self-llm
self-llm 是一本专为中文初学者打造的“开源大模型食用指南”,旨在帮助用户在 Linux 环境下轻松完成国内外主流大语言模型(LLM)及多模态模型的本地部署与微调。面对层出不穷的开源模型,普通用户往往受限于复杂的环境配置和高门槛的技术细节,难以亲手体验或定制专属模型。self-llm 通过提供全流程教程,有效解决了这一痛点,将原本繁琐的配置、部署和应用过程简化为清晰的步骤。
该项目内容覆盖从基础环境搭建、模型本地运行(支持 LLaMA、ChatGLM、Qwen 等 50+ 主流模型),到进阶的高效微调技术(如 LoRA、全参数微调、P-Tuning),甚至包含 LangChain 集成与命令行调用等实战应用。此外,项目还收录了丰富的案例,如模仿特定语气的聊天机器人、数学解题助手及个性化数字人制作教程,让学习者能直观理解如何将大模型应用于具体场景。
self-llm 特别适合希望低成本长期使用大模型的学生、NLP 领域初学者、研究人员以及想要构建私域特色模型的开发者。无论你是否具备深厚的技术背景,只要想在本地自由探索和驾驭开源大模型,都能在这里找到循序渐进的学习路径,真正让前沿 AI 技术融入日常学习与研究之中。
使用场景
某高校计算机专业研究生希望基于《红楼梦》人物对话数据,在本地 Linux 服务器上微调一个具有“林黛玉”说话风格的专属大模型,用于文学创作辅助研究。
没有 self-llm 时
- 环境配置劝退:面对 PyTorch、CUDA 版本冲突及各类依赖库报错,花费数天仍无法跑通基础环境,甚至不知道从何查起。
- 教程碎片化:网上关于 LLaMA、ChatGLM 等不同模型的部署教程分散且步骤不一,缺乏针对国内网络环境的优化指南,下载模型权重经常中断。
- 微调门槛高:不懂分布式训练原理,面对全量微调和 LoRA 的代码实现无从下手,难以将自定义数据集适配到模型训练中。
- 应用落地难:模型训练好后,不知道如何通过命令行调用或集成到 LangChain 框架中,只能对着终端发呆,无法转化为实际应用。
使用 self-llm 后
- 一键配环境:直接参照 self-llm 提供的 Linux 环境配置指南,按步骤执行脚本,快速解决依赖冲突,半天内即可完成基础环境搭建。
- 全流程指引:利用 self-llm 中针对 Qwen 或 InternLM 等主流模型的专属教程,顺利下载权重并完成本地部署,过程清晰且避开了常见坑点。
- 低代码微调:跟随 self-llm 的 LoRA 微调章节,轻松加载《红楼梦》数据集,通过标准化流程完成风格化训练,无需深究底层分布式代码。
- 快速集成应用:依据 self-llm 的应用指导,迅速将微调后的模型封装为 API 或嵌入 Demo,实现了与“林黛玉”的实时对话交互。
self-llm 将原本高不可攀的大模型技术转化为标准化的操作手册,让普通学生也能低成本、高效率地拥有并驾驭专属大模型。
运行环境要求
- Linux
- macOS
- NVIDIA GPU (主流部署),AMD GPU (专区支持), 昇腾 Ascend NPU (专区支持)
- 显存需求视具体模型而定 (如 7B 模型通常需 16GB+ 以进行全量微调,推理可更低)
- CUDA 版本未明确说明 (通常需 11.7+ 或 12.1+)
未说明 (建议 16GB 以上,大模型微调推荐 32GB+)

快速开始

开源大模型食用指南
中文 | English
本项目是一个围绕开源大模型、针对国内初学者、基于 Linux 平台的中国宝宝专属大模型教程,针对各类开源大模型提供包括环境配置、本地部署、高效微调等技能在内的全流程指导,简化开源大模型的部署、使用和应用流程,让更多的普通学生、研究者更好地使用开源大模型,帮助开源、自由的大模型更快融入到普通学习者的生活中。
本项目的主要内容包括:
- 基于 Linux 平台的开源 LLM 环境配置指南,针对不同模型要求提供不同的详细环境配置步骤;
- 针对国内外主流开源 LLM 的部署使用教程,包括 LLaMA、ChatGLM、InternLM 等;
