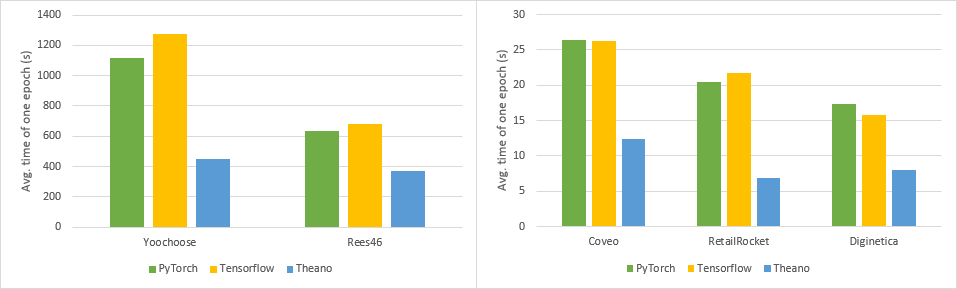
本版本是目前最快的版本(遥遥领先)。官方的 PyTorch 和 TensorFlow 实现的速度受限于各自深度学习框架带来的额外开销。
在公开可用的数据集上,采用最佳参数配置(见下文),使用 nVidia A30 显卡测得完成一个 epoch 所需的时间(单位:秒)。Theano 版本比 PyTorch 或 TensorFlow 版本快 1.7 到 3 倍。
详细说明: 简而言之,Theano 要求先构建计算图,然后基于该图创建一个 Theano 函数来执行计算。在函数创建过程中,代码会被编译成一个或多个 C++/CUDA 可执行文件,每次从 Python 调用该函数时都会执行这些二进制文件。如果完全不使用任何基于 Python 的算子,控制权无需返回 Python,从而大幅降低开销。GRU4Rec 的发布版本基于 ID 表示法,因此单个 mini-batch 通常无法将 GPU 充分利用。这样一来,像 PyTorch 和 TensorFlow 那样需要在 C++/CUDA 和 Python 之间频繁切换控制权的做法,会显著增加训练时间。这也是为什么当层数和/或 batch size 较大时,速度差异会变小的原因。不过,为了达到最佳性能,有时反而需要使用较小的 batch size。
训练时间主要取决于事件数量和模型参数。以下参数会影响事件处理速度(事件/秒):
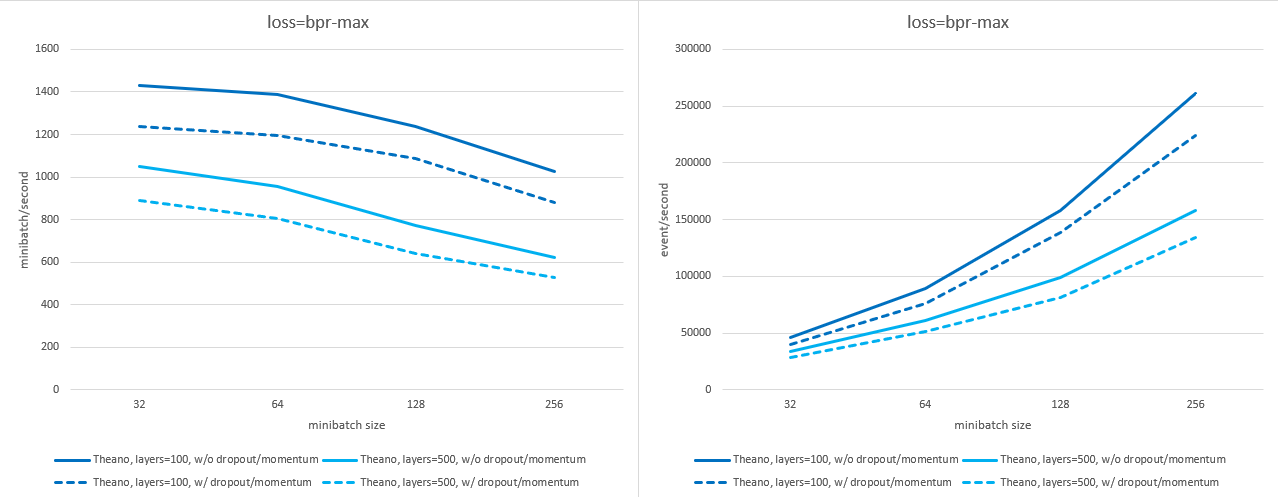
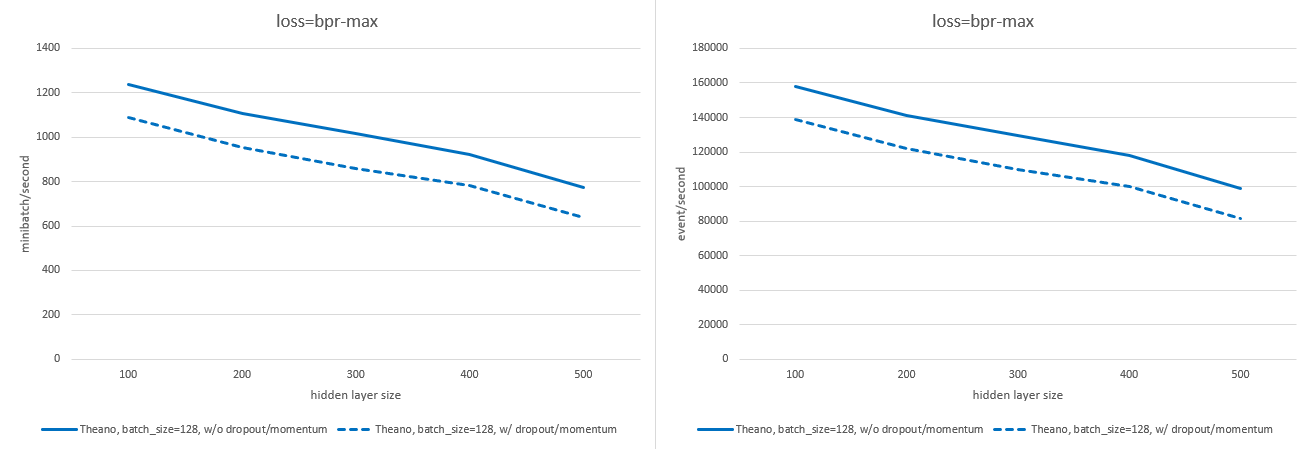
batch_size--> 处理批次的速度(MB/s)下降幅度远小于 batch size 增加的速度,因此随着batch_size的增大,事件处理速度也会加快。然而,batch_size同时也会影响模型精度,对于大多数数据集而言,较小的 batch size meistens besser.n_sample--> 在硬件允许的情况下,负样本数量在 500–1000 以内不会影响处理速度。默认设置为n_sample=2048,但如果物品数量较少,可以适当降低此值而不影响准确性。loss-->交叉熵损失略快于BPR-Max损失。dropout_p_embed、dropout_p_hidden、momentum--> 如果将这些参数设为非零值,训练速度会略微减慢。
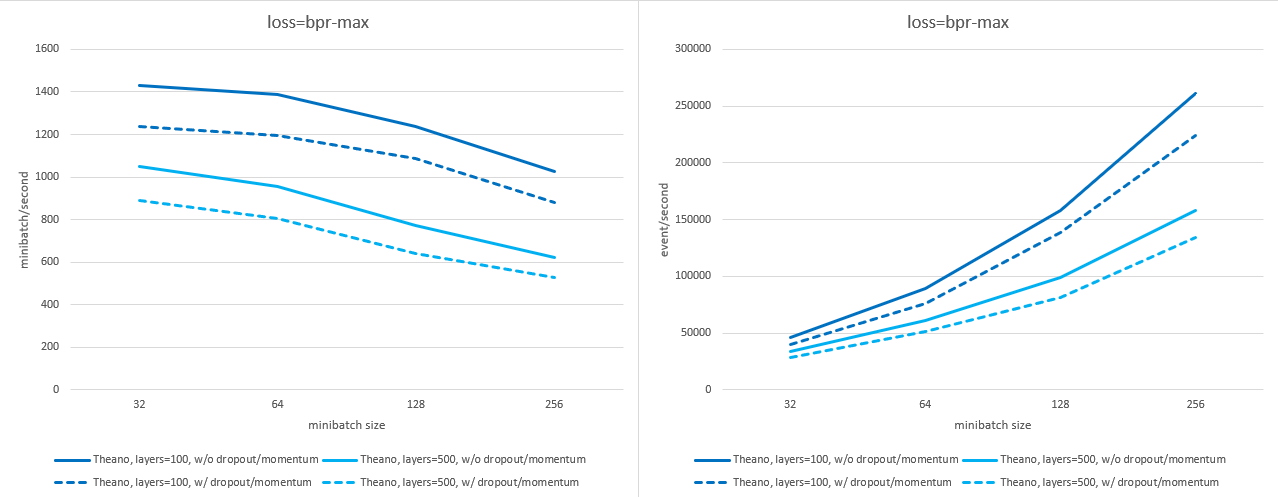
