cvat
CVAT 是一款行业领先的交互式计算机视觉标注工具,专为图像和视频数据的机器学习任务设计。它致力于解决 AI 开发中数据标注效率低、协作难的核心痛点,帮助用户构建高质量的训练数据集,从而推动“以数据为中心”的 AI 落地实践。
无论是个人开发者、科研团队还是大型企业,都能通过 CVAT 灵活应对不同规模的数据处理需求。研究人员可利用其强大的语义分割等功能构建学术数据集;开发团队能借助自动标注、模型集成(如 Roboflow 和 HuggingFace)大幅提升工作流效率;企业用户则可选择云端服务或私有化部署,享受包括单点登录(SSO)、高级分析在内的企业级支持。
CVAT 的独特亮点在于其极高的灵活性与开放性:既提供开箱即用的免费在线版本,也支持完整的自托管部署方案,确保数据隐私与安全。此外,它还配备了完善的 Python SDK、命令行工具以及 Datumaro 数据集框架,方便用户进行二次开发和深度集成。凭借活跃的社区生态和广泛的全球应用案例,CVAT 已成为连接原始数据与智能模型之间不可或缺的桥梁。
使用场景
某自动驾驶初创团队正急需构建一个包含数万张城市道路图像的数据集,用于训练识别行人和交通标志的目标检测模型。
没有 cvat 时
- 标注人员只能使用本地单机软件(如 LabelImg)逐个打开图片,文件分散且无法实时同步进度,协作效率极低。
- 缺乏统一的质量审核机制,不同标注员对“遮挡行人”的判定标准不一,导致数据集标签噪声大,模型训练效果波动明显。
- 视频数据需要逐帧拆解为图片再手动标注,耗时费力,且难以利用前后帧的连续性进行快速插值处理。
- 项目管理者无法直观查看整体标注进度或分配具体任务,沟通成本高昂,经常发生任务重复或遗漏。
使用 cvat 后
- 团队通过 cvat 的云端或私有化部署实现多人在线协同,支持任务自动分发与实时状态同步,标注吞吐量提升数倍。
- 利用内置的审核工作流和评论功能,资深工程师可直接在画面上修正错误并统一标准,显著降低了标签噪声,提升了模型精度。
- 针对监控视频数据,cvat 提供强大的视频插值功能,只需标注关键帧即可自动生成中间帧轨迹,视频标注效率提高 80% 以上。
- 管理者通过可视化仪表盘实时监控各任务进度与人员绩效,灵活调整资源分配,确保项目按时交付。
cvat 通过标准化的协同工作流和智能辅助功能,将原本杂乱低效的数据标注过程转变为高效、可控的工业化生产线。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 支持自动标注的无服务器函数可选使用 GPU(如 Segment Anything 支持 CPU/GPU,部分 OpenVINO 模型仅支持 CPU)
