DeepSeek-V2
DeepSeek-V2 是一款由深度求索推出的强大且高效的混合专家(MoE)语言模型。它旨在解决大型人工智能模型在训练成本高昂、推理速度慢以及显存占用过高等核心痛点,让高性能 AI 变得更加经济实惠。
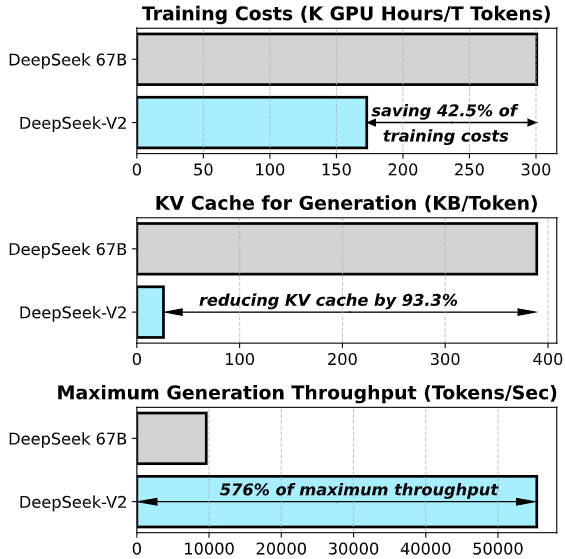
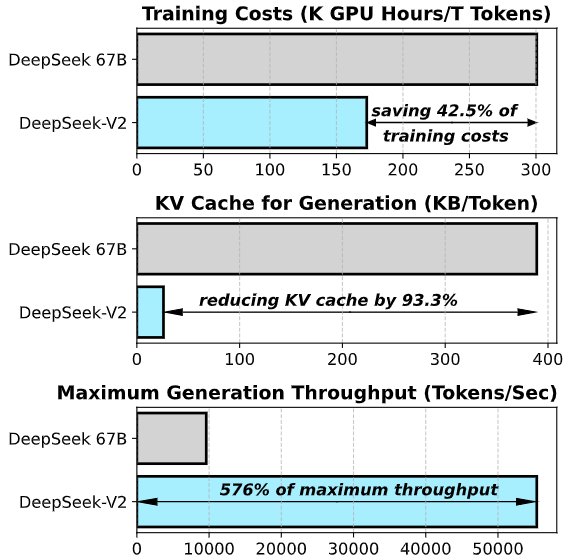
该模型拥有 2360 亿总参数,但在处理每个词元时仅激活 210 亿参数。这种独特的架构设计带来了显著优势:与前代 DeepSeek 67B 相比,DeepSeek-V2 不仅性能更强,还将训练成本降低了 42.5%,推理时的键值缓存(KV Cache)减少了 93.3%,最大生成吞吐量更是提升了 5.76 倍。这意味着它能在保持顶尖智能水平的同时,大幅降低硬件门槛并提升响应速度。
DeepSeek-V2 非常适合各类用户群体。对于开发者和研究人员,它是构建高效应用和探索大模型架构的理想基座,其开源协议友好,便于二次开发与部署;对于企业用户,它能有效降低算力投入;而对于普通用户,通过集成该模型的聊天机器人或应用,也能享受到更快速、更聪明的智能服务。凭借“强性能、低成本、高效率”的特点,DeepSeek-V2 正成为推动大模型落地普及的重要力量。
使用场景
某中型电商公司的后端团队需要在高并发促销期间,实时处理海量用户评论以生成智能摘要并识别潜在风险内容。
没有 DeepSeek-V2 时
- 推理成本高昂:部署参数量巨大的传统大模型导致 GPU 资源消耗剧增,单次调用成本难以承受,限制了服务覆盖范围。
- 响应延迟严重:在高流量峰值下,模型推理速度慢,用户等待摘要生成的时间过长,严重影响购物体验。
- 显存占用过大:庞大的 KV Cache 占用了大量显存,导致单卡能支持的并发请求数极低,不得不频繁扩容硬件。
- 训练迭代缓慢:团队试图针对电商垂直领域微调模型,但全参数训练耗时极长且算力开销巨大,难以快速响应业务变化。
使用 DeepSeek-V2 后
- 显著降低运营成本:利用其混合专家(MoE)架构,每次仅激活 210 亿参数,在保持高性能的同时将训练成本降低了 42.5%,大幅节省预算。
- 吞吐量提升近 6 倍:高效的推理机制使最大生成吞吐量提升至原来的 5.76 倍,用户几乎无感知地获取实时评论摘要。
- 显存效率极大优化:KV Cache 体积减少了 93.3%,单张显卡可承载的并发请求数成倍增加,无需额外购买昂贵硬件即可应对流量洪峰。
- 快速落地垂直场景:经济的训练特性让团队能在短时间内完成针对电商术语的微调,迅速上线更精准的风险识别功能。