- 开源 LLM 的部署应用指导,包括命令行调用、在线 Demo 部署、LangChain 框架集成等;
- 开源 LLM 的全量微调、高效微调方法,包括分布式全量微调、LoRA、ptuning 等。
项目的主要内容就是教程,让更多的学生和未来的从业者了解和熟悉开源大模型的食用方法!任何人都可以提出issue或是提交PR,共同构建维护这个项目。
想要深度参与的同学可以联系我们,我们会将你加入到项目的维护者中。
学习建议:本项目的学习建议是,先学习环境配置,然后再学习模型的部署使用,最后再学习微调。因为环境配置是基础,模型的部署使用是基础,微调是进阶。初学者可以选择Qwen1.5,InternLM2,MiniCPM等模型优先学习。
进阶学习推荐 :如果您在学习完本项目后,希望更深入地理解大语言模型的核心原理,并渴望亲手从零开始训练属于自己的大模型,我们强烈推荐关注 Datawhale 的另一个开源项目—— Happy-LLM 从零开始的大语言模型原理与实践教程 。该项目将带您深入探索大模型的底层机制,掌握完整的训练流程。
注:如果有同学希望了解大模型的模型构成,以及从零手写RAG、Agent和Eval等任务,可以学习Datawhale的另一个项目Tiny-Universe,大模型是当下深度学习领域的热点,但现有的大部分大模型教程只在于教给大家如何调用api完成大模型的应用,而很少有人能够从原理层面讲清楚模型结构、RAG、Agent 以及 Eval。所以该仓库会提供全部手写,不采用调用api的形式,完成大模型的 RAG 、 Agent 、Eval 任务。
注:考虑到有同学希望在学习本项目之前,希望学习大模型的理论部分,如果想要进一步深入学习 LLM 的理论基础,并在理论的基础上进一步认识、应用 LLM,可以参考 Datawhale 的 so-large-llm课程。
注:如果有同学在学习本课程之后,想要自己动手开发大模型应用。同学们可以参考 Datawhale 的 动手学大模型应用开发 课程,该项目是一个面向小白开发者的大模型应用开发教程,旨在基于阿里云服务器,结合个人知识库助手项目,向同学们完整的呈现大模型应用开发流程。
项目意义
什么是大模型?
大模型(LLM)狭义上指基于深度学习算法进行训练的自然语言处理(NLP)模型,主要应用于自然语言理解和生成等领域,广义上还包括机器视觉(CV)大模型、多模态大模型和科学计算大模型等。
百模大战正值火热,开源 LLM 层出不穷。如今国内外已经涌现了众多优秀开源 LLM,国外如 LLaMA、Alpaca,国内如 ChatGLM、BaiChuan、InternLM(书生·浦语)等。开源 LLM 支持用户本地部署、私域微调,每一个人都可以在开源 LLM 的基础上打造专属于自己独特的大模型。
然而,当前普通学生和用户想要使用这些大模型,需要具备一定的技术能力,才能完成模型的部署和使用。对于层出不穷又各有特色的开源 LLM,想要快速掌握一个开源 LLM 的应用方法,是一项比较有挑战的任务。
本项目旨在首先基于核心贡献者的经验,实现国内外主流开源 LLM 的部署、使用与微调教程;在实现主流 LLM 的相关部分之后,我们希望充分聚集共创者,一起丰富这个开源 LLM 的世界,打造更多、更全面特色 LLM 的教程。星火点点,汇聚成海。
我们希望成为 LLM 与普罗大众的阶梯,以自由、平等的开源精神,拥抱更恢弘而辽阔的 LLM 世界。
项目受众
本项目适合以下学习者:
- 想要使用或体验 LLM,但无条件获得或使用相关 API;
- 希望长期、低成本、大量应用 LLM;
- 对开源 LLM 感兴趣,想要亲自上手开源 LLM;
- NLP 在学,希望进一步学习 LLM;
- 希望结合开源 LLM,打造领域特色的私域 LLM;
- 以及最广大、最普通的学生群体。
项目规划及进展
本项目拟围绕开源 LLM 应用全流程组织,包括环境配置及使用、部署应用、微调等,每个部分覆盖主流及特点开源 LLM:
Example 系列
