Awesome-Deep-Learning-Resources
Awesome-Deep-Learning-Resources 是由开发者 Guillaume Chevalier 主导的深度学习资源整理项目,旨在为学习者和从业者提供系统化的知识地图。它通过精心分类的 8 大模块(包括在线课程、书籍、论文、实践工具等),覆盖从基础概念到前沿技术的完整学习路径,尤其注重理论与实践结合。项目特别收录了作者亲自验证过的课程、代码库和数据集,并附带 Google 趋势分析图,帮助用户把握领域发展脉络。
该项目解决了深度学习学习资源分散、缺乏系统性指导的问题,尤其适合需要快速建立知识框架的开发者、研究人员和高校学生。其独特价值在于:1)资源经过作者逐项验证,避免无效信息;2)包含罕见的数学理论专题(如梯度下降算法、复数信号处理);3)前瞻性地探讨 GPU 架构演进与量子计算对深度学习的影响。对于希望从零基础入门或需要持续跟踪技术动态的用户,这里提供了从 Andrew Ng 经典课程到最新论文的完整生态链,同时推荐的实战工具和数据集能直接应用于项目开发。
使用场景
李明是一名刚毕业的软件工程师,计划转行进入人工智能领域,但面对零散的网络资源和复杂的知识体系,他陷入了学习困境。
没有 Awesome-Deep-Learning-Resources 时
- 资源分散难整合:在多个平台搜索课程时,常遇到重复内容或过时信息,耗费大量时间筛选
- 学习路径不清晰:尝试从《深度学习》花书开始,但数学基础薄弱导致前两章就难以推进
- 实践机会缺失:虽然完成了Kaggle入门赛,却找不到与课程内容匹配的实战项目
- 理论实践脱节:看论文时遇到LSTM结构,但缺乏对应的代码实现参考
使用 Awesome-Deep-Learning-Resources 后
- 一站式资源导航:通过分类目录直接定位到"Online Classes"中的Andrew Ng课程,配合配套的Python实践项目
- 渐进式学习规划:按照"Books"章节先完成《神经网络与深度学习》的数学基础训练,再进入高级课程
- 项目驱动学习:在"Practical resources"中找到PyTorch官方教程,边学理论边复现图像分类案例
- 理论实践闭环:当研究"Attention Mechanisms"论文时,可同步查看HuggingFace的Transformer实现代码
这个工具为深度学习学习者构建了完整的知识图谱,将碎片化资源转化为系统化学习路径,显著提升了从理论掌握到工程落地的效率。
运行环境要求
需要 NVIDIA GPU(未说明具体型号),显存需求取决于模型规模(未明确说明)
未说明

快速开始
深度学习资源精选 
这是一份我整理的深度学习(Deep Learning)优质资源清单。它对我学习深度学习非常有帮助,我经常用它来复习相关主题或作为参考资料。 我(Guillaume Chevalier)亲自构建了这份清单,并仔细学习了其中列出的所有内容。
目录
趋势
以下是2004年至2017年9月的Google Trends数据趋势图:
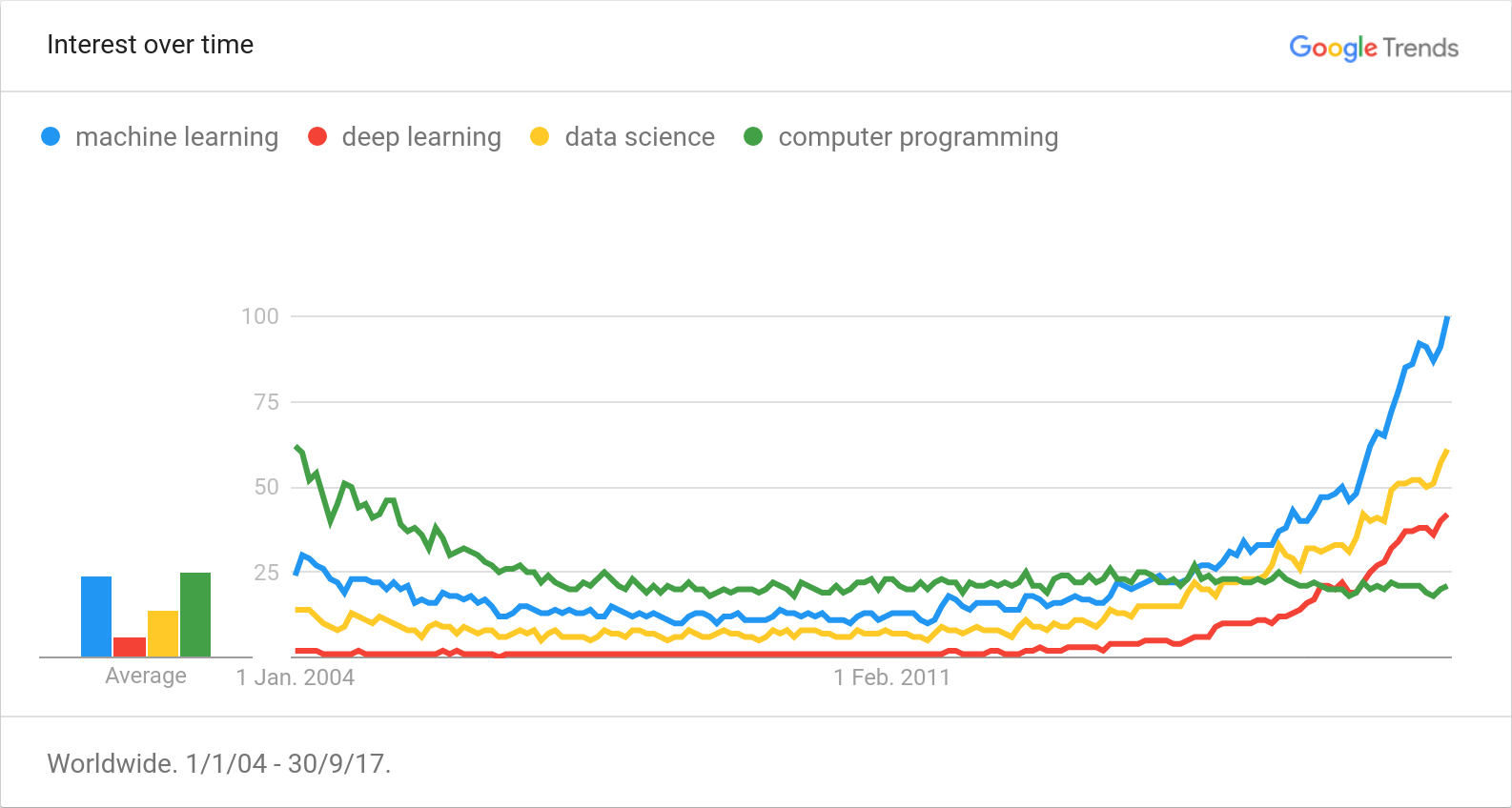
你也可以查看 Andrej Karpathy 的 新文章 了解机器学习研究的最新趋势。
我认为深度学习是让计算机更像人类思考的关键技术,具有巨大潜力。许多原本用传统算法难以解决的自动化任务,现在通过深度学习可以轻松实现。
摩尔定律(Moore's Law)描述的计算机硬件指数级进步,如今更多体现在GPU而非CPU上,因为物理限制使得原子晶体管无法无限缩小。我们正在向并行架构发展[了解更多]。深度学习通过GPU利用了这种并行架构。此外,深度学习算法未来可能结合量子计算(Quantum Computing)并应用于脑机接口(machine-brain interface)领域。