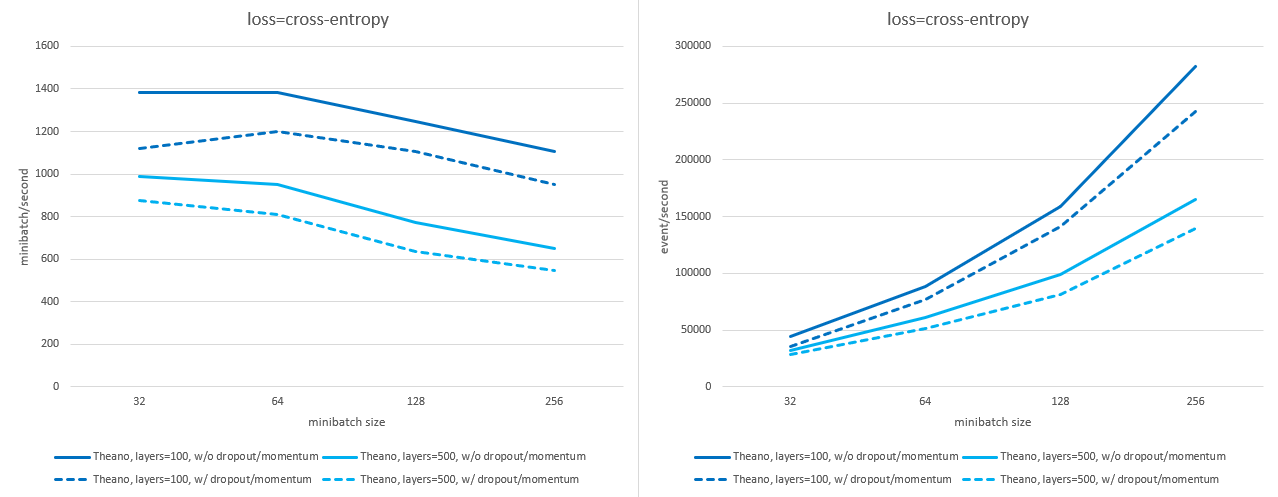
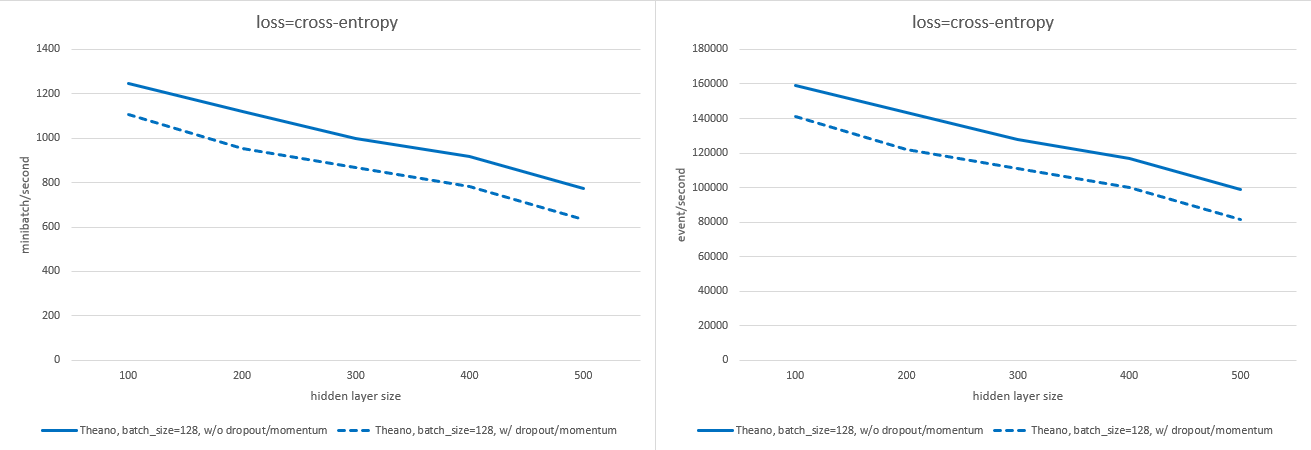
以下图表展示了在启用或禁用 dropout 和 momentum 的情况下,不同 batch size 和隐藏层大小下,使用 n_sample=2048 时的训练速度差异(每秒处理的 mini-batch 数量及每秒处理的事件数量;数值越高越好)。测量设备为 nVidia A30 显卡。
使用 交叉熵 损失:
使用 BPR-Max 损失:
在公开数据集上复现结果
GRU4Rec 的性能已在 [1,2,3,4] 中的多个公开数据集上进行了评估:Yoochoose/RSC15、Rees46、Coveo、RetailRocket 和 Diginetica。
重要提示: 仅当数据(以及任务)本身表现出序列模式时,例如基于会话的数据,衡量序列推荐系统的性能才有意义。在评分数据上进行评估无法得出有意义的结果。有关详细信息以及其他人在评估序列推荐系统时常见的错误,请参阅 [4]。
注意事项:
- 始终尽量在比较中包含至少一个规模较为真实的大型数据集(例如,Rees46 是一个很好的例子)。
- 评估设置在 [1,2,3] 中有详细描述。这是一种下一 item 预测类型的评估,仅将下一个 item 视为与给定推理相关的唯一目标。这种设置非常适合行为预测,并且在一定程度上与线上表现相关。它比将后续任意 item 都视为相关的目标更为严格;后者虽然也是一种合理的设置,但对简单的方法(例如基于计数的方法)更加宽容。然而,与任何其他离线评估一样,它并不能直接反映线上性能。
获取数据: 请参考数据的原始来源以获得完整且合法的副本。此处提供的链接仅为尽力而为,不能保证长期有效。
预处理:
RSC15 的预处理细节及其背后的理由可在 [1,2] 中找到,而 Yoochoose、Rees46、Coveo、RetailRocket 和 Diginetica 的预处理则在 [3] 中说明。RSC15 的预处理脚本可在 这里 找到,Yoochoose、Rees46、Coveo、RetailRocket 和 Diginetica 的预处理脚本则位于 对应于 [3] 的仓库 中。运行脚本后,请务必核对生成的数据集统计信息是否与论文中报告的一致。
预处理脚本会为每个数据集生成 4 个文件:
train_full--> 完整的训练集,用于最终评估时的模型训练test--> 模型最终评估所用的测试集(与train_full成对)train_tr--> 用于超参数优化和实验的训练集train_valid--> 用于超参数优化和实验的验证集(与train_tr成对)
