balance
balance 是一款专为处理数据偏差而设计的 Python 开源工具包。在调查研究、观察性实验或任何存在“选择偏差”的场景中,我们收集到的样本往往无法完美代表目标总体(例如问卷回收率低导致特定人群缺失)。balance 的核心价值在于提供了一套简洁的工作流,帮助研究者利用辅助信息(如年龄、性别、教育程度等已知特征)对偏差样本进行加权调整,从而更准确地推断总体情况。
该工具特别适用于需要严谨数据分析的专业人士,包括调查方法学家、人口统计学家、用户体验研究员、市场分析师,以及广大数据科学家和机器学习工程师。无论是处理非响应偏差还是采样偏差,只要数据满足“随机缺失”假设,balance 都能通过科学的加权算法有效缓解偏差带来的影响。
作为由 Facebook Research 推出的项目,balance 不仅拥有扎实的统计学理论支撑(相关论文已发表于 arXiv),还具备友好的工程化实现。它让复杂的样本平衡方法变得易于调用,让用户无需从头编写算法,即可在 Python 环境中快速完成从数据诊断到偏差校正的全过程,是提升推断结果可靠性的得力助手。目前该项目处于 Beta 阶段,正在积极维护中。
使用场景
某市场研究团队正试图通过线上问卷数据,推断全国消费者对新款智能手表的购买意愿,但回收的样本中年轻男性比例严重过高。
没有 balance 时
- 直接基于原始数据建模会导致预测结果严重偏向年轻群体,完全无法代表全年龄段的真实市场需求。
- 分析师需手动编写复杂的加权算法代码来匹配人口普查数据,不仅耗时且极易因公式错误导致统计偏差。
- 缺乏标准化的评估指标,难以量化样本偏差的具体程度,无法向管理层证明最终结论的可信度。
- 面对多维度的协变量(如年龄、性别、收入、地区),传统手动调整方法难以同时平衡所有特征分布。
使用 balance 后
- 利用 balance 内置的加权方法,自动将样本权重调整至与目标人口结构一致,显著消除了非响应偏差。
- 仅需几行代码即可调用成熟的统计流程,无需重复造轮子,将原本数天的数据清洗工作缩短至小时级。
- 工具提供可视化的平衡性诊断图表,直观展示调整前后协变量分布的差异,让分析结论有据可依。
- 能够同时处理多个辅助变量,确保在年龄、性别和地域等多个维度上样本与总体高度对齐,提升推断精度。
balance 将复杂的统计加权理论转化为简单的 Python 工作流,让研究人员能从有偏样本中可靠地推断出总体真相。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始

balance: 一个用于平衡有偏数据样本的 Python 包

![]()
![]()

![]()
![]()
![]()
![]()

[!注意] balance 目前处于 测试阶段,并得到积极维护。请在 GitHub 上关注我们。
什么是 balance?
balance 是一个 Python 包,提供了一套 简单的工作流程和方法,用于在从有偏样本推断目标总体时, 处理有偏数据样本的问题。
有偏样本通常出现在 调查统计学 中,当受访者表现出 无响应偏差 或调查本身存在 抽样偏差(而非 完全随机缺失)时。类似的问题也会出现在 观察性研究 中,在比较接受治疗与未接受治疗的组别时,以及任何存在选择偏差的数据中。
在随机缺失假设 (MAR) 下,样本中的偏差有时可以通过利用辅助信息(即“协变量”或“特征”)来部分缓解——这些信息既存在于样本中的所有个体中,也存在于来自总体的样本中。例如,如果我们希望从某次调查的样本中进行推断,可以使用年龄、性别、教育程度等人口统计信息来调整无响应偏差。这可以通过利用辅助信息对样本进行加权,使其更接近总体分布来实现。