DeepSeek-V2 凭借“强性能、低消耗、高效率”的特性,帮助企业在不牺牲智能体验的前提下,实现了大模型规模化落地的成本与速度双重突破。
运行环境要求
需要 NVIDIA GPU(文中提及在 GPU 上运行 HuggingFace 代码性能较慢,建议使用专用的 vllm 解决方案以获得高效执行),具体显存大小和 CUDA 版本未说明
未说明
快速开始

模型下载 | 评估结果 | 模型架构 | API平台 | 许可证 | 引用
DeepSeek-V2:一款强大、经济高效且高效的专家混合语言模型
1. 引言
今天,我们隆重推出DeepSeek-V2,这是一款强大的专家混合(MoE)语言模型,以其经济高效的训练和高效的推理能力而著称。该模型总参数量为2360亿,其中每次处理一个token时仅激活210亿个参数。与DeepSeek 67B相比,DeepSeek-V2不仅性能更优,还节省了42.5%的训练成本,将KV缓存减少了93.3%,并将最大生成吞吐量提升了5.76倍。
我们在包含8.1万亿个token的多样化高质量语料库上预训练了DeepSeek-V2。全面的预训练之后,我们又进行了监督微调(SFT)和强化学习(RL),以充分释放模型的能力。评估结果证明了我们方法的有效性:DeepSeek-V2在标准基准测试以及开放式生成评估中均表现出色。
2. 新闻
- 2024年5月16日:我们发布了DeepSeek-V2-Lite。
- 2024年5月6日:我们发布了DeepSeek-V2。
3. 模型下载
| 模型 | 总参数量 | 激活参数量 | 上下文长度 | 下载 |
|---|---|---|---|---|
| DeepSeek-V2-Lite | 160亿 | 24亿 | 32k | 🤗 HuggingFace |
| DeepSeek-V2-Lite-Chat (SFT) | 160亿 | 24亿 | 32k | 🤗 HuggingFace |
| DeepSeek-V2 | 2360亿 | 210亿 | 128k | 🤗 HuggingFace |
| DeepSeek-V2-Chat (RL) | 2360亿 | 210亿 | 128k | 🤗 HuggingFace |
由于HuggingFace平台的限制,在使用HuggingFace运行于GPU上的代码时,开源代码的性能目前仍不及我们的内部代码库。为了便于高效运行我们的模型,我们提供了一个专门的vllm解决方案,可优化性能,从而更有效地运行我们的模型。
4. 評估結果
基础模型
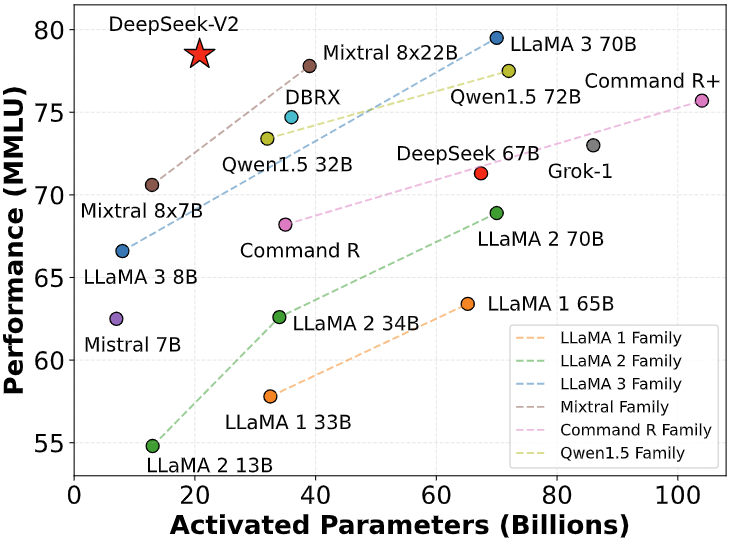
