copilot-metrics-viewer
copilot-metrics-viewer 是一款专为 GitHub 组织及企业账户设计的可视化工具,旨在直观展示 GitHub Copilot 的使用数据与采纳情况。它有效解决了官方 API 仅能提供最近 28 天滚动数据、缺乏长期历史趋势分析以及难以按团队维度拆解指标的痛点,帮助管理者清晰评估 Copilot 的实际影响力。
该工具特别适合企业的技术负责人、工程效能分析师及 DevOps 团队使用,助力其通过数据驱动决策来优化开发流程。其核心技术亮点在于提供了两种灵活模式:无需数据库的“直接 API 模式”可快速查看近期概览;而搭配 PostgreSQL 的“历史模式”则支持每日自动同步,不仅突破时间限制实现无限期数据留存,还能基于用户级数据动态聚合出团队维度的深度报表。此外,它还支持自定义日期范围筛选(最长 100 天)、排除节假日干扰以及多团队横向对比功能,让数据分析更加精准且贴合实际业务场景。
使用场景
某大型科技公司的工程效能团队正在评估 GitHub Copilot 在企业内的推广效果,并需要向管理层汇报各研发团队的采纳情况与投资回报率。
没有 copilot-metrics-viewer 时
- 数据视野受限:只能获取最近 28 天的滚动数据,无法追溯半年前的试点项目表现,难以分析长期趋势。
- 团队对比困难:官方 API 不提供团队维度的聚合数据,手动整理数百名开发者的使用情况并按团队归类耗时且易错。
- 决策缺乏依据:无法排除周末或节假日干扰,导致人均代码生成量等关键指标波动异常,误导资源分配决策。
- 汇报效率低下:每次月度汇报都需要工程师编写临时脚本抓取数据并制作图表,重复劳动严重。
使用 copilot-metrics-viewer 后
