laravel
Laravel 开发者可以借助 Gemini PHP for Laravel 轻松集成 Google 的 Gemini AI 能力。这是一个由社区维护的 PHP 客户端,专为 Laravel 框架设计,让你在应用中调用 Gemini API 实现文本生成、多模态输入(如图文、视频)、对话聊天、函数调用、内容嵌入等多种 AI 功能。
它解决了 Laravel 项目中接入大模型 API 的复杂性问题,通过简洁的配置和丰富的功能封装,省去了手动处理 HTTP 请求、数据格式和流式响应的麻烦。只需一条 Composer 命令安装,并配置 API 密钥,即可快速启用 Gemini 的各项能力。
该工具主要面向使用 Laravel 框架的 PHP 开发者,尤其适合希望在 Web 应用中集成 AI 功能(如智能客服、内容生成、图像理解等)的后端工程师或全栈开发者。普通用户或非技术角色通常不直接使用。
值得一提的是,它支持 Gemini 的高级特性,如结构化输出、Google 搜索增强(Grounding)、语音生成、缓存内容管理以及流式响应,同时兼容 Laravel 的配置习惯和环境变量机制,兼顾灵活性与易用性。
使用场景
一家电商 SaaS 平台的技术团队正在为商家后台开发一个“智能商品描述生成”功能,允许用户上传商品图片后,自动生成符合 SEO 规范的多语言文案。
没有 laravel 时
- 需手动封装 HTTP 请求调用 Gemini API,处理认证、重试、超时等逻辑,代码冗余且易出错
- 无法直接在 Laravel 项目中使用熟悉的 Facade 或依赖注入方式调用 AI 能力,集成成本高
- 处理图文混合输入(如上传商品图+文字提示)需自行实现文件上传、URI 构造和上下文管理
- 缺乏对流式响应、结构化输出等高级功能的封装,难以满足实时预览或格式化输出需求
- 每次升级 API 版本或调整配置都要修改底层调用逻辑,维护负担重
使用 laravel 后
- 通过
Gemini::chat()->textAndImage()一行代码即可完成图文联合推理,自动处理文件上传与上下文绑定 - 直接使用 Laravel 风格的链式调用和配置系统,API 密钥、超时等参数通过
.env统一管理 - 内置对流式生成、结构化 JSON 输出、函数调用等高级特性的支持,轻松实现“边生成边展示”效果
- 借助
php artisan gemini:install快速初始化配置,升级版本只需更新 Composer 包,无需重写集成代码 - 与 Laravel 的异常处理、日志系统无缝衔接,调试和监控更高效
laravel 让 Laravel 开发者以原生方式高效、安全地调用 Gemini AI 能力,大幅降低 AI 功能落地门槛。
运行环境要求
- 未说明
未说明
未说明

快速开始


Laravel 的 Gemini PHP 是一个社区维护的 PHP API 客户端,允许你与 Gemini AI API 进行交互。
- Fatih AYDIN github.com/aydinfatih
- Vytautas Smilingis github.com/Plytas
更多信息请查看 google-gemini-php/client 仓库。
目录
- 先决条件
- 设置
- 使用方法
- 故障排除
- 测试
先决条件
要完成本快速入门,请确保你的开发环境满足以下要求:
- 需要 PHP 8.1+
- 需要 Laravel 9,10,11,12
设置
安装
首先,通过 Composer 包管理器安装 Gemini:
composer require google-gemini-php/laravel
接下来,执行安装命令:
php artisan gemini:install
这将在你的项目中创建一个 config/gemini.php 配置文件,你可以使用环境变量根据需要进行修改。.env 文件中已经自动添加了空白的 Gemini API 密钥环境变量。
GEMINI_API_KEY=
你也可以定义以下环境变量。
GEMINI_BASE_URL=
GEMINI_REQUEST_TIMEOUT=
设置你的 API 密钥
要使用 Gemini API,你需要一个 API 密钥。如果你还没有密钥,请在 Google AI Studio 中创建一个。
升级到 2.0
从 2.0 版本开始,此包仅支持 Gemini v1beta API(参见 API 版本)。
要更新,请运行以下命令:
composer require google-gemini-php/laravel:^2.0
此版本引入了对以下新功能的支持:
- 结构化输出(Structured output)
- 系统指令(System instructions)
- 文件上传(File uploads)
- 函数调用(Function calling)
- 代码执行(Code execution)
- 使用 Google 搜索进行事实核查(Grounding with Google Search)
- 缓存内容(Cached content)
- 思考模式配置(Thinking model configuration)
- 语音模式配置(Speech model configuration)
\Gemini\Enums\ModelType 枚举已被弃用,并将在下一个主要版本中移除。同时,Gemini::geminiPro() 和 Gemini::geminiFlash() 方法也已被移除。
我们建议使用 Gemini::generativeModel() 方法并直接传入模型字符串。所有之前接受 ModelType 枚举的方法现在都接受 BackedEnum。我们建议你为方便起见实现自己的枚举。
此处可能未列出其他破坏性变更。如果你遇到任何问题,请提交 issue 或 pull request。
使用方法
与 Gemini API 交互:
use Gemini\Enums\ModelVariation;
use Gemini\GeminiHelper;
use Gemini\Laravel\Facades\Gemini;
$result = Gemini::generativeModel(model: 'gemini-2.0-flash')->generateContent('Hello');
$result->text(); // Hello! How can I assist you today?
