langextract
LangExtract 是一个开源的 Python 库,帮你从杂乱文本(比如医疗报告、小说或会议记录)中自动抓取结构化信息。它用大型语言模型(LLMs)理解你的需求——只需简单描述任务并提供几个例子,就能精准提取关键内容,如人物关系、药物名称或诊断结果,同时确保每个结果都能精确回溯到原文位置,避免“凭空捏造”。
它解决了非结构化文本处理的痛点:传统方法常漏掉细节、难以验证准确性,尤其面对长文档时更棘手。LangExtract 通过三大亮点提升体验:一是“精确溯源”,自动高亮提取内容在原文的出处,方便快速核对;二是“交互式可视化”,一键生成可浏览的 HTML 文件,轻松审查成百上千条数据;三是高效处理长文本,用智能分块和并行计算提升召回率。它灵活支持云端模型(如 Gemini)和本地开源模型(通过 Ollama),无需模型微调,几分钟就能适配新领域。
开发者、研究人员(尤其是医疗、金融或学术领域)会爱上它的易用性——你只需定义任务规则,就能构建定制化提取流程,省去繁琐编码。普通技术用户也能快速上手,让文本分析变得直观可靠。试试 LangExtract,把杂乱信息变成清晰结构,专注你的核心工作吧!(字数:298)
使用场景
一位医疗数据分析师正在处理医院电子健康记录系统中的非结构化医生笔记,需要从数千份长篇临床文档中提取患者当前服用的药物清单,以支持用药安全分析。
没有 langextract 时
- 手动逐行阅读笔记耗时极长,处理一份2000字的文档平均需40分钟,团队每周浪费20+小时在重复劳动上。
- 提取的药物信息缺乏原文位置标记,审核时需反复翻查原始文本,错误率高达15%,例如漏掉“阿司匹林 100mg”中的剂量单位。
- 输出格式混乱:不同分析师对“二甲双胍”可能写成“Metformin”或“格华止”,导致后续数据整合失败。
- 长文档中关键信息分散(如药物名藏在段落末尾),人工易遗漏低频药物,召回率不足70%。
使用 langextract 后
- 自动解析文档仅需2分钟/份,通过Ollama本地模型并行处理,团队效率提升20倍,周节省15+小时。
- 每个提取项(如“二甲双胍 500mg”)精确高亮原文位置,交互式HTML报告一键跳转验证,错误率降至5%以下。
- 强制输出标准化JSON结构(含药物名、剂量、频率字段),确保所有数据统一格式,无缝对接分析系统。
- 优化分块策略自动扫描全文,多轮提取覆盖边缘案例,低频药物召回率提升至95%,关键信息零遗漏。
langextract将非结构化医疗文本的提取过程转化为高效、精准且可追溯的自动化流程,释放数据价值。
运行环境要求
- 未说明
未说明
未说明
快速开始
![]()
LangExtract


![]()
![]()
目录
- 简介
- 为什么选择 LangExtract?
- 快速开始
- 安装
- 云模型的 API 密钥配置
- 添加自定义模型提供商
- 使用 OpenAI 模型
- 通过 Ollama 使用本地大语言模型(LLM)
- 更多示例
- 社区提供商
- 贡献指南
- 测试
- 免责声明
简介
LangExtract 是一个 Python 库,利用大型语言模型(LLM)根据用户定义的指令从非结构化文本文档中提取结构化信息。它处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本严格对应。
为什么选择 LangExtract?
