ComfyUI-Index-TTS
ComfyUI-Index-TTS 是一款专为 ComfyUI 设计的高质量文本转语音(TTS)扩展节点,基于先进的 IndexTTS 模型打造。它核心解决了传统 TTS 工具在情感表达和声音复刻上的不足,支持中英文双语输入,并能通过参考音频精准还原说话人的音色特征,甚至能细致地复刻情绪状态。
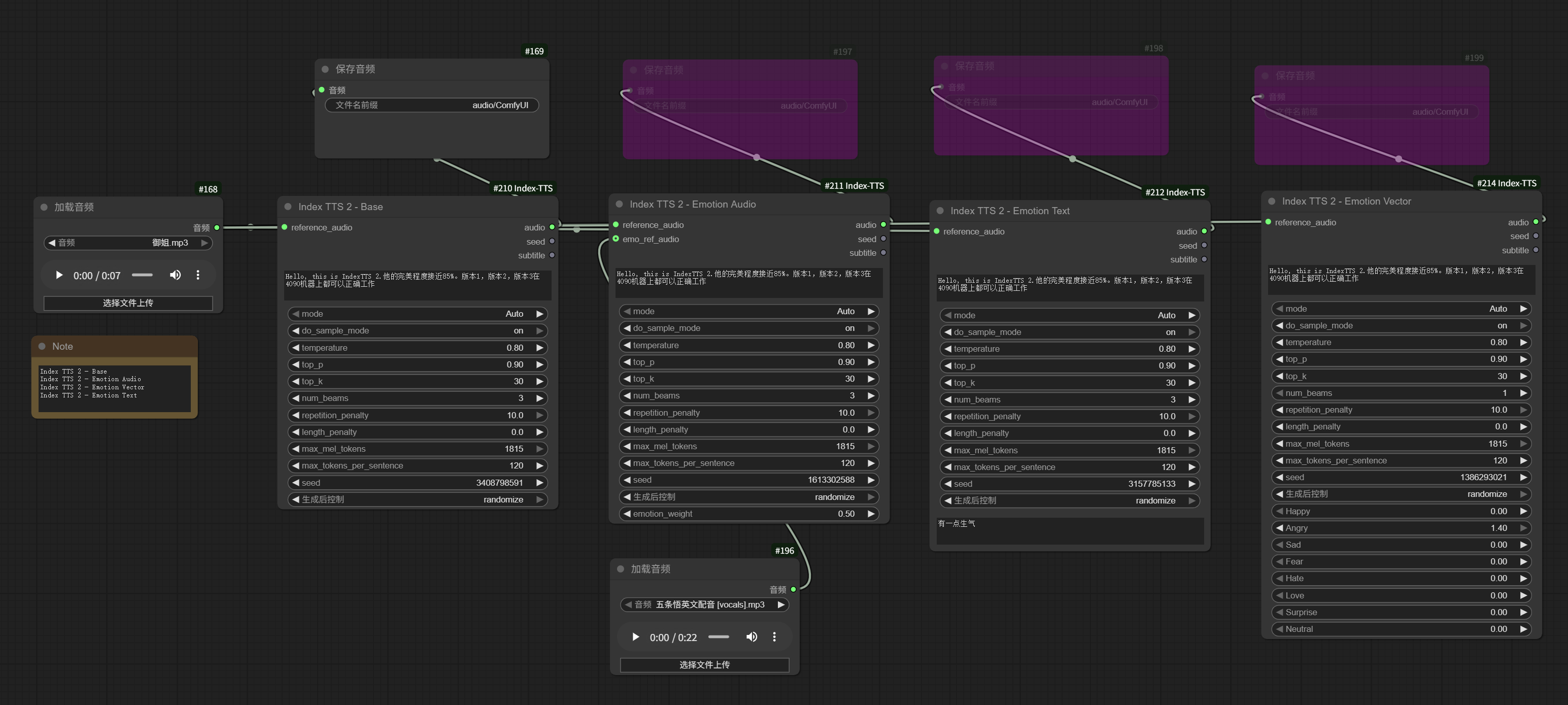
该工具最大的技术亮点在于其灵活的工作流设计。最新版本将功能拆分为基础合成、参考音频情绪复刻、情绪向量控制及文本情绪描述四个独立节点,用户可根据需求自由组合,实现从“读稿机器”到“富有情感的真人演绎”的跨越。此外,它深度集成了 Qwen 情绪分类、CampPlus 说话人嵌入及 BigVGAN 声码器等前沿技术,确保了生成语音的自然度与表现力。
ComfyUI-Index-TTS 非常适合希望在可视化工作流中构建复杂语音应用的开发者、需要定制化配音方案的内容创作者,以及研究语音合成技术的专业人员。对于熟悉 ComfyUI 操作的用户而言,它能轻松融入现有的自动化流程,为视频制作、有声书生成或虚拟角色对话提供极具表现力的声音解决方案。需要注意的是,使用前需按指引配置多个模型文件,建议具备一定技术动手能力的用户尝试。
使用场景
一位独立游戏开发者正在为一款悬疑视觉小说制作多结局配音,需要让不同性格的 NPC 用同一声音模型演绎出恐惧、愤怒或冷静等多种情绪。
没有 ComfyUI-Index-TTS 时
- 声音特征割裂:传统 TTS 工具难以在保持角色音色一致的前提下切换情绪,导致同一个角色在不同剧情中听起来像不同的人。
- 工作流断裂:音频生成与图像、逻辑节点分离,开发者需手动导出再导入音频文件,无法在 ComfyUI 中实现“文生图 + 文生音”的一体化自动化流程。
- 中文表现生硬:通用模型对中文语调处理机械,缺乏抑扬顿挫,难以还原悬疑氛围所需的细腻情感张力。
- 复刻成本高昂:若想模仿特定参考音频(如导演的小样),往往需要昂贵的定制训练或复杂的命令行操作,门槛极高。
使用 ComfyUI-Index-TTS 后
- 精准情绪复刻:利用
Index TTS 2 - Emotion Audio节点,直接上传一段参考音频,即可让模型完美复刻该声音的情绪色彩,同时锁定角色音色不变。 - 全链路自动化:作为原生自定义节点,它能与 ComfyUI 的工作流无缝串联,实现从剧本文本到最终音视频输出的端到端自动生成,无需人工干预文件流转。
- 中英双语自然:基于 IndexTTS-2 模型,无论是中文对话还是英文旁白,都能生成极具感染力且发音自然的语音,显著提升叙事沉浸感。
- 灵活组合控制:开发者可根据需求自由组合基础合成、情绪向量或文本情绪节点,精细调控每一句台词的表现力,极大降低了高质量配音的制作门槛。
ComfyUI-Index-TTS 通过将高保真语音克隆深度融入可视化工作流,让单人开发者也能轻松打造出电影级的情感化角色配音。
运行环境要求
- Windows
- Linux
- macOS
- 需要 NVIDIA GPU (推荐),支持 Apple Silicon MPS (需测试反馈)
- 显存需求:12GB+ 适合日常使用(开启缓存控制可优化),未明确最低显存但暗示低显存需频繁清理缓存
- CUDA 版本未明确说明
未说明
快速开始
免责声明
本项目基于B站开源项目进行二次开发,由本人对项目进行了ComfyUI的实现,并进行了部分功能优化与调整与进阶功能的开发。然而,需要强调的是,本项目严禁用于任何非法目的以及与侵犯版权相关的任何行为!本项目仅用于开源社区内的交流与学习,以促进技术共享与创新,旨在为开发者提供有益的参考和学习资源。
在此郑重声明,本项目所有个人使用行为与开发者本人及本项目本身均无任何关联。开发者对于项目使用者的行为不承担任何责任,使用者应自行承担使用过程中可能产生的所有风险和法律责任。请广大使用者在遵守法律法规及相关规定的前提下,合理、合法地使用本项目,维护开源社区的良好秩序与健康发展。
感谢您的理解与支持!
