mlops-python-package
mlops-python-package 是一个专为机器学习运维(MLOps)打造的 Python 项目模板,旨在帮助团队快速启动并标准化数据管道与模型开发流程。它解决了 MLOps 实践中常见的代码结构混乱、工具链分散以及缺乏统一规范等痛点,让开发者无需从零搭建基础设施,即可拥有具备生产级质量的代码库。
这款工具特别适合从事机器学习工程化的开发人员、数据科学家以及希望构建稳健 AI 平台的团队使用。其核心亮点在于“开箱即用”的最佳实践集成:在代码质量方面,内置了 Ruff 格式化、Mypy 类型检查及 Pytest 测试框架;在配置管理上,结合 OmegaConf 与 Pydantic 实现灵活且安全的参数验证;同时原生支持 MLflow 进行模型追踪与注册,并配备 GitHub Actions 自动化流水线。此外,它还提供了从数据校验(Pandera)到文档生成的完整工具链。通过 mlops-python-package,用户可以专注于核心算法与业务逻辑,轻松构建灵活、健壮且易于维护的机器学习系统。
使用场景
某金融科技公司的数据科学团队正在构建一个实时反欺诈模型,需要频繁迭代算法并满足严格的合规审计要求。
没有 mlops-python-package 时
- 环境混乱难复现:每位成员自行配置依赖和目录结构,导致“在我机器上能跑”的代码无法在测试或生产环境中运行。
- 质量管控靠人工:缺乏统一的代码格式化、类型检查和安全性扫描流程,低级错误常流入生产环节,引发线上故障。
- 模型追踪缺失:实验参数、数据集版本和模型指标散落在本地笔记或临时文件中,无法满足审计对模型全生命周期可追溯的要求。
- 部署流程繁琐:从代码提交到生成 Docker 镜像缺乏自动化流水线,每次发布需手动打包,耗时且容易出错。
使用 mlops-python-package 后
- 标准化项目骨架:直接套用预置的最佳实践模板,统一了配置管理(OmegaConf)、数据结构(Pandera)和日志规范,确保任何环境下一键复现。
- 自动化质量门禁:集成 Ruff、Mypy 和 Bandit 等工具至 Git 钩子与 CI 流程,自动拦截格式错误、类型不匹配及安全漏洞,代码质量显著提升。
- 全链路模型治理:内置 MLflow 支持,自动记录实验轨迹、注册模型版本并关联数据血缘,轻松生成符合合规要求的审计报告。