该包面向希望使用 Python 包来平衡有偏样本的研究人员,例如来自调查的数据。这种需求可能出现在调查方法学家、人口统计学家、用户体验研究人员、市场研究人员,以及广义上的数据科学家、统计学家和机器学习从业者中。
更多方法论背景可参见 Sarig, T., Galili, T., & Eilat, R. (2023). balance – a Python package for balancing biased data samples。
安装
要求
运行 balance 需要 Python 3.9、3.10、3.11、3.12、3.13 或 3.14。balance 可以在 Linux、OSX 和 Windows 上构建和运行。
所需的 Python 依赖项如下:
REQUIRES = [
# Numpy 和 pandas:严格控制版本以确保二进制兼容性
"numpy>=1.21.0,<2.0; python_version<'3.12'",
"numpy>=1.24.0; python_version>='3.12'",
"pandas>=1.5.0,<4.0.0; python_version<'3.12'",
"pandas>=2.0.0,<4.0.0; python_version>='3.12'",
# 科学计算栈
"scipy>=1.7.0,<1.14.0; python_version<'3.12'",
"scipy>=1.11.0; python_version>='3.12'",
"scikit-learn>=1.0.0,<1.4.0; python_version<'3.12'",
"scikit-learn>=1.3.0; python_version>='3.12'",
"ipython",
"patsy",
"seaborn",
"plotly",
"matplotlib",
"statsmodels",
"session-info",
]
更多详细信息请参阅 pyproject.toml。
安装 balance
通过 PyPI 安装
我们建议通过 pip 从 PyPI 安装 balance 的最新稳定版本:
python -m pip install balance
安装将使用 PyPI 提供的 Python 轮包,适用于 OSX、Linux 和 Windows。
从源代码/Git 安装
您也可以从 Git 安装最新的(前沿)版本:
python -m pip install git+https://github.com/facebookresearch/balance.git
或者,如果您已经克隆了仓库:
cd balance
python -m pip install .
也可以使用开发依赖项:
cd balance
python -m pip install .[dev]
入门
balance 的高级工作流程
balance 的核心工作流程涉及为样本拟合和评估权重。对于样本中的每个单元(例如调查的受访者),balance 会拟合一个权重,这个权重可以粗略地理解为该受访者所代表的目标总体中的人数。其目的是帮助缓解覆盖偏差和无响应偏差,如图所示。
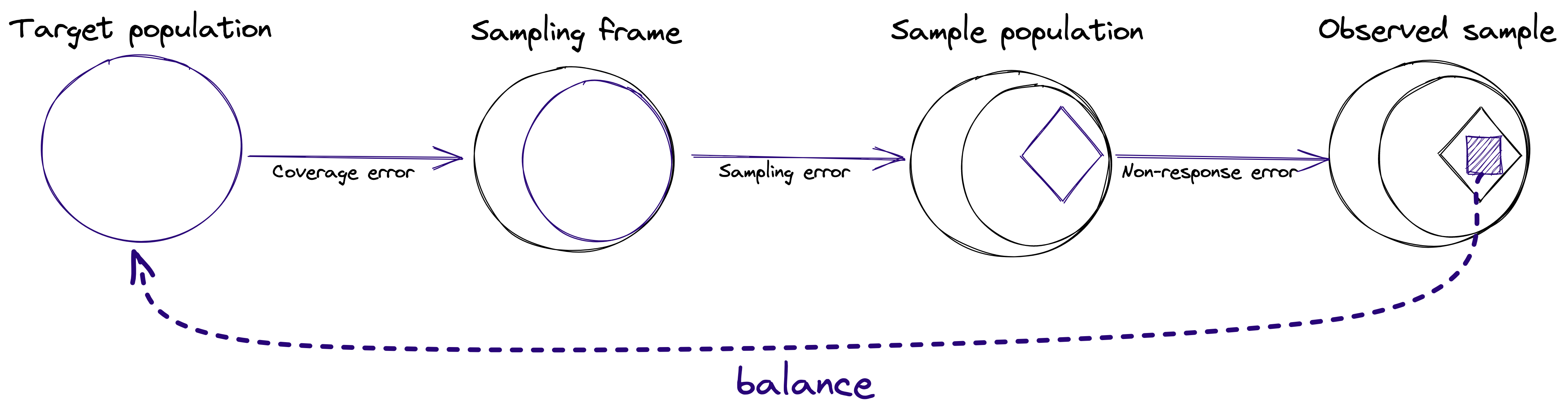
通过 balance 对调查数据进行加权的主要步骤如下:
- 加载调查受访者的数据。
- 加载我们希望校正的目标总体的相关数据。
- 对样本协变量进行诊断,以评估是否需要进行加权。
- 将样本调整至目标总体。
- 评估结果。
