DeepSeek-Coder-V2
DeepSeek-Coder-V2 是一款开源的混合专家(MoE)代码大模型,旨在打破闭源模型在代码智能领域的性能垄断。它在 DeepSeek-V2 的基础上,额外使用了 6 万亿个令牌进行持续预训练,不仅大幅提升了代码生成与数学推理能力,还保持了出色的通用语言处理水平。
这款模型主要解决了开发者在面对复杂编程任务时,开源工具往往难以媲美顶尖闭源模型(如 GPT-4 Turbo)的痛点。它将支持的编程语言从 86 种扩展至 338 种,并将上下文窗口从 16K 显著提升至 128K,使其能够轻松处理超长代码库和复杂的项目逻辑。
DeepSeek-Coder-V2 非常适合软件工程师、算法研究人员以及需要高质量代码辅助的企业团队使用。无论是日常代码补全、跨语言项目迁移,还是高难度的算法推导,它都能提供强有力的支持。其独特的技术亮点在于采用高效的 MoE 架构,在实现比肩闭源模型性能的同时,依然保持开源免费的优势,并支持 MIT 代码许可证,让使用者可以更自由地进行本地部署和二次开发。
使用场景
某金融科技公司后端团队正紧急重构一个遗留的单体支付系统,需将其拆分为微服务并迁移至云原生架构,同时必须兼容十余种老旧编程语言编写的核心算法模块。
没有 DeepSeek-Coder-V2 时
- 多语言支持受限:团队被迫组合使用多个专用工具来处理 Python、Go 及冷门的 COBOL 代码,上下文切换频繁且容易出错。
- 长上下文理解困难:面对数十万行的遗留代码库,现有模型因 16K 上下文限制无法一次性读取完整逻辑,导致重构时经常遗漏关键依赖或产生幻觉。
- 复杂逻辑推理不足:在处理涉及高精度数学计算的利息算法时,通用模型常给出逻辑错误的代码片段,需要资深工程师花费大量时间人工审查和修正。
- 闭源模型成本高:若追求同等智能水平需调用昂贵的闭源 API,且敏感金融代码上传至第三方服务器存在合规与数据泄露风险。
使用 DeepSeek-Coder-V2 后
- 全栈语言统一处理:凭借对 338 种编程语言的广泛支持,DeepSeek-Coder-V2 能流畅理解并转换从现代 Go 到古老 Fortran 的所有模块,实现单一工作流覆盖。
- 全景代码分析:利用 128K 超长上下文窗口,DeepSeek-Coder-V2 可一次性摄入整个服务模块的代码,精准梳理调用链路,确保重构后的逻辑完整性。
- 专家级推理能力:基于 MoE 架构增强的数学与代码推理能力,DeepSeek-Coder-V2 能直接生成经过验证的高精度算法代码,大幅减少人工调试时间。
- 安全自主可控:团队可本地部署该开源模型,在完全不外传代码的前提下享受媲美 GPT-4 Turbo 的智能辅助,完美满足金融级安全合规要求。
DeepSeek-Coder-V2 通过突破闭源模型的性能壁垒,让企业在保障数据安全的同时,以开源成本实现了全语言、长上下文的顶级代码智能重构。
运行环境要求
未说明(模型基于 DeepSeekMoE 架构,参数量巨大:Lite 版总参数 16B/激活 2.4B,完整版总参数 236B/激活 21B,通常推理需要高性能多卡 GPU 集群或量化处理)
未说明
快速开始

