outlines
Outlines 是一个帮助开发者让大语言模型生成结构化数据的工具。它解决了传统方法中生成结果不可控、需要后期处理的问题,通过在生成过程中直接确保输出符合预设格式,避免了解析错误和格式混乱。适合开发者和研究人员使用,尤其在需要精准数据提取或分类的场景中非常实用。其核心亮点是支持多种模型,并能通过简单类型声明实现结构化输出,提升开发效率。
使用场景
某医疗信息系统的开发团队需要从患者病历中提取关键信息,如诊断结果、用药建议和检查项目。这些信息用于后续的电子健康记录系统整合。
没有 outlines 时
- 依赖正则表达式或手动解析,容易出错且维护成本高
- 不同医生的书写风格差异大,导致提取准确率低
- 需要频繁调整解析逻辑以适应新格式的病历
- 提取的数据结构不稳定,难以直接用于系统集成
使用 outlines 后
- 直接定义 Pydantic 模型,确保提取数据结构一致
- 自动处理不同书写风格,提升提取准确率
- 无需修改代码即可适配多种病历格式
- 输出数据可直接用于系统集成,减少后期处理
通过结构化生成,显著提升了病历信息提取的效率与准确性。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始





🚀 构建结构化生成的未来
我们正与精选合作伙伴携手,开发结构化生成的新接口。
需要 XML、FHIR、自定义模式或语法吗?欢迎联系我们。
进行模式审计:只需分享一个模式,我们会展示在生成过程中哪些部分会出错、如何通过约束修复这些问题,以及修复前后的合规率。请在此处报名 here。
目录
为什么选择 Outlines?
大语言模型功能强大,但其输出往往难以预测。大多数解决方案试图在生成后通过解析、正则表达式或易失效的代码来修复不良输出。
而 Outlines 能够在生成过程中直接保证结构化输出——无论使用哪种大语言模型。
- 兼容任何模型:同一段代码可在 OpenAI、Ollama、vLLM 等多种模型上运行。
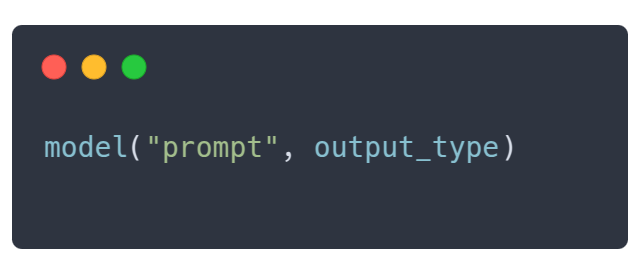
- 集成简单:只需传入期望的输出类型:
model(prompt, output_type)。 - 结构绝对有效:不再有解析难题或 JSON 格式错误。
- 不受供应商限制:无需更改代码即可切换模型。
Outlines 的理念
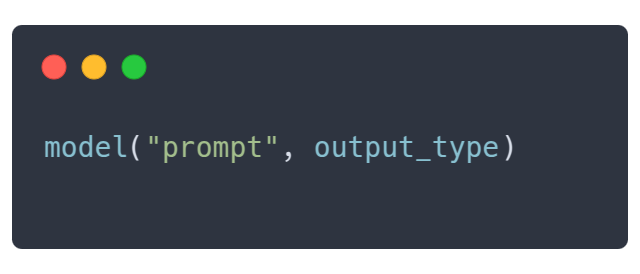
Outlines 遵循一种简洁的模式,类似于 Python 自身的类型系统。只需指定所需的输出类型,Outlines 就会确保你的数据完全符合该结构:
- 对于“是/否”回答,使用
Literal["Yes", "No"]。 - 对于数值,使用
int。 - 对于复杂对象,则使用 Pydantic 模型 定义结构。
快速入门
开始使用 Outlines 非常简单:
1. 安装 Outlines
pip install outlines
2. 连接至您首选的模型
import outlines
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_NAME = "microsoft/Phi-3-mini-4k-instruct"
model = outlines.from_transformers(
AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto"),
AutoTokenizer.from_pretrained(MODEL_NAME)
)
3. 从简单的结构化输出入手
from typing import Literal
from pydantic import BaseModel
# 简单分类
sentiment = model(
"分析:‘这款产品彻底改变了我的生活!’",
Literal["Positive", "Negative", "Neutral"]
)
print(sentiment) # "Positive"
# 提取特定类型
temperature = model("水的沸点是多少摄氏度?", int)
print(temperature) # 100
4. 创建复杂结构
from pydantic import BaseModel
from enum import Enum
class Rating(Enum):
poor = 1
fair = 2
good = 3
excellent = 4
class ProductReview(BaseModel):
rating: Rating
pros: list[str]
cons: list[str]
summary: str
review = model(
"评价:XPS 13 的电池续航出色,显示屏惊艳,但机身发热严重,摄像头质量较差。",
ProductReview,
max_new_tokens=200,
)
review = ProductReview.model_validate_json(review)
print(f"评分:{review.rating.name}") # "评分:good"
print(f"优点:{review.pros}") # "优点:['出色的电池续航', '惊艳的显示屏']"
print(f"总结:{review.summary}") # "总结:一款显示效果优秀但散热问题明显的笔记本电脑"
真实场景示例
以下是一些可用于生产的示例,展示了 Outlines 如何解决常见问题:
🙋♂️ 客服工单分类
此示例演示如何将自由格式的客户邮件转换为结构化的服务工单。通过解析优先级、类别和升级标志等属性,代码能够实现支持问题的自动化路由和处理。
import outlines
from enum import Enum
from pydantic import BaseModel
from transformers import AutoTokenizer, AutoModelForCausalLM
from typing import List
MODEL_NAME = "microsoft/Phi-3-mini-4k-instruct"
model = outlines.from_transformers(
AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto"),
AutoTokenizer.from_pretrained(MODEL_NAME)
)
def alert_manager(ticket):
print("警报!", ticket)
class TicketPriority(str, Enum):
low = "low"
medium = "medium"
high = "high"
urgent = "urgent"