// 辅助方法用法
$result = Gemini::generativeModel(
model: GeminiHelper::generateGeminiModel(
variation: ModelVariation::FLASH,
generation: 2.5,
version: "preview-04-17"
), // models/gemini-2.5-flash-preview-04-17
)->generateContent('Hello');
$result->text(); // Hello! How can I assist you today?
聊天资源(Chat Resource)
有关 Gemini API v1 支持的完整输入格式和方法列表,请参阅 模型文档。
纯文本输入
根据输入消息从模型生成响应。
use Gemini\Laravel\Facades\Gemini;
$result = Gemini::generativeModel(model: 'gemini-2.0-flash')->generateContent('Hello');
$result->text(); // Hello! How can I assist you today?
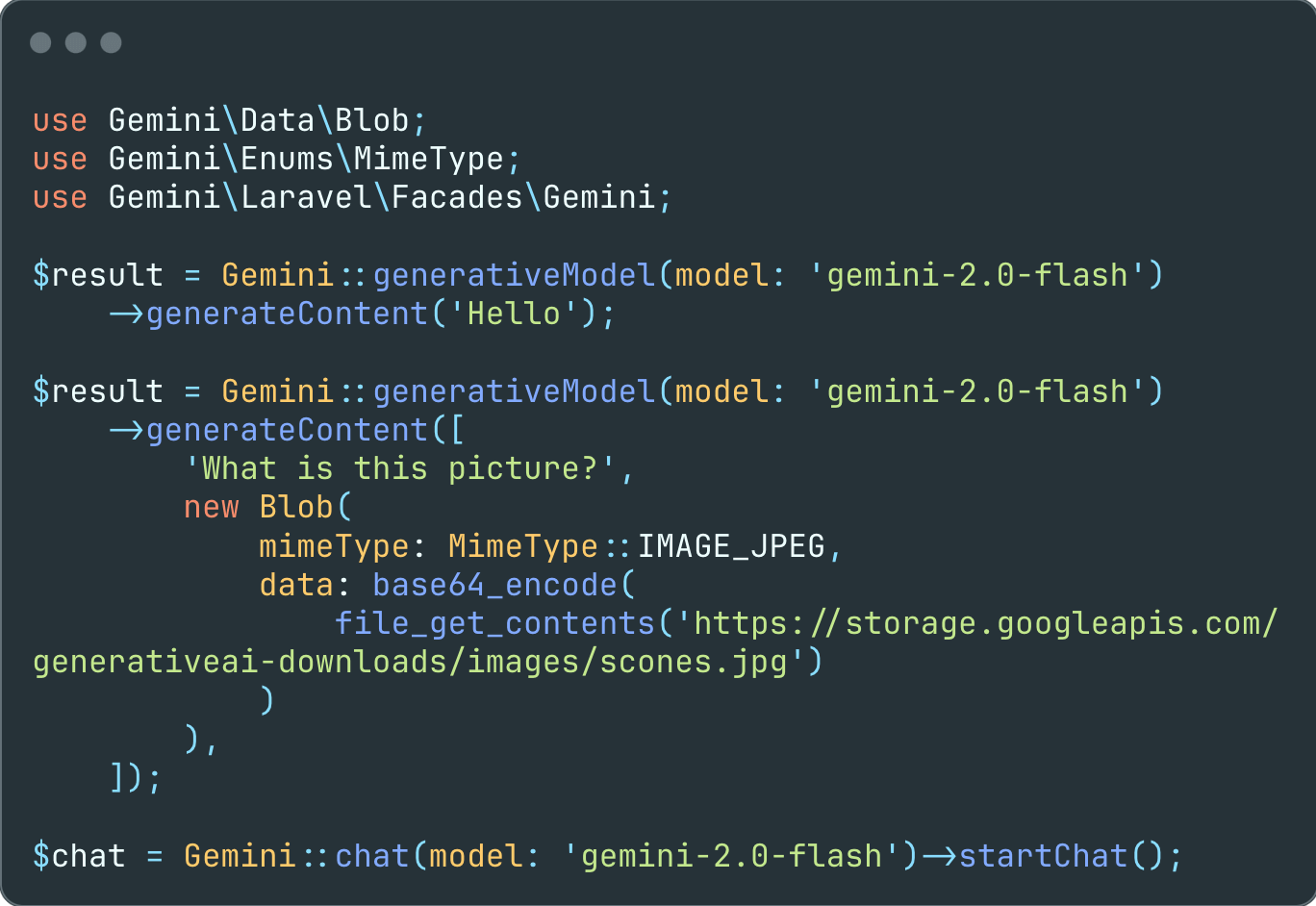
文本和图像输入
通过向 Gemini 模型提供文本提示和图像来生成响应。
use Gemini\Data\Blob;
use Gemini\Enums\MimeType;
use Gemini\Laravel\Facades\Gemini;
$result = Gemini::generativeModel(model: 'gemini-2.0-flash')
->generateContent([
'What is this picture?',
new Blob(
mimeType: MimeType::IMAGE_JPEG,
data: base64_encode(
file_get_contents('https://storage.googleapis.com/generativeai-downloads/images/scones.jpg')
)
)
]);
$result->text(); // The picture shows a table with a white tablecloth. On the table are two cups of coffee, a bowl of blueberries, a silver spoon, and some flowers. There are also some blueberry scones on the table.