- 全周期历史洞察:启用 Historical 模式连接 PostgreSQL 数据库,轻松调取任意时间段的历史数据,清晰展示从试点到全面推广的增长曲线。
- 自动化团队画像:利用内置的团队指标派生功能,一键生成各研发小组的采纳率对比图,快速识别高绩效团队与待帮扶对象。
- 精准数据清洗:通过自定义日期范围过滤器排除非工作日干扰,获得更真实的效能数据,为预算审批提供坚实支撑。
- 仪表盘即时呈现:管理层可直接访问可视化仪表盘查看实时动态,无需等待人工报表,将数据分析时间从数天缩短至几分钟。
copilot-metrics-viewer 将分散的 API 数据转化为可操作的组织级洞察,让技术管理者真正看清 AI 辅助编程带来的实际价值。
运行环境要求
- 未说明
不需要 GPU
未说明
快速开始
注意:有关支持和帮助的信息,请点击这里。
ℹ️ v3.0 — 新的 Copilot 使用指标 API
自 v3.0 起,Copilot Metrics Viewer 使用 Copilot 使用指标 API。旧版 Copilot 使用指标 API 已于 2026 年 4 月 2 日关闭,不再可用。
v3.0 的新功能:
- 所有数据均使用异步 Copilot 使用指标 API
- 历史模式:通过 PostgreSQL 数据库存储超过 28 天滚动窗口的数据
- 用户级指标选项卡:提供个人使用情况细分
- 基于用户级数据的团队指标:不再需要已弃用的团队级别 API 端点
- 同步服务:用于每日自动数据收集
您的 GitHub 应用程序需要 “组织 Copilot 指标:读取” 权限。有关设置详情,请参阅 GitHub 应用程序注册。
GitHub Copilot 指标查看器

