spiritlm
SpiritLM 是 Meta 开源的一款创新语言模型,旨在打破传统文本与语音处理的界限。它不仅能理解文字,还能直接处理语音信号,实现了口语与书面语的无缝交织建模。过去,AI 系统通常需要将语音先转写为文字再进行处理,这一过程往往丢失了语调、情感等关键信息;SpiritLM 则通过统一的架构直接对语音和文本进行联合建模,有效解决了多模态交互中信息割裂的难题,尤其在保留说话人情感色彩方面表现卓越。
这款工具特别适合人工智能研究人员、开发者以及对多模态大模型感兴趣的技术团队使用。通过提供的推理代码、预训练权重及评估脚本,用户可以快速复现论文成果,开展语音生成、情感保持基准测试等前沿探索。其核心技术亮点在于采用了独特的语音分词器(Speech Tokenizer),将连续的语音信号转化为离散的令牌序列,使其能像处理文本一样高效地处理语音,从而在单一模型内实现高质量的语音 - 文本混合生成。无论是希望构建更自然的人机对话系统,还是深入研究语音与语言内在联系的专业人士,SpiritLM 都提供了一个强大且灵活的实验平台。
使用场景
某在线教育平台的技术团队正致力于升级其口语陪练系统,希望实现更自然的语音与文本混合交互体验。
没有 spiritlm 时
- 模态割裂严重:系统需分别调用独立的语音识别(ASR)和大型语言模型(LLM),导致语音中的语气、停顿等情感信息在转文字过程中丢失。
- 响应延迟高:音频必须先完整转录为文本才能送入模型处理,多阶段串行流程使得用户对话等待时间过长,破坏沉浸感。
- 上下文理解偏差:模型仅基于纯文本进行推理,无法感知说话人的犹豫或强调,常给出机械且缺乏同理心的回复。
- 开发维护复杂:工程师需要维护两套独立的接口和数据管道,对齐语音时间戳与文本逻辑不仅代码量大且极易出错。
使用 spiritlm 后
- 音文深度融合:spiritlm 直接接受交错的语音令牌与文本输入,能精准捕捉并保留原声中的情感色彩与韵律特征。
- 端到端低延迟:得益于统一的生成架构,spiritlm 支持流式处理,边听边想边回答,显著缩短了首字生成的等待时间。
- 拟人化交互增强:模型能根据语音语调调整回复策略,如在检测到用户犹豫时主动引导,使对话更像真人教练而非机器。