- 一键持续交付:基于 GitHub Actions 构建标准化流水线,实现从代码提交到 Wheel 包发布及 Docker 镜像构建的全自动化,发布效率提升数倍。
mlops-python-package 通过提供一套工业级的标准模板与自动化工具链,将碎片化的 MLOps 实践转化为高效、可靠且可审计的工程体系。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
MLOps Python 包
![]()
![]()
![]()


此仓库包含一个基于最佳实践的 Python 代码库,旨在支持您的 MLOps 计划。
该包利用多种 工具 和 技巧 来使您的 MLOps 体验尽可能灵活、稳健且高效。
您可以将此包用作 MLOps 工具箱或平台的一部分(例如,模型注册表、实验跟踪、实时推理等)。
相关资源:
- LLMOps 编码包(示例):包含最佳实践和工具的示例,用于支持您的 LLMOps 项目。
- MLOps 编码课程(学习):学习如何创建、开发和维护最先进的 MLOps 代码库。
- Cookiecutter MLOps 包(模板):开始构建和部署用于 MLOps 任务的 Python 包和 Docker 镜像。
- 智能体技能(资源):通过标准化的 MLOps 和编码技能提升您的 AI 智能体能力。
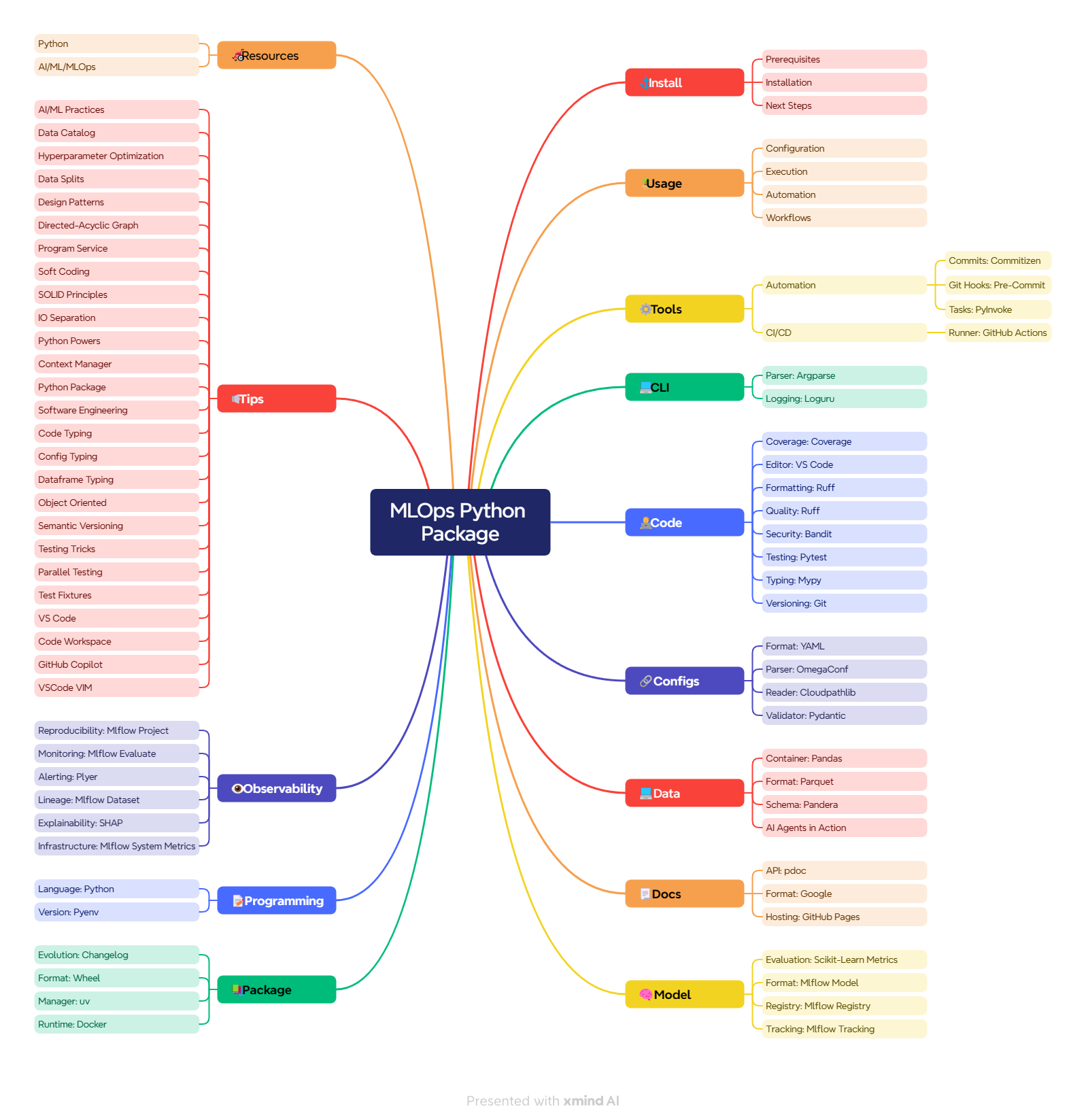
目录
安装
本节详细介绍了启动您的 MLOps 项目所需的条件、操作步骤及后续安排。
先决条件
- Python>=3.13:以充分利用 最新功能和性能改进
- uv>=0.5.5:用于初始化项目的 虚拟环境及其依赖项
安装
- 将此 GitHub 仓库 克隆到您的计算机
# 推荐使用 SSH
$ git clone git@github.com:fmind/mlops-python-package
# 或使用 HTTPS
$ git clone https://github.com/fmind/mlops-python-package
- 使用 uv 运行项目安装
cd mlops-python-package/
uv sync
- 根据您的需求调整代码库
后续步骤
在此基础上,您可以通过多种方式将此包集成到您的 MLOps 平台中。
例如,您可以使用 Databricks 或 AWS 作为计算平台和模型注册表。
具体如何调整包中的代码以适配您的目标解决方案,完全取决于您自己。祝您成功!