模型下载 | 评估结果 | API平台 | 使用方法 | 许可证 | 引用
DeepSeek-Coder-V2:突破代码智能领域闭源模型的壁垒
1. 引言
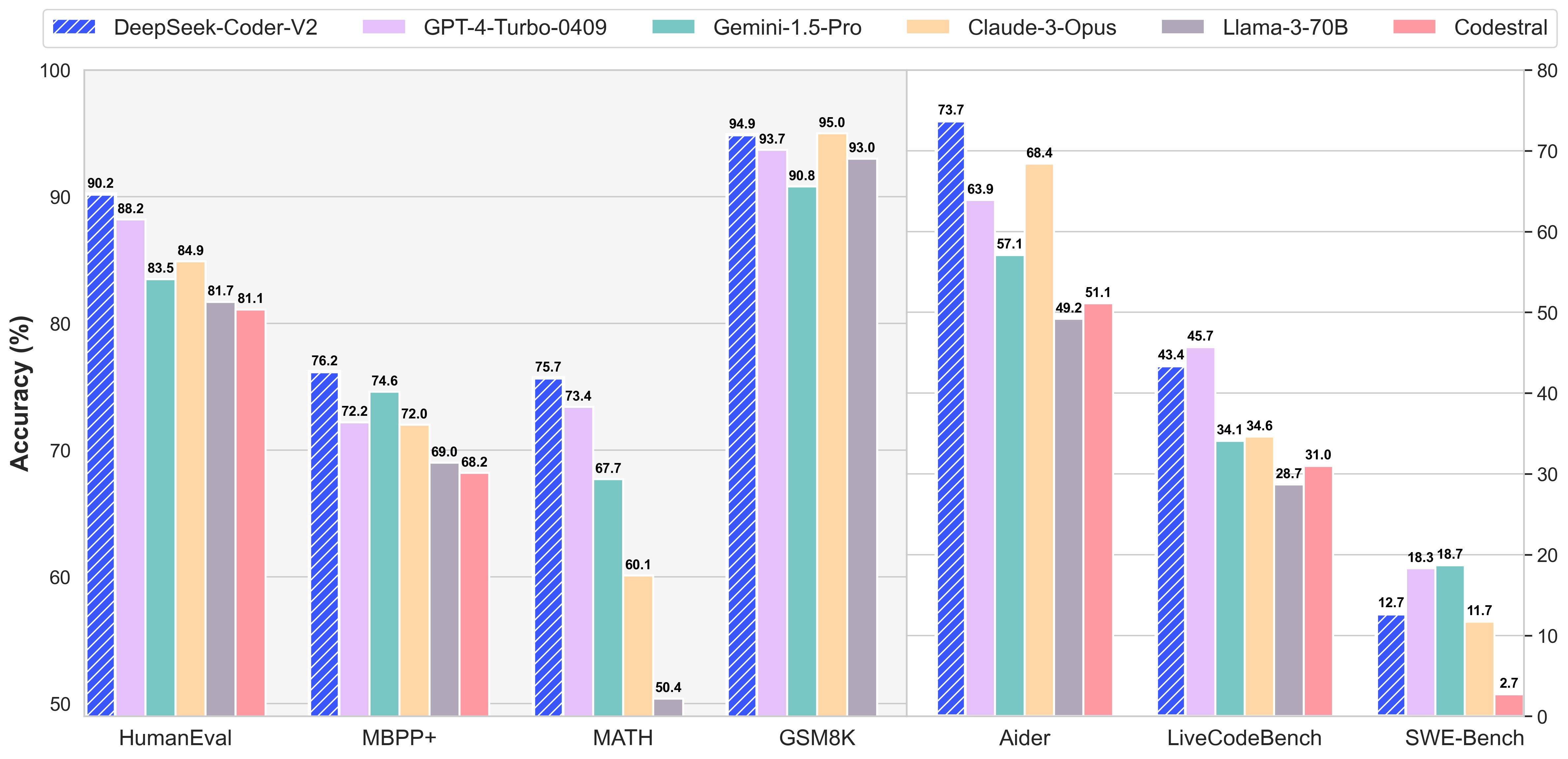
我们推出了DeepSeek-Coder-V2,这是一个开源的专家混合(MoE)代码语言模型,在代码相关任务中达到了与GPT4-Turbo相当的性能。具体来说,DeepSeek-Coder-V2是在DeepSeek-V2的中间检查点基础上,通过额外的6万亿个token继续预训练而成。通过这一持续的预训练,DeepSeek-Coder-V2显著提升了DeepSeek-V2的编码和数学推理能力,同时在通用语言任务上保持了相近的性能。与DeepSeek-Coder-33B相比,DeepSeek-Coder-V2在各类代码相关任务以及推理和通用能力方面都有了显著提升。此外,DeepSeek-Coder-V2将支持的编程语言从86种扩展到了338种,并将上下文长度从16K扩展至128K。
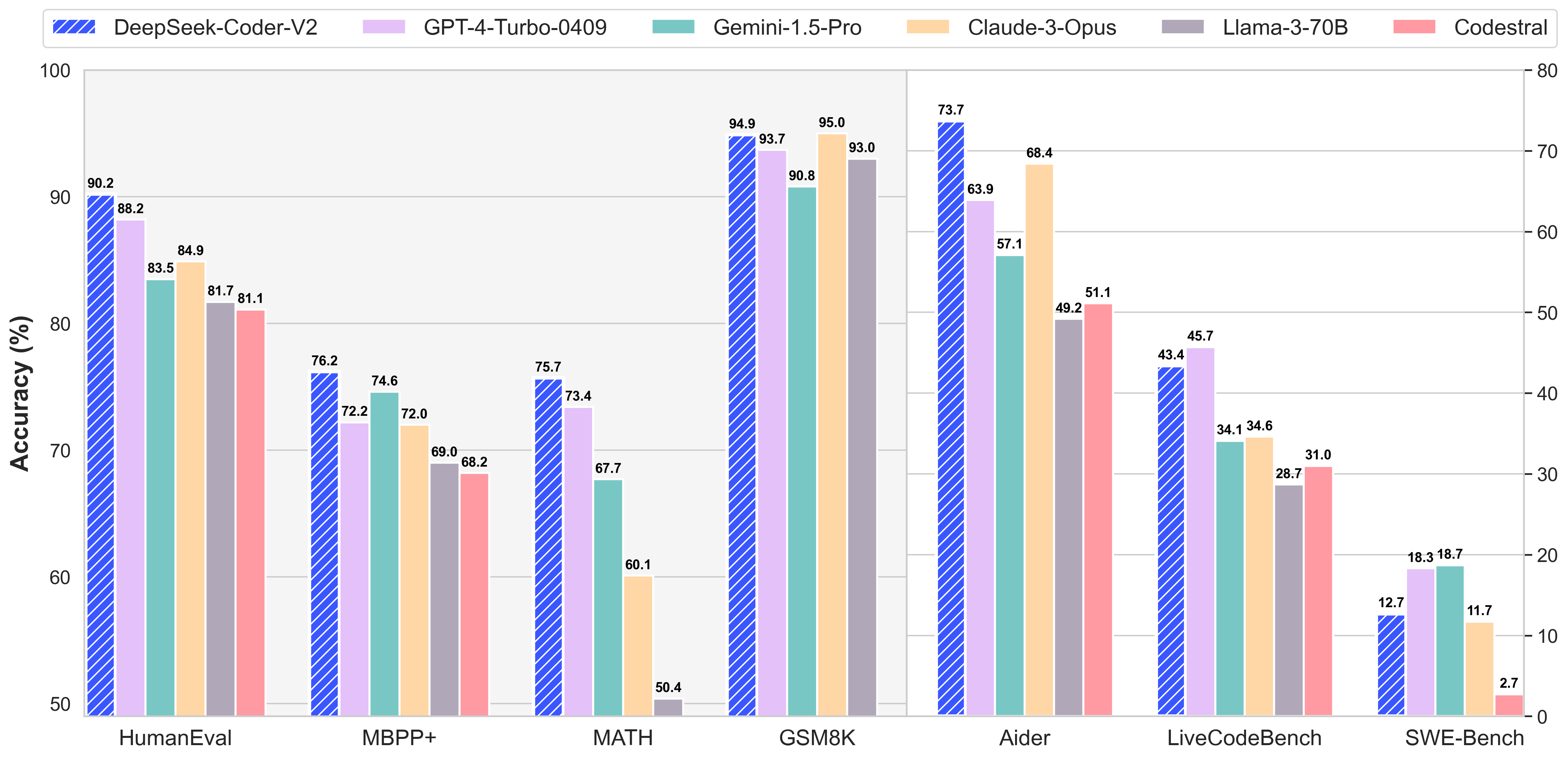
在标准基准测试中,DeepSeek-Coder-V2在编码和数学基准测试中均表现出优于GPT4-Turbo、Claude 3 Opus和Gemini 1.5 Pro等闭源模型的性能。支持的编程语言列表可以在此处找到这里。
2. 模型下载
我们基于DeepSeekMoE框架发布了具有16B和236B参数的DeepSeek-Coder-V2,其有效参数仅为2.4B和21B,包括基础模型和指令微调模型,现已向公众开放。
| 模型 | 总参数量 | 有效参数量 | 上下文长度 | 下载 |
|---|---|---|---|---|
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Base | 236B | 21B | 128k | 🤗 HuggingFace |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 128k | 🤗 HuggingFace |
3. 评估结果
3.1 代码生成
| #TP | #AP | HumanEval | MBPP+ | LiveCodeBench | USACO | |
|---|---|---|---|---|---|---|
| 闭源模型 | ||||||
| Gemini-1.5-Pro | - | - | 83.5 | 74.6 | 34.1 | 4.9 |
| Claude-3-Opus | - | - | 84.2 | 72.0 | 34.6 | 7.8 |
| GPT-4-Turbo-1106 | - | - | 87.8 | 69.3 | 37.1 | 11.1 |
| GPT-4-Turbo-0409 | - | - | 88.2 | 72.2 | 45.7 | 12.3 |
| GPT-4o-0513 | - | - | 91.0 | 73.5 | 43.4 | 18.8 |
| 开源模型 | ||||||
