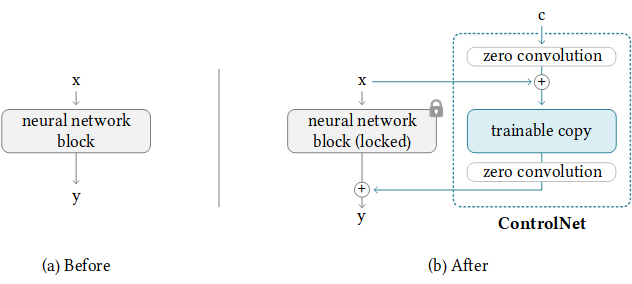
ControlNet-for-Diffusers
ControlNet-for-Diffusers 是一个专为开发者设计的开源项目,旨在让 ControlNet 能够灵活搭配任意基础模型(Base Model),在 Hugging Face 的 Diffusers 框架中运行。它主要解决了官方 ControlNet 最初仅绑定 Stable Diffusion 1.5 模型的局限性,让用户无需依赖 WebUI,即可将姿态控制、边缘检测等能力迁移到 Anything-v3 等社区热门模型上。
该工具的核心价值在于提供了一套简洁的代码教程和权重转换逻辑。通过特定的算法公式,它能保留原有的控制网络权重,仅替换底层基础模型,从而快速生成适配新模型的 ControlNet 权重文件。虽然项目目前标记为“已弃用”(因后续计划重构),但其核心功能在兼容环境下依然有效,且作者还配套提供了 T2I-Adapter 和 LoRA 在 Diffusers 中的实现方案。
ControlNet-for-Diffusers 特别适合熟悉 Python 编程的 AI 开发者、研究人员以及希望深入定制生成式工作流的工程师使用。对于想要摆脱固定模型限制、探索不同风格与 ControlNet 组合效果的技术人员来说,这是一个极具参考价值的实践指南。需要注意的是,由于涉及底层权重操作,普通用户或非技术背景的设计师可能需要一定的学习成本或借助 Colab 演示环境来体验。
使用场景
一位游戏美术开发者希望将基于 Stable Diffusion 1.5 训练的姿势控制能力,迁移到更擅长二次元风格生成的 Anything-V3 模型上,以构建定制化的角色生成管线。
没有 ControlNet-for-Diffusers 时
- 模型绑定僵化:官方 ControlNet 权重仅锁定在 SD-1.5 基座上,无法直接兼容 Anything-V3 等社区热门模型,导致风格与控制力不可兼得。
- 手动融合高风险:开发者需自行编写复杂的权重加减脚本($NewBase + ControlHint - OriginalBase$),极易因维度不匹配或参数错位导致推理崩溃。
- 框架适配困难:缺乏针对 Diffusers 框架的原生支持教程,若要从 PyTorch Lightning 迁移代码,需耗费大量时间重构底层逻辑。
- 试错成本高昂:每次尝试新基座模型都需重复上述繁琐过程,严重拖慢原型验证和迭代速度。
使用 ControlNet-for-Diffusers 后
- 无缝基座替换:只需配置少量路径参数,即可通过内置算法自动将 ControlNet 的控制权重“移植”到 Anything-V3 等新基座上。
- 原生框架支持:提供专为 Diffusers 设计的精简代码示例,无需修改底层架构即可直接加载转换后的模型进行推理。
- 流程标准化:将复杂的权重运算封装为
tool_transfer_control.py一键脚本,大幅降低人为操作失误率,确保输出模型可用。 - 灵活扩展生态:不仅支持姿势控制,还可轻松适配 T2I-Adapter 和 LoRA,让开发者能自由组合各类社区模型构建专属工作流。
ControlNet-for-Diffusers 打破了基座模型与控制插件间的壁垒,让开发者能以最低成本实现“任意模型 + 精准控制”的自由组合。
运行环境要求
- 未说明
需要 NVIDIA GPU (代码示例使用 .to('cuda'),且 Colab 演示仅适用于拥有较大显存的 Colab Pro 用户)
Colab 演示提示需要较大 RAM (具体数值未说明,建议 16GB+)
快速开始
ControlNet适用于任何基础模型 
本项目已弃用,虽然仍可运行,但可能与最新版本的软件包不兼容。我将很快重构此工具,如有紧急问题,请直接通过 haofanwang.ai@gmail.com 联系我。