class ServiceTicket(BaseModel):
priority: TicketPriority
category: str
requires_manager: bool
summary: str
action_items: List[str]
customer_email = """
主题:紧急 — 支付后仍无法访问账户
我3小时前支付了高级套餐费用,但至今仍无法使用任何功能。我已经多次尝试退出并重新登录,但这仍然无效。这种情况实在无法接受,因为我还有一个小时就要为客户做演示,急需使用分析仪表盘。请立即解决问题,否则请退还我的款项。
"""
prompt = f"""
<|im_start|>user
请分析这封客户邮件:
{customer_email}
<|im_end|>
<|im_start|>assistant
"""
ticket = model(
prompt,
ServiceTicket,
max_new_tokens=500
)
# 使用结构化数据路由工单
ticket = ServiceTicket.model_validate_json(ticket)
if ticket.priority == "urgent" or ticket.requires_manager:
alert_manager(ticket)
📦 电商产品分类
此用例展示了 outlines 如何将产品描述转换为结构化的分类数据(例如主类目、子类目和属性),从而简化库存管理等任务。每个产品描述都会自动处理,减少手动分类的开销。
import outlines
from pydantic import BaseModel
from transformers import AutoTokenizer, AutoModelForCausalLM
from typing import List, Optional
MODEL_NAME = "microsoft/Phi-3-mini-4k-instruct"
model = outlines.from_transformers(
AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto"),
AutoTokenizer.from_pretrained(MODEL_NAME)
)
def update_inventory(product, category, sub_category):
print(f"已更新 {product.split(',')[0]},归入 {category}/{sub_category} 类别")
class ProductCategory(BaseModel):
main_category: str
sub_category: str
attributes: List[str]
brand_match: Optional[str]
# 批量处理产品描述
product_descriptions = [
"苹果 iPhone 15 Pro Max 256GB 钛金属款,6.7 英寸 Super Retina XDR 显示屏,支持 ProMotion 技术",
"有机棉 T 恤,男士中码,海军蓝,100% 可持续材料",
"KitchenAid 立式搅拌机,5 夸脱容量,红色,10 档速度调节,带揉面钩附件"
]
template = outlines.Template.from_string("""
<|im_start|>user
请对以下产品进行分类:
{{ description }}
<|im_end|>
<|im_start|>assistant
""")
# 获取所有产品的结构化分类
categories = model(
[template(description=desc) for desc in product_descriptions],
ProductCategory,
max_new_tokens=200
)
# 使用分类结果进行库存管理
categories = [
ProductCategory.model_validate_json(category) for category in categories
]
for product, category in zip(product_descriptions, categories):
update_inventory(product, category.main_category, category.sub_category)
📊 解析不完整数据的活动详情
本示例使用 outlines 将活动描述解析为结构化信息(如活动名称、日期、地点、类型和主题),即使数据不完整也能处理。它利用联合类型返回结构化的活动信息或“我不知道”的默认答案,确保在不同场景下都能稳健地提取信息。
import outlines
from typing import Union, List, Literal
from pydantic import BaseModel
from enum import Enum
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_NAME = "microsoft/Phi-3-mini-4k-instruct"
model = outlines.from_transformers(
AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto"),
AutoTokenizer.from_pretrained(MODEL_NAME)
)
class EventType(str, Enum):
conference = "conference"
webinar = "webinar"
workshop = "workshop"
meetup = "meetup"
other = "other"
class EventInfo(BaseModel):
"""关于科技活动的结构化信息"""
name: str
date: str
location: str
event_type: EventType
topics: List[str]
registration_required: bool
# 创建一个联合类型,可以是结构化的 EventInfo 或者 “我不知道”
EventResponse = Union[EventInfo, Literal["我不知道"]]
# 示例活动描述
event_descriptions = [
# 完整信息
"""
欢迎参加 2023 年 DevCon 开发者大会,本次顶级开发者会议将于 2023 年 11 月 15 日至 17 日在旧金山会议中心举行。会议主题包括人工智能/机器学习、云基础设施和 Web3。需提前注册。
""",
# 信息不足
"""
下周将举办一场科技活动,更多详情即将公布!
