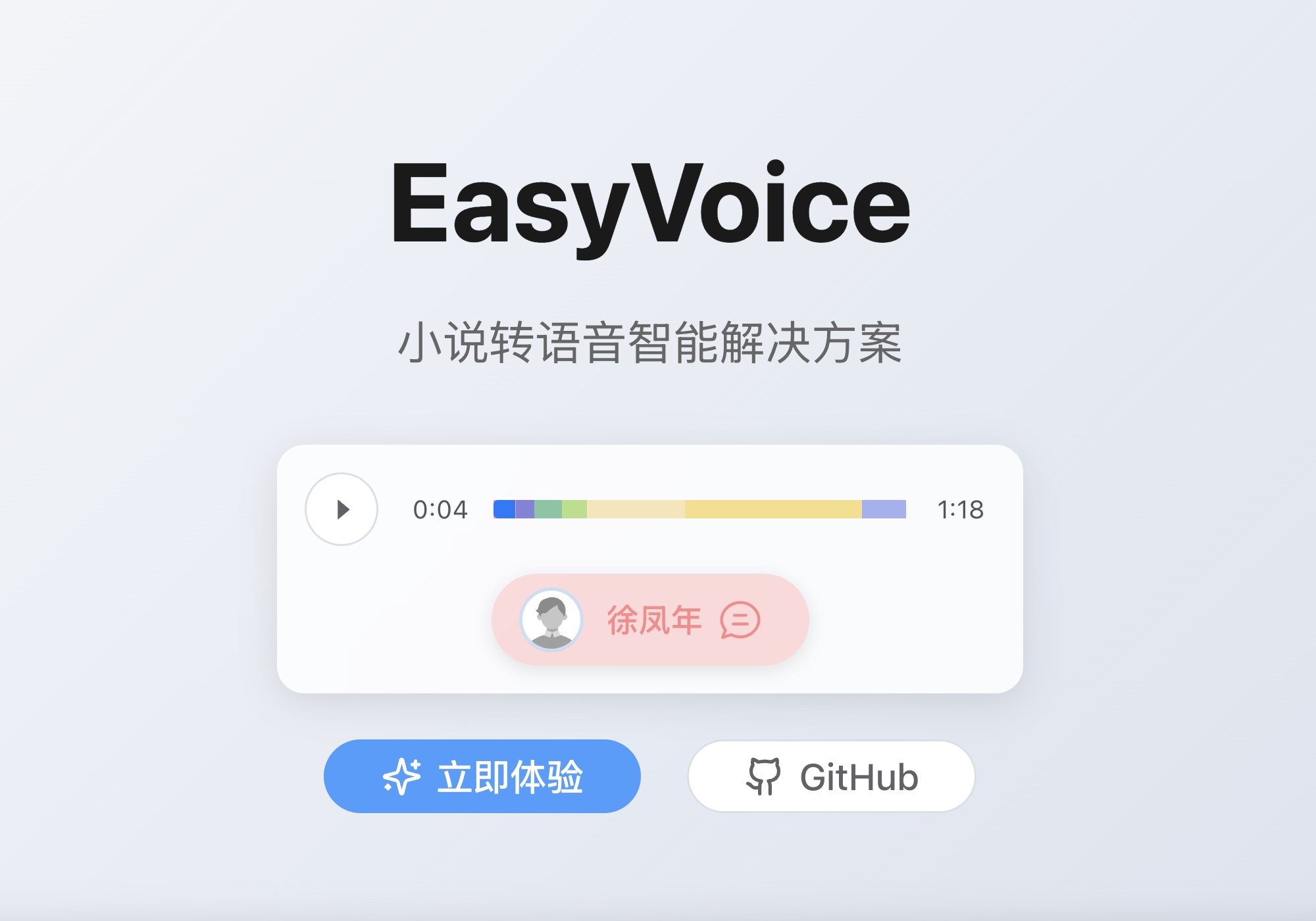
easyVoice
EasyVoice 是一款开源的文本转语音工具,专为处理超长内容(如十万字小说)而设计,能一键生成高质量语音与配套字幕。它解决了传统 TTS 工具对文本长度限制、角色单一、无法流式播放等问题,特别适合需要将大量文字转化为有声内容的用户。无论是普通读者想“听小说”、内容创作者制作配音、还是开发者搭建语音服务,都能轻松上手。其亮点在于支持多角色自定义配音——不同人物可分配不同声线、语速和音量,并通过 AI 智能推荐最优配置;同时采用流式传输技术,再长的文本也能边生成边播放,无需等待。部署灵活,既可通过 Docker 一键运行,也支持本地 Node.js 环境开发调试。目前基于 Azure TTS 引擎,未来将持续接入更多语音后端。完全免费、无字数与时长限制,是打造个性化音频体验的理想选择。
使用场景
一位独立游戏开发者正在为自己的武侠题材视觉小说制作全程配音,需要将10万字剧本中的多个角色对话与旁白转为自然语音,并适配不同人物性格。
没有 easyVoice 时
- 手动分段粘贴到免费TTS网站,每段限制500字,处理整本剧本需操作上百次,极易出错且耗时数天。
- 不同角色只能使用同一音色,缺乏情绪区分,玩家反馈“像机器人念经”,沉浸感严重不足。
- 无法预览效果,生成后才发现语速或音调不合适,必须全部重做,反复试错成本极高。
- 字幕需手动同步时间轴,与音频对齐耗费大量精力,后期修改更是噩梦。
- 超过2万字的章节直接被平台拒绝,被迫拆分成多个文件管理,版本混乱频发。
使用 easyVoice 后
- 一键上传整本剧本,自动识别角色并智能推荐匹配声线(如“徐凤年”用沉稳男声,“姜泥”用清脆女声),10分钟内完成全书语音合成。
