graph4nlp
Graph4NLP 是一款专为自然语言处理(NLP)与图深度学习(DLG)交叉领域设计的开源库,旨在让用户能轻松构建和应用图神经网络。它有效解决了传统开发中模型复现难、代码复用率低以及从数据构建到模型训练全流程割裂的痛点。
无论是希望快速验证想法的数据科学家,还是需要灵活定制前沿算法的研究人员与开发者,都能从中获益。Graph4NLP 不仅提供了多种最先进(SOTA)模型的完整实现,还支持高度灵活的自定义接口,覆盖从数据处理、图构建、模块组合到最终应用的全流水线需求。
其核心技术亮点在于底层基于高性能的 DGL(Deep Graph Library)运行时库,兼顾了运行效率与扩展性。架构上清晰划分为数据层、模块层、模型层和应用层,并支持静态与动态图的自动化构建。通过统一的参数设计和新增的推理封装函数,Graph4NLP 大幅降低了图神经网络在文本分析任务中的使用门槛,是探索图文结合技术的得力助手。
使用场景
某医疗科技公司的算法团队正致力于构建一个基于电子病历(EMR)的疾病风险预测系统,需要深入挖掘患者、症状与药物之间复杂的非结构化关联。
没有 graph4nlp 时
- 图构建繁琐:开发人员需手动编写大量底层代码,将文本数据转换为图拓扑结构,难以处理动态变化的医疗关系网络。
- 模型复现困难:缺乏现成的图神经网络(GNN)与自然语言处理(NLP)融合模型,复现前沿论文算法需从零搭建,耗时数月。
- 流程割裂严重:数据预处理、图嵌入学习与最终预测任务分散在不同框架中,接口不统一,导致调试和维护成本极高。
- 运行效率低下:未针对图计算进行深度优化,在处理大规模病历数据时训练速度缓慢,难以满足实时性要求。
使用 graph4nlp 后
- 自动化建图:利用其 Data Layer 和更新的
topology_builder,仅需指定graph_name参数即可自动完成从病历文本到静态或动态图的构建。 - 开箱即用模型:直接调用 Model Layer 中预置的 SOTA 模型实现,快速部署疾病预测任务,将研发周期从数月缩短至数周。