使用方法
本节介绍如何配置项目代码并在您的系统上执行它。
配置
您可以在 confs/ 文件夹中添加或编辑配置文件,以更改程序的行为。
# confs/training.yaml
job:
KIND: TrainingJob
inputs:
KIND: ParquetReader
path: data/inputs_train.parquet
targets:
KIND: ParquetReader
path: data/targets_train.parquet
此配置文件指示程序启动一个 TrainingJob,包含两个参数:
inputs: 包含模型输入的数据集targets: 包含模型目标的数据集
您可以在 src/[package]/jobs/*.py 文件中找到程序的所有参数。
您还可以使用 uv run bikes --schema 打印该包支持的完整模式。
执行
在开发过程中,您可以使用 uv 来执行项目代码:
uv run [package] confs/tuning.yaml
uv run [package] confs/training.yaml
uv run [package] confs/promotion.yaml
uv run [package] confs/inference.yaml
uv run [package] confs/evaluations.yaml
uv run [package] confs/explanations.yaml
在生产环境中,您可以将项目构建、打包并作为 Python 包运行:
uv build
uv publish # 可选
python -m pip install [package]
[package] confs/inference.yaml
您也可以将此包安装为库,供其他 AI/ML 项目使用:
from [package] import jobs
job = jobs.TrainingJob(...)
with job as runner:
runner.run()
附加提示:
- 您可以通过命令行使用
--extras标志传递额外的配置- 可用于传递运行时值(例如,先前作业执行的结果)
- 您可以在命令行中传递多个配置文件,它们会从左到右合并
- 您可以定义作业之间共享的通用配置(例如,模型参数)
- 由于 Pydantic 的区分联合类型,将自动选择正确的作业任务
- 这是运行应用程序支持的任何作业(训练、调参等)的绝佳方式
自动化
此项目包含多项自动化任务,可轻松重复常见操作。
您可以通过 命令行 或 VS Code 扩展 调用这些操作。
# 执行项目 DAG
$ just project
# 创建代码归档
$ just package
# 列出其他操作
$ just
可用任务:
default # 显示帮助信息
[check]
check # 运行检查任务
check-code # 检查代码质量
check-coverage numprocesses="auto" cov_fail_under="80" # 检查代码覆盖率
check-format # 检查代码格式
check-security # 检查代码安全
check-test numprocesses="auto" # 检查单元测试
check-type # 检查代码类型
[clean]
clean # 运行清理任务
clean-build # 清理构建文件夹
clean-cache # 清理缓存文件夹
clean-constraints # 清理约束文件
clean-coverage # 清理覆盖率文件
clean-docs # 清理文档文件夹
clean-environment # 清理环境文件
clean-mlruns # 清理 mlruns 文件夹
clean-mypy # 清理 mypy 文件夹
clean-outputs # 清理输出文件夹
clean-pytest # 清理 pytest 缓存
clean-python # 清理 Python 缓存
clean-requirements # 清理需求文件
clean-ruff # 清理 ruff 缓存
clean-venv # 清理 venv 文件夹
[commit]
commit-bump # 提升包版本
commit-files # 提交包
commit-info # 获取提交信息
[doc]
doc # 运行文档任务
doc-build format="google" output="docs" # 构建文档
doc-serve format="google" port="8088" # 提供文档服务
[docker]
docker # 运行 Docker 任务
docker-build tag="latest" # 构建 Docker 镜像
docker-compose # 启动 Docker Compose
docker-run tag="latest" # 运行最新版 Docker 镜像
[format]
format # 运行格式化任务
format-import # 格式化代码导入
format-source # 格式化代码源
[install]
