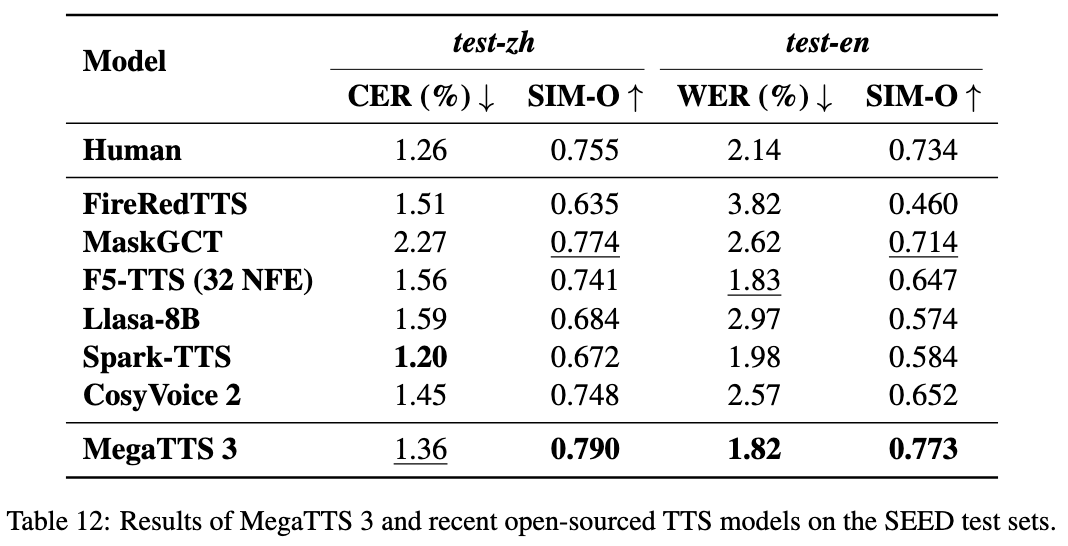
MegaTTS3
MegaTTS3 是字节跳动与浙江大学联合开源的一款高质量文本转语音(TTS)工具,能够将文字自然流畅地转换为逼真的人声,并支持用短短几秒钟的音频样本克隆特定说话人的音色。
这款工具主要解决了传统语音合成模型体积庞大、部署困难,以及克隆音质不够自然的问题。MegaTTS3 采用轻量化的 Diffusion Transformer 架构,仅需 4.5 亿参数即可实现专业级效果,大幅降低了对计算资源的要求。同时支持中英文双语及无缝切换,还能调节口音强度,满足个性化需求。
MegaTTS3 适合开发者集成到语音助手、有声读物、视频配音等应用中,也便于研究人员探索语音合成技术。普通用户可通过 Hugging Face 在线 demo 直接体验,无需编程基础。技术亮点在于用极小的模型体积实现了接近真人的语音克隆质量,且支持本地部署保护隐私。目前代码已开源,采用 Apache 2.0 协议,Linux 环境可直接运行,Windows 版本正在测试中。
使用场景
某独立游戏工作室正在开发一款悬疑解谜游戏,需要为5位性格迥异的角色配音,但预算有限无法聘请专业声优全程录制。
没有 MegaTTS3 时
- 成本高昂:请专业配音演员录制全部台词需花费数万元,小团队难以承担
- 周期漫长:协调演员档期、反复补录修改,配音环节可能拖慢整体开发进度2-3个月
- 一致性难保证:临时更换演员或补录时,音色和情绪难以与之前版本完全匹配
- 多语言版本困难:想做中英文双语版本,需要找两组完全不同的配音团队,成本翻倍
使用 MegaTTS3 后
- 零成本克隆音色:只需收集少量参考音频(甚至可用团队成员的声音),即可生成高质量角色配音,预算全部投入到美术和程序开发
- 实时迭代调整:编剧修改台词后,开发者直接在本地运行推理,几分钟内生成新音频,无需等待演员档期
- 音色永久固化:将角色声音保存为
.npy潜向量文件,任何时候都能复现完全一致的声音特质,续作或DLC开发无缝衔接 - 中英双语无缝切换:同一角色音色支持中英文混合输出,配合口音强度控制功能,轻松实现"带外国口音的中文"或"带中文腔的英文"等个性化设定
MegaTTS3 让小团队用极低成本获得专业级配音能力,把"做不起配音"的困境变成了"声音设计自由"的创作优势。
运行环境要求
- Linux
- Windows
- GPU 非必需但推荐,支持 CUDA 的 NVIDIA GPU 可用于加速推理
- Windows 需安装特定版本 PyTorch(如 cu126)
- CPU 推理约需 30 秒(10 步推理)
未说明

快速开始
MegaTTS 3 
官方 PyTorch 实现
核心特性
- 🚀轻量高效: TTS Diffusion Transformer(文本转语音扩散 Transformer)主干网络仅有 0.45B(4.5亿)参数。
- 🎧超高音质语音克隆: 您可以在 Huggingface Demo🎉 体验我们的模型。.wav 和 .npy 文件可在 link1 获取。在 link2 提交样本(.wav 格式,< 24秒,文件名请勿包含空格)即可获取可在本地使用的 .npy 语音隐变量(voice latents)。
- 🌍双语支持: 支持中文和英文,以及代码切换(code-switching)。
- ✍️可控性强: 支持口音强度控制 ✅ 和细粒度发音/时长调整(即将推出)。
🎯路线图
- [2025-03-22] 项目已发布!