- 使用权重生成总体层面的估计值。
- 保存输出的权重。
您可以在 通用框架 页面中找到上述步骤的逐步描述(附带代码)。
使用 balance 的代码示例
你可以运行以下代码来体验 balance 的基本工作流程(这些片段摘自 快速入门教程):
首先,我们加载数据并进行调整:
from balance import load_data, Sample
# 加载模拟示例数据
target_df, sample_df = load_data()
# 将样本和目标数据导入 Sample 对象
sample = Sample.from_frame(sample_df, outcome_columns=["happiness"])
target = Sample.from_frame(target_df)
# 设置目标为样本的目标
sample_with_target = sample.set_target(target)
# 在调整之前检查样本与目标的基本诊断:
# sample_with_target.covars().plot()
你可以在 预调整诊断 页面中了解更多关于预调整数据评估的信息。
接下来,我们通过拟合平衡抽样权重将样本调整到总体:
# 使用 ipw 拟合抽样权重
adjusted = sample_with_target.adjust()
你可以在 将样本调整到总体 页面中了解更多关于调整过程的信息。
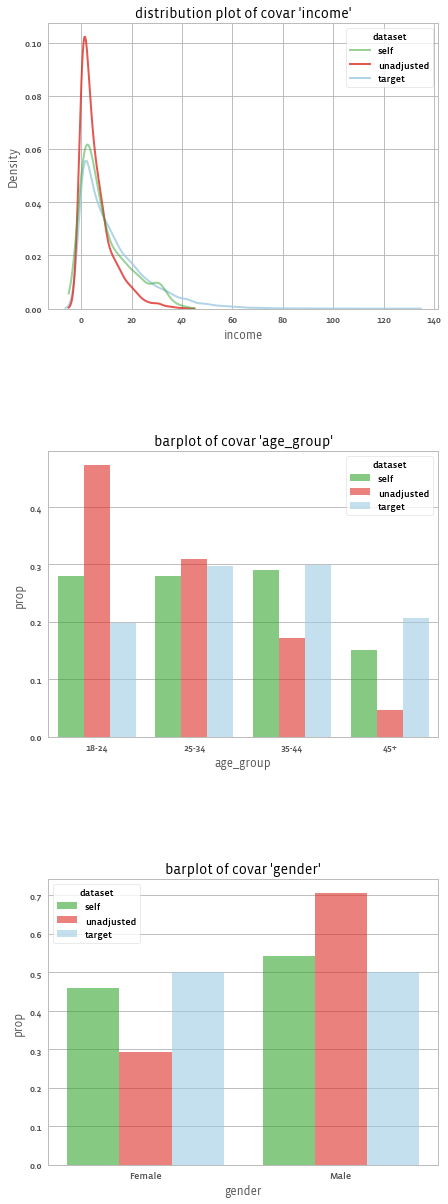
上述代码会生成一个带有权重的 adjusted 对象。我们可以评估权重对协变量平衡的好处,例如通过运行:
print(adjusted.summary())
# 协变量 ASMD 降低:62.3%,设计效应:2.249
# 协变量 ASMD(7 个变量):0.335 -> 0.126
# 模型性能:模型解释的偏差比例:0.174
adjusted.covars().plot(library = "seaborn", dist_type = "kde")
得到如下结果:
我们还可以通过以下方式检查权重对结果的影响:
# 对于结果:
print(adjusted.outcomes().summary())
# 1 个结果:['happiness']
# 平均结果:
# happiness
# source
# self 54.221388
# unadjusted 48.392784
#
# 回应率(相对于样本中的受访者数量):
# happiness
# n 1000.0
# % 100.0
adjusted.outcomes().plot()
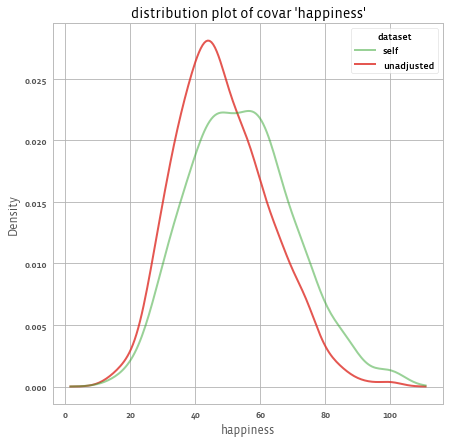
你可以在 评估和使用调整权重 页面中了解更多关于调整后数据评估的信息。
最后,可以使用以下代码下载调整后的数据:
adjusted.to_download() # 或者:
# adjusted.to_csv()
若想查看更详细的分步代码示例,包括代码输出打印和图表(静态及交互式),请前往 教程部分。
已实现的调整方法
balance 目前实现了多种调整方法。点击链接以了解每种方法的详细信息:
已实现的诊断/评估方法
在诊断方面,主要工具(比较应用权重前后以及与目标总体的情况)包括:
- 图表
- 条形图
- 密度图(用于权重和协变量)
- QQ 图
- 统计摘要
你可以在 评估和使用调整权重 页面中了解更多关于调整后数据评估的信息。
其他资源
- 演示文稿: "使用 'balance' Python 包平衡有偏数据样本" - 于 2023 年 6 月 1 日在以色列统计协会 (ISA) 大会上发表。
