sqlcoder
sqlcoder 是由 Defog 推出的一系列开源大语言模型,专为将自然语言问题自动转化为精准的 SQL 查询语句而设计。它主要解决了非技术人员难以直接编写复杂数据库查询的痛点,让用户只需像日常对话一样提问,即可获取所需数据,大幅降低了数据分析的门槛。
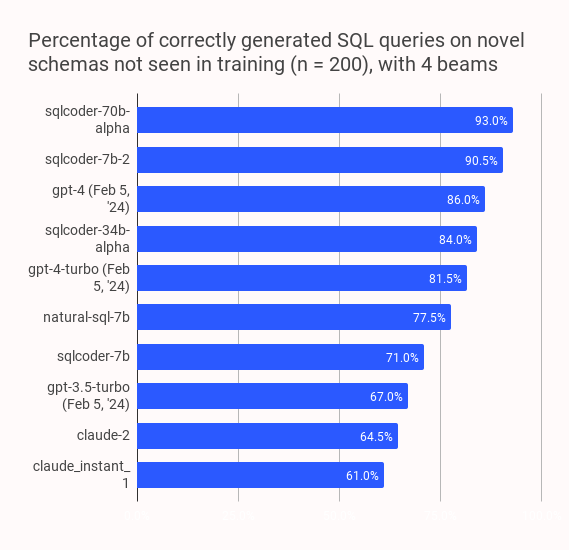
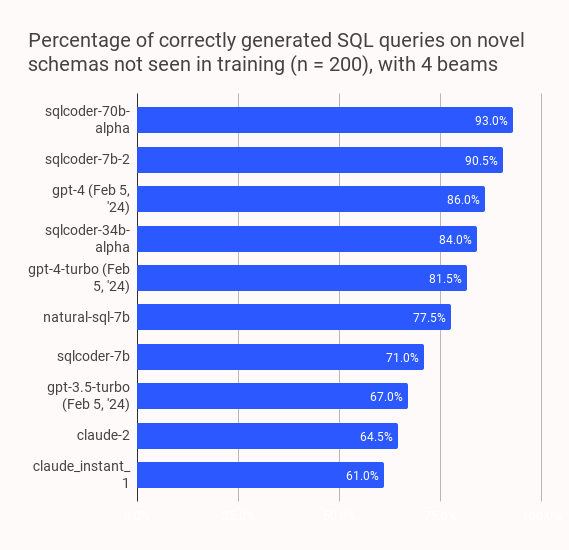
这款工具非常适合开发者、数据分析师以及希望集成智能查询功能的研究人员使用。其核心亮点在于卓越的性能表现:在针对未见过的数据库架构测试中,sqlcoder 的准确率不仅显著超越了各类主流开源模型,甚至在多项指标上优于 GPT-4 和 GPT-4 Turbo。特别是在处理日期计算、多表连接(Join)及复杂比率统计等高难度任务时,表现尤为出色。
技术层面,sqlcoder 基于超过 20,000 个人工精心策划的问题进行训练,涵盖了多种数据库模式,确保了模型在面对全新数据结构时仍具备强大的泛化能力。项目完全开源,模型权重采用宽松的许可协议,支持商业应用及二次微调。用户既可以通过简单的命令行启动本地服务直连数据库,也能利用 Hugging Face 提供的权重结合 transformers 库灵活部署,是实现自然语言到 SQL 转换的高性价比选择。
使用场景
某电商公司的数据分析师需要快速响应运营团队关于“纽约与旧金山客户营收对比”的临时查询需求,但受限于复杂的数据库架构和紧张的排期,传统取数流程显得捉襟见肘。
没有 sqlcoder 时
- 沟通成本高昂:分析师需反复与业务方确认指标口径,再将自然语言需求手动转化为复杂的 SQL 代码,耗时且易产生理解偏差。
- 技术门槛限制:非技术背景的运营人员无法直接获取数据,必须依赖分析师排期,导致简单的数据验证也需要等待数小时甚至数天。
- 错误率高企:在处理多表关联(Join)或复杂日期筛选时,人工编写的 SQL 容易出现语法错误或逻辑漏洞,需多次返工调试。
- 资源浪费严重:资深分析师的大量时间被消耗在编写基础查询语句上,无法专注于深度的数据洞察与策略建议。
使用 sqlcoder 后
- 即时生成查询:运营人员直接用自然语言提问"Compare revenue from New York vs San Francisco customers",sqlcoder 瞬间生成准确的高效 SQL 语句。
- 赋能业务自助:借助 sqlcoder 的高精度转换能力(尤其在 Join 和聚合运算上超越 GPT-4),业务方可通过简单界面自助获取数据,打破取数瓶颈。
- 逻辑精准可靠:sqlcoder 基于两万多条人工 curated 数据训练,能精准处理复杂的分组(Group By)和比率计算,大幅减少因手写代码导致的逻辑错误。
- 释放核心生产力:分析师从繁琐的写代码工作中解脱出来,转而利用节省的时间进行数据趋势分析和商业价值挖掘。
sqlcoder 通过将自然语言无缝转化为高精度 SQL 查询,彻底消除了业务需求与技术实现之间的壁垒,让数据获取变得像对话一样简单高效。
运行环境要求
- Linux
- macOS
- Windows
- NVIDIA GPU (推荐 16GB+ VRAM,如 A10, RTX 4090, RTX 3090)
- Apple Silicon (M2 Pro/Max/Ultra 需 20GB+ 统一内存)
- 支持浮点 16、8-bit 和 4-bit 量化版本
未说明 (模型加载依赖显存/统一内存,消费级显卡需 20GB+ 内存以运行量化版本)
快速开始
Defog SQLCoder
Defog 的 SQLCoder 是一系列最先进的大型語言模型,用於將自然語言問題轉換為 SQL 查詢。
互動演示 | 🤗 HF 倉庫 | ♾️ Colab | 🐦 Twitter
縮短版
SQLCoder 是一系列大型語言模型,在我們的 sql-eval 框架上進行的自然語言到 SQL 生成任務中,其表現優於 gpt-4 和 gpt-4-turbo,並且顯著超越所有流行的開源模型。
安裝 SQLCoder
如果在具備超過 16GB VRAM 的 NVIDIA GPU 的設備上運行(性能最佳)
pip install "sqlcoder[transformers]"