install # 运行安装任务
install-hooks # 安装 Git 钩子
install-project # 安装项目
install-rulesets # 安装 GitHub 规则集
[mlflow]
mlflow # 运行 MLflow 任务
mlflow-doctor # 运行 MLflow 医生
mlflow-serve host="127.0.0.1" port="5000" uri="./mlruns" # 启动 MLflow 服务器
[package]
package # 运行打包任务
package-build constraints="constraints.txt" # 构建 Python 包
package-constraints constraints="constraints.txt" # 构建包约束
[project]
project # 运行项目任务
project-environment # 导出环境文件
project-requirements # 导出需求文件
project-run job # 使用 MLflow 运行项目作业
工作流
此包在 .github/workflows 中支持两个 GitHub 工作流:
check.yml: 在每次 Pull Request 上验证包的质量publish.yml: 在代码发布时构建并发布文档和包。
您可以使用并扩展这些工作流来自动化重复性的包管理任务。
工具
本节旨在鼓励使用开发者工具来提升您的编码体验。
自动化
预定义的操作,用于自动化您的项目开发。
AI 助手:Gemini Code Assist
- 动机:
- 提高您的编码效率
- 获取代码建议和补全
- 减少审查代码的时间
- 局限性:
- 可能生成错误的代码、评论或摘要
提交:Commitizen
Dependabot:Dependabot
- 动机:
- 避免安全问题
- 避免破坏性更改
- 更新您的依赖项
- 局限性:
- 可能破坏您的代码
- 替代方案:
- 自己动手 (DIY)
Git 钩子:Pre-Commit
- 动机:
- 在提交前本地检查您的代码
- 避免在 CI/CD 上浪费资源
- 可以执行额外的动作(例如,清理文件)
- 局限性:
- 在提交前增加开销
- 替代方案:
- Git 钩子:使用起来不太方便
任务:Just
- 动机:
- 自动化项目工作流
- 语法清晰,优于其他工具
- 在功能强大与简单易用之间取得了良好平衡
- 局限性:
- 大多数开发者并不熟悉
- 替代方案:
CI/CD
在代码推送和发布时执行自动化工作流。
运行器:GitHub Actions
- 动机:
- 原生集成于 GitHub
- 工作流语法简单
- 如有需要可进行大量配置
- 局限性:
- SaaS 服务
- 替代方案:
- GitLab:可部署在本地
CLI
与系统命令行界面(CLI)的集成。
解析器:Argparse
- 动机:
- 提供 CLI 参数
- 内置于 Python 运行时
- 对于提供配置已足够
- 局限性:
- 对于高级解析较为冗长
- 替代方案:
日志记录:Loguru
- 动机:
- 向用户展示进度
- 开箱即用,效果良好
- 日志语法更加清晰
- 局限性:
- 不允许偏离基础用法
- 替代方案:
- Logging:默认可用,但显得有些过时
代码
项目源代码的编辑、验证和版本控制。
覆盖率:Coverage
- 动机:
- 报告被测试覆盖的代码
- 确定待测试的代码路径
- 向用户展示代码成熟度
- 局限性:
- 无
- 替代方案:
- Pytest Cov:一个使用
coverage.py来衡量代码覆盖率的 Pytest 插件。
- Pytest Cov:一个使用
编辑器:VS Code
- 动机:
- 开源
- 免费、简单且开源
- 拥有优秀的 Python 开发插件
- 局限性:
- 需要为 Python 进行一些配置
- 替代方案:
格式化:Ruff
- 动机:
- 相较于其他工具速度极快
- 不必浪费时间整理代码
- 使代码更具可读性和可维护性
- 局限性:
- 仍处于 0.x 版本,但采用率越来越高
- 替代方案:
质量:Ruff
- 动机:
- 提升代码质量
- 相较其他工具速度极快
- 与 VS Code 的出色集成
- 局限性:
- 无
- 替代方案:
安全性:Bandit
- 动机:
- 检测安全问题
- 作为 linting 解决方案的补充
- 使用和启用都不算复杂
- 局限性:
- 无
- 替代方案:
- 无
测试:Pytest
- 动机:
- 编写测试,否则将付出代价
- 极易编写新的测试用例
- 拥有大量优秀的插件(xdist、sugar、cov 等)
- 局限性:
- 默认不支持并行执行
- 替代方案:
- Unittest:语法更为冗长,趣味性较低
类型检查:Mypy
- 动机:
- 静态类型检查很酷!
- 可以明确类型用途
- Python 的官方类型检查工具
- 局限性:
- 复杂类型检查可能会带来额外开销
- 替代方案:
版本控制:Git
- 动机:
- 如果不进行版本控制,那真是愚蠢
- 最流行的源代码管理工具(还能有什么选择呢?)
