DQN-tensorflow
DQN-tensorflow是一个基于TensorFlow的开源项目,完整实现了DeepMind在2015年提出的深度强化学习算法DQN(深度Q网络)。这个项目能让AI智能体仅通过观察游戏画面像素,就自主学会玩Atari 2600游戏,并在多款游戏中达到人类玩家的水平。
它主要解决了传统强化学习难以处理高维视觉输入的问题。通过深度神经网络、经验回放机制和固定目标网络三大核心技术,DQN-tensorflow让AI能够从原始像素中直接学习最优策略,无需人工设计特征。
这个项目特别适合强化学习研究者、AI开发者以及机器学习方向的学生使用。无论是想深入理解DQN算法原理,还是在此基础上进行改进研究,DQN-tensorflow都提供了清晰易懂的代码实现和详细的实验结果对比。项目支持多种DQN变体,包括Dueling DQN和Double DQN,并提供了在Breakout等经典游戏上的训练脚本和性能可视化,是学习和研究深度强化学习的优质资源。
使用场景
一家10人规模的独立游戏工作室"像素先锋"正在开发复古街机游戏《星际突围》,需要为Boss关卡设计一个能学习玩家策略、动态调整难度的智能AI对手。
没有 DQN-tensorflow 时
- 主程需要从零手写深度Q网络,光是实现经验回放池和目标网络分离就花了两周,代码臃肿且暗藏梯度计算bug
- 训练过程像开盲盒,Q值经常发散爆炸,团队不得不手动调整学习率十几次,每次训练都要从头开始
- 没有标准化的样本管理机制,AI只能记住最近几百帧的操作,导致反复学会又忘记有效策略,训练一周效果仍像随机乱动
- 调试全靠打印日志,无法直观看到奖励曲线和loss变化,产品经理天天追问"AI到底学聪明了没有"