ComfyUI-Index-TTS
使用IndexTTS模型在ComfyUI中实现高质量文本到语音转换的自定义节点。支持中文和英文文本,可以基于参考音频复刻声音特征。
最新更新(重要)
本项目已新增对 IndexTTS-2(简称 TTS2)的支持,并将功能拆分为四个核心节点,方便在 ComfyUI 中按需组合: 基础工作流已更新,详见./workflow/TTS2.json. 会有一些BUG,欢迎反馈。功能基本复刻了原版IndexTTS,关于功能建议欢迎交流。
- Index TTS 2 - Base(基础合成)
- Index TTS 2 - Emotion Audio(基于参考音频情绪复刻)
- Index TTS 2 - Emotion Vector(基于情绪向量复刻)
- Index TTS 2 - Emotion Text(基于情绪文本复刻)
TTS2 模型下载与放置位置(全部放到 ./ComfyUI/models/IndexTTS-2/):
基础模型
- 页面:TTS2
- 放置:
.\ComfyUI\models\IndexTTS-2
qwen 模型(情绪分类)
- 页面:IndexTTS-2/qwen0.6bemo4-merge
- 放置:
.\ComfyUI\models\IndexTTS-2\qwen0.6bemo4-merge\
semantic codec(MaskGCT 语义编码器)
- 页面:https://huggingface.co/amphion/MaskGCT/tree/main/semantic_codec
- 直链:https://huggingface.co/amphion/MaskGCT/resolve/main/semantic_codec/model.safetensors
- 放置:
.\ComfyUI\models\IndexTTS-2\semantic_codec\model.safetensors
CampPlus 说话人嵌入
- 页面:https://huggingface.co/funasr/campplus
- 直链:https://huggingface.co/funasr/campplus/resolve/main/campplus_cn_common.bin
- 放置:
.\ComfyUI\models\IndexTTS-2\campplus_cn_common.bin
Wav2Vec2Bert 特征提取器(facebook/w2v-bert-2.0)
- 页面:https://huggingface.co/facebook/w2v-bert-2.0/tree/main
- 放置(离线优先):
.\ComfyUI\models\IndexTTS-2\w2v-bert-2.0\(整个仓库文件夹,包含config.json、model.safetensors、preprocessor_config.json等) - 若未放置本地文件夹,将自动下载到 HF 缓存:
.\ComfyUI\models\IndexTTS-2\hf_cache\
BigVGAN 声码器
- 名称读取自
config.yaml的vocoder.name(示例:nvidia/bigvgan_v2_22khz_80band_256x) - 建议:提前将对应模型完整缓存到
.\ComfyUI\models\IndexTTS-2\bigvgan\内
- 名称读取自
其他本地直读文件(需与
config.yaml一致):gpt.pth(cfg.gpt_checkpoint)s2mel.pth(cfg.s2mel_checkpoint)bpe.model(cfg.dataset.bpe_model)wav2vec2bert_stats.pt(cfg.w2v_stat)- 语义编码配置(如
repcodec.json,若需要,cfg.semantic_codec) emo_matrix(例如feat2.pt)spk_matrix(例如feat1.pt)qwen0.6bemo4-merge\(cfg.qwen_emo_path指定目录)
