Duix-Avatar
Duix-Avatar 是一款完全开源的 AI 数字人工具包,致力于实现离线的视频生成与数字人克隆。长期以来,制作逼真的数字人往往需要高昂的 3D 建模费用或依赖云端服务,这不仅增加了成本,还带来了隐私泄露的风险。Duix-Avatar 通过先进的 AI 算法,能够精准复刻用户的外貌特征与声音特质,支持文本输入或语音驱动来生成自然的口播视频,并实现了高精度的音画同步。
Duix-Avatar 最大的亮点在于其完全本地化的运行模式,无需联网即可在 Windows 系统上完成所有操作,有效保障了数据安全。同时,Duix-Avatar 支持中英法德等多国语言,界面简洁易用。无论是希望探索技术的开发者、研究人员,还是需要高效生产内容的创作者、教育工作者,甚至是关注隐私保护的普通用户,都可以免费下载并使用。Duix-Avatar 旨在打破技术门槛,让每个人都能零成本拥有专属的数字分身。
使用场景
某独立编程教育博主计划每周更新三次技术教程视频,但受限于时间精力和预算,急需高效解决方案。
没有 Duix-Avatar 时
- 传统拍摄需搭建专业影棚,单次录制准备及打光时间长达两小时。
- 发现口误必须重新整段录制,后期剪辑效率极低,难以快速响应反馈。
- 使用在线 SaaS 平台存在个人生物特征数据上传云端泄露风险。
- 订阅制付费高昂,且不支持多语言切换,难以覆盖海外学员群体。
使用 Duix-Avatar 后
- Duix-Avatar 支持本地部署,只需少量样本即可克隆形象,无需反复出镜。
- 通过文本驱动数字人口型,修改脚本后秒级重新生成,极大提升迭代速度。
- 全离线模式确保所有训练数据保留在本地电脑,彻底杜绝隐私隐患。
- 内置八国语言支持,一键切换中英双语输出,轻松触达全球学习者。
Duix-Avatar 以零成本、高隐私的本地化方案,彻底解决了数字人视频制作的效率与数据安全难题。
运行环境要求
- Windows
- Linux
需要 NVIDIA 显卡,推荐 RTX 4070,需安装正确驱动程序,50 系显卡需使用官方预览版 PyTorch
32GB
快速开始
🚀🚀🚀 Duix Avatar — 真正开源的离线视频生成和数字人克隆 AI 头像工具包
🔗 官方网站: www.duix.com
目录
1. 什么是 Duix.Avatar
Duix.Avatar 是由 Duix.com 开发的一款免费开源的 AI (人工智能) 头像项目。
七年前,一群年轻的先驱者选择了一条非传统的技术路径,开发了一种使用真人视频数据训练数字人模型的方法。与传统的昂贵 3D 数字人方法不同,我们利用 AI 生成技术创建了超逼真的数字人,将制作成本从数十万美元降低到仅需 1000 美元。这一创新已赋能超过 10,000 家企业,并为教育者、内容创作者、法律专家、医疗从业者及企业家等各行各业的专业人士生成了超过 500,000 个个性化头像,极大地提高了他们的视频制作效率。然而,我们的愿景不仅限于商业应用。我们相信这项变革性技术应惠及每个人。为了普及数字人创作,我们开源了我们的克隆技术和视频制作框架。我们的承诺始终如一:打破技术壁垒,让尖端工具触手可及。现在,任何人只要有电脑,就可以免费制作自己的 AI 头像并零成本制作视频——这就是 Duix.Avatar 的核心精髓。