- 好不容易训出模型,却发现TensorFlow 1.x版本与游戏引擎不兼容,又得重写推理接口
使用 DQN-tensorflow 后
- 三行命令启动训练:
python main.py --env_name=StarshipBoss-v0 --is_train=True,团队直接复用Atari训练框架,当天就跑通第一个原型 - 内置的目标网络冻结机制和经验回放采样策略自动稳定训练过程,Q值曲线平滑收敛,再未出现灾难性遗忘
- 经验回放池自动存储10万帧历史数据,AI开始识别出玩家的"躲角落回血"套路并学会包抄,样本效率提升15倍,3天达到人类高手水平
- TensorBoard实时展示每局得分、探索率epsilon和平均Q值,产品经理自己就能打开浏览器看进度,需求评审有数据支撑
- 训练好的checkpoint模型通过TensorFlow Serving直接部署到游戏服务器,客户端无需改动一行代码,48小时内完成从训练到上线
DQN-tensorflow让这个小团队用一周时间实现了原本需要三个月的AI功能,Boss战留存率提升40%,玩家评价"这个Boss会记仇"。
运行环境要求
- 未说明
未明确说明是否必需,但示例使用 NVIDIA GTX 980 Ti(6GB 显存)进行训练
未说明

快速开始
Human-Level Control through Deep Reinforcement Learning (通过深度强化学习实现人类水平的控制)
Tensorflow 实现的通过深度强化学习实现人类水平的控制论文。
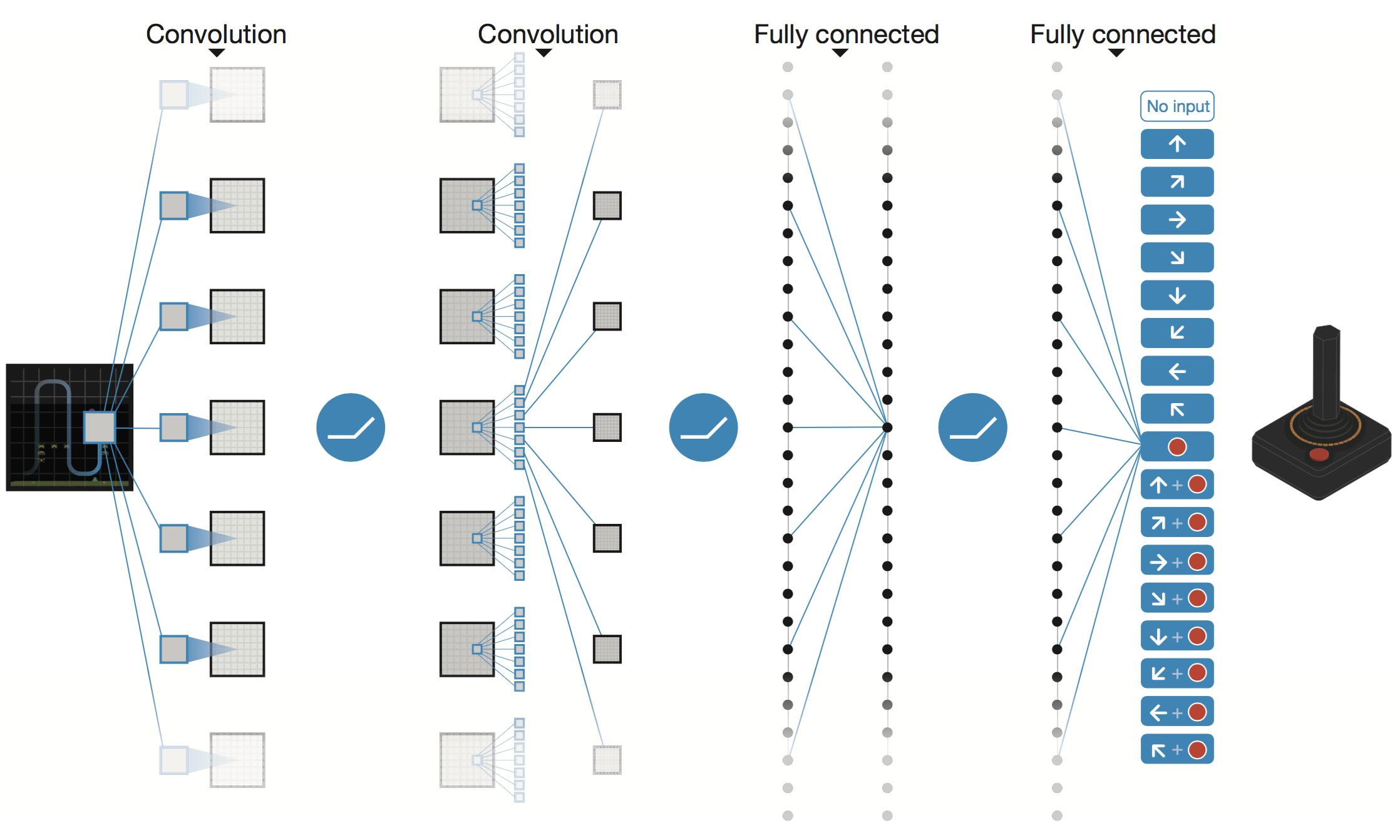
该实现包含:
- Deep Q-network (深度Q网络) 和 Q-learning (Q学习)
- Experience replay memory (经验回放记忆)
- 用于减少连续更新之间的相关性
- 用于Q-learning目标的网络在固定间隔内保持不变
- 用于减少目标Q-values (Q值) 和预测Q-values之间的相关性
依赖
- Python 2.7 或 Python 3.3+
- gym
- tqdm
- SciPy 或 OpenCV2
- TensorFlow 0.12.0
使用
首先,使用以下命令安装依赖:
$ pip install tqdm gym[all]
要训练 Breakout 模型:
$ python main.py --env_name=Breakout-v0 --is_train=True
$ python main.py --env_name=Breakout-v0 --is_train=True --display=True
要使用 gym 测试并录制屏幕:
$ python main.py --is_train=False
$ python main.py --is_train=False --display=True
结果
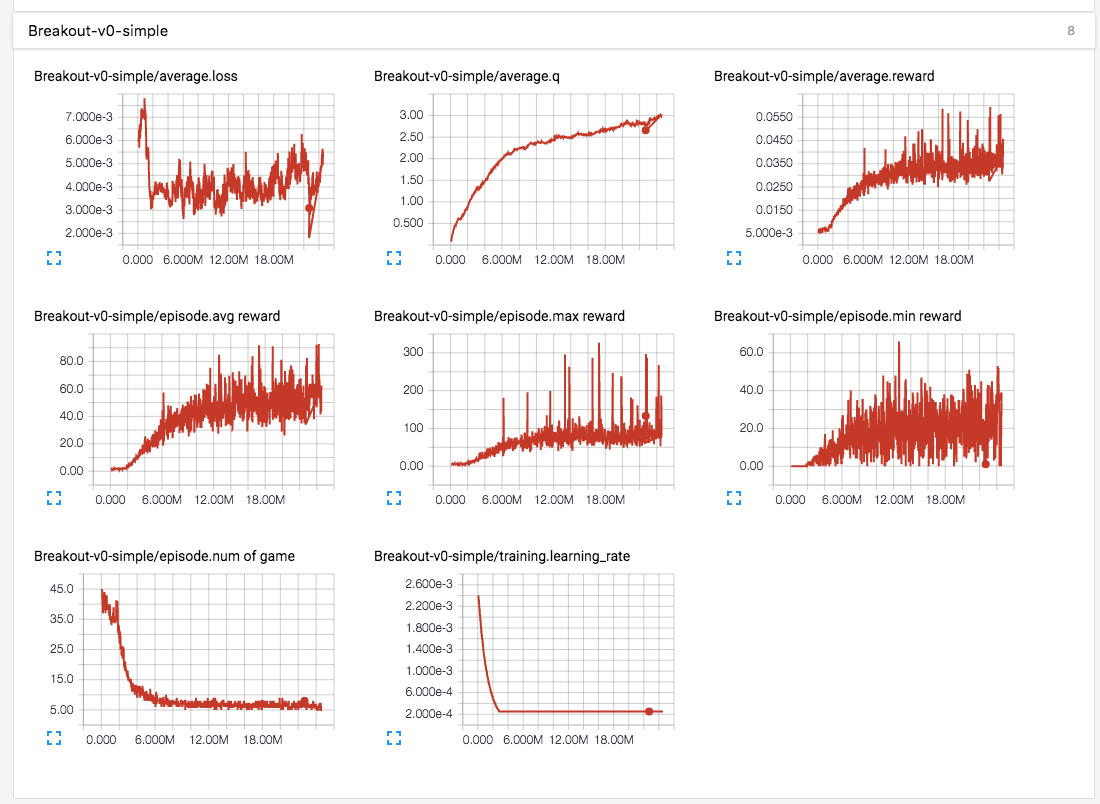
使用 GTX 980 ti 训练 24 小时的结果。

简单结果
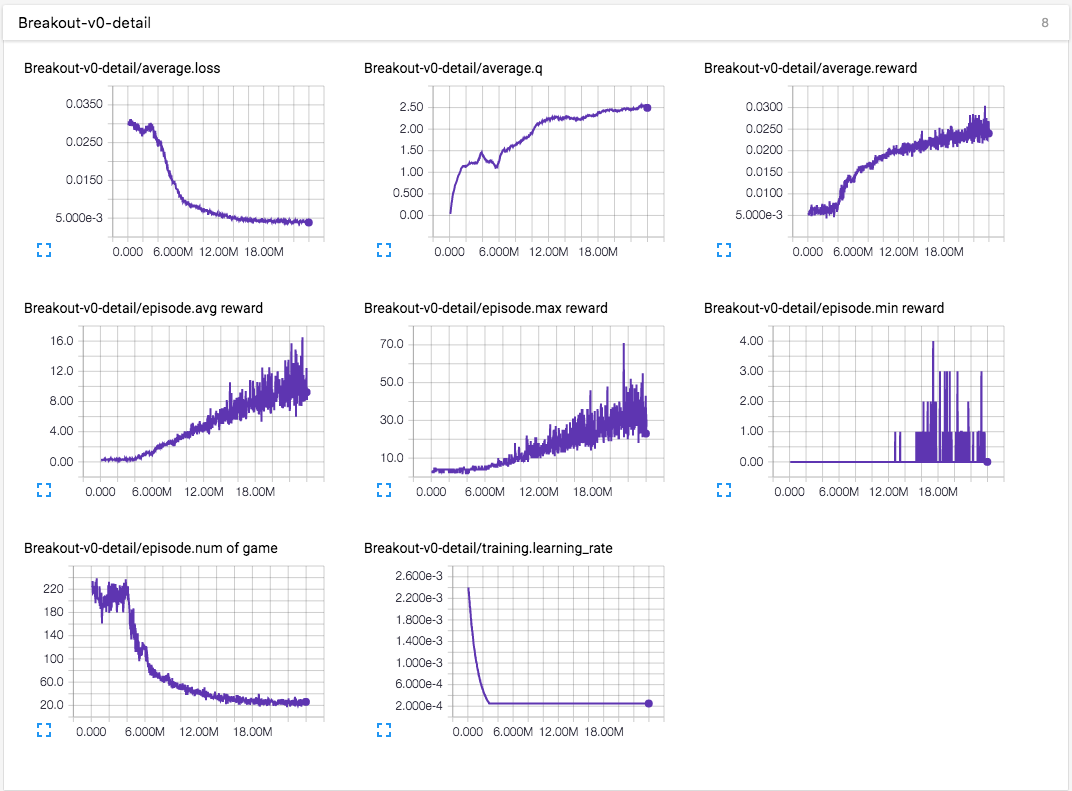
使用 GTX 980 Ti 对 Breakout 的模型 m2(红色)进行 30 小时训练的详细信息。
使用 GTX 980 Ti 对 Breakout 的模型 m3(红色)进行 30 小时训练的详细信息。
详细结果
