lstm-char-cnn-tensorflow
lstm-char-cnn-tensorflow 是一个基于 TensorFlow 框架实现的神经语言模型开源项目,复现了论文《Character-Aware Neural Language Models》中的核心算法。它旨在解决传统语言模型在处理未登录词(OOV)及拼写变体时的局限性,通过引入字符级特征来提升模型对文本的理解能力。
该项目的独特技术亮点在于其混合架构:首先利用字符级卷积神经网络(CNN)提取单词内部的细粒度特征,接着通过高速公路网络(Highway Network)优化信息流动,最后结合循环神经网络(RNN/LSTM)捕捉长距离上下文依赖。这种“字符 + 单词”的双层级设计,使得模型既能理解词汇含义,又能感知构词规律。
需要注意的是,根据项目说明,当前版本在复现原论文性能指标上存在一定差距,且主要支持 Python 2.7 或 3.3+ 环境。因此,lstm-char-cnn-tensorflow 更适合对自然语言处理(NLP)有深入研究需求的算法工程师、科研人员或高阶开发者使用。它可以作为学习字符级建模、CNN 与 RNN 融合架构的教学代码,或作为进一步改进和实验的基础底座,而不建议直接用于对精度要求极高的生产环境。
使用场景
某自然语言处理团队正在为金融风控系统构建一个能够精准识别生僻词和拼写错误的文本预测模型,以应对用户输入的不规范数据。
没有 lstm-char-cnn-tensorflow 时
- 生僻词处理能力弱:传统的词级模型遇到训练集中未出现的专有名词或错别字时,只能将其标记为未知符(UNK),导致语义理解完全中断。
- 特征提取粒度粗糙:仅依赖预训练的词向量,无法捕捉单词内部的形态学特征(如词根、词缀),难以区分形近词的细微差别。
- 模型泛化成本高:每当业务领域出现新词汇(如新的金融衍生品名称),必须重新收集大量语料并从头训练整个词表,迭代周期长达数周。
- 长序列依赖丢失:简单的循环神经网络在处理长文本时容易遗忘早期信息,难以在复杂的句子结构中保持上下文连贯性。
使用 lstm-char-cnn-tensorflow 后
- 字符级感知增强:利用字符级卷积神经网络(CNN)直接编码单词内部结构,即使面对从未见过的生僻词或拼写错误,也能通过字符组合推断出合理语义。
- 深层特征融合:结合高速公路网络(Highway Network)与 LSTM,有效融合了字符局部特征与句子全局上下文,显著提升了对复杂金融术语的解析精度。
- 动态适应新词:无需维护固定的词表,模型天然具备处理任意字符串的能力,新业务词汇出现时可即时生效,将模型更新周期从周缩短至小时级。
- 长程依赖优化:深层递归结构更好地捕捉了长距离依赖关系,在生成风控报告或预测用户意图时,逻辑连贯性大幅提升。
lstm-char-cnn-tensorflow 通过引入字符感知的混合架构,彻底解决了传统模型在面对非规范文本和新词汇时的“失明”问题,让语言模型更具鲁棒性和适应性。
运行环境要求
未说明
未说明

快速开始
字符感知神经语言模型
字符感知神经语言模型 的 TensorFlow 实现。作者的原始代码可在 这里 找到。
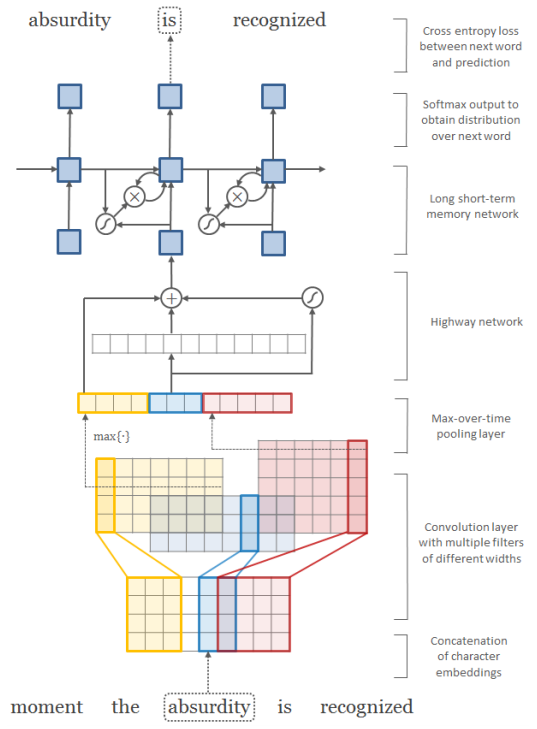
该实现包含:
- 词级和字符级卷积神经网络
- 高速公路网络
- 循环神经网络语言模型
当前实现存在性能问题。请参阅 #3。
前提条件
- Python 2.7 或 Python 3.3+
- TensorFlow
使用方法
使用 ptb 数据集训练模型:
$ python main.py --dataset ptb
测试现有模型:
$ python main.py --dataset ptb --forward_only True
查看所有训练选项,运行:
$ python main.py --help
将打印出:
usage: main.py [-h] [--epoch EPOCH] [--word_embed_dim WORD_EMBED_DIM]