2. 简介
![]()
Duix.Avatar 是一款专为 Windows 系统设计的完全离线视频合成工具,能够精确克隆您的外貌和声音,实现您形象的数字化。您可以通过文本和语音驱动虚拟头像来创建视频。无需互联网连接,在享受便捷高效数字体验的同时保护您的隐私。
- 核心功能
- 精确外貌与声音克隆:利用先进的 AI 算法高精度捕捉人类面部特征,包括五官、轮廓等,构建逼真的虚拟模型。它还能精确克隆声音,捕捉并重现人类声音的细微特征,支持多种声音参数设置,以创造高度相似的克隆效果。
- 文本与语音驱动的虚拟头像:通过自然语言处理 (NLP) 技术理解文本内容,将文本转换为自然流畅的语音以驱动虚拟头像。也可以直接使用语音输入,允许虚拟头像根据语音的节奏和语调执行相应的动作和面部表情,使虚拟头像的表演更加自然生动。
- 高效视频合成:高度同步数字人视频图像与声音,实现自然流畅的口型同步,智能优化音视频同步效果。
- 多语言支持:脚本支持八种语言——英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
- 关键优势
- 完全离线运行:无需互联网连接,有效保护用户隐私,允许用户在安全独立的环境中创作,避免网络传输过程中潜在的数据泄露。
- 用户友好:界面简洁直观,即使是没有技术背景的初学者也能轻松上手,快速掌握软件用法,开启数字人创作之旅。
- 多模型支持:支持导入多个模型并通过一键启动包进行管理,方便用户根据不同的创作需求和应用场景选择合适的模型。
- 技术支持
- 声音克隆技术:利用人工智能等先进技术,基于给定的声音样本生成相似或相同的声音,涵盖语境、语调、语速等语音方面。
- 自动语音识别 (ASR):将人类语音词汇内容转换为计算机可读的输入(文本格式),使计算机能够“理解”人类语音的技术。
- 计算机视觉技术:用于视频合成中的视觉处理,包括人脸识别和唇部运动分析,确保虚拟头像的唇部运动与语音和文本内容相匹配。
3. 本地运行指南
Duix.Avatar 支持基于 Docker (容器引擎) 的快速部署。部署前,请确保您的硬件和软件环境满足指定要求。
Duix.Avatar 支持两种部署模式:Windows / Ubuntu 22.04 安装
依赖项
- Nodejs 18
- Docker 镜像
- docker pull guiji2025/fun-asr
- docker pull guiji2025/fish-speech-ziming
- docker pull guiji2025/duix.avatar
模式 1:Windows 安装
系统要求:
- 目前支持 Windows 10 19042.1526 或更高版本
硬件要求:
必须拥有 D 盘:主要用于存储数字人和项目数据
- 剩余空间要求:大于 30GB
C 盘:用于存储服务镜像文件