"""
]
# 处理活动
results = []
for description in event_descriptions:
prompt = f"""
<|im_start>system
您是一位乐于助人的助手
<|im_end|>
<|im_start>user
请提取以下科技活动的结构化信息:
{description}
如果信息足够完整,请返回包含以下字段的 JSON 对象:
- name:活动名称
- date:活动日期
- location:活动地点
- event_type:活动类型,可选值为 'conference'、'webinar'、'workshop'、'meetup' 或 'other'
- topics:会议主题列表
- registration_required:是否需要注册
如果现有信息不足以填写上述 JSON,且仅在此情况下,请回答 '我不知道'。
<|im_end|>
<|im_start>assistant
"""
# 联合类型使模型能够返回结构化数据或 “我不知道”
result = model(prompt, EventResponse, max_new_tokens=200)
results.append(result)
# 显示结果
for i, result in enumerate(results):
print(f"活动 {i+1}:")
if isinstance(result, str):
print(f" {result}")
else:
# 这是一个 EventInfo 对象
print(f" 名称:{result.name}")
print(f" 类型:{result.event_type}")
print(f" 日期:{result.date}")
print(f" 主题:{', '.join(result.topics)}")
print()
# 在下游流程中使用结构化数据
structured_count = sum(1 for r in results if isinstance(r, EventInfo))
print(f"成功从 {structured_count} 场活动中提取了数据,总共有 {len(results)} 场活动")
🗂️ 将文档分类为预定义类型
在此案例中,outlines 使用字面量类型规范将文档分类为预定义类别(例如“财务报告”、“法律合同”)。分类结果以表格形式展示,并通过类别分布汇总图呈现,说明结构化输出如何简化内容管理。
import outlines
from typing import Literal, List
import pandas as pd
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_NAME = "microsoft/Phi-3-mini-4k-instruct"
model = outlines.from_transformers(
AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto"),
AutoTokenizer.from_pretrained(MODEL_NAME)
)
# 使用 Literal 定义分类类别
DocumentCategory = Literal[
"财务报告",
"法律合同",
"技术文档",
"营销材料",
"个人信件"
]
# 待分类的示例文档
documents = [
"第三季度财务摘要:收入同比增长15%,达到1240万美元。EBITDA利润率从去年第三季度的19%提升至23%。运营费用...",
"本协议由甲方和乙方于…日签订,以下简称‘双方’,",
"该API接受带有JSON负载的POST请求。必需参数包括‘user_id’和‘transaction_type’。成功时,端点返回200状态码。"
]
template = outlines.Template.from_string("""
<|im_start|>user
请将以下文档精确地归类到下列类别之一:
- 财务报告
- 法律合同
- 技术文档
- 市场营销材料
- 个人通信
文档:
{{ document }}
<|im_end|>
<|im_start|>assistant
""")
# 对文档进行分类
def classify_documents(texts: List[str]) -> List[DocumentCategory]:
results = []
for text in texts:
prompt = template(document=text)
# 模型必须返回预定义的其中一个类别
category = model(prompt, DocumentCategory, max_new_tokens=200)
results.append(category)
return results
# 执行分类
classifications = classify_documents(documents)
# 创建一个简单的结果表格
results_df = pd.DataFrame({
"文档": [doc[:50] + "..." for doc in documents],
"分类": classifications
})
print(results_df)
# 按类别统计文档数量
category_counts = pd.Series(classifications).value_counts()
print("\n类别分布:")
print(category_counts)
📅 使用函数调用从请求中安排会议
此示例展示了outlines如何解析自然语言会议请求,并将其转换为与预定义函数参数匹配的结构化格式。一旦提取出会议详情(例如标题、日期、时长、参会人员),这些信息就会被用来自动安排会议。
import outlines
import json
from typing import List, Optional
from datetime import date
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_NAME = "microsoft/phi-4"
model = outlines.from_transformers(
AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto"),
AutoTokenizer.from_pretrained(MODEL_NAME)
)
# 定义一个带类型参数的函数
def schedule_meeting(
title: str,
date: date,
duration_minutes: int,
attendees: List[str],
location: Optional[str] = None,
agenda_items: Optional[List[str]] = None