- 支持自定义每个角色的语速、音调和音量,比如让反派“卢白撷”语速稍慢+低沉音调,增强压迫感。
- 生成前可逐句试听调整,不满意立即修改参数,避免返工,效率提升90%以上。
- 自动生成精准时间轴的SRT字幕文件,导入游戏引擎即可无缝播放,省去手动对齐的繁琐。
- 流式传输技术让超长文本边生成边播放,无需等待,本地部署还能离线使用,保护剧本版权。
easyVoice 让单人开发者也能低成本打造媲美商业级的多角色有声体验,把精力真正聚焦在创作而非技术琐事上。
运行环境要求
未说明
未说明
快速开始
EasyVoice 🎙️
项目简介 ✨
EasyVoice 是一个开源的文本、小说智能转语音(Text-to-Speech, TTS)解决方案,旨在帮助用户轻松将文本内容转换为高质量的语音输出。
一键生成语音和字幕
AI 智能推荐配音
完全免费,无时长、无字数限制
支持将 10 万字以上的小说一键转为有声书!
流式传输(Streaming),多长的文本都能立刻播放
支持自定义多角色配音
无论你是想听小说、为创作配音,还是打造个性化音频,EasyVoice 都是你的最佳助手!
你可以轻松地将 EasyVoice 部署到你的云服务器或者本地!
体验一下
核心功能 🌟
- 文本转语音 📝 ➡️ 🎵
一键将大段文本转为语音,高效又省时。 - 流式传输 🌊
再多的文本,都可以迅速返回音频直接开始试听! - 多语言支持 🌍
支持中文、英文等多种语言。 - 字幕支持 💬
自动生成字幕文件,方便视频制作和字幕翻译。 - 角色配音 🎭
提供多种声音选项,完美适配不同角色。 - 自定义设置 ⚙️
可调整语速、音调等参数,打造专属语音风格。 - AI 推荐 🧠
通过 AI 智能推荐最适合的语音配置,省心又贴心。 - 试听功能 🎧
生成前可试听效果,确保每一句都如你所愿!
