chaiNNer
chaiNNer 是一款基于节点流程的图像处理图形界面工具,旨在让复杂的图像任务变得像搭积木一样简单直观。它最初专为 AI 图像超分辨率(放大)设计,如今已进化为功能极其强大的通用图像处理平台。
对于需要精细控制工作流的用户而言,chaiNNer 解决了传统软件操作僵化、难以定制复杂处理链条的痛点。用户只需通过拖拽节点并连线,即可自由组合出从基础调整到高度复杂的自动化处理流程,无需编写任何代码。
这款工具非常适合设计师、AI 爱好者以及希望尝试深度学习模型但畏惧命令行操作的普通用户。无论是进行图片高清修复、格式转换还是批量处理,都能轻松上手。同时,其开放的架构也吸引了开发者和研究人员参与扩展。
技术亮点方面,chaiNNer 支持跨平台运行(Windows、macOS、Linux),并内置了独立的 Python 环境,用户无需手动配置繁琐的开发依赖。它广泛兼容 PyTorch、NCNN、ONNX 和 TensorRT 等主流神经网络框架,能根据用户的显卡类型(如 NVIDIA 或 AMD)智能推荐最优方案,让高性能 AI 推理触手可及。
使用场景
一位独立游戏开发者需要将大量低分辨率的像素艺术素材批量放大并统一风格,以适配高清显示屏。
没有 chaiNNer 时
- 操作繁琐重复:必须编写复杂的 Python 脚本或手动在 Photoshop 中逐个处理数百张图片,效率极低且容易出错。
- 环境配置困难:部署 AI 超分模型需要手动安装特定版本的 PyTorch、CUDA 驱动及各类依赖库,常因版本冲突导致运行失败。
- 流程僵化单一:难以将“放大”、“去噪”、“色彩校正”等多个步骤串联,每次调整参数都需重新运行整个脚本,缺乏灵活性。
- 硬件适配麻烦:在不同显卡(如 NVIDIA 与 AMD)之间切换时,往往需要重写代码或更换推理后端,学习成本高昂。
使用 chaiNNer 后
- 可视化流水线:通过拖拽节点即可构建“加载图片→AI 超分→自动调色→保存”的自动化流程,一键批量处理所有素材。
- 开箱即用体验:chaiNNer 内置独立 Python 环境和依赖管理器,无需配置系统环境,启动即可直接调用 PyTorch 或 NCNN 等框架。
- 高度灵活定制:利用节点连线自由组合复杂任务,随时插入新的处理环节(如人脸修复),并实时预览中间结果以微调参数。
- 跨平台兼容:同一套节点流程图可在 Windows、macOS 和 Linux 间无缝迁移,自动适配不同用户的显卡硬件进行加速。
chaiNNer 将原本高门槛的编程式图像处理转化为直观的可视化工作流,让创作者能专注于内容而非技术细节。
运行环境要求
- Windows
- macOS
- Linux
- 非必需(支持 CPU 模式)
- NVIDIA: 支持 CUDA (PyTorch), TensorRT
- AMD (Linux): 支持 ROCm (PyTorch)
- 所有平台 AMD/Intel: 支持 NCNN
- Apple Silicon: 支持 MPS
- 具体显存和 CUDA 版本未说明,取决于所选后端和模型
未说明

快速开始
chaiNNer





chaiNNer 是一款基于节点的图像处理 GUI,旨在让图像处理任务的串联变得简单且可定制。最初作为一款 AI 超分辨率应用诞生,如今 chaiNNer 已发展成为一款极其灵活且功能强大的程序化图像处理工具。
chaiNNer 让你对图像处理工作流拥有极高的自定义能力,这是很少有其他工具能做到的。你不仅可以完全掌控整个处理流程,只需通过连接几个节点就能完成极其复杂的任务。
此外,chaiNNer 还是跨平台的,这意味着你可以在 Windows、macOS 和 Linux 上运行它。
如需帮助、提出建议或只是想聊聊天,欢迎加入 chaiNNer Discord 社区。
chaiNNer 目前仍在积极开发中。如果你熟悉 TypeScript、React 或 Python,欢迎为本项目贡献力量,帮助我们持续改进!