此应用程序为您的GitHub 组织或企业账户显示一组与 GitHub Copilot 相关的各种指标图表。这些可视化旨在清晰地呈现数据,便于理解和分析 GitHub Copilot 的影响及采用情况。
运行模式
该应用程序支持两种运行模式:
| 模式 | 描述 | 要求 | 团队指标 | 数据保留 |
|---|---|---|---|---|
| 直接 API | 在每次页面加载时直接从 GitHub 的 API 获取指标 | 仅需 GitHub 令牌 | ❌ 不可用 | 滚动 28 天 |
| 历史模式 | 从本地 PostgreSQL 数据库读取数据,每日同步 | PostgreSQL + 同步服务 | ✅ 完整历史 | 无限制 |
直接 API 模式是最简单的设置——无需数据库。它会返回来自 Copilot 使用指标 API 的最新 28 天滚动窗口数据。由于团队指标是根据数据库中存储的用户记录推导出来的,因此在此模式下无法查看团队范围的视图。
历史模式则增加了 PostgreSQL 数据库和一个每日下载指标的同步服务。这使得:
- 可以查看 超出 28 天 API 窗口 的指标
- 提供 用户时间序列历史 和趋势图
- 团队指标——由存储的用户数据根据团队成员资格筛选后得出
有关每种模式的设置说明,请参阅 DEPLOYMENT.md。
应用程序概述
GitHub Copilot 指标查看器通过直观的仪表板界面提供全面的分析:
新功能
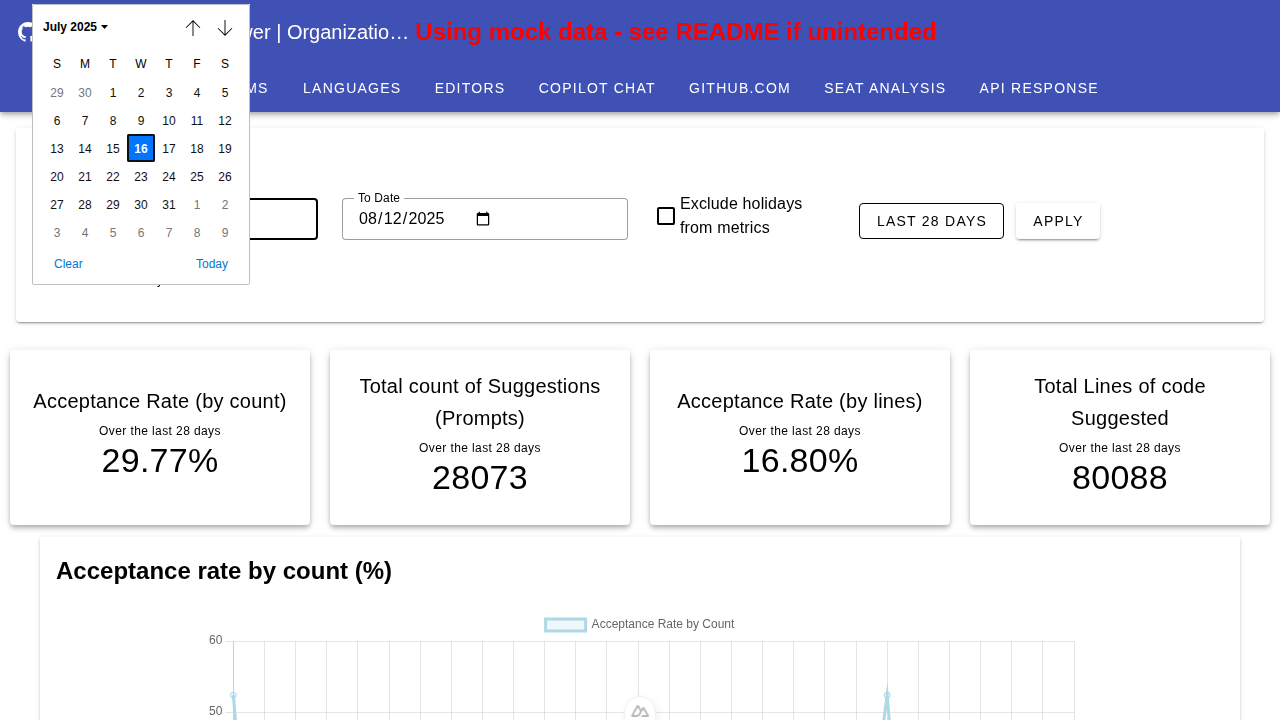
日期范围筛选(最长 100 天)
用户现在可以使用直观的日历选择界面,按自定义日期范围筛选最多 100 天内的指标。系统还支持在计算中排除周末和节假日。
团队比较
比较您组织内多个团队的 Copilot 指标,以了解采用模式并识别表现优异的团队。
