chatgpt-web
chatgpt-web 是一款基于 Express 后端与 Vue3 前端构建的开源 ChatGPT 网页界面,旨在通过调用 OpenAI 官方 API 为用户提供稳定、私有的对话服务。chatgpt-web 主要解决了官方访问受限、缺乏多用户管理及数据私有化部署的痛点,特别适合开发者、技术团队或希望搭建内部 AI 平台的组织使用。
相较于同类项目,chatgpt-web 的独特之处在于引入了数据库支持,实现了完整的用户体系,包括注册登录、双重验证、密码重置及后台用户管理。管理员可灵活设置对话数量限制、生成兑换码,并支持多 API Key 随机轮换以优化成本与稳定性。技术亮点方面,chatgpt-web 集成了 Web 网络搜索功能(基于 Tavily API),支持 VLLM 模型接入与深度思考模式开关,并提供 Auth Proxy 实现 SSO 单点登录(兼容 LDAP/OIDC 等协议)。
部署方式灵活,支持 Docker 容器化部署或手动打包,环境变量配置简单。作为基于 MIT 协议开源的项目,chatgpt-web 免费供学习与使用,帮助用户安全、高效地构建专属的 AI 对话环境。
使用场景
某初创技术团队负责人需要为 5 名后端开发人员提供稳定的 AI 编程助手,旨在提升编码效率的同时,严格管控 API 成本与核心代码数据安全。
没有 chatgpt-web 时
- 团队成员共用单个 API Key,一旦泄露需全局重置,安全隐患大。