示例目录结构(部分):
ComfyUI/models/IndexTTS-2/
│ .gitattributes
│ bpe.model
│ campplus_cn_common.bin
│ config.yaml
│ feat1.pt
│ feat2.pt
│ gpt.pth
│ README.md
│ s2mel.pth
│ wav2vec2bert_stats.pt
│
├─bigvgan
│ └─bigvgan_v2_22khz_80band_256x
│ .gitattributes
│ .gitignore
│ activations.py
│ bigvgan.py
│ bigvgan_discriminator_optimizer.pt
│ bigvgan_discriminator_optimizer_3msteps.pt
│ bigvgan_generator.pt
│ bigvgan_generator_3msteps.pt
│ config.json
│ env.py
│ LICENSE
│ meldataset.py
│ README.md
│ utils.py
│
├─hf_cache
├─qwen0.6bemo4-merge
│ added_tokens.json
│ chat_template.jinja
│ config.json
│ generation_config.json
│ merges.txt
│ model.safetensors
│ Modelfile
│ special_tokens_map.json
│ tokenizer.json
│ tokenizer_config.json
│ vocab.json
│
├─semantic_codec
│ model.safetensors
│
└─w2v-bert-2.0
.gitattributes
config.json
conformer_shaw.pt
model.safetensors
preprocessor_config.json
README.md
提示:若你只使用旧版 IndexTTS/IndexTTS-1.5,可忽略上述 TTS2 模型放置步骤。
一键下载脚本(推荐)
- 脚本位置:
ComfyUI/custom_nodes/ComfyUI-Index-TTS/TTS2_download.py - 作用:自动下载并放置上述所有 TTS2 所需模型文件,支持断点续传、国内镜像(HF_ENDPOINT=hf-mirror.com)、本地缓存(HF_HOME=./ComfyUI/models/IndexTTS-2/hf_cache)。
- 脚本使用时,可能会存在国内镜像设置不成功的问题,可直接在控制台设置环境变量:Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com",linuxexport HF_ENDPOINT=https://hf-mirror.com
python .\ComfyUI\custom_nodes\ComfyUI-Index-TTS\TTS2_download.py
- 运行后根据提示选择 2 使用国内镜像(默认)或 1 使用官方源。
- 依赖:
huggingface_hub(必须);可选加速:hf_transfer、hf_xet。
python -m pip install -U huggingface_hub
# 可选加速:
python -m pip install -U hf_transfer
python -m pip install -U "huggingface_hub[hf_xet]"
显存/缓存控制(新功能)
新增节点:
Index TTS 2 - Cache Control- 输出:
cache_control(类型:DICT),包含{"keep_cached": true/false}。 - 用法:将该输出连到以下任一/多个节点的
cache_control输入上:Index TTS 2 - BaseIndex TTS 2 - Emotion AudioIndex TTS 2 - Emotion VectorIndex TTS 2 - Emotion Text