剩余空间要求:大于 100GB
如果可用空间少于 100GB,在安装 Docker(容器引擎)后,您可以选择下方所示位置的其他磁盘文件夹,该文件夹需有超过 100GB 的剩余空间。
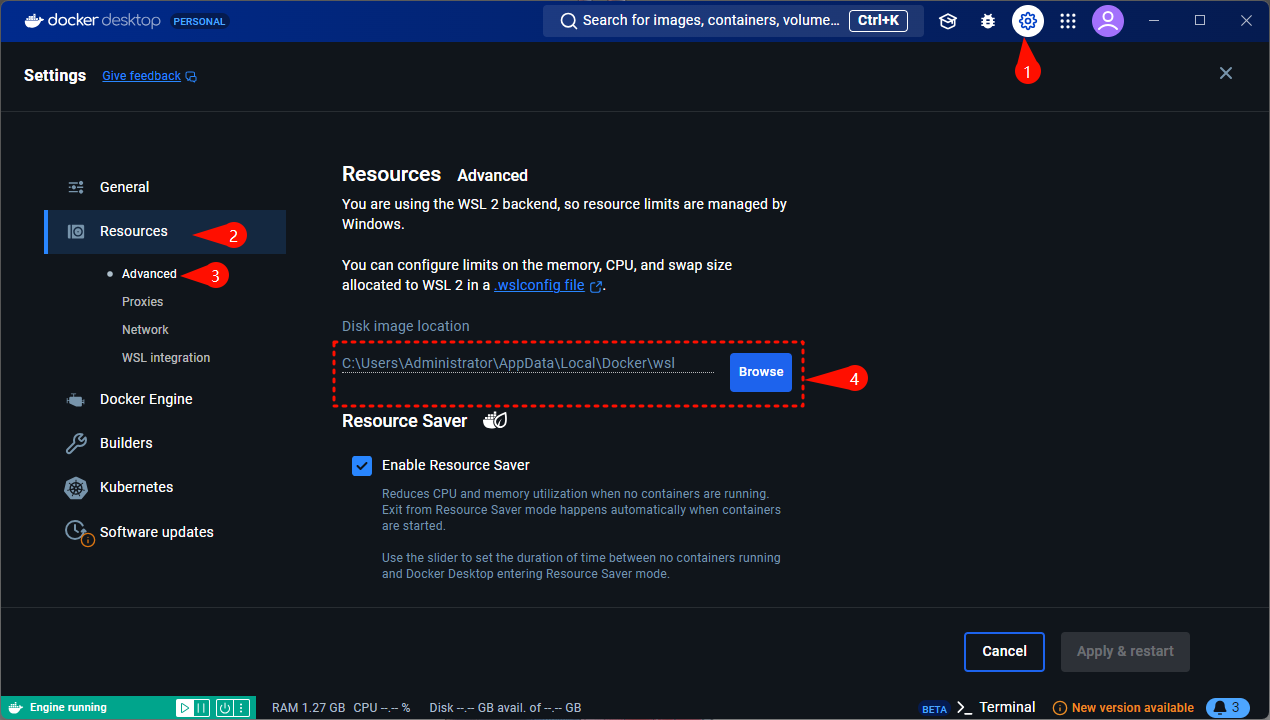
推荐配置:
- 处理器:第 13 代 Intel Core i5-13400F
- 内存:32GB
- 显卡:RTX 4070
确保您拥有 NVIDIA 显卡且驱动程序已正确安装
NVIDIA 驱动程序下载链接:https://www.nvidia.cn/drivers/lookup/
安装 Windows Docker
使用命令
wsl --list --verbose检查是否已安装 WSL(Windows 子系统 for Linux)。如果显示如下,则表示已安装,无需进一步安装。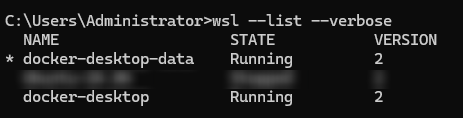
使用
wsl --update更新 WSL。
下载 Docker for Windows,根据您的 CPU 架构选择合适的安装包。
看到此界面时,表示安装成功。
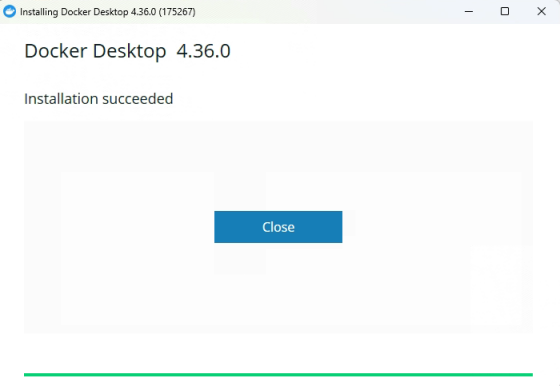
运行 Docker

首次运行时接受协议并跳过登录
安装服务器
使用 Docker 和 docker-compose(编排工具)进行安装,步骤如下:
docker-compose.yml文件位于/deploy目录中。在
/deploy目录下执行docker-compose up -d,如果您想使用精简版,请执行docker-compose -f docker-compose-lite.yml up -d请耐心等待(约半小时,速度取决于网络),下载将消耗约 70GB 流量,请确保使用 WiFi
当您在 Docker 中看到三个服务时,表示成功(精简版只有一个服务
Duix.Avatar-gen-video)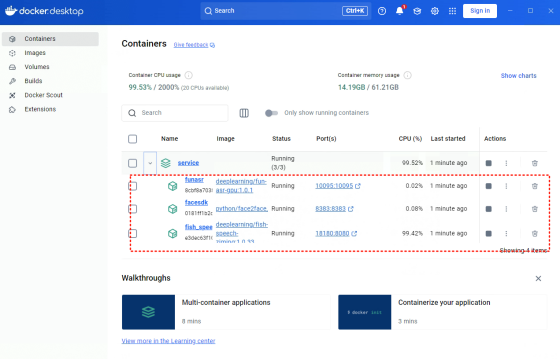
NVIDIA 50 系列显卡的服务器部署方案
对于 50 系列显卡(经测试,配合 CUDA 12.8 也适用于 30/40 系列),使用 PyTorch(深度学习框架)官方预览版。
客户端
- 直接下载 官方构建的安装包
- 双击
Duix.Avatar-x.x.x-setup.exe进行安装
模式 2:Ubuntu 22.04 安装
系统要求:
我们在 Ubuntu 22.04 上进行了完整测试。理论上,它支持桌面 Linux 发行版。
硬件要求:
- 推荐配置
- 处理器:第 13 代 Intel Core i5 - 13400F
- 内存:32G 或更多(必需)
- 显卡:RTX - 4070(确保您拥有 NVIDIA 显卡且显卡驱动程序已正确安装)
- 硬盘:剩余空间大于 100G
安装 Docker:
首先,使用 docker --version 检查是否已安装 Docker。如果已安装,请跳过以下步骤。
sudo apt update