- 精准的源文本定位(Precise Source Grounding): 将每次提取精确映射到源文本中的具体位置,支持可视化高亮显示,便于追溯和验证。
- 可靠的结构化输出(Reliable Structured Outputs): 基于您的少样本示例(few-shot examples)强制执行一致的输出模式,利用 Gemini 等支持模型的受控生成能力,确保结果稳健且结构化。
- 长文档优化(Optimized for Long Documents): 通过优化的文本分块策略、并行处理和多轮提取,克服大型文档中"大海捞针"的挑战,提高召回率。
- 交互式可视化(Interactive Visualization): 即时生成独立的交互式 HTML 文件,在原始上下文中可视化和审查数千个提取实体。
- 灵活的 LLM 支持(Flexible LLM Support): 支持您偏好的模型,从 Google Gemini 系列等云托管 LLM 到通过内置 Ollama 接口的本地开源模型。
- 全领域适配(Adaptable to Any Domain): 仅需少量示例即可定义任意领域的提取任务。LangExtract 无需模型微调即可适配您的需求。
- 利用 LLM 世界知识(Leverages LLM World Knowledge): 通过精确的提示词设计和少样本示例,影响提取任务如何利用 LLM 的知识。任何推断信息的准确性及其对任务规范的符合程度,取决于所选 LLM、任务复杂度、提示指令清晰度以及提示示例的性质。
快速开始
注意: 使用 Gemini 等云托管模型需要 API 密钥。请参阅 API 密钥配置 部分获取密钥申请和配置说明。
仅需几行代码即可提取结构化信息。
1. 定义提取任务
首先,创建一个清晰描述提取目标的提示词。然后提供高质量示例引导模型。
import langextract as lx
import textwrap
# 1. 定义提示词和提取规则
prompt = textwrap.dedent("""\
按出现顺序提取角色、情绪和关系。
使用原文文本进行提取,不得改写或重叠实体。
为每个实体提供有意义的属性以补充上下文。""")
# 2. 提供高质量示例引导模型
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
注意: 示例驱动模型行为。每个