- 提供钩子,可在特定事件发生时执行自动化操作
- 局限性:
- Git 可能比较难掌握:https://xkcd.com/1597/
- 替代方案:
- Mercurial:过去很喜欢它,但现在 Git 才是唯一的选择
配置
管理项目的配置文件,以便调整执行行为。
格式:YAML
- 动机:
- 在不修改代码的情况下改变执行方式
- 语法易读,支持注释
- 可以使用 OmegaConf <3
- 局限性:
- Python 默认不支持 YAML
- 替代方案:
解析器:OmegaConf
- 动机:
- 解析并合并 YAML 文件
- 功能强大,不会妨碍你的工作
- 几行代码就能完成大量任务
- 局限性:
- 不支持远程文件(如 s3、gcs 等)
- 可以将其与 cloudpathlib 结合使用
- 不支持远程文件(如 s3、gcs 等)
- 替代方案:
文件读取器:Cloudpathlib
- 动机:
- 从云存储中读取文件
- 与云平台的集成更好
- 支持多个平台:AWS、GCP 和 Azure
- 局限性:
- 目前对 Python 类型的支持还不够完善
- 替代方案:
- 云 SDK(GCP、AWS、Azure 等):厂商专用,对于此任务来说过于复杂
验证器:Pydantic
- 动机:
- 在执行前验证配置
- Pydantic 应该是内置的(就这么简单)
- 极大地增强你的 Python 类
- 局限性:
- 无
- 替代方案:
数据
定义数据集,以提供数据输入和输出。
容器:Pandas
- 动机:
- 将数据文件加载到内存中
- Python 的通用数据交换格式
- 最流行的选择
- 局限性:
- 存在许多陷阱 gotchas
- 替代方案:
格式:Parquet
模式:Pandera
- 动机:
- 为 DataFrame 提供类型注解
- 明确数据字段的含义
- 支持 Pandas 及其他库 others
- 局限性:
- 无
- 替代方案:
- Great Expectations:功能强大,但集成难度大得多
文档
生成并分享项目文档。
API:pdoc
- 动机:
- 与他人共享文档
- 工具简单,仅用于生成 API 文档
- 快速完成任务,不拖后腿
- 局限性:
- 仅支持 API 文档(即无法生成自定义文档)
- 替代方案:
格式:Google
托管:GitHub Pages
- 动机:
- 设置简单
- 免费且便捷
- 与 GitHub 无缝集成
- 局限性:
- 仅支持静态内容
- 替代方案:
- ReadTheDocs:提供更多功能
模型
处理机器学习模型的工具集。
评估:Scikit-Learn Metrics
- 动机:
- 提供常用指标
- 避免重复造轮子
- 避免实现错误
- 局限性:
- 可选择的指标种类有限
- 替代方案:
- 自行实现:用于自定义指标
格式:Mlflow Model
- 动机:
- 标准化的机器学习模型格式
- 存储模型依赖项
- 拥有强大的社区生态
- 局限性:
- 无
- 替代方案:
- Pickle:开箱即用,但不适合大型数组
- ONNX:非常适合深度学习,但与其他框架的兼容性无法保证 no guaranteed compatibility for the rest
注册表:Mlflow Registry
- 动机:
- 保存和加载模型
- 将生产环境与消费环境分离
- 流行、开源,可在本地系统上运行
- 局限性:
- 无
- 替代方案:
- Neptune.ai:SaaS 解决方案
- Weights and Biases:SaaS 解决方案
追踪:Mlflow Tracking
- 动机:
- 跟踪指标和超参数
- 可以比较不同模型的表现
- 流行、开源,可在本地系统上运行
- 局限性:
- 无
- 替代方案:
- Neptune.ai:SaaS 解决方案
- Weights and Biases:SaaS 解决方案
包
定义并构建现代 Python 包。
变更日志:Changelog
- 动机:
- 向用户传达变更信息
- 可以使用 Commitizen 更新
- 遵循 Keep a Changelog 的标准化格式
- 局限性:
- 无
- 替代方案:
- 无
格式:Wheel
- 动机:
- 具有多项优势 has several advantages
- 创建源代码归档
- 当前最现代的 Python 格式
- 局限性:
- 不包含 C/C++ 依赖项(例如 CUDA)
