xtreme
XTREME 是一个专为评估预训练多语言模型跨语言泛化能力而设计的大规模基准测试平台。它旨在解决当前人工智能在处理非英语语种,尤其是低资源语言时表现不佳的难题,帮助开发者验证模型是否能将从一种语言学到的知识有效迁移到其他语言中。
该平台涵盖了 40 种类型学差异巨大的语言,涉及 12 个语系,其中包括泰米尔语、斯瓦希里语等以往常被忽视的语言。XTREME 包含了句子分类、结构化预测、句子检索和问答等九项核心任务,要求模型在不同语法和语义层级上进行综合推理。其独特的技术亮点在于采用“零样本跨语言”评估设定,即模型仅在英语数据上训练,直接在其他语言测试集上进行评测,从而真实反映模型的泛化潜力。
XTREME 非常适合自然语言处理领域的研究人员和算法工程师使用。通过提供标准化的数据集下载脚本、基线系统代码以及详细的排行榜提交指南,它为多语言模型的对比研究和性能优化提供了权威依据,是推动全球语言平等和技术普惠的重要基础设施。
使用场景
某跨国科技公司的算法团队正在研发一款支持全球市场的多语言情感分析模型,急需验证其在低资源语种上的泛化能力。
没有 xtreme 时
- 评估维度单一:团队只能依赖常见的英语或少数主流语言数据集进行测试,无法得知模型在斯瓦希里语、泰米尔语等 40 种类型学多样语言上的真实表现。
- 零样本迁移效果未知:缺乏统一的零样本跨语言评估标准,难以判断模型是否真正学会了跨语言推理,还是仅仅过拟合了训练数据。
- 基线对比困难:由于缺少涵盖句法、语义等多层级任务的标准化基准,团队无法与业界最先进模型进行公平、全面的性能对标。
- 数据准备繁琐:自行收集并清洗覆盖 12 个语系的多语言测试数据耗时耗力,且难以保证数据质量和任务多样性。
使用 xtreme 后
- 全景式能力画像:利用 xtreme 覆盖的 40 种语言和 9 项任务,团队迅速定位到模型在尼日尔 - 刚果语系等低资源语言上的薄弱环节。
- 量化泛化增益:通过标准的零样本跨语言设置,清晰验证了预训练模型在未见过语言上的迁移效果,证明了架构的鲁棒性。
- 精准对标前沿:直接复用 xtreme 提供的基线系统和排行榜机制,快速确认当前模型在全球范围内的竞争力排名。
- 开箱即用数据:一键下载包含句子分类、问答、检索等多种范式的高质量数据集,将原本数周的数据准备工作缩短至几小时。
xtreme 通过提供大规模、多样化的标准化基准,帮助开发者从“盲目猜测”转向“数据驱动”,显著提升了多语言模型的研发效率与可靠性。
运行环境要求
- 未说明
未说明
未说明

快速开始
XTREME:用于评估跨语言泛化能力的大规模多语言多任务基准
任务 | 下载 | 基线系统 | 排行榜 | 官网 | 论文 | 译文
本仓库包含关于XTREME的介绍、数据下载代码以及该基准测试中基线系统的实现。
简介
跨语言迁移多语言编码器评测(XTREME)基准是一个用于评估预训练多语言模型跨语言泛化能力的基准。它涵盖了40种类型学上多样化的语言(横跨12个语系),并包括九项任务,这些任务综合起来需要对不同层次的句法和语义进行推理。XTREME中的语言选择旨在最大化语言多样性、现有任务的覆盖范围以及训练数据的可获得性。其中包含许多研究较少的语言,例如达罗毗荼语系的泰米尔语(主要在印度南部、斯里兰卡和新加坡使用)、泰卢固语和马拉雅拉姆语(主要在印度南部使用),以及尼日尔-刚果语系的斯瓦希里语和约鲁巴语,它们广泛分布于非洲。
有关该基准的完整描述,请参阅论文。
任务与语言
XTREME包含的任务覆盖了自然语言处理领域的一系列标准范式,包括句子分类、结构化预测、句子检索和问答。完整的任务列表见下图。
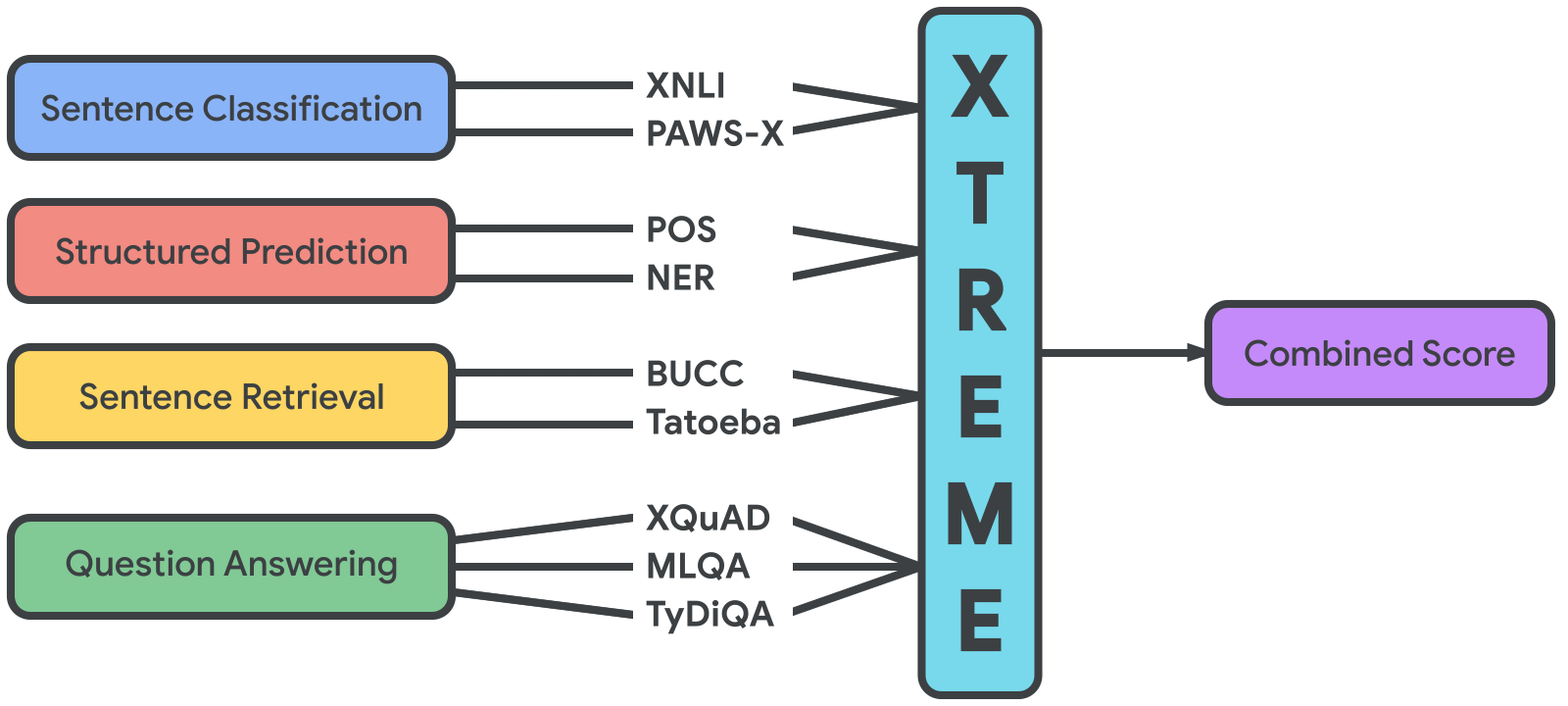
为了在XTREME基准上取得成功,模型必须学习能够在多种任务和语言之间泛化的表示。每项任务都涵盖XTREME中所包含的40种语言中的部分子集(以下为其ISO 639-1代码):af, ar, bg, bn, de, el, en, es, et, eu, fa, fi, fr, he, hi, hu, id, it, ja, jv, ka, kk, ko, ml, mr, ms, my, nl, pt, ru, sw, ta, te, th, tl, tr, ur, vi, yo, 和 zh。这些语言是从拥有最多维基百科文章的前100种语言中选出的,以最大限度地提高语言多样性、任务覆盖范围以及训练数据的可用性。它们包括非洲-亚欧语系、南亚语系、南岛语系、达罗毗荼语系、印欧语系、日本语系、高加索语系、壮侗语系、尼日尔-刚果语系、汉藏语系、突厥语系和乌拉尔语系的成员,以及两种孤立语言——巴斯克语和韩语。