extraction_text应理想地直接取自示例的text(不得改写),并按出现顺序列出。若示例不符合此模式,LangExtract 默认会触发Prompt alignment警告——为获得最佳结果,请解决这些警告。源文本定位(Grounding): LLM 有时可能从少样本示例而非输入文本中提取内容。LangExtract 会自动检测此情况:无法在源文本中定位的提取项将具有
char_interval = None。使用[e for e in result.extractions if e.char_interval]过滤,仅保留有定位的结果。
2. 执行提取
将输入文本和提示材料提供给 lx.extract 函数。
# 待处理的输入文本
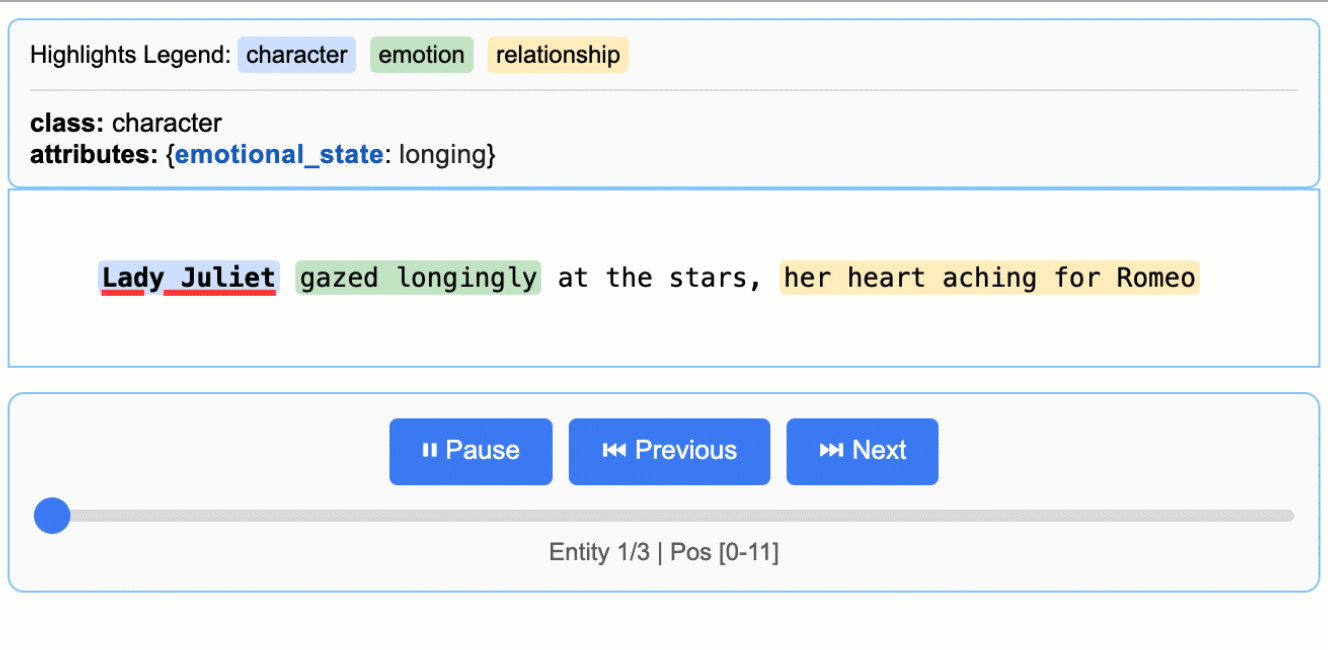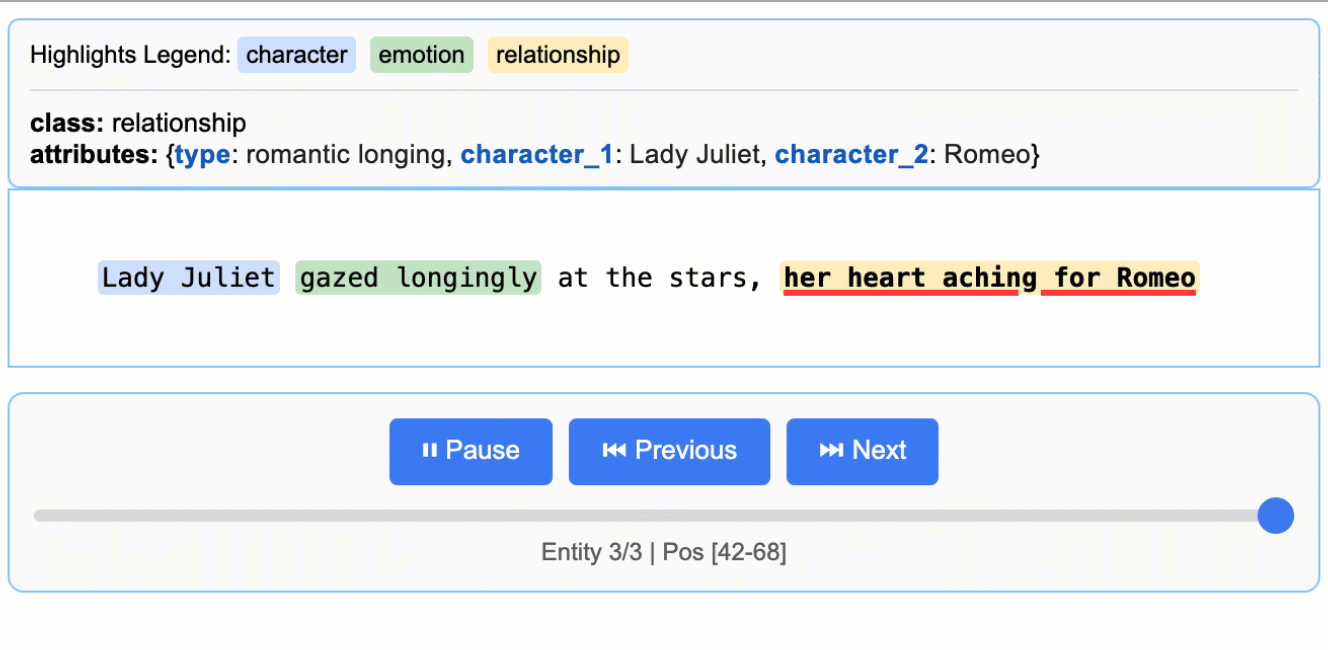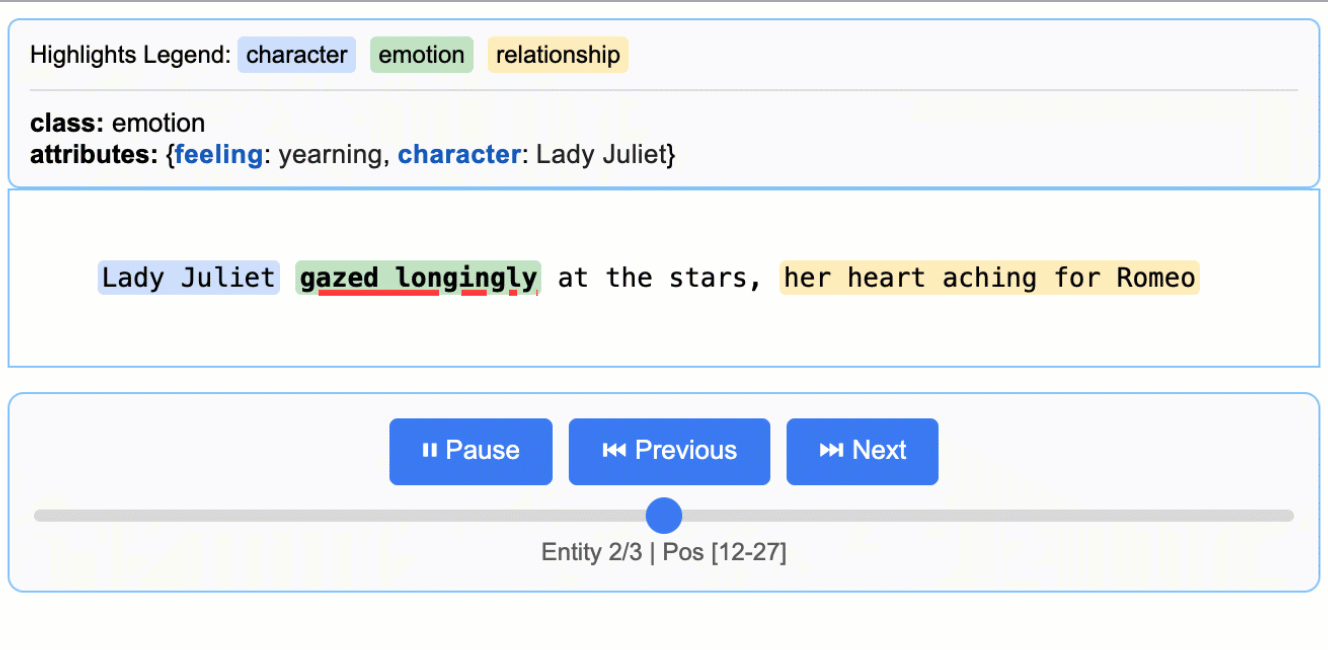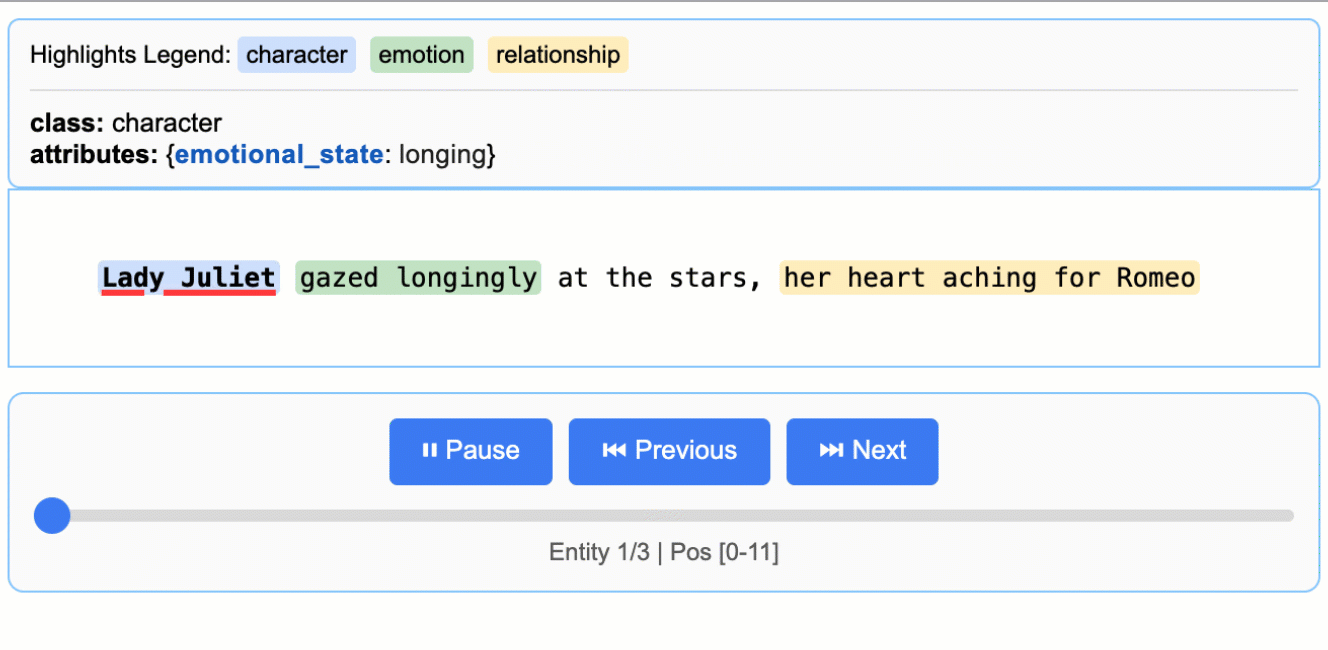
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# 执行提取
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
模型选择:
gemini-2.5-flash是推荐的默认选项,在速度、成本和质量间取得极佳平衡。对于需要深度推理的高复杂度任务,gemini-2.5-pro可能提供更优结果。大规模或生产环境建议申请 Gemini Tier 2 配额以提升吞吐量并避免速率限制。详情参见 速率限制文档。模型生命周期: Gemini 模型具有明确的生命周期和退役日期。用户应查阅 官方模型版本文档 了解最新稳定版和旧版信息。
3. 可视化结果
提取结果可保存为 .jsonl 文件(处理语言模型数据的常用格式)。LangExtract 可从此文件生成交互式 HTML 可视化界面,在上下文中审查实体。
# 将结果保存到 JSONL 文件
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# 从文件生成可视化
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data) # For Jupyter/Colab
else:
f.write(html_content)
这将生成一个动画和交互式的 HTML 文件:
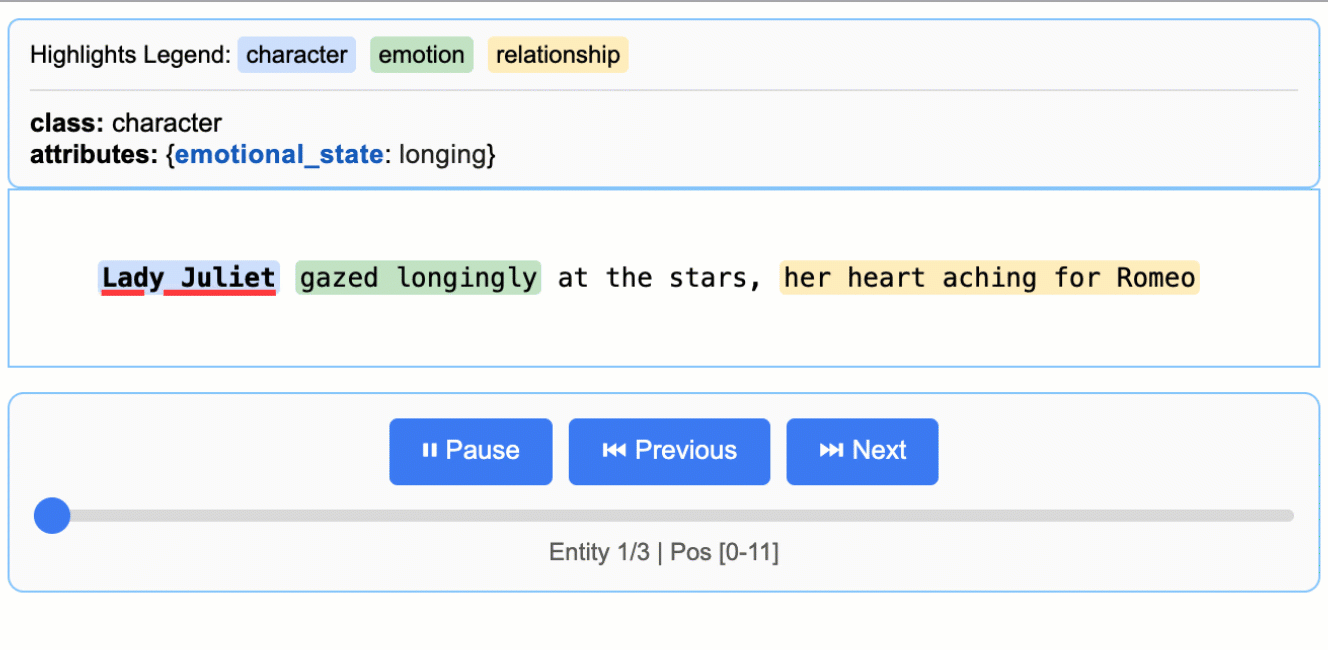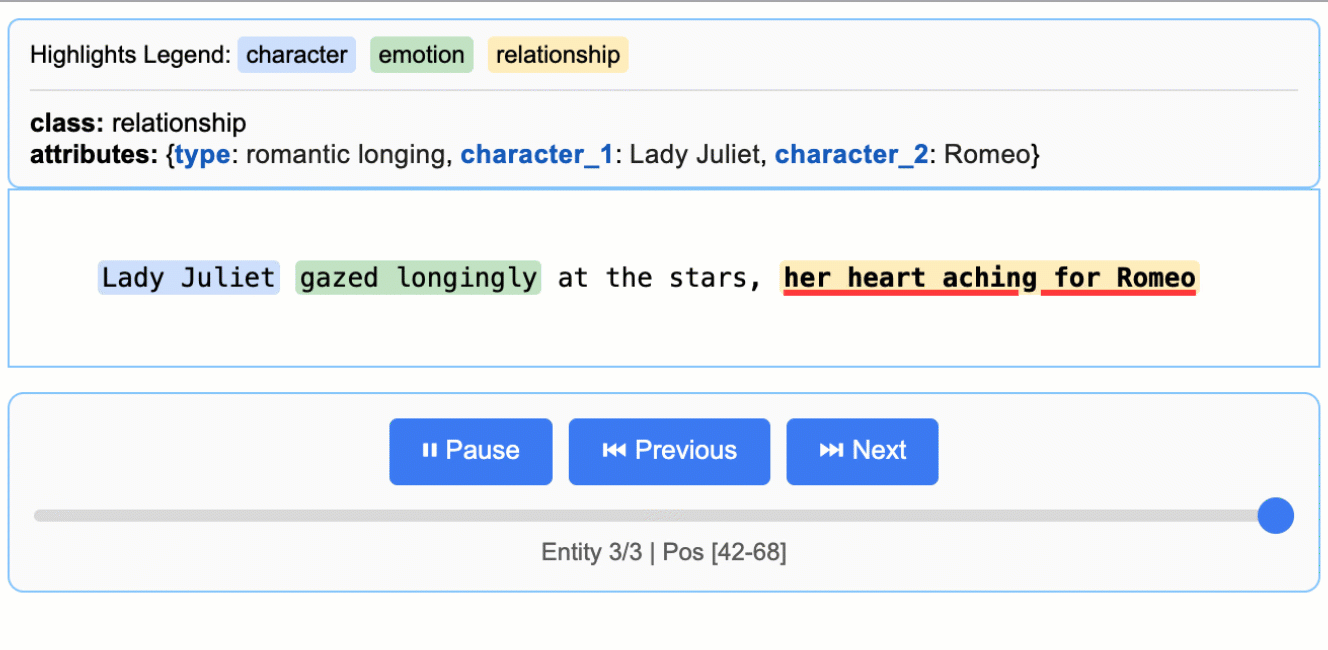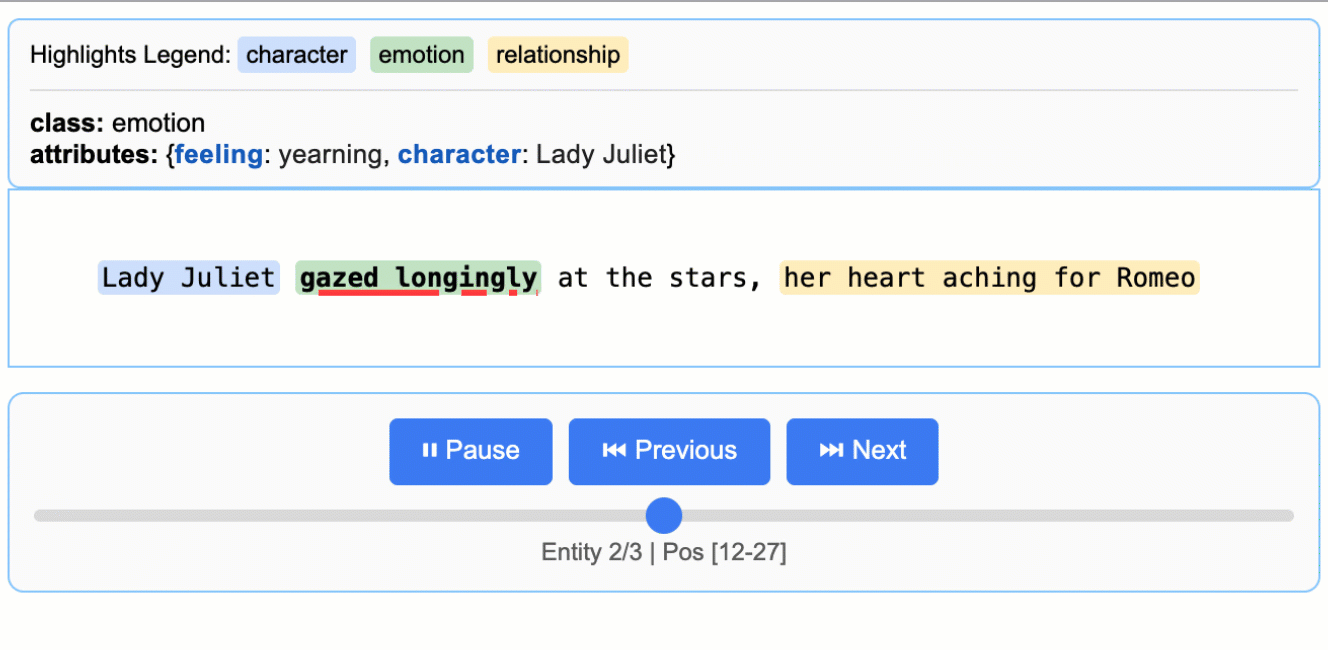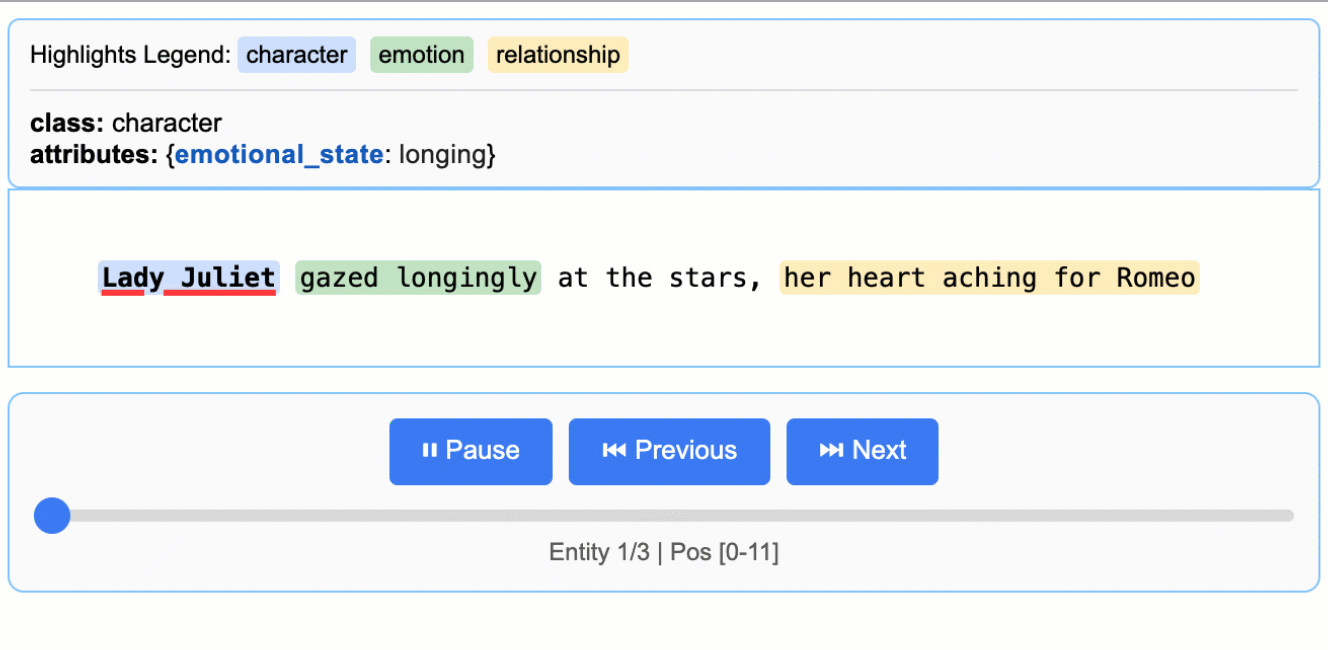
关于 LLM(大型语言模型)知识利用的说明: 本示例展示了紧密基于文本证据的提取——为朱丽叶小姐的情感状态提取 "longing"(渴望),并从 "gazed longingly at the stars" 中识别出 "yearning"(渴望)。该任务可以修改为生成更多依赖 LLM 世界知识的属性(例如,添加
"identity": "Capulet family daughter"或"literary_context": "tragic heroine")。文本证据与知识推理之间的平衡由您的提示指令和示例属性控制。
扩展到更长文档
对于较大文本,您可以通过并行处理和增强敏感度直接从 URL 处理整个文档:
# 直接从 Project Gutenberg 处理《罗密欧与朱丽叶》
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # 通过多次提取提高召回率
max_workers=20, # 并行处理以提升速度
max_char_buffer=1000 # 更小的上下文以提高准确性
)
此方法可以从整部小说中提取数百个实体,同时保持高精度。交互式可视化无缝处理大型结果集,便于从输出的 JSONL 文件中探索数百个实体。查看完整的《罗密欧与朱丽叶》提取示例 → 以获取详细结果和性能洞察。
Vertex AI(谷歌云顶点 AI)批量处理
通过启用 Vertex AI 批量 API 降低大规模任务成本:language_model_params={"vertexai": True, "batch": {"enabled": True}}。
参见 this example 中的 Vertex AI 批量 API 使用示例。
安装
从 PyPI 安装
pip install langextract
推荐给大多数用户。对于隔离环境,建议使用虚拟环境:
python -m venv langextract_env
source langextract_env/bin/activate # 在 Windows 上:langextract_env\Scripts\activate