如果在 Apple Silicon 上運行(性能較差,因為量化和缺乏束搜索)
CMAKE_ARGS="-DLLAMA_METAL=on" pip install "sqlcoder[llama-cpp]"
如果在沒有 GPU 存取權限的非 Apple Silicon 計算機上運行,請在 Linux/Intel Mac 上執行以下命令:
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install "sqlcoder[llama-cpp]"
而在 Windows 上則執行:
$env:CMAKE_ARGS = "-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS"
pip install "sqlcoder[llama-cpp]"
目前尚未在其他平台上測試 SQLCoder。歡迎大家貢獻力量,協助在其他平台上的測試!
運行 SQLCoder
在您的終端中,運行:
sqlcoder launch
這樣您就可以直接連接到您的資料庫,添加元數據並以視覺化方式查詢資料。
授權條款
此倉庫中的程式碼(雖然不多)採用 Apache-2 許可證。模型權重則採用 CC BY-SA 4.0 許可證。簡而言之,您可以將該模型用於任何目的,包括商業用途。然而,如果您修改了權重(例如通過微調),則必須根據相同的許可條款公開您修改後的權重。
訓練
Defog 使用超過 20,000 個由人類精心挑選的問題進行訓練。這些問題基於 10 個不同的資料模式。訓練資料中的任何模式均未包含在我們的評估框架中。
按問題類別的結果
我們將每個生成的問題分為 6 個類別。下表顯示了各模型按類別正確回答問題的百分比。
| 日期 | 分組 | 排序 | 比例 | 連接 | 條件 | |
|---|---|---|---|---|---|---|
| sqlcoder-70b | 96 | 91.4 | 97.1 | 85.7 | 97.1 | 91.4 |
| sqlcoder-7b-2 | 96 | 91.4 | 94.3 | 91.4 | 94.3 | 77.1 |
| sqlcoder-34b | 80 | 94.3 | 85.7 | 77.1 | 85.7 | 80 |
| gpt-4 | 72 | 94.3 | 97.1 | 80 | 91.4 | 80 |
| gpt-4-turbo | 76 | 91.4 | 91.4 | 62.8 | 88.6 | 77.1 |
| natural-sql-7b | 56 | 88.6 | 85.7 | 60 | 88.6 | 80 |
| sqlcoder-7b | 64 | 82.9 | 74.3 | 54.3 | 74.3 | 74.3 |
| gpt-3.5 | 72 | 77.1 | 82.8 | 34.3 | 65.7 | 71.4 |
| claude-2 | 52 | 71.4 | 74.3 | 57.1 | 65.7 | 62.9 |
使用 SQLCoder
您可以通過 transformers 庫使用 SQLCoder,從 Hugging Face 倉庫下載我們的模型權重。我們已添加了針對 推論 的示例代碼,並提供了一個 示例資料庫模式。
python inference.py -q "這裡輸入關於示例資料庫的問題"
# 示例問題:
# 我們從紐約客戶獲得的收入是否高於舊金山客戶?請給出每個城市的總收入,以及兩者之間的差額。
您也可以在我們的網站上使用演示 這裡。
硬體需求
SQLCoder-34B 已在配備 float16 權重的 4xA10 GPU 上進行測試。您也可以在具有 20GB 或以上記憶體的消費級 GPU 上載入該模型的 8 位和 4 位量化版本——例如 RTX 4090、RTX 3090,以及具有 20GB 或以上記憶體的 Apple M2 Pro、M2 Max 或 M2 Ultra 晶片。
待辦事項
- 開源 v1 模型權重
- 使用更多且更具多樣性的數據來訓練模型
- 進一步透過獎勵建模和 RLHF 對模型進行調優
- 從頭開始預訓練一個專門用於 SQL 分析的模型
星星歷史

常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。