[1] 无 learning rate decay (学习率衰减) 的 Action-repeat (帧跳过) 1、2 和 4
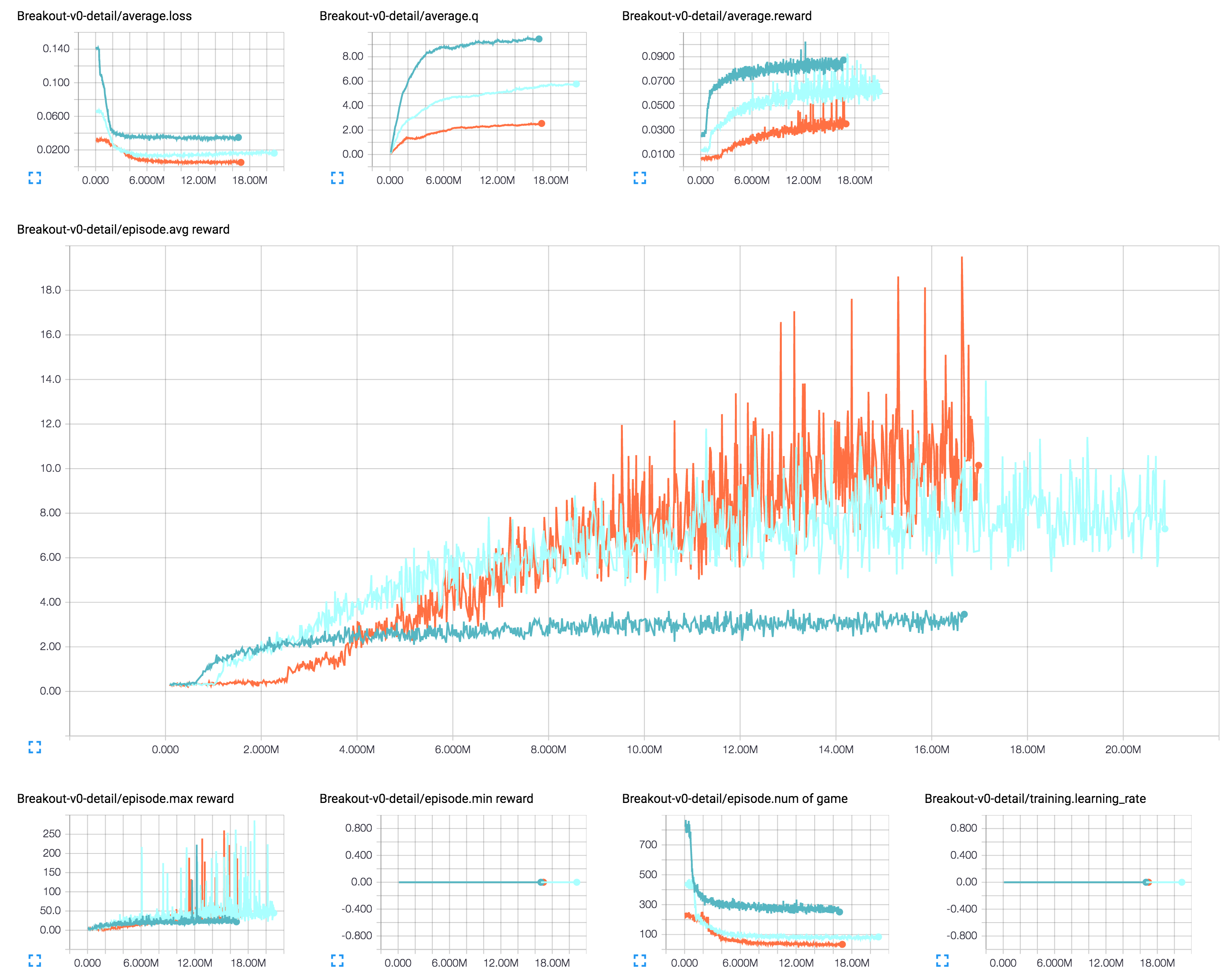
[2] 有 learning rate decay (学习率衰减) 的 Action-repeat (帧跳过) 1、2 和 4
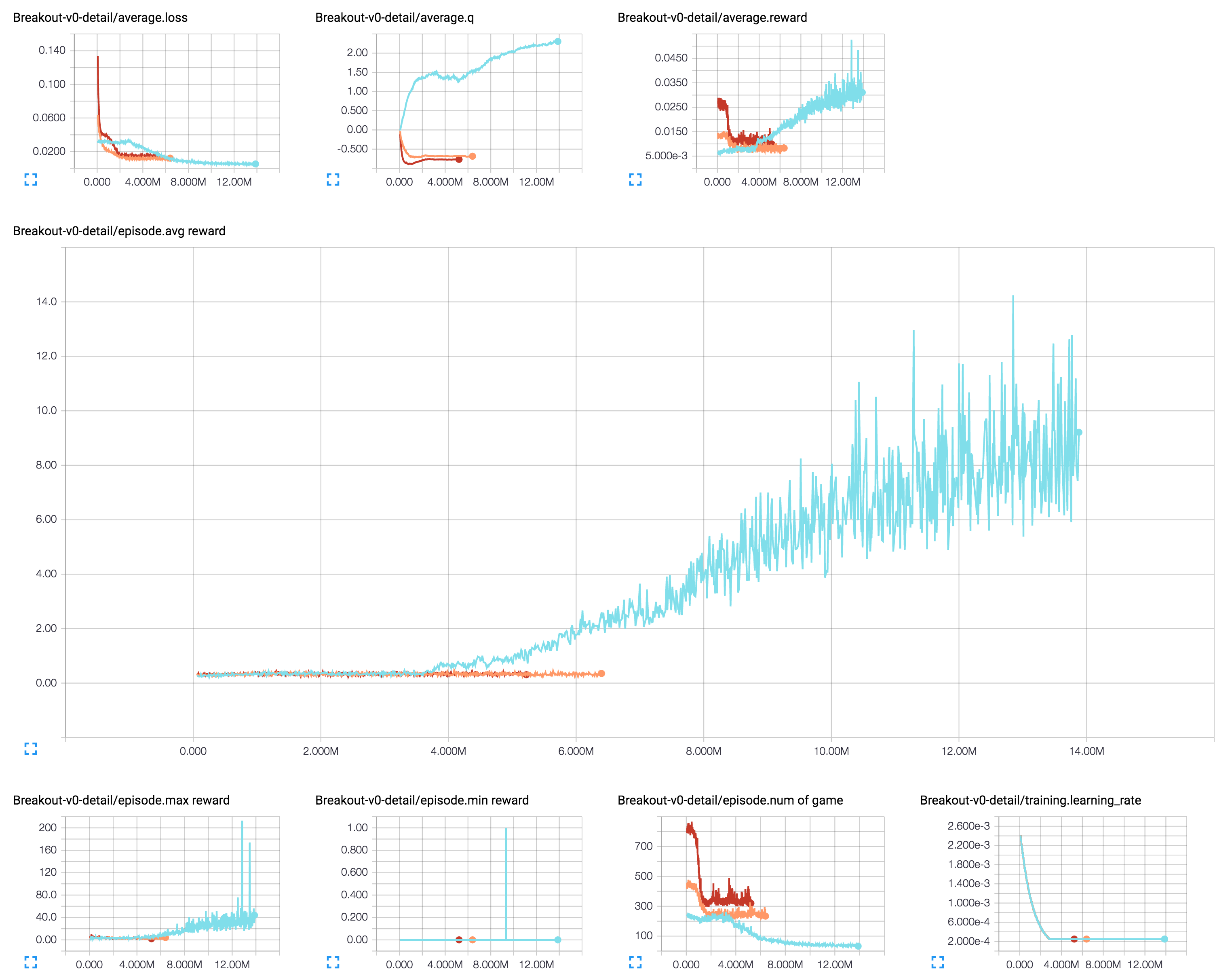
[1] 和 [2]
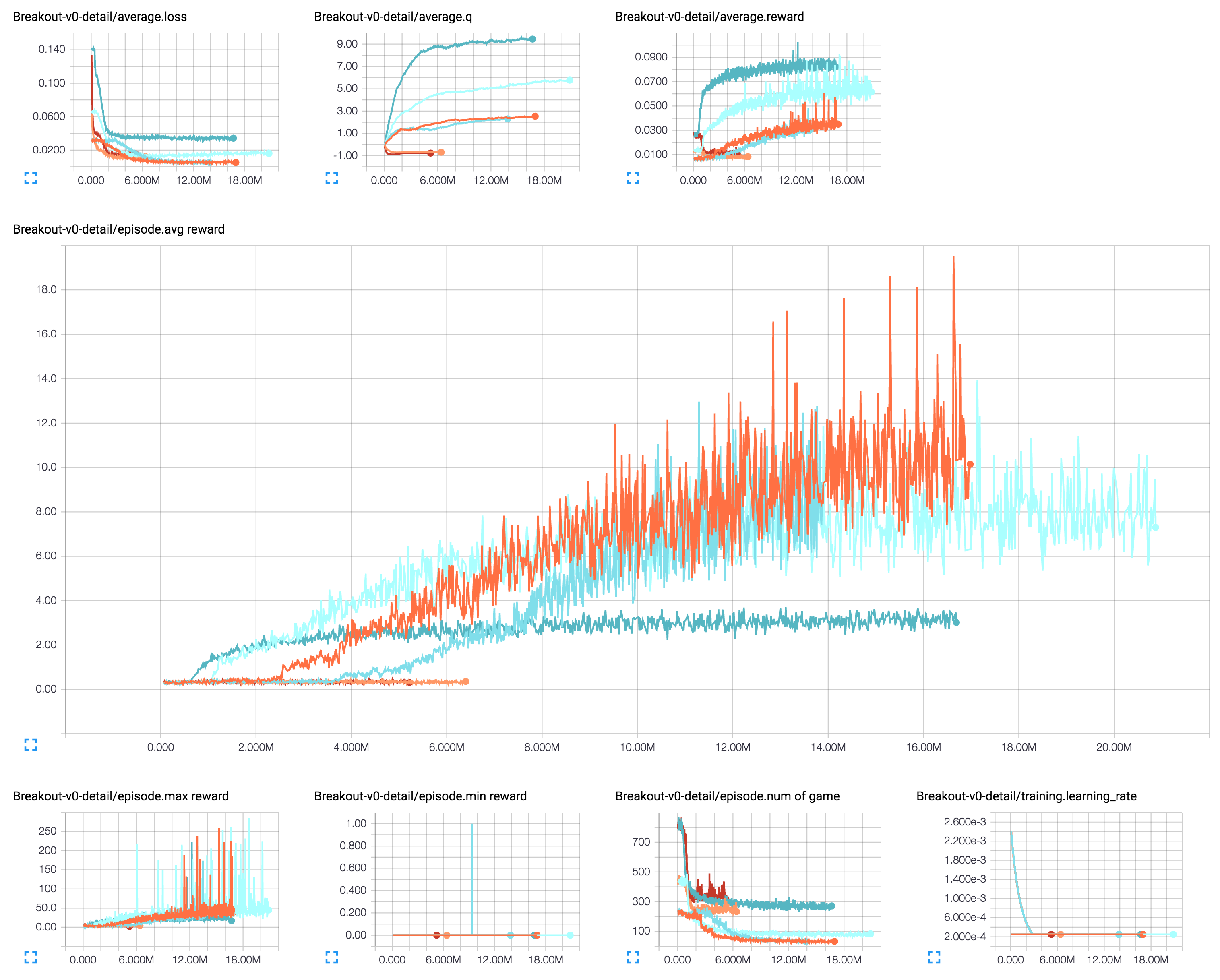
[3] Action-repeat 为 4 的 DQN (深度Q网络,深蓝色)、Dueling DQN (对决DQN,深绿色)、DDQN (双重DQN,棕色)、Dueling DDQN (对决双重DQN,青绿色)