pip install langextract
从源码安装
LangExtract 使用现代 Python 打包方式,通过 pyproject.toml 进行依赖管理:
使用 -e 安装会将包置于开发模式,允许您修改代码而无需重新安装。
git clone https://github.com/google/langextract.git
cd langextract
# 基础安装:
pip install -e .
# 开发环境(包含代码检查工具):
pip install -e ".[dev]"
# 测试环境(包含 pytest):
pip install -e ".[test]"
Docker
docker build -t langextract .
docker run --rm -e LANGEXTRACT_API_KEY="your-api-key" langextract python your_script.py
云模型的 API 密钥设置
当将 LangExtract 与云托管模型(如 Gemini 或 OpenAI)一起使用时,您需要设置 API 密钥。设备上模型不需要 API 密钥。对于使用本地 LLM(大型语言模型)的开发者,LangExtract 提供对 Ollama 的内置支持,并可通过更新推理端点扩展到其他第三方 API。
API 密钥来源
从以下位置获取 API 密钥:
- AI Studio 用于 Gemini 模型
- Vertex AI 用于企业级应用
- OpenAI Platform 用于 OpenAI 模型
在环境中设置 API 密钥
选项 1:环境变量
export LANGEXTRACT_API_KEY="your-api-key-here"
选项 2:.env 文件(推荐)
将您的 API 密钥添加到 .env 文件:
# 将 API 密钥添加到 .env 文件
cat >> .env << 'EOF'
LANGEXTRACT_API_KEY=your-api-key-here
EOF
# 保护您的 API 密钥安全
echo '.env' >> .gitignore
在您的 Python 代码中:
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract information...",
examples=[...],
model_id="gemini-2.5-flash"
)
选项 3:直接 API 密钥(不推荐用于生产环境)