[!NOTE] GitHub 的 Copilot 使用指标 API 不提供团队级别的端点。团队指标是通过从组织/企业端点获取每日用户级指标、利用 GitHub Teams API 解析团队成员资格,并在内存中聚合用户级数据来“推导”出的。此方法适用于直接 API 模式(28 天窗口)和历史模式(完整历史)。

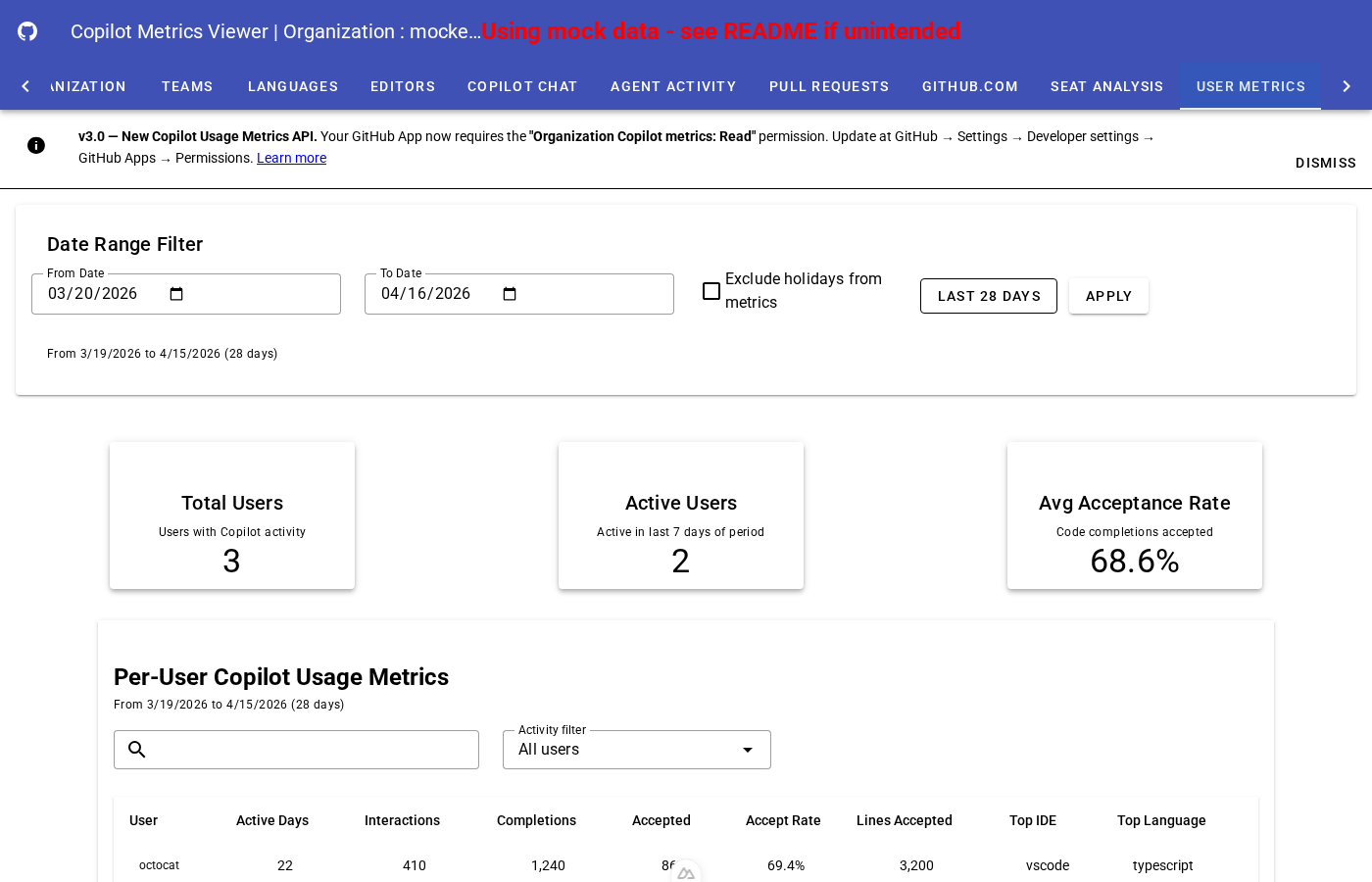
用户级指标
查看个人用户级别的 Copilot 使用指标,包括代码补全、聊天交互和代码审查活动。摘要卡片显示总用户数、活跃用户数以及平均接受率。
在 历史模式(使用 PostgreSQL 数据库)下,用户指标选项卡还会显示用户的时间序列历史图表,使您可以跟踪个人随时间的变化趋势。
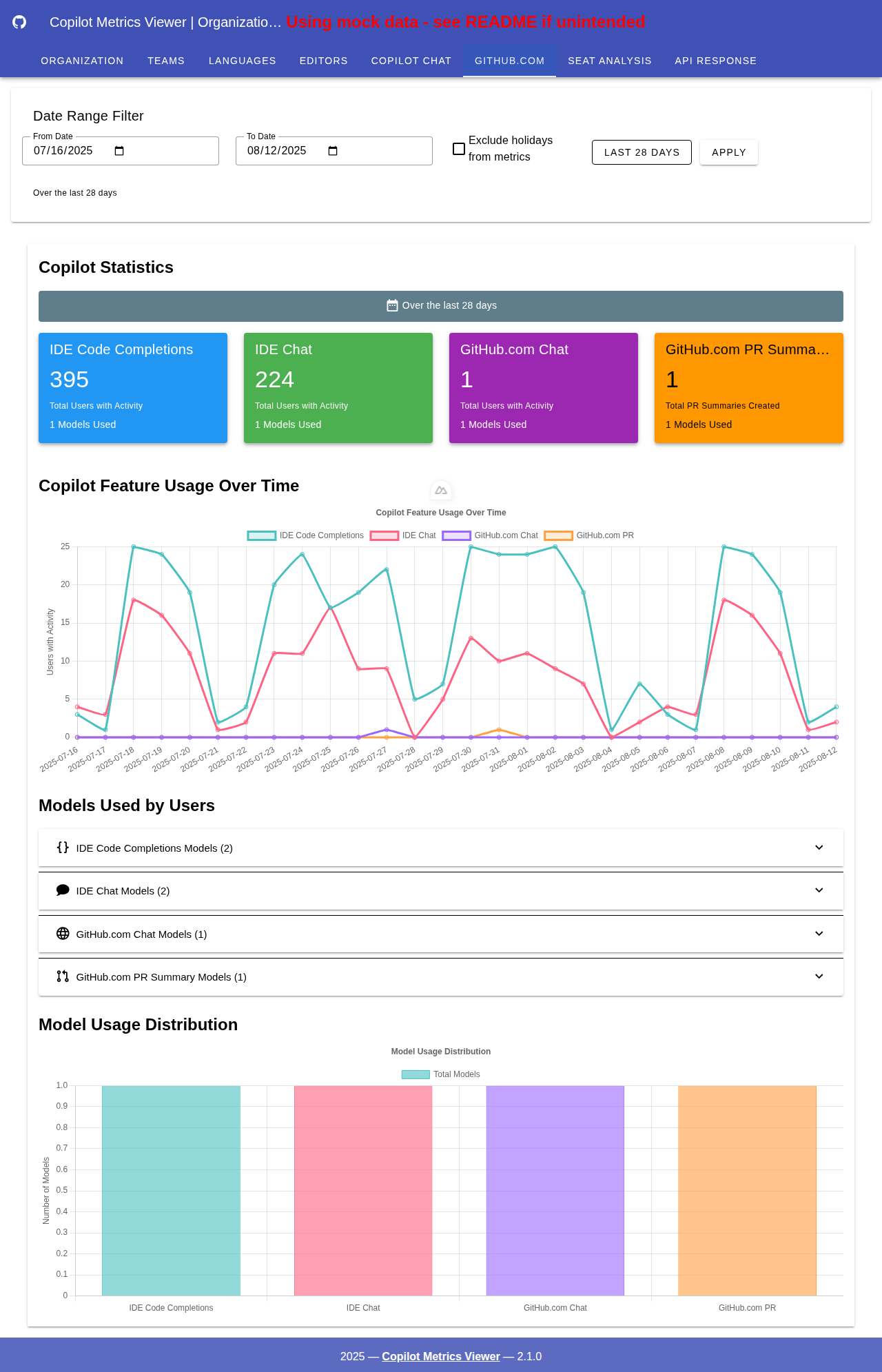
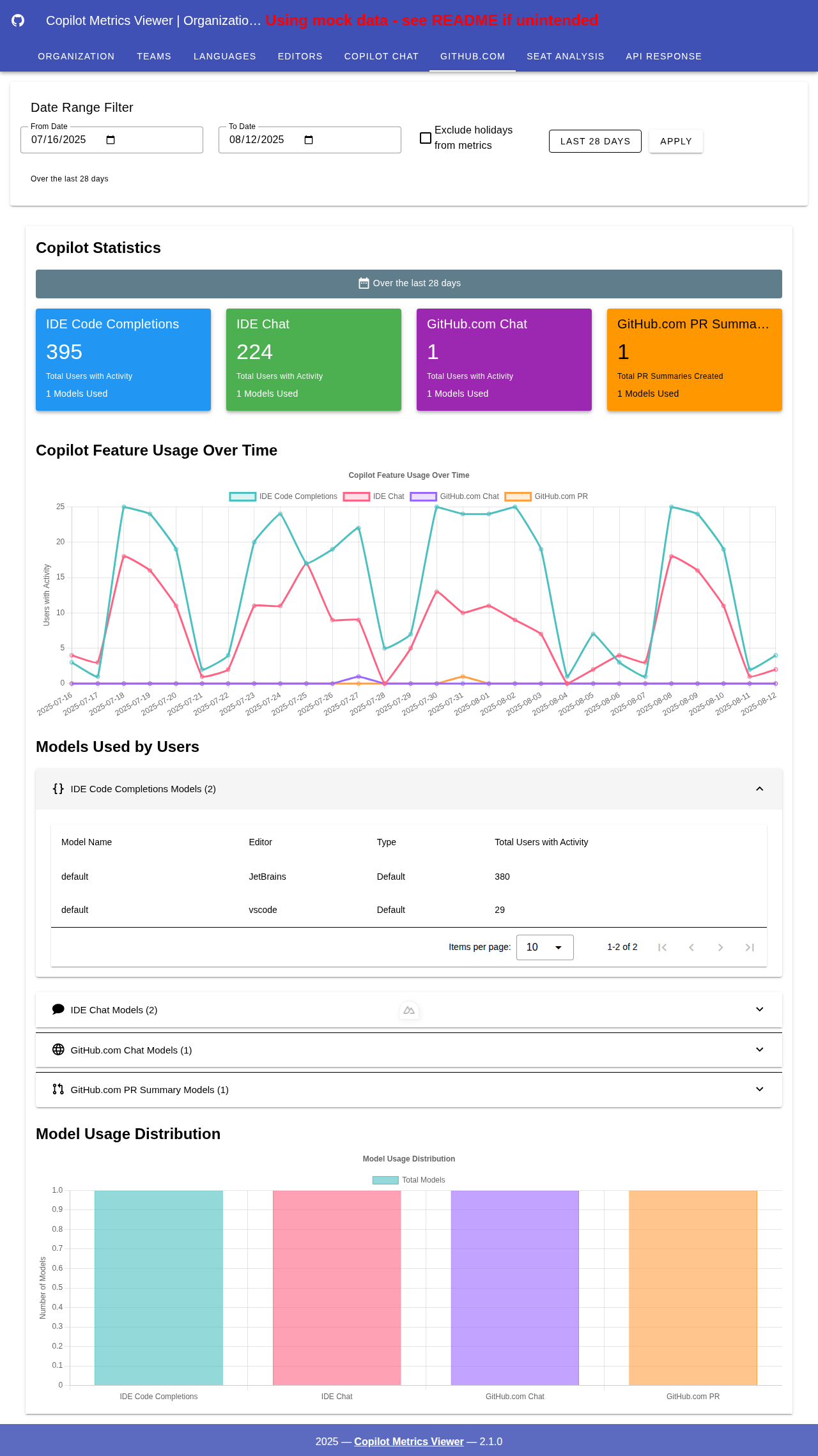
GitHub.com 集成与模型分析
查看 GitHub.com 功能的综合统计数据,包括聊天、PR 摘要以及详细的模型使用分析。每个部分都提供可展开的详细信息,显示模型类型、编辑器和使用模式。
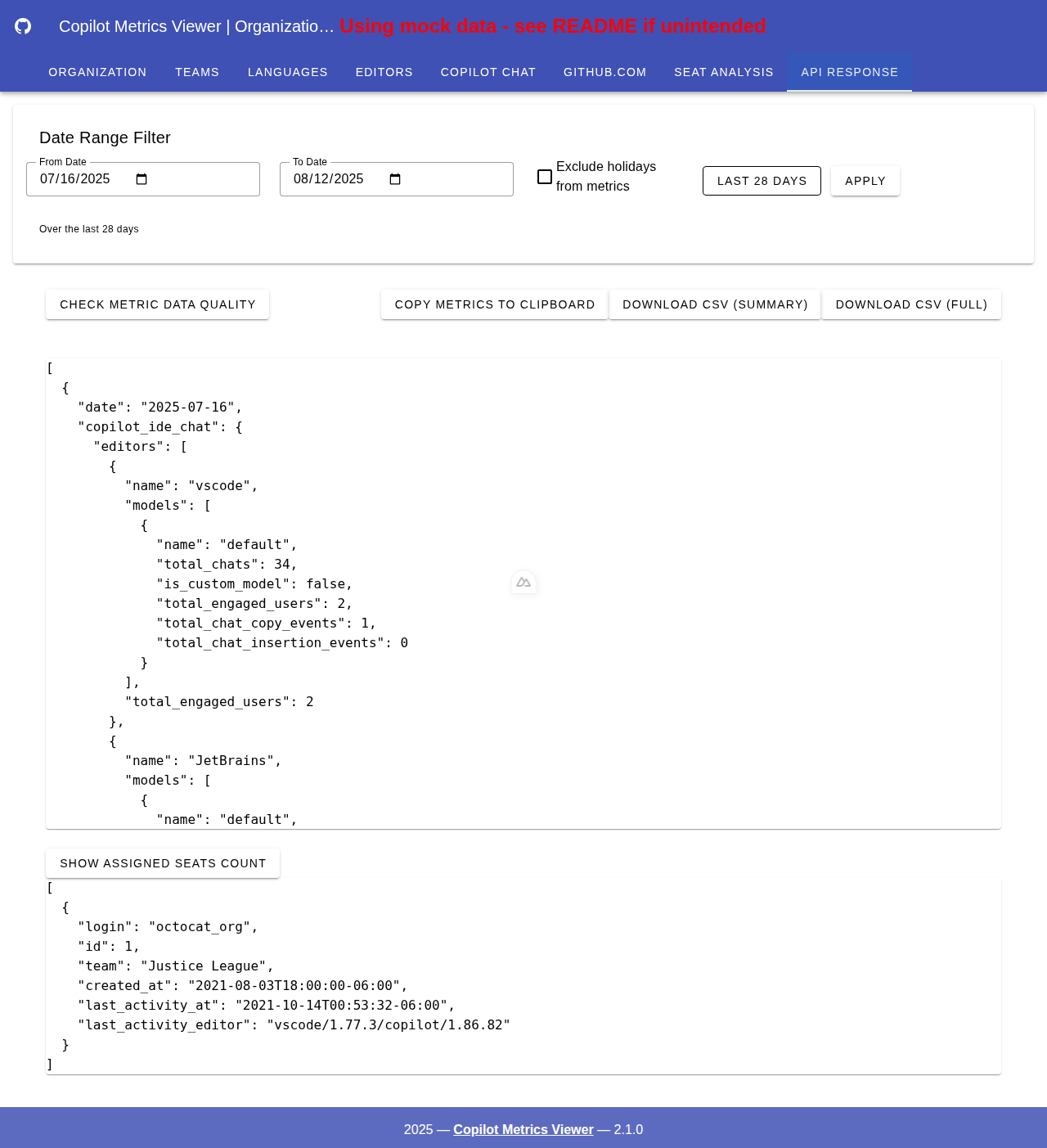
CSV 导出功能
将您的指标数据导出为多种格式,以便进一步分析或报告。选项包括摘要报告、完整详细导出以及直接复制到剪贴板。
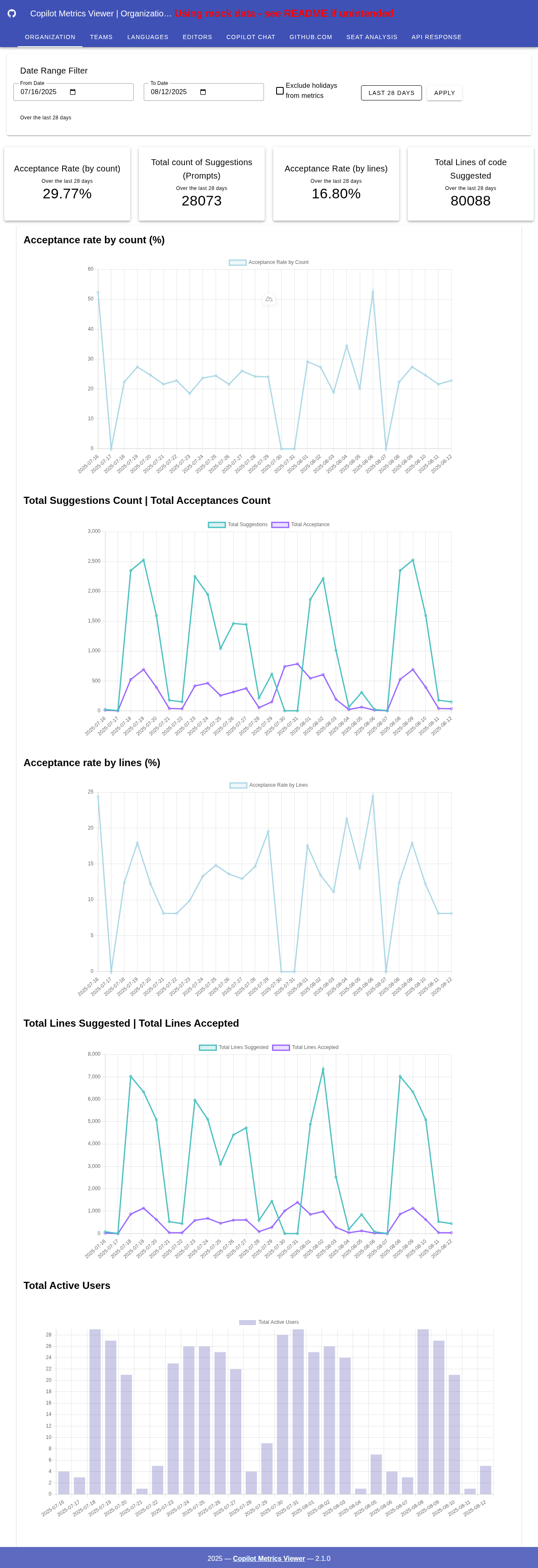
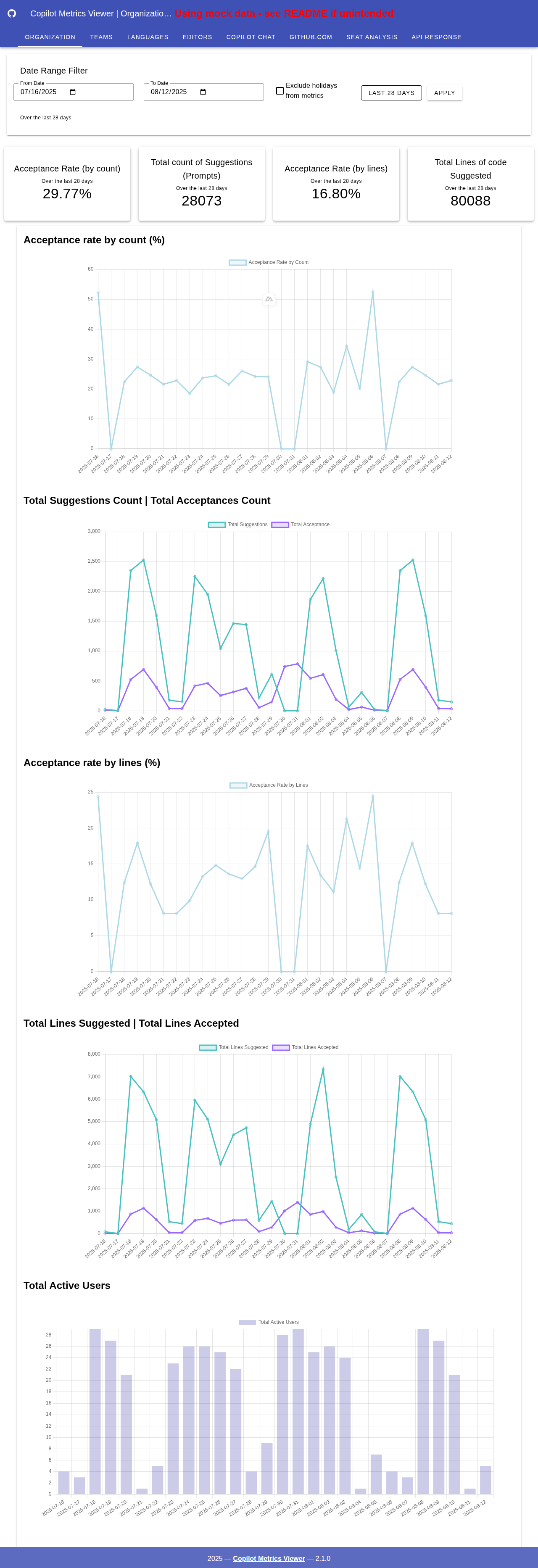
图表
关键指标
[!NOTE] 指标详情在 Copilot 使用情况指标 API 文档 中有详细说明
以下是在这些图表中可视化的关键指标:
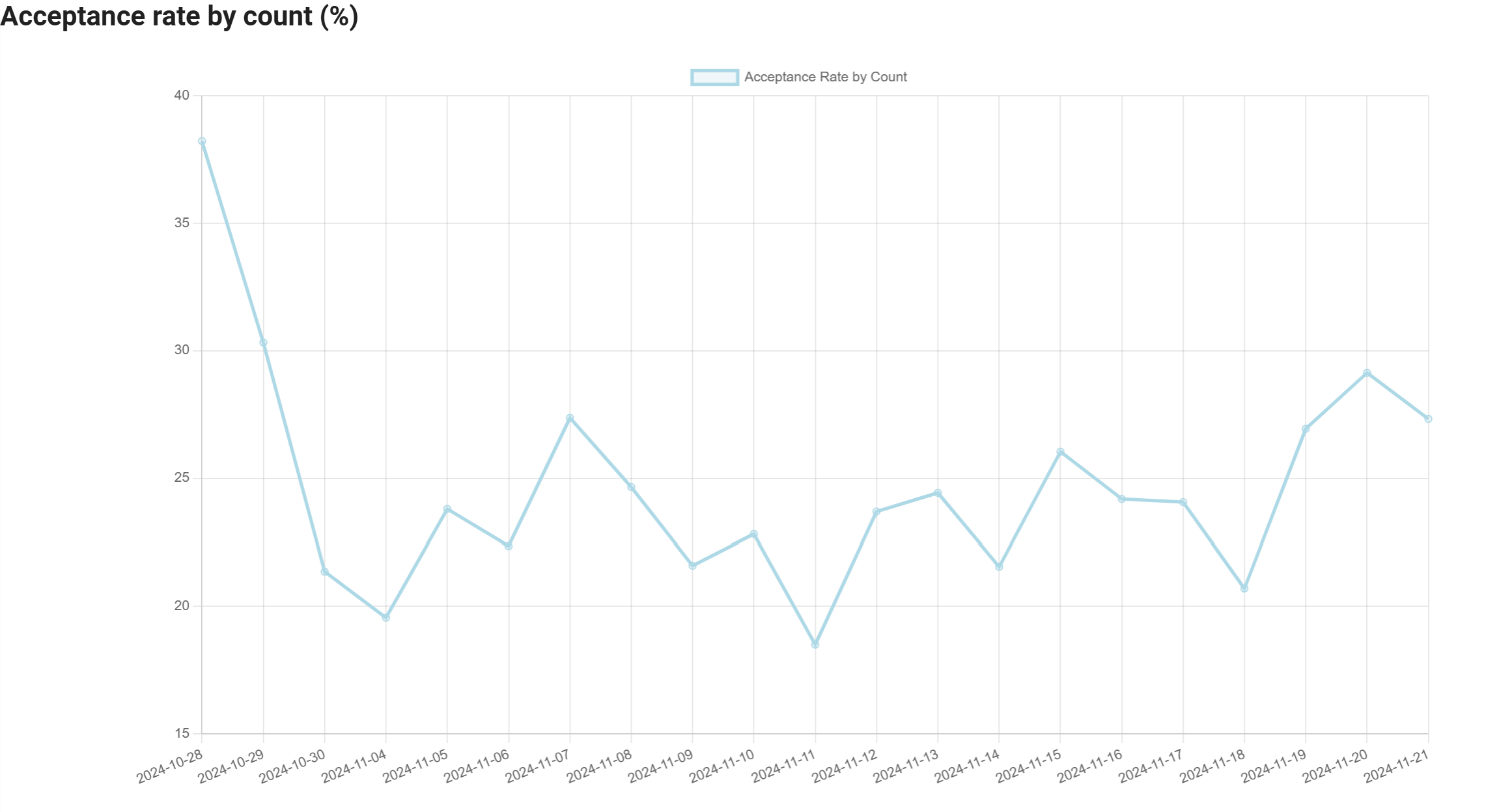
- 接受率:该指标表示 GitHub Copilot 接受的代码行数和建议数占其总建议数的比例。这一比率是 Copilot 建议相关性和有用性的一个指标。然而,与任何指标一样,使用时也应谨慎,因为开发者使用 Copilot 的方式多种多样(研究、确认、验证等,并非总是直接“注入”代码)。
总建议数:此图表展示了 GitHub Copilot 提出的代码建议总数。它反映了工具的活跃度及其随时间推移与用户的互动情况。
总接受数:此可视化专注于用户接受的建议总数。
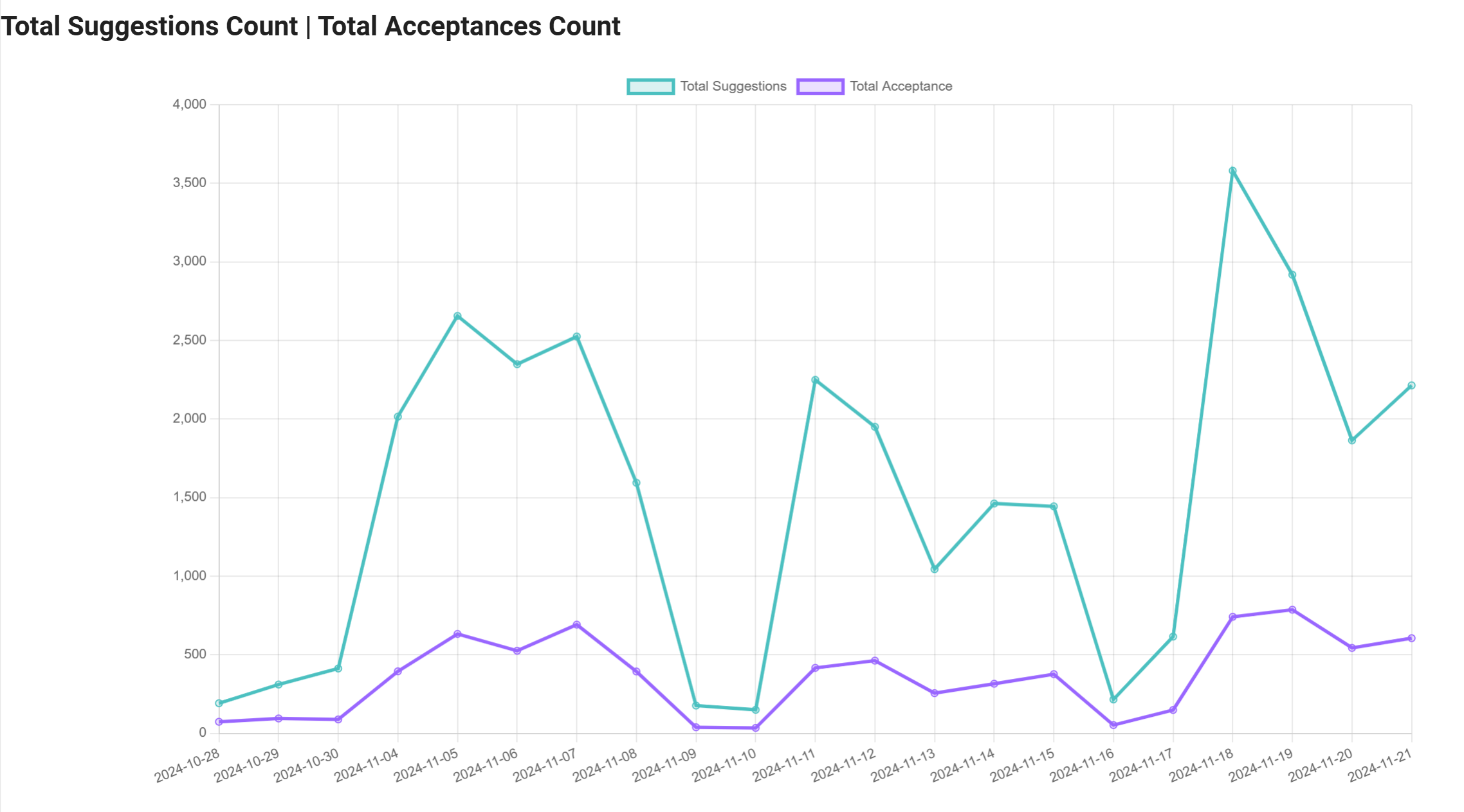
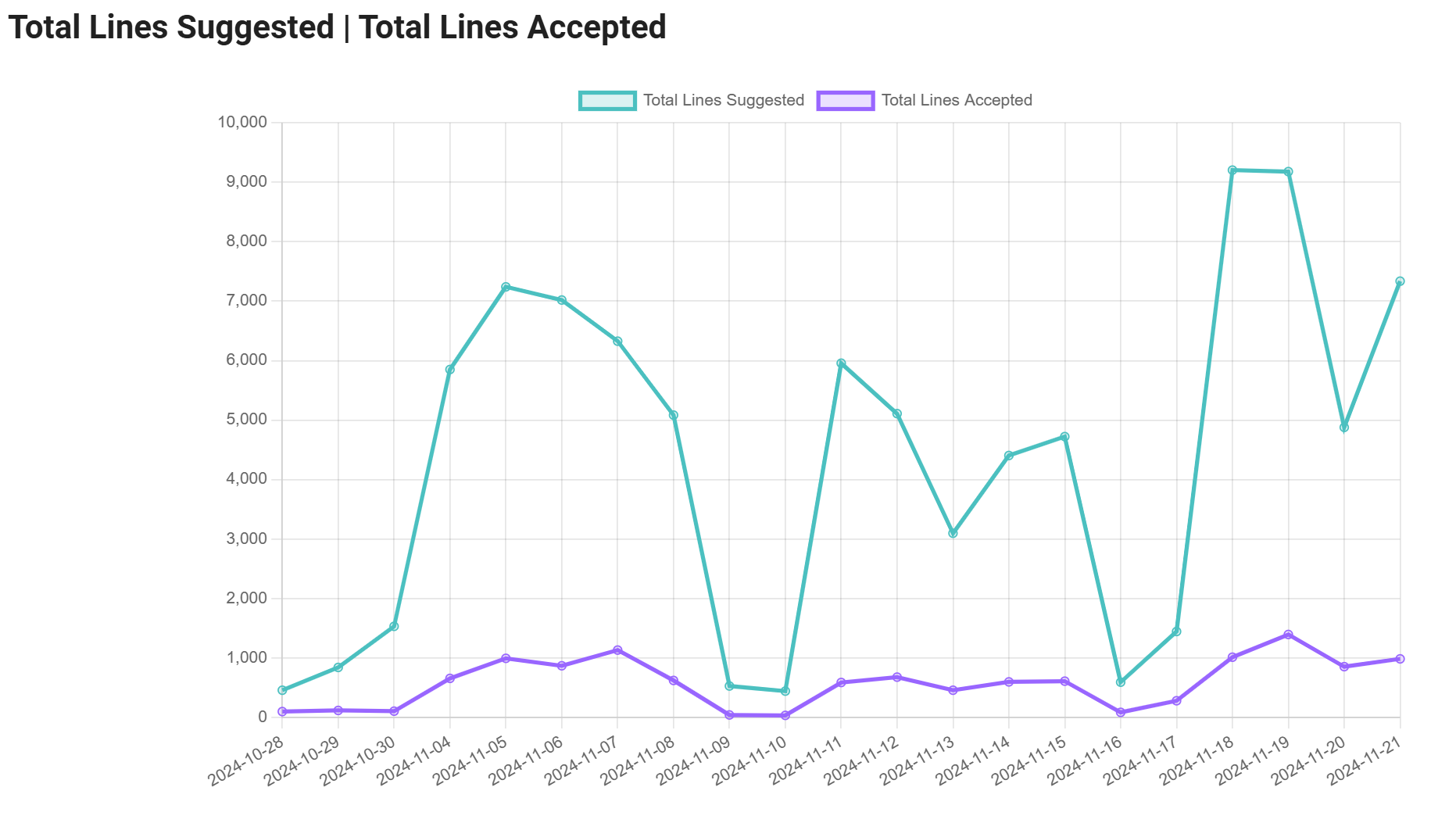
总建议行数:展示了 GitHub Copilot 建议的代码行数总和。这有助于了解代码生成和辅助工作的规模。
总接受行数:顾名思义,该指标显示了用户接受的代码行数(完全接受),从而揭示有多少建议代码被实际使用并整合到代码库中。
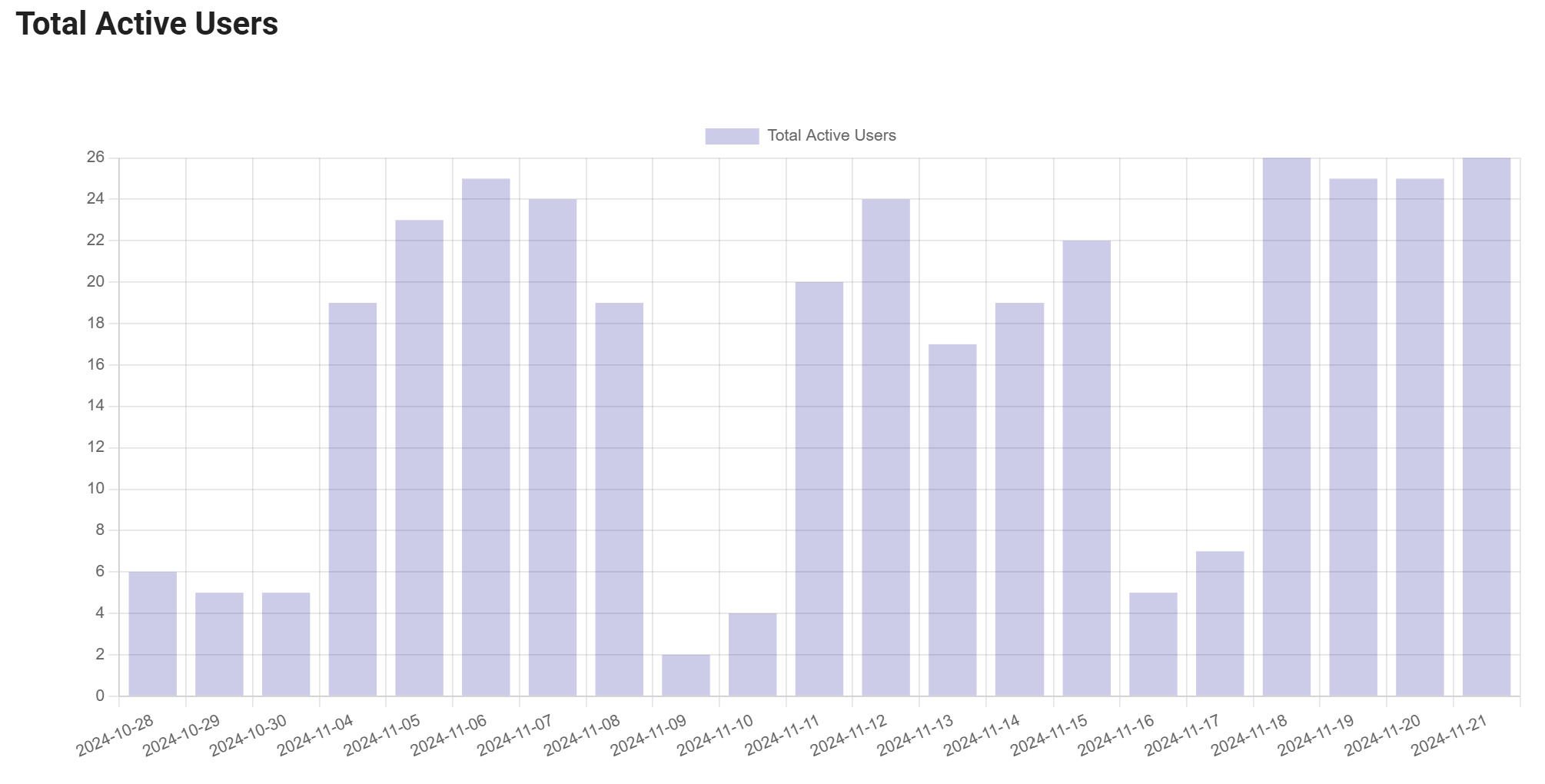
- 总活跃用户数:代表与 GitHub Copilot 互动的活跃用户数量。这有助于了解用户群体的增长和采用率。
语言细分分析
顶部展示了按接受提示数和接受率(按次数/按行数)排列的前 5 种语言的饼图。
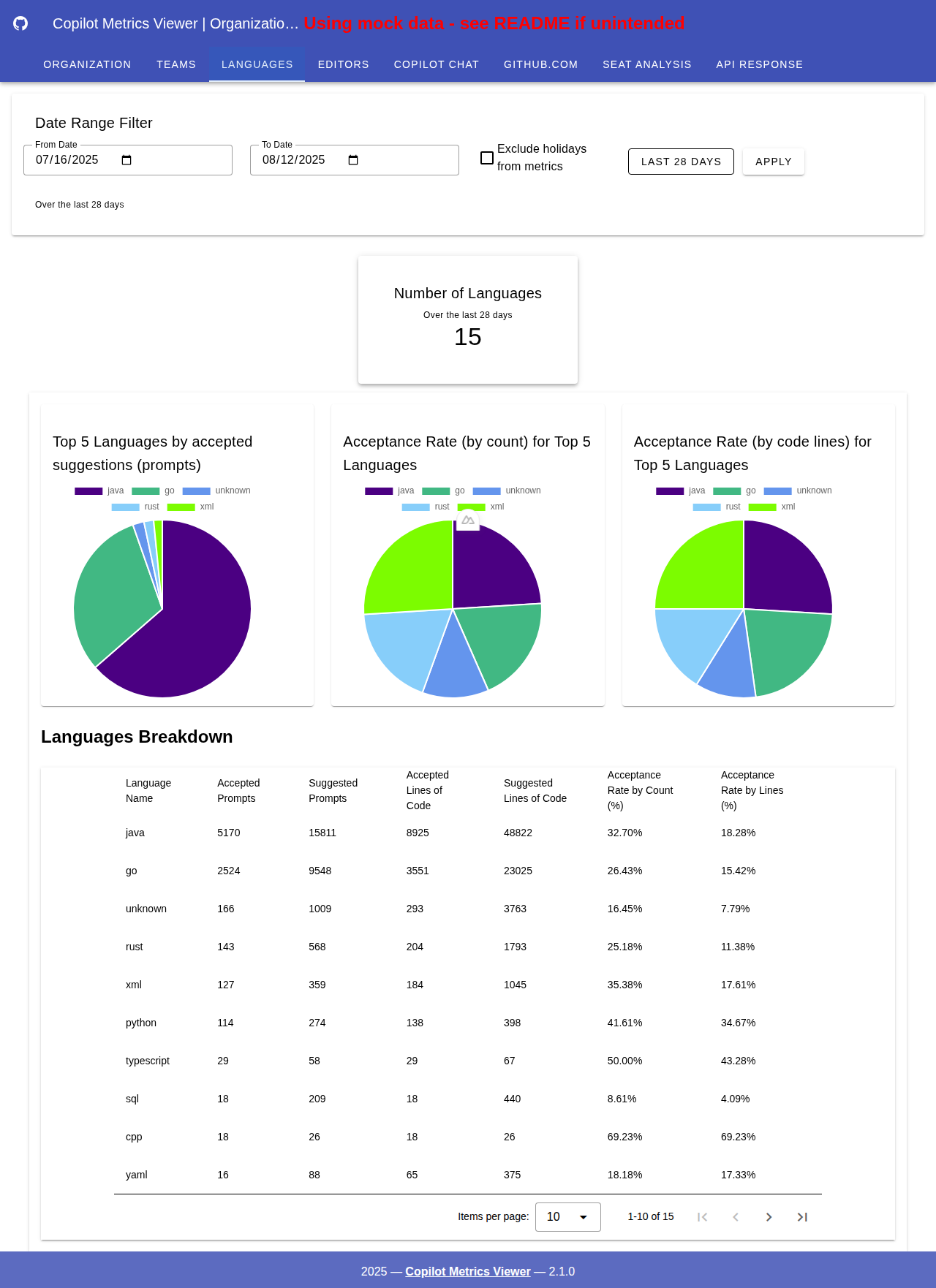
语言细分分析选项卡还显示了一个表格,列出所选时间段内每种语言的接受提示数、接受代码行数以及接受率(%)。条目按“接受代码行数降序”排列。
Copilot 聊天指标
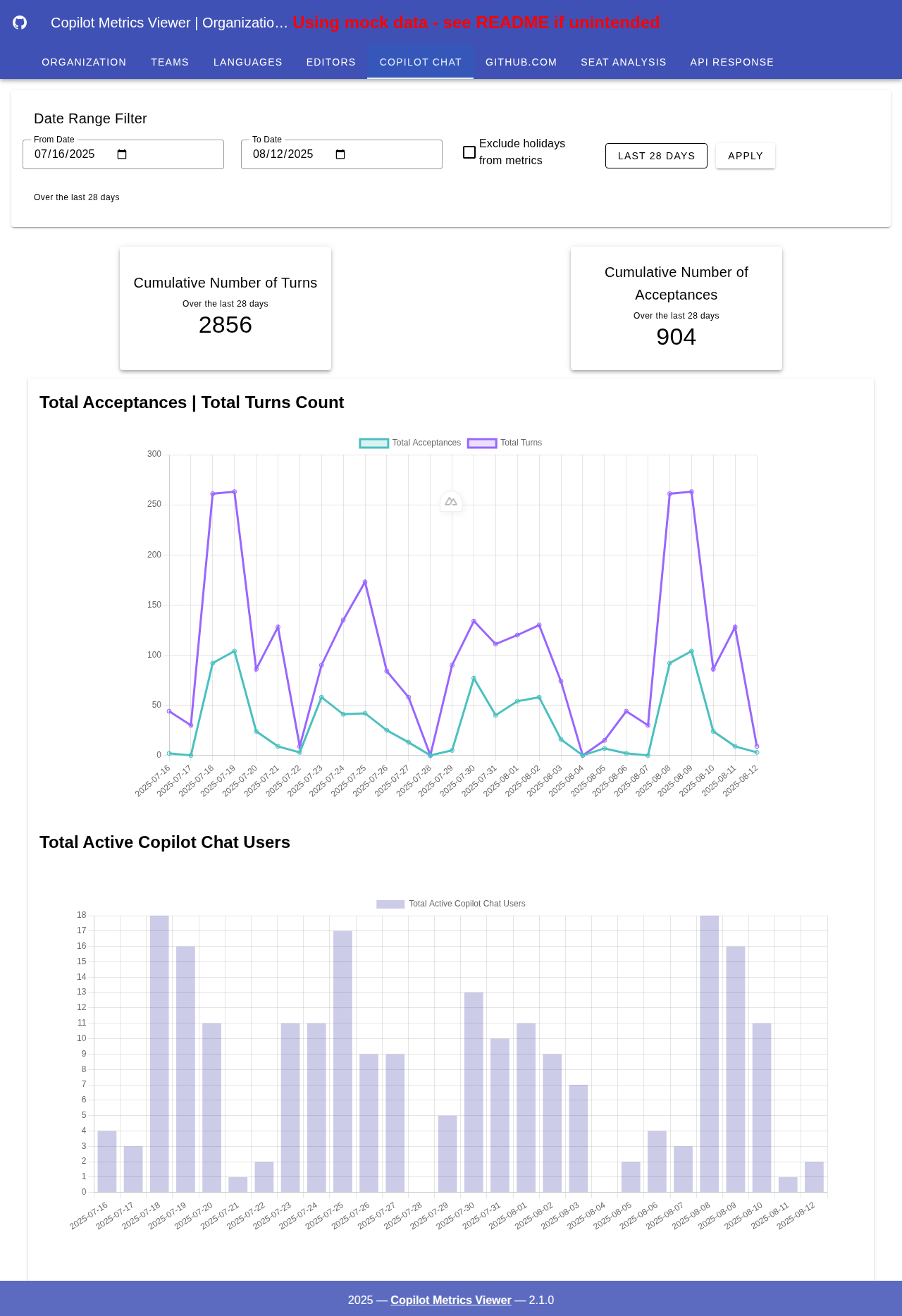
