LSTM-Human-Activity-Recognition
LSTM-Human-Activity-Recognition 是一个基于 TensorFlow 构建的开源项目,旨在利用智能手机传感器数据识别用户的日常行为。它能够准确分类六种常见活动:行走、上楼梯、下楼梯、坐着、站立以及躺卧。
该项目主要解决了传统行为识别方法中过度依赖人工特征工程的痛点。以往的研究往往需要结合复杂的信号处理技术来提取数据特征,而 LSTM-Human-Activity-Recognition 采用长短期记忆网络(LSTM)这一循环神经网络架构,能够直接处理近乎原始的传感器时间序列数据。这种“多对一”的深度学习模型像一个智能黑盒,自动学习数据中的时序规律,无需繁琐的前置处理即可实现高精度分类。
其核心技术亮点在于利用 LSTM 擅长处理序列数据的特性,仅需对加速度计数据进行简单的重力过滤,即可让模型从连续的传感器读数中提炼出行为模式。这使得整个流程比传统方法更加简洁高效。
该工具非常适合人工智能开发者、深度学习研究人员以及希望探索移动端行为识别应用的学生使用。对于想要快速复现论文结果、学习如何将 RNN 应用于物联网传感器数据,或需要为健康监控、运动分析等应用构建原型的技术人员来说,这是一个极具参考价值的入门范例。
使用场景
某智能穿戴设备团队正在开发一款能自动记录用户日常行为(如行走、上下楼梯、坐立等)的健康监测 App,旨在为康复训练提供数据支持。
没有 LSTM-Human-Activity-Recognition 时
- 特征工程耗时巨大:团队需手动设计复杂的信号处理流程,从加速度计和陀螺仪原始数据中提取时域、频域特征,开发周期长达数周。
- 模型泛化能力弱:传统机器学习方法严重依赖人工提取的特征质量,面对不同用户的动作差异或传感器噪声时,识别准确率大幅下降。
- 难以捕捉时间序列规律:静态分类算法无法有效理解动作的连续性(如“上楼梯”是一个动态过程),导致对相似动作(如快走与慢跑)混淆严重。
- 维护成本高:一旦传感器硬件升级或数据采集频率变化,整个特征提取管道需重新调整和验证。
使用 LSTM-Human-Activity-Recognition 后
- 免去繁琐特征工程:直接输入近乎原始的传感器时序数据,LSTM 网络自动学习关键特征,将算法开发时间从数周缩短至几天。
- 鲁棒性显著提升:利用长短期记忆网络(LSTM)对时间依赖性的建模能力,即使在有噪声或个体差异的情况下,也能稳定识别六类活动。
- 精准识别动态行为:“多对一”的架构完美契合动作识别场景,能准确区分“上楼梯”与“下楼梯”等具有方向性的连续动作。
- 部署灵活便捷:基于 TensorFlow 的实现易于移植到移动端,当数据源微调时,只需少量重新训练即可适应,无需重构整个预处理流程。
LSTM-Human-Activity-Recognition 通过将复杂的时序建模任务转化为端到端的深度学习方案,让开发者从繁重的信号处理中解放出来,专注于上层应用创新。
运行环境要求
- Linux
未说明 (代码基于 TensorFlow CPU 版本示例,未明确提及 GPU 需求)
未说明

快速开始
用于人类活动识别的LSTM
使用智能手机数据集和LSTM RNN进行人类活动识别(HAR)。将运动类型分类为六类:
- 步行,
- 上楼梯,
- 下楼梯,
- 坐着,
- 站立,
- 躺着。
与传统方法相比,使用带有长短期记忆单元(LSTM)的循环神经网络(RNN)几乎不需要特征工程。可以直接将数据输入到神经网络中,神经网络就像一个黑箱一样,正确地建模问题。其他研究在该活动识别数据集上可能需要大量的特征工程,这更接近于结合经典数据科学技术的信号处理方法。而这里的方法在数据预处理方面则非常简单。
我们将使用Google简洁的深度学习库TensorFlow,演示如何使用LSTM——一种可以处理序列数据/时间序列的人工神经网络。
视频数据集概述
请点击此链接观看实验中记录的6种活动视频,由其中一位参与者完成:

输入数据详情
我将使用LSTM对数据进行学习(模拟附着在腰部的手机),以识别用户正在进行的活动类型。数据集的描述如下:
传感器信号(加速度计和陀螺仪)经过噪声滤波器预处理后,以2.56秒的固定宽度滑动窗口采集,且窗口之间有50%的重叠(每个窗口包含128个读数)。传感器加速度信号包含重力和身体运动成分,通过巴特沃斯低通滤波器将其分离为身体加速度和重力。假设重力只含有低频成分,因此使用了截止频率为0.3 Hz的滤波器。
也就是说,我将使用几乎未经处理的数据:仅在预处理步骤中从加速度计中滤除了重力效应,作为另一个三维特征输入以帮助学习。如果你希望自行提取重力,可以基于我的代码,使用Python中的巴特沃斯低通滤波器(LPF),并将其修改为合适的0.3 Hz截止频率,这对于来自身体传感器的活动识别来说是一个很好的频率。
什么是RNN?