文本和视频输入
使用上传的视频文件通过 Gemini API 处理视频内容并获取 AI 生成的描述。
use Gemini\Data\UploadedFile;
use Gemini\Enums\MimeType;
use Gemini\Laravel\Facades\Gemini;
$result = Gemini::generativeModel(model: 'gemini-2.0-flash') ->generateContent([ 'What is this video?', new UploadedFile( fileUri: '123-456', // accepts just the name or the full URI mimeType: MimeType::VIDEO_MP4 ) ]);
$result->text(); // The video shows...
#### 图像生成(Image Generation)
使用 Imagen 模型根据文本提示生成图像。
```php
use Gemini\Data\ImageConfig;
use Gemini\Data\GenerationConfig;
use Gemini\Laravel\Facades\Gemini;
$imageConfig = new ImageConfig(aspectRatio: '16:9');
$generationConfig = new GenerationConfig(imageConfig: $imageConfig);
$response = Gemini::generativeModel(model: 'gemini-2.5-flash-image')
->withGenerationConfig($generationConfig)
->generateContent('Draw a futuristic city');
// Save the image
file_put_contents('image.png', base64_decode($response->parts()[0]->inlineData->data));
多轮对话(Multi-turn Conversations,Chat)
使用 Gemini,你可以构建跨越多轮的自由形式对话。
use Gemini\Data\Content;
use Gemini\Enums\Role;
use Gemini\Laravel\Facades\Gemini;
$chat = Gemini::generativeModel(model: 'gemini-2.0-flash')
->startChat(history: [
Content::parse(part: 'The stories you write about what I have to say should be one line. Is that clear?'),
Content::parse(part: 'Yes, I understand. The stories I write about your input should be one line long.', role: Role::MODEL)
]);
$response = $chat->sendMessage('Create a story set in a quiet village in 1600s France');
echo $response->text(); // Amidst rolling hills and winding cobblestone streets, the tranquil village of Beausoleil whispered tales of love, intrigue, and the magic of everyday life in 17th century France.
$response = $chat->sendMessage('Rewrite the same story in 1600s England');
echo $response->text(); // In the heart of England's lush countryside, amidst emerald fields and thatched-roof cottages, the village of Willowbrook unfolded a tapestry of love, mystery, and the enchantment of ordinary days in the 17th century.