):
"""根据指定的细节安排会议"""
# 在实际应用中,这会创建会议
meeting = {
"title": title,
"date": date,
"duration_minutes": duration_minutes,
"attendees": attendees,
"location": location,
"agenda_items": agenda_items
}
return f"会议‘{title}’已安排在{date}举行,共有{len(attendees)}位参会者"
# 自然语言请求
user_request = """
我需要下周二下午2点与工程团队安排一次产品路线图评审会议。会议应持续90分钟。请邀请john@example.com、sarah@example.com以及product@example.com的产品团队参加。
"""
# Outlines会自动从函数签名中推断出所需的结构
prompt = f"""
<|im_start|>user
请从该请求中提取会议详情:
{user_request}
<|im_end|>
<|im_start|>assistant
"""
meeting_params = model(prompt, schedule_meeting, max_new_tokens=200)
# 结果是一个与函数参数匹配的字典
meeting_params = json.loads(meeting_params)
print(meeting_params)
# 使用提取的参数调用函数
result = schedule_meeting(**meeting_params)
print(result)
# “会议‘产品路线图评审’已安排在2023年10月17日举行,共有3位参会者”
📝 使用可重用模板动态生成提示
通过基于Jinja的模板,此示例展示了如何为情感分析等任务生成动态提示。它说明了如何轻松地复用和自定义提示——包括少样本学习策略——以适应不同的内容类型,同时确保输出保持结构化。
import outlines
from typing import List, Literal
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_NAME = "microsoft/phi-4"
model = outlines.from_transformers(
AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto"),
AutoTokenizer.from_pretrained(MODEL_NAME)
)
# 1. 创建一个使用Jinja语法的可重用模板
sentiment_template = outlines.Template.from_string("""
<|im_start>user
请分析以下{{ content_type }}的情感倾向:
{{ text }}
请将您的分析结果表述为“正面”、“负面”或“中性”。
<|im_end>
<|im_start>assistant
""")
# 2. 使用不同参数生成提示
review = "这家餐厅完全超出了我的预期。服务太棒了!"
prompt = sentiment_template(content_type="评论", text=review)
# 3. 使用模板化的提示进行结构化生成
result = model(prompt, Literal["正面", "负面", "中性"])
print(result) # "正面"
# 模板也可以从文件中加载
example_template = outlines.Template.from_file("templates/few_shot.txt")
# 结合示例进行少样本学习
examples = [
("食物很冷", "负面"),
("员工很友好", "正面")
]
few_shot_prompt = example_template(examples=examples, query="服务很慢")
print(few_shot_prompt)
他们使用outlines


模型集成
| 模型类型 | 描述 | 文档 |
|---|---|---|
| 服务器支持 | vLLM 和 Ollama | 服务器集成 → |
| 本地模型支持 | transformers 和 llama.cpp | 模型集成 → |
| API支持 | OpenAI 和 Gemini | API集成 → |
核心功能
| 功能 | 描述 | 文档 |
|---|---|---|
| 多选 | 将输出限制为预定义选项 | 多选指南 → |
| 函数调用 | 从函数签名中推断结构 | 函数指南 → |
| JSON/Pydantic | 生成符合 JSON 模式的输出 | JSON 指南 → |
| 正则表达式 | 生成符合正则表达式模式的文本 | 正则表达式指南 → |
| 语法 | 强制复杂的输出结构 | 语法指南 → |
其他功能
| 功能 | 描述 | 文档 |
|---|---|---|
| 提示模板 | 将复杂提示与代码分离 | 模板指南 → |
| 自定义类型 | 直观的界面用于构建复杂类型 | Python 类型指南 → |
| 应用 | 将模板和类型封装成函数 | 应用指南 → |
关于 .txt


Outlines 由 .txt 开发并维护,该公司致力于使大语言模型在生产级应用中更加可靠。
我们的重点是通过以下方式推动结构化生成技术的发展:
请关注我们的 Twitter 或访问我们的 博客,以了解我们在提升大语言模型可靠性方面的最新进展。
社区



引用 Outlines
@article{willard2023efficient,
title={高效的大语言模型引导式生成},
author={Willard, Brandon T and Louf, R{\'e}mi},
journal={arXiv 预印本 arXiv:2307.09702},
year={2023}
}
版本历史
1.2.122026/03/031.2.112026/02/131.2.102026/02/061.2.92025/11/241.2.82025/10/271.2.72025/10/141.2.62025/10/141.2.52025/09/151.2.42025/09/021.2.32025/08/111.2.22025/08/081.2.12025/08/041.2.02025/07/311.1.12025/07/111.1.02025/07/101.0.42025/07/041.0.32025/07/011.0.22025/06/261.0.12025/06/201.0.02025/06/18常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。