| CodeStral | 22B | 22B | 78.1 | 68.2 | 31.0 | 4.6 |
| DeepSeek-Coder-Instruct | 33B | 33B | 79.3 | 70.1 | 22.5 | 4.2 |
| Llama3-Instruct | 70B | 70B | 81.1 | 68.8 | 28.7 | 3.3 |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 81.1 | 68.8 | 24.3 | 6.5 |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 90.2 | 76.2 | 43.4 | 12.1 |
3.2 代码补全
| 模型 | #TP | #AP | RepoBench (Python) | RepoBench (Java) | HumanEval FIM |
|---|---|---|---|---|---|
| CodeStral | 22B | 22B | 46.1 | 45.7 | 83.0 |
| DeepSeek-Coder-Base | 7B | 7B | 36.2 | 43.3 | 86.1 |
| DeepSeek-Coder-Base | 33B | 33B | 39.1 | 44.8 | 86.4 |
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 38.9 | 43.3 | 86.4 |
3.3 代码修复
| #TP | #AP | Defects4J | SWE-Bench | Aider | |
|---|---|---|---|---|---|
| 闭源模型 | |||||
| Gemini-1.5-Pro | - | - | 18.6 | 19.3 | 57.1 |
| Claude-3-Opus | - | - | 25.5 | 11.7 | 68.4 |
| GPT-4-Turbo-1106 | - | - | 22.8 | 22.7 | 65.4 |
| GPT-4-Turbo-0409 | - | - | 24.3 | 18.3 | 63.9 |
| GPT-4o-0513 | - | - | 26.1 | 26.7 | 72.9 |
| 开源模型 | |||||
| CodeStral | 22B | 22B | 17.8 | 2.7 | 51.1 |
| DeepSeek-Coder-Instruct | 33B | 33B | 11.3 | 0.0 | 54.5 |
| Llama3-Instruct | 70B | 70B | 16.2 | - | 49.2 |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 9.2 | 0.0 | 44.4 |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 21.0 | 12.7 | 73.7 |
3.4 数学推理
| #TP | #AP | GSM8K | MATH | AIME 2024 | Math Odyssey | |
