awesome-transformer-nlp
awesome-transformer-nlp 是一个专注于自然语言处理(NLP)领域的精选资源导航,核心围绕 Transformer 网络、注意力机制、BERT、GPT 及大语言模型等技术展开。面对海量且分散的技术资料,学习者常面临筛选困难的问题,而这份列表通过汇聚高质量论文、文章、教程、视频及代码实现,有效解决了信息碎片化的挑战。
项目非常适合 AI 开发者、算法研究人员以及对大模型感兴趣的学生使用。内容不仅包含 BERT 和 Transformer-XL 等经典论文解读,还详细列出了 PyTorch、TensorFlow 等主流框架的官方实现与社区版本,甚至涵盖 AI 安全及命名实体识别等具体任务指南。此外,它还特别关注迁移学习与强化学习在 Transformer 中的应用,为不同阶段的学习者提供了从理论基础到工程落地的完整路径。这种结构化的整理方式,帮助用户高效构建知识体系,快速追踪技术前沿,是探索现代 NLP 技术与深度学习应用的理想起点。
使用场景
某电商公司的 NLP 工程师小张需要在一个月内为商品评论构建情感分析模型,急需基于 Transformer 架构的高效解决方案。
没有 awesome-transformer-nlp 时
- 在搜索引擎中分散查找 BERT 原始论文和最新变体,耗时且极易遗漏关键文献
- 面对 PyTorch 和 TensorFlow 多种实现方案,难以快速筛选适合当前业务规模的代码库
- 缺乏系统的迁移学习教程,导致微调过程中反复调试超参数,模型收敛效率低下
- 对 Attention 机制等底层原理理解不深,无法针对长文本场景有效优化模型结构
使用 awesome-transformer-nlp 后
- 通过精选 Papers 板块直接定位到 BERT 核心论文及 Transformer-XL 等进阶研究,明确技术选型
- 在 Official Implementations 章节一键获取官方推荐的代码仓库,显著减少环境配置与复现时间
- 利用 Transfer Learning in NLP 专栏快速掌握领域适配技巧,大幅缩短模型从开发到落地的周期
- 结合 Educational 中的 Tutorials 视频课程,深入理解注意力机制以优化特定任务如命名实体识别的表现
核心价值:awesome-transformer-nlp 将碎片化的前沿知识整合成结构化导航,大幅降低技术调研成本并加速项目落地进程。
运行环境要求
未说明
未说明

快速开始
自然语言处理中精选的 Transformer 与迁移学习 
本仓库收录了一份精心挑选的自然语言处理(NLP)机器学习(深度学习)资源列表,重点涵盖生成式预训练 Transformer(GPT)、基于 Transformer 的双向编码器表示(BERT)、注意力机制、Transformer 架构/网络、ChatGPT 以及 NLP 中的迁移学习。


Transformer (来源)
目录
展开目录
论文
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context by Zihang Dai, Zhilin Yang, Yiming Yang, William W. Cohen, Jaime Carbonell, Quoc V. Le and Ruslan Salakhutdinov.
- 使用智能缓存来改进 Transformer 中长期依赖的学习。关键结果:在 5 个语言建模基准测试上达到最先进水平,包括 One Billion Word (LM1B) 上的 ppl 为 21.8 和 enwiki8 上的 0.99。作者声称该方法更灵活,评估期间更快(加速 1874 倍),在小数据集上泛化良好,且对短序列和长序列建模有效。
- Conditional BERT Contextual Augmentation by Xing Wu, Shangwen Lv, Liangjun Zang, Jizhong Han and Songlin Hu.
- SDNet: Contextualized Attention-based Deep Network for Conversational Question Answering by Chenguang Zhu, Michael Zeng and Xuedong Huang.
- Language Models are Unsupervised Multitask Learners by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
- The Evolved Transformer by David R. So, Chen Liang and Quoc V. Le.
- 他们使用架构搜索来改进 Transformer 架构。关键在于使用进化算法并以 Transformer 本身作为初始种群的种子。该架构更好且更高效,特别是对于小尺寸模型。
- XLNet: Generalized Autoregressive Pretraining for Language Understanding by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
一种新的 NLP 预训练方法,在 20 个任务(如 SQuAD, GLUE, RACE)上显著优于 BERT。
“Transformer-XL 是一个移位模型(每个超列以下一个 token 结尾),而 XLNet 是一个直接模型(每个超列以相同 token 的上下文表示结尾)。” — Thomas Wolf。
-
一种巧妙的双重掩码和缓存算法。
这并非仅仅是向问题“投入更多算力 (compute)"。
- 作者们设计了一种巧妙的双重掩码加缓存机制 (dual-masking-plus-caching mechanism),以促使基于注意力的模型 (attention-based model) 学习从同一输入序列中所有其他词元 (tokens) 的因子分解顺序的所有可能排列中预测词元。
- 在期望上,模型学习收集每个词元两侧所有位置的信息来预测该词元。
- 例如,如果输入序列有四个词元 ["The", "cat", "is", "furry"],在一个训练步骤中,模型将在看到 "The" 后尝试预测 "is",然后是 "cat",然后是 "furry"。
- 在另一个训练步骤中,模型可能会先看到 "furry",然后是 "The",然后是 "cat"。
- 注意,原始序列顺序始终保留,例如,模型始终知道 "furry" 是第四个词元。
- 实现这一目标的掩码和缓存算法在我看来并非易事。
- 在各种任务中对 SOTA(State-of-the-Art,最先进)性能的改进是显著的 -- 参见论文中的表 2、3、4、5 和 6。
- CTRL: Conditional Transformer Language Model for Controllable Generation by Nitish Shirish Keskar, Richard Socher et al. [Code].
- PLMpapers - BERT (Transformer, transfer learning) 已经催化了预训练语言模型 (PLMs) 的研究并引发了许多扩展。此仓库包含一份关于 PLMs 的论文列表。
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer by Google Brain.
- 该团队使用统一的文本到文本转移 Transformer (T5) 模型对 NLP(自然语言处理)的迁移学习进行了系统研究,并推动其达到 SuperGLUE(接近人类基线)、SQuAD 和 CNN/DM 基准的 SOTA(最先进水平)。[Code].
- Reformer: The Efficient Transformer by Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya.
- “他们提出了降低 Transformer 时间和内存复杂度的技术,允许非常长的序列(64K)批次适配到一个 GPU 上。应为 Transformer 在 NLP 领域之外产生真正的影响力铺平道路。” — @hardmaru
- Supervised Multimodal Bitransformers for Classifying Images and Text (MMBT) by Facebook AI.
- A Primer in BERTology: What we know about how BERT works by Anna Rogers et al.
- “你是否正淹没在 BERT 论文中?”。该团队调查了超过 40 篇关于 BERT 的语言学知识、架构调整、压缩、多语言能力等的论文。
- tomohideshibata/BERT-related papers
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity by Google Brain. [Code] | [Blog post (unofficial)]
- 核心思想:架构在每个训练步骤和每个样本上使用一部分参数。优点:模型训练快得多。缺点:超大规模模型无法适应很多环境。
- An Attention Free Transformer by Apple.
- A Survey of Transformers by Tianyang Lin et al.
- Evaluating Large Language Models Trained on Code by OpenAI.
- Codex,一个驱动 GitHub Copilot 的 GPT 语言模型。
- 他们调查了模型的局限性(及优势)。
- 他们讨论了部署强大代码生成技术的潜在更广泛影响,涵盖安全、安全和经济方面。
- Training language models to follow instructions with human feedback by OpenAI. 他们将生成的模型称为 InstructGPT。ChatGPT 是 InstructGPT 的兄弟模型。
- LaMDA: Language Models for Dialog Applications by Google.
- Training Compute-Optimal Large Language Models by Hoffmann et al. at DeepMind. TLDR(简而言之):介绍了一种新的 70B LM(语言模型),名为 "Chinchilla",其表现优于更大的 LLMs(GPT-3, Gopher)。DeepMind 发现了廉价扩展大型语言模型的秘诀——为了达到计算最优,模型大小和训练数据必须同等扩展。这表明大多数 LLMs 严重缺乏数据且训练不足。鉴于 新的缩放定律,即使你将千万亿参数注入模型(GPT-4 都市传说),收益也无法弥补 4 倍更多的训练 token。
- Improving language models by retrieving from trillions of tokens by Borgeaud et al. at DeepMind - 该团队探索了一条通过互联网规模检索进行高效训练的替代路径。该方法被称为 RETRO,即“检索增强 Transformer (Retrieval Enhanced TRansfOrmers)"。使用 RETRO 模型不受训练期间所见数据的限制——它可以通过检索机制访问整个训练数据集。与具有相同参数数量的标准 Transformer 相比,这带来了显著的性能提升。尽管使用了 25 倍更少的参数,RETRO 在 Pile 数据集上获得了与 GPT-3 相当的性能。他们表明,随着检索数据库规模的增加,语言建模性能持续提升。[blog post]
- Scaling Instruction-Finetuned Language Models by Google - 他们发现,上述方面的指令微调极大地提高了各种模型类别(PaLM, T5, U-PaLM)、提示设置(零样本、少样本、思维链 (CoT))和评估基准上的性能。Flan-PaLM 540B 在多个基准上实现了 SOTA 性能。他们还公开发布了 Flan-T5 检查点,即使在比 PaLM 62B 大得多的模型面前,也能实现强大的少样本性能。
- Emergent Abilities of Large Language Models by Google Research, Stanford University, DeepMind, and UNC Chapel Hill.
- Nonparametric Masked (NPM) Language Modeling by Meta AI et al. [code] - 非参数模型拥有 500 倍更少的参数却在零样本任务上超越了 GPT-3。
至关重要的是,它没有针对固定输出词汇表的 softmax,而是拥有短语上的完全非参数分布。这与最近(2022 年)将非参数组件纳入参数化模型的一系列工作形成对比。
结果显示,NPM 在参数效率方面显著更高,性能优于高达 500 倍的更大参数化模型以及高达 37 倍的更大检索生成模型。
- Transformer models: an introduction and catalog by Xavier Amatriain, 2023 - 本文的目标是提供一份相当全面但简单的最流行 Transformer 模型的目录和分类。论文还介绍了 Transformer 模型最重要的方面和创新。
- Foundation Models for Decision Making: Problems, Methods, and Opportunities by Google Research et al., 2023 - 一份关于近期方法(即条件生成建模、RL(强化学习)、提示)的报告,这些方法将预训练模型(即 LMs)应用于实际决策智能体。模型可以服务于世界动态或引导决策。
- GPT-4 Technical Report by OpenAI, 2023.
