bitpredict
bitpredict 是一个专注于利用机器学习进行高频比特币价格预测的开源项目。它旨在解决加密货币市场中短期价格波动难以捉摸的难题,通过深度分析 Bitfinex 交易所的市场微观结构数据(如每秒订单簿快照和成交记录),来预判未来 30 秒的价格中点走势。
该项目非常适合量化交易开发者、金融数据科学家以及对算法交易感兴趣的研究人员使用。其核心技术亮点在于构建了一套精细的特征工程体系:不仅考量买卖价差和订单不平衡度,还创新性地引入“幂次加权”算法来衡量买卖双方的力量对比与价格倾向,并结合不同时间窗口内的交易频次、均价变化及主动买卖盘力度等多维指标。基于这些特征,bitpredict 训练了梯度提升(Gradient Boosting)模型,并在严格的时间序列验证下取得了可观的样本外拟合效果。此外,项目还内置了理论交易策略的回测框架,能够直观展示在不同阈值下的模拟收益表现,为用户探索高频交易策略提供了坚实的数据基础和实验工具。
使用场景
某高频量化交易团队正在开发针对比特币的秒级套利策略,急需从 Bitfinex 交易所的微观订单流中挖掘短期价格波动规律。
没有 bitpredict 时
- 特征工程耗时巨大:团队需手动编写复杂代码计算买卖盘不平衡度、加权价格偏差及激进交易者指标,开发周期长达数周。
- 预测精度难以突破:仅依靠简单的移动平均或趋势线分析,无法捕捉毫秒级的市场微观结构变化,模型在测试集上的 R-squared 值极低。
- 回测验证缺乏依据:缺乏基于滑动时间窗口的严谨验证机制,策略在历史数据上表现良好,但实盘时因过拟合频繁亏损。
- 决策延迟严重:人工处理每秒快照数据效率低下,导致交易信号生成滞后,错失 30 秒内的最佳入场时机。
使用 bitpredict 后
- 自动化特征提取:bitpredict 直接内置了幂次不平衡、攻击者成交量差等高级特征算法,将原本数周的特征工程压缩至小时级。
- 显著提升预测能力:利用梯度提升模型训练,成功在样本外数据上实现了 0.0846 的 R-squared 值,精准锁定未来 30 秒的中点价格趋势。
- 严谨的策略仿真:通过内置的滑动窗口回测框架,团队可快速验证不同阈值下的理论收益,有效避免了实盘前的盲目部署。
- 实时信号输出:系统能即时处理实时订单流并输出交易信号,支持在检测到微小价差(如 0.01%)时立即触发模拟持仓,大幅降低延迟。
bitpredict 通过将复杂的微观市场数据转化为可操作的高频预测信号,帮助交易团队在激烈的比特币市场中建立了显著的时效与精度优势。
运行环境要求
未说明
未说明
快速开始
bitpredict
摘要
本项目旨在利用市场微观结构数据进行高频比特币价格预测。数据集由Bitfinex交易所每秒一次的买卖盘快照以及已成交交易记录组成,数据采集始于2015年8月20日。