标准基准测试(模型参数量大于67B)
| 基准测试 | 领域 | LLaMA3 70B | Mixtral 8x22B | DeepSeek-V1(密集型-67B) | DeepSeek-V2(MoE-236B) |
|---|---|---|---|---|---|
| MMLU | 英语 | 78.9 | 77.6 | 71.3 | 78.5 |
| BBH | 英语 | 81.0 | 78.9 | 68.7 | 78.9 |
| C-Eval | 中文 | 67.5 | 58.6 | 66.1 | 81.7 |
| CMMLU | 中文 | 69.3 | 60.0 | 70.8 | 84.0 |
| HumanEval | 代码 | 48.2 | 53.1 | 45.1 | 48.8 |
| MBPP | 代码 | 68.6 | 64.2 | 57.4 | 66.6 |
| GSM8K | 数学 | 83.0 | 80.3 | 63.4 | 79.2 |
| Math | 数学 | 42.2 | 42.5 | 18.7 | 43.6 |
标准基准测试(模型参数量小于16B)
| 基准测试 | 领域 | DeepSeek 7B(密集型) | DeepSeekMoE 16B | DeepSeek-V2-Lite(MoE-16B) |
|---|---|---|---|---|
| 架构 | - | MHA+密集 | MHA+MoE | MLA+MoE |
| MMLU | 英语 | 48.2 | 45.0 | 58.3 |
| BBH | 英语 | 39.5 | 38.9 | 44.1 |
| C-Eval | 中文 | 45.0 | 40.6 | 60.3 |
| CMMLU | 中文 | 47.2 | 42.5 | 64.3 |
| HumanEval | 代码 | 26.2 | 26.8 | 29.9 |
| MBPP | 代码 | 39.0 | 39.2 | 43.2 |
| GSM8K | 数学 | 17.4 | 18.8 | 41.1 |
| Math | 数学 | 3.3 | 4.3 | 17.1 |
上下文窗口
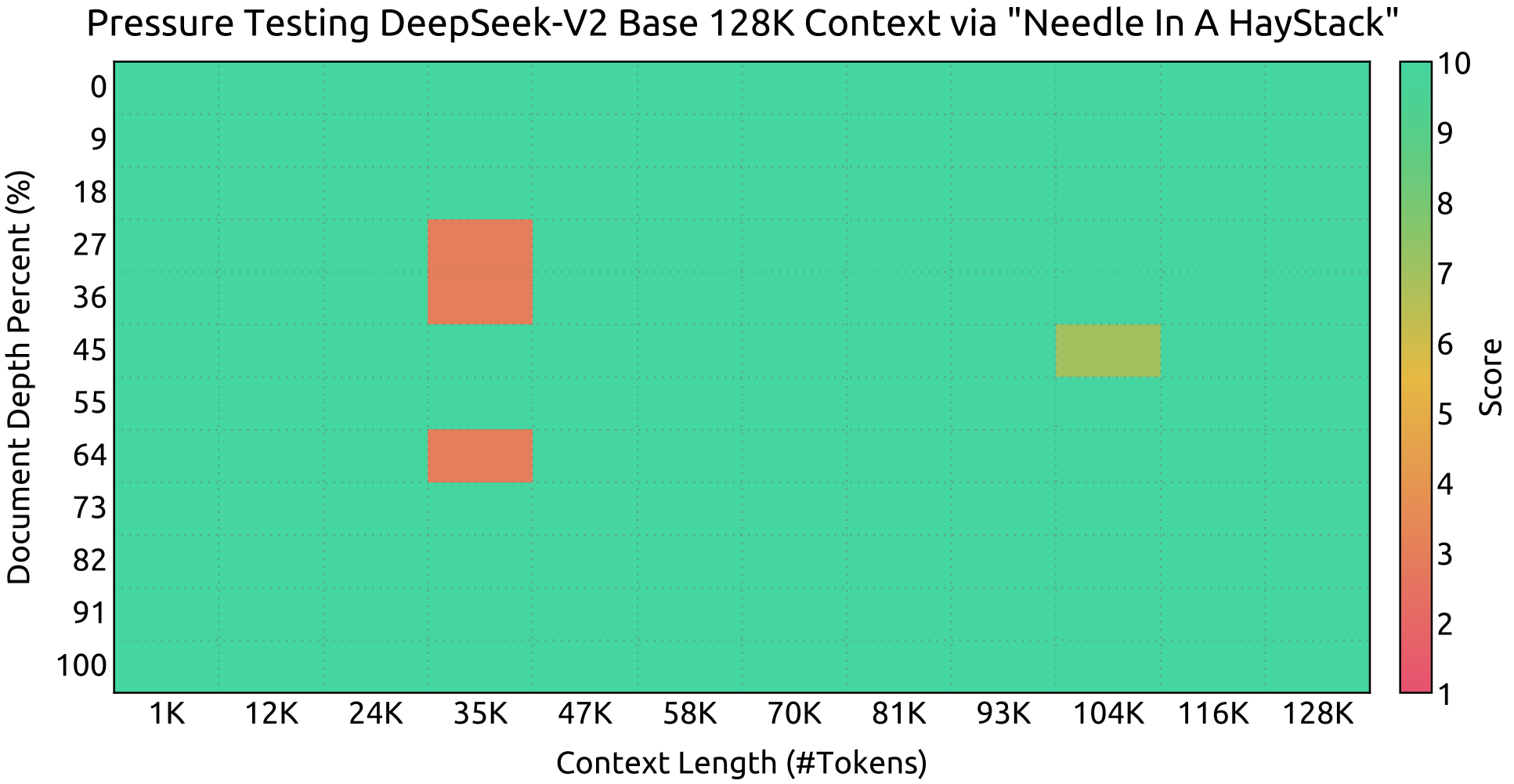
在“针中找针”(NIAH)测试中的评估结果。DeepSeek-V2 在所有上下文窗口长度上均表现出色,最长可达 128K。
对话模型
标准基准测试(模型参数量大于67B)
| 基准测试 | 领域 | QWen1.5 72B Chat | Mixtral 8x22B | LLaMA3 70B Instruct | DeepSeek-V1 Chat(SFT) | DeepSeek-V2 Chat(SFT) | DeepSeek-V2 Chat(RL) |