|---|---|---|---|---|---|---|
| 闭源模型 | ||||||
| Gemini-1.5-Pro | - | - | 90.8 | 67.7 | 2/30 | 45.0 |
| Claude-3-Opus | - | - | 95.0 | 60.1 | 2/30 | 40.6 |
| GPT-4-Turbo-1106 | - | - | 91.4 | 64.3 | 1/30 | 49.1 |
| GPT-4-Turbo-0409 | - | - | 93.7 | 73.4 | 3/30 | 46.8 |
| GPT-4o-0513 | - | - | 95.8 | 76.6 | 2/30 | 53.2 |
| 开源模型 | ||||||
| Llama3-Instruct | 70B | 70B | 93.0 | 50.4 | 1/30 | 27.9 |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 86.4 | 61.8 | 0/30 | 44.4 |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 94.9 | 75.7 | 4/30 | 53.7 |
3.5 通用自然语言
| 基准测试 | 领域 | DeepSeek-V2-Lite Chat | DeepSeek-Coder-V2-Lite Instruct | DeepSeek-V2 Chat | DeepSeek-Coder-V2 Instruct |
|---|---|---|---|---|---|
| BBH | 英语 | 48.1 | 61.2 | 79.7 | 83.9 |
| MMLU | 英语 | 55.7 | 60.1 | 78.1 | 79.2 |
| ARC-Easy | 英语 | 86.1 | 88.9 | 98.1 | 97.4 |
| ARC-Challenge | 英语 | 73.4 | 77.4 | 92.3 | 92.8 |
| TriviaQA | 英语 | 65.2 | 59.5 | 86.7 | 82.3 |
| NaturalQuestions | 英语 | 35.5 | 30.8 | 53.4 | 47.5 |
| AGIEval | 英语 | 42.8 | 28.7 | 61.4 | 60 |
| CLUEWSC | 中文 | 80.0 | 76.5 | 89.9 | 85.9 |
| C-Eval | 中文 | 60.1 | 61.6 | 78.0 | 79.4 |
| CMMLU | 中文 | 62.5 | 62.7 | 81.6 | 80.9 |
| Arena-Hard | - | 11.4 | 38.1 | 41.6 | 65.0 |
| AlpaceEval 2.0 | - | 16.9 | 17.7 | 38.9 | 36.9 |
| MT-Bench | - | 7.37 | 7.81 | 8.97 | 8.77 |
| Alignbench | - | 6.02 | 6.83 | 7.91 | 7.84 |