智能与认知的本质是极其有趣的探索课题,目前尚未完全被理解。这些技术充满前景。
在线课程
- DL&RNN 课程 - 我创建的深度学习与循环神经网络(RNN)密集课程。
- Coursera 上 Andrew Ng 的机器学习课程 - 著名的入门级课程,提供证书。讲师:斯坦福大学副教授 Andrew Ng,百度首席科学家,Coursera 联合创始人。
- Coursera 上 Andrew Ng 的深度学习专项课程 - Andrew Ng 新推出的5门深度学习课程系列,使用 Python 而非 Matlab/Octave,完成可获得专项证书。
- Google 的深度学习课程 - 中高级课程,涵盖深度学习高级概念,适合掌握基础后进行创意开发。
- Georgia Tech 的交易机器学习课程 - 介绍交易领域机器学习基础知识及AI与金融概念。Q-Learning部分尤其精彩。
- Hugo Larochelle 的神经网络课程(Sherbrooke大学) - Hugo Larochelle 免费提供的在线神经网络课程,我已观看部分内容。
- GLO-4030/7030 深度神经网络学习 - Laval大学 Philippe Giguère 教授的课程。特别推荐其多头注意力机制(multi-head attention mechanism)的可视化演示,详见第13周第28页幻灯片。
- 深度学习与循环神经网络(DL&RNN) - 本领域最密集的加速课程(滚动至页面底部)。
书籍
- 代码整洁之道 - 回归编程基础!学习如何编写整洁代码以提升职业素养。这本书是我读过的最佳书籍,尽管它与深度学习无关。
- 程序员的职业素养 - 学习如何作为专业程序员与经理沟通。这对任何编程职业都至关重要。
- 如何创造思维 - 通勤时聆听音频版很合适。这本书激励人们反向工程大脑并思考AI编码。
- 神经网络与深度学习 - 覆盖神经网络和深度学习核心概念的经典书籍。
- 深度学习 - MIT出版社书籍 - 书中包含丰富的数学内容,帮助理解实际深度学习原理。
- 其他我读过的书籍 - 部分书籍与深度学习关联较弱,但仍与本清单相关。
文章与帖子
- 雷·库兹韦尔的预测 - 雷·库兹韦尔(Ray Kurzweil)关于中长期未来预测的列表。
- 循环神经网络的惊人有效性 - 必读文章,由安德烈·卡帕蒂(Andrej Karpathy)撰写——正是这篇文章促使我学习循环神经网络(RNN),它展示了RNN在最基础的自然语言处理(NLP)中的应用效果。
- 神经网络、流形与拓扑 - 从新视角探讨神经元如何映射信息。
- 理解长短期记忆网络(LSTM) - 解释LSTM单元的内部工作机制,并在结论部分提供了有趣的链接。
- 注意力机制与增强型循环神经网络 - 通过视觉动画展示注意力机制的入门介绍。
- 使用深度学习在Spotify推荐音乐 - 在音频聚类方面的绝佳案例——由Spotify实习生撰写的文章。
- 发布SyntaxNet:世界上最精确的解析器开源 - Parsey McParseface的诞生,一种神经语法树解析器。
- 改进Inception与TensorFlow中的图像分类 - 非常有趣的卷积神经网络(CNN)架构(例如:Inception风格的卷积层在减少参数数量方面具有高效性)。
- WaveNet:原始音频的生成模型 - 实现逼真语音合成的机器:完美的语音生成。
- 弗朗索瓦·肖莱的推特账号 - Keras作者——拥有有趣的推文和创新性想法。
- Neuralink与大脑的神奇未来 - 关于大脑未来和脑机接口的启发性文章。
- 为开发大型文件的深度学习应用迁移到Git LFS - 轻松管理私有Git项目中的超大文件。