|---|---|---|---|---|---|---|---|
| MMLU | 英语 | 76.2 | 77.8 | 80.3 | 71.1 | 78.4 | 77.8 |
| BBH | 英语 | 65.9 | 78.4 | 80.1 | 71.7 | 81.3 | 79.7 |
| C-Eval | 中文 | 82.2 | 60.0 | 67.9 | 65.2 | 80.9 | 78.0 |
| CMMLU | 中文 | 82.9 | 61.0 | 70.7 | 67.8 | 82.4 | 81.6 |
| HumanEval | 代码 | 68.9 | 75.0 | 76.2 | 73.8 | 76.8 | 81.1 |
| MBPP | 代码 | 52.2 | 64.4 | 69.8 | 61.4 | 70.4 | 72.0 |
| LiveCodeBench (0901-0401) | 代码 | 18.8 | 25.0 | 30.5 | 18.3 | 28.7 | 32.5 |
| GSM8K | 数学 | 81.9 | 87.9 | 93.2 | 84.1 | 90.8 | 92.2 |
| Math | 数学 | 40.6 | 49.8 | 48.5 | 32.6 | 52.7 | 53.9 |
标准基准测试(模型参数量小于16B)
| 基准测试 | 领域 | DeepSeek 7B Chat(SFT) | DeepSeekMoE 16B Chat(SFT) | DeepSeek-V2-Lite 16B Chat(SFT) |
|---|---|---|---|---|
| MMLU | 英语 | 49.7 | 47.2 | 55.7 |
| BBH | 英语 | 43.1 | 42.2 | 48.1 |
| C-Eval | 中文 | 44.7 | 40.0 | 60.1 |
| CMMLU | 中文 | 51.2 | 49.3 | 62.5 |
| HumanEval | 代码 | 45.1 | 45.7 | 57.3 |
| MBPP | 代码 | 39.0 | 46.2 | 45.8 |
| GSM8K | 数学 | 62.6 | 62.2 | 72.0 |
| Math | 数学 | 14.7 | 15.2 | 27.9 |
英语开放式生成评估
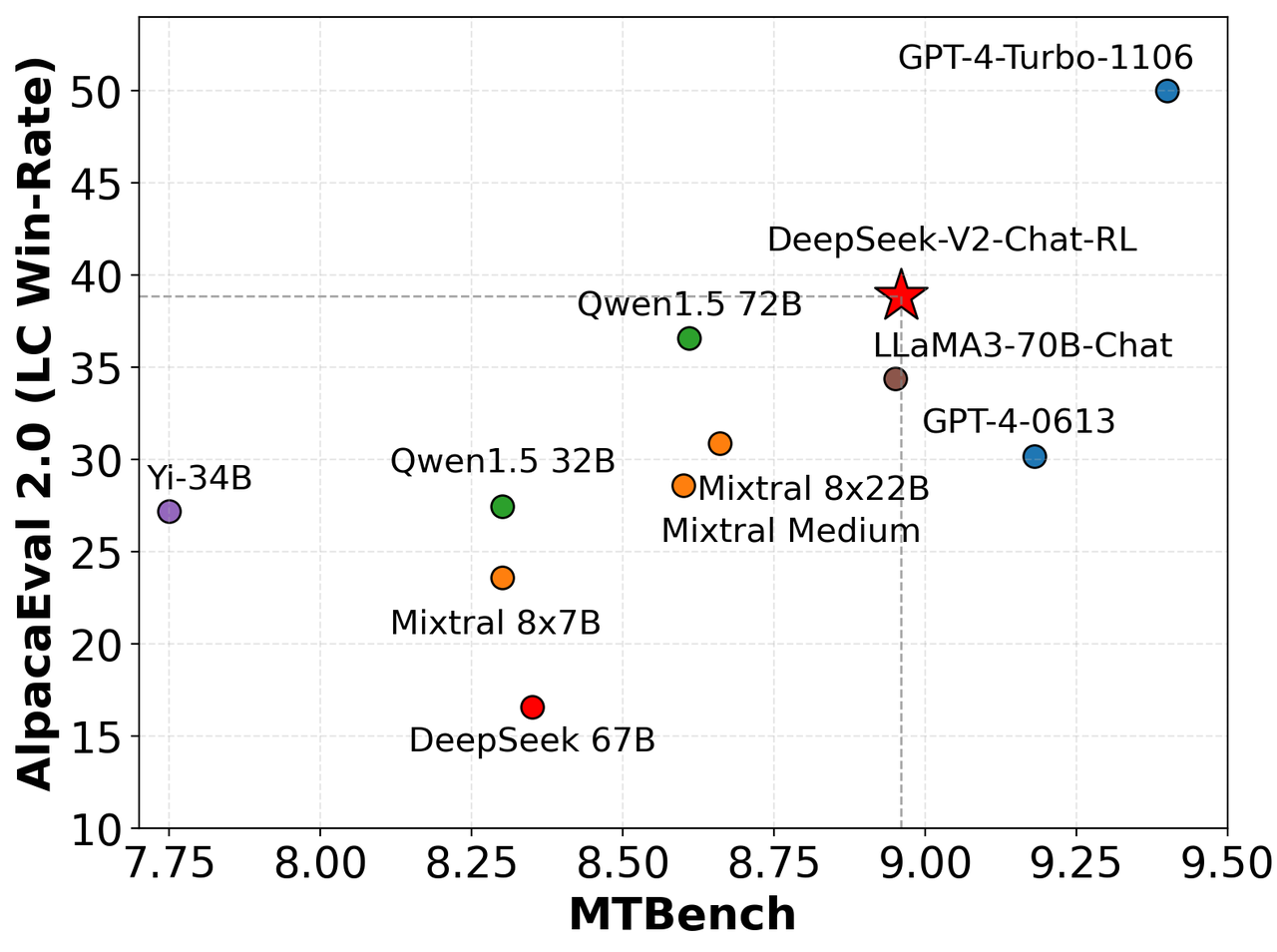