- 全链路整合:通过统一的四層架构(数据、模块、模型、应用),实现了从数据输入到推理预测的端到端流水线,大幅降低集成难度。
- 高性能推理:基于高度优化的 DGL 运行时库,显著提升了图嵌入学习和模型训练效率,并支持灵活的
inference_wrapper进行快速验证。
graph4nlp 通过提供标准化的全栈式解决方案,让团队能专注于医疗逻辑创新而非底层工程实现,极大加速了 AI 在复杂文本图谱场景下的落地应用。
运行环境要求
- Linux (Ubuntu 18.04+)
- macOS (仅 CPU 版本)
- Windows 10 (仅支持 PyTorch >= 1.8)
- 非必需(macOS 仅支持 CPU)
- Linux/Windows GPU 用户需 NVIDIA 显卡,测试环境为 2080Ti,CUDA 版本需与已安装的 PyTorch 匹配(示例中为 10.2)
未说明

快速开始


![]()

![]()
![]()



Graph4NLP
Graph4NLP 是一款易于使用的库,专为图深度学习与自然语言处理(即 DLG4NLP)的交叉领域研发而设计。它既提供了面向数据科学家的最新前沿模型的完整实现,又提供了灵活的接口,方便研究人员和开发者构建定制化模型,并提供完整的全流程支持。基于高度优化的运行时库,包括 DGL,Graph4NLP 既拥有卓越的运行效率,又具备强大的扩展性。Graph4NLP 的架构如图所示:虚线框代表正在开发的功能模块。Graph4NLP 由四个不同的层次组成:1)数据层、2)模块层、3)模型层,以及 4)应用层。
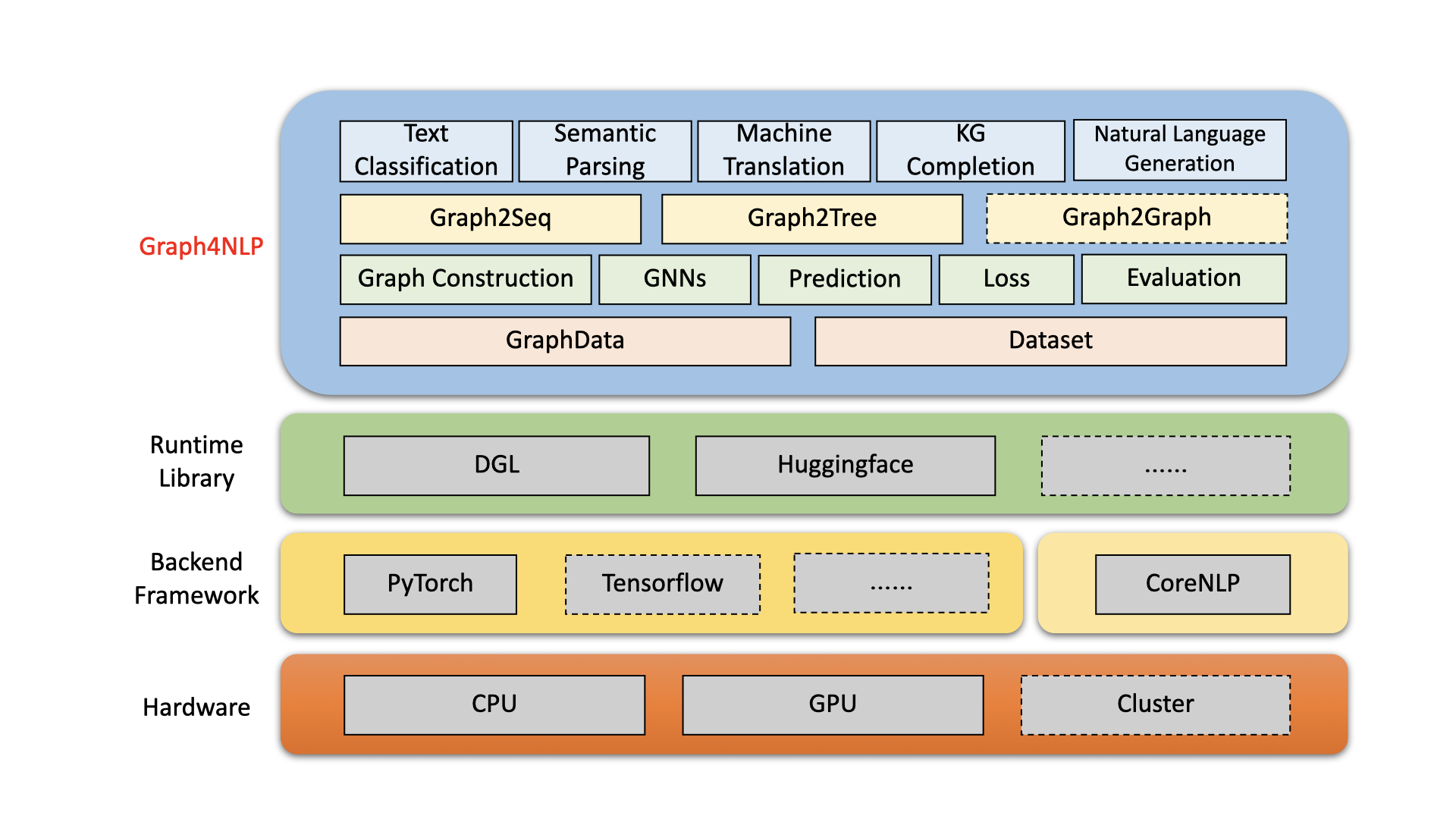
图:Graph4NLP 整体架构
 Graph4NLP 新闻
Graph4NLP 新闻
2022年1月20日: v0.5.5 版本发布!快来试用吧!
2021年9月26日: v0.5.1 版本发布!快来试用吧!
2021年9月1日: 欢迎访问我们的 DLG4NLP 网站(https://dlg4nlp.github.io/index.html),获取丰富的学习资源!
2021年6月5日: v0.4.1 版本发布!