- 深度学习的未来 - 弗朗索瓦·肖莱对深度学习未来的思考。
- 通过决策树发现数据背后的结构 - 构建并可视化决策树,推断数据背后的隐藏逻辑。
- 优化神经网络超参数的Hyperopt教程 - 学习自动优化超参数空间,而非手动调整。
- 估计深度神经网络的最优学习率 - 一种巧妙的技巧,在完整训练之前估计最优学习率。
- 注释版Transformer - 有助于理解《Attention Is All You Need》(AIAYN)论文。
- 图解Transformer - 同样有助于理解《Attention Is All You Need》(AIAYN)论文。
- 通过无监督学习提升语言理解 - 通过大规模语料的无监督预训练,在多个NLP任务中达到SOTA(最先进)水平。
- NLP的ImageNet时刻已到来 - 欢呼NLP的ImageNet时刻。
- 图解BERT、ELMo等(NLP如何攻克迁移学习) - 理解NLP的ImageNet时刻所采用的不同方法。
- Uncle Bob的面向对象设计原则 - 不仅需要SOLID原则来编写干净代码,更进一步的REP、CCP、CRP、ADP、SDP和SAP原则对于开发需要打包成多个独立模块的大型软件至关重要。
- 为什么87%的数据科学项目从未投入生产? - 数据不可忽视,团队与数据科学家之间的沟通对于正确集成解决方案至关重要。
- 机器学习项目失败的真正原因 - 聚焦清晰的业务目标,避免算法迭代除非代码非常整洁,并能够判断何时代码“足够好”。
- 面向机器学习的SOLID原则 - 将SOLID原则应用于机器学习。
实用资源
库和实现
- Neuraxle(机器学习流水线框架) - 用于构建和部署机器学习项目的最佳框架,且兼容大多数框架(例如:Scikit-Learn、TensorFlow、PyTorch、Keras 等)。
- TensorFlow 的 GitHub 仓库 - 最知名的深度学习框架,兼具高层和底层功能,同时保持灵活性。
- skflow - TensorFlow 的 scikit-learn 风格封装。
- Keras - 另一个类似 TensorFlow 的深度学习框架,主要面向高层接口。
- carpedm20 的仓库 - 韩国开发者 Taehoon Kim(carpedm20)实现了许多有趣的神经网络架构。
- carpedm20/NTM-tensorflow - 基于 TensorFlow 的神经图灵机(Neural Turing Machine)实现。
- 懒人深度学习 - 使用预训练 CNN(AlexNet 2012)的高层嵌入进行视觉领域的迁移学习教程。
- LSTM 用于人体活动识别(HAR) - 我关于使用 LSTM 对时间序列进行分类的教程。
- 深度堆叠残差双向 LSTM 用于 HAR - 对前述项目的改进版本。
- 序列到序列(seq2seq)循环神经网络(RNN)用于时间序列预测 - 我关于预测多通道时间序列的教程。
- Hyperopt 优化 Keras CNN 在 CIFAR-100 上的表现 - 在 CIFAR-100 数据集上自动优化神经网络及其架构。
- 我收藏的 ML/DL 仓库 - GitHub 上有许多优秀的代码示例和项目。
- 平滑融合图像块 - 用于 U-Net 语义分割 的图像块平滑合并工具。
- 自治理神经网络(SGNN):投影层 - 使用此方法,无需训练或加载嵌入即可在深度学习模型中使用文本。
- Neuraxle - Neuraxle 是一个用于构建整洁流水线的机器学习(ML)库,提供合适的抽象层次以简化 ML 应用的研究、开发和部署。
- Clean Machine Learning,编码练习 - 通过实践学习良好的机器学习设计模式。
一些数据集
这些是我发现的可用于模型开发的有趣资源。