- 输出:
行为说明:
- 关闭(默认):本次推理结束后自动卸载 TTS2 模型并清理 CUDA 缓存,降低显存驻留峰值,适合 12GB 显卡日常使用。
- 开启:保留已加载的权重(尽量驻留,视环境/模式),连续多次生成更快,但显存占用更高。调参批量测试时可临时打开,用完关闭。
功能特点
- 支持中文和英文文本合成
- 基于参考音频复刻声音特征(变声功能)
- 支持调节语速(原版不支持后处理实现效果会有一点折损)
- 多种音频合成参数控制
- Windows兼容(无需额外依赖)
废话两句
演示案例
以下是一些实际使用效果演示:
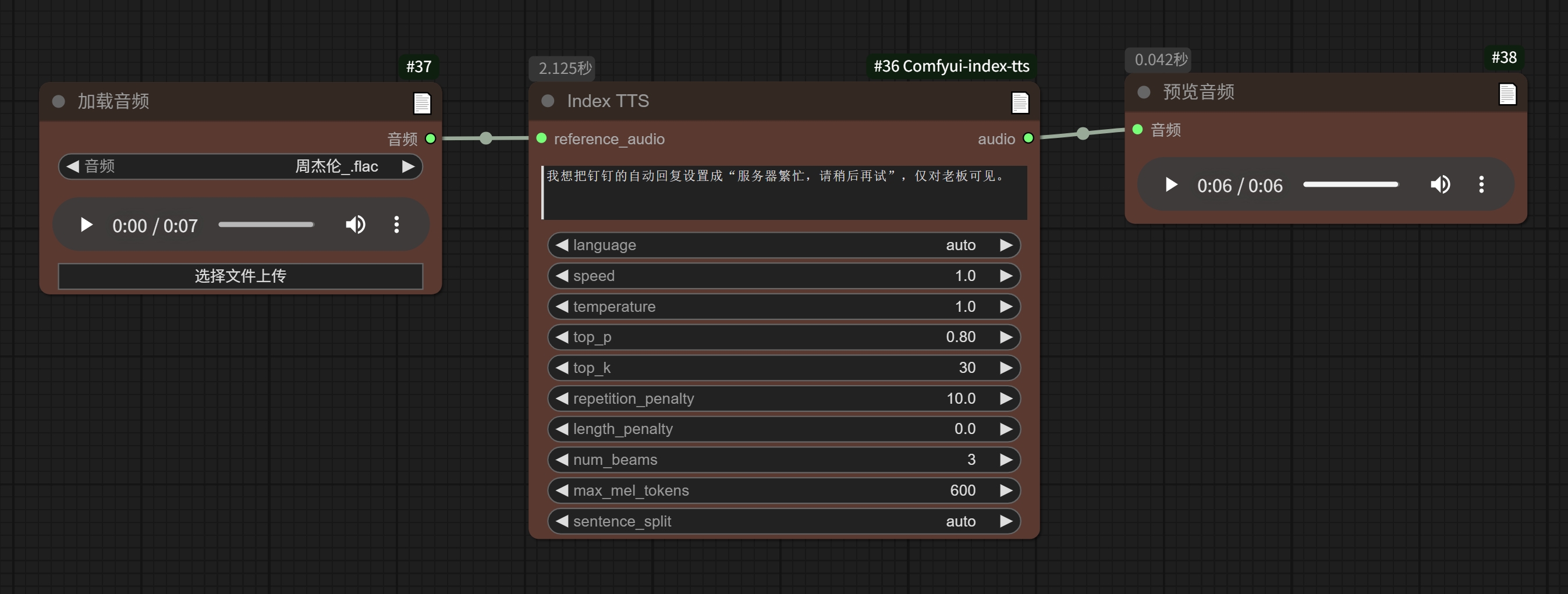
| 参考音频 | 输入文本 | 推理结果 |
|---|---|---|
| 我想把钉钉的自动回复设置成"服务器繁忙,请稍后再试",仅对老板可见。 我想把钉钉的自动回复设置成"服务器繁忙,请稍后再试",仅对老板可见。 | ||
| 我想把钉钉的自动回复设置成"服务器繁忙,请稍后再试",仅对老板可见。 |
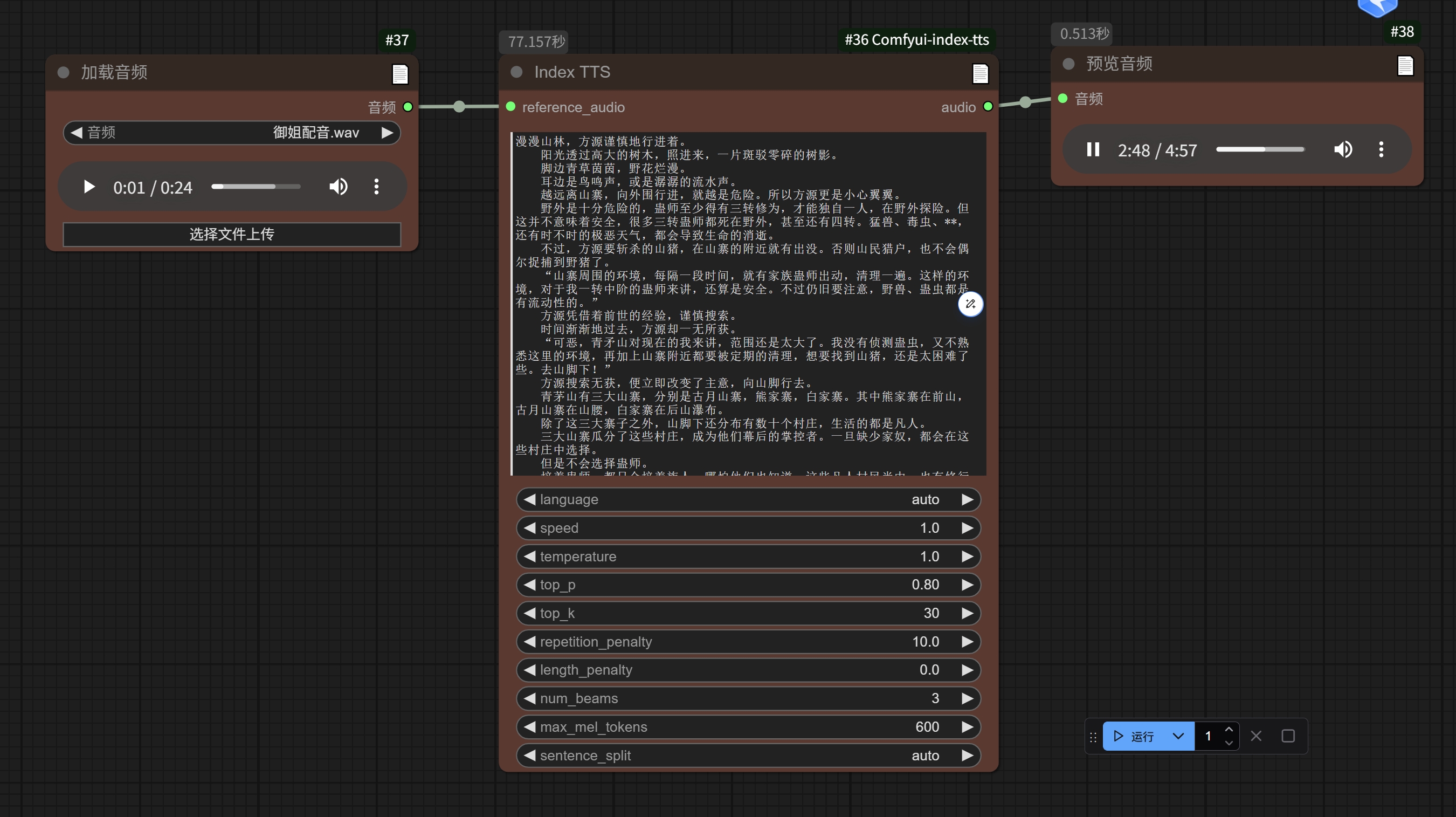
- 长文本测试:
- 多角色小说测试:
更新日志
2025年12月18日
- 修复多个社区反馈问题:
- 老节点
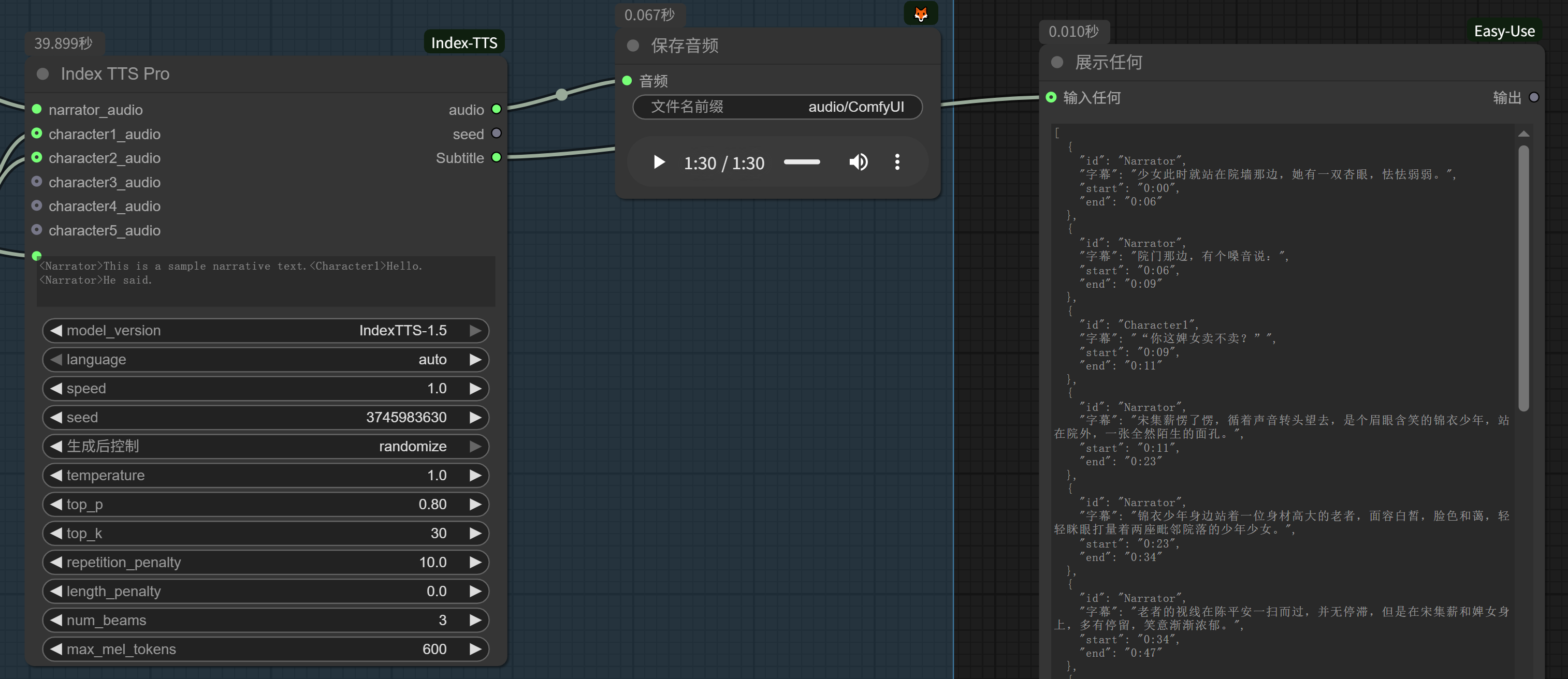
Index TTS现已支持 IndexTTS-2 模型 (#121) - 新增
Index TTS 2 Pro (小说多角色)节点,支持 TTS 2.0 多角色小说朗读 (#111) - 修复 tensor 尺寸不匹配随机报错问题 (#122)
- 支持 w2v-bert-2.0 本地离线加载,无需联网 (#72/#113)
- 适配 transformers 4.50+ 版本 API 变化 (#117)
- 更新 safetensors 版本要求 (#123)
- 新增 README 常见问题解答 (FAQ) 部分
- 老节点
2025年6月24日
- pro节点新增了对于字幕的json输出,感谢@qy8502提供的玩法思路
2025年6月5日
- 改进了小说文本解析器(Novel Text Parser)的功能
- 增加了对预格式化文本的检测和处理
- 优化了对话检测和角色识别算法
- 改进了中文角色名称的识别
- 支持引号中的对话自动识别
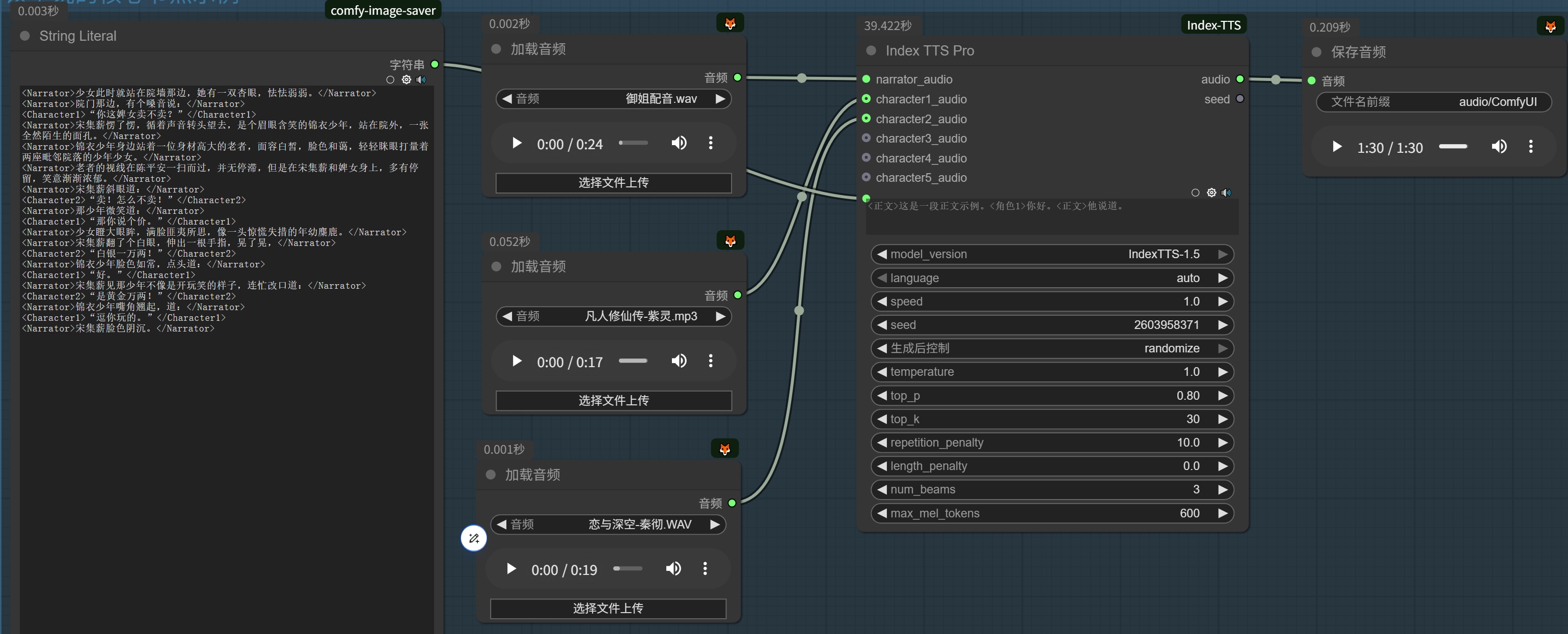
多角色小说文本解析
本项目包含一个专门用于解析小说文本的节点(Novel Text Structure Node),可以将普通小说文本解析为多角色对话结构,以便生成更加自然的多声音TTS效果。
使用说明
- 节点会尝试自动识别小说中的角色对话和旁白部分
- 对话部分会标记为
<CharacterX>形式(X为数字,最多支持5个角色) - 旁白部分会标记为
<Narrator> - 解析后的文本可直接用于多声音TTS生成
局限性
- 当前解析算法并不完美,复杂的小说结构可能导致错误的角色识别
- 对于重要文本,建议使用LLM(如GPT等)手动拆分文本为以下格式:
<Narrator>少女此时就站在院墙那边,她有一双杏眼,怯怯弱弱。</Narrator>
<Narrator>院门那边,有个嗓音说:</Narrator>
<Character1>"你这婢女卖不卖?"</Character1>
<Narrator>宋集薪愣了愣,循着声音转头望去,是个眉眼含笑的锦衣少年,站在院外,一张全然陌生的面孔。</Narrator>
<Narrator>锦衣少年身边站着一位身材高大的老者,面容白皙,脸色和蔼,轻轻眯眼打量着两座毗邻院落的少年少女。</Narrator>
<Narrator>老者的视线在陈平安一扫而过,并无停滞,但是在宋集薪和婢女身上,多有停留,笑意渐渐浓郁。</Narrator>
<Narrator>宋集薪斜眼道:</Narrator>