- 具体显卡型号、显存大小及 CUDA 版本未在文档中明确说明
未说明
快速开始
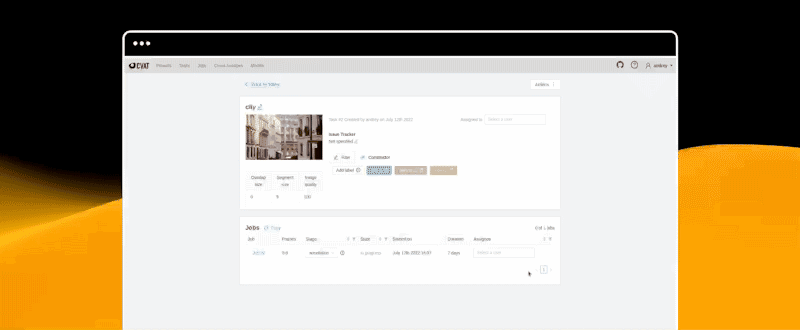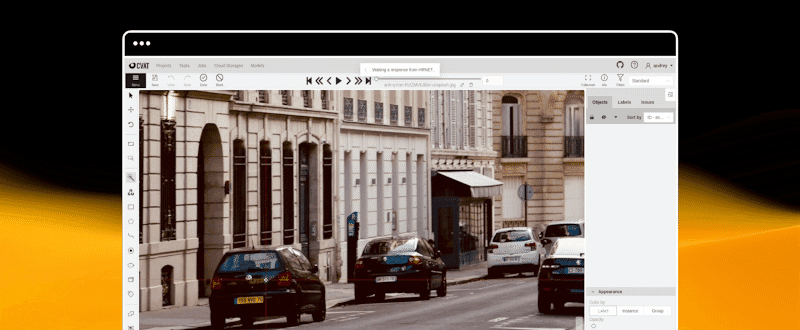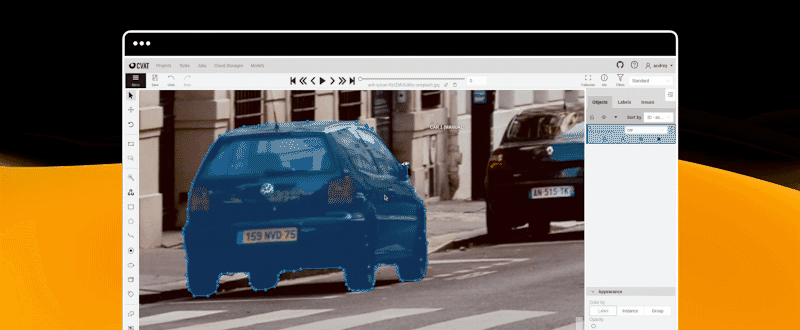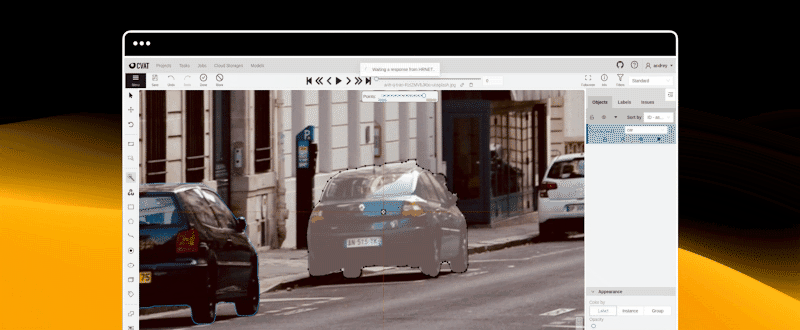

计算机视觉标注工具 (CVAT)
![]()


![]()


![]()

CVAT 是一款用于计算机视觉的交互式视频和图像标注工具。全球数以万计的用户和公司都在使用它。我们的使命是帮助世界各地的开发者、企业和组织,通过以数据为中心的人工智能方法解决实际问题。
在线使用 CVAT:cvat.ai。您可以免费使用,也可以订阅,以获得无限的数据存储、组织管理、自动标注功能,以及与 Roboflow 和 HuggingFace 的集成。
或者将 CVAT 部署为自托管解决方案: 自托管安装指南。 我们为自托管部署提供企业级支持,包含高级功能:SSO、LDAP、与 Roboflow 和 HuggingFace 的集成,以及高级分析(即将推出)。此外,我们还提供培训和 24 小时 SLA 的专属支持。
快速入门 ⚡
合作伙伴 ❤️
CVAT 被全球各地的团队广泛使用。在列表中,您可以看到那些帮助我们支持产品或构成我们生态系统重要组成部分的关键公司。如果您正在使用 CVAT,请发送邮件至 contact@cvat.ai 与我们联系。
- Human Protocol 将 CVAT 用作向 Human Protocol 添加标注服务的方式。
- FiftyOne 是一个开源的数据集管理和模型分析工具,用于可视化、探索和改进计算机视觉数据集及模型,它与 CVAT 紧密集成,用于标注和标签优化。
公开数据集
由南卡罗来纳大学土木与环境工程系的 iWERS 团队开发的水体图像语义分割开源数据集 ATLANTIS 正在使用 CVAT。
有关如何使用 CVAT 构建语义分割数据集,请参阅:
CVAT 在线版:cvat.ai
这是 CVAT 的在线版本。它免费、高效且易于使用。
cvat.ai 运行的是最新版本的工具。您可以在那里创建最多 10 个任务,并上传最多 500MB 的数据进行标注。这些数据仅对您或您指定的人员可见。
目前,它不具备分析功能,例如管理和监控数据标注团队。同时,它也不支持导出图像,只能导出标注信息。
我们计划为 cvat.ai 增加更多强大的新功能。敬请期待!