Screenshots📸
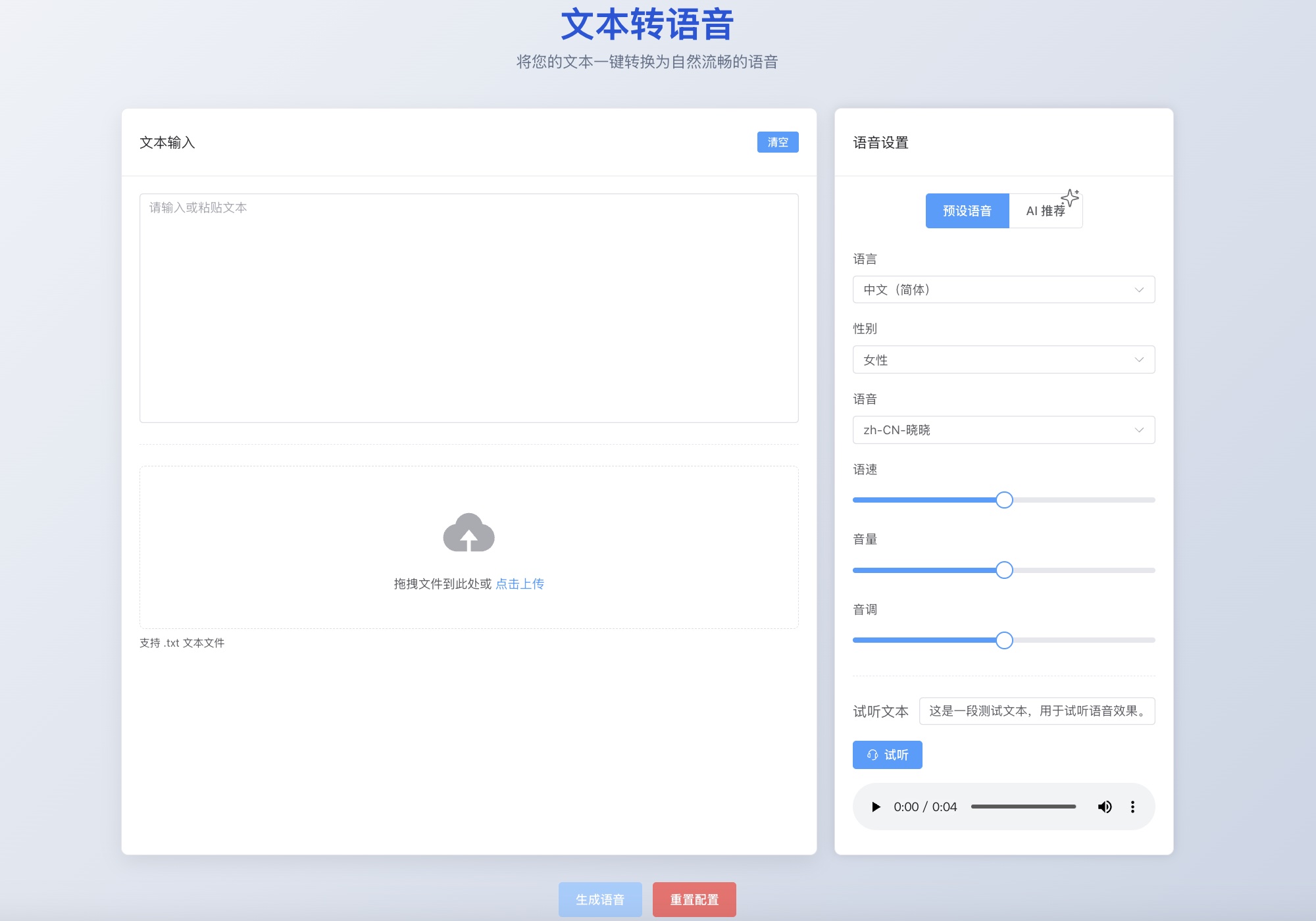
快速开始 🚀
1. 通过 docker 运行
# 极简运行,你可以通过 -e 指定环境变量
docker run -d -p 3000:3000 -v $(pwd)/audio:/app/audio cosincox/easyvoice:latest
或 将仓库克隆到本地,使用 Docker Compose 一键运行!