您也可以在代码中直接提供 API 密钥,但不建议在生产环境中使用:
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract information...",
examples=[...],
model_id="gemini-2.5-flash",
api_key="your-api-key-here" # 仅用于测试/开发
)
选项 4:Vertex AI(服务账号)
使用 Vertex AI 通过服务账号进行身份验证:
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract information...",
examples=[...],
model_id="gemini-2.5-flash",
language_model_params={
"vertexai": True,
"project": "your-project-id",
"location": "global" # 或区域端点
}
)
添加自定义模型提供者
LangExtract 通过轻量级插件系统支持自定义 LLM 提供者。您可以在不更改核心代码的情况下添加对新模型的支持。
- 独立于核心库添加新模型支持
- 将您的提供者作为单独的 Python 包分发
- 保持自定义依赖项隔离
- 通过基于优先级的解析覆盖或扩展内置提供者
参见 Provider System Documentation 中的详细指南,了解如何:
- 使用
@registry.register(...)注册提供者 - 发布用于发现的入口点
- 可选地通过
get_schema_class()提供模式以实现结构化输出 - 通过
create_model(...)与工厂集成
使用 OpenAI 模型
LangExtract 支持 OpenAI 模型(需要可选依赖:pip install langextract[openai]):
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o", # 自动选择 OpenAI 提供者
api_key=os.environ.get('OPENAI_API_KEY'),
fence_output=True,
use_schema_constraints=False
)
注意:OpenAI 模型需要 fence_output=True 和 use_schema_constraints=False,因为 LangExtract 尚未为 OpenAI 实现模式约束。