基本上,完整的预处理数据集会被分割成 train_full 和 test,然后 train_full 再按照相同的逻辑被进一步分割为 train_tr 和 train_valid。
重要提示: 请注意,尽管 RSC15 和 Yoochoose 来自同一来源(Yoochoose 数据集),但它们的预处理方式并不相同。主要区别在于 RSC15 没有进行去重处理。因此,在这两个数据集上的结果不可直接比较,最优超参数也可能不同。建议使用 Yoochoose 版本,仅在因某些原因无法复现实验时(例如方法实现不可用)才参考 RSC15 版本的结果。
[1] Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, Domonkos Tikk: 基于会话的推荐系统与循环神经网络, ICLR 2016
[2] Balázs Hidasi, Alexandros Karatzoglou: 具有 Top-k 收益的循环神经网络用于基于会话的推荐, CIKM 2018
[3] Balázs Hidasi, Ádám Czapp: 第三方实现对可重复性的影响, RecSys 2023
[4] Balázs Hidasi, Ádám Czapp: 推荐系统离线评估中的普遍缺陷, RecSys 2023
超参数:
RSC15 的超参数是通过局部(星型)搜索优化器获得的,该优化器会在找到更好的参数组合时重启。其使用的参数空间比本仓库中包含的要小(例如,隐藏层大小固定为 100)。借助新的 Optuna 基础优化器,这里可能还存在一些小幅改进的空间。
Yoochoose、Rees46、Coveo、RetailRocket 和 Diginetica 的超参数则是使用本仓库中上传的参数空间获得的。针对每个数据集、每种嵌入模式(无嵌入、独立嵌入、共享嵌入)以及每种损失函数(交叉熵、BPR-Max),均执行了 200 次运行。主要指标是 MRR@20,它通常也能在召回率@20 方面取得最佳效果。超参数优化过程中使用了一组单独的训练/验证集,该集是从完整的训练集中按照与从完整数据集中划分出完整训练集/测试集相同的方式创建的。最终结果是在测试集上测量的,模型则是在完整训练集上训练得到的。
最佳超参数:
注: 为方便起见,参数文件(可通过 run.py 的 -pf 参数使用)已 包含 在本仓库中。
