decord
Decord 是一款专为深度学习设计的高效视频加载工具,旨在让视频数据的读取像处理图片一样流畅自然。在训练神经网络时,随机访问视频帧是常见需求,但传统方式往往效率低下且操作繁琐。Decord 通过封装硬件加速解码器(如 FFMPEG、NVIDIA 及 Intel codecs),提供了智能的视频切片与随机读取功能,显著提升了数据加载速度,完美解决了视频随机访问的性能瓶颈。
除了视频,Decord 还能同步解码音频,让用户能轻松获取音画同步的数据片段,实现音视频处理的一站式解决方案。它特别支持“智能洗牌”策略,进一步优化了深度学习训练中的数据预处理流程。
这款工具非常适合 AI 研究人员、深度学习开发者以及需要处理大规模视频数据集的工程师使用。无论是构建视频分类模型还是动作识别系统,Decord 都能凭借其卓越的随机访问性能和灵活的框架桥接能力,成为你数据处理流水线中的得力助手。目前它支持 Linux、macOS 和 Windows 平台,并可通过 pip 快速安装,同时也支持从源码编译以启用 GPU 加速功能。
使用场景
某视频内容审核团队正在构建基于深度学习的违规动作识别模型,需要每天对数万段监控视频进行随机帧采样训练。
没有 decord 时
- 读取速度极慢:使用传统 FFmpeg 或 OpenCV 逐帧解码,面对海量视频数据时,GPU 经常因等待数据而空闲,训练效率低下。
- 随机访问困难:深度学习训练需要随机打乱视频片段顺序,传统方法难以高效实现“跳跃式”读取,往往被迫顺序加载后再洗牌,内存占用极高。
- 音画同步复杂:若模型需同时分析声音与画面,开发者需自行编写复杂的同步逻辑来分别处理音频和视频流,极易出现声画不同步的 Bug。
- 硬件加速缺失:默认方案无法便捷调用 NVIDIA NVDEC 等硬件解码器,导致 CPU 负载长期满载,服务器资源浪费严重。
使用 decord 后
- 吞吐量大幅提升:decord 底层封装了硬件加速解码器,支持高并发随机读取,使数据加载速度提升数倍,GPU 利用率瞬间跑满。
- 智能随机切片:内置的智能洗牌机制允许像读取图片一样轻松随机抽取视频帧,无需预加载整个视频,显著降低内存压力。
- 音画一键同步:提供统一的音视频切片接口,单次调用即可返回时间轴严格对齐的视频帧与音频波形,彻底解决同步难题。
- 无缝集成框架:原生支持 PyTorch 和 MXNet 等主流框架,只需几行代码即可替换原有 DataLoader,快速启用 GPU 硬解加速。
decord 通过硬件加速与智能随机访问机制,将繁琐的视频数据处理转化为高效的深度学习输入流,让模型训练不再受限于 I/O 瓶颈。
运行环境要求
- Linux
- macOS (>= 10.12)
- Windows
- 非必需
- 若需启用 GPU 加速解码,需要 NVIDIA GPU 支持 NVDEC,并安装 CUDA Toolkit
- 具体显存大小和 CUDA 版本未说明,但需确保系统能正确链接 libnvcuvid.so
未说明
快速开始
Decord
![]()
![]()


Decord 是 Record 的逆过程。它基于硬件加速视频解码器的轻量封装,提供了便捷的视频切片方法,例如:
- FFMPEG/LibAV(已完成)
- Nvidia 编解码器(已完成)
- Intel 编解码器
Decord 的设计旨在解决深度学习中视频随机打乱时的卡顿问题,从而提供类似于随机图像加载器的流畅体验。
此外,Decord 还可以从视频和音频文件中解码音频。用户可以同时对视频和音频进行切片以获得同步的结果,因此它为视频和音频解码提供了一站式的解决方案。
目录
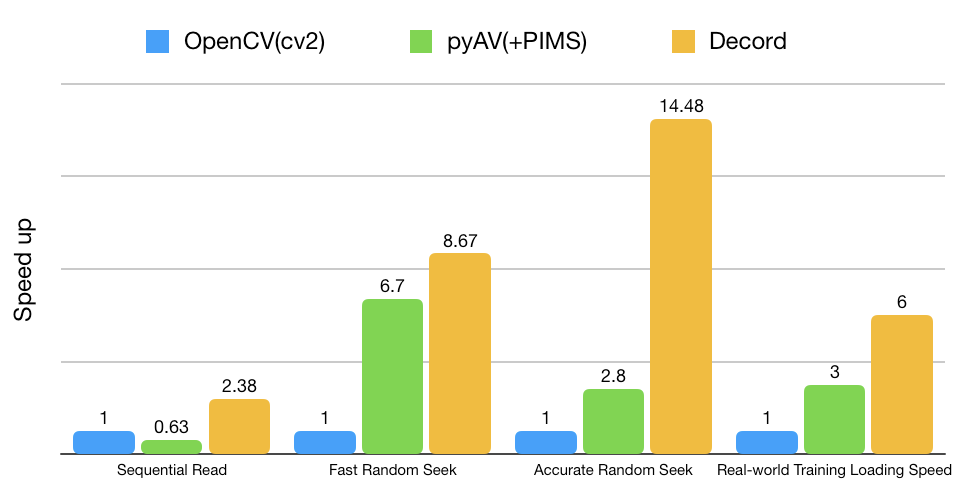
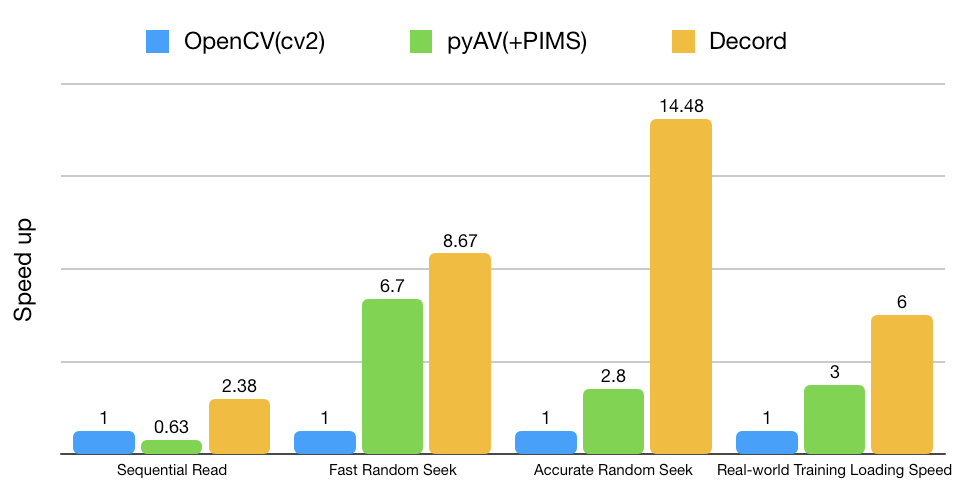
初步基准测试
Decord 在处理随机访问模式方面表现出色,而这种模式在神经网络训练中非常常见。
安装
通过 pip 安装
只需运行以下命令:
pip install decord
支持的平台:
- Linux
- Mac OS >= 10.12, python>=3.5
- Windows
请注意,目前 PYPI 上仅提供 CPU 版本。如需启用 GPU 加速,请从源代码编译安装。
从源代码安装
Linux
安装用于构建共享库的系统软件包。对于 Debian/Ubuntu 用户,执行以下操作:
# 官方 PPA 提供的是 ffmpeg 2.8,功能严重不足,我们这里使用 ffmpeg 4.0
sudo add-apt-repository ppa:jonathonf/ffmpeg-4 # 对于 ubuntu20.04,官方 PPA 已经是版本 4.2,可以跳过这一步
sudo apt-get update
