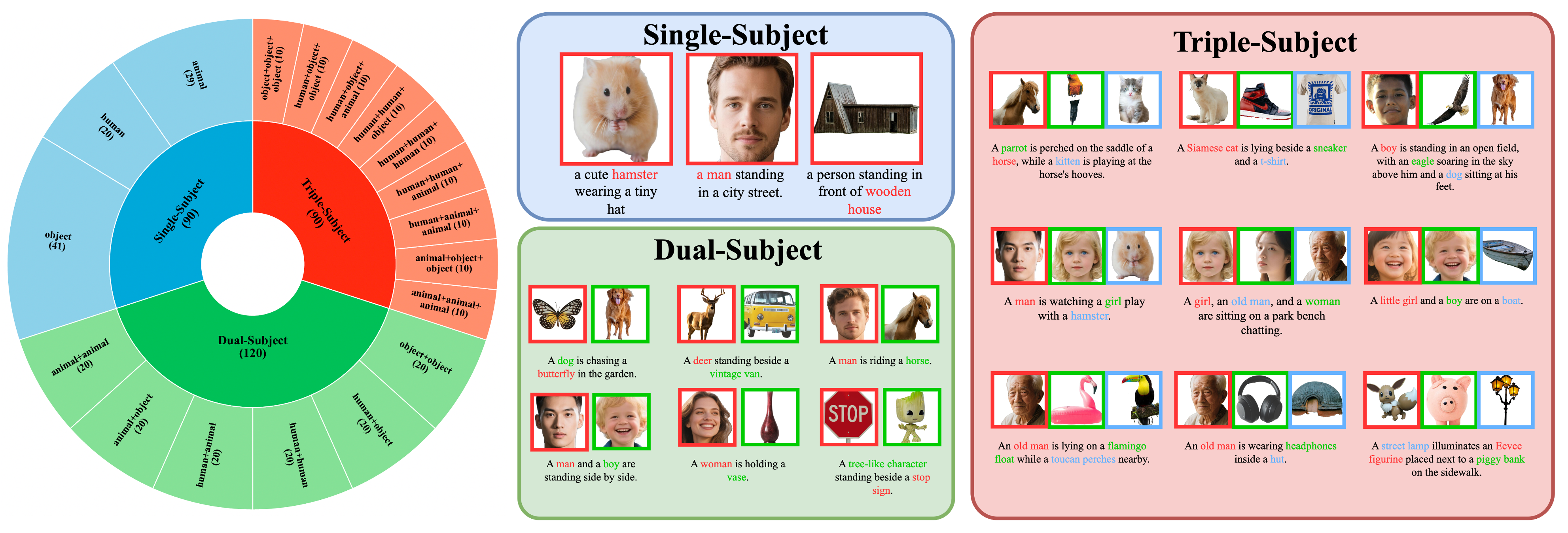
XVerse
XVerse 是一款专注于多主体图像生成的开源 AI 工具,旨在解决传统模型在合成复杂场景时难以同时保持多个角色身份一致性与独立控制语义属性(如姿势、风格、光照)的难题。它通过一种创新的 DiT 调制技术,将参考图像转化为针对特定文本流的偏移量,从而在不干扰整体图像潜在特征的前提下,实现对画面中每个主体的精准、独立操控。这意味着用户可以轻松生成高保真且可编辑的图像,确保多个角色在同一场景中既保留各自独特的面部特征,又能灵活调整动作与环境互动。
该工具特别适合从事个性化内容创作的设计师、需要高质量多主体合成数据的研究人员,以及希望探索前沿生成技术的开发者。其技术亮点在于不仅支持高精度的身份保持,还兼容量化扩散模型,并通过分组卸载等技术优化,使得在 16GB 显存的设备上也能流畅运行,大幅降低了使用门槛。此外,项目配套发布了专用的评测基准数据集与在线演示,方便用户快速上手体验或进行二次开发。无论是构建复杂的叙事场景,还是进行精细的角色定制,XVerse 都能提供强大而灵活的支持。
使用场景
某电商视觉团队需要为“双十一”大促快速生成一组包含多位特定模特、穿着不同风格服饰且姿态各异的商品宣传海报。
没有 XVerse 时
- 身份一致性难以维持:当尝试让同一位模特出现在多张不同背景或动作的图片中时,传统方法往往导致模特面部特征发生漂移,看起来像不同的人。
- 多主体控制混乱:一旦画面中出现两位以上特定人物,模型容易混淆特征,导致“张冠李戴”,无法精准指定谁穿什么衣服或摆什么姿势。
- 属性编辑相互干扰:调整其中一个人的姿态或光影时,往往会意外改变另一个人的身份特征或整体画面的语义逻辑。
- 重绘成本极高:为了修正上述错误,设计师不得不反复进行局部重绘(Inpainting)和后期 PS 修补,单张海报耗时数小时。
使用 XVerse 后
- 身份精准锁定:利用 DiT 调制技术,XVerse 能将参考图转化为独立的令牌偏移量,确保每位模特在任何场景下都能保持高度一致的面部 identity。
- 独立的多主体操控:支持对画面中的每个主体进行解耦控制,可分别指定模特 A 穿红衣挥手、模特 B 穿蓝衣微笑,互不干扰。
- 语义属性自由编辑:在保持人物身份不变的前提下,能独立调整每个人的姿态、光照风格甚至服饰细节,实现高保真的精细化编辑。
- 工作流大幅提速:无需繁琐的后期修补,输入提示词与参考图即可直接生成可用素材,将单张海报的制作周期从小时级缩短至分钟级。