带流式传输的聊天(Chat with Streaming)
你也可以在聊天会话中以流式方式接收响应。流式传输完成后,历史记录会自动更新为完整的响应内容。
use Gemini\Laravel\Facades\Gemini;
$chat = Gemini::generativeModel(model: 'gemini-2.0-flash')->startChat();
$stream = $chat->streamSendMessage('Hello');
foreach ($stream as $response) {
echo $response->text();
}
流式生成内容(Stream Generate Content)
默认情况下,模型会在完成整个生成过程后返回响应。为了实现更快的交互,你可以不等待完整结果,而是使用流式传输来处理部分结果。
use Gemini\Laravel\Facades\Gemini;
$stream = Gemini::generativeModel(model: 'gemini-2.0-flash')
->streamGenerateContent('Write long a story about a magic backpack.');
foreach ($stream as $response) {
echo $response->text();
}
结构化输出(Structured Output)
Gemini 默认生成非结构化文本,但某些应用需要结构化文本。针对这些场景,你可以约束 Gemini 以 JSON 格式(一种适合自动化处理的结构化数据格式)进行响应。你还可以约束模型仅从枚举(enum)中指定的选项中选择响应。
use Gemini\Data\GenerationConfig;
use Gemini\Data\Schema;
use Gemini\Enums\DataType;
use Gemini\Enums\ResponseMimeType;
use Gemini\Laravel\Facades\Gemini;
$result = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withGenerationConfig(
generationConfig: new GenerationConfig(
responseMimeType: ResponseMimeType::APPLICATION_JSON,
responseSchema: new Schema(
type: DataType::ARRAY,
items: new Schema(
type: DataType::OBJECT,
properties: [
'recipe_name' => new Schema(type: DataType::STRING),
'cooking_time_in_minutes' => new Schema(type: DataType::INTEGER)
],
required: ['recipe_name', 'cooking_time_in_minutes'],
)
)
)
)
->generateContent('List 5 popular cookie recipes with cooking time');
$result->json();
//[
// {
// +"cooking_time_in_minutes": 10,
// +"recipe_name": "Chocolate Chip Cookies",
// },
// {
// +"cooking_time_in_minutes": 12,
// +"recipe_name": "Oatmeal Raisin Cookies",
// },
// {
// +"cooking_time_in_minutes": 10,
// +"recipe_name": "Peanut Butter Cookies",
// },
// {
// +"cooking_time_in_minutes": 10,
// +"recipe_name": "Snickerdoodles",
// },
// {
// +"cooking_time_in_minutes": 12,
// +"recipe_name": "Sugar Cookies",
// },
// ]
函数调用(Function calling)
Gemini 支持定义和使用自定义函数,模型可以在对话过程中调用这些函数。这使得模型能够通过你定义的函数执行特定操作或计算。
<?php
use Gemini\Data\Content;
use Gemini\Data\FunctionCall;
use Gemini\Data\FunctionDeclaration;
use Gemini\Data\FunctionResponse;
use Gemini\Data\Part;
use Gemini\Data\Schema;
use Gemini\Data\Tool;
use Gemini\Enums\DataType;
use Gemini\Enums\Role;
use Gemini\Laravel\Facades\Gemini;
function handleFunctionCall(FunctionCall $functionCall): Content
{
if ($functionCall->name === 'addition') {
return new Content(
parts: [
new Part(
functionResponse: new FunctionResponse(
name: 'addition',
response: ['answer' => $functionCall->args['number1'] + $functionCall->args['number2']],
),
thoughtSignature: 'some-signature' // 可选:某些模型(例如 Gemini 3 Pro)需要此参数
)
],
role: Role::USER
);
}
//Handle other function calls
}
$chat = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withTool(new Tool(
functionDeclarations: [
new FunctionDeclaration(
name: 'addition',
description: 'Performs addition',
parameters: new Schema(
type: DataType::OBJECT,
properties: [
'number1' => new Schema(
type: DataType::NUMBER,
description: 'First number'
),
'number2' => new Schema(
type: DataType::NUMBER,
description: 'Second number'
),
],
required: ['number1', 'number2']
)
)
]
))
->startChat();
$response = $chat->sendMessage('What is 4 + 3?');
if ($response->parts()[0]->functionCall !== null) { $thoughtSignature = $response->parts()[0]->thoughtSignature; // 访问思维签名(thought signature) $functionResponse = handleFunctionCall($response->parts()[0]->functionCall);
$response = $chat->sendMessage($functionResponse);
}
echo $response->text(); // 4 + 3 = 7
#### 代码执行(Code Execution)
Gemini 模型可以自动生成并执行代码,并将结果返回给你。这对于需要计算、数据处理或其他编程操作的任务非常有用。
```php
use Gemini\Data\CodeExecution;
use Gemini\Data\Tool;
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withTool(new Tool(codeExecution: CodeExecution::from()))
->generateContent('前 50 个质数的和是多少?请生成并运行代码进行计算,并确保包含全部 50 个质数。');
// 访问已执行的代码和结果
foreach ($response->parts() as $part) {
if ($part->executableCode !== null) {
echo "Language: " . $part->executableCode->language->value . "\n";