- The Llama 3 Herd of Models by Llama Team, AI @ Meta, Jul 2024 - 这篇论文作为项目的常被忽视的组成部分,被证明同样重要,甚至更为关键,其重要性来得完全出乎意料。这篇论文本身也是一部杰作,提供了关于模型预训练和后训练流程的详细信息的宝库,提供了既深刻又实用的见解。[Discussion]
文章
BERT 与 Transformer
- 开源 BERT:自然语言处理 (NLP) 的先进预训练技术 来自 Google AI。
- 图解 BERT、ELMo 及其同类(NLP 如何攻克迁移学习)。
- 拆解 BERT 由 Miguel Romero 和 Francisco Ingham 撰写 —— 通过直观、简洁的相关概念解释,深入理解 BERT。
- Transformer-XL 轻量入门。
- 通用语言模型 由 OpenAI 研究科学家 Lilian Weng 撰写。
- XLNet 是什么以及为何它优于 BERT
- 排列语言建模 (Permutation Language Modeling) 目标是 XLNet 的核心。
- DistilBERT(来自 HuggingFace),随博客文章 更小、更快、更便宜、更轻:推出 DistilBERT,一种 BERT 的蒸馏版本 一同发布。
- ALBERT:用于语言表示自监督学习的轻量级 BERT 论文 来自 Google Research 和丰田技术研究所。—— 提高参数使用效率的改进:因子化嵌入参数化、跨层参数共享以及用于建模句间一致性的句子顺序预测 (SOP) 损失。[博客文章 | 代码]
- ELECTRA:将文本编码器作为判别器而非生成器进行预训练 由 Kevin Clark, Minh-Thang Luong, Quoc V. Le, 和 Christopher D. Manning 撰写 —— 一种类似 ALBERT 的 BERT 变体,且训练成本更低。他们仅使用一个 GPU 就训练出了超越 GPT 的模型;使用 1/4 的计算量即可达到 RoBERTa 的性能。它使用了一种名为替换令牌检测 (Replaced Token Detection, RTD) 的新预训练方法,该方法在从所有输入位置学习的同时训练双向模型。[博客文章 | 代码]
- ALBERT (轻量级 BERT) 可视化论文总结
- Cramming:一天内在单个 GPU 上训练语言模型(论文) (2022) —— 当社区大多数人都在询问如何将极端计算的极限推向何处时,我们提出了相反的问题:在仅仅一天的时间内,单个 GPU 能走多远?……通过缩放定律 (Scaling laws) 的视角,我们对近期的一系列训练和架构改进进行了分类,并讨论了它们在有限计算设置下的优点和实际适用性(或缺乏适用性)。
- BERT 和 T5 发生了什么?关于 Transformer 编码器、PrefixLM 和去噪目标 作者 Yi Tay,2024 年 7 月
简而言之,我们看不到任何扩展版的 xBERT 在运行:BERT 模型已被弃用,转而采用更灵活的去噪(自回归)T5 模型形式。这主要是由于范式统一,人们希望用一个通用模型执行任何任务(而不是特定任务模型)。同时,自回归去噪有时被折叠为因果语言模型 (Causal Language Models) 的辅助目标。
注意力机制
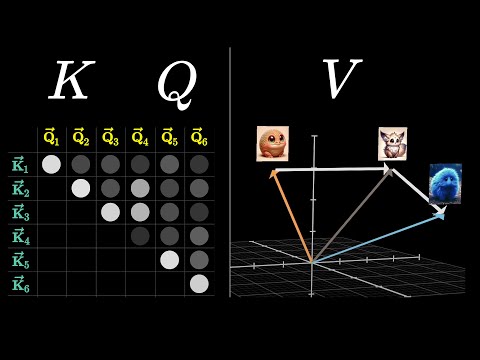
可视化注意力:Transformer 的心脏
- 神经机器翻译:联合学习对齐与翻译 by Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio, 2014 - Bahdanau 发明了基于内容的神经网络注意力,这现在是基于深度学习的自然语言处理 (NLP)(语言模型)中的核心工具。固定长度上下文向量设计的一个缺点是无法记住长句子。注意力机制 (Attention Mechanism) 应运而生以解决此问题。它旨在帮助在语言翻译中记忆长输入句子。[Bahdanau 值得称赞]
- Harvard NLP 小组注解版 Transformer - 进一步阅读以理解“Attention is all you need"论文。
- Attention?Attention! - OpenAI 的 Lilian Weng 撰写的注意力指南。
- 可视化神经机器翻译模型(带注意力的 Seq2seq 模型原理) by Jay Alammar, Udacity ML Engineer Nanodegree 讲师。
- 使 Transformer 网络更简单、更高效 - FAIR 发布了一个全注意力层以简化 Transformer 模型,并采用自适应注意力跨度方法以提高效率(减少计算时间和内存占用)。
- BERT 关注什么?对 BERT 注意力的分析论文 by Stanford NLP 小组。
- 快速 Transformer 解码:只需一个写入头 (论文) by Noam Shazeer, Google (2019) - 他们提出了一种称为 多查询注意力 (MQA) 的注意力类型变体。普通多头注意力机制每个头有一个查询、键和值;而多查询注意力则在所有不同的注意力“头”之间共享一个键和值。实际上,训练时间保持不变,但推理时的解码速度更快。MQA 显著提高了语言模型的性能和效率。用户可以获得约 10 倍的更好吞吐量,以及推理时约 30% 的更低延迟。然而,MQA 可能导致质量下降,而且仅为了更快的推理而训练单独的模型可能并不理想。2022 年,PaLM 是一种解码器风格的模型,其使用 MQA 是对 GPT 的一种有趣的架构改进。最近使用 MQA 的模型包括 TII 的 Falcon (2023)。
- GQA:从多头检查点训练通用多查询 Transformer 模型 by Google Research, 2023 - 他们 (1) 提出了一种利用原始预训练算力的 5%,将现有的多头注意力 (MHA) 模型升级训练为具有多查询注意力 (MQA) 的模型的技术,和 (2) 引入分组查询注意力 (GQA),这是 MQA 的一种泛化形式,使用中间数量(多于一个,少于查询头数量)的键值头。GQA 通过减少键值头的数量,实现了接近 MHA 的收益,同时拥有与 MQA 相当的推理速度。使用 MQA 的模型包括 Meta 的 Llama 2 (2023)。 [一些推文]
- 用于近无限上下文的块状 Transformer 环注意力 by UC Berkeley, 2023 - Ring Attention 是一种系统级优化技术,通过利用特定的硬件架构使精确的注意力计算更高效。
- 不留任何上下文:使用 Infini-attention 的高效无限上下文 Transformer by Google, 2024 - Infini-attention 具有额外的压缩记忆和线性注意力,用于处理无限长的上下文。他们训练了一个 1B 参数的 Transformer 模型,该模型在高达 5K 序列长度的密码实例上进行了微调,从而解决了 1M Token 输入长度的问题。Infini-attention 机制为 Transformer 语言模型提供了一种高效且强大的方法,用于处理非常长的上下文,而无需大幅增加内存或计算量。
- 检索头从机制上解释长上下文事实性 by Wenhao Wu, Yao Fu 等,2024 - 该论文解释了 LLM(大语言模型)实际上如何处理上下文窗口。研究发现:他们发现 LLM 意外地开发了检索头,这并非创作者明确编码的。[代码:一种统计计算 Transformer 模型中注意力头检索分数的算法]
Transformer 架构
- Transformer(转换器)博客文章。
- 图解 Transformer by Jay Alammar,Udacity 机器学习工程师纳米学位讲师。
- 观看 Łukasz Kaiser 的演讲,了解该模型及其细节。
- Transformer-XL:释放注意力模型的潜力 by Google Brain。
- 使用稀疏 Transformer 进行生成建模 by OpenAI - 一种对注意力机制 (attention mechanism) 的算法改进,可从比之前可能长 30 倍的序列中提取模式。
- 为强化学习稳定 Transformer 论文 by DeepMind 和 CMU - 他们提出了对原始 Transformer 和 XL 变体的架构修改,通过移动层归一化 (layer-norm) 并添加门控 (gating) 创建了门控 Transformer-XL (Gated Transformer-XL, GTrXL)。这大大提高了强化学习 (RL) 中的稳定性和学习速度(通过时间整合经验)。
- Transformer 家族 by Lilian Weng - 自从《Attention Is All You Need》论文发表以来,为了改进 Transformer 模型发生了许多新变化。本文就是关于这方面的内容。
- [DETR (**DE**tection **TR**ansformer):基于 Transformer 的端到端目标检测](https://ai.facebook.com/blog/end-to-end-object detection-with-transformers/) by FAIR - :fire: 计算机视觉尚未被 Transformer 革命席卷。与之前的目标检测系统相比,DETR 彻底改变了架构。(PyTorch 代码和预训练模型)。“对(非自回归)端到端检测的一次扎实尝试。锚框 + 非极大值抑制 (NMS) 是一团糟。我希望早在 ~2013 年检测就能实现端到端。” —— Andrej Karpathy
- 面向软件工程师的 Transformer - 这篇文章将对有兴趣学习机器学习模型 (ML models) 的软件工程师有帮助,特别是任何对 Transformer 可解释性 (interpretability) 感兴趣的人。这篇文章将逐步介绍一个(大部分)完整的 GPT 风格 Transformer 实现,但目标不是运行代码;相反,他们使用软件工程编程语言的语言来解释这些模型的工作原理,并阐述他们在进行可解释性工作时的某些观点。
- Pathways 语言模型 (PaLM):扩展至 5400 亿参数以实现突破性性能 - PaLM 是一个使用 Pathways 系统训练的密集仅解码器 (dense decoder-only) Transformer 模型,该系统使 Google 能够高效地在多个 TPU v4 Pods 上训练单个模型。解释笑话的例子令人瞩目。这表明它可以为需要复杂的多步逻辑推理、世界知识和深层语言理解组合的场景生成明确的解释。
- 通过状态空间增强 Transformer 实现高效的长序列建模 (论文) by 佐治亚理工学院和微软 - 注意力机制的二次计算成本限制了其在长序列中的实用性。现有的注意力变体提高了计算效率,但它们有效计算全局信息的能力有限。与 Transformer 模型并行,状态空间模型 (State Space Models, SSMs) 专为长序列量身定制,但不够灵活以捕捉复杂的局部信息。他们提出了 SPADE(状态空间增强 Transformer 的缩写),在长程领域 (Long Range Arena) 基准和各种语言模型 (LM) 任务上执行了各种基线,包括 Mega。这是一个有趣的方向。SSMs 和 Transformer 此前已被结合。
- DeepNet:将 Transformer 扩展至 1000 层 (论文) by 微软研究院 (2022) - 该团队引入了一种新的归一化函数 (DEEPNORM) 来修改 Transformer 中的残差连接 (residual connection),并表明模型更新可以以稳定的方式进行约束。这提高了深层 Transformer 的训练稳定性,并将模型深度与 Google Brain (2019) 的 Gpipe(管道并行,pipeline parallelism)相比扩大了数量级(10 倍)。(谁还记得 ResNet (2015) 对卷积网络 (ConvNet) 做了什么?)