- 即在这种情况下应使用 Docker 容器
- 不包含 C/C++ 依赖项(例如 CUDA)
- 替代方案:
管理器:uv
- 动机:
- 定义并构建 Python 包
- 快速且符合标准的包管理器
- 将所有元数据打包成一个静态文件
- 局限性:
- 无法添加 Python 之外的依赖项(例如 CUDA)
- 即在这种情况下应使用 Docker 容器
- 无法添加 Python 之外的依赖项(例如 CUDA)
- 替代方案:
- Setuptools:动态文件速度较慢且风险较高
- Poetry:该包的前身解决方案
- Pdm、Hatch、PipEnv:https://xkcd.com/1987/
运行时:Docker
- 动机:
- 创建隔离的运行环境
- 容器已成为事实上的标准
- 可以将 C/C++ 依赖项随项目一起打包
- 局限性:
- 有些公司可能会阻止使用 Docker Desktop,此时应考虑其他替代方案
- 替代方案:
- Conda:解析速度慢且资源占用高
编程
选择你的编程环境。
语言:Python
版本:Uv
- 动机:
- 在不同 Python 版本之间切换
- 允许选择最佳版本
- 支持全局和局部调度
- 局限性:
- 需要进行一些 shell 配置
- 替代方案:
- 手动安装:耗时较长
- PyEnv:基于 shell,需要更多设置
可观测性
可复现性:Mlflow Project
- 动机:
- 共享通用的项目格式
- 确保项目可以被重复使用
- 避免项目执行中的随机性
- 局限性:
- Mlflow Project 最适合小型项目
- 替代方案:
- DVC:同时管理数据和模型
- Metaflow:专注于机器学习
- Apache Airflow:适用于大型项目
监控:Mlflow Evaluate
- 动机:
- 计算模型指标
- 使用阈值验证模型
- 进行训练后的评估
- 局限性:
- Mlflow Evaluate 的功能相比其他工具较为有限
- 替代方案:
告警:Plyer
血缘关系:Mlflow Dataset
- 动机:
- 将信息存储在 Mlflow 中
- 跟踪运行时数据集的元数据
- 保留数据集来源的 URI(例如网站)
- 局限性:
- 功能不如其他解决方案丰富
- 替代方案:
- Databricks Lineage:仅限于 Databricks
- OpenLineage 和 Marquez:开源且灵活
可解释性:SHAP
- 动机:
- 最流行的工具包
- 支持多种模型(线性模型等)
- 可通过 SHAP 模块 与 Mlflow 集成
- 局限性:
- 处理大规模数据集时速度极慢
- Mlflow SHAP 模块尚不成熟
- 替代方案:
- LIME:目前已不再维护
基础设施:Mlflow System Metrics
- 动机:
- 跟踪基础设施信息(RAM、CPU 等)
- 与 Mlflow 跟踪系统集成
- 提供硬件洞察
- 局限性:
- 功能不如其他解决方案成熟
- 替代方案:
- Datadog:流行且成熟的解决方案
技巧
本节提供一些技巧和窍门,以提升开发体验。
AI/ML 实践
数据目录
应将数据指针与其访问方式解耦。
在代码中,您可以使用标签(如 inputs、targets)来引用数据集。
然后,可以在配置文件中将这些标签与具体的读写器实现关联:
inputs:
KIND: ParquetReader
path: data/inputs_train.parquet
targets:
KIND: ParquetReader
path: data/targets_train.parquet
在此软件包中,实现位于 src/[package]/io/datasets.py,并通过 KIND 来选择。
超参数优化
应使用优化搜索方法为模型选择最佳超参数。
对于最简单的项目,可以使用 sklearn.model_selection.GridSearchCV 来遍历整个搜索空间。
此软件包在 src/[package]/utils/searchers.py 中提供了该超参数搜索功能的简单接口。
对于更复杂的项目,建议采用更复杂的策略(如 贝叶斯优化)和相应的软件包(如 Optuna)。
数据划分
应将数据集合理划分为训练集、验证集和测试集。
- 训练集:用于拟合模型参数
- 验证集:用于寻找最佳超参数
- 测试集:用于评估最终模型性能
各集合应互斥,且测试集绝不能用作训练输入!