- 架构极简统一:开发者只需部署一个 spiritlm 模型即可同时处理听、说、读、写任务,大幅降低了系统复杂度与维护成本。
spiritlm 通过打破语音与文本的模态壁垒,让 AI 真正具备了“听懂弦外之音”的能力,重塑了人机语音交互的自然度。
运行环境要求
- 未说明
未说明
未说明

快速开始
Meta Spirit LM:交错式语音与文本语言模型
本仓库包含 Spirit LM 模型的权重、推理代码以及评估脚本 论文。您可以在我们的 演示页面 上找到更多生成示例。
Spirit LM 模型概述
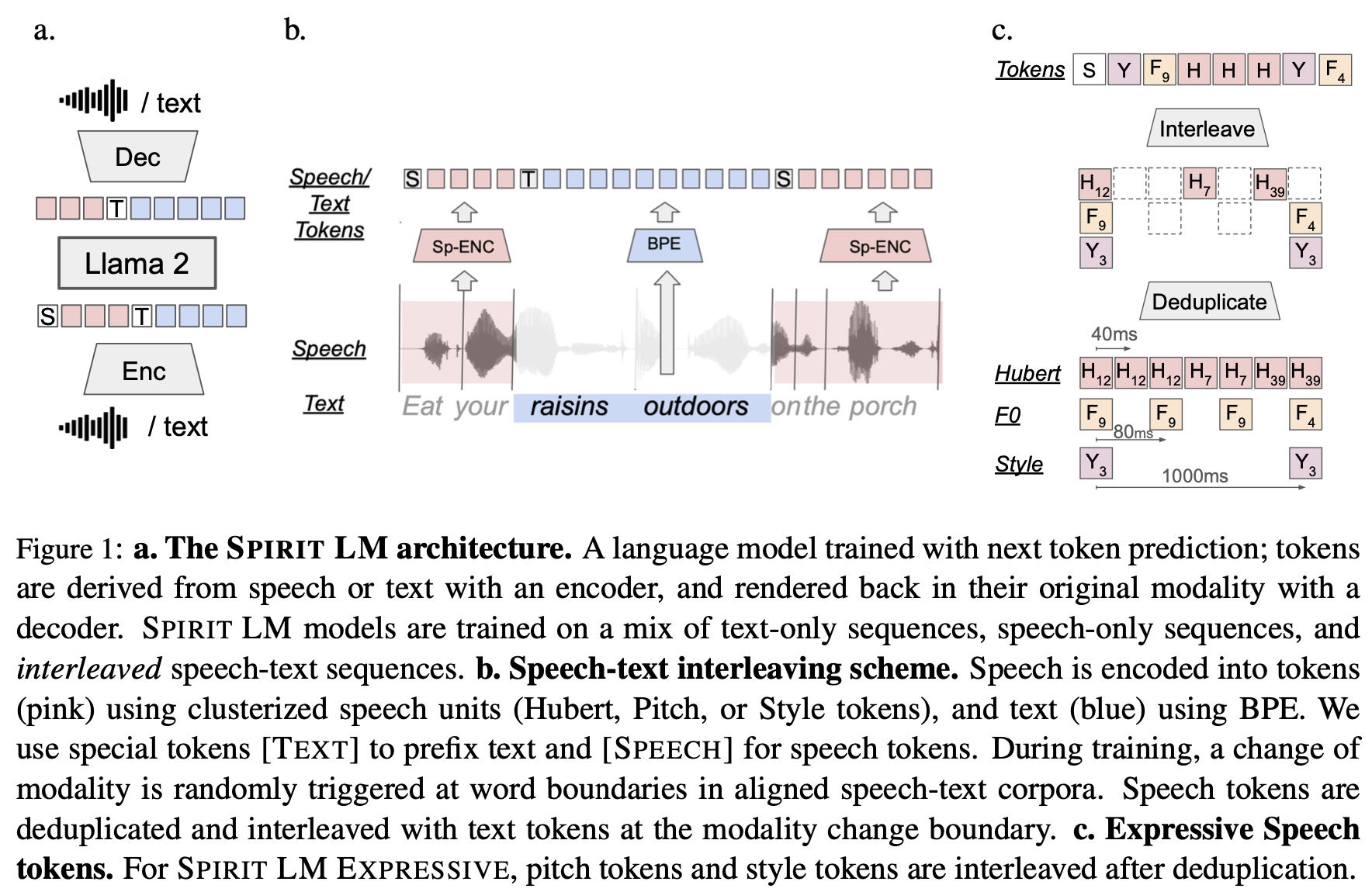
安装与设置
Conda
conda env create -f env.yml
pip install -e '.[eval]'
Pip
pip install -e '.[eval]'
开发环境
(仅在需要运行测试时使用。)
pip install -e '.[dev]'
检查点设置
快速入门
语音分词
请参阅 spiritlm/speech_tokenizer/README.md。
Spirit LM 生成
语音-文本情感保持基准测试 (STSP)
模型卡片
有关模型的更多详细信息,请参阅 MODEL_CARD.md。
许可证
本代码依据 LICENSE 中的 FAIR 非商业研究许可证 提供。
引用
@misc{nguyen2024spiritlminterleavedspokenwritten,
title={SpiRit-LM: 交错式语音与文本语言模型},
author={阮安英、本杰明·穆勒、于博凯、玛尔塔·R·科斯塔-胡萨、马哈·埃尔巴亚德、斯拉维娅·波普里、保罗-安布罗兹·杜肯、罗宾·阿尔盖尔斯、鲁斯兰·马夫柳托夫、伊泰·加特、加布里埃尔·西纳耶夫、胡安·皮诺、贝努瓦·萨戈、埃曼纽埃尔·迪普克斯},
year={2024},
eprint={2402.05755},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2402.05755},
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。