| 数据集 | 损失函数 | 约束嵌入 | 嵌入类型 | ELU 参数 | 层数 | 批量大小 | 嵌入 dropout 率 | 隐藏层 dropout 率 | 学习率 | 动量 | 样本数量 | 样本 alpha | BPREG | logq |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RSC15 | 交叉熵 | 是 | 0 | 0 | 100 | 32 | 0.1 | 0 | 0.1 | 0 | 2048 | 0.75 | 0 | 1 |
| Yoochoose | 交叉熵 | 是 | 0 | 0 | 480 | 48 | 0 | 0.2 | 0.07 | 0 | 2048 | 0.2 | 0 | 1 |
| Rees46 | 交叉熵 | 是 | 0 | 0 | 512 | 240 | 0.45 | 0 | 0.065 | 0 | 2048 | 0.5 | 0 | 1 |
| Coveo | BPR-Max | 是 | 0 | 1 | 512 | 144 | 0.35 | 0 | 0.05 | 0.4 | 2048 | 0.2 | 1.85 | 0 |
| RetailRocket | BPR-Max | 是 | 0 | 0.5 | 224 | 80 | 0.5 | 0.05 | 0.05 | 0.4 | 2048 | 0.4 | 1.95 | 0 |
| Diginetica | BPR-Max | 是 | 0 | 1 | 512 | 128 | 0.5 | 0.3 | 0.05 | 0.15 | 2048 | 0.3 | 0.9 | 0 |
结果:
注: 由于 GPU 上操作执行顺序的变化,指标可能会出现轻微波动(甚至高达几个百分点),这是可以接受的。
| 数据集 | 召回率@1 | MRR@1 | 召回率@5 | MRR@5 | 召回率@10 | MRR@10 | 召回率@20 | MRR@20 |
|---|---|---|---|---|---|---|---|---|
| RSC15 | 0.1845 | 0.1845 | 0.4906 | 0.2954 | 0.6218 | 0.3130 | 0.7283 | 0.3205 |
| Yoochoose | 0.1829 | 0.1829 | 0.4478 | 0.2783 | 0.5715 | 0.2949 | 0.6789 | 0.3024 |
| Rees46 | 0.1114 | 0.1114 | 0.3010 | 0.1778 | 0.4135 | 0.1928 | 0.5293 | 0.2008 |