本仓库为开发者提供了在 diffusers 框架中使用 ControlNet 和基础模型的最简教程,而非通过 WebUI。我们的工作高度依赖于其他优秀的工作成果。尽管这些工作已经做出了一些尝试,但目前仍缺乏支持 diffusers 中多种 ControlNet 的教程。
我们还支持了 T2I-Adapter-for-Diffusers、Lora-for-Diffusers。如果对您有所帮助,请不要吝啬给我们点个赞哦。
ControlNet + Anything-v3
我们的目标是替换 ControlNet 的基础模型,并在 diffusers 框架中进行推理。原始的 ControlNet 是在 pytorch_lightning 中训练的,而其发布的权重仅以 stable-diffusion-1.5 作为基础模型。然而,用户采用自己的基础模型而非 sd-1.5 会更加灵活。现在,我们以 anything-v3 为例,逐步展示如何实现这一目标(ControlNet-AnythingV3)。我们提供了一个 Colab 演示 ![]() ,但它仅适用于拥有更大内存的 Colab Pro 用户。
,但它仅适用于拥有更大内存的 Colab Pro 用户。
(1) 第一步是替换基础模型。
幸运的是,ControlNet 已经提供了一份 指南,用于将 ControlNet 转移到任何其他社区模型。其逻辑如下:我们保留添加的控制权重,只替换基础模型。请注意,这并不总是可行的,因为 ControlNet 可能在基础模型中包含一些可训练的权重。
新基础模型-控制提示 = 新基础模型 + 原始基础模型-控制提示 - 原始基础模型
首先,我们从 ControlNet 克隆这个仓库。
git clone https://github.com/lllyasviel/ControlNet.git
cd ControlNet
然后,我们需要准备好所需的权重,包括 原始基础模型(path_sd15)、原始基础模型-控制提示(path_sd15_with_control)、新基础模型(path_input)。你只需下载以下权重,我们以 pose 作为控制提示,以 anything-v3 作为新的基础模型为例。我们将所有权重放在 ./models 目录下。
path_sd15 = './models/v1-5-pruned.ckpt'
path_sd15_with_control = './models/control_sd15_openpose.pth'
path_input = './models/anything-v3-full.safetensors'
path_output = './models/control_any3_openpose.pth'
最后,我们可以直接运行
python tool_transfer_control.py
如果成功,你将得到新的模型。该模型已经可以在 ControlNet 的代码库中使用。
models/control_any3_openpose.pth
如果你想尝试其他模型,只需定义你自己的 path_sd15_with_control 和 path_input。如果 path_input 是用 diffusers 训练的,你可以先使用 convert_diffusers_to_original_stable_diffusion.py 将其转换为 safetensors 格式。
(2) 第二步是转换为 diffusers
值得庆幸的是,Takuma Mori 在最近的 PR 中对此进行了支持,因此我们可以轻松实现这一目标。由于该功能仍在开发中,可能会不稳定,因此我们必须使用特定的提交版本。我们注意到 diffusers 已于 2023 年 3 月 2 日合并了该 PR,我们将很快重新整理我们的教程。
git clone https://github.com/takuma104/diffusers.git
cd diffusers
git checkout 9a37409663a53f775fa380db332d37d7ea75c915
pip install .