- 一种长度外推的 Transformer (论文) by 微软 (2022) [TorchScale 代码] - 这提高了扩展 Transformer 的建模能力。
- 饥饿的河马 (H3):迈向使用状态空间模型 (SSMs) 的语言建模 (论文) by 斯坦福大学 AI 实验室 (2022) - 一种新的语言建模架构。它随上下文大小 (context size) 近乎线性扩展而非二次方。不再有固定的上下文窗口,人人皆可拥有长上下文。尽管如此,由于硬件利用率低,SSMs 仍然比 Transformer 慢。那么,它是 Transformer 的继任者吗?[推文]
- 使用投机采样加速大语言模型解码 (论文) by DeepMind (2023) - 投机采样 (Speculative sampling) 算法使得每次 Transformer 调用都能生成多个 token。在分布式设置下,使用 Chinchilla 实现了 2–2.5 倍的解码加速,同时不损害样本质量或对模型本身进行修改。
- Transformer 高效训练综述 (论文) by 莫纳什大学等,2023 - 第一个系统概述,涵盖 1) 计算效率;优化(即稀疏训练)和数据选择(即 Token 掩码),2) 内存效率(即数据/模型并行,卸载/使用外部内存)和 3) 硬件/算法协同设计(即高效注意力,硬件感知的低精度)。
- 无需捷径的深度 Transformer:修改自注意力以实现忠实信号传播 (论文) by DeepMind 等,2023
- Hyena 层次结构:迈向更大的卷积语言模型 (论文) by 斯坦福大学等,2023 - 注意力机制很棒。Hyena 是注意力的替代方案,通过使用隐式长卷积和门控,可以在10 倍更长的序列上学习,速度比优化的注意力快100 倍。[推文]
- FlashAttention:具有 IO 感知能力的快速且内存高效的精确注意力 (论文) by 斯坦福大学等,2022 - Transformer 变得更深更宽,但在长序列上训练它们仍然很困难。其核心的注意力层是计算和内存瓶颈:序列长度翻倍会导致运行时间和内存需求翻四倍。FlashAttention 是一种加速注意力并减少其内存占用的新算法——没有任何近似。它使得训练具有更长上下文的 LLMs 成为可能。[代码]
- 得出结论:用线性变换捷径 Transformer (论文) by Google Research 等,2023。[推文]
- CoLT5:使用条件计算更快的长程 Transformer (论文) by Google Research,2023 - 语言模型的 64K 上下文大小!这种方法在保持或提高与 LONGT5 相比的性能的同时,实现了更快的训练和推理。COLT5 的主要组件包括路由模块、条件前馈层和条件注意力层。路由模块为每个输入和组件选择重要的 token,而轻量分支以较低容量的操作处理所有 token,重分支仅对选定的重要 token 应用较高容量的操作。此外,COLT5 结合了多查询交叉注意力以加快推理速度,以及 UL2 预训练目标以改善长输入的上下文内学习能力。[推文]
- google-research/meliad - Meliad 库是正在开发的模型集合,作为 Google 持续进行的深度学习架构改进研究的一部分。该库目前包含几种 Transformer 变体,探索如何扩展流行的 Transformer 架构以更好地支持长序列上的语言建模。变体包括记忆 Transformer、带滑动窗口的 Transformer、块循环 Transformer 等。
- LongNet:将 Transformer 扩展至 10 亿 tokens (论文) by 微软研究院,2023。
- vLLM:使用分页注意力轻松、快速且廉价地服务 LLM by UC Berkeley 等,2023 - 吞吐量的提高来自于在几乎完全利用的 GPU 上节省显存 (VRAM)。
- LLM 中 10 万上下文窗口背后的秘密酱料:所有技巧汇集一处
- Unlimiformer:具有无限长度输入的长程 Transformer (论文) by CMU,2023。
- PaLM 2 技术报告 (PDF) by Google,2023。
- 深度混合 (MoD):动态分配基于 Transformer 的语言模型的计算 by Google DeepMind 等,2024 - MoD 方法在深度维度上扩展,同时保持浮点运算次数 (FLOPs) 不变(类似于专家混合 (Mixture of Experts, MoE) 在宽度维度上所做的方式)。MoD 模型可以学习将更复杂的 token 路由到更多层(类似于 MoE 中的专家可以专门针对某些领域)。该团队探讨了如何在不牺牲性能的情况下优化计算预算并提高效率。结果:MoD 以 66% 更快的训练速度匹配基线性能。现在的问题是,它能否扩展到超过 1B tokens。他们在 500M tokens 上进行了测试。[ELI5 版本:深度混合遇上专家混合]
- 通过位置插值扩展大语言模型的上下文窗口 by Meta Platforms,2023 - 位置插值 (Positional Interpolation, PI) 是一种有效且高效的方法,可以稳定地将基于 RoPE 的预训练大语言模型(如 LLaMA)的上下文窗口扩展到更长的长度(最高达 32768),同时保持最小微调(在千步以内)并保持性能。
- PoSE:通过位置跳过训练高效扩展 LLM 的上下文窗口 by Dawei Zhu 等,ICLR 2024 - PoSE 通过在固定上下文窗口内操纵位置索引来模拟训练期间的更长输入序列,而不是在完整的目标长度上进行训练。这使得训练长度与目标上下文长度解耦,与全长微调相比大大减少了内存和计算需求。PoSE 成功扩展了 LLaMA-1 以支持长达 128k tokens 的上下文长度,仅使用 2k 训练窗口,性能下降极小。此模型 使用 PoSE 将 Llama-3 8B 的上下文长度从 8k 扩展到 64k。PoSE 有潜力进一步扩展上下文长度,仅受限于推理内存,随着高效推理技术的不断改进。[代码:PoSE]
- 通过多 token 预测实现更好更快的大语言模型 by Meta 的 FAIR,2024 年 4 月 - 如果我们让语言模型预测几个 token 而不是仅仅下一个 token 会发生什么?他们表明,用多 token 预测任务替换下一个 token 预测任务可以导致代码生成性能显著提高,使用完全相同的训练预算和数据——同时将推理性能提高 3 倍。虽然类似的方法此前已用于微调以提高推理速度,但这项研究扩展到大型模型的预训练,展示了这些规模下的显著行为和结果。
- nGPT:在超球面上进行表示学习的归一化 Transformer by NVIDIA,2024 年 10 月 - 一种新颖的 Transformer 架构,其中所有向量(嵌入、MLP、注意力矩阵、隐藏状态)都归一化为单位范数并在超球面上运行。与标准 Transformer 相比,训练期间的收敛速度快 4-20 倍。通过强制归一化消除了对权重衰减的需求。归一化方法:矩阵向量乘法变为限制在 [-1,1] 的点积。架构更改:1) 注意力机制 - 归一化 QKV 投影矩阵,为 Q-K 点积引入可训练缩放因子,2) 层结构:为注意力块和 MLP 块引入可学习的“特征学习率”(α)。理论:可以在黎曼优化的背景下解释。优势:训练更稳定,下游任务性能提升,架构简化。
- 差分 Transformer by 微软研究院等,2024 年 10 月 - 他们在多个维度上呈现了相对于标准 Transformer 的显著改进,特别强调注意力效率和 LM 任务的实际应用。一种新的架构,通过减少对无关上下文的注意力来改进注意力机制。与标准 Transformer 相比,在需要更少参数和训练 token 的情况下实现了更好的性能。解决方案:引入了“差分注意力”机制,将注意力分数计算为两个独立 softmax 注意力的差异。这种减法抵消了噪声。可以使用现有的 FlashAttention 高效实现。扩展效率:仅需约 65% 的参数或训练 token 即可达到标准 Transformer 的性能。改进:1) 在长达 64K tokens 的长序列上表现更好。2) 更擅长发现文档中嵌入的关键信息。3) ICL:对提示词顺序排列更具鲁棒性。4) 减少注意力误分配,这是幻觉的主要原因。技术细节:包括逐头归一化以处理稀疏注意力模式等。未来:开发高效的低比特注意力内核,由于更稀疏的注意力模式,压缩 KV 缓存的潜力等。[收听 NotebookLM 播客]
生成式预训练 Transformer (GPT)
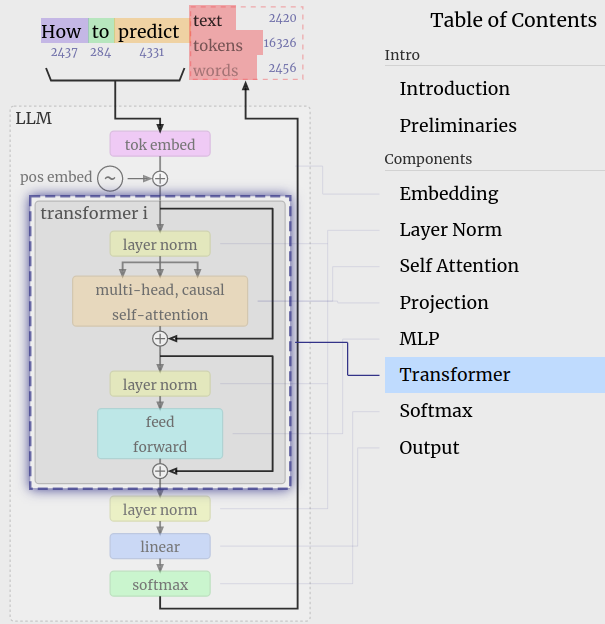
GPT 可视化
- 更好的语言模型及其影响。
- 利用无监督学习改进语言理解 - 这是对原始 OpenAI GPT 模型的概述。
- 🦄 如何使用迁移学习构建最先进的对话 AI by Hugging Face。
- 图解 GPT-2(可视化 Transformer 语言模型) by Jay Alammar。
- MegatronLM:使用 GPU 模型并行训练数十亿参数语言模型 by NVIDIA ADLR。
- OpenGPT-2:我们复现了 GPT-2,因为你也可以 - 作者在类似规模的文本数据集上训练了一个 15 亿参数的 GPT-2 模型,并报告了可与原始模型进行比较的结果。
- MSBuild 演示 OpenAI 生成式文本模型生成 Python 代码 [视频] - 该模型是在 GitHub 开源软件 (OSS) 仓库上训练的。该模型使用英文代码注释或仅函数签名来生成整个 Python 函数。很酷!