使用 Ollama 与本地大语言模型(LLM)
LangExtract 支持通过 Ollama(本地大语言模型运行框架)进行本地推理,无需 API 密钥即可运行模型:
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b", # 自动选择 Ollama 提供商
model_url="http://localhost:11434",
fence_output=False,
use_schema_constraints=False
)
快速设置: 从 ollama.com 安装 Ollama,运行 ollama pull gemma2:2b,然后执行 ollama serve。
详细安装指南、Docker(容器化平台)配置及示例请参阅 examples/ollama/。
更多样例
LangExtract 实际应用的其他示例:
罗密欧与朱丽叶 全文提取
LangExtract 可直接从 URL 处理完整文档。本示例演示了从 Project Gutenberg 获取的 罗密欧与朱丽叶 全文(147,843 个字符)进行提取,展示了并行处理、顺序提取流程以及长文档处理的性能优化。
药物信息提取
免责声明: 本演示仅用于说明 LangExtract 的基础能力,不代表已完成或获批的产品,不用于诊断或建议任何疾病/症状的治疗,不可作为医疗建议使用。
LangExtract 擅长从临床文本中提取结构化医疗信息。这些示例展示了基础实体识别(药物名称、剂量、给药途径)和关系提取(关联药物与其属性),体现 LangExtract 在医疗健康应用中的有效性。
放射科报告结构化:RadExtract
探索 RadExtract,这是一个 HuggingFace Spaces 上的实时交互式演示,展示 LangExtract 如何自动结构化放射科报告。无需配置,直接在浏览器中体验。
社区提供商
通过自定义模型提供商扩展 LangExtract!查阅我们的 社区提供商插件 注册表,发现社区创建的提供商或添加您自己的插件。
创建提供商插件的详细说明请参见 自定义提供商插件示例。
贡献指南
欢迎贡献!参阅 CONTRIBUTING.md 了解开发、测试和提交拉取请求的流程。提交补丁前必须签署 贡献者许可协议。
测试
从源码本地运行测试:
# 克隆仓库
git clone https://github.com/google/langextract.git