预构建 Docker 镜像 🐳
预构建的 Docker 镜像是在本地快速启动 CVAT 的最简单方式。它们可在 Docker Hub 上找到:
这些镜像至今已被下载超过 100 万次。
屏幕录像 🎦
以下是一些展示如何使用 CVAT 的屏幕录像。
计算机视觉标注课程: 我们推出了这一系列课程,旨在帮助您使用 CVAT 更快、更好地标注数据。本课程主要介绍 CVAT 的部署与集成,内容包括演示文稿,涵盖以下主题:
- 加速您的数据标注流程:CVAT 和 Datumaro 简介。 CVAT 和 Datumaro 解决了哪些问题?它们如何加速您的模型训练过程?还有一些资源可以帮助您进一步了解如何使用它们。
- CVAT 的部署与使用。在线使用 app.cvat.ai。本地部署。使用 Docker Compose 的容器化本地部署(适用于常规使用),以及使用 Kubernetes 的本地集群部署(适用于企业用户)。2 分钟界面概览,CVAT 内部结构解析,以及演示如何使用 Docker Compose 部署 CVAT。
产品巡礼:在本课程中,我们展示了如何使用 CVAT,并帮助您熟悉其功能和界面。本课程不涉及集成,完全专注于 CVAT。内容包括:
- 工作流。在这段视频中,我们展示了如何使用 app.cvat.ai:如何注册、上传数据、进行标注并下载结果。
如需反馈,请参阅 联系我们
API
SDK
CLI
支持的标注格式
CVAT 支持多种标注格式。您可以在点击 上传标注 和 导出标注 按钮后选择格式。 Datumaro 数据集框架通过其命令行工具和 Python 库,支持对数据集进行额外的转换。
有关支持的格式的更多信息,请参阅: 标注格式。
| 标注格式 | 导入 | 导出 |
|---|---|---|
| 适用于图像的 CVAT | ✔️ | ✔️ |
| 适用于视频的 CVAT | ✔️ | ✔️ |
| Datumaro | ✔️ | ✔️ |
| PASCAL VOC | ✔️ | ✔️ |
| 来自 PASCAL VOC 的分割掩码 | ✔️ | ✔️ |
| YOLO | ✔️ | ✔️ |
| MS COCO 对象检测 | ✔️ | ✔️ |
| MS COCO 关键点检测 | ✔️ | ✔️ |
| MOT | ✔️ | ✔️ |
| MOTS PNG | ✔️ | ✔️ |
| LabelMe 3.0 | ✔️ | ✔️ |
| ImageNet | ✔️ | ✔️ |
| CamVid | ✔️ | ✔️ |
| WIDER Face | ✔️ | ✔️ |
| VGGFace2 | ✔️ | ✔️ |
| Market-1501 | ✔️ | ✔️ |
| ICDAR13/15 | ✔️ | ✔️ |
| Open Images V6 | ✔️ | ✔️ |
| Cityscapes | ✔️ | ✔️ |
| KITTI | ✔️ | ✔️ |
| Kitti 原始格式 | ✔️ | ✔️ |
| LFW | ✔️ | ✔️ |
| Supervisely 点云格式 | ✔️ | ✔️ |
| Ultralytics YOLO 检测 | ✔️ | ✔️ |
| Ultralytics YOLO 有向边界框 | ✔️ | ✔️ |
| Ultralytics YOLO 分割 | ✔️ | ✔️ |
| Ultralytics YOLO 姿态 | ✔️ | ✔️ |
| Ultralytics YOLO 分类 | ✔️ | ✔️ |
用于自动标注的深度学习无服务器函数
CVAT 支持自动标注功能,可将标注流程提速高达 10 倍。以下是我们的支持算法及其运行平台列表:
| 名称 | 类型 | 框架 | CPU | GPU |
|---|---|---|---|---|