sudo apt-get install -y build-essential python3-dev python3-setuptools make cmake
sudo apt-get install -y ffmpeg libavcodec-dev libavfilter-dev libavformat-dev libavutil-dev
# 注意:确保你有 cmake 3.8 或更高版本,如果太旧,可以从 cmake 官网安装
递归克隆仓库(重要):
git clone --recursive https://github.com/dmlc/decord
在源码根目录下构建共享库:
cd decord
mkdir build && cd build
cmake .. -DUSE_CUDA=0 -DCMAKE_BUILD_TYPE=Release
make
你可以指定 -DUSE_CUDA=ON 或 -DUSE_CUDA=/path/to/cuda 或 -DUSE_CUDA=ON -DCMAKE_CUDA_COMPILER=/path/to/cuda/nvcc 来启用 NVDEC 硬件加速解码:
cmake .. -DUSE_CUDA=ON -DCMAKE_BUILD_TYPE=Release
请注意,如果你遇到 libnvcuvid.so 相关的问题(例如参见 #102),很可能是缺少该库的链接。你可以手动查找它(ldconfig -p | grep libnvcuvid)并将其链接到 CUDA_TOOLKIT_ROOT_DIR\lib64,以便 decord 能够顺利检测并链接正确的库。
要指定自定义的 FFMPEG 库路径,使用 -DFFMPEG_DIR=/path/to/ffmpeg。
安装 Python 绑定:
cd ../python
# 选项 1:将 Python 路径添加到 $PYTHONPATH,你需要单独安装 numpy
pwd=$PWD
echo "PYTHONPATH=$PYTHONPATH:$pwd" >> ~/.bashrc
source ~/.bashrc
# 选项 2:使用 setuptools 安装
python3 setup.py install --user
Mac OS
macOS 上的安装与 Linux 类似。但 macOS 用户需要先安装 clang、GNU Make 和 cmake 等构建工具。
clang 和 GNU Make 等工具包含在 macOS 的 Command Line Tools 中。安装方法如下:
xcode-select --install
要安装其他所需的软件包,如 cmake,建议先安装 Homebrew,这是一个流行的 macOS 包管理器。详细说明可在其官网找到。
安装 Homebrew 后,再安装 cmake 和 ffmpeg:
brew install cmake ffmpeg
# 注意:确保你有 cmake 3.8 或更高版本,如果太旧,可以从 cmake 官网安装
递归克隆仓库(重要):
git clone --recursive https://github.com/dmlc/decord
然后进入根目录构建共享库:
cd decord
mkdir build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make
安装 Python 绑定:
cd ../python
# 选项 1:将 Python 路径添加到 $PYTHONPATH,你需要单独安装 numpy
pwd=$PWD
echo "PYTHONPATH=$PYTHONPATH:$pwd" >> ~/.bash_profile
source ~/.bash_profile
# 选项 2:使用 setuptools 安装
python3 setup.py install --user
``。
#### Windows
在 Windows 上,你需要 CMake 和 Visual Studio 来进行 C++ 编译。
- 首先,安装 `git`、`cmake`、`ffmpeg` 和 `python`。你可以使用 [Chocolatey](https://chocolatey.org/) 来管理软件包,类似于 Linux/Mac OS。
- 其次,安装 [`Visual Studio 2017 Community`](https://visualstudio.microsoft.com/),这可能需要一些时间。
当依赖项准备就绪后,打开命令提示符:
```bash
cd your-workspace
git clone --recursive https://github.com/dmlc/decord
cd decord
mkdir build
cd build