docker-compose up -d
2. 本地运行项目(请先确保已安装 Node.js 环境,参考:安装 Node.js)
# 开启/安装 pnpm
corepack enable
# 或者使用 npm 安装 pnpm
npm install -g pnpm
# 克隆仓库
git clone git@github.com:cosin2077/easyVoice.git
cd easyVoice
# 安装依赖
pnpm i -r
# 开发模式
pnpm dev:root
# 生产模式
pnpm build:root
pnpm start:root
3. 生成的音频、字幕保存位置
- Docker 部署: 保存在挂载的
audio目录下 - Node.js 运行保存在
./packages/backend/audio目录下
高级
角色自定义
启动服务后尝试在命令行运行下述命令:
curl -X POST http://localhost:3000/api/v1/tts/generateJson \
-H "Content-Type: application/json" \
-d '{
"data": [
{
"desc": "徐凤年",
"text": "你敢动他,我会穷尽一生毁掉卢家,说到做到",
"voice": "zh-CN-YunjianNeural",
"volume": "40%"
},
{
"desc": "姜泥",
"text": "徐凤年,你快走,你打不过的",
"voice": "zh-CN-XiaoyiNeural"
},
{
"desc": "路人甲",
"text": "他可是堂堂棠溪剑仙,这小子真是遇到强敌了",
"voice": "zh-CN-XiaoniNeural",
"volume": "-20%"
},
{
"desc": "路人乙",
"text": "这小子真是不知死活,竟然敢挑战卢白撷",
"voice": "zh-TW-HsiaoChenNeural",
"volume": "-20%"
},
{
"desc": "旁白",
"text": "面对棠溪剑仙卢白撷的杀意,徐凤年按住剑柄蓄势待发,他将姜泥放在心尖上,话锋一句比一句犀利,威逼利诱的要求卢白撷放姜泥一条生路。卢白撷也是不撞南墙不回头的人,他与西楚有深仇大恨不得不报...",
"voice": "zh-CN-YunxiNeural",
"rate": "0%",
"pitch": "0Hz",
"volume": "0%"
},
{
"desc": "旁白",
"text": "卢白撷凝聚剑气,剑光如虹,直指姜泥。剑气快到姜泥的时候,竟然被一颗小石子打破!万千剑气瞬间消散。居然就是刚刚进入山门的青衣男子。卢白撷心中警铃大作,再次凝结千万水剑想要先下手为强,青衣男子竟然一只手就挡下了,随之飓风盘起,竟然有山呼海啸之势,众人分分被逼退。随后的打斗,青衣男子每一步都精准预测了卢白撷的动作,卢白撷心中惊骇不已。",
"voice": "zh-CN-YunxiNeural",
"rate": "0%",
"pitch": "0Hz",
"volume": "0%"
},
{
"desc": "卢白撷",
"text": "人心入局,观子无敌,棋局未央,棋子难逃。你是!? 曹长卿!",
"voice": "zh-CN-YunyangNeural",
"rate": "-2%",
"pitch": "2Hz",
"volume": "10%"
}
]
}' \
-o output.mp3
你将看到output.mp3文件的生成,并立即可以播放。
参数说明
- text: 你需要转语音的文字。
- voice: 你需要用到的声音,参考:支持的声音列表
- rate: 语速调整,百分比形式,默认 +0%(正常),如 "+50%"(加快 50%),"-20%"(减慢 20%)。
- volume: 音量调整,百分比形式,默认 +0%(正常),如 "+20%"(增 20%),"-10%"(减 10%)。
- pitch: 音调调整,默认 +0Hz(正常),如 "+10Hz"(提高 10 赫兹),"-5Hz"(降低 5 赫兹)。
接入其他 TTS 服务
- TODO
技术实现 🛠️
- 前端:Vue 3 + TypeScript + Element Plus 🌐
- 后端:Node.js + Express + TypeScript ⚡
- 语音合成:Microsoft Azure TTS(更多引擎接入中) + OpenAI(OpenAI 兼容即可) + ffmpeg 🎤
- 部署:Node.js + Docker + Docker Compose 🐳
快速开发 🚀
1.克隆仓库
git clone https://github.com/cosin2077/easyVoice.git
2.安装依赖
pnpm i -r
3.启动项目
pnpm dev
4.打开浏览器,访问 http://localhost:5173/,开始体验吧!