我们在 AlpacaEval 2.0 和 MTBench 上对我们的模型进行了评估,结果显示 DeepSeek-V2-Chat-RL 在英语对话生成方面具有竞争力。
中文开放式生成评估
Alignbench(https://arxiv.org/abs/2311.18743)
| 模型 | 开源/闭源 | 总分 | 中文推理 | 中文语言 |
|---|---|---|---|---|
| gpt-4-1106-preview | 闭源 | 8.01 | 7.73 | 8.29 |
| DeepSeek-V2 Chat(RL) | 开源 | 7.91 | 7.45 | 8.36 |
| erniebot-4.0-202404(文心一言) | 闭源 | 7.89 | 7.61 | 8.17 |
| DeepSeek-V2 Chat(SFT) | 开源 | 7.74 | 7.30 | 8.17 |
| gpt-4-0613 | 闭源 | 7.53 | 7.47 | 7.59 |
| erniebot-4.0-202312(文心一言) | 闭源 | 7.36 | 6.84 | 7.88 |
| moonshot-v1-32k-202404(月之暗面) | 闭源 | 7.22 | 6.42 | 8.02 |
| Qwen1.5-72B-Chat(通义千问) | 开源 | 7.19 | 6.45 | 7.93 |
| DeepSeek-67B-Chat | 开源 | 6.43 | 5.75 | 7.11 |
| Yi-34B-Chat(零一万物) | 开源 | 6.12 | 4.86 | 7.38 |
| gpt-3.5-turbo-0613 | 闭源 | 6.08 | 5.35 | 6.71 |
| DeepSeek-V2-Lite 16B Chat | 开源 | 6.01 | 4.71 | 7.32 |
编码基准测试
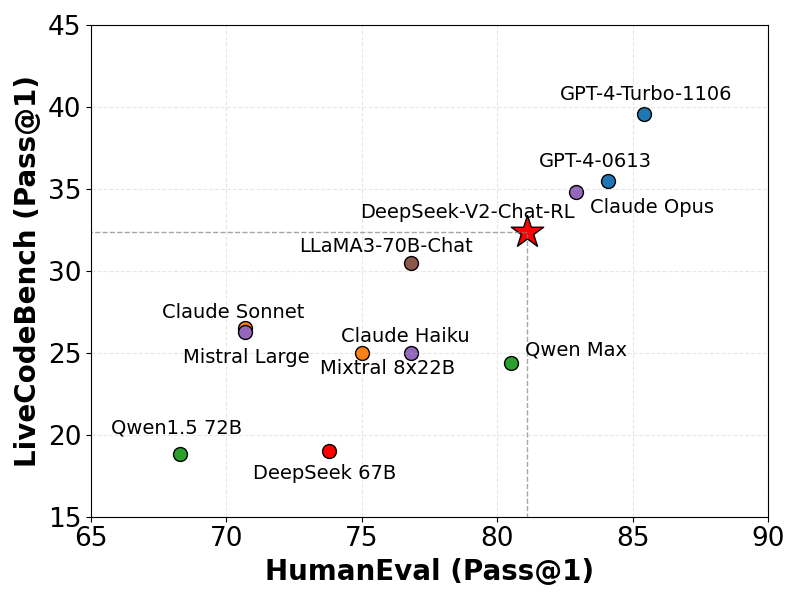
我们在 LiveCodeBench(0901-0401)上对我们的模型进行了评估,该基准测试专为实时编码挑战而设计。正如所示,DeepSeek-V2 在 LiveCodeBench 中表现出相当高的水平,其 Pass@1 分数超越了其他一些复杂模型。这一表现凸显了该模型在处理实时编码任务方面的有效性。
5. 模型架构
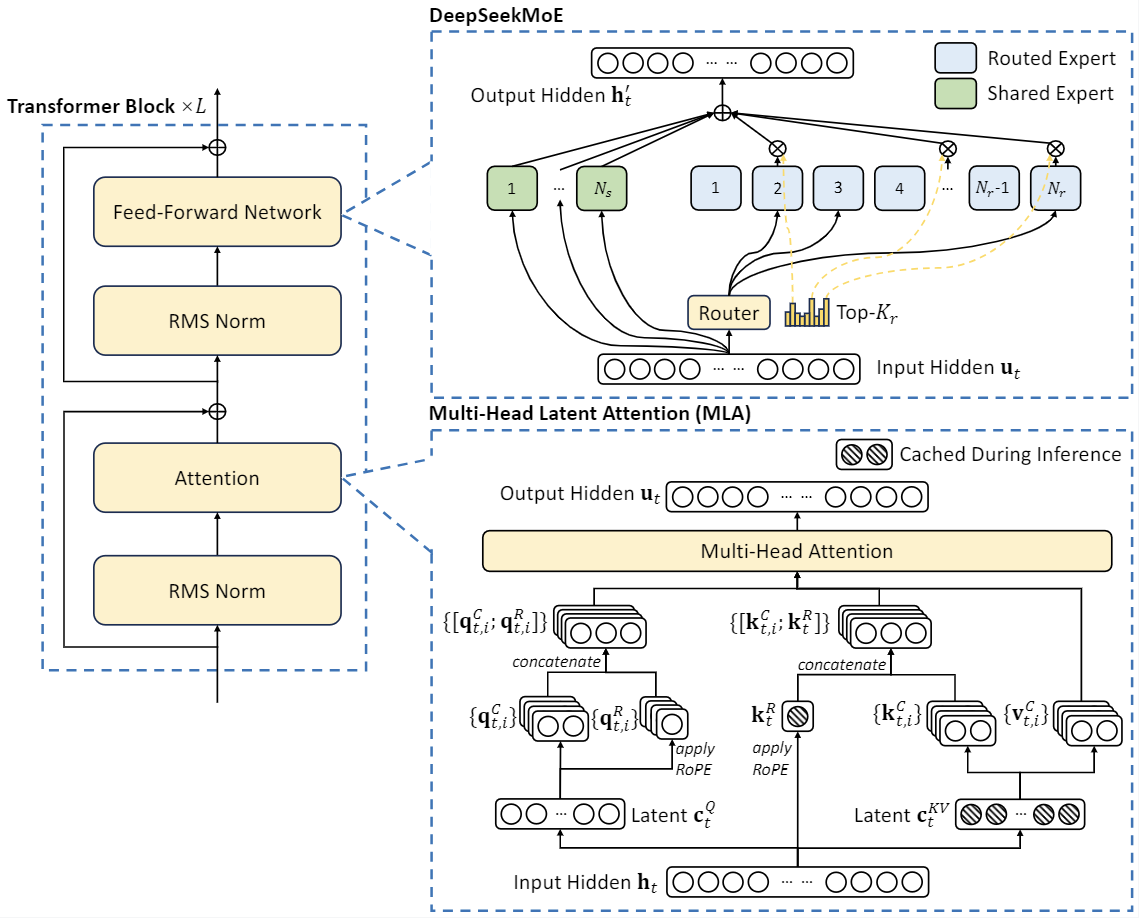
DeepSeek-V2 采用了创新的架构,以确保经济高效的训练和高效的推理:
- 在注意力机制方面,我们设计了 MLA(多头潜在注意力),它利用低秩键值联合压缩来消除推理时键值缓存的瓶颈,从而支持高效的推理。