| Segment Anything | 交互式 | PyTorch | ✔️ | ✔️ |
| Faster RCNN | 检测器 | OpenVINO | ✔️ | |
| Mask RCNN | 检测器 | OpenVINO | ✔️ | |
| YOLO v3 | 检测器 | OpenVINO | ✔️ | |
| YOLO v7 | 检测器 | ONNX | ✔️ | ✔️ |
| 目标重识别 | 重识别 | OpenVINO | ✔️ | |
| 面向 ADAS 的语义分割 | 检测器 | OpenVINO | ✔️ | |
| 文本检测 v4 | 检测器 | OpenVINO | ✔️ | |
| SiamMask | 跟踪器 | PyTorch | ✔️ | ✔️ |
| TransT | 跟踪器 | PyTorch | ✔️ | ✔️ |
| 内外引导 | 交互式 | PyTorch | ✔️ | |
| Faster RCNN | 检测器 | TensorFlow | ✔️ | ✔️ |
| RetinaNet | 检测器 | PyTorch | ✔️ | ✔️ |
| 人脸检测 | 检测器 | OpenVINO | ✔️ |
许可证
该代码根据 MIT 许可证 发布。
位于 /serverless 目录中的代码同样根据 MIT 许可证 发布。
然而,它可能会下载并使用各种资源,例如源代码、架构和权重等。
这些资源可能采用不同的许可证进行分发,其中包括非商业用途的许可证。
在使用这些资源之前,您有责任确保遵守相关许可证的条款。
本软件使用了来自 FFmpeg 项目的 LGPL 许可库。 关于 FFmpeg 的具体配置和编译步骤,请参阅 Dockerfile。
FFmpeg 是一个基于 LGPL 和 GPL 许可的开源框架。 详情请参阅 https://www.ffmpeg.org/legal.html。您需自行判断是否需要为您的 FFmpeg 使用申请额外的许可证。 CVAT.ai 公司不负责获取此类许可证,亦不对因您使用 FFmpeg 而产生的任何许可费用承担责任。
联系我们
如有关于 CVAT 使用的问题,请前往 Gitter 提问。 通常,核心团队或社区成员会迅速回复问题。您也可以在该平台上浏览其他常见问题。
Discord 同样是提问或讨论与 CVAT 相关话题的好去处。
如需咨询公司及工作相关事宜,请访问 LinkedIn。
观看关于 CVAT 的屏幕录制和教程,请访问 YouTube。
如需提出功能请求或报告 bug,请前往 GitHub issues。 如果是 bug,请务必附上复现步骤。
在 StackOverflow 上搜索 #cvat 标签,也是提问并获得支持的一种方式。
如果您需要商业支持,请通过我们的官网联系我们:使用我们的网站。
链接
版本历史
v2.62.02026/04/02v2.61.02026/03/20v2.60.02026/03/17v2.59.12026/03/09v2.59.02026/03/06v2.58.02026/02/23v2.57.02026/02/17v2.56.12026/02/03v2.56.02026/02/02v2.55.02026/01/19v2.54.02025/12/24v2.53.02025/12/18v2.52.02025/12/16v2.51.02025/12/01v2.50.02025/11/26v2.49.02025/11/06v2.48.12025/10/29v2.48.02025/10/27v2.47.02025/10/14v2.46.12025/10/10常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。