累计轮次总数:该指标表示在所选时间段内与 Copilot 的累计轮次(交互次数)。一轮包括用户输入和 Copilot 的回复。
累计接受总数:该指标显示在所选时间段内 Copilot 建议并被用户接受的代码行数总和。
总轮次 | 总接受数统计:这是一个展示总轮次和总接受数的图表。
总活跃 Copilot 聊天用户数:一个柱状图,展示了在所选时间段内与 Copilot 积极互动的用户总数。
使用席位分析
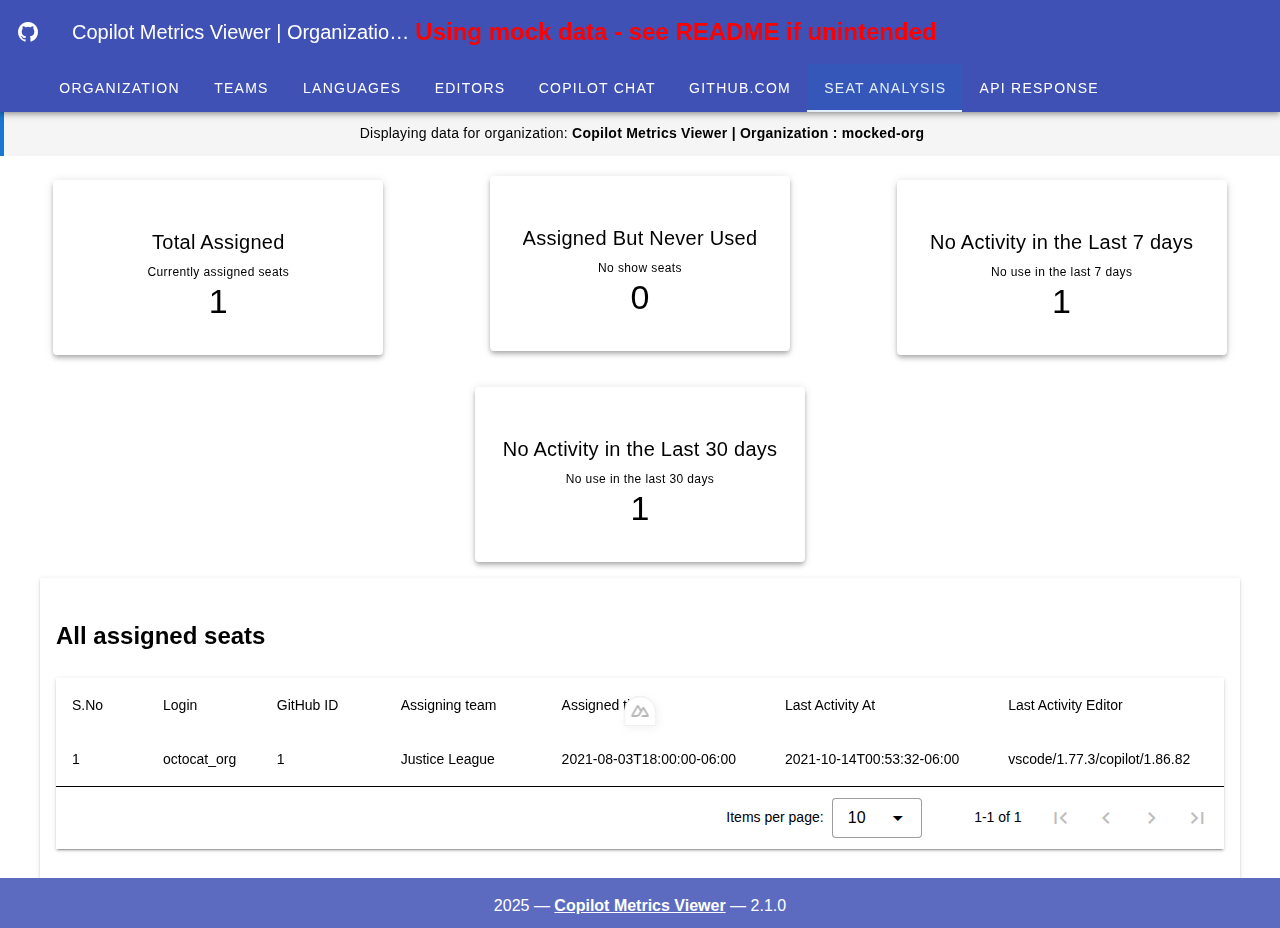
总分配席位数:该指标表示当前组织/企业中已分配的 Copilot 席位总数。
已分配但从未使用:该指标显示在当前组织/企业中已分配但从未使用的席位。图表中还显示了分配时间戳。
过去 7 天无活动:包括从未使用过的席位或虽曾使用但过去 7 天内无活动的席位。
过去 7 天无活动(含从未使用过的席位):一个表格,用于展示过去 7 天内无任何活动的席位,并按最后活动日期排序。较早使用过的席位将显示在顶部。
高级功能
灵活的日期范围选择
该应用支持灵活的日期范围选择,允许用户分析长达 100 天内的任意时间段的指标。日期选择器提供直观的日历界面,并可选择在分析中排除周末和节假日。
数据导出功能
API 响应选项卡中提供了多种导出选项:
- 下载 CSV(摘要):以精简格式导出关键指标
- 下载 CSV(完整):导出全面的详细数据
- 将指标复制到剪贴板:快速复制功能,便于即时使用
- 检查指标数据质量:验证数据的完整性和可靠性
团队分析
组织可以比较不同团队的指标,以:
- 识别高绩效团队
- 了解采用模式
- 在团队间分享最佳实践
- 监控各团队的参与度水平