| Coveo | 0.0513 | 0.0513 | 0.1496 | 0.0852 | 0.2212 | 0.0946 | 0.3135 | 0.1010 |
| RetailRocket | 0.1274 | 0.1274 | 0.3237 | 0.1977 | 0.4207 | 0.2107 | 0.5186 | 0.2175 |
| Diginetica | 0.0725 | 0.0725 | 0.2369 | 0.1288 | 0.3542 | 0.1442 | 0.4995 | 0.1542 |
超参数调优
paropt.py 支持在新数据集上进行超参数优化。它内部使用 Optuna,并需要定义一个参数空间。该仓库中已包含一些预定义的参数空间,详见 此处。
建议:
- 使用附带的参数空间运行 100 到 200 次迭代。
- 当使用不同的损失函数和嵌入模式时(无嵌入,即
embedding=0,constrained_embedding=False;独立嵌入,即embedding=layersize,constrained_embedding=False;共享嵌入,即embedding=0,constrained_embedding=True),应分别进行优化。
固定参数: 您也可以在优化器中调整这些参数,但以下固定设置在过去表现良好:
logq--> 交叉熵损失通常在logq=1时效果最佳;当使用 BPR-max 损失时,此参数无效。n_sample--> 根据经验,n_sample=2048对于拥有数百万个物品的数据集来说已经足够获得良好的性能,同时也不会过大而显著降低训练速度。不过,如果活跃物品总数低于 5–10K,则可以适当降低此值。n_epochs--> 通常设置为n_epochs=10,但在大多数情况下,5个 epoch 也能达到相似的效果。迄今为止,尚无必要大幅增加 epoch 数。- 嵌入模式 --> 全面的超参数优化需要分别检查所有三种选项,但过去对于大多数数据集而言,共享嵌入(
constrained_embedding=True且embedding=0)的表现最佳。 loss--> 全面的超参数优化需要分别测试两种损失函数,但根据以往经验,BPR-max 在较小数据集上表现更好,而交叉熵损失则更适合较大数据集。final_act--> 始终使用与损失函数相匹配的最终激活函数,例如,当loss=cross-entropy时使用final_act=softmax,而当loss=bpr-max时则使用elu-<x>、linear或relu。