更多详情
获取帮助、提交错误报告和贡献代码
欢迎你:
- 访问 balance 官网了解更多。
- 在以下链接寻求帮助: https://github.com/facebookresearch/balance/issues/new?template=support_question.md
- 在以下链接提交错误报告和功能建议: https://github.com/facebookresearch/balance/issues
- 向 https://github.com/facebookresearch/balance 提交拉取请求。请参阅 CONTRIBUTING 文件以了解如何参与贡献。同时,请参考我们的 行为准则,了解我们对贡献者的期望。
引用 balance
Sarig, T., Galili, T., & Eilat, R. (2023). balance – 用于平衡有偏数据样本的 Python 包。 https://arxiv.org/abs/2307.06024
@misc{sarig2023balance,
title={balance - 用于平衡有偏数据样本的 Python 包},
author={Tal Sarig 和 Tal Galili 以及 Roee Eilat},
year={2023},
eprint={2307.06024},
archivePrefix={arXiv},
primaryClass={stat.CO}
}
许可证
balance 软件包采用 MIT 许可证 许可,网站上的所有文档(包括文字和图片)则采用 CC-BY 许可。
新闻
你可以关注我们的:
致谢 / 参与人员
balance 包由来自 中央应用科学 团队(位于门洛帕克和特拉维夫)的以下人员积极维护:Wesley Lee、Tal Sarig 和 Tal Galili。
balance 包的开发曾由并仍在由多位同事共同完成,其中包括:Roee Eilat、Tal Galili、Daniel Haimovich、Kevin Liou、Steve Mandala、Adam Obeng(Meta 内部初始版本的作者)、Tal Sarig、Luke Sonnet、Sean Taylor、Barak Yair Reif、Soumyadip Sarkar 等。如果您过去曾参与 balance 的相关工作,请发送邮件至我们,以便将您的名字加入此列表。
balance 包于 2022 年底由 Tal Sarig、Tal Galili 和 Steve Mandala 共同开源。
品牌设计由 Meta AI 设计与市场团队的 Dana Beaty 完成。有关徽标文件,请参阅此处。
版本历史
0.18.02026/03/240.17.02026/03/170.16.02026/02/090.15.02026/01/200.14.02025/12/140.13.02025/12/020.12.12025/11/030.12.02025/10/150.11.02025/09/240.10.02025/01/060.9.02023/05/220.8.02023/04/260.7.02023/04/100.6.02023/04/050.5.02023/03/080.4.02023/02/080.3.12023/02/010.3.02023/01/310.2.02023/01/190.1.02022/11/21常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。