sudo apt install docker.io
sudo apt install docker-compose
安装显卡驱动:
- 参考官方文档安装显卡驱动 (https://www.nvidia.cn/drivers/lookup/)。
安装完成后,执行 nvidia-smi 命令。如果显示了显卡信息,则安装成功。
- 安装 NVIDIA Container Toolkit
NVIDIA Container Toolkit 是 Docker 使用 NVIDIA GPU(图形处理器)所必需的工具。安装步骤如下:
- 添加 NVIDIA 软件源仓库:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
- 更新软件包列表并安装工具包:
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
- 配置 Docker 使用 NVIDIA 运行时:
sudo nvidia-ctk runtime configure --runtime=docker
- 重启 Docker 服务:
sudo systemctl restart docker
安装服务器
cd /deploy
docker-compose -f docker-compose-linux.yml up -d
安装客户端
- 直接下载 Linux 版本的 官方构建的安装包。
- 双击
Duix.Avatar-x.x.x.AppImage启动它。无需安装。
注意:在 Ubuntu 系统中,如果您以 root 用户身份进入桌面,直接双击 Duix.Avatar - x.x.x.AppImage 可能无法运行。您需要在命令行终端中执行 ./Duix.Avatar - x.x.x.AppImage --no - sandbox。添加 --no - sandbox 参数即可解决。(注:沙箱模式限制)
4. 开放 API
我们已开放用于模型训练和视频合成的 API。Docker 启动后,将暴露几个本地端口,可通过 http://127.0.0.1 访问。
具体代码请参考:
- src/main/service/model.js
- src/main/service/video.js
- src/main/service/voice.js
模型训练
将视频分离为无声视频 + 音频
将音频放置于
D:\duix_avatar_data\voice\data与guiji2025/fish-speech-ziming服务约定一致,可在 docker-compose 中修改调用接口
参数示例:响应示例:记录响应结果,因为后续音频合成需要用到
音频合成
接口:http://127.0.0.1:18180/v1/invoke
// 请求参数
{
"speaker": "{uuid}", // 唯一的 UUID(通用唯一识别码)
"text": "xxxxxxxxxx", // 要合成的文本内容
"format": "wav", // 固定参数
"topP": 0.7, // 固定参数