环境变量 ⚙️
| 变量名 | 默认值 | 描述 |
|---|---|---|
PORT |
3000 |
服务端口 |
OPENAI_BASE_URL |
https://api.openai.com/v1 |
OpenAI 兼容 API 地址 |
OPENAI_API_KEY |
- | OpenAI API Key |
MODEL_NAME |
- | 使用的模型名称 |
RATE_LIMIT_WINDOW |
1 |
速率限制窗口大小(分钟) |
RATE_LIMIT |
10 |
速率限制次数 |
EDGE_API_LIMIT |
3 |
Edge-TTS API 并发数 |
- 配置文件:可在
.env或packages/backend/.env中设置,优先级为packages/backend/.env > .env。 - Docker 配置:通过
-e参数传入环境变量,如上文示例。
FAQ
Q: 如何配置 OpenAI 相关信息?
A: 在
.env文件中添加OPENAI_API_KEY=your_api_keyOPENAI_BASE_URL=openai_compatible_base_urlMODEL_NAME=openai_model_name,你可以用任何 openai compatible 的 API 地址和模型名称,例如https://openrouter.ai/api/v1/和deepseek。Q: 为什么我的AI配音效果不好?
A: AI 推荐配音是通过大模型来决定不同的段落的配音参数,大模型的能力直接影响配音结果,你可以尝试更换不同的大模型,或者是用 Edge-TTS 选择固定的声音配音。
Q: 速度太慢?
A: AI 推荐配音需要把输入的文本分段、然后让 AI 分析、推荐每一分段的配音参数,最后再生成音频、拼接。速度会比直接用 Edge-TTS慢。你可以更换相应更快的大模型,或者尝试调节 Edge-TTS 的并发参数:EDGE_API_LIMIT为更大的值(10 以下),注意并发太高可能会有限制。
Tips
当前主要通过 Edge-TTS API 提供免费语音合成。
未来计划支持官方 API、Google TTS、声音克隆等功能。
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。
LocalAI
LocalAI 是一款开源的本地人工智能引擎,旨在让用户在任意硬件上轻松运行各类 AI 模型,包括大语言模型、图像生成、语音识别及视频处理等。它的核心优势在于彻底打破了高性能计算的门槛,无需昂贵的专用 GPU,仅凭普通 CPU 或常见的消费级显卡(如 NVIDIA、AMD、Intel 及 Apple Silicon)即可部署和运行复杂的 AI 任务。 对于担心数据隐私的用户而言,LocalAI 提供了“隐私优先”的解决方案,确保所有数据处理均在本地基础设施内完成,无需上传至云端。同时,它完美兼容 OpenAI、Anthropic 等主流 API 接口,这意味着开发者可以无缝迁移现有应用,直接利用本地资源替代云服务,既降低了成本又提升了可控性。 LocalAI 内置了超过 35 种后端支持(如 llama.cpp、vLLM、Whisper 等),并集成了自主 AI 代理、工具调用及检索增强生成(RAG)等高级功能,且具备多用户管理与权限控制能力。无论是希望保护敏感数据的企业开发者、进行算法实验的研究人员,还是想要在个人电脑上体验最新 AI 技术的极客玩家,都能通过 LocalAI 获