- 无法统计个人使用量,月底账单超标也无法追溯具体责任人。
- 对话记录分散在各自浏览器中,离职后关键代码思路随之丢失。
- 缺乏权限管理,无法限制访问频率或禁止特定敏感话题查询。
使用 chatgpt-web 后
- 部署 chatgpt-web 私有化服务,每人独立账号登录,支持 2FA 双重验证。
- 后台设置每人每日对话限额,配置多 Key 随机轮换,稳定且成本可控。
- 会话历史云端同步,支持导出关键对话,团队知识库得以沉淀。
- 通过用户管理一键禁用离职员工权限,自定义敏感词过滤保障合规。
chatgpt-web 成功将分散且不可控的 AI 使用行为,转变为可管控、可审计的企业级协作流程,在保障安全的前提下显著提升团队研发效率。
运行环境要求
- Linux
- macOS
- Windows
不需要 (本项目为 Web 应用,调用外部 API,非本地模型部署)
未说明

快速开始
ChatGPT Web
说明
[!IMPORTANT] 此项目 Fork 自 Chanzhaoyu/chatgpt-web
由于原项目作者不愿意引入对数据库的依赖 故制作该永久分叉独立开发 详见讨论
再次感谢 Chanzhaoyu 大佬对开源的贡献 🙏
新增了部分特色功能:
[✓] 注册 & 登录 & 重置密码 & 2FA (双重身份验证)
[✓] 同步历史会话
[✓] 前端页面设置 apikey (API 密钥)
[✓] 自定义敏感词
[✓] 每个会话设置独有 Prompt (提示词)