- UCI 机器学习仓库 - 包含大量机器学习数据集。
- 康奈尔电影对话语料库 - 可用于聊天机器人开发。
- SQuAD 斯坦福问答数据集 - 可在线探索的问答数据集,以及表现优异的模型列表。
- LibriSpeech ASR 语料库 - 高质量的免费英语语音数据集,性别和说话人分布均衡。
- Awesome 公共数据集 - 优质公共数据集合集。
- SentEval:通用句子表示评估工具包 - 用于在多个数据集(NLP 任务)上基准测试句子表示的 Python 框架。
- ParlAI:对话研究软件平台 - 另一个用于在多个数据集(NLP 任务)上基准测试句子表示的 Python 框架。
其他数学理论
梯度下降算法与优化理论
- 神经网络与深度学习,第2章 - 反向传播算法(backpropagation)的工作原理概述
- 神经网络与深度学习,第4章 - 神经网络可以计算任何函数的可视化证明
- 是的,你应该理解反向传播 - 揭示反向传播的注意事项及其在模型训练中的重要性
- 人工神经网络:反向传播的数学原理 - 数学角度解析反向传播
- 深度学习第12讲:循环神经网络与LSTM - 详细解释RNN图展开过程及梯度下降算法的潜在问题
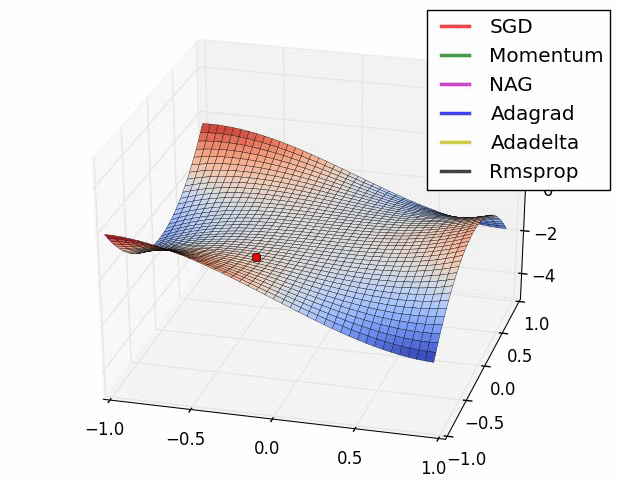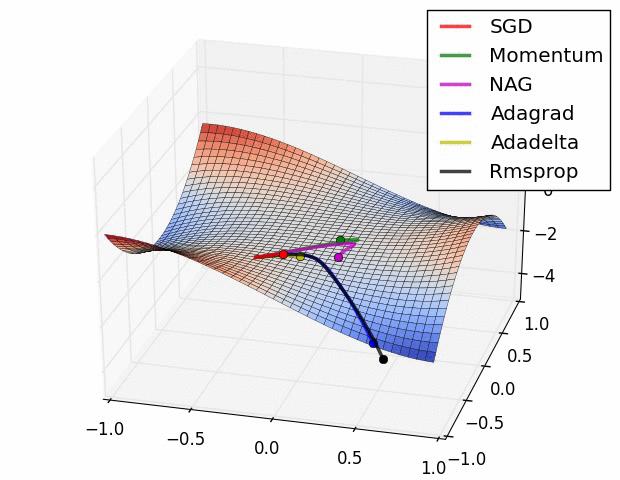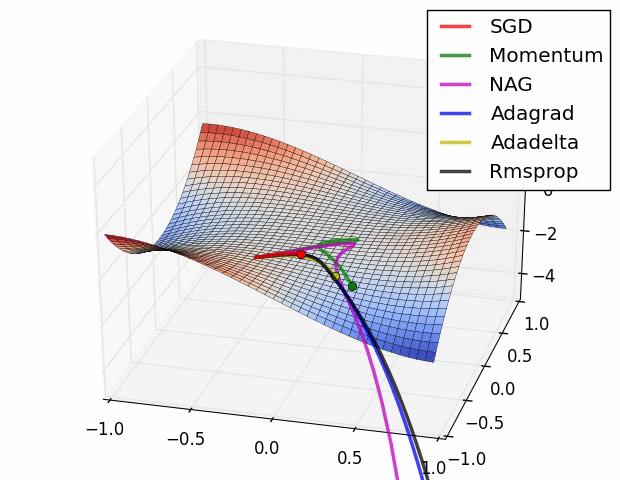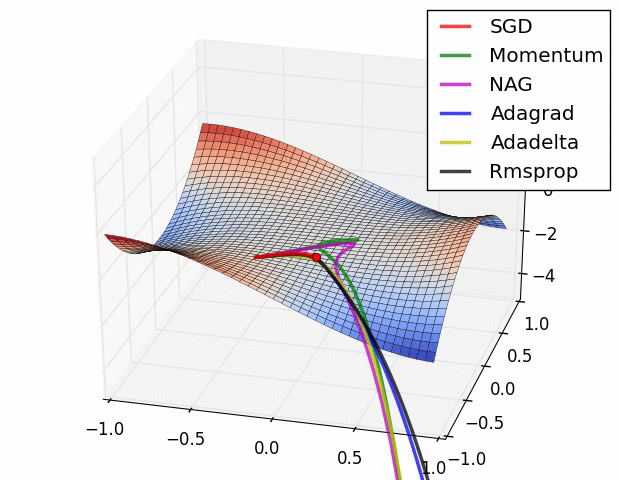
- 鞍点中的梯度下降算法 - 可视化不同优化器在鞍点的表现
- 平坦景观中的梯度下降算法 - 可视化不同优化器在接近平坦景观的表现
- 梯度下降 - 已列出Andrew NG的Coursera课程,但此视频作为梯度下降算法的入门介绍特别相关
- 梯度下降:直观理解 - 前一视频的延伸:添加直观理解
- 实践中的梯度下降2:学习率 - 如何调整神经网络的学习率
- 过拟合问题 - 过拟合现象及其解决方案的详细解释
- 偏差与方差诊断 - 理解神经网络预测中的偏差与方差问题及其解决方案
- 自归一化神经网络 - 引入革命性的SELU激活函数
- 通过梯度下降学习如何通过梯度下降学习 - RNN作为优化器:介绍L2L优化器(元神经网络)
{kind=link}
{kind=link}
复数与数字信号处理
信号处理可能与深度学习无直接关联,但研究它有助于在基于信号设计神经网络架构时获得更深入的直觉。
- 窗口函数 - 维基百科列出的已知窗口函数 - 注意Hann-Poisson窗口对贪婪爬山算法(如梯度下降)特别重要
- MathBox,图形代数与傅里叶分析工具 - 对傅里叶分析的新视角
- 如何折叠朱利亚分形 - 涉及复数和波动方程的动画
- 用动画走向辉煌,数学与物理运动 - 物理引擎中的收敛方法及其在交互设计中的应用
- 用动画走向辉煌 - 第二部分,数学与物理运动 - 使用四元数(处理3D旋转的数学对象)进行旋转和旋转插值的动画
- 信号滤波、STFT绘图与拉普拉斯变换 - 信号处理的Python简单演示
论文
循环神经网络
- 神经网络中的深度学习:概述 - You_Again对深度学习的总结/概述,主要聚焦RNN
- 双向循环神经网络 - 通过时间轴双向扫描提升RNN分类性能
- 使用RNN编码器-解码器进行短语表示学习的统计机器翻译 - 将两个网络组合成seq2seq(序列到序列)编码器-解码器架构。RNN编码器-解码器,1000个隐藏单元。Adadelta优化器
- 神经网络的序列到序列学习 - 4层堆叠的LSTM单元(1000个隐藏层),输入句子反转,并在WMT’14英法数据集上使用波束搜索