给定步骤 (1) 中生成的模型路径,运行
python ./scripts/convert_controlnet_to_diffusers.py --checkpoint_path control_any3_openpose.pth --dump_path control_any3_openpose --device cpu
我们得到了保存的模型 control_any3_openpose。现在我们可以像往常一样对其进行测试。
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_image
pose_image = load_image('https://huggingface.co/takuma104/controlnet_dev/resolve/main/pose.png')
pipe = StableDiffusionControlNetPipeline.from_pretrained("control_any3_openpose").to("cuda")
pipe.safety_checker = lambda images, clip_input: (images, False)
image = pipe(prompt="1gril,masterpiece,graden", controlnet_hint=pose_image).images[0]
image.save("generated.png")
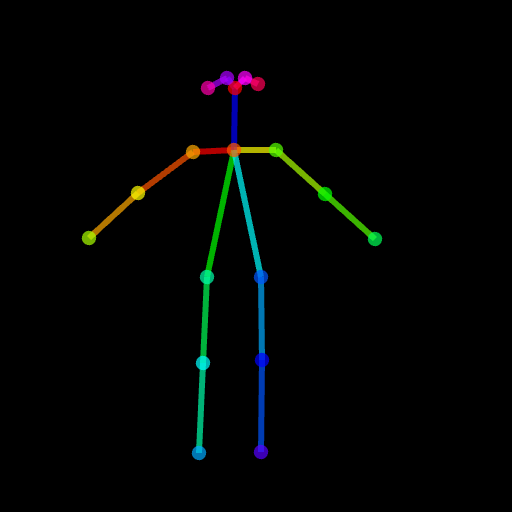
生成的结果可能不够理想,因为 pose 图像较为复杂。为了确保一切顺利,建议通过 PoseMaker 生成一个标准的 pose,或者使用我们在 ./images/pose.png 中提供的 pose 图像。

ControlNet + 图像修复
这是为了支持 ControlNet 具备仅修改目标区域的能力,而不是像 stable-diffusion-inpainting 那样修改整张图像。目前,我们提前提供了条件(pose、分割图),但你也可以使用 ControlNet 中预训练的检测器。
我们提供了用于使用的 所需管道。但请注意,该文件尚未经过全面测试,比较脆弱,我们将在后续正式考虑将其集成到 diffusers 框架中。此外,我们发现 ControlNet(基于 sd1.5)与 stable-diffusion-2-inpainting 不兼容,因为某些层的模块和维度不同。如果你强行加载权重并跳过那些不匹配的层,结果将会很糟糕。
# 假设你已经知道已安装 diffusers 的绝对路径
cp pipeline_stable_diffusion_controlnet_inpaint.py PATH/pipelines/stable_diffusion
然后,你需要在相应的文件中导入这个新添加的管道:
PATH/pipelines/__init__.py
PATH/__init__.py
现在,我们可以运行以下代码:
import torch
from diffusers.utils import load_image
from diffusers import StableDiffusionInpaintPipeline, StableDiffusionControlNetInpaintPipeline
# 我们已经将模型下载到本地,你也可以从 Hugging Face 加载
# control_sd15_seg 是根据上述说明,由 control_sd15_seg.safetensors 转换而来的
pipe_control = StableDiffusionControlNetInpaintPipeline.from_pretrained("./diffusers/control_sd15_seg",torch_dtype=torch.float16).to('cuda')
pipe_inpaint = StableDiffusionInpaintPipeline.from_pretrained("./diffusers/stable-diffusion-inpainting",torch_dtype=torch.float16).to('cuda')
# 是的,我们可以直接替换 UNet
pipe_control.unet = pipe_inpaint.unet
pipe_control.unet.in_channels = 4
# 我们也使用与 stable-diffusion-inpainting 相同的示例
image = load_image("https://oss.gittoolsai.com/images/haofanwang_ControlNet-for-Diffusers_readme_ebee4664a2ef.png")
mask = load_image("https://oss.gittoolsai.com/images/haofanwang_ControlNet-for-Diffusers_readme_00d96a10bfe2.png")