bark
Bark 是由 Suno 推出的开源生成式音频模型,能够根据文本提示创造出高度逼真的多语言语音、音乐、背景噪音及简单音效。与传统仅能朗读文字的语音合成工具不同,Bark 基于 Transformer 架构,不仅能模拟说话,还能生成笑声、叹息、哭泣等非语言声音,甚至能处理带有情感色彩和语气停顿的复杂文本,极大地丰富了音频表达的可能性。 它主要解决了传统语音合成声音机械、缺乏情感以及无法生成非语音类音效的痛点,让创作者能通过简单的文字描述获得生动自然的音频素材。无论是需要为视频配音的内容创作者、探索多模态生成的研究人员,还是希望快速原型设计的开发者,都能从中受益。普通用户也可通过集成的演示页面轻松体验其神奇效果。 技术亮点方面,Bark 支持商业使用(MIT 许可),并在近期更新中实现了显著的推理速度提升,同时提供了适配低显存 GPU 的版本,降低了使用门槛。此外,社区还建立了丰富的提示词库,帮助用户更好地驾驭模型生成特定风格的声音。只需几行 Python 代码,即可将创意文本转化为高质量音频,是连接文字与声音世界的强大桥梁。
airi
airi 是一款开源的本地化 AI 伴侣项目,旨在将虚拟角色(如“二次元老婆”或赛博生命)带入用户的现实世界。它的核心目标是复刻并超越知名 AI 主播 Neuro-sama 的能力,让用户能够拥有完全自主掌控、可私有化部署的智能伙伴。 airi 主要解决了用户对高度定制化、具备情感交互能力且数据隐私安全的 AI 角色的需求。不同于依赖云端服务的通用助手,airi 允许用户在本地运行,不仅保护了对话隐私,还赋予了用户定义角色性格与灵魂的自由。它支持实时语音聊天,甚至能直接参与《我的世界》(Minecraft)和《异星工厂》(Factorio)等游戏,实现了从单纯对话到共同娱乐的跨越。 这款工具非常适合喜爱虚拟角色的普通用户、希望搭建个性化 AI 陪伴的技术爱好者,以及研究多模态交互的开发者。其独特的技术亮点在于跨平台支持(涵盖 Web、macOS 和 Windows)以及强大的游戏交互能力,让 AI 不仅能“说”,还能“玩”。通过容器化的灵魂设计,airi 为每个人创造专属数字生命提供了可能,让虚拟陪伴变得更加真实且触手可及。
MockingBird
MockingBird 是一款开源的实时语音克隆工具,旨在让用户仅需 5 秒的参考音频,即可快速合成任意内容的语音,并实现逼真的音色复刻。它有效解决了传统语音合成技术中数据采集成本高、训练周期长以及难以实时生成的痛点,让个性化语音生成变得触手可及。 这款工具特别适合开发者、AI 研究人员以及对语音技术感兴趣的技术爱好者使用。无论是用于构建交互式语音应用、进行声学模型研究,还是制作创意内容,MockingBird 都能提供强大的支持。普通用户若具备基础的编程环境配置能力,也可通过其提供的 Web 服务或工具箱体验前沿的变声效果。 在技术亮点方面,MockingBird 基于 PyTorch 框架,不仅完美支持中文普通话及多种主流数据集,还实现了跨平台运行,兼容 Windows、Linux 乃至 M1 架构的 macOS。其独特的架构设计允许复用预训练的编码器与声码器,只需微调合成器即可获得出色效果,大幅降低了部署门槛。此外,项目内置了现成的 Web 服务器功能,方便用户通过远程调用快速集成到自己的应用中。尽管原作者已转向云端优化版本,但 MockingBird 作为经典的本地部署方案