此软件包在 src/[package]/utils/splitters.py 中实现了一种简单的确定性划分策略。
设计模式
有向无环图
应使用有向无环图(DAG)连接您的 ML 流水线步骤。
DAG 可以表达步骤之间的依赖关系,同时保持每个步骤的独立性。
此软件包在 tasks/project.just 中提供了一个 DAG 示例。该方法基于 Just,并在上述自动化部分进行了说明。
在生产环境中,我们建议使用可扩展的系统,如 Airflow、Dagster、Prefect、Metaflow 或 ZenML。
程序服务
应为程序的执行提供一个全局上下文。
此软件包受到 Clojure mount 的启发,在 src/[package]/io/services.py 中提供了实现。
软编码
应将程序实现与程序配置分离。
向用户暴露配置可以让用户在不修改代码的情况下影响程序的行为。
此软件包旨在将尽可能多的参数暴露给用户,并将其存储在 confs/ 文件夹中。
SOLID 原则
你应该实现 SOLID 原则,以使你的代码尽可能灵活。
- 单一职责原则:一个类只负责一项职责。每当需求发生变化时,只需修改一个类即可。
- 开闭原则:类对被他人使用持开放态度;但对被他人修改则持封闭态度。
- 里氏替换原则:任何子类都可以替换其父类。子类继承了父类的行为。
- 接口隔离原则:当类之间相互承诺时,应将这些承诺(接口)拆分为多个小的、更易理解的接口。
- 依赖倒置原则:当类之间以非常具体的方式交互时,它们会相互依赖,从而导致难以更改。相反,类应该通过接口或抽象基类进行交互,这样即使类本身发生变化,只要遵守接口约定,就不会影响整体。
在实践中,这意味着你可以使用接口来定义软件契约,并轻松切换其实现。
例如,你可以在 src/[package]/jobs/*.py 中实现多个任务,并在配置中灵活切换它们。
要了解更多关于本包所选机制的信息,可以查阅 Pydantic 标记联合体 的文档。
IO 分离
你应该将与外部世界交互的代码与其他部分分离。
外部环境往往杂乱无章且充满风险:文件缺失、权限问题、磁盘空间不足等。
为了隔离这些风险,你可以将所有相关代码放入一个 io 包中,并使用接口来管理。
Python 功能
上下文管理器
你应该使用 Python 上下文管理器来控制和增强代码的执行流程。
Python 提供了上下文管理器,可用于扩展代码块的功能。例如:
# 在 src/[package]/scripts.py 中
with job as runner: # 上下文
runner.run() # 在上下文中执行
这种模式与功能强大的编程模式 Monad 具有相似的优势。
该包使用 src/[package]/jobs/*.py 来处理异常和提供服务。
Python 包
你应该创建 Python 包,以便为他人提供库和应用程序。
在你的 AI/ML 项目中使用 Python 包具有以下优势:
- 构建可上传到 PyPI 的代码归档(即 wheel 文件)。
- 将 Python 包作为库安装(例如,像 pandas 一样)。
- 暴露脚本入口点,以运行 CLI 或 GUI。
使用 uv 构建 Python 包时,只需在终端中输入以下命令:
# 对于所有 uv 项目
uv build
# 仅针对该项目
inv packages
软件工程
代码类型注解
你应该为你的 Python 代码添加类型注解,使其更加健壮并明确地向用户传达意图。
Python 提供了 typing 模块 用于添加类型提示,并使用 mypy 来检查这些类型提示。
# 在 src/[package]/core/models.py 中
@abc.abstractmethod
def fit(self, inputs: schemas.Inputs, targets: schemas.Targets) -> "Model":
"""根据给定的输入和目标拟合模型。"""
@abc.abstractmethod
def predict(self, inputs: schemas.Inputs) -> schemas.Outputs:
"""根据给定的输入生成输出。"""
这段代码清晰地说明了方法的输入和输出,既便于开发者理解,也便于类型检查工具验证。
该包旨在为所有函数和类添加类型注解,以提升开发体验并在运行前发现错误。
配置类型注解
你应该为你的配置添加类型注解,以避免程序运行时出现异常。
Pydantic 允许定义类,在程序启动时验证配置的有效性。
# 在 src/[package]/utils/splitters.py 中
class TrainTestSplitter(Splitter):
shuffle: bool = False # 必填项(时间敏感)
test_size: int | float = 24 * 30 * 2 # 2 个月
random_state: int = 42
这段代码明确了预期的配置值,有助于避免本可以避免的错误。
该包结合 OmegaConf 和 Pydantic,以尽早解析并验证 YAML 配置文件。
数据框类型注解
你应该为你的数据框添加类型注解,以明确其字段并进行验证。
Pandera 支持 Pandas 及其他库(如 PySpark)的数据框类型注解:
# 在 src/package/schemas.py 中
class InputsSchema(Schema):
instant: papd.Index[papd.UInt32] = pa.Field(ge=0, check_name=True)
dteday: papd.Series[papd.DateTime] = pa.Field()
season: papd.Series[papd.UInt8] = pa.Field(isin=[1, 2, 3, 4])