<Character2>"卖!怎么不卖!"</Character2>
<Narrator>那少年微笑道:</Narrator>
<Character1>"那你说个价。"</Character1>
<Narrator>少女瞪大眼眸,满脸匪夷所思,像一头惊慌失措的年幼麋鹿。</Narrator>
<Narrator>宋集薪翻了个白眼,伸出一根手指,晃了晃,</Narrator>
<Character2>"白银一万两!"</Character2>
<Narrator>锦衣少年脸色如常,点头道:</Narrator>
<Character1>"好。"</Character1>
<Narrator>宋集薪见那少年不像是开玩笑的样子,连忙改口道:</Narrator>
<Character2>"是黄金万两!"</Character2>
<Narrator>锦衣少年嘴角翘起,道:</Narrator>
<Character1>"逗你玩的。"</Character1>
<Narrator>宋集薪脸色阴沉。</Narrator>
示例用法
- 将小说文本输入到 Novel Text Structure 节点
- 连接输出到 Index TTS Pro 节点
- 设置不同角色的语音
- 运行工作流生成多声音小说朗读
- 实在不会看我最新增加的工作流
- 如果你想在comfyui中一站式完成这个,我推荐你使用各类的llm节点,比如kimichat
- 我也提供了一段llm提示词模板,你可以在llm_prompt模板.txt中看到他
2025年5月18日
- 优化了长期以来transformers库4.50+版本的API变化与原始IndexTTS模型代码不兼容导致的生成报错问题
2025年5月16日
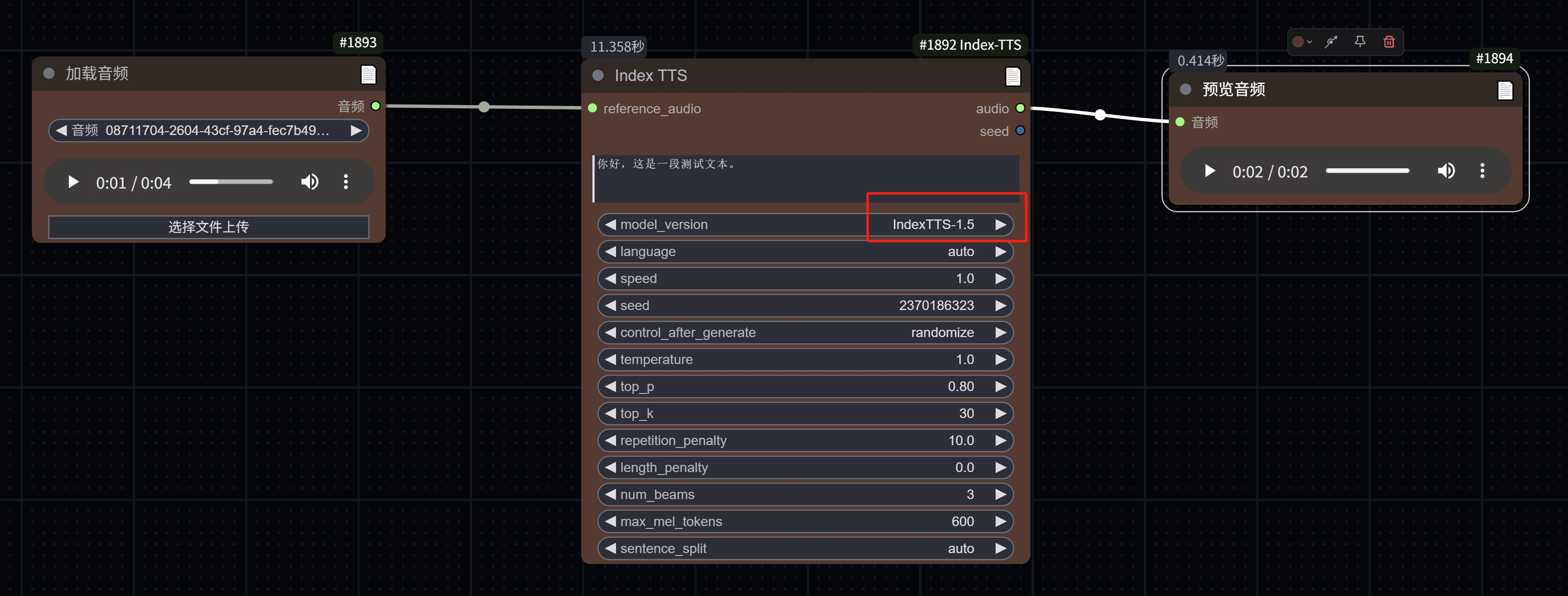
新增对IndexTTS-1.5模型的支持
- 现在可以在UI中通过下拉菜单切换不同版本的模型
- 支持原始的Index-TTS和新的IndexTTS-1.5模型
- 切换模型时会自动加载相应版本,无需重启ComfyUI
2025年5月11日
- 增加了seed功能,现在linux也可以重复执行抽卡了
- 增加了对 Apple Silicon MPS 设备的检测(仍需测试反馈~)
2025年4月23日
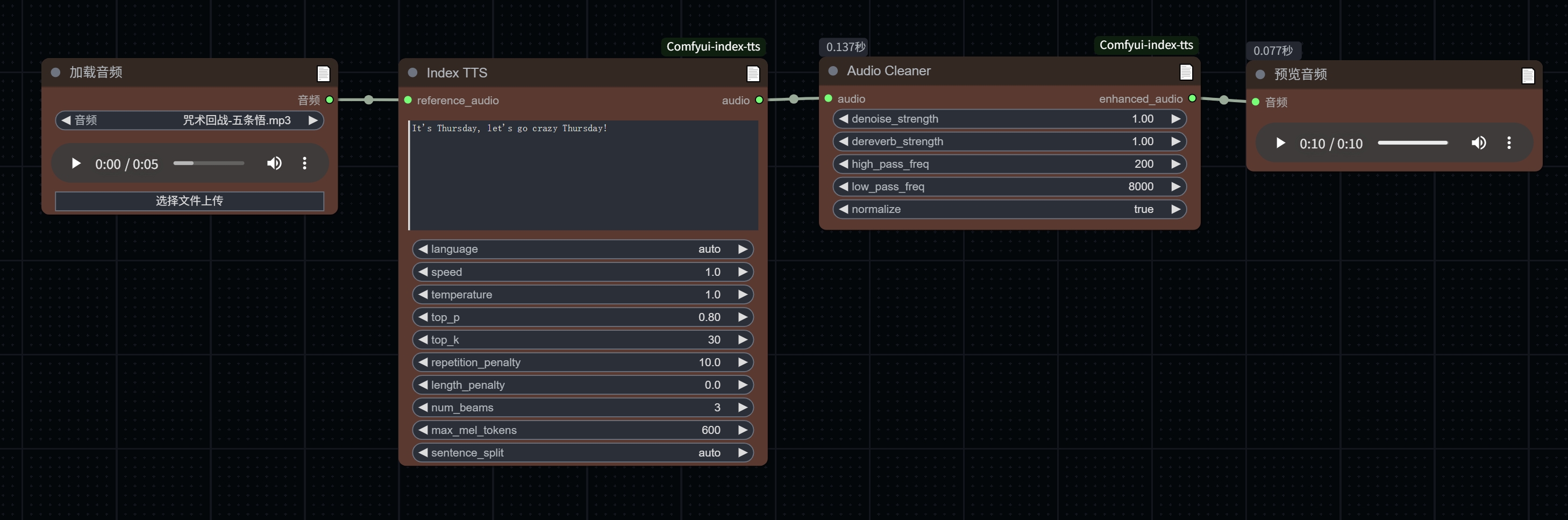
新增 Audio Cleaner 节点,用于处理TTS输出音频中的混响和杂音问题
- 该节点可以连接在 Index TTS 节点之后,优化生成音频的质量
- 主要功能:去除混响、降噪、频率滤波和音频归一化
- 适用于处理有杂音或混响问题的TTS输出
修复了对于transformers版本强依赖的问题
Audio Cleaner 参数说明
必需参数::
- audio: 输入音频(通常为 Index TTS 节点的输出)
- denoise_strength: 降噪强度(0.1-1.0,默认0.5)
- 值越大,降噪效果越强,但可能影响语音自然度
- dereverb_strength: 去混响强度(0.0-1.0,默认0.7)
- 值越大,去混响效果越强,适合处理在回声环境下录制的参考音频
可选参数::
- high_pass_freq: 高通滤波器频率(20-500Hz,默认100Hz)
- 用于过滤低频噪音,如环境嗡嗡声
- low_pass_freq: 低通滤波器频率(1000-16000Hz,默认8000Hz)
- 用于过滤高频噪音
- normalize: 是否归一化音频("true"或"false",默认"true")
- 开启可使音量更均衡
使用建议
- 对于有明显混响的音频,将
dereverb_strength设置为 0.7-0.9 - 对于有背景噪音的音频,将
denoise_strength设置为 0.5-0.8 - 如果处理后音频听起来不自然,尝试减小
dereverb_strength和denoise_strength - 高通和低通滤波器可以微调以获得最佳人声效果
2025年4月25日