Chat-嬛嬛: Chat-甄嬛是利用《甄嬛传》剧本中所有关于甄嬛的台词和语句,基于LLM进行LoRA微调得到的模仿甄嬛语气的聊天语言模型。
Tianji-天机:天机是一款基于人情世故社交场景,涵盖提示词工程 、智能体制作、 数据获取与模型微调、RAG 数据清洗与使用等全流程的大语言模型系统应用教程。
AMChat: AM (Advanced Mathematics) chat 是一个集成了数学知识和高等数学习题及其解答的大语言模型。该模型使用 Math 和高等数学习题及其解析融合的数据集,基于 InternLM2-Math-7B 模型,通过 xtuner 微调,专门设计用于解答高等数学问题。
数字生命: 本项目将以我为原型,利用特制的数据集对大语言模型进行微调,致力于创造一个能够真正反映我的个性特征的AI数字人——包括但不限于我的语气、表达方式和思维模式等等,因此无论是日常聊天还是分享心情,它都以一种既熟悉又舒适的方式交流,仿佛我在他们身边一样。整个流程是可迁移复制的,亮点是数据集的制作。
已支持模型
✨ 已支持 50+ 主流大语言模型 ✨
每个模型都提供完整的部署、微调和使用教程
📖 查看完整模型列表和教程 |
🎯 快速开始
|
• Kimi-K2.5 • Step-3.5-Flash • GLM-4.7-Flash • Gemma3 • MiniMax-M2.5 • MiniMax-M2 • Qwen3 • Qwen3-VL • SpatialLM • Hunyuan3D-2 • Qwen2-VL • MiniCPM-o • Qwen2.5-Coder • DeepSeek-Coder-V2 • gpt-oss-20b • GLM-4.1-Thinking |
• DeepSeek-R1 • InternLM3 • phi4 • GLM-4.5-Air • Hunyuan-A13B • DeepSeek • Baichuan • InternLM • Kimi • ERNIE-4.5 • Llama4 • Apple OpenELM |
• Llama3.1 • Gemma-2 • Qwen2.5 • Qwen2 • GLM-4 • Qwen 1.5 • phi-3 • MiniCPM • Yi 零一万物 • Yuan2.0 • Yuan2.0-M32 • 哔哩哔哩 Index |
• CharacterGLM • BlueLM • Qwen-Audio • TransNormerLLM • Atom • ChatGLM3 • Qwen2-57B-A14B-Instruct • Qwen2-72B-Instruct • Qwen2-7B-Instruct • InternLM2-20B • Tele-Chat • XVERSE2 |
AMD GPU 专区
🚀 AMD GPU 平台已支持模型
每个模型都提供完整的 AMD 环境配置和部署教程
感谢 AMD University Program 对本项目的支持
📖 查看完整 AMD 平台模型列表和教程
|
• 谷歌 Gemma3 • AMD 环境准备与配置 • NPU 推理加速支持 |
• Qwen3 • lemonade-server SDK 部署 • Ryzen AI 300 系列优化 |
昇腾Ascend NPU 专区
🚀 昇腾Ascend NPU 平台已支持模型
每个模型都提供完整的昇腾Ascend NPU 环境配置和部署教程
📖 查看完整昇腾 NPU 平台模型列表和教程
|
• Qwen3 • Ascend NPU 环境配置通用指南 • MindIE 服务化部署调用 • vLLM-ascend 部署调用 • sglang-ascend 部署调用 |
• 大模型服务化性能和精度测试 • AISBench 测试工具环境配置 • 昇腾大模型服务化性能测试 • 昇腾大模型服务化精度测试 |
沐曦专区
Coming Soon!
Apple M 专区
Welcome More Platforms!
- 🚀 即将支持更多平台(Apple M 系列已有设备测试),敬请期待!