安装
# 克隆仓库
git clone https://github.com/bytedance/MegaTTS3
cd MegaTTS3
环境要求(Linux)
# 创建 Python 3.10 的 conda 环境(也可使用 virtualenv)
conda create -n megatts3-env python=3.10
conda activate megatts3-env
pip install -r requirements.txt
# 设置根目录
export PYTHONPATH="/path/to/MegaTTS3:$PYTHONPATH"
# [可选] 设置 GPU
export CUDA_VISIBLE_DEVICES=0
# 如果在推理时遇到 pydantic 相关错误,请检查 pydantic 和 gradio 的版本是否匹配。
# [注意] 如果遇到 httpx 相关错误,请检查环境变量 "no_proxy" 是否包含 "::" 等模式。
环境要求(Windows)
# [Windows 版本目前正在测试中]
# 在 requirements.txt 中注释以下依赖:
# # WeTextProcessing==1.0.4.1
# 创建 Python 3.10 的 conda 环境(也可使用 virtualenv)
conda create -n megatts3-env python=3.10
conda activate megatts3-env
pip install -r requirements.txt
conda install -y -c conda-forge pynini==2.1.5
pip install WeTextProcessing==1.0.3
# [可选] 如需 GPU 推理,可能需要从 https://pytorch.org/ 安装适合您 GPU 的特定 PyTorch 版本。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# [注意] 如果遇到 `ffprobe` 或 `ffmpeg` 相关错误,可通过 `conda install -c conda-forge ffmpeg` 安装。
# 设置根目录环境变量
set PYTHONPATH="C:\path\to\MegaTTS3;%PYTHONPATH%" # Windows
$env:PYTHONPATH="C:\path\to\MegaTTS3;%PYTHONPATH%" # Windows Powershell
conda env config vars set PYTHONPATH="C:\path\to\MegaTTS3;%PYTHONPATH%" # conda 用户
# [可选] 设置 GPU
set CUDA_VISIBLE_DEVICES=0 # Windows
$env:CUDA_VISIBLE_DEVICES=0 # Windows Powershell
环境要求(Docker)
# [Docker 版本目前正在测试中]
# ! 运行以下命令前请先下载预训练检查点
docker build . -t megatts3:latest
# GPU 推理
docker run -it -p 127.0.0.1:7929:7929 --gpus all -e CUDA_VISIBLE_DEVICES=0 megatts3:latest
# CPU 推理
docker run -it -p 127.0.0.1:7929:7929 megatts3:latest
# 访问 http://127.0.0.1:7860/ 使用 gradio。
模型下载
预训练检查点可在 Google Drive 或 Huggingface 获取。请下载并放置到 ./checkpoints/xxx。
[!IMPORTANT]
出于安全考虑,我们未在上述链接中上传 WaveVAE 编码器的参数。您只能使用从 link1 获取的预提取隐变量进行推理。如需为说话人 A 合成语音,您需要在同一目录下准备 "A.wav" 和 "A.npy"。如有任何问题或建议,请邮件联系我们。本项目主要用于学术研究。如需评估学术数据集,您可将其上传至 link2 的语音请求队列(每段不超过 24 秒)。验证上传语音无安全问题后,我们将尽快将隐变量文件上传至 link1。
未来几天,我们还将准备并发布一些常用 TTS 基准测试的隐变量表示。
推理
命令行使用(标准)