"max_new_tokens": 1024, // 固定参数
"chunk_length": 100, // 固定参数
"repetition_penalty": 1.2, // 固定参数
"temperature": 0.7, // 固定参数
"need_asr": false, // 固定参数
"streaming": false, // 固定参数
"is_fixed_seed": 0, // 固定参数
"is_norm": 0, // 固定参数
"reference_audio": "{voice.asr_format_audio_url}", // 前一步“模型训练”步骤的返回值
"reference_text": "{voice.reference_audio_text}" // 前一步“模型训练”步骤的返回值
}
视频合成
合成接口:
http://127.0.0.1:8383/easy/submit// Request parameters { "audio_url": "{audioPath}", // Audio path "video_url": "{videoPath}", // Video path "code": "{uuid}", // Unique key "chaofen": 0, // Fixed value "watermark_switch": 0, // Fixed value "pn": 1 // Fixed value }进度查询:
http://127.0.0.1:8383/easy/query?code=${taskCode}
GET 请求,参数 taskCode 为上述合成接口输入中的 code
致开发者合作伙伴的重要通知
我们现在宣布两种并行的服务解决方案:
| 项目 | Duix.Avatar Open Source(开源)本地部署 | 数字人/克隆语音 API(应用程序编程接口)服务 |
|---|---|---|
| 用途 | Open Source(开源)本地部署 | 快速克隆 API 服务 |
| 推荐人群 | 技术用户 | 商业用户 |
| 技术门槛 | 具有深度学习框架经验的开发者/追求深度定制/希望参与社区共建 | 快速业务集成/专注于上层应用开发/需要企业级 SLA(服务等级协议)保障的商业场景 |
| 硬件要求 | 需购买 GPU(图形处理器)服务器 | 无需购买 GPU 服务器 |
| 定制化能力 | 可根据需求修改和扩展代码,完全控制软件的功能和行为 | 无法直接修改源代码,只能通过 API 提供的接口扩展功能,灵活性不如开源项目 |
| 技术支持 | 社区支持 | 动态扩展支持 + 专业技术响应团队 |
| 维护成本 | 高维护成本 | 简单维护 |
| 唇形同步效果 | 可用效果 | 惊艳且更高清的效果 |
| 商业授权 | 支持全球免费商用(用户超过 10 万或年营收超过 1000 万美元的企业需签署商业许可协议) | 允许商用 |
| 迭代速度 | 更新慢,bug 修复依赖社区 | 优先使用最新模型/算法,问题解决速度快 |