echo "Code: " . $part->executableCode->code . "\n";
}
if ($part->codeExecutionResult !== null) {
echo "Outcome: " . $part->codeExecutionResult->outcome->value . "\n";
echo "Output: " . $part->codeExecutionResult->output . "\n";
}
}
使用 Google 搜索进行事实核查(Grounding with Google Search)
使用 Google 搜索进行事实核查可将 Gemini 模型连接到实时网络内容,并支持所有可用语言。这使得 Gemini 能够提供更准确的答案,并引用超出其知识截止日期的可验证来源。
适用于 Gemini 2.0 及更高版本模型(推荐):
使用简单的 GoogleSearch 工具,它会自动处理搜索查询:
use Gemini\Data\GoogleSearch;
use Gemini\Data\Tool;
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withTool(new Tool(googleSearch: GoogleSearch::from()))
->generateContent('谁赢得了 2024 年欧洲杯?');
echo $response->text();
// 西班牙赢得了 2024 年欧洲杯,在决赛中以 2-1 击败英格兰。
// 访问事实核查元数据以查看来源
$groundingMetadata = $response->candidates[0]->groundingMetadata;
if ($groundingMetadata !== null) {
// 获取已执行的搜索查询
foreach ($groundingMetadata->webSearchQueries ?? [] as $query) {
echo "Search query: {$query}\n";
}
// 获取网络来源
foreach ($groundingMetadata->groundingChunks ?? [] as $chunk) {
if ($chunk->web !== null) {
echo "Source: {$chunk->web->title} - {$chunk->web->uri}\n";
}
}
// 获取事实核查支持信息(将文本片段与来源关联)
foreach ($groundingMetadata->groundingSupports ?? [] as $support) {
if ($support->segment !== null) {
echo "Text segment: {$support->segment->text}\n";
echo "Supported by chunks: " . implode(', ', $support->groundingChunkIndices ?? []) . "\n";
}
}
}
系统指令(System Instructions)
系统指令允许你根据特定需求和使用场景引导模型的行为。你可以设定模型的角色和个性、定义响应格式,并为模型行为提供目标和约束。
use Gemini\Data\Content;
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withSystemInstruction(
Content::parse('你是一个乐于助人的助手,总是以海盗的风格回答问题。在所有回答中使用航海术语和海盗俚语。')
)
->generateContent('给我讲讲 PHP 编程');
echo $response->text();
// 啊哈,伙计!让俺给你讲讲这个叫 PHP 编程的宝贝儿……
你也可以将系统指令与其他功能结合使用:
use Gemini\Data\Content;
use Gemini\Data\GenerationConfig;
use Gemini\Enums\ResponseMimeType;
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withSystemInstruction(
Content::parse('你是一个 JSON API。始终以有效的 JSON 对象进行响应。保持简洁。')
)
->withGenerationConfig(
new GenerationConfig(responseMimeType: ResponseMimeType::APPLICATION_JSON)
)
->generateContent('给我一些关于埃菲尔铁塔的信息');
print_r($response->json());
语音生成(Speech generation)
Gemini 支持从文本生成语音。要使用此功能,请确保使用支持该功能的模型。模型将输出 base64 编码的音频字符串。
单说话人
use Gemini\Data\GenerationConfig;
use Gemini\Data\SpeechConfig;
use Gemini\Data\VoiceConfig;
use Gemini\Data\PrebuiltVoiceConfig;
use Gemini\Enums\ResponseModality;
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel('gemini-2.5-flash-preview-tts')->withGenerationConfig(
generationConfig: new GenerationConfig(
responseModalities: [ResponseModality::AUDIO],
speechConfig: new SpeechConfig(
voiceConfig: new VoiceConfig(
new PrebuiltVoiceConfig(voiceName: 'Kore')
),
)
)
)->generateContent("Say: Hello world");
// 响应包含 base64 编码的音频
$audioData = $response->parts()[0]->inlineData->data;
多说话人
use Gemini\Data\GenerationConfig;
use Gemini\Data\SpeechConfig;
use Gemini\Data\MultiSpeakerVoiceConfig;
use Gemini\Data\PrebuiltVoiceConfig;
use Gemini\Data\SpeakerVoiceConfig;
use Gemini\Data\VoiceConfig;
use Gemini\Enums\ResponseModality;
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel('gemini-2.5-flash-preview-tts')->withGenerationConfig(
generationConfig: new GenerationConfig(
responseModalities: [ResponseModality::AUDIO],
speechConfig: new SpeechConfig(
multiSpeakerVoiceConfig: new MultiSpeakerVoiceConfig([
new SpeakerVoiceConfig(
speaker: 'Joe',
voiceConfig: new VoiceConfig(
new PrebuiltVoiceConfig('Kore'),
)
),
new SpeakerVoiceConfig(
speaker: 'Jane',
voiceConfig: new VoiceConfig(
new PrebuiltVoiceConfig('Puck'),
)
)
]),
languageCode: 'en-GB'
)
)
)->generateContent("TTS the following conversation between Joe and Jane:\nJoe: How's it going today Jane?\nJane: Not too bad, how about you?");
// 响应包含 base64 编码的音频
$audioData = $response->parts()[0]->inlineData->data;
思考模式(Thinking Mode)
对于支持思考模式的模型(如 Gemini 2.0),你可以配置模型以展示其推理过程。这在解决复杂问题以及理解模型如何得出答案时非常有用。
use Gemini\Data\GenerationConfig;
use Gemini\Data\ThinkingConfig;