[✓] 用户管理
[✓] 多 Key 随机
[✓] 对话数量限制 & 设置不同用户对话数量 & 兑换数量
[✓] 通过 auth proxy (认证代理) 功能实现 sso (单点登录) 登录 (配合第三方身份验证反向代理 可实现支持 LDAP/OIDC/SAML 等协议登录)
[✓] Web Search 网络搜索功能 (基于 Tavily API 实现实时网络搜索)
[✓] VLLM API 模型支持 & 可选关闭深度思考模式
[✓] 上下文窗口控制
[!CAUTION] 声明:此项目只发布于 Github,基于 MIT 协议,免费且作为开源学习使用。并且不会有任何形式的卖号、付费服务、讨论群、讨论组等行为。谨防受骗。
截图
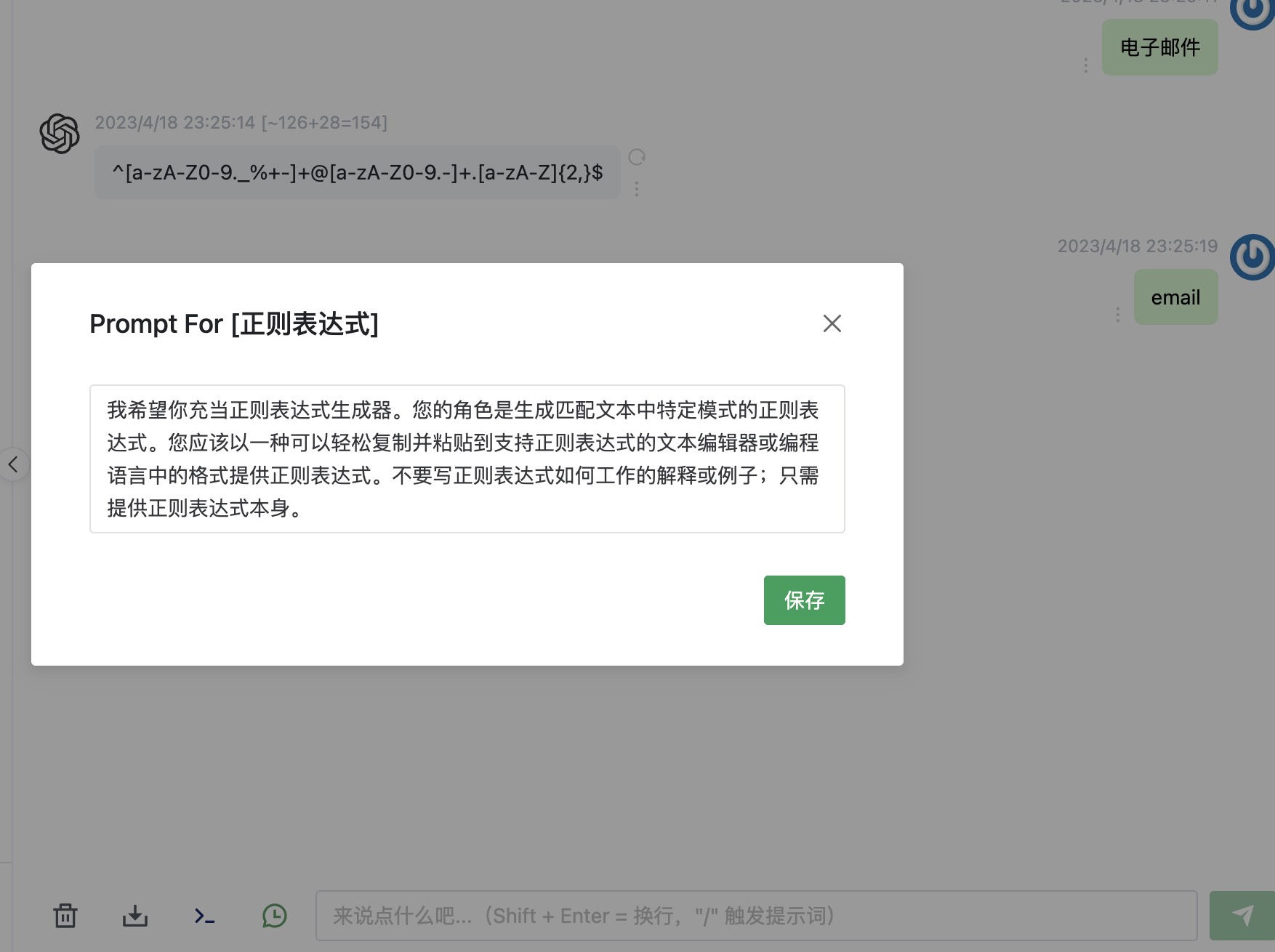
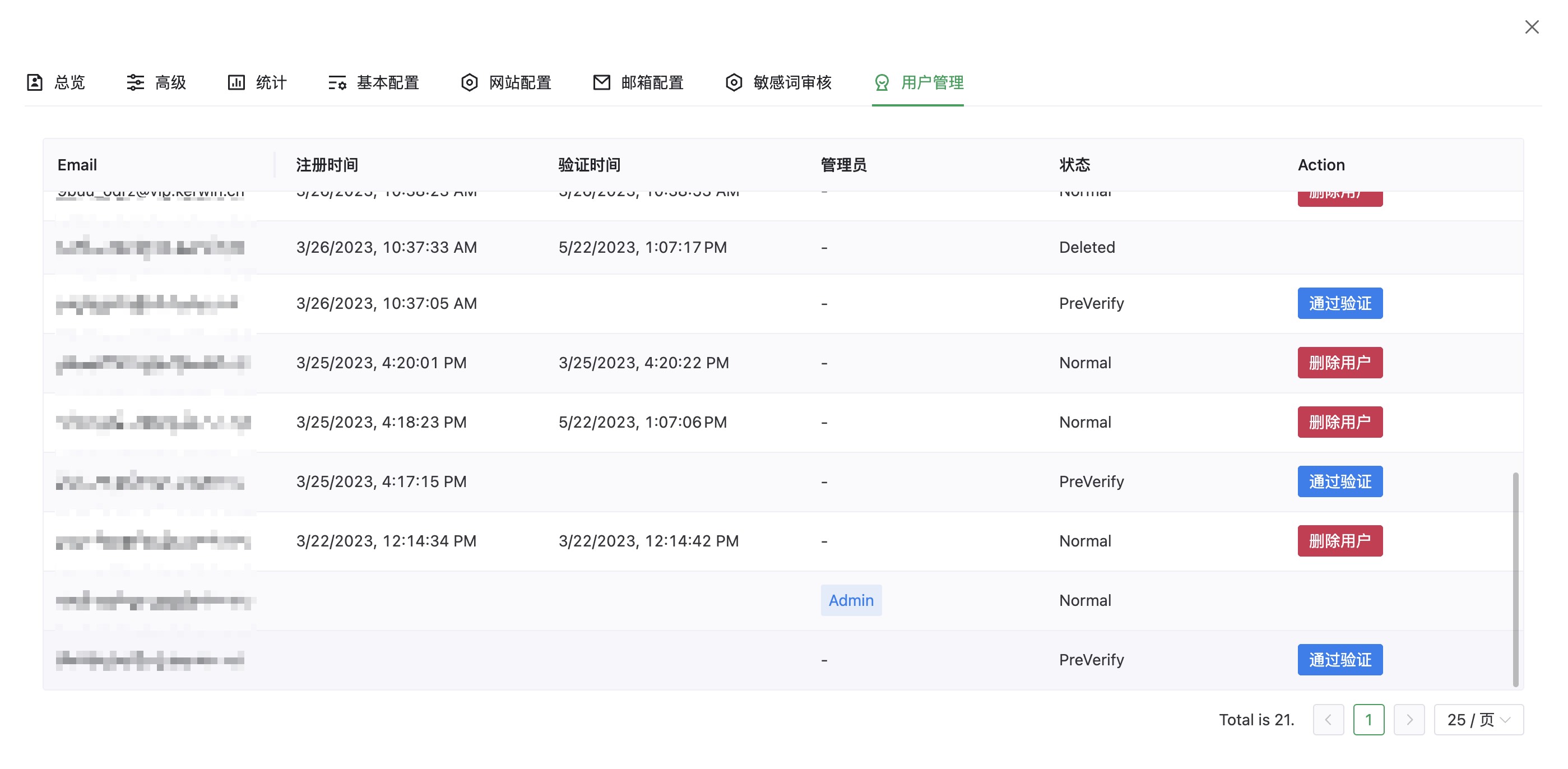
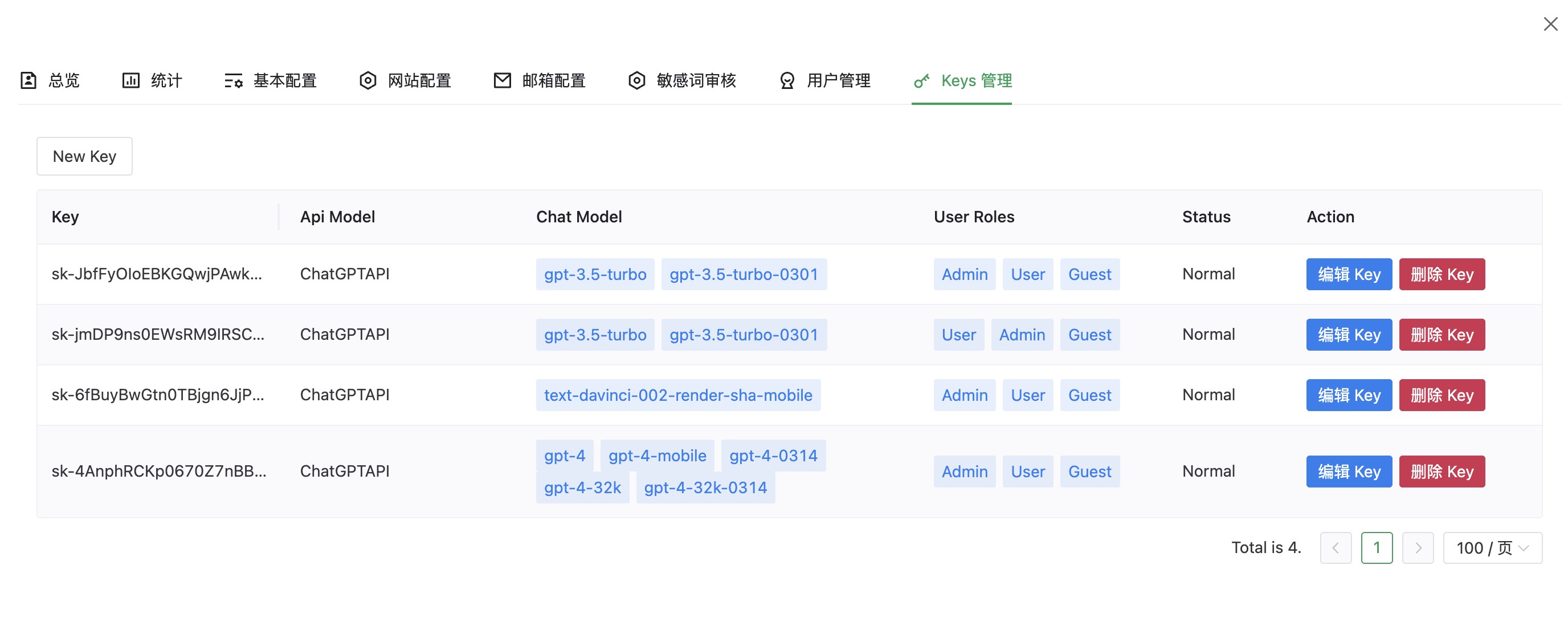
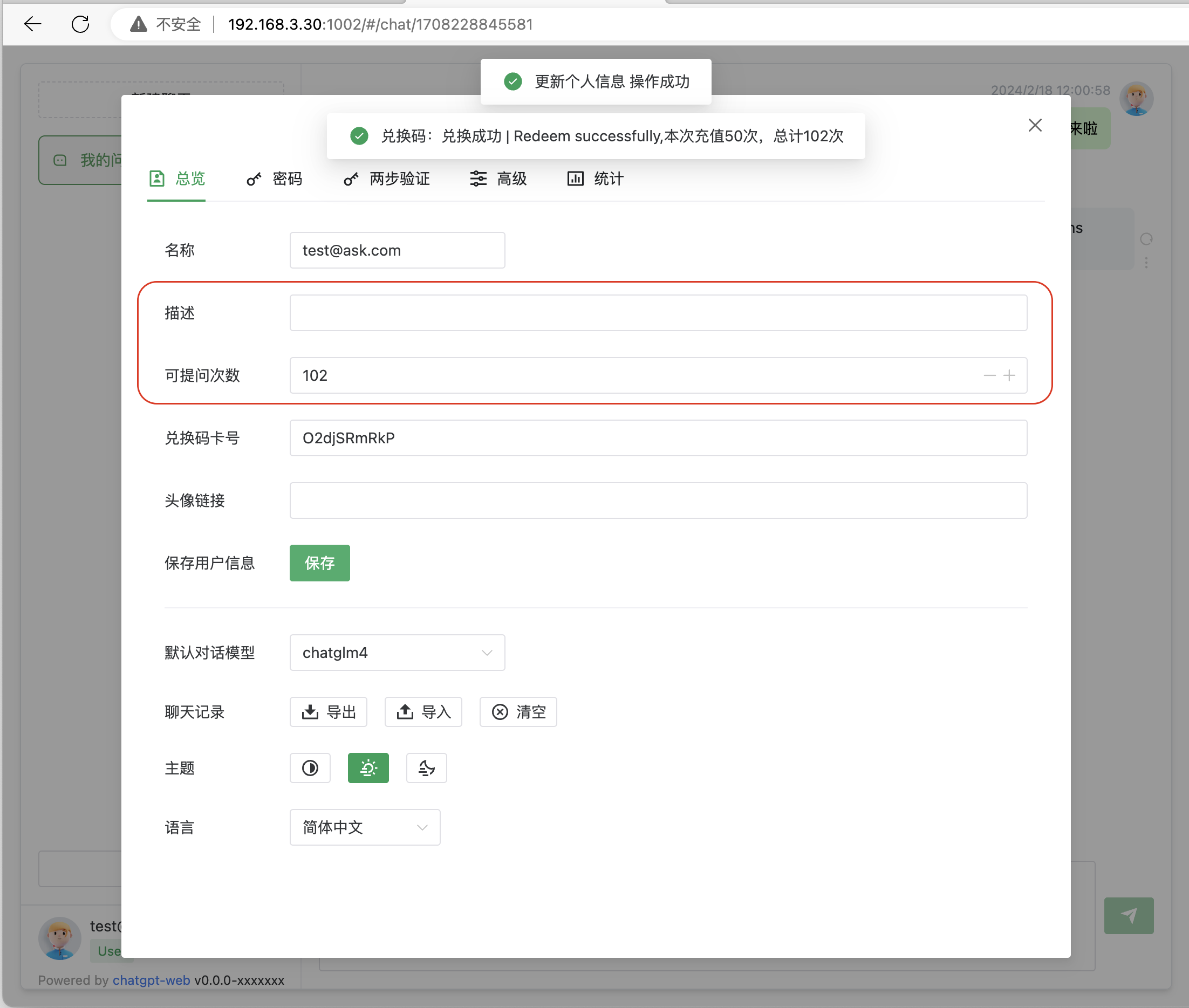
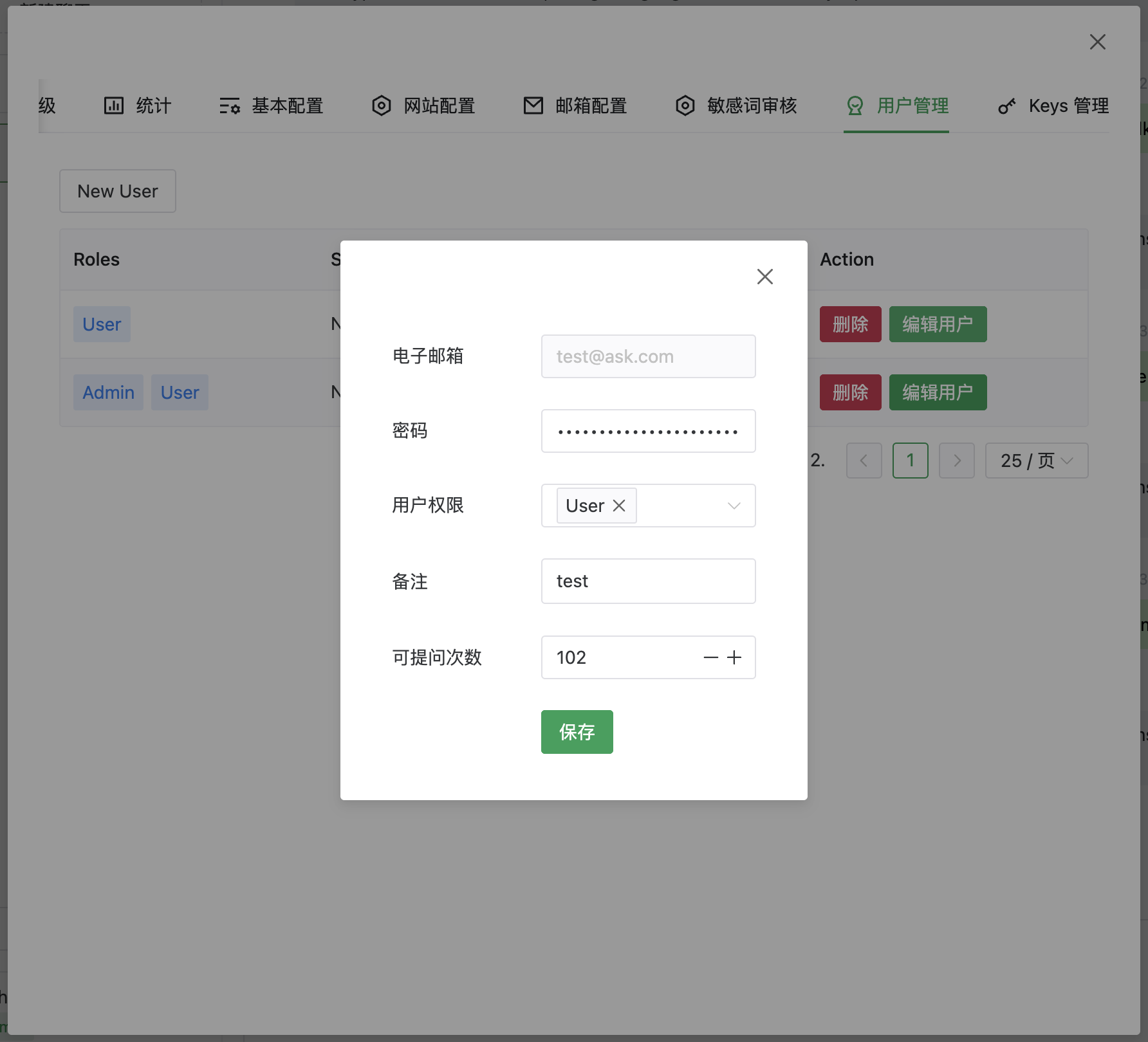
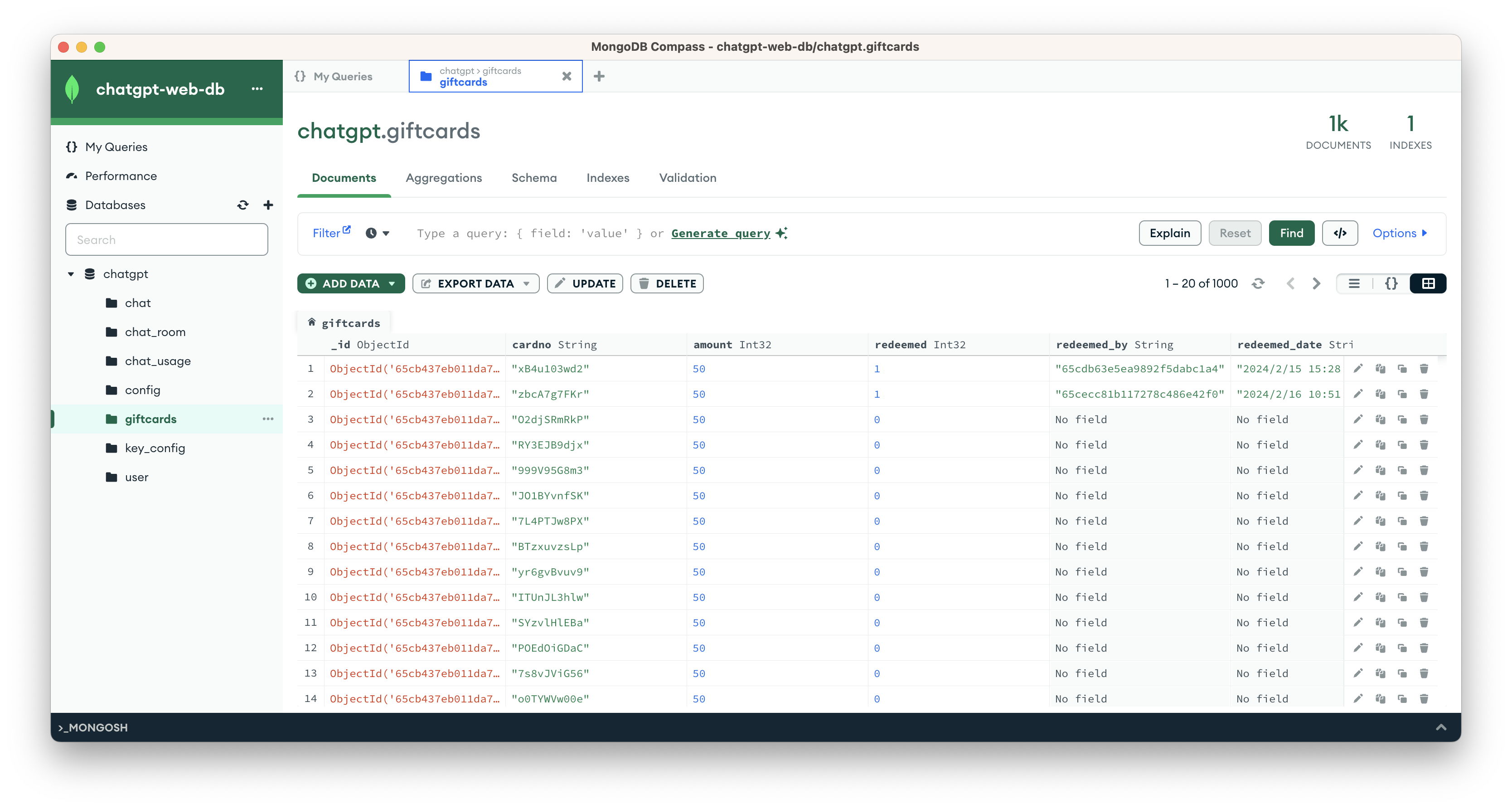
介绍
使用官方 OpenAI API (应用程序接口) 访问 ChatGPT:
ChatGPTAPI 使用 gpt-4.1 通过 OpenAI 官方 API 调用 ChatGPT(需要 API 密钥)。