- GPT-3:语言模型是少样本学习者(论文) by Tom B. Brown (OpenAI) 等 - “我们训练了 GPT-3,这是一个拥有 1750 亿参数的自回归语言模型 :scream:,比任何之前的非稀疏语言模型多 10 倍,并在少样本设置下测试了其性能。”
- elyase/awesome-gpt3 - 关于 OpenAI GPT-3 API 的一系列演示和文章集合。
- GPT3 工作原理 - 可视化与动画 by Jay Alammar。
- GPT-Neo - 复制一个 GPT-3 规模的模型并免费开源。GPT-Neo 是“一种模型并行 GPT2 及类 GPT3 模型的实现,能够使用 mesh-tensorflow 库扩展到完整的 GPT3 规模(甚至更大!)”。[代码]。
- GitHub Copilot,由 OpenAI Codex 提供支持 - Codex 是 GPT-3 的衍生模型。Codex 将自然语言转换为代码。
- GPT-4 来自硅谷的传闻 - GPT-4 几乎准备好了。GPT-4 将是多模态的,接受文本、音频、图像以及可能的视频输入。发布时间窗口:12 月 - 2 月。#热议
- 新 GPT-3 模型:text-Davinci-003 - 改进点:
- 处理更复杂的意图 — 现在您可以更有创意地利用其功能。
- 更高质量的写作 — 更清晰、更具吸引力且更引人入胜的内容。
- 更长篇幅内容生成的能力更强。
- GPT-4 研究 落地页。
- GPT-3 和 GPT-3.5 系列模型的综合能力分析 by Fudan University 等,2023。
- 通用人工智能的火花:GPT-4 的早期实验 by Microsoft Research,2023 - 论文中有完全令人惊叹的例子。
ChatGPT
简而言之: ChatGPT 是一个对话式 Web 界面,由 OpenAI 最新的语言模型支持,该模型基于 GPT-3.5 系列(于 2022 年初完成训练)进行微调,针对对话进行了优化。它使用人类反馈强化学习 (RLHF) 进行训练;人类 AI 训练师通过扮演对话双方提供监督微调。
显然,它在遵循用户指令和上下文方面优于 GPT-3。人们已经注意到 ChatGPT 的输出质量似乎代表了相对于之前 GPT-3 模型的显著改进。
更多信息,请查看 ChatGPT 宇宙。这是我关于 ChatGPT 的所有理解的零散笔记,并存储了有关 ChatGPT 的一些有趣事物。
大型语言模型 (LLM)
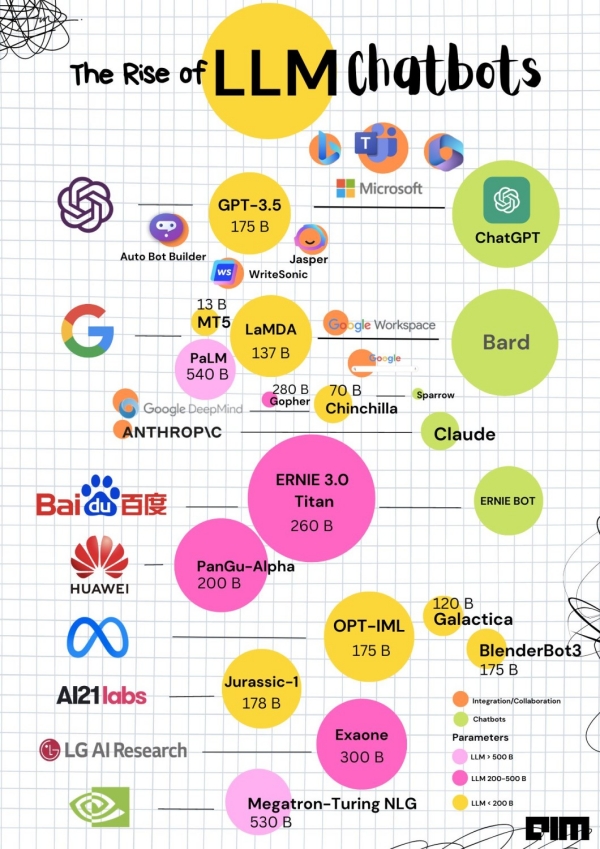
ChatGPT 与各类大语言模型 [^1]
- GPT-J-6B - 无法访问 GPT-3?这是 GPT-J —— 它的开源表亲。
- Fun and Dystopia With AI-Based Code Generation Using GPT-J-6B - 使用基于 AI 的代码生成进行娱乐与反乌托邦:在 GitHub Copilot 技术预览发布之前,数据科学家 Max Woolf 测试了 GPT-J-6B 的“编写”代码能力。
- GPT-Code-Clippy (GPT-CC) - GitHub Copilot 的开源版本。GPT-CC 模型是 GPT-2 和 GPT-Neo 的微调版本。
- GPT-NeoX-20B - 一个拥有 200 亿参数的模型,使用 EleutherAI 的 GPT-NeoX 框架训练。他们期望它在许多任务上表现良好。你可以在 GooseAI 沙盒上试用该模型。
- Metaseq - 用于处理 Open Pre-trained Transformers (OPT)(开放预训练 Transformer)的代码库。
- YaLM 100B by Yandex is a GPT-like pretrained language model with 100B parameters for generating and processing text. It can be used freely by developers and researchers from all over the world. - 由 Yandex 开发的 YaLM 100B 是一个类似 GPT 的预训练语言模型,拥有 1000 亿参数,用于生成和处理文本。它可被来自世界各地的开发者和研究人员免费使用。
- BigScience's BLOOM-176B from the Hugging Face repository [paper, blog post] - BLOOM 是一个拥有 1750 亿参数的语言处理模型,能够像 GPT-3 和 OPT-175B 一样生成文本。它被开发为多语言模型,故意在包含 46 种自然语言和 13 种编程语言的语料集上进行训练。
- bitsandbytes-Int8 inference for Hugging Face models - 你可以轻松地在单台机器上运行 BLOOM-176B/OPT-175B,而不会降低性能。如果属实,这可能是一个游戏规则改变者,使大型科技公司以外的人也能使用这些大语言模型(LLM)。
- WeLM: A Well-Read Pre-trained Language Model for Chinese (paper) by WeChat. [online demo] - 由微信开发的 WeLM:一个阅读广泛的中文预训练语言模型(论文)[在线演示]
- GLM-130B: An Open Bilingual (Chinese and English) Pre-Trained Model (code and paper) by Tsinghua University, China [article] - One of the major contributions is making LLMs cost affordable using int4 quantization so it can run in limited compute environments.
The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4×RTX 3090 (24G) or 8×RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models.
- 由中国清华大学开发的 GLM-130B:一个开放的 bilingual(中英双语)预训练模型(代码和论文)[文章] - 主要贡献之一是使用 int4 量化使大语言模型(LLM)成本可控,以便在有限的计算环境中运行。
生成的 GLM-130B 模型在广泛流行的英文基准测试中表现出显著优于 GPT-3 175B 的性能,而在 OPT-175B 和 BLOOM-176B 中未观察到这种性能优势。它还一致且显著地优于 ERNIE TITAN 3.0 260B——最大的中文语言模型——在相关基准测试中。最后,我们利用GLM-130B 的独特缩放特性实现了 INT4 量化,无需量化感知训练且几乎没有性能损失,使其成为 1000 亿规模模型中的第一个。更重要的是,该特性允许其在 4×RTX 3090 (24G) 或 8×RTX 2080 Ti (11G) GPU 上进行有效推理,这是使用 1000 亿规模模型所需的最经济的 GPU。
- Teaching Small Language Models to Reason (paper) - They finetune a student model on the chain of thought (CoT) outputs generated by a larger teacher model. For example, the accuracy of T5 XXL on GSM8K improves from 8.11% to 21.99% when finetuned on PaLM-540B generated chains of thought.
- 教导小语言模型进行推理(论文) - 他们在一个更大的教师模型生成的思维链(CoT)输出上微调学生模型。例如,当在 PaLM-540B 生成的思维链上微调时,T5 XXL 在 GSM8K 上的准确率从 8.11% 提高到 21.99%。
- ALERT: Adapting Language Models to Reasoning Tasks (paper) by Meta AI - They introduce ALERT, a benchmark and suite of analyses for assessing language models' reasoning ability comparing pre-trained and finetuned models on complex tasks that require reasoning skills to solve. It covers 10 different reasoning skills including logistic, causal, common-sense, abductive, spatial, analogical, argument and deductive reasoning as well as textual entailment, and mathematics.
- Meta AI 发布的 ALERT:将语言模型适应于推理任务(论文) - 他们引入了 ALERT,这是一个基准和分析套件,用于评估语言模型的推理能力,比较预训练和微调模型在需要推理技能解决的复杂任务上的表现。它涵盖了 10 种不同的推理技能,包括逻辑、因果、常识、溯因、空间、类比、论证和演绎推理,以及文本蕴含和数学。
- Evaluating Human-Language Model Interaction (paper) by Stanford University and Imperial College London - They find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
- 评估人类与语言模型交互(论文) - 斯坦福大学和伦敦帝国理工学院的研究人员发现,非交互式性能并不总是导致更好的人类-LM 交互,并且第一人称和第三方指标可能会产生分歧,这表明检查人类-LM 交互细微差别的重要性。
- Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor (paper) by Meta AI [data] - Fine-tuning a T5 on a large dataset collected with virtually no human labor leads to a model that surpassing the performance of models such as T0++ and Tk-Instruct across various benchmarks. These results demonstrate the potential of model-generated data as a cost-effective alternative to crowdsourcing for dataset expansion and diversification.
- Meta AI 发布的 Unnatural Instructions:用(几乎)零人力微调语言模型(论文)[数据] - 在通过几乎零人力收集的大型数据集上微调 T5,会导致一个在各种基准测试中超越 T0++ 和 Tk-Instruct 等模型性能的模型。这些结果证明了模型生成数据作为数据集扩展和多样化众包(crowdsourcing)的经济替代方案的潜力。
- OPT-IML (OPT + Instruction Meta-Learning) (paper) by Meta AI - OPT-IML is a set of instruction-tuned versions of OPT, on a collection of ~2000 NLP tasks — for research use cases. It boosts the performance of the original OPT-175B model using instruction tuning to improve zero-shot and few-shot generalization abilities — allowing it to adapt for more diverse language applications (i.e., answering Q’s, summarizing text). This improves the model's ability to better process natural instruction style prompts. Ultimately, humans should be able to "talk" to models as naturally and fluidly as possible. [code (available soon), weights released]
- Meta AI 发布的 OPT-IML (OPT + Instruction Meta-Learning) (论文) - OPT-IML 是一组针对约 2000 个自然语言处理(NLP)任务的指令微调版本的 OPT,用于研究用例。它使用指令微调来提升原始 OPT-175B 模型的性能,以改进 zero-shot 和 few-shot(少样本/零样本)泛化能力——使其能够适应更多样化的语言应用(即,回答问题、总结文本)。这提高了模型更好地处理自然指令风格提示的能力。最终,人类应该能够尽可能自然流畅地与模型“交谈”。[代码(即将发布),权重已发布]
- jeffhj/LM-reasoning - This repository contains a collection of papers and resources on reasoning in Large Language Models.
- 此存储库包含关于大语言模型(LLM)中推理的一系列论文和资源。
- Rethinking with Retrieval: Faithful Large Language Model Inference (paper) by University of Pennsylvania et al., 2022 - They shows the potential of enhancing LLMs by retrieving relevant external knowledge based on decomposed reasoning steps obtained through chain-of-thought (CoT) prompting. I predict we're going to see many of these types of retrieval-enhanced LLMs in 2023.
- 宾夕法尼亚大学等人在 2022 年发表的 Rethinking with Retrieval: Faithful Large Language Model Inference(论文) - 他们展示了通过基于思维链(CoT)提示获得的分解推理步骤检索相关外部知识来增强大语言模型(LLM)的潜力。我预测我们在 2023 年将看到许多这类检索增强的 LLM。
- REPLUG: Retrieval-Augmented Black-Box Language Models (paper) by Meta AI et al., 2023 - TL;DR: Enhancing GPT-3 with world knowledge — a retrieval-augmented LM framework that combines a frozen LM with a frozen/tunable retriever. It improves GPT-3 in language modeling and downstream tasks by prepending retrieved documents to LM inputs. [Tweet]
- Meta AI 等人于 2023 年发表的 REPLUG: Retrieval-Augmented Black-Box Language Models(论文) - TL;DR: 用世界知识增强 GPT-3 —— 一种检索增强 LM 框架,结合冻结的 LM 与冻结/可调的检索器。它通过将检索到的文档前置到 LM 输入中来改进 GPT-3 的语言建模和下游任务。[推文]
- Progressive Prompts: Continual Learning for Language Models (paper) by Meta AI et al., 2023 - Current LLMs have hard time with catastrophic forgetting and leveraging past experiences. The approach learns a prompt for new task and concatenates with frozen previously learned prompts. This efficiently transfers knowledge to future tasks. [code]
- Meta AI 等人于 2023 年发表的 Progressive Prompts: Continual Learning for Language Models(论文) - 当前的 LLM 难以应对灾难性遗忘和利用过去的经验。该方法学习新任务的提示,并将其与之前学习的冻结提示连接起来。这有效地将知识转移到未来任务。[代码]
- Large Language Models Can Be Easily Distracted by Irrelevant Context (paper) by Google Research et al., 2023 - Adding the instruction "Feel free to ignore irrelevant information given in the questions." consistently improves robustness to irrelevant context.
- Google Research 等人于 2023 年发表的大语言模型容易被无关上下文分心(论文) - 添加指令“请随意忽略问题中给出的无关信息。”持续提高对无关上下文的鲁棒性。
- Toolformer: Language Models Can Teach Themselves to Use Tools (paper) by Meta AI, 2023 - A smaller model trained to translate human intention into actions (i.e. decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction).