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel(model: 'gemini-2.0-flash-thinking-exp')
->withGenerationConfig(
new GenerationConfig(
thinkingConfig: new ThinkingConfig(
includeThoughts: true,
thinkingBudget: 1024
)
)
)
->generateContent('Solve this logic puzzle: If all Bloops are Razzies and all Razzies are Lazzies, are all Bloops definitely Lazzies?');
// 访问模型的思考过程和最终答案
foreach ($response->candidates[0]->content->parts as $part) {
if ($part->thought === true) {
// 此部分内容包含模型的思考过程
echo "Model's thinking: " . $part->text . "\n\n";
} else if ($part->text !== null) {
// 这是最终答案
echo "Final answer: " . $part->text . "\n";
}
}
计算 Token 数量
当你使用较长的提示(prompt)时,在将内容发送给模型之前计算 token 数量可能会很有用。
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel(model: 'gemini-2.0-flash')
->countTokens('Write a story about a magic backpack.');
echo $response->totalTokens; // 9
配置
你发送给模型的每个提示都包含控制模型如何生成响应的参数值。对于不同的参数值,模型可能会生成不同的结果。了解更多关于 模型参数(model parameters) 的信息。
此外,你可以使用安全设置(safety settings)来调整收到可能被视为有害内容的响应的可能性。默认情况下,安全设置会阻止在所有维度上具有中等或高概率的不安全内容。了解更多关于 安全设置(safety settings) 的信息。
use Gemini\Data\GenerationConfig;
use Gemini\Enums\HarmBlockThreshold;
use Gemini\Data\SafetySetting;
use Gemini\Enums\HarmCategory;
use Gemini\Laravel\Facades\Gemini;
$safetySettingDangerousContent = new SafetySetting(
category: HarmCategory::HARM_CATEGORY_DANGEROUS_CONTENT,
threshold: HarmBlockThreshold::BLOCK_ONLY_HIGH
);
$safetySettingHateSpeech = new SafetySetting(
category: HarmCategory::HARM_CATEGORY_HATE_SPEECH,
threshold: HarmBlockThreshold::BLOCK_ONLY_HIGH
);
$generationConfig = new GenerationConfig(
stopSequences: [
'Title',
],
maxOutputTokens: 800,
temperature: 1,
topP: 0.8,
topK: 10
);
$generativeModel = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withSafetySetting($safetySettingDangerousContent)
->withSafetySetting($safetySettingHateSpeech)
->withGenerationConfig($generationConfig)
->generateContent("Write a story about a magic backpack.");
文件管理(File Management)
文件 API 允许你每个项目最多存储 20GB 的文件,单个文件最大为 2GB。文件将保存 48 小时,并可在 API 调用中访问。
文件上传
若要在各种提示中引用较大的文件和视频,请将它们上传到 Gemini 存储。
use Gemini\Enums\FileState;
use Gemini\Enums\MimeType;
use Gemini\Laravel\Facades\Gemini;
$files = Gemini::files();
echo "Uploading\n";
$meta = $files->upload(
filename: 'video.mp4',
mimeType: MimeType::VIDEO_MP4,
displayName: 'Video'
);
echo "Processing";
do {
echo ".";
sleep(2);
$meta = $files->metadataGet($meta->uri);
} while (!$meta->state->complete());
echo "\n";
if ($meta->state == FileState::Failed) {
die("Upload failed:\n" . json_encode($meta->toArray(), JSON_PRETTY_PRINT));
}
echo "Processing complete\n" . json_encode($meta->toArray(), JSON_PRETTY_PRINT);
echo "\n{$meta->uri}";
列出文件
列出项目中所有已上传的文件。
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::files()->list(pageSize: 10);
foreach ($response->files as $file) {
echo "Name: {$file->name}\n";
echo "Display Name: {$file->displayName}\n";
echo "Size: {$file->sizeBytes} bytes\n";
echo "MIME Type: {$file->mimeType}\n";
echo "State: {$file->state->value}\n";
echo "---\n";
}
// 如果有下一页,则获取下一页
if ($response->nextPageToken) {
$nextPage = Gemini::files()->list(pageSize: 10, nextPageToken: $response->nextPageToken);
}
获取文件元数据
获取特定文件的元数据。
use Gemini\Laravel\Facades\Gemini;
$meta = Gemini::files()->metadataGet('abc123');
// 或使用完整 URI
$meta = Gemini::files()->metadataGet($file->uri);
echo "File: {$meta->displayName}\n";
echo "State: {$meta->state->value}\n";
echo "Size: {$meta->sizeBytes} bytes\n";
删除文件
从 Gemini 存储中删除文件。
use Gemini\Laravel\Facades\Gemini;
Gemini::files()->delete('files/abc123');
// 或使用完整 URI
Gemini::files()->delete($file->uri);
缓存内容(Cached Content)
上下文缓存(Context caching)允许你保存并重用预计算的输入 token,适用于频繁使用的共享内容。这可以降低具有大量共享上下文的请求的成本和延迟。
创建缓存内容
缓存将在多个请求中重复使用的内容。
use Gemini\Data\Content;
use Gemini\Laravel\Facades\Gemini;
$cachedContent = Gemini::cachedContents()->create(
model: 'gemini-2.0-flash',
systemInstruction: Content::parse('You are an expert PHP developer.'),
parts: [
'This is a large codebase...',
'File 1 contents...',
'File 2 contents...'