[!NOTE] 团队指标基于每位用户的个人数据,通过解析 GitHub 团队成员关系并进行汇总得出。GitHub Copilot 使用情况指标 API 并没有专门的团队端点——本应用会自动计算团队视图。在直接 API 模式下,团队数据涵盖最近 28 天的数据;而在历史模式(使用 PostgreSQL)下,则可获取完整的团队历史趋势。
模型使用分析
对 AI 模型使用的详细洞察,包括:
- 各编辑器和模型类型的 IDE 代码补全情况
- IDE 聊天互动及模型偏好
- GitHub.com 聊天使用模式
- PR 摘要生成统计数据
- 自定义模型与默认模型的采用率
设置说明
在 .env 文件中,您可以配置多个环境变量来控制应用程序的行为。
公共变量:
NUXT_PUBLIC_IS_DATA_MOCKEDNUXT_PUBLIC_SCOPENUXT_PUBLIC_GITHUB_ENTNUXT_PUBLIC_GITHUB_ORGNUXT_PUBLIC_GITHUB_TEAMNUXT_PUBLIC_HIDDEN_TABSNUXT_PUBLIC_ENABLE_HISTORICAL_MODE
这些变量可以通过路由参数进行覆盖,例如:
http://localhost:3000/enterprises/octo-demo-enthttp://localhost:3000/orgs/octo-demo-orghttp://localhost:3000/orgs/octo-demo-org/teams/the-a-teamhttp://localhost:3000/enterprises/octo-demo-ent/teams/the-a-teamhttp://localhost:3000/orgs/mocked-org?mock=true
NUXT_PUBLIC_SCOPE(必填!)