警告:
- 使用
API时,如果网络不通,那是国内被墙了,你需要自建代理,绝对不要使用别人的公开代理,那是危险的。 - 把项目发布到公共网络时,你应该设置
AUTH_SECRET_KEY变量添加你的密码访问权限,你也应该修改index.html中的title,防止被关键词搜索到。
设置方式:
- 进入
service/.env.example文件,复制内容到service/.env文件 - 填写
OPENAI_API_KEY字段 (获取 apiKey)
环境变量:
全部参数变量请查看或 这里
/service/.env.example
待实现路线
[✓] 双模型
[✓] 多会话储存和上下文逻辑
[✓] 对代码等消息类型的格式化美化处理
[✓] 支持用户登录注册
[✓] 前端页面设置 apikey 等信息
[✓] 数据导入、导出
[✓] 保存消息到本地图片
[✓] 界面多语言
[✓] 界面主题
[✓] VLLM API 模型支持
[✓] 深度思考模式开关
[✗] More...
前置要求
Node
node 需要 ^20 || ^22 || ^24 版本,使用 nvm 可管理本地多个 node 版本
node -v
PNPM
如果你没有安装过 pnpm
npm install pnpm -g
填写 API 密钥
获取 OpenAI API Key 并填写本地环境变量 跳转
# service/.env 文件
# OpenAI API Key - https://platform.openai.com/overview
OPENAI_API_KEY=
安装依赖
为了简便
后端开发人员的了解负担,所以并没有采用前端workspace模式,而是分文件夹存放。如果只需要前端页面做二次开发,删除service文件夹即可。
后端
进入文件夹 /service 运行以下命令
pnpm install
前端
根目录下运行以下命令
pnpm bootstrap
测试环境运行
后端服务
进入文件夹 /service 运行以下命令
pnpm start
前端网页
根目录下运行以下命令
pnpm dev
环境变量
API 可用:
OPENAI_API_KEY必填OPENAI_API_BASE_URL设置接口地址,可选,默认:https://api.openai.comOPENAI_API_DISABLE_DEBUG设置接口关闭 debug 日志,可选,默认:empty 不关闭
通用:
AUTH_SECRET_KEY访问权限密钥,可选MAX_REQUEST_PER_HOUR每小时最大请求次数,可选,默认无限TIMEOUT_MS超时,单位毫秒,可选SOCKS_PROXY_HOST和SOCKS_PROXY_PORT一起时生效,可选SOCKS_PROXY_PORT和SOCKS_PROXY_HOST一起时生效,可选HTTPS_PROXY支持http,https,socks5,可选
打包
使用 Docker
Docker 参数示例