cmake -DCMAKE_CXX_FLAGS="/DDECORD_EXPORTS" -DCMAKE_CONFIGURATION_TYPES="Release" -G "Visual Studio 15 2017 Win64" ..
# 打开 `decord.sln` 并构建项目
使用
Decord 提供了最小化的 API 集合,方便快速上手。你也可以查看 Jupyter Notebook 中的示例。
VideoReader
VideoReader 用于直接从视频文件中访问帧。
from decord import VideoReader
from decord import cpu, gpu
vr = VideoReader('examples/flipping_a_pancake.mkv', ctx=cpu(0))
# 文件对象同样适用,可用于内存中的解码
with open('examples/flipping_a_pancake.mkv', 'rb') as f:
vr = VideoReader(f, ctx=cpu(0))
print('视频帧数:', len(vr))
# 1. 最简单的方式是直接访问帧
for i in range(len(vr)):
# 视频读取器会以最高效的方式处理寻址和跳过操作
frame = vr[i]
print(frame.shape)
# 如果需要一次获取多帧,可以使用 get_batch
# 这是获取大量帧的高效方式
frames = vr.get_batch([1, 3, 5, 7, 9])
print(frames.shape)
# (5, 240, 320, 3)
# 重复的帧索引会被接受并在内部处理,以避免重复解码
frames2 = vr.get_batch([1, 2, 3, 2, 3, 4, 3, 4, 5]).asnumpy()
print(frames2.shape)
# (9, 240, 320, 3)
# 2. 你也可以采用 cv2 风格的读取方式
# 跳过 100 帧
vr.skip_frames(100)
# 寻找开头
vr.seek(0)
batch = vr.next()
print('帧形状:', batch.shape)
print('numpy 帧:', batch.asnumpy())
VideoLoader
VideoLoader 专为使用大量视频文件训练深度学习模型而设计。它提供了智能的视频打乱技术,以实现高效的随机访问性能(我们知道,在视频中进行定位是非常缓慢且冗余的)。这些优化都隐藏在底层的 C++ 代码中,用户无需感知。
from decord import VideoLoader
from decord import cpu, gpu
vl = VideoLoader(['1.mp4', '2.avi', '3.mpeg'], ctx=[cpu(0)], shape=(2, 320, 240, 3), interval=1, skip=5, shuffle=1)
print('总批次数:', len(vl))
for batch in vl:
print(batch[0].shape)
视频的打乱操作可能比较复杂,因此我们提供了多种模式:
shuffle = -1 # 智能打乱模式,基于视频属性(尚未实现)
shuffle = 0 # 全部按顺序,不进行定位,按照初始文件名顺序
shuffle = 1 # 随机文件名顺序,每个视频内部不进行随机访问,非常高效
shuffle = 2 # 完全随机顺序
shuffle = 3 # 仅在每个视频内随机访问帧
AudioReader
AudioReader 用于直接从视频(如果有音频轨道)和音频文件中读取样本。
from decord import AudioReader
from decord import cpu, gpu
# 可以指定所需的采样率和声道布局
# 声道方面有两个选项:保持原始布局或转换为单声道
ar = AudioReader('example.mp3', ctx=cpu(0), sample_rate=44100, mono=False)
print('音频样本的形状: ', ar.shape())
# 访问音频样本
print('第一个样本: ', ar[0])
print('前五个样本: ', ar[0:5])
print('获取一批样本: ', ar.get_batch([1,3,5]))
AVReader
AVReader 是 AudioReader 和 VideoReader 的封装器,允许您同时对视频和音频进行切片操作。
from decord import AVReader
from decord import cpu, gpu
av = AVReader('example.mov', ctx=cpu(0))
# 同时访问视频帧和对应的音频样本
audio, video = av[0:20]