XVerse 通过解耦身份与语义属性的控制难题,让复杂的多角色商业图像生成变得既精准又高效。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 标准模式需 24GB+ 显存
- 开启低显存模式 (--use_low_vram) 需 24GB (支持 2 个条件图) 或 16GB (支持 3 个条件图,--use_lower_vram)
- 使用量化模型 (GGUF/BNB) 配合 CPU 卸载可在 24GB-32GB 显存下运行多条件生成
- 安装命令指定 CUDA 12.4
未说明 (建议系统内存充足以支持 CPU 卸载模式)
快速开始
XVerse:通过DiT调制实现身份与语义属性的一致性多主体控制
![]()
🔥 最新消息
- 2025年9月19日:🎉 恭喜!XVerse已被NeurIPS 2025接收!🎉
- 2025年7月18日:支持量化扩散模型,并新增分组卸载功能,可在16GB显存下运行XVerse模型。
- 2025年7月10日:发布Hugging Face Space演示。
- 2025年7月8日:支持低显存推理,可在24GB显存下运行XVerse模型。
- 2025年6月26日:代码已公开!

📖 简介
XVerse提出了一种全新的多主体图像合成方法,能够在不破坏整体图像潜在空间或特征的情况下,对各个主体进行精确且独立的控制。我们通过将参考图像转换为针对特定标记的文本流调制偏移量来实现这一目标。
这一创新使得高保真、可编辑的图像生成成为可能,您可以稳健地控制个体主体特征(身份)及其语义属性。XVerse显著提升了个性化和复杂场景生成的能力。
⚡️ 快速入门
环境要求与安装
首先,安装必要的依赖项:
# 创建名为XVerse的conda环境,Python版本为3.10.16
conda create -n XVerse python=3.10.16 -y
# 激活XVerse环境
conda activate XVerse
# 安装适合您硬件的PyTorch版本
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
# 使用pip安装requirements.txt中列出的依赖
pip install -r requirements.txt
# 安装flash-attn
pip install flash-attn==2.7.4.post1 --no-build-isolation
# 更新httpx版本
pip install httpx==0.23.3
接下来,下载所需的检查点文件:
cd checkpoints
bash ./download_ckpts.sh
cd ..