- 对于前馈网络(FFN),我们采用了 DeepSeekMoE 架构,这是一种高性能的 MoE 架构,能够在更低的成本下训练出更强大的模型。
6. 聊天网站
您可以在 DeepSeek 的官方网站上与 DeepSeek-V2 进行对话:chat.deepseek.com
7. API 平台
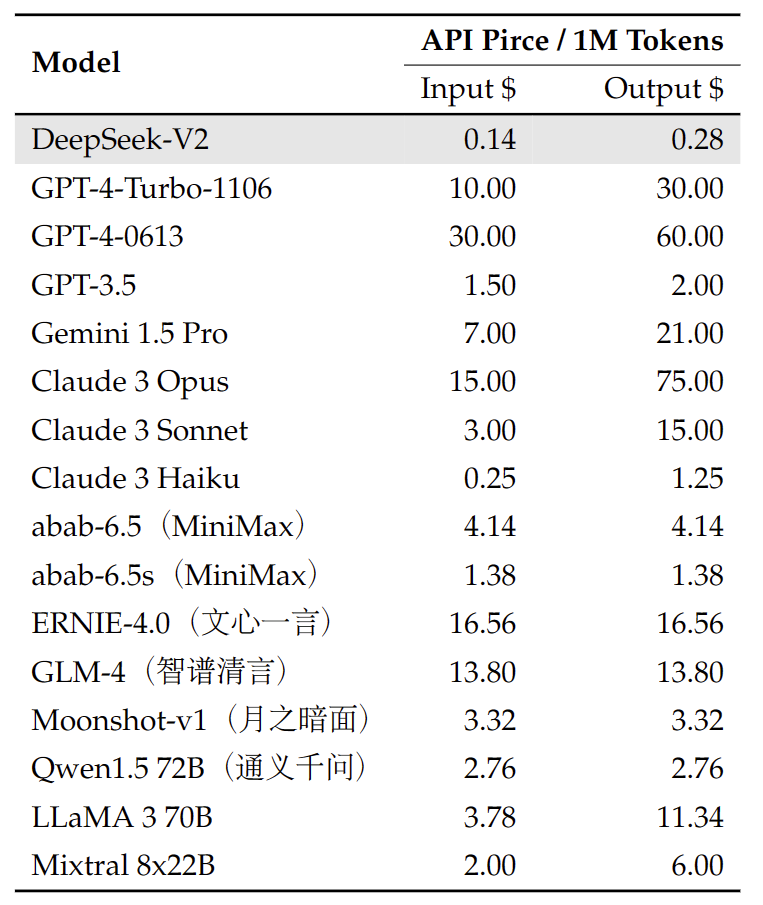
我们还在 DeepSeek 平台上提供了与 OpenAI 兼容的 API:platform.deepseek.com。注册即可获得数百万个免费 Token,并且还可以按需付费,价格极具竞争力。
8. 如何在本地运行
要在 BF16 格式下使用 DeepSeek-V2 进行推理,需要 80GB 显存的 8 张 GPU。
使用 Hugging Face 的 Transformers 进行推理
您可以直接使用 Hugging Face 的 Transformers 进行模型推理。
文本补全
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# `max_memory` 应根据您的设备设置
max_memory = {i: "75GB" for i in range(8)}
# `device_map` 不能设置为 `auto`
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
聊天补全
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# `max_memory` 应根据您的设备设置
max_memory = {i: "75GB" for i in range(8)}
# `device_map` 不能设置为 `auto`
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Write a piece of quicksort code in C++"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
完整的聊天模板可以在 Hugging Face 模型仓库中的 tokenizer_config.json 文件中找到。
聊天模板示例如下:
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
您也可以添加一个可选的系统消息:
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
使用 SGLang 进行推理(推荐)