主要版本
| 版本 | 发布日期 | 功能特性 |
|---|---|---|
| v0.5.5 | 2022-01-20 | - 支持 model.predict API,通过引入包装函数实现。 - 新增三个新的推理包装函数:classifier_inference_wrapper、generator_inference_wrapper、generator_inference_wrapper_for_tree。 - 在每个应用中新增推理及推理前处理示例。 - 将图拓扑结构与图嵌入过程分离。 - 对所有图构造函数进行更新。 - 模块化图嵌入被拆分为图嵌入初始化和图嵌入学习。 - 统一了数据集中的参数。我们移除了模棱两可的参数“graph_type”,并引入了“graph_name”,用于标识图构造方法,以及“static_or_dynamic”,用于指示图的静态或动态构造类型。 - 新功能:数据集现在可以通过一个参数“graph_name”自动选择默认方法(例如“topology_builder”)。 |
| v0.5.1 | 2021-09-26 | - 代码 lint 检查 - 支持使用用户自己的数据进行测试 - 修复了一个错误:在 0.4.1 版本中,词嵌入大小被硬编码。现在其值等于“word_emb_size”参数。 - 修复了一个错误:在 0.4.1 版本中,build_vocab() 被调用了两次。 - 修复了一个错误:知识图谱补全示例的两个主文件在恢复模型训练时,遗漏了可选参数“kg_graph”。 - 修复了一个错误:我们已修正了 KGC 阅读指南中预处理路径的错误。 - 修复了一个错误:我们在设置 emb_strategy 为 ‘w2v’ 时,修复了嵌入构造的错误。 |
| v0.4.1 | 2021-06-05 | - 支持 Graph4NLP 的全流程 - GraphData 和 Dataset 支持 |
快速入门
Graph4nlp 致力于让 NLP 任务中的 GNN 使用变得极其简单(请参阅 Graph4NLP 文档)。以下是一个使用 Graph2seq 模型的示例(该模型广泛应用于机器翻译、问答、语义解析以及各种其他 NLP 任务,这些任务均可抽象为图到序列的问题,并且取得了优异的性能)。
此外,我们还提供其他高级模型 API,例如图到树模型。如果您对 DLG4NLP 相关的研究课题感兴趣,欢迎随时使用我们的库,并参考我们的 graph4nlp 调研报告。
from graph4nlp.pytorch.datasets.jobs import JobsDataset
from graph4nlp.pytorch.modules.graph_construction.dependency_graph_construction import DependencyBasedGraphConstruction
from graph4nlp.pytorch.modules.config import get_basic_args
from graph4nlp.pytorch.models.graph2seq import Graph2Seq
from graph4nlp.pytorch.modules.utils.config_utils import update_values, get_yaml_config
# 构建数据集
jobs_dataset = JobsDataset(root_dir='graph4nlp/pytorch/test/dataset/jobs',
topology_builder=DependencyBasedGraphConstruction,
topology_subdir='DependencyGraph') # 您应后台运行斯坦福核心词法分析器
vocab_model = jobs_dataset.vocab_model
# 构建模型
user_args = get_yaml_config("examples/pytorch/semantic_parsing/graph2seq/config/dependency_gcn_bi_sep_demo.yaml")
args = get_basic_args(graph_construction_name="node_emb", graph_embedding_name="gat", decoder_name="stdrnn")
update_values(to_args=args, from_args_list=[user_args])
graph2seq = Graph2Seq.from_args(args, vocab_model)
# 计算
batch_data = JobsDataset.collate_fn(jobs_dataset.train[0:12])
scores = graph2seq(batch_data["graph_data"], batch_data["tgt_seq"]) # [Batch_size, seq_len, Vocab_size]
概述
我们的 Graph4NLP 计算流程如下所示。

Graph4NLP 模型与应用
Graph4NLP 模型
- Graph2Seq:一种通用的端到端神经编码解码模型,可将输入图映射为一串标记序列。
- Graph2Tree:一种通用的端到端神经编码解码模型,可将输入图映射为一棵树结构。
Graph4NLP 应用场景
我们提供了一套全面的 NLP 应用方案,并附有详细的示例:
- 文本分类:为句子或文档赋予恰当的标签。
- 语义解析:将自然语言转换为机器可理解的正式语义表示。
- 神经机器翻译:将源语言中的句子翻译成目标语言。
- 摘要生成:自动生成输入文本的简短版本,同时保留其主要含义。
- 知识图谱补全:预测已知知识图谱中两个现有实体之间的缺失关系。
- 数学应用题求解:以通俗易懂的语言,自动解答提供问题背景信息的数学练习题。
- 人名实体识别:对输入文本中的实体进行标注,并为其指定相应的类型。
- 问题生成:根据给定的文段和目标答案(可选),生成有效且流畅的问题。
性能表现
环境:PyTorch 1.8,Ubuntu 16.04,配备 2080Ti GPU
| 任务 | 数据集 | GNN 模型 | 图结构构建 | 评估指标 | 性能表现 |
|---|---|---|---|---|---|
| 文本分类 | TRECT CAirline CNSST |
GAT | 依赖关系 构成关系 依赖关系 |
准确率 | 0.948 0.785 0.538 |
| 语义解析 | JOBS | SAGE | 构成关系 | 执行准确率 | 0.936 |
| 问题生成 | SQuAD | GGNN | 依赖关系 | BLEU-4 | 0.15175 |
| 机器翻译 | IWSLT14 | GCN | 动态调整 | BLEU-4 | 0.3212 |
| 摘要生成 | CNN(30k) | GCN | 依赖关系 | ROUGE-1 | 26.4 |
| 知识图谱补全 | Kinship | GCN | 依赖关系 | MRR | 82.4 |
| 数学应用题求解 | MAWPS | SAGE | 动态调整 | 解决准确率 | 76.4 |
安装方法
目前,用户可通过 pip 或 源代码 安装 Graph4NLP。Graph4NLP 支持以下操作系统:
- 基于 Linux 的系统(已在 Ubuntu 18.04 及更高版本上测试)
- macOS(仅支持 CPU 版本)
- Windows 10(仅支持 PyTorch >= 1.8)
使用 pip 安装(二进制包)
我们为所有主流操作系统、PyTorch 和 CUDA 组合提供了 pip 轮子文件。请注意,我们强烈建议 Windows 用户参考“通过源代码安装”方式,以确保兼容性。
确保已安装至少 PyTorch (>=1.6.0):
注意,>=1.6.0 即可。
$ python -c "import torch; print(torch.__version__)"
>>> 1.6.0
查找 PyTorch 的 CUDA 版本(适用于 GPU 用户):
$ python -c "import torch; print(torch.version.cuda)"
>>> 10.2
安装相关依赖项:
Graph4NLP 依赖 torchtext 来实现嵌入式功能。在安装 torchtext 之前,请务必仔细查看 PyTorch 的依赖要求!如需详细版本匹配,请参阅 这里。
pip install torchtext # >=0.7.0
安装 Graph4NLP
pip install graph4nlp${CUDA}
其中 ${CUDA} 应替换为具体的 CUDA 版本(none(CPU 版本)、"-cu92"、"-cu101"、"-cu102"、"-cu110")。下表列出了具体的命令行操作。对于 CUDA 11.1 用户,请参考“通过源代码安装”。
| 平台 | 命令 |
|---|---|
| CPU | pip install graph4nlp |
| CUDA 9.2 | pip install graph4nlp-cu92 |
| CUDA 10.1 | pip install graph4nlp-cu101 |
| CUDA 10.2 | pip install graph4nlp-cu102 |
| CUDA 11.0 | pip install graph4nlp-cu110 |
通过源代码安装
确保已安装至少 PyTorch (>=1.6.0):
注意,>=1.6.0 即可。
$ python -c "import torch; print(torch.__version__)"
>>> 1.6.0
查找 PyTorch 的 CUDA 版本(适用于 GPU 用户):
$ python -c "import torch; print(torch.version.cuda)"
>>> 10.2
安装相关依赖项:
Graph4NLP 依赖 torchtext 来实现嵌入式功能。在安装 torchtext 之前,请务必仔细查看 PyTorch 的依赖要求!如需详细版本匹配,请参阅 这里。
pip install torchtext # >=0.7.0
从 GitHub 下载 Graph4NLP 的源代码:
git clone https://github.com/graph4ai/graph4nlp.git
cd graph4nlp
配置 CUDA 版本
随后运行 ./configure(如果使用 Windows 10,则运行 ./configure.bat)以完成安装配置。配置工具会提示您指定 CUDA 版本。如果您没有 GPU,请输入 cpu。
./configure
安装相关软件包:
最后,安装该软件包:
python setup.py install
用于超参数调优
我们展示了常被调优的一些超参数 此处。
初学者如何学习基于图的深度学习在自然语言处理中的应用?