我们使用一系列特征工程构建的特征来训练梯度提升模型,并在历史数据和实时数据上模拟了一种理论交易策略。
目标
预测的目标是30秒后的中价。中价定义为最佳买价与最佳卖价的平均值。
特征
宽度
这是最佳买价与最佳卖价之间的差值。
功率失衡
这是一个衡量买卖单之间不平衡程度的指标。对于每笔订单,其权重计算为到当前中价距离的倒数,并取某个幂次方。然后用加权卖单总量减去加权买单总量。分别采用2、4和8次幂,生成三个独立的特征。
功率调整价格
这与功率失衡类似,但使用的是到当前中价的距离(未取倒数)作为权重,计算价格的加权平均值。接着计算该加权平均值相对于当前中价的变化百分比。同样采用2、4和8次幂,生成三个独立的特征。
成交次数
这是过去X秒内的成交次数。通过设置30、60、120和180秒的偏移量,生成四个独立的特征。
成交均价
这是当前中价与过去X秒内成交价格平均值之间的变化百分比。通过设置30、60、120和180秒的偏移量,生成四个独立的特征。
侵略性
这是一个衡量过去X秒内买方或卖方谁更具侵略性的指标。如果买入订单的时间晚于卖出订单,则视为买入侵略;反之则为卖出侵略。将卖出侵略产生的总成交量减去买入侵略产生的总成交量。通过设置30、60、120和180秒的偏移量,生成四个独立的特征。
趋势
这是过去X秒内成交价格的线性趋势。通过设置30、60、120和180秒的偏移量,生成四个独立的特征。
模型
上述特征被用于训练梯度提升模型。模型采用滑动的10万秒窗口进行验证,其中测试数据始终位于训练数据之后。每次迭代时,训练数据的长度都会逐步增加。我们以平均的样本外R²作为评估指标。在使用四周数据的情况下,模型实现了0.0846的样本外R²。
回测结果
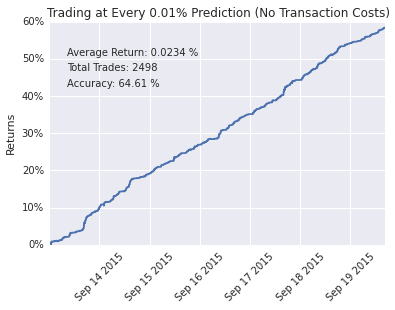
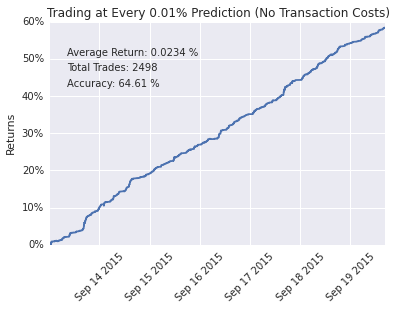
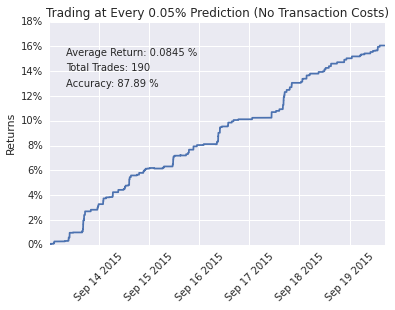
为了可视化模型的表现,我们实现了一个理论交易策略:当模型预测值超过某一阈值时,即启动一个持续30秒的模拟仓位,且同一时间仅允许持有一个仓位。理论执行以中价成交,不考虑交易成本。
不同阈值下的回测结果如下所示。我们使用三周的数据进行训练,再用一周的数据进行理论交易。
实时结果
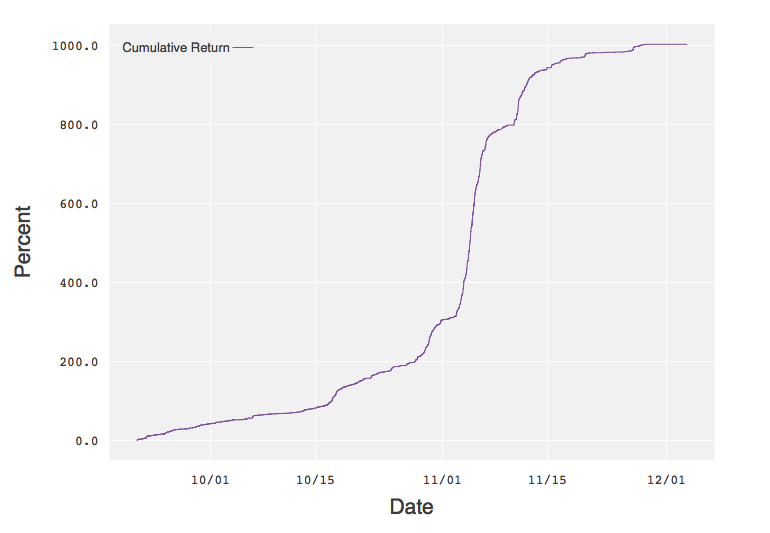
我们将模型应用于实时数据,并通过一个Web应用展示了理论结果。以下是交易阈值为0.01%时的实时表现。
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。