yr: papd.Series[papd.UInt8] = pa.Field(ge=0, le=1)
mnth: papd.Series[papd.UInt8] = pa.Field(ge=1, le=12)
hr: papd.Series[papd.UInt8] = pa.Field(ge=0, le=23)
holiday: papd.Series[papd.Bool] = pa.Field()
weekday: papd.Series[papd.UInt8] = pa.Field(ge=0, le=6)
workingday: papd.Series[papd Bool] = pa.Field()
weathersit: papd.Series[papd.UInt8] = pa.Field(ge=1, le=4)
temp: papd.Series[papd.Float16] = pa.Field(ge=0, le=1)
atemp: papd.Series[papd Float16] = pa.Field(ge=0, le=1)
hum: papd.Series[papd Float16] = pa.Field(ge=0, le=1)
windspeed: papd.Series[papd Float16] = pa.Field(ge=0, le=1)
casual: papd.Series[papd UInt32] = pa.Field(ge=0)
registered: papd.Series[papd UInt32] = pa.Field(ge=0)
这段代码定义了数据框的字段及其约束条件。
该包鼓励为 src/[package]/core/schemas.py 中使用的每个数据框添加类型注解。
面向对象编程
你应该使用面向对象编程,以充分利用 多态性。
结合 SOLID 原则,多态性使得代码组件的替换变得非常容易。
class Reader(abc.ABC, pdt.BaseModel):
@abc.abstractmethod
def read(self) -> pd.DataFrame:
"""从数据集中读取数据框。"""
这段代码使用 abc 模块 定义了一个包含读写方法的数据集接口。
该包尽可能多地定义类接口,以为你的 AI/ML 项目提供直观且可替换的组件。
语义版本控制
你应该使用语义版本控制来传达你发布的版本之间的兼容性级别。
语义版本控制(SemVer)提供了一个简单的模式来传达代码变更。对于包 X.Y.Z:
- 主版本(X):包含破坏性变更的主版本发布(即需要用户采取相应行动)
- 次版本(Y):包含新功能的次版本发布(即提供了新的能力)
- 修订版本(Z):用于修复 bug 的修订版本发布(即修正了错误行为)
Uv 和这个包都采用了语义版本控制,以便开发者能够控制新版本的采用速度。
测试技巧
并行测试
你可以并行运行测试,以加快对代码库的验证速度。
为此,可以使用 pytest-xdist 插件 来扩展 Pytest。
该包默认在其自动化任务中启用了 Pytest。
测试夹具
你应该使用 夹具 为你的测试定义可重用的对象和操作。
夹具可以为你的测试用例准备对象,例如数据框、模型、文件等。
该包在 tests/conftest.py 中定义了夹具,以提升你的测试体验。
VS Code
代码工作区
你可以使用 VS Code 工作区来为你的项目定义配置。
代码工作区 可以启用某些功能(如格式化)并设置默认解释器。
{
"settings": {
"editor.formatOnSave": true,
"python.defaultInterpreterPath": ".venv/bin/python",
...
},
}
该包定义了一个工作区文件,你可以从 [package].code-workspace 加载它。
GitHub Copilot
你可以使用 GitHub Copilot 将你的编码效率提高 30%。
GitHub Copilot 凭借其智能补全功能,极大地提升了开发效率。
你只需一次编码实践,就能很快熟悉它的用法。
VSCode VIM
你可以使用 VIM 键绑定更高效地导航和修改代码。
学习 VIM 是投身 IT 行业的一项绝佳投资。它能使你的工作效率提升 30%。
与 GitHub Copilot 相比,掌握 VIM 需要更多时间。不过,你可以在一个月内看到回报。
资源
本节提供了构建 Python 以及 AI/ML/MLOps 相关软件包的资源。
Python
- https://github.com/krzjoa/awesome-python-data-science#readme
- https://github.com/ml-tooling/best-of-ml-python
- https://github.com/ml-tooling/best-of-python
- https://github.com/ml-tooling/best-of-python-dev
- https://github.com/vinta/awesome-python
AI/ML/MLOps
版本历史
v4.1.02025/03/05v4.0.02025/03/04v3.0.02024/12/14v2.0.02024/07/28v1.1.12024/07/23v1.0.02024/03/19v0.9.02024/03/19v0.8.02024/03/18v0.7.02024/03/16v0.6.02024/03/16v0.5.02024/03/16v0.4.02024/03/16v0.3.02024/03/16v0.2.02024/03/16v0.1.02024/03/16常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。