- Meta AI 于 2023 年发表的 Toolformer: Language Models Can Teach Themselves to Use Tools(论文) - 一个较小的模型,经过训练将人类意图转化为行动(即决定调用哪些 API、何时调用、传递什么参数,以及如何最好地将结果纳入未来的 token 预测中)。
- ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation (paper) by Baidu et al., 2021 - ERNIE 3.0 Titan is the latest addition to Baidu's ERNIE (Enhanced Representation through kNowledge IntEgration) family. It's inspired by the masking strategy of Google's BERT. ERNIE is also a unified framework. They also proposed a controllable learning algorithm and a credible learning algorithm. They apply online distillation technique to compress their model. To their knowledge, it is the largest (260B parameters) Chinese dense pre-trained model so far. [article]
- 百度等人于 2021 年发表的 ERNIE 3.0 Titan:探索更大规模的增强知识预训练以进行语言理解和生成(论文) - ERNIE 3.0 Titan 是百度 ERNIE(Enhanced Representation through kNowledge IntEgration)系列的最新成员。它受到 Google BERT 的掩码策略启发。ERNIE 也是一个统一框架。他们还提出了一种可控学习算法和一种可信学习算法。他们应用在线蒸馏技术来压缩他们的模型。据他们所知,这是迄今为止最大的(2600 亿参数)中文稠密预训练模型。[文章]
- Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models (paper) by Google Research, 2023 - Despite recent progress, it has been difficult to prevent semantic hallucinations in generative LLMs. One common solution to this is augmenting LLMs with a retrieval system and making sure that the generated output is attributable to the retrieved information.
- Google Research 于 2023 年发表的表征检索增强大语言模型的归因与流畅度权衡(论文) - 尽管最近取得了进展,但很难防止生成式 LLM 中的语义幻觉。解决这个问题的一个常见方法是用检索系统增强 LLM,并确保生成的输出可归因于检索到的信息。
- Augmented Language Models (ALMs): a Survey (paper) by Meta AI, 2023 - Augmenting language models with reasoning skills and the ability to use various, non-parametric external modules for context processing and outperform traditional LMs on several benchmarks. This new research direction has the potential to address interpretability, consistency and scalability issues.
- Meta AI 于 2023 年发表的增强语言模型(ALMs):综述(论文) - 用推理技能和利用各种非参数外部模块进行上下文处理的能力增强语言模型,并在多个基准测试中超越传统 LM。这一新的研究方向有望解决可解释性、一致性和可扩展性问题。
- A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT (paper) by MSU et al., 2023 - My remarks: this paper raises a lot of questions around the term "foundation models", i.e., what's the model bare minimum number of parameters to qualify as foundation? It sounds to me foundation models are an "invented" concept that doesn't have good validity.
- MSU 等人于 2023 年发表的预训练基础模型全面调查:从 BERT 到 ChatGPT 的历史(论文) - 我的评论:这篇论文引发了很多关于“基础模型”一词的问题,即,作为基础资格的最小参数数量是多少?在我看来,基础模型是一个“发明”的概念,没有很好的有效性。
- Multimodal Chain-of-Thought Reasoning in Language Models (paper) by Amazon Web Service et al., 2023 - The model outperform GPT-3.5 by 16% on the ScienceQA benchmark. This work is the first to study CoT reasoning in different modalities, language (text) and vision (images). Unfortunately, they never provide ablation study on how much of that performance gain was caused by the new modalities. [code]
- Amazon Web Service 等人于 2023 年发表的多模态思维链推理(论文) - 该模型在 ScienceQA 基准测试中比 GPT-3.5 高出 16%。这项工作首次研究了不同模态(语言/文本和视觉/图像)中的 CoT 推理。遗憾的是,他们从未提供消融实验来说明多少性能提升是由新模态引起的。[代码]
- RECITE: Recitation-Augmented Language Models (paper) by Google Research et al., ICLR 2023 - How can ChatGPT-like models achieve greater factual accuracy without relying on an external retrieval search engine? This paper shows that recitation can help LLMs generate accurate factual knowledge by reciting relevant passages from their own memory (by sampling) before producing final answers. The core idea is motivated by the intuition: recite-step that recollects relevant knowledge pieces helps answer-step (generation) better output. That's a recite-answer paradigm: first ask the LLM to generate the support paragraphs that contain the answer (knowledge-recitation) and then use it as additional prompt, along with the question to ask the LLM to generate the answer. They verify the effectiveness on four LLMs. They also show that recitation can be more effective than retrieval. This is important since having a retriever may lead to unpredictable behavior (i.e., Bing/Sydney). [code]
- Google Research 等人于 ICLR 2023 年发表的 RECITE:背诵增强语言模型(论文) - 像 ChatGPT 这样的模型如何在不依赖外部检索搜索引擎的情况下实现更高的事实准确性?这篇论文表明,背诵可以帮助 LLM 通过从自己的记忆(通过采样)中背诵相关段落来生成准确的事实知识,然后再产生最终答案。核心思想源于直觉:回顾步骤(recollect relevant knowledge pieces)有助于回答步骤(generation)更好地输出。这是一种背诵 - 回答范式:首先要求 LLM 生成包含答案的支持段落(知识背诵),然后将其作为额外提示,连同问题一起询问 LLM 生成答案。他们在四个 LLM 上验证了其有效性。他们还表明,背诵可能比检索更有效。这很重要,因为拥有检索器可能会导致不可预测的行为(即 Bing/Sydney)。[代码]
- LLaMA: Open and Efficient Foundation Language Models (paper) by Meta AI, 2023 - A collection of language models ranging from 7B to 65B parameters. LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B. This shows that smaller models trained with more data can outperform larger models. This is not contradictory to anything in the Chinchilla paper, because it's not compute-optimally trained. GPU hours for training 7B model=82,432, 65B model=1,022,362 :scream:. Total time spent for all models: 2048 A100-80GB GPU for a period of approximately 5 months. The 65B model cost something in the range of ~$1-4M. Access to the model will be granted on a case-by-case basis though. People interested can apply for access. (Mar 2: they just approved access to the models, llama-7B works in Colab cedrickchee/llama) [Takeaways: Tweet]
- Meta AI 于 2023 年发表的 LLaMA:开放和高效的基础语言模型(论文) - 一系列从 70 亿到 650 亿参数的语言模型。LLaMA-13B 在大多数基准测试中优于 GPT-3 (175B),LLaMA-65B 与最佳模型 Chinchilla70B 和 PaLM-540B 具有竞争力。这表明使用更多数据训练的较小模型可以胜过较大模型。这与 Chinchilla 论文中的任何内容都不矛盾,因为它不是按计算最优训练的。训练 7B 模型的 GPU 小时数=82,432,65B 模型=1,022,362 :scream:。所有模型花费的总时间:2048 A100-80GB GPU 大约 5 个月。65B 模型的成本大约在~$1-4M 范围内。不过,模型访问将根据具体情况授予。感兴趣的人可以申请访问。(3 月 2 日:他们刚刚批准了模型访问权限,llama-7B 可在 Colab 上使用 cedrickchee/llama)[要点:推文]
- Language Is Not All You Need: Aligning Perception with Language Models (paper) by Microsoft, 2023 - They introduce KOSMOS-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). The total number of parameters is about 1.6B.
- Microsoft 于 2023 年发表的语言并非你所需的一切:将感知与语言模型对齐(论文) - 他们介绍了 KOSMOS-1,一种多模态大语言模型(MLLM),可以感知通用模态,在上下文中学习(即 few-shot),并遵循指令(即 zero-shot)。参数总数约为 16 亿。
- Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback by Microsoft Research et al - LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. The architecture and data flow: 1) Retrieve evidence from external knowledge. 2) Context and reasoning chains. 3) Give to LLM (i.e., ChatGPT). 4) Verify hallucinations. 5) If hallucinate, give feedback and revise.
- Microsoft Research 等人发表的核实事实并重试:利用外部知识和自动反馈改进大语言模型 - LLM-Augmenter 显著减少了 ChatGPT 的幻觉,同时不牺牲其响应的流畅度和信息量。架构和数据流:1) 从外部知识检索证据。2) 上下文和推理链。3) 交给 LLM(即 ChatGPT)。4) 验证幻觉。5) 如果幻觉,给予反馈并修订。
- UL2: Unifying Language Learning Paradigms (paper) by Google Brain, 2022 - UL2 is a unified framework for pretraining models that are universally effective across datasets and setups. Takeaways: Objective matters way more than architecture. Mixture-of-Denoisers (MoD) is effective if you care about doing well on more than one type of tasks/settings. UL2 frames different objective functions for training language models as denoising tasks, where the model has to recover missing sub-sequences of a given input. During pre-training it uses Mixture-of-Denoisers (MoD) that samples from a varied set of such objectives, each with different configurations. MoD combines diverse pre-training paradigms together. They demonstrated that models trained using the UL2 framework perform well in a variety of language domains, including prompt-based few-shot learning and models fine-tuned for down-stream tasks. They open sourced UL2 20B model and checkpoints back in 2022. In 2023, they open sourced Flan-UL2 20B and released the weights. Check out: [blog post, Tweet]. I'm excited to see what the community does with this new model.
- Google Brain 于 2022 年发表的 UL2:统一语言学习范式(论文) - UL2 是一个统一的框架,用于预训练跨数据集和设置普遍有效的模型。要点:目标比架构重要得多。如果你关心在多种类型的任务/设置中表现出色,Denoisers 混合(MoD)是有效的。 UL2 将训练语言模型的不同目标函数框架化为去噪任务,其中模型必须恢复给定输入的缺失子序列。在预训练期间,它使用 Mixture-of-Denoisers (MoD),从这样的一组多样化的目标中进行采样,每个都有不同的配置。MoD 结合了不同的预训练范式。他们证明,使用 UL2 框架训练的模型在各种语言领域表现良好,包括基于提示的 few-shot 学习和为下游任务微调的模型。他们在 2022 年开源了 UL2 20B 模型和检查点。2023 年,他们开源了 Flan-UL2 20B 并发布了权重。查看:[博客文章, 推文]。我很期待社区如何使用这个新模型。
- Larger language models do in-context learning (ICL) differently (paper) by Google Research, 2023 - Overriding semantic priors when presented with enough flipped labels is an emergent ability of scale. LLMs learn better mappings when ICL labels are semantically unrelated to inputs (i.e., apple/orange, negative/positive). Fine-tuning to follow instruction helps both. [Tweet]
- Google Research 于 2023 年发表的大语言模型以不同方式执行上下文学习(ICL)(论文) - 当呈现足够的翻转标签时,覆盖语义先验是规模的一种涌现能力。当 ICL 标签与输入在语义上不相关时(即,苹果/橙子,负面/正面),LLM 学习更好的映射。微调以遵循指令有助于两者。[推文]
- The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset (paper) by Hugging Face et al., 2023 - Documents the data creation and curation efforts of Responsible Open-science Open-collaboration Text Source (ROOTS) corpus, a dataset used to train BLOOM. [Tweet]
- Hugging Face 等人于 2023 年发表的 BigScience ROOTS 语料库:一个 1.6TB 复合多语言数据集(论文) - 记录了负责任开源科学开放协作文本源(ROOTS)语料库的数据创建和策展工作,该语料库用于训练 BLOOM。[推文]
- PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing (paper) by Huawei Technologies, 2023 - They develop a system that trained a trillion-parameter language model on a cluster of Ascend 910 AI processors and MindSpore framework. This resulted in a 6.3x increase in training throughput through heterogeneous computing.