- 优化了阿拉伯数字的发音判断问题;可以参考这个case使用:“4 0 9 0”会发音四零九零,“4090”会发音四千零九十;
2025年4月26日
- 优化英文逗号导致吞字的问题;
2025年4月29日
- 修正了语言模式切换en的时候4090依然读中文的问题,auto现在会按照中英文占比确定阿拉伯数字读法
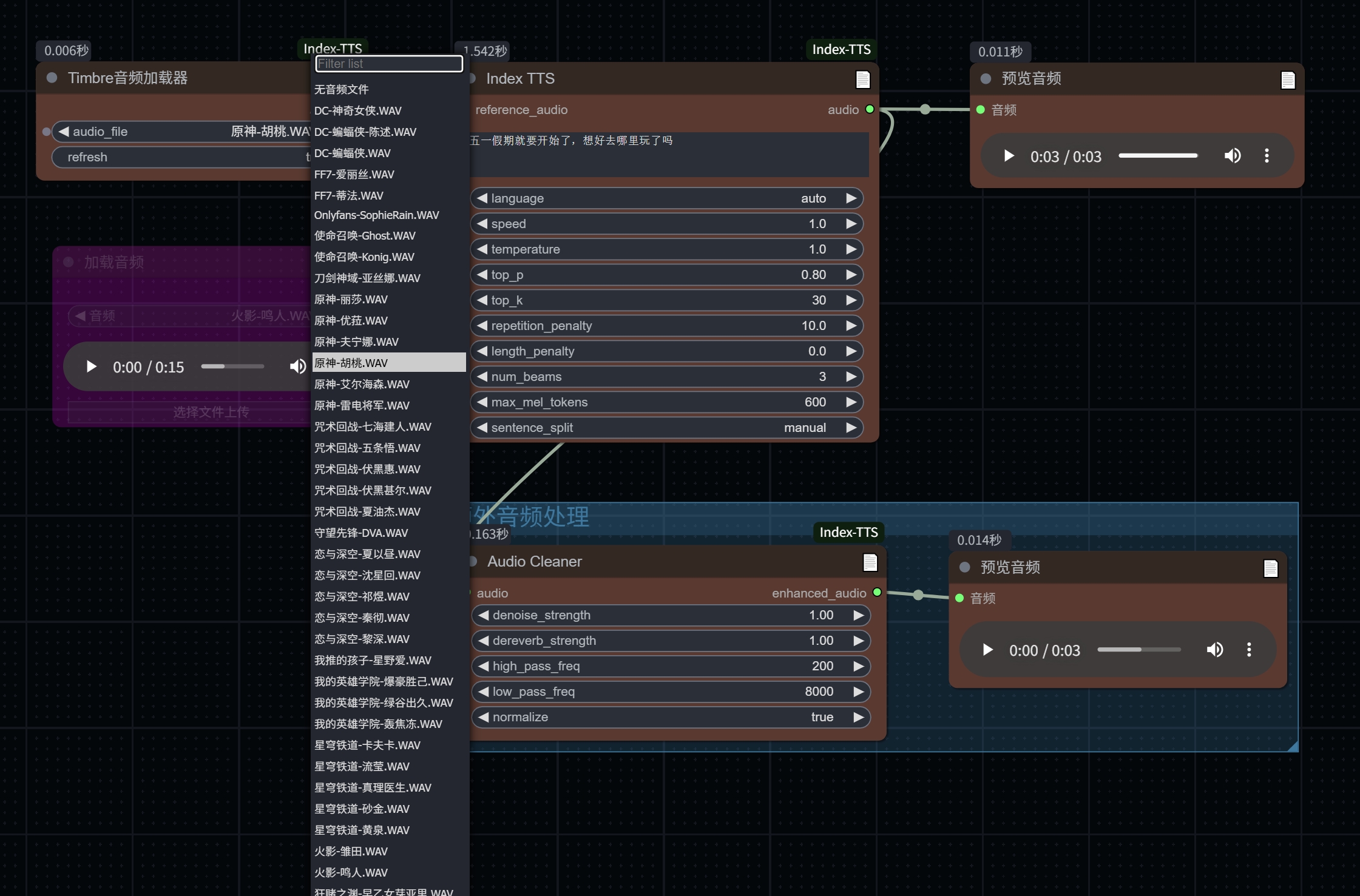
- 新增了从列表读取音频的方法,同时新增了一些音色音频供大家玩耍;你可以将自己喜欢的音频放入 ComfyUI-Index-TTS\TimbreModel 里,当然也很鼓励你能把好玩的声音分享出来。
- 示例用法如图:
安装
安装节点
将此代码库克隆或下载到ComfyUI的
custom_nodes目录:cd ComfyUI/custom_nodes git clone https://github.com/chenpipi0807/ComfyUI-Index-TTS.git安装依赖: 安装依赖:
cd ComfyUI-Index-TTS .\python_embeded\python.exe -m pip install -r requirements.txt git pull # 更新很频繁你可能需要
下载模型
原始版本 (Index-TTS)
从Hugging Face或者魔搭下载IndexTTS模型文件
将模型文件放置在
ComfyUI/models/Index-TTS目录中(如果目录不存在,请创建)模型文件夹结构:
ComfyUI/models/Index-TTS/ ├── .gitattributes ├── bigvgan_discriminator.pth ├── bigvgan_generator.pth ├── bpe.model ├── config.yaml ├── configuration.json ├── dvae.pth ├── gpt.pth ├── README.md └── unigram_12000.vocab确保所有文件都已完整下载,特别是较大的模型文件如
bigvgan_discriminator.pth(1.6GB)和gpt.pth(696MB)。
新版本 (IndexTTS-1.5)
从Hugging Face下载IndexTTS-1.5模型文件
将模型文件放置在
ComfyUI/models/IndexTTS-1.5目录中(如果目录不存在,请创建)模型文件夹结构与Index-TTS基本相同,但文件大小和内容会有所不同:
ComfyUI/models/IndexTTS-1.5/ ├── .gitattributes ├── bigvgan_discriminator.pth ├── bigvgan_generator.pth ├── bpe.model ├── config.yaml ├── configuration.json ├── dvae.pth ├── gpt.pth ├── README.md └── unigram_12000.vocab
使用方法
- 在ComfyUI中,找到并添加
Index TTS节点 - 连接参考音频输入(AUDIO类型)
- 输入要转换为语音的文本
- 调整参数(语言、语速等)
- 运行工作流获取生成的语音输出
示例工作流
项目包含一个基础工作流示例,位于workflow/workflow.json,您可以在ComfyUI中通过导入此文件来快速开始使用。
参数说明
必需参数
- text: 要转换为语音的文本(支持中英文)
- reference_audio: 参考音频,模型会复刻其声音特征
- model_version: 模型版本选择,可选项:
Index-TTS: 原始模型版本(默认)IndexTTS-1.5: 新版本模型
- language: 文本语言选择,可选项:
auto: 自动检测语言(默认)zh: 强制使用中文模式en: 强制使用英文模式
- speed: 语速因子(0.5~2.0,默认1.0)
可选参数
以下参数适用于高级用户,用于调整语音生成质量和特性:
- temperature (默认1.0): 控制生成随机性,较高的值增加多样性但可能降低稳定性