- 🤝 欢迎昇腾 Ascend、摩尔线程 MUSA、沐曦等平台提供技术支持、硬件支持或参与贡献
- 🌟 欢迎各平台开发者共建共享,推动大模型技术在更多国产硬件生态中的繁荣发展!
致谢
核心贡献者
- 宋志学(不要葱姜蒜)-项目负责人 (Datawhale成员)
- 邹雨衡-项目负责人 (Datawhale成员-对外经济贸易大学)
- 刘十一-Ascend专区负责人(Datawhale成员-鲸英助教)
- 姜舒凡(内容创作者-Datawhale成员)
- 郭宣伯(内容创作者-北京航空航天大学)
- 林泽毅(内容创作者-SwanLab产品负责人)
- 林恒宇(内容创作者-广东东软学院-鲸英助教)
- 王泽宇(内容创作者-太原理工大学-鲸英助教)
- 郭志航(内容创作者)
- 陈榆(内容创作者-谷歌开发者机器学习技术专家)
- 肖鸿儒 (Datawhale成员-同济大学)
- 张帆(内容创作者-Datawhale成员)
- 李娇娇 (Datawhale成员)
- 高立业(内容创作者-DataWhale成员)
- Kailigithub (Datawhale成员)
- 丁悦 (Datawhale-鲸英助教)
- 谢好冉(内容创作者-鲸英助教)
- 惠佳豪 (Datawhale-宣传大使)
- 王茂霖(内容创作者-Datawhale成员)
- 孙健壮(内容创作者-对外经济贸易大学)
- 郑皓桦 (内容创作者)
- 荞麦(内容创作者-Datawhale成员)
- 骆秀韬(内容创作者-Datawhale成员-似然实验室)
- 李柯辰 (Datawhale成员)
- 程宏(内容创作者-Datawhale意向成员)
- 李秀奇(内容创作者-DataWhale意向成员)
- 余洋(内容创作者-安徽理工大学副教授-Datawhale成员)
- 陈思州 (Datawhale成员)
- 颜鑫 (Datawhale成员)
- 杜森(内容创作者-Datawhale成员-南阳理工学院)
- 散步 (Datawhale成员)
- 郑远婧(内容创作者-鲸英助教-福州大学)
- Swiftie (小米NLP算法工程师)
- 张友东(内容创作者-Datawhale成员)
- 张晋(内容创作者-Datawhale成员)
- 娄天奥(内容创作者-中国科学院大学-鲸英助教)
- 小罗 (内容创作者-Datawhale成员)
- 邓恺俊(内容创作者-Datawhale成员)
- 赵文恺(内容创作者-太原理工大学-鲸英助教)
- 王熠明(内容创作者-Datawhale成员)
- 黄柏特(内容创作者-西安电子科技大学)
- 左春生(内容创作者-Datawhale成员)
- 杨卓(内容创作者-西安电子科技大学-鲸英助教)
- 付志远(内容创作者-海南大学)
- 三水(内容创作者-鲸英助教)
- 樊奇(内容创作者-上海交通大学)
- 陈辅元(内容创作者-Datawhale成员)
- 谭逸珂(内容创作者-对外经济贸易大学)
- 何至轩(内容创作者-鲸英助教)
- 康婧淇(内容创作者-Datawhale成员)
- 杨晨旭(内容创作者-太原理工大学-鲸英助教)
- 赵伟(内容创作者-鲸英助教)
- 苏向标(内容创作者-广州大学-鲸英助教)
- 陈睿(内容创作者-西交利物浦大学-鲸英助教)
- 张龙斐(内容创作者-鲸英助教)
- 孙超(内容创作者-Datawhale成员)
- 卓堂越(内容创作者-鲸英助教)
- fancy(内容创作者-鲸英助教)
- 谭斐然(西安电子科技大学-鲸英助教)
注:排名根据贡献程度排序
其他
- 特别感谢@Sm1les对本项目的帮助与支持
- 感谢 AMD University Program 对本项目的支持
- 部分lora代码和讲解参考仓库:https://github.com/zyds/transformers-code.git
- 如果有任何想法可以联系我们 DataWhale 也欢迎大家多多提出 issue
- 特别感谢以下为教程做出贡献的同学!