安装
从 GitHub 发布页面 下载最新版本,并运行最适合你系统的安装程序即可。非常简单。
你甚至无需预先安装 Python,因为 chaiNNer 在启动时会自动下载一个独立的集成式 Python 版本。之后,你可以通过依赖管理器安装所有其他依赖项。
如果你仍然希望使用系统自带的 Python 环境,可以启用“使用系统 Python”选项。不过,强烈建议使用集成式 Python。若选择使用系统 Python,则需要 Python 3.10 或更高版本(推荐 3.11 及以上)。
如果你想体验最新的更改和优化,可以尝试我们的 夜间构建版本。
使用方法
基本用法
尽管由于选项众多,chaiNNer 初次使用时可能会让人感到有些复杂,但实际上它非常易于上手。例如,要进行图像超分辨率处理,你只需执行以下步骤:
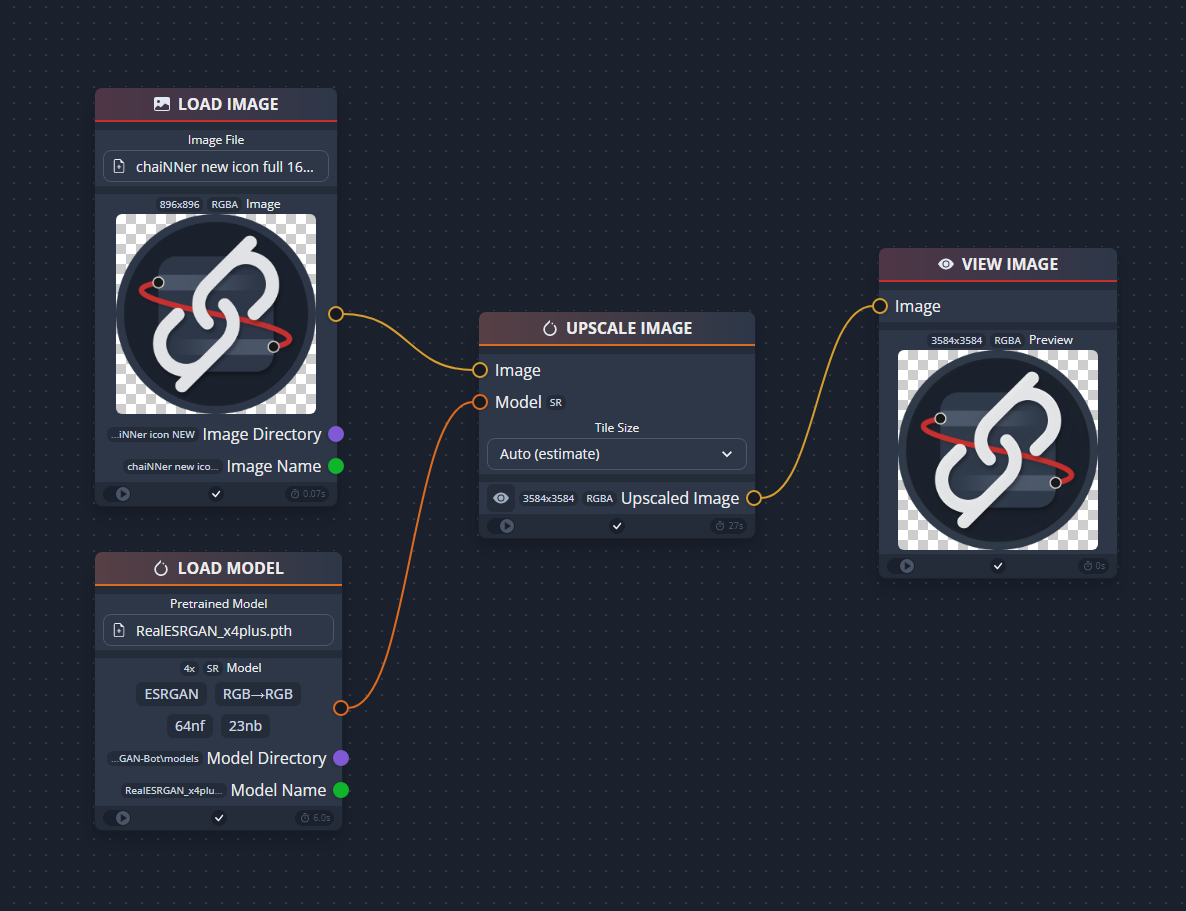
不过,在此之前,你需要先通过依赖管理器安装其中一个神经网络框架。可以通过右上角的按钮访问该功能。chaiNNer 支持 PyTorch(部分模型架构)、NCNN、ONNX 和 TensorRT。