- top_p (默认0.8): 采样时考虑的概率质量,降低可获得更准确但可能不够自然的发音
- top_k (默认30): 采样时考虑的候选项数量
- repetition_penalty (默认10.0): 重复内容的惩罚系数
- length_penalty (默认0.0): 生成内容长度的调节因子
- num_beams (默认3): 束搜索的宽度,增加可提高质量但降低速度
- max_mel_tokens (默认600): 最大音频token数量
- sentence_split (默认auto): 句子拆分方式
音色优化建议
要提高音色相似度:
- 使用高质量的参考音频(清晰、无噪音)
- 尝试调整
temperature参数(0.7-0.9范围内效果较好) - 增加
repetition_penalty(10.0-12.0)可以提高音色一致性 - 对于长文本,确保
max_mel_tokens足够大
故障排除
常见问题解答 (FAQ)
Q: w2v-bert-2.0 加载失败 / 401 Unauthorized 错误 (#72/#113)
问题: 运行时提示 401 Client Error: Unauthorized for url: https://huggingface.co/facebook/w2v-bert-2.0。
解决方案:
- 下载 w2v-bert-2.0 模型到本地:从 HuggingFace 下载所有文件。
- 放置到
ComfyUI/models/IndexTTS-2/w2v-bert-2.0/目录。 - 确保目录包含
config.json、model.safetensors、preprocessor_config.json等文件。 - 重启 ComfyUI,插件会自动使用本地模型,无需联网。
Q: transformers 版本不兼容 (#117)
问题: 使用 transformers>=4.57.1 版本后 TTS2 无法使用。
解决方案:
- 推荐使用
transformers==4.52.1或transformers==4.54.1。 - 安装命令:
pip install transformers==4.52.1。 - 本插件已适配 transformers 4.50+ 版本的 API 变化。
Q: SafeTensorFile 没有 get_slice 属性 (#123)
问题: AttributeError: 'SafeTensorFile' object has no attribute 'get_slice'。
解决方案:
- 升级 safetensors 到最新版本:
pip install safetensors --upgrade。 - 确保版本 >= 0.4.3。
Q: tensor 尺寸不匹配随机报错 (#122)
问题: 随机出现 RuntimeError: Sizes of tensors must match except in dimension 1。
解决方案:
- 此问题已在最新版本中修复。
- 请更新插件到最新版本:
git pull。
Q: Python 3.13 / pynini 安装失败 (#125)
问题: Ubuntu 24 + Python 3.13 环境下 pynini 编译失败。
解决方案:
- pynini 目前不支持 Python 3.13。
- 建议使用 Python 3.10 或 3.11。
- Windows 用户不需要 pynini,可以忽略此错误。
Q: 老节点不支持 IndexTTS-2 模型 (#121)
解决方案:
- 最新版本已支持!在
Index TTS节点的model_version下拉菜单中选择IndexTTS-2即可。 - 也可以使用新的
Index TTS 2 Pro (小说多角色)节点进行多角色小说朗读。
Q: TTS 2.0 读小说功能 (#111)
解决方案:
- 新增了
Index TTS 2 Pro (小说多角色)节点。 - 支持多角色语音合成,可配合