用法:
$ python paropt.py -h
输出:
usage: paropt.py [-h] [-g GRFILE] [-tf [FLAGS]] [-fp PARAM_STRING] [-opf PATH] [-m [AT]] [-nt [NT]] [-fm [AT [AT ...]]] [-pm METRIC] [-e EVAL_TYPE] [-ik IK] [-sk SK] [-tk TK] PATH TEST_PATH
训练或加载 GRU4Rec 模型,并在指定的测试集上评估召回率和 MRR。
位置参数:
PATH 训练数据的路径(以 TAB 分隔的文件 (.tsv 或 .txt) 或 Pickle 格式的 pandas.DataFrame 对象 (.pickle),前提是未提供 --load_model 参数);或者序列化后的模型路径(若提供了 --load_model 参数)。
TEST_PATH 测试数据集的路径。
可选参数:
-h, --help 显示帮助信息并退出
-g GRFILE, --gru4rec_model GRFILE
包含 GRU4Rec 类的文件名。可用于选择不同变体。(默认值:gru4rec)
-tf [FLAGS], --theano_flags [FLAGS]
Theano 设置。
-fp PARAM_STRING, --fixed_parameters PARAM_STRING
以单个字符串形式提供的固定训练参数。字符串格式为 `param_name1=param_value1,param_name2=param_value2...`,例如:`loss=bpr-max,layers=100,constrained_embedding=True`。布尔型参数应为 True 或 False;可接受列表的参数应使用 / 作为分隔符(如 layers=200/200)。此参数与 -pf(--parameter_file)和 -l(--load_model)参数互斥,三者必须提供其一。
-opf PATH, --optuna_parameter_file PATH
描述 Optuna 参数空间的文件。
-m [AT], --measure [AT]
在指定的推荐列表长度上测量召回率和 MRR。可提供单个值。(默认值:20)
-nt [NT], --ntrials [NT]
执行的优化试验次数。(默认值:50)
-fm [AT [AT ...]], --final_measure [AT [AT ...]]