对于 NVIDIA 用户,推荐使用 PyTorch 或 TensorRT 进行超分辨率;而对于 AMD 用户,则推荐使用 NCNN(或在 Linux 上搭配 ROCm 的 PyTorch)。
所有其他 Python 依赖项都会自动安装,而且 chaiNNer 自带集成式 Python 支持,因此你无需修改现有的 Python 配置。
接下来,只需将选择面板中的节点名称拖放到编辑器中即可。然后,从一个节点的端口拖动到另一个节点的端口以建立连接。每个端口都按类型进行了颜色编码,连接时只会显示兼容的连接方式,这使得你很容易知道应该将哪些节点连接在一起。
当编辑器中搭建好工作链后,点击顶部栏的绿色“运行”按钮即可开始执行。你会看到节点之间的连接会动态显示,处理完成后则会恢复原状。你可以分别使用红色“停止”按钮和黄色“暂停”按钮来停止或暂停处理过程。
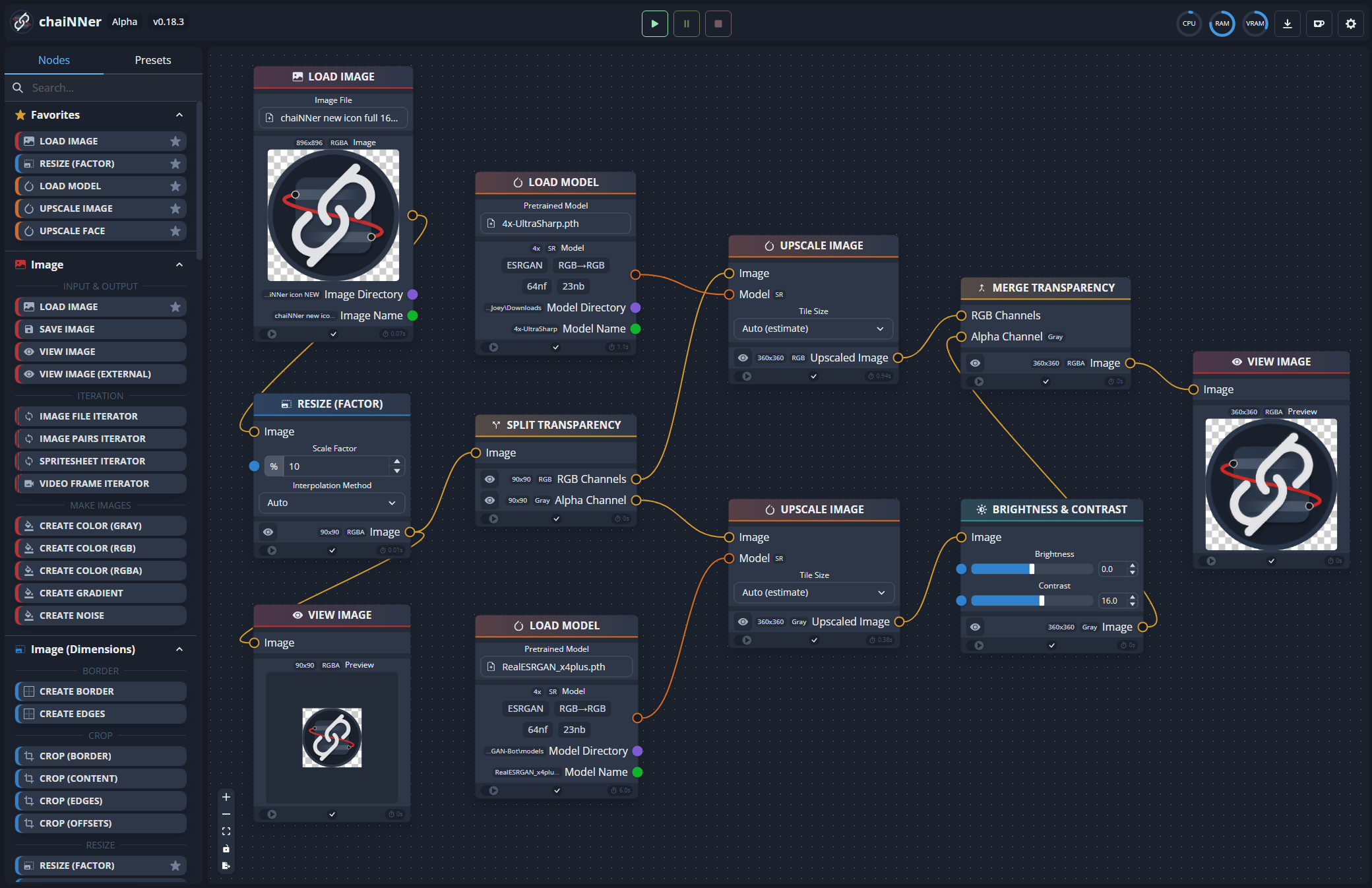
别忘了,chaiNNer 还可以用于许多非超分辨率的图像处理任务哦!