OPENAI_API_KEY必填OPENAI_API_BASE_URL可选,设置接口地址,默认:https://api.openai.comOPENAI_API_MODEL可选,指定使用的模型AUTH_SECRET_KEY访问密码,可选TIMEOUT_MS超时,单位毫秒,可选SOCKS_PROXY_HOST可选,与 SOCKS_PROXY_PORT 一起使用SOCKS_PROXY_PORT可选,与 SOCKS_PROXY_HOST 一起使用SOCKS_PROXY_USERNAME可选,与 SOCKS_PROXY_HOST 和 SOCKS_PROXY_PORT 一起使用SOCKS_PROXY_PASSWORD可选,与 SOCKS_PROXY_HOST 和 SOCKS_PROXY_PORT 一起使用HTTPS_PROXY可选,支持 http,https, socks5
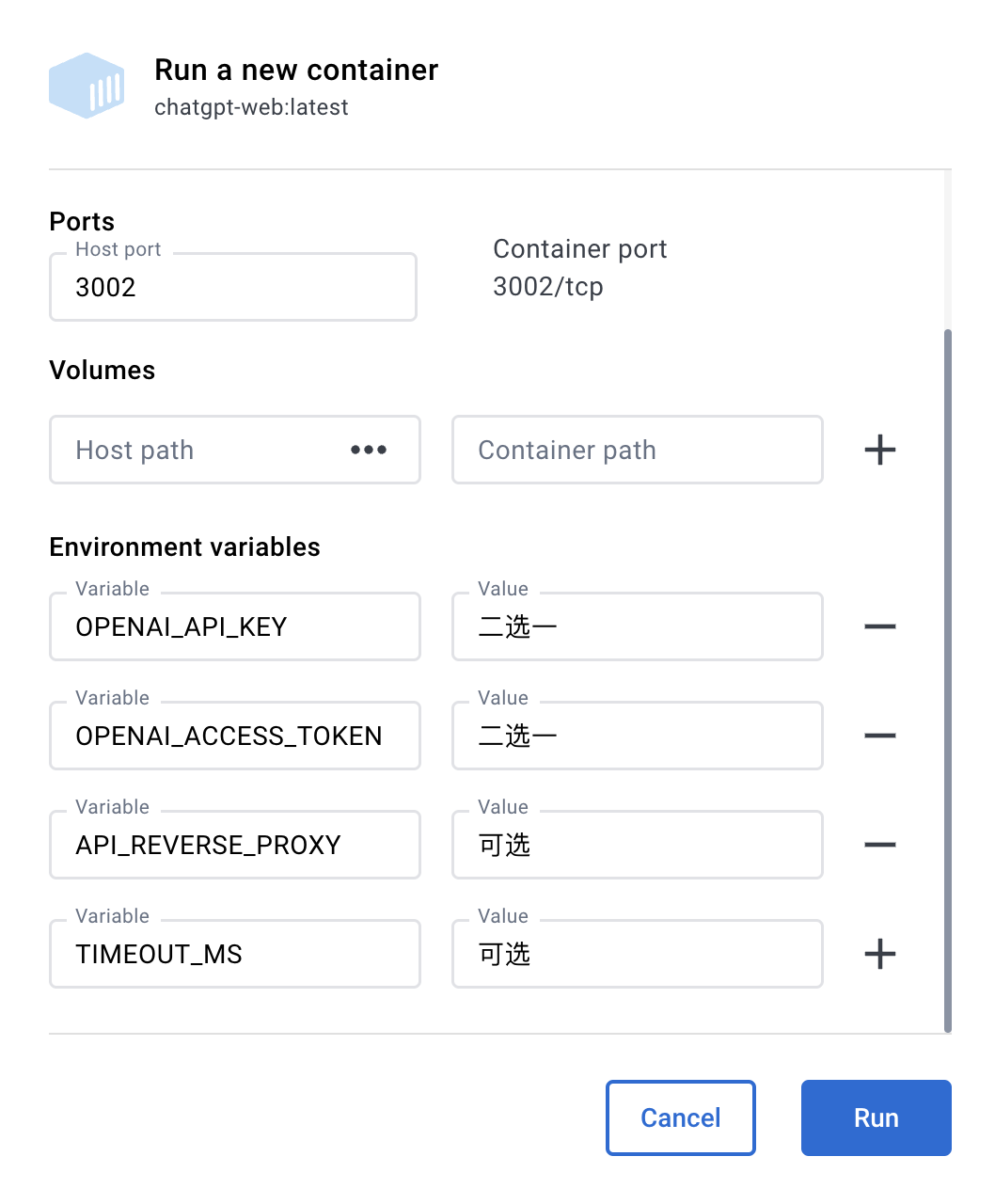
Docker build & Run
GIT_COMMIT_HASH=`git rev-parse HEAD`
RELEASE_VERSION=`git branch --show-current`
docker build --build-arg GIT_COMMIT_HASH=${GIT_COMMIT_HASH} --build-arg RELEASE_VERSION=${RELEASE_VERSION} -t chatgpt-web .