重要提示:您还需要从InsightFace_Pytorch下载人脸识别模型model_ir_se50.pth,并将其直接放置在./checkpoints/文件夹中。
之后,您可以将模型路径导出为环境变量。这一步骤确保后续的推理脚本能够正确找到所需的模型:
export FLORENCE2_MODEL_PATH="./checkpoints/Florence-2-large"
export SAM2_MODEL_PATH="./checkpoints/sam2.1_hiera_large.pt"
export FACE_ID_MODEL_PATH="./checkpoints/model_ir_se50.pth"
export CLIP_MODEL_PATH="./checkpoints/clip-vit-large-patch14"
export FLUX_MODEL_PATH="./checkpoints/FLUX.1-dev"
export DPG_VQA_MODEL_PATH="./checkpoints/mplug_visual-question-answering_coco_large_en"
export DINO_MODEL_PATH="./checkpoints/dino-vits16"
本地Gradio演示
要在本地运行交互式Gradio演示,请执行以下命令:
python run_gradio.py
输入设置说明
Gradio演示提供了多个参数来控制您的图像生成过程:
- Prompt:指导图像生成的文本描述。
- 生成高度/宽度:使用滑块设置输出图像的尺寸。
- Weight_id/ip:调整这些权重参数。较高的值通常能提升主体一致性,但可能会略微影响生成图像的自然度。
- latent_lora_scale和vae_lora_scale:控制LoRA比例。与Weight_id/ip类似,较大的LoRA值可以提高主体一致性,但可能降低图像自然度。
- vae_skip_iter_before和vae_skip_iter_after:配置VAE跳过迭代次数。跳过更多步骤可以使图像更自然,但可能会影响主体一致性。
输入图像
演示对输入图像提供了详细的控制选项:
- 展开面板:点击“Input Image X”以显示每张图像的选项。
- 上传图像:点击“Image X”上传您希望使用的参考图像。
- 图像描述:在“Caption X”输入框中输入描述。您也可以点击“Auto Caption”自动生成描述。
- 检测与分割:点击“Det & Seg”对上传的图像进行检测和分割。
- 裁剪人脸:使用“Crop Face”自动裁剪图像中的人脸。
- ID复选框:勾选或取消勾选“ID or not”,以决定是否对该输入图像使用与身份相关的权重。
⚠️ 重要使用说明:
- Prompt构建:主文本提示必须包含您为每个启用的图像在“Image Description”字段中输入的确切文本。如果提示中缺少该描述,生成将失败。
- 示例:如果您上传两张图像,并分别设置其描述为“红发男子”(图像1)和“蓝眼睛女子”(图像2),那么您的主提示可能是:“一位
红发男子在公园里与蓝眼睛女子并肩行走。”- 您随后只需简单地写下主提示:“
ENT1在公园里与ENT2并肩行走。”代码会在生成前将这些占位符自动替换为完整的描述文本。- 启用的图像:只有处于展开状态(未折叠)的图像才会被送入模型。折叠的图像面板将被忽略。
单样本推理
要对单个样本进行推理,请运行以下命令。您可以通过调整提示词、种子值、输出尺寸等参数来自定义图像生成:
python inference_single_sample.py --prompt "ENT1戴着一顶小帽子" --seed 42 --cond_size 256 --target_height 768 --target_width 768 --weight_id 3 --weight_ip 5 --latent_lora_scale 0.85 --vae_lora_scale 1.3 --vae_skip_iter_s1 0.05 --vae_skip_iter_s2 0.8 --images "sample/hamster.jpg" --captions "一只仓鼠" --idips false --save_path "generated_image_1.png" --num_images 1
对于使用多张条件图像的推理,请使用下面的命令。这允许您在生成过程中纳入多张参考图像。请确保 --images、--captions 和 --ids 的数量一致:
python inference_single_sample.py --prompt "ENT1和ENT2一起站在公园里。" --seed 42 --cond_size 256 --target_height 768 --target_width 768 --weight_id 2 --weight_ip 5 --latent_lora_scale 0.85 --vae_lora_scale 1.3 --vae_skip_iter_s1 0.05 --vae_skip_iter_s2 0.8 --images "sample/woman.jpg" "sample/girl.jpg" --captions "一位女性" "一位女孩" --idips true true --save_path "generated_image_2.png" --num_images 1