如果您想深入了解如何将图神经网络技术应用于自然语言处理任务,欢迎访问我们的 DLG4NLP 网站(https://dlg4nlp.github.io/index.html),这里提供丰富的学习资源!您还可以参考我们的调查论文,该论文对这一现有研究方向进行了全面概述。如需查阅我们库中更详尽的参考资料,请参阅我们的文档。
- 文档:文档
- Graph4NLP 调查:Graph4NLP 调查
- Graph4NLP 教程:
- Graph4NLP-NAACL'21、SIGIR'21、IJCAI'21、KDD'21
- SyncedReview 邀请的中文演讲 (视频(密码:wppp),幻灯片(密码:flwv))
- Graph4NLP 研讨会:
- Graph4NLP 演示:演示
- Graph4NLP 文献综述:文献列表
贡献
如果您发现错误或有任何建议,请通过提交问题报告告知我们。 我们欢迎从修复错误到开发新功能和扩展的所有贡献。 我们期望所有贡献都能在问题跟踪器中进行讨论,并通过 PR 进行提交。
引用
如果您觉得这段代码很有用,请考虑引用以下论文。
- [1] 吴凌飞、陈宇、沈凯、郭晓杰、高汉宁、李树成、裴健和龙波。【“面向自然语言处理的图神经网络:综述”】(https://arxiv.org/abs/2106.06090)。
- [2] 【NeurIPS 2020】陈宇、吴凌飞和穆罕默德·J·扎基,【“用于图神经网络的迭代深度图学习:更优且更鲁棒的节点嵌入”】(https://arxiv.org/abs/2006.13009)。
- [3] 【ICLR 2020】陈宇、吴凌飞和穆罕默德·J·扎基,【“基于强化学习的图到序列模型用于自然问题生成”】(https://arxiv.org/abs/1908.04942)。
- [4] 许坤、吴凌飞、王志国、冯彦松、迈克尔·维特布罗克和瓦迪姆·谢宁,【“Graph2Seq:利用注意力机制的神经网络实现图到序列的学习”】(https://arxiv.org/abs/1804.00823)。
- [5] 【EMNLP 2020】李树成、吴凌飞、冯世伟、徐芳丽、徐凤元和盛中,【“用于结构化输入输出翻译的学习的图到树神经网络——兼及语义解析与数学应用题的案例研究”】(https://aclanthology.org/2020.findings-emnlp.255.pdf)。
- [6] 【ACL 2020】黄路阳、吴凌飞和王璐,【“基于语义驱动的填空奖励的知识图增强摘要生成”】(https://arxiv.org/abs/2005.01159)。
- [7] 【EMNLP 2018】吴凌飞、伊恩·E·H·严、许坤、徐芳丽、阿维纳什·巴拉克里希南、陈品玉、普拉迪普·拉维库马尔和迈克尔·J·维特布罗克,【“词迁移嵌入:从 Word2Vec 到文档嵌入”】(https://arxiv.org/abs/1811.01713)。
- [8] 【IJCAI 2020】陈宇、吴凌飞和穆罕默德·J·扎基,【“GraphFlow:利用图神经网络挖掘对话流,实现对话式机器理解”】(https://www.ijcai.org/Proceedings/2020/171)。
- [9] 【IJCAI 2020】沈凯、吴凌飞、徐芳丽、唐思亮、肖俊和庄月婷,【“基于层次注意力的空间-时间图到序列学习用于落地视频描述”】(https://www.ijcai.org/Proceedings/2020/171)。
- [10] 【IJCAI 2020】高汉宁、吴凌飞、胡博和徐芳丽,【“利用图增强的结构化神经编码器进行 RDF 到文本生成”】(https://www.ijcai.org/Proceedings/2020/419)。
@article{wu2021graph,
title={面向自然语言处理的图神经网络:综述},
author={吴凌飞、陈宇、沈凯、郭晓杰、高汉宁、李树成、裴健和龙波},
journal={arXiv预印本 arXiv:2106.06090},
year={2021}
}
@inproceedings{chen2020iterative,
title={用于图神经网络的迭代深度图学习:更优且更鲁棒的节点嵌入},
author={陈宇、吴凌飞和扎基,穆罕默德·J.},
booktitle={第34届神经信息处理系统会议论文集},
month={12月6日至12日},
year={2020}
}
@inproceedings{chen2020reinforcement,
author = {陈宇、吴凌飞和扎基,穆罕默德·J.},
title = {基于强化学习的图到序列模型用于自然问题生成},