# 前台运行
# 如果在宿主机运行 mongodb 则使用 MONGODB_URL=mongodb://host.docker.internal:27017/chatgpt
docker run --name chatgpt-web --rm -it -p 3002:3002 --env OPENAI_API_KEY=your_api_key --env MONGODB_URL=your_mongodb_url chatgpt-web
# 后台运行
docker run --name chatgpt-web -d -p 127.0.0.1:3002:3002 --env OPENAI_API_KEY=your_api_key --env MONGODB_URL=your_mongodb_url chatgpt-web
# 运行地址
http://localhost:3002/
Docker compose
version: '3'
services:
app:
image: chatgptweb/chatgpt-web # 总是使用 latest,更新时重新 pull 该 tag 镜像即可
container_name: chatgptweb
restart: unless-stopped
ports:
- 3002:3002
depends_on:
- database
environment:
TZ: Asia/Shanghai
# 每小时最大请求次数,可选,默认无限
MAX_REQUEST_PER_HOUR: 0
# 访问 jwt 加密参数,可选 不为空则允许登录 同时需要设置 MONGODB_URL
AUTH_SECRET_KEY: xxx
# 网站名称
SITE_TITLE: ChatGpt Web
# mongodb 的连接字符串
MONGODB_URL: 'mongodb://chatgpt:xxxx@database:27017'
# 开启注册之后 密码加密的盐
PASSWORD_MD5_SALT: xxx
# 开启注册之后 超级管理邮箱
ROOT_USER: me@example.com
# 网站是否开启注册 必须开启,否则管理员都没法注册,可后续关闭
REGISTER_ENABLED: true
# 更多配置,在运行后,注册管理员,在管理员页面中设置
links:
- database
database:
image: mongo
container_name: chatgptweb-database
restart: unless-stopped
ports:
- '27017:27017'
expose:
- '27017'
volumes:
- mongodb:/data/db
environment:
MONGO_INITDB_ROOT_USERNAME: chatgpt
MONGO_INITDB_ROOT_PASSWORD: xxxx
MONGO_INITDB_DATABASE: chatgpt
volumes:
mongodb: {}
OPENAI_API_BASE_URL可选,设置OPENAI_API_KEY时可用
防止爬虫抓取
nginx
将下面配置填入 nginx 配置文件中,可以参考 docker-compose/nginx/nginx.conf 文件中添加反爬虫的方法
# 防止爬虫抓取
if ($http_user_agent ~* "360Spider|JikeSpider|Spider|spider|bot|Bot|2345Explorer|curl|wget|webZIP|qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot|NSPlayer|bingbot"){
return 403;
}
使用 Railway 部署

参考这个 issue 详细教程 https://github.com/Kerwin1202/chatgpt-web/issues/266
注意:
Railway修改环境变量会重新Deploy
手动打包
后端服务
如果你不需要本项目的
node接口,可以省略如下操作
复制 service 文件夹到你有 node 服务环境的服务器上。
# 安装
pnpm install
# 打包
pnpm build
运行
pnpm prod
注:不进行打包,直接在服务器上运行 `pnpm start` 也可
#### 前端网页
1、修改根目录下 `.env` 文件中的 `VITE_GLOB_API_URL` 为你的实际后端接口地址
2、根目录下运行以下命令,然后将 `dist` 文件夹内的文件复制到你网站服务的根目录下
[参考信息](https://cn.vitejs.dev/guide/static-deploy.html#building-the-app)
```shell
pnpm build
认证代理模式 (Auth Proxy Mode)
[!WARNING] 该功能仅适用于有相关经验的运维人员在集成企业内部账号管理系统时部署 配置不当可能会导致安全风险
设置环境变量 AUTH_PROXY_ENABLED=true 即可开启认证代理 (Auth Proxy) 模式
在开启该功能后 需确保 chatgpt-web 只能通过反向代理访问
由反向代理进行进行身份验证 并再转发请求时携带请求头标识用户身份
默认请求头为 X-Email 并可以通过设置环境变量 AUTH_PROXY_HEADER_NAME 自定义配置
推荐当前身份提供商 (Idp) 使用 LDAP (轻量级目录访问协议) 协议的 可以选择使用 authelia
当前身份提供商 (Idp) 使用 OIDC (开放身份连接协议) 协议的 可以选择使用 oauth2-proxy
网络搜索功能 (Web Search)
[!TIP] Web Search 功能基于 Tavily API 实现,可以让 ChatGPT 获取最新的网络信息来回答问题。
功能特性
- 实时网络搜索: 基于 Tavily API 获取最新的网络信息
- 智能查询提取: 自动从用户问题中提取最相关的搜索关键词
- 搜索结果整合: 将搜索结果无缝整合到 AI 对话中
- 按会话控制: 每个对话可以独立开启或关闭搜索功能
- 搜索历史记录: 保存搜索查询和结果到数据库
- 可配置系统消息: 支持自定义搜索相关的系统提示消息
配置方式
1. 获取 Tavily API 密钥 (API Key)
- 访问 Tavily 官网 注册账号
- 获取 API 密钥 (API Key)
2. 管理员配置
- 以管理员身份登录系统
- 进入系统设置页面
- 找到 "Web Search 配置" 选项
- 填写以下配置:
- 启用状态: 开启/关闭全局搜索功能
- API 密钥 (API Key): 填入 Tavily API 密钥
- 最大搜索结果数: 设置每次搜索返回的最大结果数量(1-20,默认 10)
- 搜索查询系统消息: 用于提取搜索关键词的提示模板
- 搜索结果系统消息: 用于处理搜索结果的提示模板
3. 系统消息模板
搜索查询提取模板 (用于从用户问题中提取搜索关键词):
You are a search query extraction assistant. Extract the most relevant search query from user's question and wrap it with <search_query></search_query> tags.
Current time: {current_time}
搜索结果处理模板 (用于处理包含搜索结果的对话):
You are a helpful assistant with access to real-time web search results. Use the provided search information to give accurate and up-to-date responses.