[--char_embed_dim CHAR_EMBED_DIM]
[--max_word_length MAX_WORD_LENGTH] [--batch_size BATCH_SIZE]
[--seq_length SEQ_LENGTH] [--learning_rate LEARNING_RATE]
[--decay DECAY] [--dropout_prob DROPOUT_PROB]
[--feature_maps FEATURE_MAPS] [--kernels KERNELS]
[--model MODEL] [--data_dir DATA_DIR] [--dataset DATASET]
[--checkpoint_dir CHECKPOINT_DIR]
[--forward_only [FORWARD_ONLY]] [--noforward_only]
[--use_char [USE_CHAR]] [--nouse_char] [--use_word [USE_WORD]]
[--nouse_word]
optional arguments:
-h, --help 显示此帮助信息并退出
--epoch EPOCH 训练的轮数 [25]
--word_embed_dim WORD_EMBED_DIM
词嵌入矩阵的维度 [650]
--char_embed_dim CHAR_EMBED_DIM
字符嵌入矩阵的维度 [15]
--max_word_length MAX_WORD_LENGTH
单词的最大长度 [65]
--batch_size BATCH_SIZE
批次大小 [100]
--seq_length SEQ_LENGTH
展开的时间步数 [35]
--learning_rate LEARNING_RATE
学习率 [1.0]
--decay DECAY SGD 的衰减率 [0.5]
--dropout_prob DROPOUT_PROB
Dropout 层的概率 [0.5]
--feature_maps FEATURE_MAPS
CNN 中特征图的数量
[50,100,150,200,200,200,200]
--kernels KERNELS CNN 核的宽度 [1,2,3,4,5,6,7]
--model MODEL 要训练和测试的模型类型 [LSTM, LSTMTDNN]
--data_dir DATA_DIR 数据目录名称 [data]
--dataset DATASET 数据集名称 [ptb]
--checkpoint_dir CHECKPOINT_DIR
保存检查点的目录名称 [checkpoint]
--forward_only [FORWARD_ONLY]
只进行前向传播为真,训练为假 [False]
--noforward_only
--use_char [USE_CHAR]
使用字符级语言模型 [True]
--nouse_char
--use_word [USE_WORD]
使用词级语言模型 [False]
--nouse_word
但更多选项可在 models/LSTMTDNN 和 models/TDNN 中找到。
性能
未能复现论文中的结果(2016年2月12日)。如果您正在寻找能够复现论文结果的代码,请参阅 https://github.com/mkroutikov/tf-lstm-char-cnn。
宾夕法尼亚树库 (PTB) 语料库测试集上的困惑度。
| 名称 | 字符嵌入 | LSTM 隐藏单元 | 论文(Y Kim 2016) | 本仓库 |
|---|---|---|---|---|
| LSTM-Char-Small | 15 | 100 | 92.3 | 进行中 |
| LSTM-Char-Large | 15 | 150 | 78.9 | 进行中 |
作者
Taehoon Kim / @carpedm20
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。