优化完成后,在指定的推荐列表长度上测量召回率和 MRR。可提供多个值。(默认值:20)
-pm METRIC, --primary_metric METRIC
设置主要指标,召回率或 MRR(例如用于超参数优化)。(默认值:召回率)
-e EVAL_TYPE, --eval_type EVAL_TYPE
设置当排序列表中多个项目具有相同预测分数时的处理方式(这通常是由于饱和或错误造成的)。更多信息请参阅 evaluation.py 中 evaluate_gpu() 的文档。(默认值:标准)
-ik IK, --item_key IK
对应物品 ID 的列名。(默认值:ItemId)
-sk SK, --session_key SK
对应会话 ID 的列名。(默认值:SessionId)
-tk TK, --time_key TK
对应时间戳的列名。(默认值:Time)
示例: 运行一次超参数优化,以 MRR@20 为目标,进行 200 次迭代,并在优化完成后对最佳模型在 1、5、10 和 20 的推荐列表长度上测量召回率和 MRR。
注意: paropt 脚本可以在 CPU 上运行(THEANO_FLAGS=device=cpu),因为模型是在独立进程中训练的。您可以通过设置 -tf 参数来控制这些训练进程使用的设备,该参数会将值传递给训练进程的 THEANO_FLAGS 环境变量。在本例中,训练将在 cuda0 上执行。
THEANO_FLAGS=device=cpu python paropt.py /path/to/training_data_file_for_optimization /path/to/valiadation_data_file_for_optimization -pm mrr -m 20 -fm 1 5 10 20 -e conservative -fp n_sample=2048,logq=1.0,loss=cross-entropy,final_act=softmax,constrained_embedding=True,n_epochs=10 -tf device=cuda0 -opf /path/to/parameter_space.json -n 200
输出(前几行):
--------------------------------------------------------------------------------
PARAMETER SPACE
PARAMETER layers type=int range=[64..512] (step=32) UNIFORM scale
PARAMETER batch_size type=int range=[32..256] (step=16) UNIFORM scale
PARAMETER learning_rate type=float range=[0.01..0.25] (step=0.005) UNIFORM scale
PARAMETER dropout_p_embed type=float range=[0.0..0.5] (step=0.05) UNIFORM scale
PARAMETER dropout_p_hidden type=float range=[0.0..0.7] (step=0.05) UNIFORM scale
PARAMETER momentum type=float range=[0.0..0.9] (step=0.05) UNIFORM scale
PARAMETER sample_alpha type=float range=[0.0..1.0] (step=0.1) UNIFORM scale
--------------------------------------------------------------------------------
[I 2023-07-25 03:19:53,684] A new study created in memory with name: no-name-83fade3e-49f3-4f26-ac76-5f6cb2f3a02c
SET n_sample TO 2048 (type: <class 'int'>)
SET logq TO 1.0 (type: <class 'float'>)
SET loss TO cross-entropy (type: <class 'str'>)
SET final_act TO softmax (type: <class 'str'>)
SET constrained_embedding TO True (type: <class 'bool'>)
SET n_epochs TO 2 (type: <class 'int'>)
SET layers TO [96] (type: <class 'list'>)
SET batch_size TO 176 (type: <class 'int'>)
SET learning_rate TO 0.045000000000000005 (type: <class 'float'>)
SET dropout_p_embed TO 0.25 (type: <class 'float'>)
SET dropout_p_hidden TO 0.25 (type: <class 'float'>)
SET momentum TO 0.0 (type: <class 'float'>)
SET sample_alpha TO 0.9 (type: <class 'float'>)
Loading training data...