],
ttl: '3600s', // 缓存 1 小时
displayName: 'PHP Codebase Cache'
);
echo "Cached content created: {$cachedContent->name}\n";
列出缓存内容
列出项目中所有已缓存的内容。
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::cachedContents()->list(pageSize: 10);
foreach ($response->cachedContents as $cached) {
echo "Name: {$cached->name}\n";
echo "Display Name: {$cached->displayName}\n";
echo "Model: {$cached->model}\n";
echo "Expires: {$cached->expireTime}\n";
echo "---\n";
}
获取缓存内容
通过名称检索特定的缓存内容。
use Gemini\Laravel\Facades\Gemini;
$cached = Gemini::cachedContents()->retrieve('cachedContents/abc123');
echo "Model: {$cached->model}\n";
echo "Created: {$cached->createTime}\n";
echo "Expires: {$cached->expireTime}\n";
更新缓存内容
更新缓存内容的过期时间。
use Gemini\Laravel\Facades\Gemini;
// 通过 TTL 延长
$updated = Gemini::cachedContents()->update(
name: 'cachedContents/abc123',
ttl: '7200s' // 延长 2 小时
);
// 或设置绝对过期时间
$updated = Gemini::cachedContents()->update(
name: 'cachedContents/abc123',
expireTime: '2024-12-31T23:59:59Z'
);
删除缓存内容
在不再需要时删除缓存内容。
use Gemini\Laravel\Facades\Gemini;
Gemini::cachedContents()->delete('cachedContents/abc123');
使用缓存内容
在请求中使用缓存内容以节省 token 并降低延迟。
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::generativeModel(model: 'gemini-2.0-flash')
->withCachedContent('cachedContents/abc123')
->generateContent('Explain the main function in this codebase');
echo $response->text();
// 检查 token 使用情况
echo "Cached tokens used: {$response->usageMetadata->cachedContentTokenCount}\n";
echo "New tokens used: {$response->usageMetadata->promptTokenCount}\n";
嵌入资源(Embedding Resource)
嵌入(Embedding)是一种将信息表示为浮点数数组的技术。通过 Gemini,你可以将文本(单词、句子和文本块)转换为向量化形式,从而更方便地进行比较和对比。例如,主题或情感相似的两段文本应具有相近的嵌入向量,可通过余弦相似度(cosine similarity)等数学比较方法识别。
使用 text-embedding-004 模型,调用 embedContents 或 batchEmbedContents:
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::embeddingModel('text-embedding-004')
->embedContent("Write a story about a magic backpack.");
print_r($response->embedding->values);
//[
// [0] => 0.008624583
// [1] => -0.030451821
// [2] => -0.042496547
// [3] => -0.029230341
// [4] => 0.05486475
// [5] => 0.006694871
// [6] => 0.004025645
// [7] => -0.007294857
// [8] => 0.0057651913
// ...
//]
模型(Models)
建议查阅 Google 官方文档 获取最新支持的模型列表。
列出模型
通过编程方式查看可用的 Gemini 模型:
pageSize(可选):
每页返回的最大模型数量。
若未指定,默认每页返回 50 个模型。即使传入更大的值,该方法每页最多也只返回 1000 个模型。nextPageToken(可选):
从上一次models.list调用中获得的分页令牌。
将前一次请求返回的pageToken作为参数传递给下一次请求,以获取下一页结果。
分页时,除pageToken外,其他所有参数必须与提供该令牌的原始请求一致。
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::models()->list(pageSize: 3, nextPageToken: 'ChFtb2RlbHMvZ2VtaW5pLXBybw==');
$response->models;
//[
// [0] => Gemini\Data\Model Object
// (
// [name] => models/gemini-2.0-flash
// [version] => 2.0
// [displayName] => Gemini 2.0 Flash
// [description] => Gemini 2.0 Flash
// ...
// )
// [1] => Gemini\Data\Model Object
// (
// [name] => models/gemini-2.5-pro-preview-05-06
// [version] => 2.5-preview-05-06
// [displayName] => Gemini 2.5 Pro Preview 05-06
// [description] => Preview release (May 6th, 2025) of Gemini 2.5 Pro
// ...
// )
// [2] => Gemini\Data\Model Object
// (
// [name] => models/text-embedding-004
// [version] => 004
// [displayName] => Text Embedding 004
// [description] => Obtain a distributed representation of a text.
// ...