3.6 上下文窗口
在“Needle In A Haystack”(NIAH)测试中的评估结果。DeepSeek-Coder-V2 在所有上下文窗口长度上表现良好,最高可达 128K。
4. 聊天网站
您可以在 DeepSeek 官方网站上与 DeepSeek-Coder-V2 进行对话:chat.deepseek.com
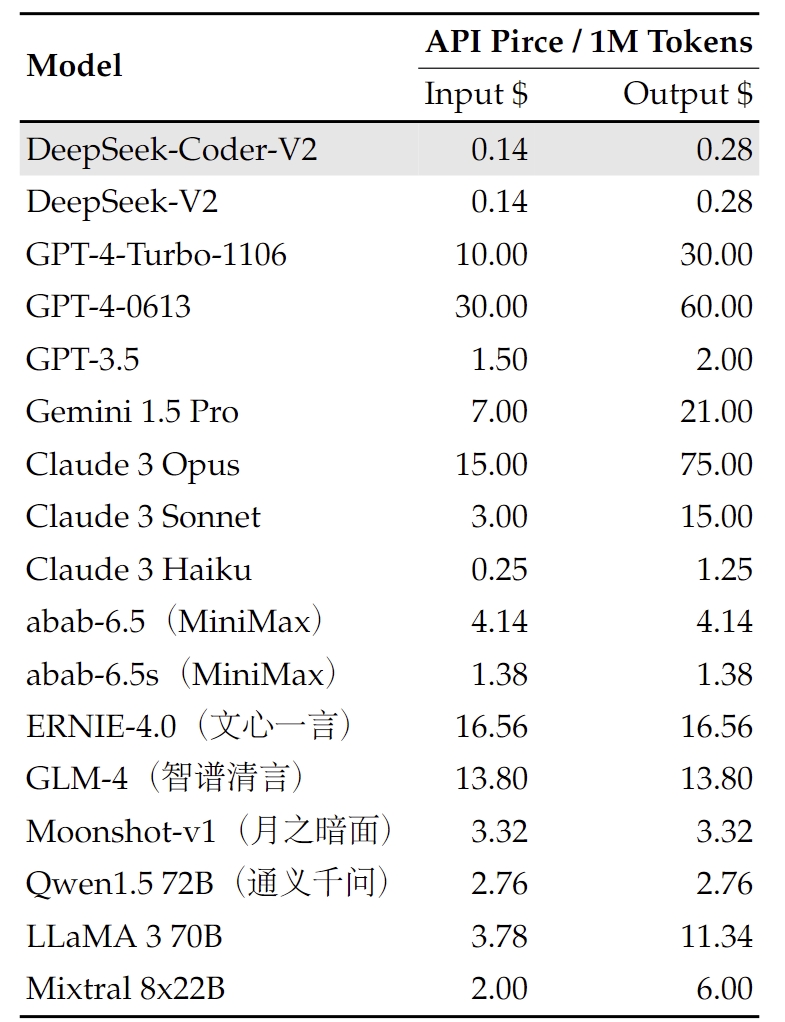
5. API 平台
我们还在 DeepSeek 平台提供与 OpenAI 兼容的 API:platform.deepseek.com,并且您可以按需付费,价格极具竞争力。
6. 如何本地运行
在此,我们提供了一些使用 DeepSeek-Coder-V2-Lite 模型的示例。如果您想以 BF16 格式运行 DeepSeek-Coder-V2 进行推理,则需要 80GB*8 张 GPU。
使用 Hugging Face 的 Transformers 进行推理
您可以直接使用 Hugging Face 的 Transformers 进行模型推理。
代码补全
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
代码插入
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
聊天补全
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id 是 <|end▁of▁sentence|> 标记的 id
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
完整的聊天模板可以在 Hugging Face 模型仓库中的 tokenizer_config.json 文件中找到。
聊天模板示例如下:
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
您还可以添加可选的系统消息:
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
在最后一轮对话中,请注意“Assistant:”后面没有空格。如果添加空格,可能会导致 16B-Lite 模型出现以下问题:
- 英文问题返回中文回答。
- 回答包含乱码。
- 回答过度重复。
Ollama 的旧版本曾存在此 bug(参见 https://github.com/deepseek-ai/DeepSeek-Coder-V2/issues/12),但最新版本已修复。
使用 SGLang 进行推理(推荐)
SGLang 目前支持 MLA 优化、FP8 (W8A8)、FP8 KV 缓存以及 Torch Compile,在开源框架中提供了最佳的延迟和吞吐量。以下是启动兼容 OpenAI API 的服务器的一些示例命令:
# BF16,张量并行度 = 8
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-Coder-V2-Instruct --tp 8 --trust-remote-code