注意事项:
- 默认情况下,Optuna 将日志记录到 stderr,而模型则将输出打印到 stdout。您可以通过在命令中添加
1> /path/to/model_training_details.log 2> /path/to/optimization.log来分别记录模型训练细节和优化总结。此外,您也可以调整 Optuna 的相关设置。目前,GRU4Rec 尚未采用完善的日志系统,仅通过 print 输出信息。 - 如果您将 stderr 和/或 stdout 重定向到文件,并希望实时查看进度,请使用 Python 的非缓冲模式,在
python后添加-u参数(即python -u paropt.py ...)。
在 CPU 上执行
一些用于加速 GPU 执行的优化(例如自定义 Theano 操作符)会阻止代码在 CPU 上运行。由于神经网络在 CPU 上的执行本身就较慢,我决定放弃对 CPU 的支持,以进一步提升 GPU 上的执行速度。不过,如果您出于某种原因仍希望在 CPU 上运行 GRU4Rec,则需要修改代码以禁用这些自定义的 GPU 优化。这样您仍然可以在 CPU 上运行该代码,但请不要期待它会很快。
禁用自定义 GPU 优化的步骤:
- 在
gpu_ops.py中,将第 13 行改为disable_custom_op = True。这会使gpu_ops中的函数在计算图构建时返回标准操作符或由标准操作符组合而成的操作符,而不是自定义操作符。 - 在
gru4rec.py中,注释掉包含import custom_opt的第 12 行。其中一个自定义操作符通过custom_opt更深入地集成到了 Theano 中,从而被添加到负责替换计算图中操作符的优化器里。移除这一导入后,该操作符将不再被使用。
主要更新
2023 年 8 月 24 日 更新
- 添加了 paropt
- 扩展了关于可重复性的说明
- 增加了参数文件和参数空间
- 完善了 README 文件
2020 年 5 月 8 日 更新
- 通过提高 GPU 利用率显著加快了训练速度。
- 添加了 logQ 归一化(在使用交叉熵损失时可提升效果)。
- 新增了
run.py脚本,便于实验。 - 进一步丰富了本 README 文件。
2018 年 6 月 8 日 更新
- 重构并清理代码。
- 提升执行效率。
- 改进易用性。
- 增加了在 GPU 上进行评估的代码。
2017 年 6 月 13 日 更新
- 升级至 v2.0 版本
- 新增 BPR-max 和 TOP1-max 损失函数,以实现更先进的性能(结合额外采样,召回率和 MRR 相较于基础结果可提升约 30%)。
- 为追求更快的 GPU 执行速度,牺牲了一部分 CPU 性能。
2016 年 12 月 22 日 更新
- 修复了交叉熵损失的不稳定性问题。此前,极小的预测分数会被四舍五入为 0,导致其对数变为 NaN。现已在计算对数之前为所有分数添加了一个微小的 ε 值(1e-24)。在隐藏单元数为 100 的网络上,使用这种稳定化的交叉熵损失所取得的效果优于 TOP1 损失。
- 增加了使用额外负样本的选项(除了默认的 minibatch 中的其他样本之外)。额外样本的数量由 n_sample 参数指定。每个样本被选中的概率为 supp^sample_alpha,即当 sample_alpha 设置为 1 时采用基于流行度的采样,而设置为 0 时则为均匀采样。使用额外的负样本可能会降低训练速度,但在 GPU 上,根据配置的不同,这种影响可能并不明显,甚至可以容纳多达 1000–2000 个额外样本。
- 新增了在训练前预先计算大量负样本的选项。待存储的整数值(ID)数量由 train 函数的 sample_store 参数决定(默认值为 1000 万)。此选项仅适用于额外的负样本,因此只有在 n_sample > 0 时才会生效。如果每一步都重新生成负样本,GPU 的利用率会非常低,因为计算过程经常会被在 CPU 上进行的样本生成打断。而提前预计算好若干步所需的样本,则能使流程更加高效。不过,应避免将 sample_store 设置得过大,因为生成过多样本需要较长时间,会导致 GPU 长时间等待其完成,同时也会增加内存占用。
2016 年 9 月 21 日 更新
- 优化了 GPU 执行代码。现在训练速度提升了约两倍。
- 增加了重新训练功能。
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。