- 华为技术有限公司于 2023 年发表的 PanGu-Σ:迈向具有稀疏异构计算的万亿参数语言模型(论文) - 他们开发了一个系统,在 Ascend 910 AI 处理器集群和 MindSpore 框架上训练了万亿参数语言模型。这通过异构计算使训练吞吐量增加了 6.3 倍。
- Context-faithful Prompting for Large Language Models (paper) by USC et al., 2023
- USC 等人于 2023 年发表的上下文忠实提示为大语言模型(论文)
- Llama 2: Open Foundation and Fine-Tuned Chat Models (paper) by Meta AI, 2023 - Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations. It outperforms other open source language models on many benchmarks. License: The model and weights are available for free for research and commercial use. It is not an open source model, rather an open approach model — for commercial use, your product cannot have more than 700 million monthly active users and requires a form to get access. Llama-2-chat is the new addition and is created through using supervised fine-tuning and then iteratively refined using RLHF. [Nathan Lambert's summary of the paper]
- Meta AI 于 2023 年发表的 Llama 2:开放基础和微调聊天模型(论文) - Llama 2 预训练模型在 2 万亿 token 上训练,上下文长度是 Llama 1 的两倍。其微调模型已在超过 100 万个人类注释上训练。它在许多基准测试中优于其他开源语言模型。许可证:模型和权重可免费用于研究和商业用途。它不是一个开源模型,而是一个开放方法模型——对于商业用途,您的产品每月活跃用户不能超过 7 亿,并且需要填写表格才能获得访问权限。Llama-2-chat 是新加入的,是通过监督微调创建的,然后使用 RLHF(人类反馈强化学习)迭代优化。[Nathan Lambert 的论文摘要]
- Code Llama: Open Foundation Models for Code (paper) by Meta AI, 2023 - Code Llama is a family of LLMs for code based on Llama 2 providing SoTA performance among open models, infilling capabilities, support for large input contexts
Transformer 强化学习
基于人类反馈的强化学习(RLHF)。
- 图解基于人类反馈的强化学习 - 语言模型的最新进展(例如 ChatGPT)均得益于 RLHF 技术。
- 使用 RLHF 训练乐于助人且无害的助手(论文) 来自 Anthropic。[代码和红队测试数据, 推文]
- 后见之明使语言模型成为更好的指令遵循者(论文) 来自加州大学伯克利分校,2023 年 - 底层 RLHF 算法较为复杂,需要额外的训练流程来训练奖励和价值网络。他们考虑了一种替代方法:后见之明指令重标记(HIR):通过对原始反馈进行重新标记将其转换为指令,并训练模型以实现更好的对齐。
- 从 r 到 Q*:你的语言模型秘密是一个 Q 函数 来自斯坦福大学,2024 年 4 月 - 该论文弥合了两种 RLHF 方法之间的差距——标准 RLHF 设置和直接偏好优化(DPO)——通过将 DPO 推导为词元级 MDP(马尔可夫决策过程)中的一种通用逆 Q 学习算法。作者提供了关于 DPO 益处的实证见解,包括其执行信用分配的能力,并使用简单的束搜索展示了相对于基础 DPO 策略的改进,具有在多轮对话、推理和智能体系统中的潜在应用。
- 迭代推理偏好优化(IRPO) 来自 Jason Weston (Meta) 等人,2024 年 5 月 - Llama-2-70B-Chat 使用此方法在 GSM8K 上从 55.6% 提升至 81.6%。他们应用迭代偏好优化来改进推理:利用 LLM 生成思维链候选项,根据答案是否正确构建偏好对,使用 DPO + NLL(负对数似然)进行训练,然后重复。例如,想象一群人试图决定如何分配有限的预算。每个人对于资金如何使用都有自己的优先事项和偏好。使用 IRPO 方法,群体会进行往复讨论,每个人根据他人的论点和妥协调整自己的偏好。随着时间的推移,群体会收敛于一组大家都能接受的偏好,即使它最初并不是任何一个人想要的。
RLHF 工具
- lvwerra/TRL - 使用强化学习训练 Transformer 语言模型。
面向 ChatGPT 的开源努力:
- CarperAI/TRLX - 起源于 TRL 的一个分支。它允许你使用强化学习微调 Hugging Face 语言模型(基于 GPT2, GPT-NeoX),参数量高达 20B。由 CarperAI 带来(诞生于 EleutherAI,是 StabilityAI 家族的一部分组织)。CarperAI 正在开发生产就绪的开源 RLHF 工具。他们已经 宣布了首个开源“指令微调”语言模型的计划。
- allenai/RL4LMs - Allen AI 的语言模型强化学习(RL4LMs)。它是一个模块化 RL 库,用于将语言模型微调至人类偏好。
延伸阅读
- 如何构建 OpenAI 的 GPT-2:“过于危险而无法发布的 AI".
- OpenAI 的 GPT2——是媒体的炒作还是警钟?
- Transformer(转换器)如何打破 NLP(自然语言处理)排行榜 作者 Anna Rogers. :fire::fire::fire:
- 一篇关于当前主导 NLP 的大模型问题的精辟总结文章。
- 更大的模型 + 更多数据 = 机器学习研究中的进步 :question:
- 从零开始构建 Transformer 教程 作者 Peter Bloem.
- 使用 NVIDIA TensorRT 和 BERT(双向编码器表示)进行实时自然语言理解 在 Google Cloud T4 GPU(图形处理器)上实现了 2.2 毫秒的推理延迟。优化方案已在 GitHub 上开源。
- NLP 的“聪明汉斯”时刻已到来 作者 The Gradient.
- 神经网络中的语言、树与几何 —— 伴随论文《可视化与测量 BERT 的几何结构》的一系列解释性笔记,由 Google 的 People + AI Research (PAIR) 团队撰写。
- Transformer 基准测试:PyTorch 与 TensorFlow 作者 Hugging Face —— 针对广泛 Transformer 架构的推理时间(CPU 和 GPU 上)及内存使用情况的对比。
- Transformer 中表示的演变 —— 一篇通俗易懂的文章,展示了他们 EMNLP 2019 论文的见解。他们研究了在不同目标下训练的 Transformer 中,各个词元(Token)的表示是如何变化的。
- BERT 的黑暗秘密 —— 这篇文章探究了微调(Fine-tuned)后的 BERT 模型中的语言学知识。特别是,作者分析了具有某种语言学解释的自注意力(Self-attention)模式实际上有多少被用于解决下游任务。TL;DR(简而言之):他们未能找到证据表明具有语言学可解释性的自注意力图对下游性能至关重要。
- 首次使用 BERT 的视觉指南 —— Jay Alammar 撰写的关于在实践中使用 BERT 的教程,例如用于电影评论的情感分析。
- Turing-NLG:一个拥有 170 亿参数的语言模型 由 Microsoft 开发,在许多下游 NLP 任务上超越了最先进水平。如果没有 DeepSpeed 库(兼容 PyTorch)和 ZeRO 优化器 取得的突破,这项工作将无法实现,更多关于此的内容可参考随附的 博客文章。
- MUM(多任务统一模型):理解信息的新 AI 里程碑 由 Google 发布。
- 基于 Transformer 架构但更强大。
- 多任务意味着:支持文本和图像,75 种语言间的知识迁移,理解上下文并深入探讨主题,以及生成内容。
- GPT-3 不再是唯一的热门选择 —— GPT-3 去年(2020 年)迄今为止是该类最大的 AI 模型。现在?情况并非如此。
- OpenAI 的 API(应用程序编程接口)现已可用,无需排队 —— 无需等待即可访问 GPT-3。然而,应用必须在 上线 之前获得批准。此次发布还允许其审查申请、监控滥用情况,并更好地理解该技术的影响。
- GPT-3 的固有局限性 —— 如果你之前读过 Gwern 的 GPT-3 创意小说文章,那么文章中缺少的一件事就是被称为“重复/发散采样”的谜团:
当你生成分散式补全时,它们最终往往会陷入无意义内容的重复循环中。
对于使用 Copilot(GitHub Copilot)的用户来说,你们应该都经历过这种奇怪的现象:它一遍又一遍地生成相同的代码行或代码块。 17. 大规模语言建模:Gopher、伦理考量与检索 by DeepMind - 该论文分析了基于 Transformer(一种深度学习架构)的语言模型在不同规模下的性能表现——从拥有数千万参数的模型到名为 Gopher 的拥有 2800 亿参数的模型。 18. 使用 AlphaCode 进行编程竞赛 by DeepMind - AlphaCode 使用基于 Transformer 的语言模型来生成代码,这些代码能够针对需要理解算法的编程问题创造出新颖的解决方案。 19. 完全通过自然语言构建游戏和应用,使用 OpenAI 的 code-davinci 模型 - 作者仅通过告诉模型他们想要什么,就构建了几个小游戏和应用,完全没有触碰一行代码。 20. OpenAI 雇佣大量人类来修复 GPT 的错误答案以使 GPT-3 正常工作 21. GPT-3 可以运行代码 - 你提供输入文本和指令,GPT-3 会将它们转换为预期的输出。它在更改编码风格、在编程语言之间翻译、重构和添加文档等任务上表现良好。例如,将 JSON 转换为 YAML,将 Python 代码翻译成 JavaScript,改进函数的运行时复杂度。 22. 使用 GPT-3 解释代码工作原理 by Simon Willison. 23. Character AI 宣布正在建立全栈 AGI(通用人工智能)公司 这样你就可以利用对话式 AI 研究创建自己的 AI 来帮助你做任何事情。联合创始人 Noam Shazeer(共同发明了 Transformer,首次将其扩展到超级计算机,并开创了大规模预训练)和 Daniel de Freitas(领导了 LaMDA 的开发),所有这些都对最近的 AI 进步至关重要。 24. OpenAI 最新的 GPT-3 模型有多好? - 除了 ChatGPT,OpenAI 还发布了 text-davinci-003,这是一个经过强化学习微调的模型,在长文写作方面表现更好。例如,它可以以 Eminem 的风格解释代码。😀 25. OpenAI 竞争对手 Cohere 推出语言模型 API - 得到 AI 专家支持,他们的目标是将谷歌质量的预测语言带给大众。Aidan Gomez 在 Google Brain 联合撰写了一篇具有开创性的 2017 年论文,发明了一种被称为“Transformer"的概念。 26. 与 OpenAI 的 GPT-3 竞争的所有初创公司都需要解决相同的问题 - 去年,两家初创公司发布了各自专有的文本生成 API。AI21 Labs 于 2021 年 8 月推出了其拥有 1780 亿参数的 Jurassic-1,Cohere 则发布了一系列模型。Cohere 尚未披露其模型包含多少参数。……还有其他新兴初创公司正致力于解决同样的问题。Anthropic 是一家由前 OpenAI 员工组成的团队创立的 AI 安全和研究公司。几位研究人员离开 Google Brain 加入了由同事创办的两家新企业。一家名为 Character.ai,另一家名为 Persimmon Labs。 27. Cohere 希望构建终极 NLP(自然语言处理)平台 - 超越像 GPT-3 这样的生成式模型。 28. Transformer 推理算术 Cohere 的 ML Ops(机器学习运维)Carol Chen 的技术文章。本文详细阐述了关于 LLM(大语言模型)推理性能的少数原则推理,没有实验或复杂的数学。 29. 2022 年 AI 状态报告 - 关键要点:
- 新的独立研究机构正在迅速开源主要机构闭源的成果。
- AI 安全正吸引更多人才……但仍极度被忽视。
- 驱动 GitHub Copilot 的 OpenAI 的 Codex,凭借其在多行代码或直接通过自然语言指令完成代码的能力,给计算机科学界留下了深刻印象。这一成功激发了该领域更多的研究。
- DeepMind 重新审视了 LM(语言模型)缩放定律,发现当前的 LMs(语言模型)显著训练不足:鉴于其庞大的规模,它们使用的训练数据不够。他们使用 4.6 倍的数据训练了 Chinchilla(Gopher 的 4 倍小版本),发现 Chinchilla 在 BIG-bench 上优于 Gopher 和其他大型模型。