.env 文件中的 NUXT_PUBLIC_SCOPE 环境变量决定了应用程序发起的 API 调用的默认作用域。它可以设置为 'enterprise'、'organization'、'team-organization' 或 'team-enterprise'。
- 如果设置为
'enterprise',应用程序将把 API 调用的目标指向在NUXT_PUBLIC_GITHUB_ENT变量中定义的 GitHub Enterprise 账户。 - 如果设置为
'organization',应用程序将把 API 调用的目标指向在NUXT_PUBLIC_GITHUB_ORG变量中定义的 GitHub Organization 账户。 - 如果设置为
'team-organization'或'team-enterprise',应用程序将显示基于指定组织或企业内NUXT_PUBLIC_GITHUB_TEAM中定义的团队成员个人数据得出的团队级别指标。
例如,如果您希望将 API 调用的目标指向某个组织,则可以在 .env 文件中设置 NUXT_PUBLIC_SCOPE=organization。
[!INFO] 具有
NUXT_PUBLIC作用域的环境变量可在浏览器中使用(即公开)。 详情请参阅 Nuxt 运行时配置。
NUXT_PUBLIC_SCOPE=organization
NUXT_PUBLIC_GITHUB_ORG=<YOUR-ORGANIZATION>
NUXT_PUBLIC_GITHUB_ENT=
NUXT_PUBLIC_GITHUB_TEAM
NUXT_PUBLIC_GITHUB_TEAM 环境变量用于筛选组织或企业账户中特定 GitHub 团队的指标。
‼️ 重要提示 ‼️ 当此变量被设置时,所有显示的指标都将仅与指定团队相关。若要查看整个组织或企业的指标,请移除此环境变量。
[!NOTE] 团队指标是 基于每位用户的个人数据 得出的,而非通过专门的团队 API 端点获取。应用程序会通过 GitHub Teams API 解析团队成员关系,并汇总团队成员的个人指标。对团队规模没有最低要求。
NUXT_PUBLIC_GITHUB_TEAM=
NUXT_PUBLIC_IS_DATA_MOCKED
该变量默认为 false。若要查看模拟数据,可将其设置为 true,或使用查询参数 ?mock=true。
NUXT_PUBLIC_IS_DATA_MOCKED=false
NUXT_GITHUB_TOKEN
指定用于 API 请求的 GitHub 个人访问令牌。生成此令牌时,请确保具备以下权限:读取成员信息、组织 Copilot 指标 和 组织 Copilot 座位管理。
[!IMPORTANT] v3.0 迁移: 新的 Copilot 使用情况指标 API 需要 读取成员信息、组织 Copilot 指标以及组织 Copilot 座位管理 权限。否则,新的 API 端点将返回 400/403 错误。有关设置详情,请参阅 GitHub 应用注册。
该令牌不会在前端使用。
NUXT_GITHUB_TOKEN=
NUXT_SESSION_PASSWORD(必填!)
此变量用于加密用户会话,长度至少为 32 个字符。更多信息请参阅 Nuxt 会话与认证。
[!WARNING] 从版本 2.0.0 开始,此变量为必填项。
NUXT_PUBLIC_USING_GITHUB_AUTH
默认值为 false。当设置为 true 时,将执行 GitHub OAuth 应用程序认证,以验证用户对仪表板的访问权限。为此,必须在企业或组织中注册并安装一个 GitHub 应用程序。有关步骤,请参阅 GitHub 应用程序注册。
GitHub 认证所需的变量包括:
NUXT_OAUTH_GITHUB_CLIENT_ID- GitHub 应用程序的客户端 ID。NUXT_OAUTH_GITHUB_CLIENT_SECRET- GitHub 应用程序的客户端密钥。- [可选]
NUXT_OAUTH_GITHUB_CLIENT_SCOPE,用于在使用 OAuth 应用程序而非 GitHub 应用程序时请求范围。详情请参阅 GitHub 文档。
[!WARNING] 只有具备相应权限(如 NUXT_GITHUB_TOKEN 中列出的范围)的用户才能查看 Copilot 指标。GitHub 会根据已认证用户的权限发起 API 调用来获取数据。
NUXT_PUBLIC_HIDDEN_TABS
逗号分隔的仪表板选项卡名称列表,用于隐藏这些选项卡。此设置在启动时生效,无需重新构建——对于预构建的 Docker 部署非常有用。过滤不区分大小写,并会去除前后空格。
可用选项卡名称:languages、editors、copilot chat、agent activity、pull requests、github.com、seat analysis、user metrics、api response
# 隐藏“Agent Activity”和“API Response”选项卡
NUXT_PUBLIC_HIDDEN_TABS=agent activity,api response
NUXT_PUBLIC_ENABLE_HISTORICAL_MODE
默认值为 false。当设置为 true 时,应用程序将使用 PostgreSQL 数据库(通过 DATABASE_URL 配置)来存储和查询历史 Copilot 指标。
[!IMPORTANT] 当
NUXT_PUBLIC_ENABLE_HISTORICAL_MODE不为true时,Teams 选项卡会自动隐藏。团队级别的指标是从数据库中的每日用户记录(user_day_metrics表)中得出的。如果没有数据库,团队比较选项卡将显示每个团队完全相同的组织级数据。
NUXT_PUBLIC_ENABLE_HISTORICAL_MODE=false
HTTP_PROXY
在企业环境中运行时,解决方案支持 HTTP 代理设置。只需设置 HTTP_PROXY 环境变量即可。
对于自定义 CA 证书,请使用环境变量 CUSTOM_CA_PATH 将证书加载到代理代理选项中。
NITRO_PORT
Dockerfile 中的默认值为 80,它定义了 Nitro(Nuxt 的服务器引擎)将监听的端口号。
例如,如果应用程序以非 root 用户身份运行,则应将其设置为 1024 到 49151 之间的数字。
安装依赖
npm install
编译并运行应用程序
npm run dev
构建 Docker 镜像
docker build -t copilot-metrics-viewer .
运行 Docker 容器
docker run -p 8080:80 --env-file ./.env copilot-metrics-viewer
应用程序将可通过 http://localhost:8080 访问。
健康检查端点
为 Kubernetes 部署和健康监控,该应用提供了专用的健康检查端点,这些端点无需身份验证且不会发起外部 API 调用:
/api/health- 通用健康检查端点/api/ready- 就绪性探针端点/api/live- 存活性探针端点
所有端点均返回包含状态信息的 JSON 响应,并在约 200 毫秒内完成响应,因此非常适合用于 Kubernetes 的健康检查,而非使用会触发 GitHub API 调用的根路径 / 端点。
Kubernetes 配置示例
livenessProbe:
httpGet:
path: /api/live
port: 80
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /api/ready
port: 80
initialDelaySeconds: 5
periodSeconds: 5
许可证
本项目采用 MIT 开源许可证条款进行许可。完整条款请参阅 MIT。
维护者
支持
本项目由独立开发者开发和维护,并非 GitHub 官方产品。它得益于 (@martedesco)、(@karpikpl) 以及我们优秀的贡献者们的辛勤付出而蓬勃发展。衷心感谢所有贡献者!✨
我计划通过 GitHub Issues 提供支持。尽管我会尽力保持响应,但无法保证即时回复。如遇紧急问题,请在标题中注明“CRITICAL”,以便更快得到处理。🙏🏼
版本历史
v3.1.02026/04/16v3.0.32026/04/05v3.0.22026/03/30v3.0.12026/03/29v3.0.02026/03/20v2.1.42026/02/24v2.1.32026/02/16v2.1.22025/09/13v2.1.12025/08/12v2.1.02025/08/09v2.0.72025/07/14v2.0.62025/07/08v2.0.52025/07/08v2.0.42025/06/06v2.0.32025/02/25v2.0.22025/02/18v2.0.12025/02/06v2.0.02025/02/04v1.9.12025/02/01v2.0.0-preview2025/01/30常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。