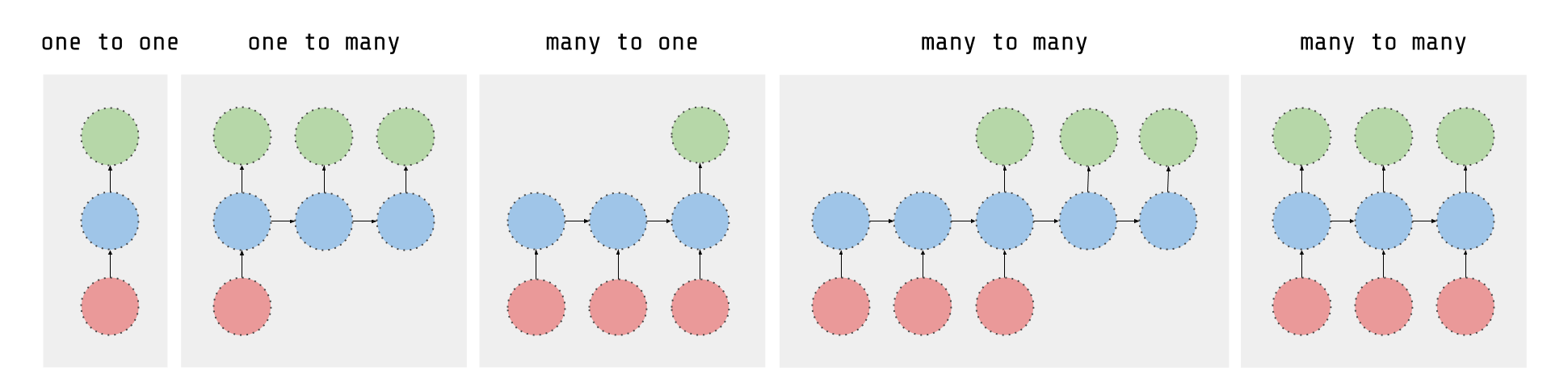
正如这篇文章所解释的那样,RNN接收多个输入向量进行处理,并输出其他向量。大致可以想象成下图所示的样子,假设每个矩形都有向量深度以及图中所示的一些特殊隐藏特性。在我们的案例中,使用的是“多对一”架构:我们接受特征向量的时间序列(每个时间步对应一个向量),将其转换为输出端的概率向量,用于分类。需要注意的是,“一对一”架构则属于标准的前馈神经网络。
什么是LSTM?
LSTM是改进版的RNN。它更加复杂,但更容易训练,能够避免所谓的梯度消失问题。我推荐你参加这门课程,以深入了解LSTM。
结果
继续往下看吧!精彩的可视化内容等着你呢。
# 所有导入
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf # 版本 1.0.0(过去的一些提交中使用过旧版本)
from sklearn import metrics
import os
# 有用的常量
这些是分别归一化的输入特征,供神经网络使用。
INPUT_SIGNAL_TYPES = [
"body_acc_x_",
"body_acc_y_",
"body_acc_z_",
"body_gyro_x_",
"body_gyro_y_",
"body_gyro_z_",
"total_acc_x_",
"total_acc_y_",
"total_acc_z_"
]
用于学习分类的输出类别。
LABELS = [
"WALKING",
"WALKING_UPSTAIRS",
"WALKING_DOWNSTAIRS",
"SITTING",
"STANDING",
"LAYING"
]
首先让我们下载数据:
# 注意:在这些“ipython notebook”单元格中,Linux bash命令以“!”开头
DATA_PATH = "data/"
!pwd && ls
os.chdir(DATA_PATH)
!pwd && ls
!python download_dataset.py
!pwd && ls
os.chdir("..")
!pwd && ls
DATASET_PATH = DATA_PATH + "UCI HAR Dataset/"
print("\n" + "数据集现在位于:" + DATASET_PATH)
/home/ubuntu/pynb/LSTM-Human-Activity-Recognition
data LSTM_files LSTM_OLD.ipynb README.md
LICENSE LSTM.ipynb lstm.py screenlog.0
/home/ubuntu/pynb/LSTM-Human-Activity-Recognition/data
download_dataset.py source.txt
下载中...