⚡️ 低显存推理
将模块卸载到 CPU
- 在单样本推理或运行 Gradio 演示时,您可以通过添加参数
--use_low_vram True或--use_lower_vram True来启用低显存模式。 use_low_vram允许在配备 24GB 显存的 GPU 上进行最多两张条件图像的推理。use_lower_vram允许在配备 16GB 显存的 GPU 上进行最多三张条件图像的推理。- 请注意,CPU 卸载会显著降低推理速度,因此仅在必要时才应启用。
量化扩散模型
- 您可以从 这里 下载量化模型,并将其放入 checkpoints 文件夹中。使用 bnb-nf4 量化模型,在 32GB 显存环境下可以进行单条件推理;而在 24GB 显存环境下,则可通过启用 CPU 卸载功能来实现三条件推理。您需要修改
FLUX_MODEL_PATH环境变量,并添加参数--dit_quant None。 - 您也可以从 这里 下载 GGUF 量化模型,并将其放入 checkpoints 文件夹中。使用此 GGUF 量化模型,在 32GB 显存环境下可进行两条件推理;而在 24GB 显存环境下,则可通过启用 CPU 卸载功能实现四条件推理。您可以使用以下命令进行推理:
export FLUX_TRANSFORMERS_PATH="./checkpoints/FLUX.1-dev-gguf/flux1-dev-Q3_K_S.gguf"
export FLUX_MODEL_PATH="./checkpoints/FLUX.1-dev"
python inference_single_sample.py --prompt "ENT1和ENT2一起站在公园里。" --seed 42 --cond_size 256 --target_height 768 --target_width 768 --weight_id 3 --weight_ip 5 --latent_lora_scale 0.7 --vae_lora_scale 1.2 --vae_skip_iter_s1 0.05 --vae_skip_iter_s2 0.8 --images "sample/woman.jpg" "sample/girl.jpg" --captions "一位女性" "一位女孩" --idips true true --save_path "generated_image_2-GGUF.png" --num_images 1 --dit_quant GGUF
注意:量化模型可能会在一定程度上降低模型性能,weight_id、weight_ip 和 lora_scale 等参数可能需要重新调整。
使用 XVerseBench 进行推理
首先,请根据 assets 文件夹中的内容下载 XVerseBench。然后,在运行推理时,请执行以下命令:
bash ./eval/eval_scripts/run_eval.sh
该脚本将自动在 XVerseBench 数据集上评估模型,并将结果保存到 ./results 文件夹中。
📌 待办事项
- 发布 GitHub 仓库。
- 发表 arXiv 论文。
- 发布模型检查点。
- 发布推理数据:XVerseBench。
- 发布 XVerseBench 的推理代码。
- 发布 Gradio 演示的推理代码。
- 发布单样本推理代码。
- 支持消费级 GPU 上的推理。
- 发布 Hugging Face Space 演示。
- 支持量化扩散模型。
- 发布基准排行榜。
- 发布 ComfyUI 实现。
许可证
本项目的代码采用 Apache 2.0 许可证;数据集采用 CC0 许可证,但受字节跳动拥有的知识产权约束。同时,该数据集改编自 dreambench++,您也应遵守 dreambench++ 的许可证。
致谢
我们衷心感谢 Alex Nasa 部署了基于 FLUX.1-schnell 模型的 Hugging Face 演示。您可以通过点击 这里 体验该在线演示。
引用
如果 XVerse 对您有所帮助,请为本仓库点赞(⭐)。
如果您认为本项目对您的研究有帮助,请考虑引用我们的论文:
@article{chen2025xverse,
title={XVerse: 通过 DiT 调制实现身份与语义属性的一致性多主体控制},
author={Chen, Bowen and Zhao, Mengyi and Sun, Haomiao and Chen, Li and Wang, Xu and Du, Kang and Wu, Xinglong},
journal={arXiv 预印本 arXiv:2506.21416},
year={2025}
}
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。