- 来自人类反馈的强化学习(RLHF)已成为微调 LLM(大语言模型)并将其与人类价值观对齐的关键方法。这涉及人类对给定输入采样的语言模型输出进行排名,利用这些排名学习人类偏好的奖励模型,然后使用此作为奖励信号,利用 RL(强化学习)微调语言模型。
- 缩放假设 by Gwern - 关于 GPT-3:元学习 (meta-learning)、缩放、影响和深层理论。
- AI 与语言的局限——仅用单词和句子训练的 AI 系统永远无法近似人类的理解 by Jacob Browning and Yann LeCun - 像 ChatGPT 这样的 LLM(大语言模型)能做什么和不能做什么,以及为什么 AGI(通用人工智能)尚未到来。
- 错误地使用 GPT-3 基础模型(Foundational Models):降低成本 40 倍,提高速度 5 倍 - 当微调模型时,需要注意几点。关于如何大规模使用这些模型,我们仍有很多要学。我们需要更好的指南。
- 下一代大型语言模型 - 它突出了 3 个新兴领域:1) 能够生成自己的训练数据以改进自身的模型,2) 能够自我事实核查的模型,以及 3) 大规模稀疏专家模型 (massive sparse expert models)。
- GPT-4 分析与预测 - 有些关联,在 "Bing Chat 明显且激进地未对齐" 帖子中,Gwern 思考 Bing Chat/Sydney 为何与 ChatGPT 如此不同,他的假设是:"Sydney 不是经过 RLHF(来自人类反馈的强化学习)训练的 GPT-3 模型,而是匆忙开发的 GPT-4 模型”。也有人认为 Sydney 在推理任务上的表现优于 ChatGPT/GPT-3.5,它可能是 GPT-4。
- Mosaic LLMs(第 2 部分):低于 50 万美元获得 GPT-3 质量(2022) - 他们声称他们的 Composer PyTorch 框架 简化了模型训练。现在有了 Colossal-AI 框架,我想知道他们的解决方案有多好。直到他们的用户实际训练它,我想一切都是纯假设。
- 我手工制作了一个 Transformer(无需训练!) (2023) - 手动制作一个 Transformer 来预测简单序列——不是通过训练一个,或使用预训练权重,而是在一个晚上内手工分配每个权重。
- 在 GCP(Google Cloud Platform)上为生产用例微调 Llama 3.1
教育类
- minGPT by Andrej Karpathy - 一个基于 PyTorch 的 GPT 重新实现,涵盖训练和推理。minGPT 力求小巧、简洁、可解释且具教育意义,因为目前可用的大多数 GPT 模型实现都略显繁杂。GPT 并非复杂的模型,该实现代码量约为 300 行。
- nanoGPT - 这是对 minGPT 的重写版本。仍在积极开发中。相关的持续视频讲座系列 Neural Networks: Zero to Hero,从头开始用代码构建 GPT,并致力于详尽说明一切。注意 Karpathy 的自下而上方法与 fast.ai 的教学风格相得益彰。(供参考,fast.ai 既有自上而下(“第一部分”)也有自下而上(“第二部分”)的方法。)
- 大型语言模型 (LLMs) 的视觉介绍 by Jay Alammar/Cohere - 对 LLMs 及其在语言处理中的一些应用的高层概览。涵盖了文本生成模型(如 GPT)和表示模型(如 BERT)。
- 解释 Transformer 语言模型的界面 by Jay Alammar - 通过查看神经网络内部的输入显著性和神经元激活来温和地介绍 Transformer 模型 (Transformer)。然而,我们对这些模型为何如此有效的工作原理的理解仍然落后于这些发展。
- 餐巾纸上的 GPT-3 架构
- PicoGPT: 用 60 行 NumPy 代码实现的 GPT
- 关于 Transformer 架构核心的视频解释 (2023) - 阅读了《图解 Transformer》,但仍觉得没有直观理解各种注意力组件的作用吗?在这个视频中,一种更具建设性的解释 Transformer 和注意力的方法可以帮助你更好地理解它:从简单的卷积神经网络 (CNN) 开始,作者将逐步带你了解将 CNN 转变为 Transformer 所需进行的所有更改。
- 黑客指南:语言模型 (视频) (2023) by Jeremy Howard, fast.ai - 快速浏览语言模型的所有基本思想,尽可能多地使用代码演示如何使用它们(包括开源模型和基于 OpenAI 的模型)。
教程
- 如何使用 Transformers 和 Tokenizers 从头开始训练新的语言模型 教程 by Hugging Face。 :fire:
AI 安全
可解释性 (Interpretability) 研究和 AI 对齐 (AI Alignment) 研究。
- Transformer Circuits Thread project by Anthropic - 我们能否将 Transformer 语言模型逆向工程为人类可理解的计算机程序?可解释性研究非常受益于交互式文章。作为其努力的一部分,除了论文外,他们还创建了其他几个资源,例如"Transformer 电路的数学框架”和 "叠加态的玩具模型"。
- 利用模型编写的评估发现语言模型行为 (论文) by Anthropic et al. - 他们使用 LLMs 自动生成评估。他们发现了 LLMs 随规模增大而变差的反向缩放新案例。他们还找到了人类反馈强化学习 (RLHF) 中反向缩放的最早示例之一,其中更多的 RLHF 会使 LLMs 变差。
- Transformer 通过梯度下降 (Gradient Descent) 学习上下文内 (In-context) 知识 (论文) by J von Oswald et al. [AI Alignment Forum]
- 为什么 GPT 能进行上下文内学习?语言模型秘密执行梯度下降作为元优化器 (Meta-Optimizers) (论文) by Microsoft Research.
- 大型语言模型中的认知偏差
- Tracr: 编译后的 Transformer 作为可解释性的实验室 (论文) (2023) by DeepMind - TRACR (TRAnsformer Compiler for RASP) 是一个编译器,用于将 RASP 程序(Transformer 的领域特定语言 (DSL))转换为类似 GPT 模型的权重。通常,我们训练 Transformer 将其算法编码到权重中。有了 TRACR,我们走相反的方向;直接从显式代码编译权重。直接这样做是为了什么?加速可解释性研究。可以把它看作 Transformer 上的形式化方法(来自软件工程)。检查可解释性工具提供的解释是否正确可能很困难。[Tweet, code]
- Yann LeCun 对当前(自回归)LLMs 的坚定看法 (推文)
- AI 安全的核心观点:何时、为何、何事及如何 by Anthropic, 2023.
- 界限内的个性化:大型语言模型与个性化反馈对齐的风险分类和政策框架 by University of Oxford, 2023. [Tweet]
- GPTs 就是 GPTs:早期审视大型语言模型对劳动力市场的潜在影响 (论文) by OpenAI et al., 2023 - 该论文认为 GPT 是一种通用技术。
视频
BERTology
- XLNet 详解 by NLP Breakfasts.
- 清晰的解释。还涵盖了双流自注意力概念。
- NLP 的未来 by 🤗
- 关于当前自然语言处理 (NLP) 迁移学习中正在发生的事情、限制和未来方向的密集概览。
- Transformer 神经网络架构详解 by AI Coffee Break with Letitia Parcalabescu.
- 高层解释,最适合不熟悉 Transformer 的人。
注意力 (Attention) 和 Transformer 网络
- Sequence to Sequence Learning Animated (Inside Transformer Neural Networks and Attention Mechanisms) by learningcurve.
通用
- Trials and tribulations of OPT-175B training by Susan Zhang at Meta - 在这次演讲中,他们回顾了 OPT-175B 的开发生命周期,涵盖了大规模部署时面临的基础设施和训练收敛挑战,以及未来解决这些问题的方法。令人惊叹的是他们竟然完成了如此壮举。关键要点:数据至关重要!对神经网络的基本原理(LR (学习率), SGD (随机梯度下降) 等)和工程实践有着超深的理解。甚至花费了比平时更多的时间盯着损失曲线。理解 Chinchilla 的缩放定律,即随着规模扩大,新架构/算法是如何工作的。 [LLM (大型语言模型) training log]
官方 BERT 实现
- google-research/bert - BERT 的 TensorFlow 代码和预训练模型。
社区提供的 Transformer 实现
GPT 和/或 BERT 的实现。
PyTorch 和 TensorFlow
- 🤗 Hugging Face Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides state-of-the-art general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, CTRL...) for Natural Language Understanding (NLU) (自然语言理解) and Natural Language Generation (NLG) (自然语言生成) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch. [Paper]
- spacy-transformers - 一个封装 Hugging Face 的 Transformers 的库,用于提取特征以驱动 NLP 管道。它还计算一个对齐,以便 Transformer 特征可以关联回实际单词,而不仅仅是 wordpieces (词元)。
- FasterTransformer - Transformer 相关优化,包括 BERT 和 GPT。此仓库提供了一个脚本和配方来运行高度优化的基于 Transformer 的 encoder (编码器) 和 decoder (解码器) 组件,并由 NVIDIA 进行测试和维护。
PyTorch
- codertimo/BERT-pytorch - Google AI 2018 BERT PyTorch 实现。
- innodatalabs/tbert - BERT 机器学习模型的 PyTorch 移植版。
- kimiyoung/transformer-xl - Transformer-XL 论文关联的代码仓库。
- dreamgonfly/BERT-pytorch - “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”中的 BERT PyTorch 实现。
- dhlee347/pytorchic-bert - Google BERT 的 PyTorch 实现。
- pingpong-ai/xlnet-pytorch - Google Brain XLNet 的 PyTorch 实现。
- facebook/fairseq - RoBERTa:Facebook AI Research 提出的鲁棒优化的 BERT 预训练方法。在 GLUE, SQuAD 和 RACE 上取得 SoTA (最先进) 结果。
- NVIDIA/Megatron-LM - 持续研究大规模训练 Transformer 语言模型,包括:BERT。
- deepset-ai/FARM - 面向行业的简单且灵活的 transfer learning (迁移学习)。
- NervanaSystems/nlp-architect - Intel AI 的 NLP Architect。除其他库外,它提供了 Transformer 模型的 quantized (量化) 版本和高效的训练方法。
- kaushaltrivedi/fast-bert - 基于 BERT 的 NLP 模型的超级简易库。基于 🤗 Transformers 构建并受 fast.ai 启发。
- NVIDIA/NeMo - Neural Modules 是 NVIDIA 用于对话式 AI 的工具包。他们正尝试 improve speech recognition with BERT post-processing (使用 BERT post-processing (后处理) 改进语音识别)。
- facebook/MMBT from Facebook AI - Multimodal (多模态) transformers 模型,可以接受一个 Transformer 模型和一个 computer vision (计算机视觉) 模型用于分类图像和文本。
- dbiir/UER-py from Tencent and RUC - PyTorch 开源预训练模型框架及预训练模型库(更侧重于中文)。
- lucidrains/x-transformers - 一个简单但完整的 full-attention (全注意力) Transformer,包含来自各种论文的有前景的实验特性(适合学习目的)。有一篇 2021 年的论文总结了 Transformer 修改,Do Transformer Modifications Transfer Across Implementations and Applications?。
Keras
- Separius/BERT-keras - 带有预训练权重的 BERT Keras 实现。
- CyberZHG/keras-bert - 可加载官方预训练模型以进行特征提取和预测的 BERT 实现。