下载数据
要在XTREME上运行实验,第一步是下载依赖项。我们假设您已安装anaconda,并且使用Python 3.7及以上版本。其他所需包包括transformers、seqeval(用于序列标注评估)、tensorboardx、jieba、kytea和pythainlp(用于中文、日语和泰语的文本分词),以及sacremoses,可通过运行以下脚本进行安装:
bash install_tools.sh
下一步是下载数据。为此,首先在本项目的根目录下创建一个download文件夹,命令为mkdir -p download。然后,您需要手动从这里下载panx_dataset(用于NER),并将其保存到download目录中(请注意,它会以AmazonPhotos.zip的形式下载)。最后,运行以下命令下载其余数据集:
bash scripts/download_data.sh
需要注意的是,为了避免在实验过程中意外对测试集进行评估,我们在预处理阶段会移除测试数据的标签,并改变跨语言句子检索任务中测试句子的顺序。
构建基线系统
XTREME中的评估设置是零样本跨语言迁移,即从英语迁移到其他语言。我们会在每项XTREME任务的英语标注数据上微调那些已在多语言数据上预训练过的模型。随后,将每个微调后的模型应用于同一任务在其他语言上的测试数据,以获得预测结果。
对于每一项任务,我们都提供了一个脚本scripts/train.sh,用于微调在Transformers库中实现的预训练模型。若要微调不同的模型,只需在脚本中传递相应的MODEL参数即可。目前支持的模型有bert-base-multilingual-cased、xlm-mlm-100-1280和xlm-roberta-large。
泛用依存关系词性标注
对于词性标注任务,我们使用泛用依存关系树库v2.5的数据。您可以通过以下命令在英语词性标注数据上微调预训练的多语言模型:
bash scripts/train.sh [MODEL] udpos
Wikiann命名实体识别
对于命名实体识别(NER)任务,我们使用Wikiann(panx)数据集。您可以通过以下命令在英语NER数据上微调预训练的多语言模型:
bash scripts/train.sh [MODEL] panx
PAXS-X句子分类
对于句子分类任务,我们使用跨语言释义对抗词汇打乱(PAWS-X)数据集。您可以通过以下命令在英语PAWS数据上微调预训练的多语言模型:
bash scripts/train.sh [MODEL] pawsx
XNLI句子分类
第二个句子分类数据集是跨语言自然语言推理(XNLI)数据集。您可以通过以下命令在英语MNLI数据上微调预训练的多语言模型:
bash scripts/train.sh [MODEL] xnli
XQuAD、MLQA、TyDiQA-GoldP问答
对于问答任务,我们使用XQuAD、MLQA和TyDiQA-Gold Passage数据集。对于XQuAD和MLQA,模型应在英语SQuAD训练集上进行训练。而对于TyDiQA-Gold Passage,则需在英语TyDiQA-GoldP训练集上训练模型。您可以先使用以下命令在相应的英语训练数据上微调预训练的多语言模型,然后再对所有任务的测试数据进行预测:
bash scripts/train.sh [MODEL] [xquad,mlqa,tydiqa]
BUCC句子检索
对于跨语言句子检索任务,我们使用构建与使用平行语料库(BUCC)共享任务的数据。由于这些模型并未针对此任务进行训练,而是直接利用预训练模型的表示来计算相似度判断,因此您可以直接应用模型对任务的测试数据进行预测:
bash scripts/train.sh [MODEL] bucc2018
Tatoeba 句子检索
我们使用的第二个跨语言句子检索数据集是 Tatoeba 数据集。与 BUCC 类似,您可以直接应用模型来获得该任务测试数据的预测结果:
bash scripts/train.sh [MODEL] tatoeba
榜单提交
提交
要将您的预测提交至 XTREME,请创建一个包含 9 个子文件夹的主文件夹,这些子文件夹分别以所有任务的名称命名,即 udpos、panx、xnli、pawsx、xquad、mlqa、tydiqa、bucc2018 和 tatoeba。在每个子文件夹中,创建一个文件,其中包含针对所有语言的测试集的预测标签。文件名应采用 test-{language}.{extension} 的格式,其中 language 表示双字符语言代码,而 extension 对于 QA 任务为 json,对于其他任务则为 tsv。您可以在 mock_test_data/predictions 中查看文件夹结构的示例。