# audio 中的每个元素都是与视频帧相对应的一批音频样本
print('帧数: ', len(audio))
print('第一帧的音频样本形状: ', audio[0].shape)
print('第一帧的形状: ', video.asnumpy()[0].shape)
# 同样地,也可以获取一批数据
audio2, video2 = av.get_batch([1,3,5])
深度学习框架的桥接:
将 Decord 与流行的深度学习框架连接起来,对于训练和推理非常重要。
- Apache MXNet(已完成)
- PyTorch(已完成)
- TensorFlow(已完成)
使用深度学习框架的桥接非常简单,例如,可以将默认张量输出设置为 mxnet.ndarray:
import decord
vr = decord.VideoReader('examples/flipping_a_pancake.mkv')
print('原生输出: ', type(vr[0]), vr[0].shape)
# 原生输出: <class 'decord.ndarray.NDArray'>, (240, 426, 3)
# 只需设置一次输出类型即可
decord.bridge.set_bridge('mxnet')
print(type(vr[0], vr[0].shape))
# <class 'mxnet.ndarray.ndarray.NDArray'> (240, 426, 3)
# 或者切换到 PyTorch 和 TensorFlow(>=2.2.0)
decord.bridge.set_bridge('torch')
decord.bridge.set_bridge('tensorflow')
# 或者恢复为 Decord 原生格式
decord.bridge.set_bridge('native')
版本历史
v0.6.02021/06/14v0.5.22021/02/09v0.5.12021/02/09v0.5.02021/02/07v0.4.22020/11/13v0.4.12020/10/01v0.4.02020/10/01v0.3.92020/05/11v0.3.82020/05/02v0.3.72020/04/28v0.3.32019/12/20v0.3.02019/10/01v0.2.12019/09/27v0.2.02019/09/27v0.1.02019/09/11常见问题
相似工具推荐
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
tabby
Tabby 是一款可私有化部署的开源 AI 编程助手,旨在为开发团队提供 GitHub Copilot 的安全替代方案。它核心解决了代码辅助过程中的数据隐私顾虑与云端依赖问题,让企业能够在完全掌控数据的前提下享受智能代码补全、聊天问答及上下文理解带来的效率提升。 这款工具特别适合注重代码安全的企业开发团队、希望本地化运行大模型的科研机构,以及拥有消费级显卡的个人开发者。Tabby 的最大亮点在于其“开箱即用”的自包含架构,无需配置复杂的数据库或依赖云服务即可快速启动。同时,它对硬件十分友好,支持在普通的消费级 GPU 上流畅运行,大幅降低了部署门槛。此外,Tabby 提供了标准的 OpenAPI 接口,能轻松集成到现有的云 IDE 或内部开发流程中,并支持通过 REST API 接入自定义文档以增强知识上下文。从代码自动补全到基于 Git 仓库的智能问答,Tabby 致力于成为开发者身边懂业务、守安全的智能伙伴。
generative-models
Generative Models 是 Stability AI 推出的开源项目,核心亮点在于最新发布的 Stable Video 4D 2.0(SV4D 2.0)。这是一个先进的视频转 4D 扩散模型,旨在解决从单一视角视频中生成高保真、多视角动态 3D 资产的技术难题。传统方法往往难以处理物体自遮挡或背景杂乱的情况,且生成的动态细节容易模糊,而 SV4D 2.0 通过改进的架构,显著提升了运动中的画面锐度与时空一致性,无需依赖额外的多视角参考图即可稳健地合成新颖视角的视频。 该项目特别适合计算机视觉研究人员、AI 开发者以及从事 3D 内容创作的设计师使用。对于研究者,它提供了探索 4D 生成前沿的完整代码与训练权重;对于开发者,其支持自动回归生成长视频及低显存优化选项,便于集成与调试;对于设计师,它能将简单的物体运动视频快速转化为可用于游戏或影视的多视角 4D 素材。技术层面,SV4D 2.0 支持一次性生成 12 帧视频对应 4 个相机视角(或 5 帧对应 8 视角),分辨率达 576x576,并能更好地泛化至真实世界场景。用户只需准备一段白底或经简单抠图处理的物体运动视频,