Star History
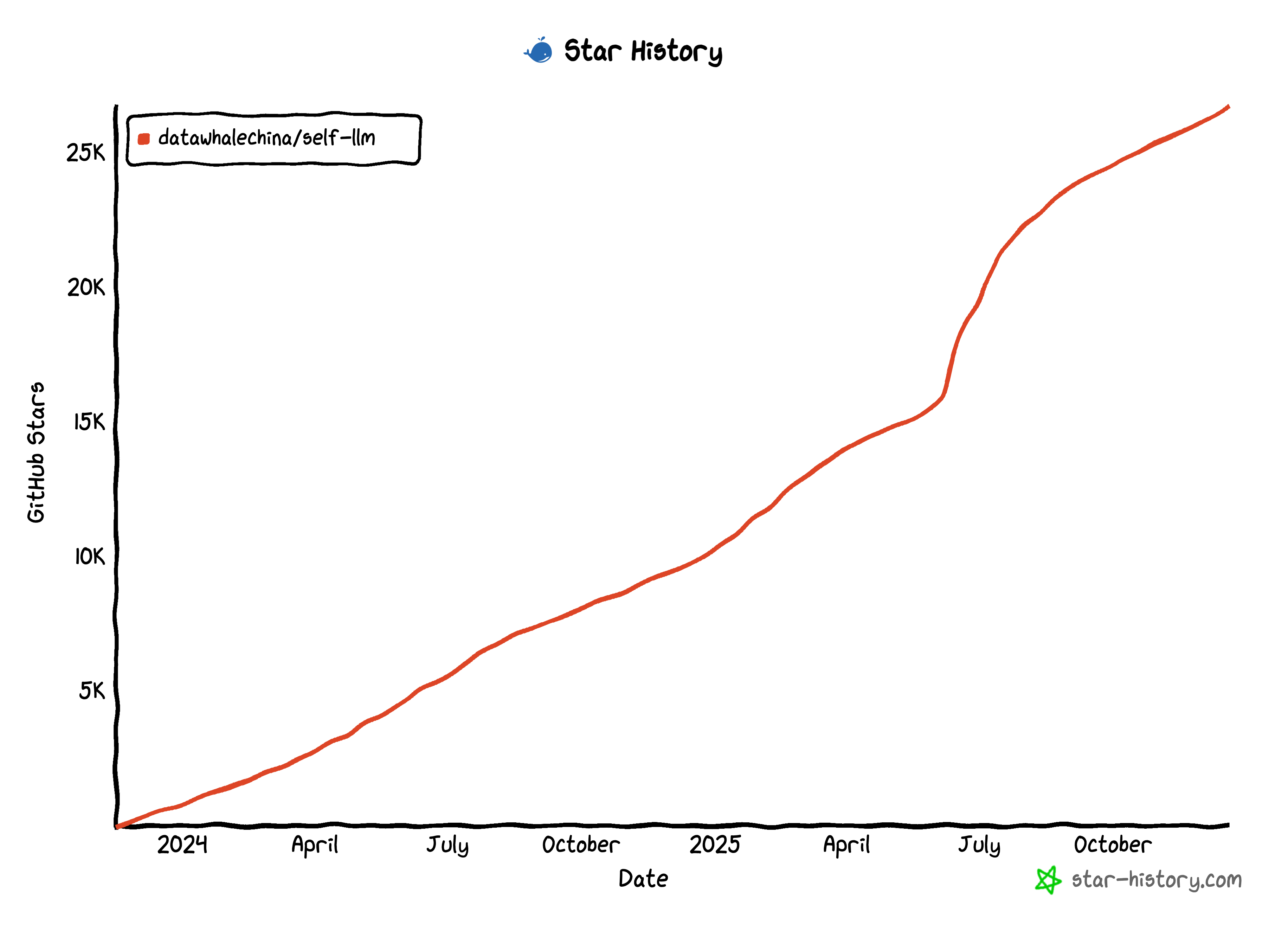
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。