SGLang 目前支持 MLA 优化、FP8(W8A8)、FP8 键值缓存以及 Torch Compile,在开源框架中提供了最佳的延迟和吞吐量。以下是一些启动兼容 OpenAI API 服务器的示例命令:
# BF16,张量并行度 = 8
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V2-Chat --tp 8 --trust-remote-code
# BF16,带 Torch Compile(编译可能需要几分钟)
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V2-Lite-Chat --trust-remote-code --enable-torch-compile
# FP8,张量并行度 = 8,FP8 键值缓存
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V2-Chat --tp 8 --trust-remote-code --quant fp8 --kv-cache-dtype fp8_e5m2
启动服务器后,您可以使用 OpenAI API 进行查询:
import openai
client = openai.Client(
base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# 聊天补全
response = client.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."},
],
temperature=0,
max_tokens=64,
)
print(response)
使用 vLLM 进行推理(推荐)
要使用 vLLM 进行模型推理,请将此 Pull Request 合并到您的 vLLM 代码库中:https://github.com/vllm-project/vllm/pull/4650。
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 8
model_name = "deepseek-ai/DeepSeek-V2-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "Translate the following content into Chinese directly: DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
LangChain 支持
由于我们的 API 与 OpenAI 兼容,因此您可以轻松地在 langchain 中使用它。 以下是一个示例:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model='deepseek-chat',
openai_api_key=<您的 DeepSeek API 密钥>,
openai_api_base='https://api.deepseek.com/v1',
temperature=0.85,
max_tokens=8000)
9. 许可证
本代码仓库采用 MIT 许可证 许可。DeepSeek-V2 Base/Chat 模型的使用受 模型许可证 约束。DeepSeek-V2 系列(包括 Base 和 Chat)支持商业用途。
10. 引用
@misc{deepseekv2,
title={DeepSeek-V2: 一款强大、经济高效且高效的专家混合语言模型},
author={DeepSeek-AI},
year={2024},
eprint={2405.04434},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
11. 联系方式
如果您有任何问题,请提交一个问题或通过 service@deepseek.com 联系我们。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
gpt4all
GPT4All 是一款让普通电脑也能轻松运行大型语言模型(LLM)的开源工具。它的核心目标是打破算力壁垒,让用户无需依赖昂贵的显卡(GPU)或云端 API,即可在普通的笔记本电脑和台式机上私密、离线地部署和使用大模型。 对于担心数据隐私、希望完全掌控本地数据的企业用户、研究人员以及技术爱好者来说,GPT4All 提供了理想的解决方案。它解决了传统大模型必须联网调用或需要高端硬件才能运行的痛点,让日常设备也能成为强大的 AI 助手。无论是希望构建本地知识库的开发者,还是单纯想体验私有化 AI 聊天的普通用户,都能从中受益。 技术上,GPT4All 基于高效的 `llama.cpp` 后端,支持多种主流模型架构(包括最新的 DeepSeek R1 蒸馏模型),并采用 GGUF 格式优化推理速度。它不仅提供界面友好的桌面客户端,支持 Windows、macOS 和 Linux 等多平台一键安装,还为开发者提供了便捷的 Python 库,可轻松集成到 LangChain 等生态中。通过简单的下载和配置,用户即可立即开始探索本地大模型的无限可能。