--2017-05-24 01:49:53-- https://archive.ics.uci.edu/ml/machine-learning-databases/00240/UCI%20HAR%20Dataset.zip
解析 archive.ics.uci.edu (archive.ics.uci.edu)... 128.195.10.249
连接到 archive.ics.uci.edu (archive.ics.uci.edu)|128.195.10.249|:443... 已连接。
发送 HTTP 请求,等待响应... 200 OK
长度:60999314 字节(58 MB)[application/zip]
保存为:‘UCI HAR Dataset.zip’
100%[======================================>] 60,999,314 1.69MB/s 在 38 秒内
2017-05-24 01:50:31 (1.55 MB/s) - ‘UCI HAR Dataset.zip’ 已保存 [60999314/60999314]
下载完成。
解压中...
成功解压至 /home/ubuntu/pynb/LSTM-Human-Activity-Recognition/data/UCI HAR Dataset。
/home/ubuntu/pynb/LSTM-Human-Activity-Recognition/data
download_dataset.py __MACOSX source.txt UCI HAR Dataset UCI HAR Dataset.zip
/home/ubuntu/pynb/LSTM-Human-Activity-Recognition
data LSTM_files LSTM_OLD.ipynb README.md
LICENSE LSTM.ipynb lstm.py screenlog.0
数据集现在位于:data/UCI HAR Dataset/
准备数据集:
TRAIN = "train/"
TEST = "test/"
# 加载“X”(神经网络的训练和测试输入)
def load_X(X_signals_paths):
X_signals = []
for signal_type_path in X_signals_paths:
file = open(signal_type_path, 'r')
# 从磁盘读取数据集,处理文本文件的语法
X_signals.append(
[np.array(serie, dtype=np.float32) for serie in [
row.replace(' ', ' ').strip().split(' ') for row in file
]]
)
file.close()
return np.transpose(np.array(X_signals), (1, 2, 0))
X_train_signals_paths = [
DATASET_PATH + TRAIN + "Inertial Signals/" + signal + "train.txt" for signal in INPUT_SIGNAL_TYPES
]
X_test_signals_paths = [
DATASET_PATH + TEST + "Inertial Signals/" + signal + "test.txt" for signal in INPUT_SIGNAL_TYPES
]
X_train = load_X(X_train_signals_paths)
X_test = load_X(X_test_signals_paths)
# 加载“y”(神经网络的训练和测试输出)
def load_y(y_path):
file = open(y_path, 'r')
# 从磁盘读取数据集,处理文本文件的语法
y_ = np.array(
[elem for elem in [
row.replace(' ', ' ').strip().split(' ') for row in file
]],
dtype=np.int32
)
file.close()
# 对每个输出类别减1,以便使用友好的0索引
return y_ - 1
y_train_path = DATASET_PATH + TRAIN + "y_train.txt"
y_test_path = DATASET_PATH + TEST + "y_test.txt"
y_train = load_y(y_train_path)
y_test = load_y(y_test_path)
额外参数:
以下是训练的一些核心参数定义。
例如,整个神经网络的结构可以通过列举这些参数以及使用两个LSTM层堆叠在一起(即隐藏层在时间步上逐层传递)来概括。
# 输入数据
training_data_count = len(X_train) # 7352个训练序列(每两个序列之间有50%的重叠)
test_data_count = len(X_test) # 2947个测试序列
n_steps = len(X_train[0]) # 每个序列有128个时间步
n_input = len(X_train[0][0]) # 每个时间步有9个输入参数
# LSTM神经网络的内部结构
n_hidden = 32 # 隐藏层的特征数
n_classes = 6 # 总共6个类别
# 训练
learning_rate = 0.0025
lambda_loss_amount = 0.0015
training_iters = training_data_count * 300 # 在数据集上循环300次
batch_size = 1500
display_iter = 30000 # 在训练过程中显示测试集准确率
# 一些调试信息
print("一些有用的信息,用于了解数据集的形状和归一化情况:")
print("(X的形状、y的形状、X中每个元素的均值、X中每个元素的标准差)")
print(X_test.shape, y_test.shape, np.mean(X_test), np.std(X_test))
print("因此,数据集如预期般已正确归一化,但尚未进行独热编码。")
一些有用的信息,用于了解数据集的形状和归一化情况:
(X的形状、y的形状、X中每个元素的均值、X中每个元素的标准差)
(2947, 128, 9) (2947, 1) 0.0991399 0.395671
因此,数据集如预期般已正确归一化,但尚未进行独热编码。
训练用的辅助函数:
def LSTM_RNN(_X, _weights, _biases):
# 函数根据给定的参数返回一个TensorFlow LSTM(RNN)人工神经网络。
# 此外,还堆叠了两个LSTM单元,使神经网络更深层。
# 注意,本笔记本中的部分代码灵感来源于另一个数据集上使用的略有不同的RNN架构,其中部分功劳归于“aymericdamien”,采用MIT许可证。
# (注意:这一步可以通过一次性调整数据集形状来大幅优化
# 输入形状:(batch_size, n_steps, n_input)
_X = tf.transpose(_X, [1, 0, 2]) # 交换n_steps和batch_size