cd langextract
# 安装测试依赖
pip install -e ".[test]"
# 运行所有测试
pytest tests
或使用 tox 本地复现完整 CI 矩阵(持续集成测试矩阵):
tox # 在 Python 3.10 和 3.11 上运行 pylint + pytest
Ollama 集成测试
若本地已安装 Ollama,可运行集成测试:
# 测试 Ollama 集成(需运行含 gemma2:2b 模型的 Ollama)
tox -e ollama-integration
该测试将自动检测 Ollama 可用性并执行真实推理测试。
开发指南
代码格式化
本项目使用自动化格式化工具保持代码风格一致:
# 自动格式化所有代码
./autoformat.sh
# 或分别运行格式化工具
isort langextract tests --profile google --line-length 80
pyink langextract tests --config pyproject.toml
预提交钩子
用于自动格式化检查:
pre-commit install # 一次性设置
pre-commit run --all-files # 手动执行
代码检查
提交 PR 前请运行代码检查:
pylint --rcfile=.pylintrc langextract tests
完整开发规范请参阅 CONTRIBUTING.md。
免责声明
本项目非 Google 官方支持产品。若在生产环境或出版物中使用 LangExtract,请适当引用并注明使用情况。使用受 Apache 2.0 License 约束。医疗相关应用还需遵守 Health AI Developer Foundations Terms of Use。
愉快提取!
版本历史
v1.2.02026/03/22v1.1.12025/11/27v1.1.02025/11/14v1.0.92025/08/31v1.0.82025/08/15v1.0.72025/08/14v1.0.62025/08/13v1.0.52025/08/08v1.0.42025/08/05v1.0.32025/08/03v1.0.22025/08/03v1.0.12025/08/02v1.0.02025/07/22常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。