// )
//]
$response->nextPageToken // Chltb2RlbHMvZ2VtaW5pLTEuMC1wcm8tMDAx
获取模型信息
获取模型的详细信息,如版本、显示名称、输入 token 限制等。
use Gemini\Laravel\Facades\Gemini;
$response = Gemini::models()->retrieve('models/gemini-2.5-pro-preview-05-06');
$response->model;
//Gemini\Data\Model Object
//(
// [name] => models/gemini-2.5-pro-preview-05-06
// [version] => 2.5-preview-05-06
// [displayName] => Gemini 2.5 Pro Preview 05-06
// [description] => Preview release (May 6th, 2025) of Gemini 2.5 Pro
// ...
//)
故障排除(Troubleshooting)
超时(Timeout)
向 API 发送请求时可能会遇到超时问题。默认超时时间取决于所使用的 HTTP 客户端。
你可以在 config/gemini.php 文件中配置超时时间:
return [
'api_key' => env('GEMINI_API_KEY'),
'base_url' => env('GEMINI_BASE_URL', 'https://generativelanguage.googleapis.com/v1beta/'),
'request_timeout' => env('GEMINI_REQUEST_TIMEOUT', 30), // 将超时时间增加到 30 秒
];
或者在 .env 文件中设置:
GEMINI_REQUEST_TIMEOUT=60
测试(Testing)
本包提供了一个 Gemini\Client 类的模拟(fake)实现,允许你模拟 API 响应。
为了测试你的代码,请确保在测试用例中将 Gemini\Client 类替换为 Gemini\Testing\ClientFake 类。
模拟响应会按照创建模拟客户端时提供的顺序依次返回。
所有响应都包含一个 fake() 方法,让你只需提供与当前测试相关的参数,即可轻松创建响应对象。
use Gemini\Laravel\Facades\Gemini;
use Gemini\Responses\GenerativeModel\GenerateContentResponse;
Gemini::fake([
GenerateContentResponse::fake([
'candidates' => [
[
'content' => [
'parts' => [
[
'text' => 'success',
],
],
],
],
],
]),
]);
$result = Gemini::generativeModel(model: 'gemini-2.0-flash')->generateContent('test');
expect($result->text())->toBe('success');
对于流式(streamed)响应,你可以选择性地提供一个包含模拟响应数据的资源(resource)。
use Gemini\Laravel\Facades\Gemini;
use Gemini\Responses\GenerativeModel\GenerateContentResponse;
Gemini::fake([
GenerateContentResponse::fakeStream(),
]);
$result = Gemini::generativeModel(model: 'gemini-2.0-flash')->streamGenerateContent('Hello');
expect($response->getIterator()->current())
->text()->toBe('In the bustling city of Aethelwood, where the cobblestone streets whispered');
在请求发送后,你可以使用多种方法来验证是否发送了预期的请求:
use Gemini\Laravel\Facades\Gemini;
use Gemini\Resources\GenerativeModel;
use Gemini\Resources\Models;
// 断言已发送列出模型(list models)的请求
Gemini::models()->assertSent(callback: function ($method) {
return $method === 'list';
});
// 或
Gemini::assertSent(resource: Models::class, callback: function ($method) {
return $method === 'list';
});
Gemini::generativeModel(model: 'gemini-2.0-flash')->assertSent(function (string $method, array $parameters) {
return $method === 'generateContent' &&
$parameters[0] === 'Hello';
});
// 或
Gemini::assertSent(resource: GenerativeModel::class, model: 'gemini-2.0-flash', callback: function (string $method, array $parameters) {
return $method === 'generateContent' &&
$parameters[0] === 'Hello';
});
// 断言已发送 2 次生成式模型(generative model)请求
Gemini::assertSent(resource: GenerativeModel::class, model: 'gemini-2.0-flash', callback: 2);
// 或
Gemini::generativeModel(model: 'gemini-2.0-flash')->assertSent(2);
// 断言未发送任何生成式模型请求
Gemini::assertNotSent(resource: GenerativeModel::class, model: 'gemini-2.0-flash');
// 或
Gemini::generativeModel(model: 'gemini-2.0-flash')->assertNotSent();
// 断言未发送任何请求
Gemini::assertNothingSent();
若要编写期望 API 请求失败的测试,你可以将一个 Throwable 对象作为响应提供。
use Gemini\Laravel\Facades\Gemini;
use Gemini\Exceptions\ErrorException;
Gemini::fake([
new ErrorException([
'message' => 'The model `gemini-basic` does not exist',
'status' => 'INVALID_ARGUMENT',
'code' => 400,
]),
]);
// 将抛出 `ErrorException`
Gemini::generativeModel(model: 'gemini-2.0-flash')->generateContent('test');
版本历史
2.0.32025/11/252.0.22025/11/222.0.12025/05/122.0.02025/05/091.0.22025/02/271.0.1-beta2025/02/271.0.0-beta2024/09/281.0.12024/02/111.0.02024/02/11常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。