- 探索语言建模的极限 - 在字符级CNN基础上使用词级LSTM的递归模型,采用大量GPU资源
- 神经机器翻译与序列到序列模型:教程 - NMT主题的有趣概述,主要阅读第8部分关于带注意力机制的RNN复习
- 通过随机残差学习探索循环神经网络的深度 - 在情感分析案例中,残差连接可能优于堆叠RNN
- 像素循环神经网络 - 类似Photoshop的“内容感知填充”功能,用于图像缺失区域补全
- 循环神经网络的自适应计算时间 - 允许RNN自主决定计算时长。期待其与神经图灵机的结合效果。关于该主题的交互式可视化可在此处找到
卷积神经网络(Convolutional Neural Networks)
- What is the Best Multi-Stage Architecture for Object Recognition? - 局部对比度归一化(local contrast normalization)的出色应用。
- ImageNet Classification with Deep Convolutional Neural Networks - AlexNet,2012 ILSVRC,ReLU激活函数(Rectified Linear Unit)的突破性应用。
- Visualizing and Understanding Convolutional Networks - 引入"去卷积网络层"(deconvnet layer)的概念。
- Fast and Accurate Deep Network Learning by Exponential Linear Units - ELU激活函数(Exponential Linear Unit)在CIFAR视觉任务中的应用。
- Very Deep Convolutional Networks for Large-Scale Image Recognition - 通过堆叠多个3x3卷积+ReLU层实现更大感受野的创新设计,包含"ConvNet配置"的优秀表格。
- Going Deeper with Convolutions - GoogLeNet:引入"Inception"模块,通过并行不同尺寸的卷积层(带"same"填充)在深度维度进行拼接。
- Highway Networks - Highway网络:残差连接(residual connections)的早期探索。
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift - 批归一化(Batch Normalization, BN):通过在批次维度进行归一化,再进行可学习的线性缩放和平移。
- U-Net: Convolutional Networks for Biomedical Image Segmentation - U型网络(U-Net):具有跳跃连接的编码器-解码器结构,适用于像素级图像分割。
- Deep Residual Learning for Image Recognition - 带批归一化的深度残差层(residual layers),即"如何通过过多层来过拟合任何视觉数据集,并在有足够的数据时使任何视觉模型在识别任务中正常工作"。
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning - 通过残差连接改进GoogLeNet。
- WaveNet: a Generative Model for Raw Audio - 基于扩张因果卷积(dilated causal convolutions)的音频生成模型,可生成高质量语音/音乐。
- Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling - 3D-GANs:用于3D模型生成和家具嵌入空间的算术操作(类似word2vec的词向量算术)。
- Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour - 极速分布式CNN训练方法。
- Densely Connected Convolutional Networks - CVPR 2017最佳论文,DenseNet(密集连接卷积网络)在CIFAR-10/100和SVHN数据集上取得SOTA性能。
- The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation - 结合U-Net和DenseNet思想的新型网络,特别适合大规模图像分割任务。
- Prototypical Networks for Few-shot Learning - 通过损失函数中的距离度量实现小样本学习(few-shot learning)。
注意力机制(Attention Mechanisms)
- Neural Machine Translation by Jointly Learning to Align and Translate - LSTM的注意力机制(attention mechanism)!图示和公式解释对我帮助极大。我在这里做过相关演讲。
- Neural Turing Machines - 允许神经网络学习算法并处理长期依赖序列的杰出工作。
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention - 在CNN特征图上使用LSTM注意力机制的神奇效果。
- Teaching Machines to Read and Comprehend - 文本问答领域的创新性突破性研究。
- Effective Approaches to Attention-based Neural Machine Translation - 探索不同注意力机制实现方式。
- Matching Networks for One Shot Learning - 通过注意力机制和查询机制实现低数据量下的单样本学习。
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation - 2016年:带注意力机制的堆叠残差LSTM是神经机器翻译(NMT)的最佳选择。
- Hybrid computing using a neural network with dynamic external memory - 基于NTM的可微分记忆改进,现称为可微分神经计算机(DNC)。
- Massive Exploration of Neural Machine Translation Architectures - 揭示序列到序列框架下NMT有效性的边界。
- Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions - 使用WaveNet作为声码器,结合Tacotron 2 LSTM网络的注意力机制,从文本生成高质量音频。
- Attention Is All You Need (AIAYN) - 引入多头自注意力(multi-head self-attention)和位置编码(positional encoding)的Transformer模型,实现无需RNN/CNN的句子级NLP(必读论文,另见这篇解析和可视化教程)。
其他
- ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections - 在深度神经网络中用词投影(word projections)替代词嵌入(word embeddings),无需预提取词典或存储嵌入矩阵。