- bojone/bert4keras - 为 Keras 设计的轻量级 BERT 重新实现。
TensorFlow
- guotong1988/BERT-tensorflow - BERT:用于语言理解的深度双向 Transformer 预训练。
- kimiyoung/transformer-xl - Transformer-XL 论文关联的代码仓库。
- zihangdai/xlnet - XLNet 论文关联的代码仓库。
Chainer
- soskek/bert-chainer - “BERT:用于语言理解的深度双向 Transformer 预训练”的 Chainer 实现。
其他
- llama.cpp - Facebook 的 LLaMA 模型的 C/C++ 移植版。
- Cformers - 具有 C 后端的高速 CPU inference (推理) SoTA Transformer。
- Transformers.js - 在浏览器中运行 🤗 Transformers。
- Alpaca.cpp - 在本地设备上运行快速的类 ChatGPT 模型。
- LLaMA compatible port
- Apple Neural Engine (ANE) Transformers - 针对 Apple Silicon (苹果硅芯片) 优化的 Transformer 架构。
NLP(自然语言处理)中的迁移学习(Transfer Learning)
NLP 终于有了进行迁移学习的方法,其效果可能堪比计算机视觉(Computer Vision)。
正如 Jay Alammar 所说:2018 年是处理文本的 Machine Learning(机器学习)模型的一个转折点(更准确地说,是 Natural Language Processing(自然语言处理)或简称 NLP)。我们对于如何最好地表示单词和句子以捕捉潜在含义和关系的概念理解正在迅速演变。此外,NLP 社区一直在提出极其强大的组件,你可以免费下载并在自己的模型和流程(pipelines)中使用它们(这被称为 NLP 的 ImageNet 时刻,引用了多年前类似的发展如何加速了计算机视觉任务中机器学习的发展)。
这一发展的最新里程碑之一是 BERT 的 发布,该事件被 描述 为标志着 NLP 新时代的开始。BERT 是一个打破了多项记录的语言处理能力模型。在描述该模型的论文发布后不久,团队也开源了该模型的代码,并提供了已在大规模数据集上 Pre-trained(预训练)好的模型版本可供下载。这是一个重大的发展,因为它使得任何构建涉及语言处理的机器学习模型的人都可以使用这个强大的组件作为现成的部分——节省了从头开始训练语言处理模型所需的时间、精力、知识和资源。
BERT 建立在 NLP 社区最近涌现的许多巧妙想法之上——包括但不限于 Semi-supervised Sequence Learning(半监督序列学习)(由 Andrew Dai 和 Quoc Le 提出),ELMo(由 Matthew Peters 以及来自 AI2 和 UW CSE 的研究人员提出),ULMFiT(由 fast.ai 创始人 Jeremy Howard 和 Sebastian Ruder 提出),OpenAI transformer(由 OpenAI 研究人员 Radford, Narasimhan, Salimans, 和 Sutskever 提出),以及 Transformer(Vaswani et al)。
ULMFiT:确立 NLP 中的迁移学习
[ULMFiT 引入了方法,有效地利用模型在预训练期间学到的大量内容] —— 不仅仅是 Embeddings(嵌入),也不仅仅是 Contextualized Embeddings(上下文嵌入)。ULMFiT 引入了一种语言模型和一个过程,可以有效地针对各种任务 Fine-tune(微调)该语言模型。
NLP 终于有了进行迁移学习的方法,其效果可能堪比计算机视觉。
MultiFiT:高效的多语言语言模型微调 由 Sebastian Ruder 等人撰写。MultiFiT 扩展了 ULMFiT,使其更高效且更适合英语之外的语言建模。(EMNLP 2019 论文)
书籍
- Transfer Learning for Natural Language Processing - 一本关于迁移学习技术的实用入门书,能够为您带来巨大的 NLP 模型改进。
- Natural Language Processing with Transformers 作者:Lewis Tunstall, Leandro von Werra, 和 Thomas Wolf - 这本实用书籍展示了如何使用 Hugging Face Transformers 来训练和扩展这些大型模型。作者采用动手实践的方法,教你了解 Transformers 的工作原理以及如何将它们集成到你的应用中。
其他资源
展开其他资源
- hanxiao/bert-as-service - 使用预训练的 BERT(双向编码器表示)模型将变长句子映射为固定长度向量。
- brightmart/bert_language_understanding - 用于语言理解的深度双向 Transformer 预训练:预训练 TextCNN。
- algteam/bert-examples - BERT 示例。
- JayYip/bert-multiple-gpu - 支持多 GPU(图形处理器)的 BERT 版本。
- HighCWu/keras-bert-tpu - BERT 实现,可在 TPU(张量处理单元)上加载官方预训练模型进行特征提取和预测。
- whqwill/seq2seq-keyphrase-bert - 为 https://github.com/memray/seq2seq-keyphrase-pytorch 的编码器部分添加 BERT。
- xu-song/bert_as_language_model - 作为语言模型的 BERT,源自 Google 官方 BERT 实现的分支。
- Y1ran/NLP-BERT--Chinese version
- yuanxiaosc/Deep_dynamic_word_representation - 用于深度动态词表示 (DDWR) 的 TensorFlow 代码和预训练模型。它结合了 BERT 模型和 ELMo 的深度上下文词表示。
- yangbisheng2009/cn-bert
- Willyoung2017/Bert_Attempt
- Pydataman/bert_examples - 一些 BERT 示例。
run_classifier.py基于 Google BERT 用于 Kaggle Quora 不真诚问题分类挑战。run_ner.py基于瑞金医院 AI 竞赛第一季以及由 BERT 编写的 NER。 - guotong1988/BERT-chinese - 用于中文语言理解的深度双向 Transformer 预训练。
- zhongyunuestc/bert_multitask - 多任务。
- Microsoft/AzureML-BERT - 使用 Azure Machine Learning 对 BERT 进行 fine-tuning(微调)的端到端指南。
- bigboNed3/bert_serving - 导出 BERT 模型用于服务部署。
- yoheikikuta/bert-japanese - 用于日语文本的带有 SentencePiece 的 BERT。
- nickwalton/AIDungeon - AI Dungeon 2 是一个完全由 AI 生成的文字冒险游戏,使用 OpenAI 最大的 15 亿参数 GPT-2 模型构建。这是一款前所未有的游戏,允许你输入并对你能想象到的任何行动做出反应。
- turtlesoupy/this-word-does-not-exist - “这个词不存在”是一个项目,允许人们从头开始训练一种 GPT-2 变体来编造单词、定义和示例。我们从未见过如此真实的伪造文本。
工具
- jessevig/bertviz - 用于可视化 Transformer(变换器)模型中注意力机制的工具。
- FastBert - 一个简单的深度学习库,允许开发者和数据科学家训练和部署基于 BERT 的 NLP(自然语言处理)任务模型,从文本分类开始。FastBert 的工作灵感来自 fast.ai。
- gpt2tc - 一个使用 GPT-2 语言模型完成和压缩文本的小程序。它没有外部依赖,不需要 GPU 且速度很快。提供了最小的模型(1.17 亿参数)。也可以下载更大的模型。(无需等待名单,无需注册)。
任务
命名实体识别 (NER)
展开 NER
- kyzhouhzau/BERT-NER - 使用 Google BERT 进行 CoNLL-2003 NER。
- zhpmatrix/bert-sequence-tagging - 中文序列标注。
- JamesGu14/BERT-NER-CLI - 带逐步设置指南的 BERT NER 命令行测试器。
- sberbank-ai/ner-bert
- mhcao916/NER_Based_on_BERT - 该项目基于 Google BERT 模型,这是一个中文 NER。
- macanv/BERT-BiLSMT-CRF-NER - 使用 Bi-LSTM-CRF 模型配合 Google BERT 微调的 NER 任务 TensorFlow 解决方案。
- ProHiryu/bert-chinese-ner - 使用预训练语言模型 BERT 进行中文 NER。
- FuYanzhe2/Name-Entity-Recognition - Lstm-CRF, 网格-CRF, 近期 NER 相关论文。
- king-menin/ner-bert - NER 任务解决方案 (BERT-Bi-LSTM-CRF),基于 Google BERT https://github.com/google-research。
分类
展开分类
- brightmart/sentiment_analysis_fine_grain - 使用 BERT 进行多标签分类;来自 AI Challenger 的细粒度情感分析。
- zhpmatrix/Kaggle-Quora-Insincere-Questions-Classification - Kaggle 基线——微调 BERT 和基于 tensor2tensor 的 Transformer 编码器解决方案。
- maksna/bert-fine-tuning-for-chinese-multiclass-classification - 使用 Google 预训练模型 BERT 微调以进行中文多类分类。
- NLPScott/bert-Chinese-classification-task - BERT 中文分类实践。
- fooSynaptic/BERT_classifer_trial - 中文语料库分类的 BERT 试验。
- xiaopingzhong/bert-finetune-for-classfier - 在构建自己的分类数据集的同时微调 BERT 模型。
- Socialbird-AILab/BERT-Classification-Tutorial - 教程。
- malteos/pytorch-bert-document-classification - 使用知识图谱嵌入丰富 BERT 以进行文档分类 (PyTorch)。
文本生成
展开文本生成
- asyml/texar - 文本生成及更多领域的工具包。Texar 是一个通用文本生成工具包,在此也实现了 BERT(双向编码器表示)用于分类,并通过结合 Texar 的其他模块实现文本生成应用。
- 即插即用语言模型:一种受控文本生成的简单方法 (PPLM) 论文,由 Uber AI 发布。
问答 (QA)
展开问答
- matthew-z/R-net - 基于 PyTorch(深度学习框架)的 R-net,包含 BERT 和 ELMo(上下文嵌入)。
- vliu15/BERT - 用于问答的 BERT 的 TensorFlow(机器学习库)实现。
- benywon/ChineseBert - 这是一个专门用于问答的中文 BERT 模型。
- xzp27/BERT-for-Chinese-Question-Answering
- facebookresearch/SpanBERT - 在 SQuAD(斯坦福问答数据集)上进行问答;通过表示和预测跨度来改进预训练。
知识图谱
展开知识图谱
- sakuranew/BERT-AttributeExtraction - 使用 BERT 进行知识图谱中的属性提取。微调和特征提取。基于 BERT 的微调和特征提取方法用于提取百度百科条目的知识属性。
- lvjianxin/Knowledge-extraction - 基于中文知识的抽取。基线:bi-LSTM(双向长短期记忆网络)+CRF(条件随机场);升级:BERT 预训练。
许可证
展开许可证
此仓库包含多种内容;部分由 Cedric Chee 开发,部分来自第三方。第三方内容按照这些方提供的许可证分发。
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer.
The content developed by Cedric Chee is distributed under the following license:
代码
此仓库中的代码,包括上述笔记本中的所有代码示例,均在 MIT 许可证 下发布。更多信息请访问 开放源代码促进会。
文本
文本内容根据 CC-BY-SA 4.0 许可证发布。更多信息请访问 知识共享。
[^1]: AIM 制作的信息图。
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。