当前的 hyper parameters (超参数) 和 gradient clipping (梯度裁剪) 并未完全按照论文中的方式实现。
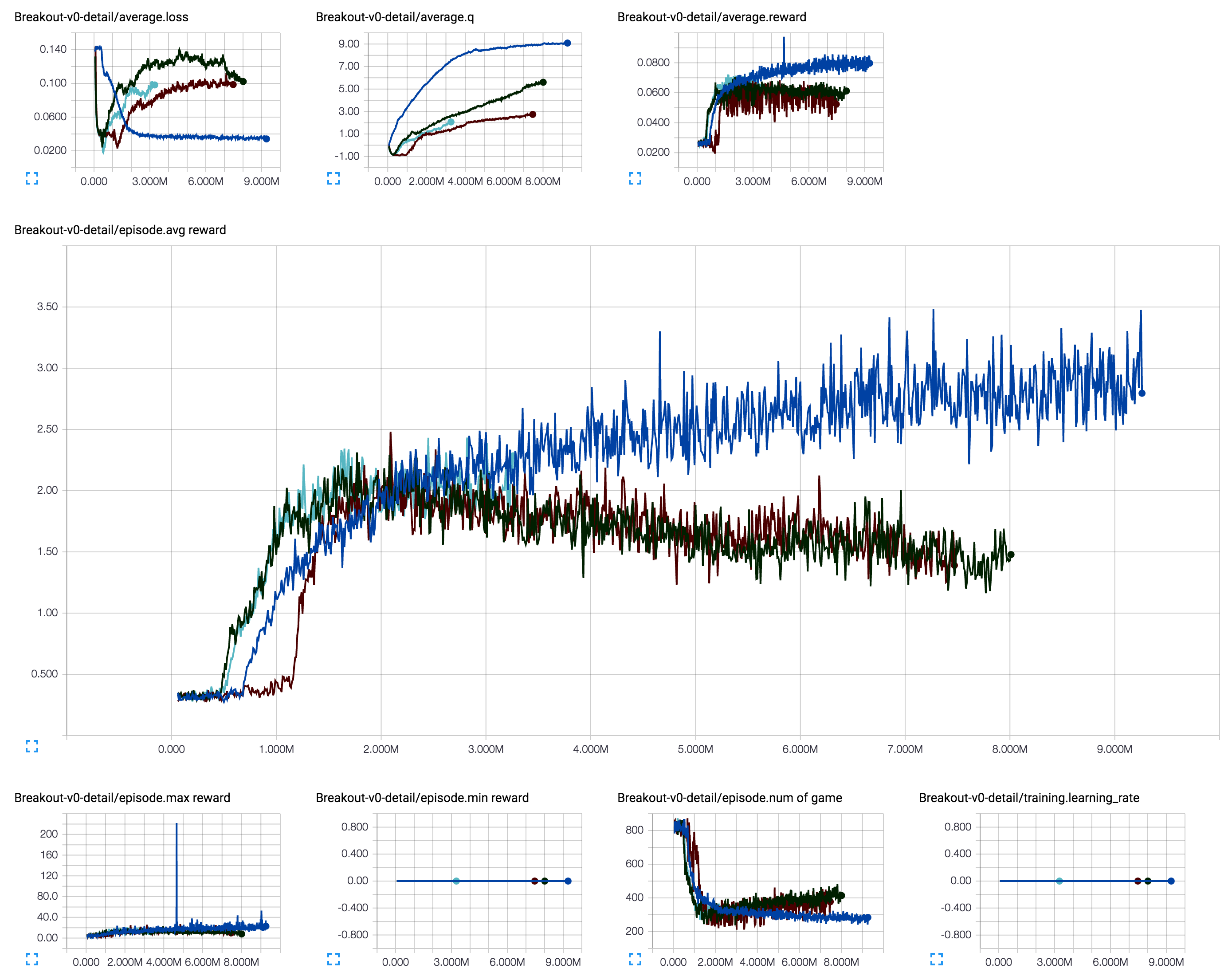
[4] Distributed (分布式) action-repeat (帧跳过) 为 1,无 learning rate decay (学习率衰减)
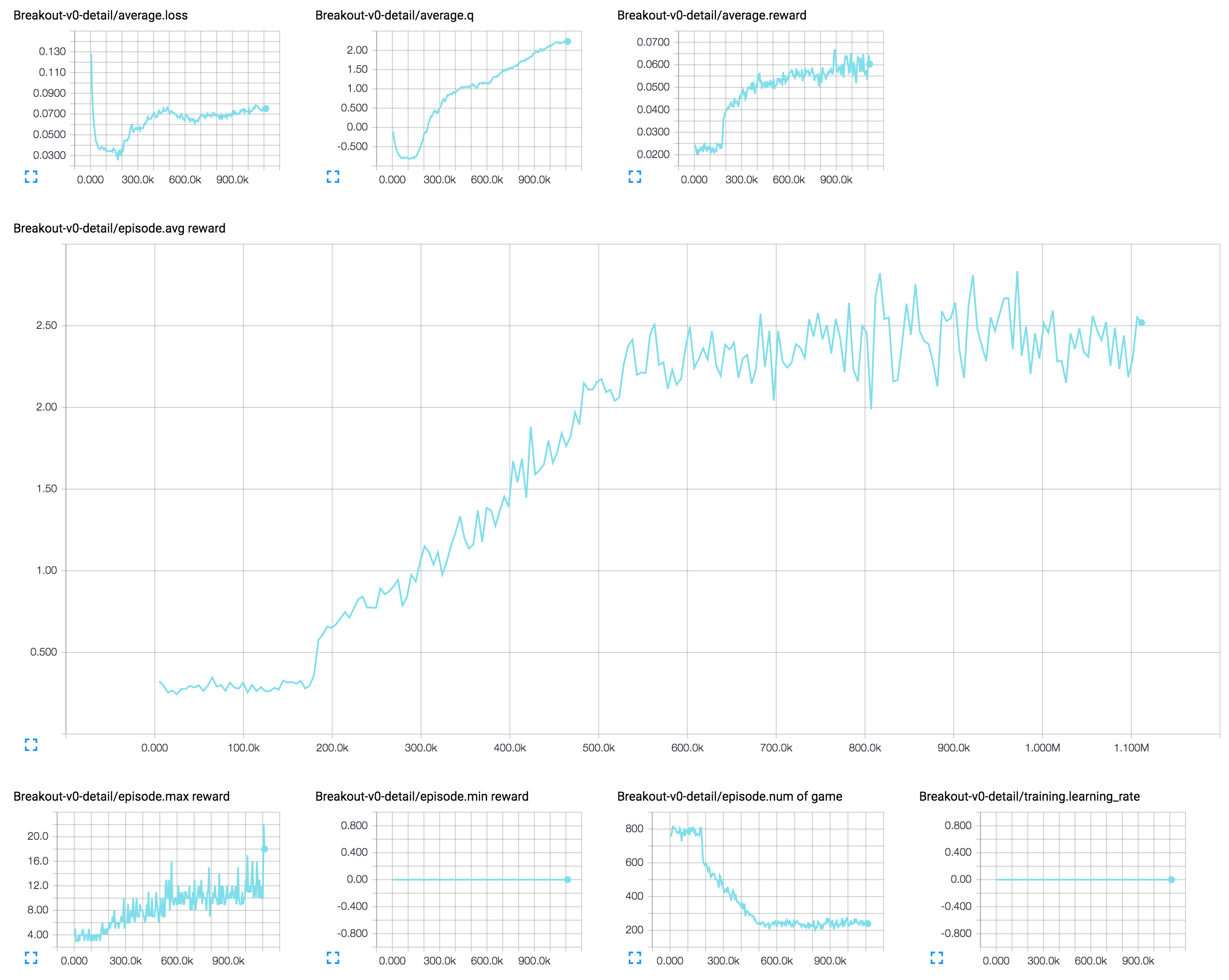
[5] Distributed (分布式) action-repeat (帧跳过) 为 4,无 learning rate decay (学习率衰减)
参考文献
许可证
MIT 许可证。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。