评估
我们将使用以下命令将您的提交与我们的标签文件进行比较:
python evaluate.py --prediction_folder [path] --label_folder [path]
翻译
作为训练 translate-train 和 translate-test 基线的一部分,我们已自动将英语训练集翻译成其他语言,并将测试集翻译成英语。翻译适用于以下数据集:SQuAD v1.1(仅训练集和验证集)、MLQA、PAWS-X、TyDiQA-GoldP、XNLI 和 XQuAD。
对于 PAWS-X 和 XNLI,翻译的格式如下:
第 1 列和第 2 列:原始句对
第 3 列和第 4 列:翻译后的句对
第 5 列:标签
这将有助于建立原始数据与其翻译之间的对应关系。
对于 XNLI 和 XQuAD,我们进一步通过将英语测试集自动翻译成 XTREME 中的其余语言,创建了伪测试集,从而使得所有 40 种语言的测试数据都可用。请注意,这些翻译存在噪声,不应被视为真实标签。
所有翻译均可在此处获取:这里。
论文
如果您使用我们的基准或本仓库中的代码,请引用我们的论文 \cite{hu2020xtreme}。
@article{hu2020xtreme,
author = {Junjie Hu and Sebastian Ruder and Aditya Siddhant and Graham Neubig and Orhan Firat and Melvin Johnson},
title = {XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization},
journal = {CoRR},
volume = {abs/2003.11080},
year = {2020},
archivePrefix = {arXiv},
eprint = {2003.11080}
}
请考虑在您的论文中加入类似下面的说明,以确保引用所有单独的数据集。
我们在 XTREME 基准上进行了实验 \cite{hu2020xtreme},这是一个用于多语言学习的综合基准,由来自 XNLI \cite{Conneau2018xnli}、PAWS-X \cite{Yang2019paws-x}、UD-POS \cite{nivre2018universal}、Wikiann NER \cite{Pan2017}、XQuAD \cite{artetxe2020cross}、MLQA \cite{Lewis2020mlqa}、TyDiQA-GoldP \cite{Clark2020tydiqa}、BUCC 2018 \cite{zweigenbaum2018overview} 和 Tatoeba \cite{Artetxe2019massively} 等任务的数据组成。我们提供它们的 BibTex 信息如下。
@inproceedings{Conneau2018xnli,
title = "{XNLI}: Evaluating Cross-lingual Sentence Representations",
author = "Conneau, Alexis and
Rinott, Ruty and
Lample, Guillaume and
Williams, Adina and
Bowman, Samuel and
Schwenk, Holger and
Stoyanov, Veselin",
booktitle = "Proceedings of EMNLP 2018",
year = "2018",
pages = "2475--2485",
}
@inproceedings{Yang2019paws-x,
title = "{PAWS-X}: A Cross-lingual Adversarial Dataset for Paraphrase Identification",
author = "Yang, Yinfei and
Zhang, Yuan and
Tar, Chris and
Baldridge, Jason",
booktitle = "Proceedings of EMNLP 2019",
year = "2019",
pages = "3685--3690",
}
@article{nivre2018universal,