# 重塑以准备输入到隐藏层激活
_X = tf.reshape(_X, [-1, n_input])
# 新形状:(n_steps*batch_size, n_input)
# ReLU激活,感谢Yu Zhao在此处添加了这一改进:
_X = tf.nn.relu(tf.matmul(_X, _weights['hidden']) + _biases['hidden'])
# 分割数据,因为RNN单元需要一个输入列表来进行RNN内部循环
_X = tf.split(_X, n_steps, 0)
# 新形状:n_steps * (batch_size, n_hidden)
# 使用TensorFlow定义两个堆叠的LSTM单元(两层递归深度)
lstm_cell_1 = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)
lstm_cell_2 = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)
lstm_cells = tf.contrib.rnn.MultiRNNCell([lstm_cell_1, lstm_cell_2], state_is_tuple=True)
# 获取LSTM单元的输出
outputs, states = tf.contrib.rnn.static_rnn(lstm_cells, _X, dtype=tf.float32)
# 获取最后一个时间步的输出特征,用于“多对一”风格的分类器,
# 就像本页顶部描述RNN的图片中所示
lstm_last_output = outputs[-1]
# 线性激活
return tf.matmul(lstm_last_output, _weights['out']) + _biases['out']
def extract_batch_size(_train, step, batch_size):
# 从“(X|y)_train”数据中获取“batch_size”数量的数据的函数。
shape = list(_train.shape)
shape[0] = batch_size
batch_s = np.empty(shape)
for i in range(batch_size):
# 循环索引
index = ((step-1)*batch_size + i) % len(_train)
batch_s[i] = _train[index]
return batch_s
def one_hot(y_, n_classes=n_classes):
# 将神经网络的独热输出标签从数字索引编码为独热向量的函数
# 例如:
# one_hot(y_=[[5], [0], [3]], n_classes=6):
# 返回 [[0, 0, 0, 0, 0, 1], [1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0]]
y_ = y_.reshape(len(y_))
return np.eye(n_classes)[np.array(y_, dtype=np.int32)] # 返回浮点数
让我们认真起来,构建神经网络:
# 图形输入/输出
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
# 图形权重
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # 隐藏层权重
'out': tf.Variable(tf.random_normal([n_hidden, n_classes], mean=1.0))
}
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
pred = LSTM_RNN(x, weights, biases)
# 损失、优化器和评估
l2 = lambda_loss_amount * sum(
tf.nn.l2_loss(tf_var) for tf_var in tf.trainable_variables()
) # L2损失防止这个过于强大的神经网络过拟合数据
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=pred)) + l2 # Softmax损失
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam优化器
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
太好了,现在开始训练神经网络:
# 用于跟踪训练性能
test_losses = []
test_accuracies = []
train_losses = []
train_accuracies = []
# 启动计算图
sess = tf.InteractiveSession(config=tf.ConfigProto(log_device_placement=True))
init = tf.global_variables_initializer()
sess.run(init)
# 每次循环使用“batch_size”数量的示例数据进行训练步骤
step = 1
while step * batch_size <= training_iters:
batch_xs = extract_batch_size(X_train, step, batch_size)
batch_ys = one_hot(extract_batch_size(y_train, step, batch_size))
# 使用批次数据进行训练
_, loss, acc = sess.run(
[optimizer, cost, accuracy],
feed_dict={
x: batch_xs,
y: batch_ys
}
)
train_losses.append(loss)
train_accuracies.append(acc)
# 为了加快训练速度,仅在某些步骤评估网络:
if (step*batch_size % display_iter == 0) or (step == 1) or (step * batch_size > training_iters):
# 为了避免频繁输出到控制台,在这个“if”语句中显示训练准确率和损失
print("训练迭代 #" + str(step*batch_size) + \
": 批次损失 = " + "{:.6f}".format(loss) + \
", 准确率 = {}".format(acc))
# 在测试集上进行评估(这里不进行学习,仅用于诊断)
loss, acc = sess.run(
[cost, accuracy],
feed_dict={
x: X_test,
y: one_hot(y_test)
}
)
test_losses.append(loss)
test_accuracies.append(acc)
print("测试集表现:" + \
"批次损失 = {}".format(loss) + \
", 准确率 = {}".format(acc))
step += 1
print("优化完成!")