Current time: {current_time}
使用方式
用户端操作
开启搜索功能:
- 在对话界面中,找到搜索开关按钮
- 点击开启当前会话的网络搜索功能
提问获取实时信息:
- 开启搜索后,直接向 ChatGPT 提问需要实时信息的问题
- 系统会自动搜索相关信息并整合到回答中
查看搜索历史:
- 搜索查询和结果会保存在数据库中
- 可以通过数据库查看具体的搜索记录
工作流程
- 用户提问: 用户在开启搜索的会话中提问
- 查询提取: 系统使用 AI 从问题中提取搜索关键词
- 网络搜索: 调用 Tavily API 进行实时搜索
- 结果整合: 将搜索结果作为上下文提供给 AI
- 生成回答: AI 基于搜索结果生成更准确的回答
技术实现
- 搜索引擎: Tavily API
- 查询提取: 使用 OpenAI API 智能提取关键词
- 结果格式: JSON 格式存储完整搜索结果
- 数据存储: MongoDB 存储搜索查询和结果
- 超时设置: 搜索请求超时时间为 300 秒
- 结果数量控制: 支持配置每次搜索返回的最大结果数量(1-20)
注意事项
- Web Search 功能需要额外的 Tavily API 费用
- 搜索功能会增加响应时间
- 建议根据实际需求选择性开启
- 管理员可以控制全局搜索功能的开启状态
- 每个会话可以独立控制是否使用搜索功能
- 最大搜索结果数设置会影响搜索的详细程度和 API 费用
上下文窗口控制
[!TIP] 上下文窗口控制功能可以让用户灵活管理 AI 对话中的上下文信息,优化模型性能和对话效果。
功能特性
- 上下文管理: 控制模型可以参考的聊天记录数量
- 按对话控制: 每个对话可以独立开启或关闭上下文窗口
- 实时切换: 在对话过程中可以随时切换上下文模式
- 记忆管理: 灵活控制 AI 的记忆范围和连续性
- 可配置数量: 管理员可设置上下文消息的最大数量
工作原理
上下文窗口决定了在生成过程中,模型可以参考的当前会话下聊天记录的量:
- 合理的上下文窗口大小有助于模型生成连贯且相关的文本
- 避免因为参考过多的上下文而导致混乱或不相关的输出
- 关闭上下文窗口会导致会话失去记忆,每次提问之间将完全独立
使用方式
1. 启用/关闭上下文窗口
- 进入对话界面: 在任何对话会话中都可以使用此功能
- 找到控制开关: 在对话界面中找到"上下文窗口"开关按钮
- 切换模式:
- 开启: 模型会参考之前的聊天记录,保持对话连贯性
- 关闭: 模型不会参考历史记录,每个问题独立处理
2. 使用场景
建议开启上下文窗口的情况:
- 需要连续对话和上下文关联
- 复杂主题的深入讨论
- 多轮问答和逐步解决问题
- 需要 AI 记住之前提到的信息
建议关闭上下文窗口的情况:
- 独立的简单问题
- 避免历史信息干扰新问题
- 处理不相关的多个主题
- 需要"重新开始"的场景
3. 管理员配置
管理员可以在系统设置中配置:
- 最大上下文数量: 设置会话中包含的上下文消息数量
- 默认状态: 设置新对话的默认上下文窗口状态
技术实现
- 上下文截取: 自动截取指定数量的历史消息
- 状态持久化: 每个对话独立保存上下文窗口开关状态
- 实时生效: 切换后立即对下一条消息生效
- 内存优化: 合理控制上下文长度,避免超出模型限制
注意事项
- 对话连贯性: 关闭上下文窗口会影响对话的连续性
- Token (令牌) 消耗: 更多的上下文会增加 Token 使用量
- 响应质量: 适当的上下文有助于提高回答质量
- 模型限制: 需要考虑不同模型的上下文长度限制
VLLM API 深度思考模式控制
[!TIP] 深度思考模式控制功能仅在后端配置为 VLLM API 时可用,可以让用户选择是否启用模型的深度思考功能。
功能特性
- VLLM API 专属功能: 仅在后端使用 VLLM API 时可用
- 按对话控制: 每个对话可以独立开启或关闭深度思考模式
- 实时切换: 在对话过程中可以随时切换深度思考模式
- 性能优化: 关闭深度思考可以提高响应速度,降低计算成本
工作原理
开启深度思考后,模型会用更多的计算资源以及消耗更长时间,模拟更复杂的思维链路进行逻辑推理:
- 适合复杂任务或高要求场景,比如数学题推导、项目规划
- 日常简单查询无需开启深度思考模式
- 关闭深度思考可以获得更快的响应速度
使用前提
必须满足以下条件才能使用此功能:
- 后端配置: 后端必须配置为使用 VLLM API 接口
- 模型支持: 使用的模型必须支持深度思考功能
- API 兼容: VLLM API 版本需要支持思考模式控制参数
使用方式
1. 启用/关闭深度思考模式
- 进入对话界面: 在支持 VLLM API 的对话会话中
- 找到控制开关: 在对话界面中找到"深度思考"开关按钮
- 切换模式:
- 开启:模型将进行深度思考,提供更详细和深入的回答
- 关闭:模型将直接回答,响应更快但可能较为简洁
2. 使用场景
建议开启深度思考的情况:
- 复杂问题需要深入分析
- 需要逻辑推理和多步骤思考
- 对回答质量要求较高的场景
- 时间不敏感的情况
建议关闭深度思考的情况:
- 简单问题快速回答
- 需要快速响应的场景
- 降低计算成本的需求
- 批量处理简单任务
3. 技术实现
- API 参数: 通过 VLLM API 的
disable_thinking参数控制 - 状态保存: 每个对话会话独立保存深度思考开关状态
- 实时生效: 切换后立即对下一条消息生效
注意事项
- 仅限 VLLM API: 此功能仅在后端使用 VLLM API 时可用,其他 API(如 OpenAI API)不支持此功能
- 模型依赖: 不是所有模型都支持深度思考模式,请确认您使用的模型支持此功能
- 响应差异: 关闭深度思考可能会影响回答的详细程度和质量
- 成本考虑: 开启深度思考通常会增加计算成本和响应时间
常见问题
问:为什么 Git 提交总是报错?
答:因为有提交信息验证,请遵循 提交指南 (Commit Guidelines)
问:如果只使用前端页面,在哪里改请求接口?
答:根目录下 .env 文件中的 VITE_GLOB_API_URL 字段。
问:文件保存时全部爆红?
答:VS Code 请安装项目推荐插件,或手动安装 ESLint 插件。
问:前端没有打字机效果?
答:一种可能原因是经过 Nginx 反向代理,开启了 buffer,则 Nginx 会尝试从后端缓冲一定大小的数据再发送给浏览器。请尝试在反代参数后添加 proxy_buffering off;,然后重载 Nginx。其他 web server 配置同理。
参与贡献
贡献之前请先阅读 贡献指南
感谢所有做过贡献的人!

Star 历史

赞助
如果你觉得这个项目对你有帮助,请给我点个 Star。并且情况允许的话,可以给我一点点支持,总之非常感谢支持~

微信支付

支付宝
感谢 DigitalOcean 赞助提供开源积分用于运行基础设施服务器
![]()
许可证 (License)
版本历史
v3.13.02026/03/04v3.12.32026/01/16v3.12.22026/01/14v3.12.12026/01/14v3.12.02026/01/13v3.11.02026/01/09v3.10.12026/01/06v3.10.02025/12/29v3.9.42025/12/25v3.9.32025/12/24v3.9.22025/12/24v3.9.12025/12/23v3.9.02025/12/23v3.8.12025/12/15v3.8.02025/12/05v3.7.02025/09/06v3.6.12025/07/11v3.6.02025/07/11v3.5.12025/07/03v3.5.02025/07/01常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。