- Self-Governing Neural Networks for On-Device Short Text Classification - 本文是对上方ProjectionNet的后续研究。SGNN(自治理神经网络)基于ProjectionNet进一步扩展,详细说明了优化方法(另见我的代码复现尝试以及观看演讲录像)。
- Matching Networks for One Shot Learning - 通过少量示例(无明确类别)对新样本进行分类,每个分类任务数据量少但存在大量相似任务的数据。该方法似乎比孪生网络(Siamese Networks)更优。简而言之:Matching Networks 可直接优化示例间的余弦相似度(类似于自注意力机制的匹配结果),并将结果直接输入softmax。我认为Matching Networks可能可以用于word2vec的CBOW或Skip-gram模型的负采样softmax训练,而无需进行上下文嵌入查找。
YouTube 和 视频
- Attention Mechanisms in Recurrent Neural Networks (RNNs) - IGGG - 关于注意力机制(Paper: Neural Machine Translation by Jointly Learning to Align and Translate)的读书小组讲座。
- Tensor Calculus and the Calculus of Moving Surfaces - 正确理解张量(Tensor)运算的通用方法,仅观看几段视频即可显著提升概念理解。
- Deep Learning & Machine Learning (Advanced topics) - 我整理的深度学习相关视频列表,涵盖各类高级主题。
- Signal Processing Playlist - 我制作的信号处理视频合集,包含DFT/FFT、STFT和拉普拉斯变换等内容(我的软件工程本科课程中几乎没有信号处理内容,除了量子物理课的一小部分)。
- Computer Science - 我制作的另一份计算机科学主题视频合集。
- Siraj's Channel - Siraj 提供的快节奏深度学习趣味教学视频。
- Two Minute Papers' Channel - 对部分研究论文的浅显概述,例如WaveNet或神经风格迁移。
- Geoffrey Hinton interview - Andrew Ng 对Geoffrey Hinton的访谈,后者谈论了他的研究突破并给学生建议。
- Growing Neat Software Architecture from Jupyter Notebooks - 使用Jupyter Notebooks构建机器学习项目的结构指南。
杂项资源与链接
- Hacker News - 可能是我发现机器学习的起点 - 该网站上的有趣趋势通常比主流媒体更早出现。
- DataTau - 类似Hacker News的数据科学专题平台。
- Naver - 韩国搜索引擎 - 建议配合Google翻译使用。令人惊讶的是,有时深度学习搜索结果和高等数学内容在这里比Google搜索更容易找到。
- Arxiv Sanity Preserver - 带TF/IDF功能的arXiv浏览器。
- Awesome Neuraxle - Neuraxle框架的精选资源列表,用于编写生产级机器学习流水线。
授权协议

在法律允许的最大范围内,Guillaume Chevalier 已放弃本作品的所有版权及相关权利。
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。