# 测试数据的准确率
one_hot_predictions, accuracy, final_loss = sess.run(
[pred, accuracy, cost],
feed_dict={
x: X_test,
y: one_hot(y_test)
}
)
test_losses.append(final_loss)
test_accuracies.append(accuracy)
print("最终结果:" + \
"批次损失 = {}".format(final_loss) + \
", 准确率 = {}".format(accuracy))
警告:tensorflow:来自 <ipython-input-19-3339689e51f6>:9:initialize_all_variables(来自 tensorflow.python.ops.variables)已弃用,并将在 2017 年 3 月 2 日之后删除。
更新说明:
请改用 `tf.global_variables_initializer`。
训练迭代 #1500: 批次损失 = 5.416760,准确率 = 0.15266665816307068
测试集表现:批次损失 = 4.880829811096191,准确率 = 0.05632847175002098
训练迭代 #30000: 批次损失 = 3.031930,准确率 = 0.607333242893219
测试集表现:批次损失 = 3.0515167713165283,准确率 = 0.6067186594009399
训练迭代 #60000: 批次损失 = 2.672764,准确率 = 0.7386667032241821
测试集表现:批次损失 = 2.780435085296631,准确率 = 0.7027485370635986
训练迭代 #90000: 批次损失 = 2.378301,准确率 = 0.8366667032241821
测试集表现:批次损失 = 2.6019773483276367,准确率 = 0.7617915868759155
训练迭代 #120000: 批次损失 = 2.127290,准确率 = 0.9066667556762695
测试集表现:批次损失 = 2.3625404834747314,准确率 = 0.8116728663444519
训练迭代 #150000: 批次损失 = 1.929805,准确率 = 0.9380000233650208
测试集表现:批次损失 = 2.306251049041748,准确率 = 0.8276212215423584
训练迭代 #180000: 批次损失 = 1.971904,准确率 = 0.9153333902359009
测试集表现:批次损失 = 2.0835530757904053,准确率 = 0.8771631121635437
训练迭代 #210000: 批次损失 = 1.860249,准确率 = 0.8613333702087402
测试集表现:批次损失 = 1.9994492530822754,准确率 = 0.8788597583770752
训练迭代 #240000: 批次损失 = 1.626292,准确率 = 0.9380000233650208
测试集表现:批次损失 = 1.879166603088379,准确率 = 0.8944689035415649
训练迭代 #270000: 批次损失 = 1.582758,准确率 = 0.9386667013168335
测试集表现:批次损失 = 2.0341007709503174,准确率 = 0.8361043930053711
训练迭代 #300000: 批次损失 = 1.620352,准确率 = 0.9306666851043701
测试集表现:批次损失 = 1.8185184001922607,准确率 = 0.8639293313026428
训练迭代 #330000: 批次损失 = 1.474394,准确率 = 0.9693333506584167
测试集表现:批次损失 = 1.7638503313064575,准确率 = 0.8747878670692444
训练迭代 #360000: 批次损失 = 1.406998,准确率 = 0.9420000314712524
测试集表现:批次损失 = 1.5946787595748901,准确率 = 0.902273416519165
训练迭代 #390000: 批次损失 = 1.362515,准确率 = 0.940000057220459
测试集表现:批次损失 = 1.5285792350769043,准确率 = 0.9046487212181091
训练迭代 #420000: 批次损失 = 1.252860,准确率 = 0.9566667079925537
测试集表现:批次损失 = 1.4635565280914307,准确率 = 0.910756587982177
训练迭代 #450000: 批次损失 = 1.190078,准确率 = 0.9553333520889282
...