小贴士与技巧
要选择多个节点,请按住 Shift 键并拖动以框选所有需要选择的节点。你也可以直接单击某个节点将其单独选中。选中节点后,按下 Backspace 或 Delete 键即可将其从编辑器中删除。
要对文件夹中的多张图片进行批量处理,可以使用“加载图片”节点;如果要处理视频,则使用“加载视频”节点。需要注意的是,你不能在同一链条中同时使用“加载图片”和“加载视频”节点(或任何两个执行批量迭代的节点)。不过,你可以在链条中组合输出(收集)节点,例如将“保存图片”与“加载视频”结合使用,或将“保存视频”与“加载图片”结合使用。
在编辑器视图中右键单击,会弹出一个内联节点列表供你选择。你也可以通过将连接线拖到编辑器中而非实际建立连接的方式来调出该菜单,此时会显示可自动创建连接的兼容节点。
有用资源
- Kim 的 chaiNNer 模板库
- 一系列实用的工作链模板,适合刚接触 chaiNNer 的用户快速上手。
- OpenModelDB 模型数据库
- 由社区训练的一系列优秀的超分辨率模型集合。
- 超分辨率模型交互式可视化对比
- 一个在线的模型对比工具。作者还提供了一份 精选模型列表。
兼容性说明
不支持 macOS 10.x 及更早版本。
不支持 Windows 8.1 及更早版本。
Apple Silicon Mac 通过 PyTorch MPS 加速得到支持。ONNX 仅支持 CPU 执行提供者,而 NCNN 在某些配置下可能无法正常工作。
部分使用非 NVIDIA 显卡的 NCNN 用户可能会遇到全黑输出的问题。目前尚不清楚如何解决这个问题,但似乎是由显卡驱动因内存不足而崩溃导致的。如果出现这种情况,可以尝试手动设置分块大小。
对于 Linux 用户,要使用剪贴板相关节点,需要安装 xclip,或者对于 Wayland 用户,需要安装 wl-copy。
GPU 支持
Nvidia GPU: 通过 PyTorch(CUDA)、ONNX 和 TensorRT 提供全面支持。对于受支持的模型,TensorRT 能够提供最佳性能。
AMD GPU:
- 在 Linux 系统上,AMD GPU 可以通过 ROCm 使用 PyTorch。
- NCNN 在所有平台上均支持 AMD GPU。
Apple Silicon(M1/M2/M3): 支持 PyTorch MPS 加速。
Intel GPU: Intel GPU 支持 NCNN 推理。
CPU: 所有框架都支持仅使用 CPU 的模式作为备用方案。
对于 NCNN,请确保在设置中选择您想要使用的 GPU。它可能会默认使用您的集成显卡!
模型架构支持
ChaiNNer 目前仅支持有限数量的神经网络架构。未来将支持更多架构。
PyTorch
自 v0.21.0 起,ChaiNNer 使用我们新推出的名为 Spandrel 的包来支持 PyTorch 模型架构。有关支持的列表,请查看 此处。
NCNN
单张图像超分辨率
- 从技术上讲,只要遵循典型的基于 CNN 的超分辨率结构,几乎任何 SR 模型都应该可以工作。不过,我目前只测试过 ESRGAN(及其变体)和 Waifu2x。
ONNX
单张图像超分辨率
- 与 NCNN 类似,理论上只要遵循典型的基于 CNN 的超分辨率结构,几乎任何 SR 模型都可以使用。不过,我目前只测试过 ESRGAN。
背景去除
TensorRT
TensorRT 为 Nvidia GPU 提供优化的推理能力。模型必须转换为 TensorRT 引擎格式才能使用。这在受支持的硬件上能够提供最佳性能。
故障排除
有关故障排除的信息,请参阅 故障排除文档。
自行构建 ChaiNNer
我在 GitHub 上提供了 ChaiNNer 的预编译版本。然而,如果您希望自行构建 ChaiNNer,只需运行 npm install(请确保已安装至少 npm v7)以安装所有 Node.js 依赖项,然后运行 npm run make 来构建应用程序。
常见问题解答
有关常见问题解答的信息,请参阅 FAQ 文档。
文档
如需深入了解 ChaiNNer 的各个方面,包括 CLI 使用、数据表示以及贡献者指南等,请参阅我们的 ChaiNNer Wiki。
版本历史
v0.25.12025/10/23v0.25.02025/10/19v0.24.12024/06/07v0.24.02024/06/01v0.23.32024/04/24v0.23.22024/04/23v0.23.12024/04/12v0.23.02024/04/11v0.22.22024/03/01v0.22.12024/02/28v0.22.02024/02/20v0.21.22024/01/24v0.21.12024/01/13v0.21.02024/01/12v0.20.22023/10/14v0.20.12023/09/16v0.20.02023/09/16v0.19.42023/08/25v0.19.32023/08/18v0.19.22023/08/14常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。