# p_w(可懂度权重, intelligibility weight)、t_w(相似度权重, similarity weight)。通常情况下,提示音频噪声越多,需要设置越高的 p_w 和 t_w
python tts/infer_cli.py --input_wav 'assets/Chinese_prompt.wav' --input_text "另一边的桌上,一位读书人嗤之以鼻道,'佛子三藏,神子燕小鱼是什么样的人物,李家的那个李子夜如何与他们相提并论?'" --output_dir ./gen
# 只要音频音量和发音合适,在合理范围内(2.0~5.0)提高 --t_w
# 可以增加生成语音的表现力和相似度(尤其适用于一些情感场景)。
python tts/infer_cli.py --input_wav 'assets/English_prompt.wav' --input_text 'As his long promised tariff threat turned into reality this week, top human advisers began fielding a wave of calls from business leaders, particularly in the automotive sector, along with lawmakers who were sounding the alarm.' --output_dir ./gen --p_w 2.0 --t_w 3.0
命令行用法(用于带口音的 TTS)
# 当 p_w(可懂度权重, intelligibility weight)≈ 1.0 时,生成的音频会紧密保留说话人的原始口音。随着 p_w 增加,发音会向标准发音靠拢。
# t_w(相似度权重, similarity weight)通常比 p_w 高 0-3 个点以获得最佳效果。
# 适用于带口音的 TTS 或解决跨语言 TTS 中的口音问题。
python tts/infer_cli.py --input_wav 'assets/English_prompt.wav' --input_text '这是一条有口音的音频。' --output_dir ./gen --p_w 1.0 --t_w 3.0
python tts/infer_cli.py --input_wav 'assets/English_prompt.wav' --input_text '这条音频的发音标准一些了吗?' --output_dir ./gen --p_w 2.5 --t_w 2.5
Web UI 用法
# 我们也支持 CPU 推理,但可能需要约 30 秒(10 个推理步)。
python tts/gradio_api.py
子模块
[!TIP] 除了 TTS,本项目中的某些子模块可能还有其他用途。 示例代码请参见
./tts/frontend_fuction.py和./tts/infer_cli.py。
Aligner(对齐器)
描述: 一个鲁棒的语音-文本对齐模型,使用大量 MFA(Montreal Forced Aligner,蒙特利尔强制对齐器)专家模型生成的伪标签进行训练。
用途: 1) 为本模型准备微调数据集;2) 过滤大规模语音数据集(如果对齐器无法对齐某段语音,则该语音很可能含有噪声);3) 音素识别;4) 语音分割。
Grapheme-to-Phoneme Model(字素到音素模型)
描述: 一个针对鲁棒字素到音素转换进行微调的 Qwen2.5-0.5B 模型。
用途: 字素到音素转换。
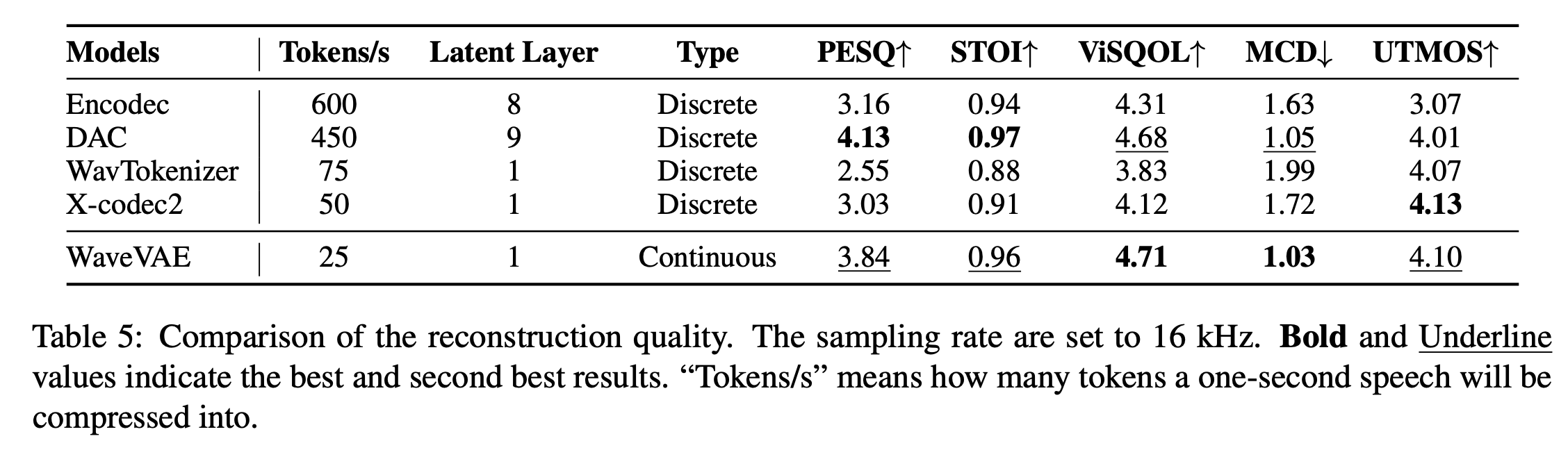
WaveVAE
描述: 一个强大的波形 VAE(变分自编码器, Variational Autoencoder),可将 24 kHz 语音压缩为 25 Hz 声学隐变量,并几乎无损地重建原始波形。
用途: 1) 与梅尔频谱图相比,声学隐变量可以为语音合成模型提供更紧凑、更具区分性的训练目标,加速收敛;2) 用作语音转换的声学隐变量;3) 高质量声码器。
安全
如果您在本项目中发现了潜在的安全问题,或者认为自己可能发现了安全问题,我们恳请您通过我们的安全中心或 sec@bytedance.com 通知字节跳动安全团队。
请不要创建公开的 GitHub issue。
许可证
本项目采用 Apache-2.0 许可证 授权。
引用
本仓库包含 Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis 的强制对齐版本,WavVAE 主要基于 Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling。与论文中描述的模型相比,本仓库包含了额外的模型。这些模型不仅增强了算法的稳定性和克隆能力,还可以独立使用以服务于更广泛的场景。
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。