测试集表现:批次损失 = 0.42567864060401917,准确率 = 0.9324736595153809
训练迭代 #2070000: 批次损失 = 0.342763,准确率 = 0.9326667189598083
测试集表现:批次损失 = 0.4292983412742615,准确率 = 0.9273836612701416
训练迭代 #2100000: 批次损失 = 0.259442,准确率 = 0.9873334169387817
测试集表现:批次损失 = 0.44131210446357727,准确率 = 0.9273836612701416
训练迭代 #2130000: 批次损失 = 0.284630,准确率 = 0.9593333601951599
测试集表现:批次损失 = 0.46982717514038086,准确率 = 0.9093992710113525
训练迭代 #2160000: 批次损失 = 0.299012,准确率 = 0.9686667323112488
测试集表现:批次损失 = 0.48389002680778503,准确率 = 0.9138105511665344
训练迭代 #2190000: 批次损失 = 0.287106,准确率 = 0.9700000286102295
测试集表现:批次损失 = 0.4670214056968689,准确率 = 0.921615123748779
优化完成!
最终结果:批次损失 = 0.45611169934272766,准确率 = 0.9165252447128296
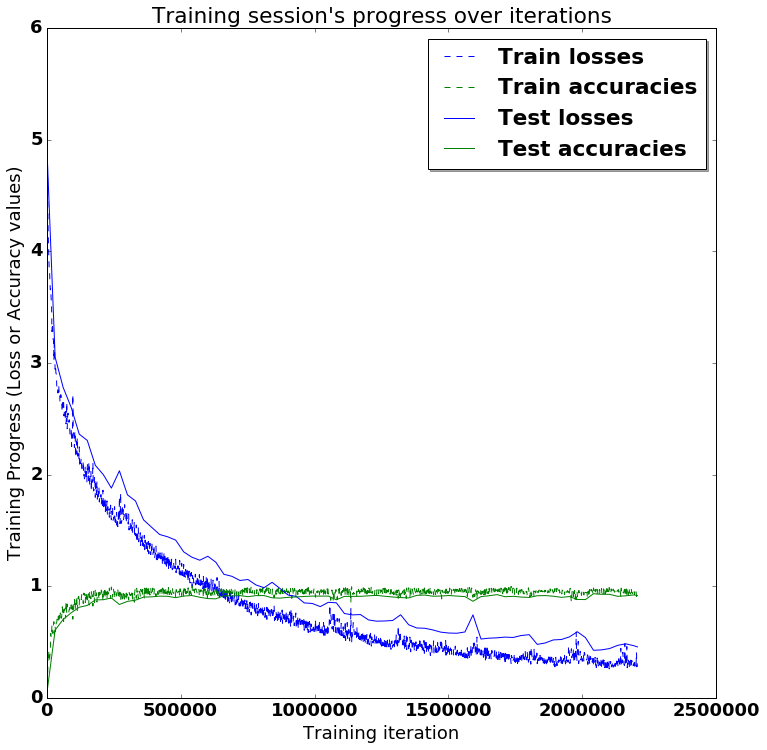
训练效果不错,但拥有可视化洞察力会更好:
好的,我们现在就简单地在笔记本中绘制这些图表吧。
# (内联绘图:)
%matplotlib inline
font = {
'family' : 'Bitstream Vera Sans',
'weight' : 'bold',
'size' : 18
}
matplotlib.rc('font', **font)
width = 12
height = 12
plt.figure(figsize=(width, height))
indep_train_axis = np.array(range(batch_size, (len(train_losses)+1)*batch_size, batch_size))
plt.plot(indep_train_axis, np.array(train_losses), "b--", label="训练损失")
plt.plot(indep_train_axis, np.array(train_accuracies), "g--", label="训练准确率")
indep_test_axis = np.append(
np.array(range(batch_size, len(test_losses)*display_iter, display_iter)[:-1]),
[training_iters]
)
plt.plot(indep_test_axis, np.array(test_losses), "b-", label=" 测试损失")
plt.plot(indep_test_axis, np.array(test_accuracies), "g-", label=" 测试准确率")
plt.title("训练过程随迭代次数的变化")
plt.legend(loc='upper right', shadow=True)
plt.ylabel('训练进展(损失或准确率值)')
plt.xlabel('训练迭代次数')
plt.show()
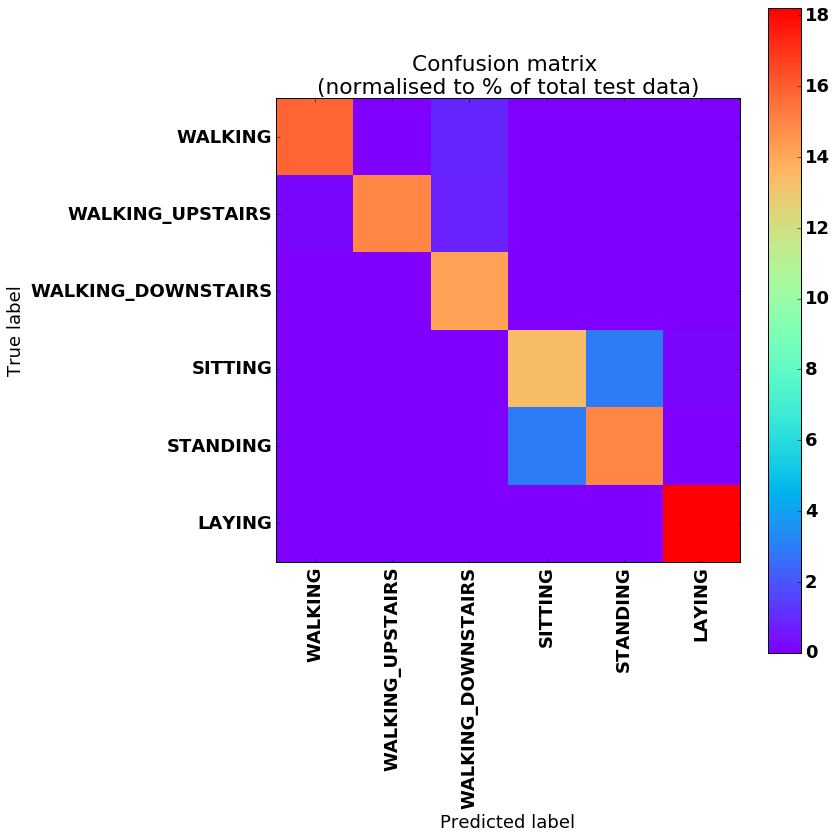
最后,多分类混淆矩阵及各项指标!
# 结果
predictions = one_hot_predictions.argmax(1)
print("测试准确率:{}%".format(100*accuracy))
print("")
print("精确率:{}%".format(100*metrics.precision_score(y_test, predictions, average="weighted")))
print("召回率:{}%".format(100*metrics.recall_score(y_test, predictions, average="weighted")))