# 分割结果来自 https://huggingface.co/spaces/hysts/ControlNet
control_image = load_image('tmptvkkr0tg.png')
image = pipe_control(prompt="一只黄色猫的脸,高分辨率,坐在公园长椅上",
negative_prompt="低分辨率,解剖结构错误,最差质量,低质量",
controlnet_hint=control_image,
image=image,
mask_image=mask,
num_inference_steps=100).images[0]
image.save("inpaint_seg.jpg")
以下图片分别是原始图像、掩码图像、分割图(控制提示)以及生成的新图像。




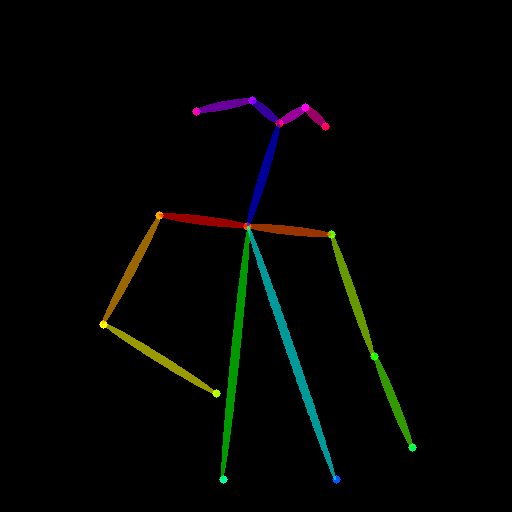
你也可以使用姿态作为控制提示。但请注意,建议使用 OpenPose 格式,这与训练过程一致。如果你只是想测试几张图片而不想在本地安装 OpenPose,可以直接使用 ControlNet 的在线演示,输入调整为 512x512 后生成姿态图。
image = load_image("./images/pose_image.jpg")
mask = load_image("./images/pose_mask.jpg")
pose_image = load_image('./images/pose_hint.png')
image = pipe_control(prompt="一个微笑的年轻男孩的脸",
negative_prompt="低分辨率,解剖结构错误,最差质量,低质量",
controlnet_hint=pose_image,
image=image,
mask_image=mask,
num_inference_steps=100).images[0]
image.save("inpaint_pos.jpg")



ControlNet + 图像修复 + 图像到图像转换
我们已经上传了 pipeline_stable_diffusion_controlnet_inpaint_img2img.py,以支持图像到图像转换。你可以按照与 这一节 相同的步骤操作。
多重 ControlNet(实验性)
类似于 T2I-Adapter,ControlNet 也支持多个控制图像作为输入。其原理很简单:由于基础模型是固定的,我们可以将 ControlNet1 和 ControlNet2 的输出结合起来,作为 UNet 的输入。这里我们提供伪代码供参考。你需要按如下方式修改管道:
control1 = controlnet1(latent_model_input, t, encoder_hidden_states=prompt_embeds, controlnet_hint=controlnet_hint1)
control2 = controlnet2(latent_model_input, t, encoder_hidden_states=prompt_embeds, controlnet_hint=controlnet_hint2)
# 请注意,权重需要相应调整
control1_weight = 1.00 # control_any3_openpose
control2_weight = 0.50 # control_sd15_depth
merged_control = []
for i in range(len(control1)):
merged_control.append(control1_weight*control[i]+control2_weight*control_1[i])
control = merged_control
noise_pred = unet(latent_model_input, t, encoder_hidden_states=prompt_embeds, cross_attention_kwargs=cross_attention_kwargs, control=control).sample
以下是一个多重 ControlNet 的示例,我们使用姿态和深度图作为控制提示。测试图片均归功于 T2I-Adapter。


训练你自己的 ControlNet
为了避免本仓库过于臃肿,我们在 Train-ControlNet-in-Diffusers 中提供了训练教程。
致谢
首先感谢 ControlNet 的作者所做出的杰出工作,我们的转换代码借鉴自 此处。我们也非常感谢 diffusers 中的 此 Pull Request 的贡献,正是它使得我们能够将 ControlNet 加载到 diffusers 中。
联系方式
本仓库仍在积极开发中,如果你在使用过程中遇到任何问题,请随时提交 issue。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。