booktitle = {第8届国际表示学习会议论文集},
month = {4月26日至30日},
year = {2020}
}
@article{xu2018graph2seq,
title={Graph2seq:利用注意力机制的神经网络实现图到序列的学习},
author={许坤、吴凌飞、王志国、冯彦松、维特布罗克,迈克尔和谢宁,瓦迪姆},
journal={arXiv预印本 arXiv:1804.00823},
year={2018}
}
@inproceedings{li-etal-2020-graph-tree,
title = {用于结构化输入输出翻译的学习的图到树神经网络——兼及语义解析与数学应用题的案例研究},
author = {李树成、吴凌飞、冯世伟、徐芳丽、徐凤元和盛中},
booktitle = {Association for Computational Linguistics:EMNLP 2020会议论文集},
month = {11月},
year = {2020}
}
@inproceedings{huang-etal-2020-knowledge,
title = {基于语义驱动的填空奖励的知识图增强摘要生成},
author = {黄路阳、吴凌飞和王璐},
booktitle = {第58届计算语言学协会年会论文集},
month = {7月},
year = {2020},
pages = {5094–5107}
}
@inproceedings{wu-etal-2018-word,
title = {词迁移嵌入:从 Word2Vec 到文档嵌入},
author = {吴凌飞、严伊恩·恩秀、许坤、徐芳丽、巴拉克里希南、陈品玉、拉维库马尔和维特布罗克,迈克尔·J.},
booktitle = {2018年自然语言处理实证方法大会论文集},
pages = {4524–4534},
year = {2018}
}
@inproceedings{chen2020graphflow,
author = {陈宇、吴凌飞和穆罕默德·J·扎基},
title = {GraphFlow:利用图神经网络挖掘对话流,实现对话式机器理解},
booktitle = {第29届国际联合人工智能会议论文集,IJCAI 2020},
publisher = {国际联合人工智能组织},
pages = {1230–1236},
year = {2020}
}
@inproceedings{shen2020hierarchical,
title={基于层次注意力的空间-时间图到序列学习用于落地视频描述},
author={沈凯、吴凌飞、徐芳丽、唐思亮、肖俊和庄月婷},
booktitle = {第29届国际联合人工智能会议,IJCAI 2020},
publisher = {国际联合人工智能组织},
pages = {941–947},
year = {2020}
}
@inproceedings{ijcai2020-419,
title = {利用图增强的结构化神经编码器进行 RDF 到文本生成},
author = {高汉宁、吴凌飞、胡博和徐芳丽},
booktitle = {第29届国际联合人工智能会议,IJCAI-20},
publisher = {国际联合人工智能组织},
pages = {3030–3036},
year = {2020}
}
团队
Graph4AI 团队:【吴凌飞】(团队负责人)、陈宇、沈凯、郭晓杰、高汉宁、李树成、王赛卓、刘晓以及胡静。我们热衷于开发实用的开源库,旨在推动自然语言处理领域中各类图神经网络技术的易用性。我们的团队由来自不同行业和学术界的科研人员、应用数据科学家以及研究生组成,其中包括 Pinterest 的吴凌飞、浙江大学的沈凯、Facebook AI 的陈宇、IBM T.J. 沃森研究中心的郭晓杰、同济大学的高汉宁、南京大学的李树成以及香港科技大学的王赛卓。
联系方式
如果您有任何技术问题,请提交新问题。
如您有其他疑问,请联系以下人员:【吴凌飞】(https://sites.google.com/a/email.wm.edu/teddy-lfwu/home)【**lwu@email.wm.edu**】,以及郭晓杰【**xiaojie.guo@jd.com**】。
许可证
Graph4NLP 采用 Apache 许可证 2.0 版本。
版本历史
v0.5.52022/01/20v0.5.1-alpha2021/09/30v0.4.1-alpha2021/06/15常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。