# BF16,启用 torch.compile(编译可能需要几分钟)
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct --trust-remote-code --enable-torch-compile
# FP8,张量并行度 = 8,FP8 KV 缓存
python3 -m sglang.launch_server --model neuralmagic/DeepSeek-Coder-V2-Instruct-FP8 --tp 8 --trust-remote-code --kv-cache-dtype fp8_e5m2
启动服务器后,您可以使用 OpenAI API 进行查询:
import openai
client = openai.Client(
base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# 聊天补全
response = client.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."},
],
temperature=0,
max_tokens=64,
)
print(response)
使用 vLLM 进行推理(推荐)
要使用 vLLM 进行模型推理,请将此 Pull Request 合并到您的 vLLM 代码库中:https://github.com/vllm-project/vllm/pull/4650。
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "write a quick sort algorithm in python."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
7. 许可证
本代码仓库采用 MIT 许可证 许可。DeepSeek-Coder-V2 Base/Instruct 模型的使用受 模型许可证 约束。DeepSeek-Coder-V2 系列(包括 Base 和 Instruct)支持商业用途。
8. 引用
@article{zhu2024deepseek,
title={DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence},
author={Zhu, Qihao and Guo, Daya and Shao, Zhihong and Yang, Dejian and Wang, Peiyi and Xu, Runxin and Wu, Y and Li, Yukun and Gao, Huazuo and Ma, Shirong and others},
journal={arXiv preprint arXiv:2406.11931},
year={2024}
}
9. 联系方式
如果您有任何疑问,请提交 issue 或联系我们的邮箱 service@deepseek.com。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。