print("f1分数:{}%".format(100*metrics.f1_score(y_test, predictions, average="weighted")))
print("")
print("混淆矩阵:")
confusion_matrix = metrics.confusion_matrix(y_test, predictions)
print(confusion_matrix)
normalised_confusion_matrix = np.array(confusion_matrix, dtype=np.float32)/np.sum(confusion_matrix)*100
print("")
print("混淆矩阵(归一化为测试数据总量的百分比):")
print(normalised_confusion_matrix)
print("注:训练和测试数据在各类别中的分布并不均衡,")
print("因此最后一位类别中正确分类的数据超过六分之一是正常现象。")
# 绘制结果:
width = 12
height = 12
plt.figure(figsize=(width, height))
plt.imshow(
normalised_confusion_matrix,
interpolation='nearest',
cmap=plt.cm.rainbow
)
plt.title("混淆矩阵 \n(归一化为测试数据总量的百分比)")
plt.colorbar()
tick_marks = np.arange(n_classes)
plt.xticks(tick_marks, LABELS, rotation=90)
plt.yticks(tick_marks, LABELS)
plt.tight_layout()
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
测试准确率:91.65252447128296%
精确率:91.76286479743305%
召回率:91.65252799457076%
f1分数:91.6437546304815%
混淆矩阵:
[[466 2 26 0 2 0]
[ 5 441 25 0 0 0]
[ 1 0 419 0 0 0]
[ 1 1 0 396 87 6]
[ 2 1 0 87 442 0]
[ 0 0 0 0 0 537]]
混淆矩阵(归一化为测试数据总量的百分比):
[[ 15.81269073 0.06786563 0.88225317 0. 0.06786563 0. ]
[ 0.16966406 14.96437073 0.84832031 0. 0. 0. ]
[ 0.03393281 0. 14.21784878 0. 0. 0. ]
[ 0.03393281 0.03393281 0. 13.43739319 2.95215464
0.20359688]
[ 0.06786563 0.03393281 0. 2.95215464 14.99830341 0. ]
[ 0. 0. 0. 0. 0. 18.22192001]]
注:训练和测试数据在各类别中的分布并不均衡,
因此最后一位类别中正确分类的数据超过六分之一是正常现象。
sess.close()
结论
令人欣喜的是,最终准确率达到91%!而且在训练过程中,由于神经网络权重的随机初始化不同,有时甚至能达到93.25%的峰值。
这意味着该神经网络几乎总是能够准确识别动作类型!请记住,手机是佩戴在腰部的,而每个待分类的序列仅包含两个内置传感器的128个样本窗口(即50帧/秒下的2.56秒),因此在如此有限的上下文和原始数据下,这些预测仍然非常准确,这让我感到十分惊讶。我已经多次验证过代码,确认其中没有重大错误,并且社区也广泛使用和测试了这段代码。(注:如果您发现任何问题,请务必在问题页面上报告;否则,Quora、StackOverflow以及其他StackExchange网站都是提问的好去处。)
我特别没想到模型在“SITTING”和“STANDING”这两个标签之间的区分效果会如此出色。从腰间设备的角度来看,根据原始数据集的收集方式,这两者似乎非常相似。然而,在混淆矩阵中仍能看到这两个类别之间存在一个小的聚类区域,虽然它与对角线略有偏离,但这已经相当不错了。
此外,还可以看出,模型在区分“WALKING”、“WALKING_UPSTAIRS”和“WALKING_DOWNSTAIRS”时存在一定困难。显然,这些活动在运动模式上确实非常相似。
我还尝试过只使用3D加速度计的6个特征来运行代码(未启用陀螺仪,并且不改变训练超参数),结果准确率为87%。通常来说,陀螺仪比加速度计消耗更多的电量,因此最好将其关闭。