title={Universal Dependencies 2.2},
author={Nivre, Joakim and Abrams, Mitchell and Agi{\'c}, {\v{Z}}eljko and Ahrenberg, Lars and Antonsen, Lene and Aranzabe, Maria Jesus and Arutie, Gashaw and Asahara, Masayuki and Ateyah, Luma and Attia, Mohammed and others},
year={2018}
}
@inproceedings{Pan2017,
author = {Pan, Xiaoman and Zhang, Boliang and May, Jonathan and Nothman, Joel and Knight, Kevin and Ji, Heng},
booktitle = {Proceedings of ACL 2017},
pages = {1946--1958},
title = {{Cross-lingual name tagging and linking for 282 languages}},
year = {2017}
}
@inproceedings{artetxe2020cross,
author = {Artetxe, Mikel and Ruder, Sebastian and Yogatama, Dani},
booktitle = {Proceedings of ACL 2020},
title = {{On the Cross-lingual Transferability of Monolingual Representations}},
year = {2020}
}
@inproceedings{Lewis2020mlqa,
author = {Lewis, Patrick and Oğuz, Barlas and Rinott, Ruty and Riedel, Sebastian and Schwenk, Holger},
booktitle = {Proceedings of ACL 2020},
title = {{MLQA: Evaluating Cross-lingual Extractive Question Answering}},
year = {2020}
}
@inproceedings{Clark2020tydiqa,
author = {Jonathan H. Clark and Eunsol Choi and Michael Collins and Dan Garrette and Tom Kwiatkowski and Vitaly Nikolaev and Jennimaria Palomaki},
booktitle = {Transactions of the Association of Computational Linguistics},
title = {{TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages}},
year = {2020}
}
@inproceedings{zweigenbaum2018overview,
title={Overview of the third BUCC shared task: Spotting parallel sentences in comparable corpora},
author={Zweigenbaum, Pierre and Sharoff, Serge and Rapp, Reinhard},
booktitle={Proceedings of 11th Workshop on Building and Using Comparable Corpora},
pages={39--42},
year={2018}
}
@article{Artetxe2019massively,
author = {Artetxe, Mikel and Schwenk, Holger},
journal = {Transactions of the ACL 2019},
title = {{Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond}},
year = {2019}
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。