小说文本结构化节点使用。 - 支持最多 5 个角色 + 旁白。
其他常见问题
- 如果出现“模型加载失败”,检查模型文件是否完整且放置在正确目录。
- 对于Windows用户,无需额外安装特殊依赖,节点已优化。
- 如果显示CUDA错误,尝试重启ComfyUI或减少
num_beams值。 - 如果你是pytorch2.7运行报错,短期无法适配,请尝试降级方案(.\python_embeded\python.exe -m pip install transformers==4.48.3)。
致谢
- 基于原始IndexTTS模型。
- 感谢ComfyUI社区的支持。
- 感谢使用!
许可证
请参考原始IndexTTS项目许可证。
常见问题
相似工具推荐
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
codex
Codex 是 OpenAI 推出的一款轻量级编程智能体,专为在终端环境中高效运行而设计。它允许开发者直接在命令行界面与 AI 交互,完成代码生成、调试、重构及项目维护等任务,无需频繁切换至浏览器或集成开发环境,从而显著提升了编码流程的连贯性与专注度。 这款工具主要解决了传统 AI 辅助编程中上下文割裂的问题。通过将智能体本地化运行,Codex 能够更紧密地结合当前工作目录的文件结构,提供更具针对性的代码建议,同时支持以自然语言指令驱动复杂的开发操作,让“对话即编码”成为现实。 Codex 非常适合习惯使用命令行的软件工程师、全栈开发者以及技术研究人员。对于追求极致效率、偏好键盘操作胜过图形界面的极客用户而言,它更是理想的结对编程伙伴。 其独特亮点在于灵活的部署方式:既可作为全局命令行工具通过 npm 或 Homebrew 一键安装,也能无缝对接现有的 ChatGPT 订阅计划(如 Plus 或 Pro),直接复用账户权益。此外,它还提供了从纯文本终端到桌面应用的多形态体验,并支持基于 API 密钥的深度定制,充分满足不同场景下的开发需求。
gstack
gstack 是 Y Combinator CEO Garry Tan 亲自开源的一套 AI 工程化配置,旨在将 Claude Code 升级为你的虚拟工程团队。面对单人开发难以兼顾产品战略、架构设计、代码审查及质量测试的挑战,gstack 提供了一套标准化解决方案,帮助开发者实现堪比二十人团队的高效产出。 这套配置特别适合希望提升交付效率的创始人、技术负责人,以及初次尝试 Claude Code 的开发者。gstack 的核心亮点在于内置了 15 个具有明确职责的 AI 角色工具,涵盖 CEO、设计师、工程经理、QA 等职能。用户只需通过简单的斜杠命令(如 `/review` 进行代码审查、`/qa` 执行测试、`/plan-ceo-review` 规划功能),即可自动化处理从需求分析到部署上线的全链路任务。 所有操作基于 Markdown 和斜杠命令,无需复杂配置,完全免费且遵循 MIT 协议。gstack 不仅是一套工具集,更是一种现代化的软件工厂实践,让单人开发者也能拥有严谨的工程流程。
openai-cookbook
openai-cookbook 是 OpenAI 官方提供的一套实用代码示例与指南合集,旨在帮助开发者快速上手并掌握 OpenAI API 的核心用法。面对大模型应用中常见的提示词工程、函数调用、数据嵌入及复杂任务编排等挑战,新手往往难以找到标准化的实现路径。openai-cookbook 通过提供经过验证的代码片段和详细教程,有效解决了“如何从零开始构建应用”以及“如何最佳实践特定功能”的痛点。 这套资源主要面向软件开发者和 AI 技术研究人员,同时也适合希望深入理解大模型能力的技术爱好者。虽然示例代码主要以 Python 编写,但其背后的设计思路和技术逻辑具有通用性,可轻松迁移至其他编程语言。其独特亮点在于内容紧跟官方最新特性更新,覆盖了从基础文本生成到高级代理(Agent)构建的全场景需求,且所有示例均支持在本地环境直接运行调试。作为开源项目,它采用宽松的 MIT 许可证,鼓励社区贡献与二次开发,是学习大模型应用开发不可或缺的实战手册。