改进
在我的另一个开源仓库 HAR-stacked-residual-bidir-LSTMs 中,通过结合双向 RNN、残差连接和堆叠单元的特殊深度 LSTM 架构,准确率被提升至接近 94%。该架构还在另一个类似的活动数据集上进行了测试。它类似于 “Google 的神经机器翻译系统:弥合人类与机器翻译之间的鸿沟” 中使用的优秀架构,但去除了注意力机制,仅保留了编码器部分——作为一种“多对一”架构,而非“多对多”,以适应人类活动识别(HAR)问题。我还进一步研究了这个问题,并提出了 LARNN,然而其复杂性与微小的性能提升并不成比例。因此,当前这个原始的活动识别项目因其简单性而更易于使用。此外,我们还使用经典特征提取技术和较旧的机器学习算法,在相同的数据集上构建了一个 非深度学习的机器学习流水线。
如果你想深入学习深度学习,我还整理了一份对我最有用的深度学习学习资源列表,可以在这里找到:深度学习优质资源。
参考文献
该 数据集 可在 UCI 机器学习存储库中找到:
Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra 和 Jorge L. Reyes-Ortiz. 使用智能手机进行人类活动识别的公共领域数据集。第 21 届欧洲人工神经网络、计算智能和机器学习研讨会,ESANN 2013。比利时布鲁日,2013 年 4 月 24–26 日。
引用
版权所有 © 2016 Guillaume Chevalier。如需引用我的代码,您可以指向 GitHub 仓库的 URL,例如:
Guillaume Chevalier, 用于人类活动识别的 LSTM,2016 年, https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition
我的代码根据 MIT 许可证 对所有人免费开放,甚至允许私人使用,但我要求在使用时注明出处。
以下是 BibTeX 格式的引用代码:
@misc{chevalier2016lstms,
title={LSTMs for human activity recognition},
author={Chevalier, Guillaume},
year={2016}
}
我还与合作者共同发表了一篇第二篇文章,内容是关于这项工作的第二次迭代及改进成果 HAR-stacked-residual-bidir-LSTMs,其中采用了更深的神经网络。该论文已在 arXiv 上发布。以下是基于该项目的这篇新论文的 BibTeX 引用代码:
@article{DBLP:journals/corr/abs-1708-08989,
author = {Yu Zhao and
Rennong Yang and
Guillaume Chevalier and
Maoguo Gong},
title = {基于可穿戴传感器的人类活动识别的深层残差双向 LSTM},
journal = {CoRR},
volume = {abs/1708.08989},
year = {2017},
url = {http://arxiv.org/abs/1708.08989},
archivePrefix = {arXiv},
eprint = {1708.08989},
timestamp = {Mon, 13 Aug 2018 16:46:48 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1708-08989},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
其他链接
与我联系
喜欢这个项目吗?它对你有帮助吗?请留下一个 星标、叉子 并分享这份喜爱吧!
这个活动识别项目曾出现在:
# 让我们自动将此笔记本转换为 GitHub 项目的标题页 README:
!jupyter nbconvert --to markdown LSTM.ipynb
!mv LSTM.md README.md
[NbConvertApp] 将笔记本 LSTM.ipynb 转换为 markdown 格式
[NbConvertApp] 支持文件将位于 LSTM_files/ 目录下
[NbConvertApp] 创建目录 LSTM_files
[NbConvertApp] 创建目录 LSTM_files
[NbConvertApp] 写入 38654 字节到 LSTM.md
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。