我们始终秉持开源精神,推出 API 服务旨在为不同需求的开发者提供更完整的解决方案矩阵。无论您选择哪种方式,都可以通过 https://duix.com 获取技术支持文档
我们期待与您携手,共同推动数字人技术的普惠发展!
您可以在官网与 Duix.Avatar 数字人聊天:https://duix.com/
我们也在 DUIX 平台提供 API:https://docs.duix.com/api-reference/api/Introduction
5. 更新内容
[NVIDIA(英伟达)50 系列 GPU(图形处理器)版本通知]
- 已在 5090 GPU 上测试验证
- 安装说明请参见 NVIDIA 50 系列显卡服务器部署方案
[新版 Ubuntu 版本通知]
Ubuntu 版本正式发布
- 已完成对 Ubuntu 22.04 桌面版(内核 6.8.0-52-generic)的适配和验证工作。尚未对其他 Linux 版本进行兼容性测试。
- 客户端程序界面增加了国际化(英文)支持。
- 修复了一些已知问题
- #304
- #292
- Ubuntu22.04 安装文档
6. 常见问题解答
提问前自查步骤
检查所有三项服务是否处于 Running(运行)状态
确认您的机器拥有 NVIDIA 显卡且驱动程序正确安装。
本项目的所有算力均为本地计算。如果没有 NVIDIA 显卡或正确的驱动程序,这三项服务将无法启动。
- 确保服务端和客户端均已更新至最新版本。该项目刚开源,社区非常活跃,更新频繁。您的问题可能在新版本中已得到解决。
- 服务端:进入
/deploy目录并重新执行docker-compose up -d - 客户端:
pull代码并重新build
- 服务端:进入
- GitHub Issue(问题单) 持续更新,每天都有问题被解决和关闭。请经常查看,您的问题可能已经解决了。
问题模板
- 问题描述
详细描述复现步骤,如有可能请附上截图。
- 提供错误日志
如何获取客户端日志:
服务端日志:
找到关键位置,或者点击我们的三个 Docker 服务,并按下图所示“复制”。
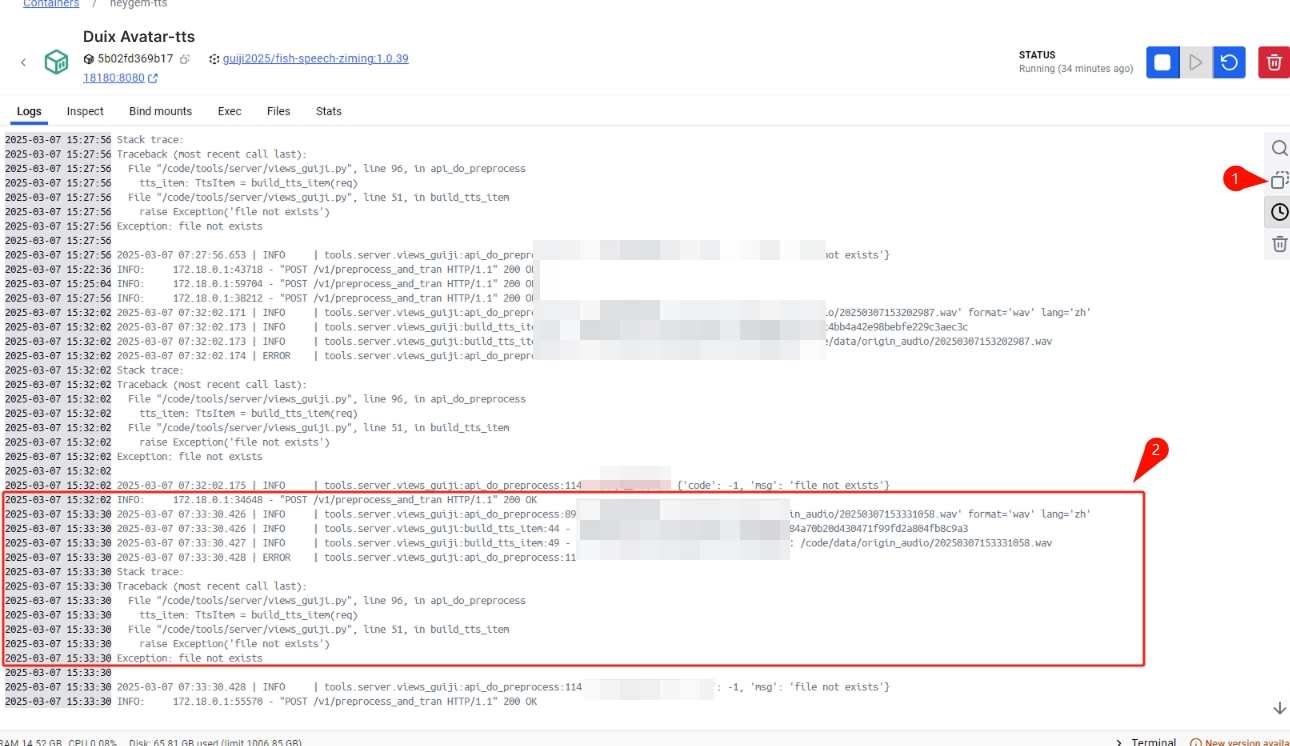
7. 如何实时交互
Duix.Avatar 数字人实现了数字人克隆和非实时视频合成。
如果您希望数字人支持交互,可以访问 duix.com 体验免费试用。
8. 联系方式
如有任何问题,请提交 Issue 或联系我们 james@duix.com
9. 许可证
https://github.com/duixcom/Duix.Avatar/blob/main/LICENSE
10. 致谢
- ASR(自动语音识别)基于 fun-asr
- TTS(文本转语音)基于 fish-speech-ziming
11. Star 历史
版本历史
v1.0.62025/09/28v1.0.52025/08/15常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。