speech-to-text-wavenet
speech-to-text-wavenet 是基于 DeepMind 经典 WaveNet 架构与 TensorFlow 构建的端到端英文语音识别开源项目。它致力于将语音信号直接转换为文本,弥补了早期 TensorFlow WaveNet 实现仅专注于音频生成而忽略识别任务的不足。
对于深度学习研究人员和对语音识别技术感兴趣的开发者而言,这是一个很好的学习资源。面对原始论文中实现细节模糊的挑战,speech-to-text-wavenet 通过调整模型结构来适应硬件限制,例如在 TitanX GPU 上移除难以运行的均值池化层,并改用 CTC Loss 以适应句子级标签数据。此外,它还整合了 VCTK、LibriSpeech 等多个公开语料库,提供了从预处理到训练的全流程代码参考。
尽管受限于旧版 TensorFlow 环境,不太适合直接用于商业生产,但它为理解 WaveNet 在序列建模中的应用提供了宝贵的实践案例,是学习神经语音识别架构的理想起点。
使用场景
某高校研究团队需要整理大量英文学术讲座录音,以便建立可搜索的文本知识库并辅助后续文献分析。
没有 speech-to-text-wavenet 时
- 人工听写效率极低,处理一小时音频需耗费数天时间,人力成本过高
- 依赖云端 API 导致原始录音数据存在隐私泄露风险,且按分钟计费累积成本高昂
- 传统开源方案多基于旧架构,对长句子的上下文理解能力不足,断句错误频发
- 缺乏本地化部署能力,在网络不稳定或离线环境下无法完成批量转换任务
使用 speech-to-text-wavenet 后
- 基于 DeepMind WaveNet 架构实现端到端句子级识别,显著提升了复杂语境下的转录准确率
- 支持本地 TensorFlow 环境运行,完全掌握数据主权,无需将敏感录音上传至第三方服务器
- 利用 CTC 损失函数优化训练流程,有效解决了连续语音流中的分词与对齐难题
- 结合 VCTK 等公开数据集微调模型参数,能更好地适配特定口音、语速及背景噪声
通过本地化部署高精度语音识别模型,团队实现了安全、低成本且高效的英文音频转文本自动化流程。
运行环境要求
- Linux
需要 NVIDIA GPU (如 GTX 1080),显存建议 8GB+,CUDA 版本需兼容 TensorFlow 1.0.0 (约 CUDA 8.0)
未说明

快速开始
Speech-to-Text-WaveNet:使用 DeepMind 的 WaveNet 进行端到端句子级英语语音识别
基于 DeepMind 的 WaveNet:原始音频生成模型 的 TensorFlow 语音识别实现。(以下简称“论文”)
虽然 ibab 和 tomlepaine 已经使用 TensorFlow 实现了 WaveNet,但他们没有实现语音识别。这就是为什么我们决定自己实现它。
DeepMind 的一些近期论文难以复现。该论文也省略了关于实现的具体细节,我们必须以自己的方式填补这些空白。
以下是一些重要说明。
首先,虽然论文使用了 TIMIT 数据集进行语音识别实验,但我们使用了免费的 VCTK 数据集。
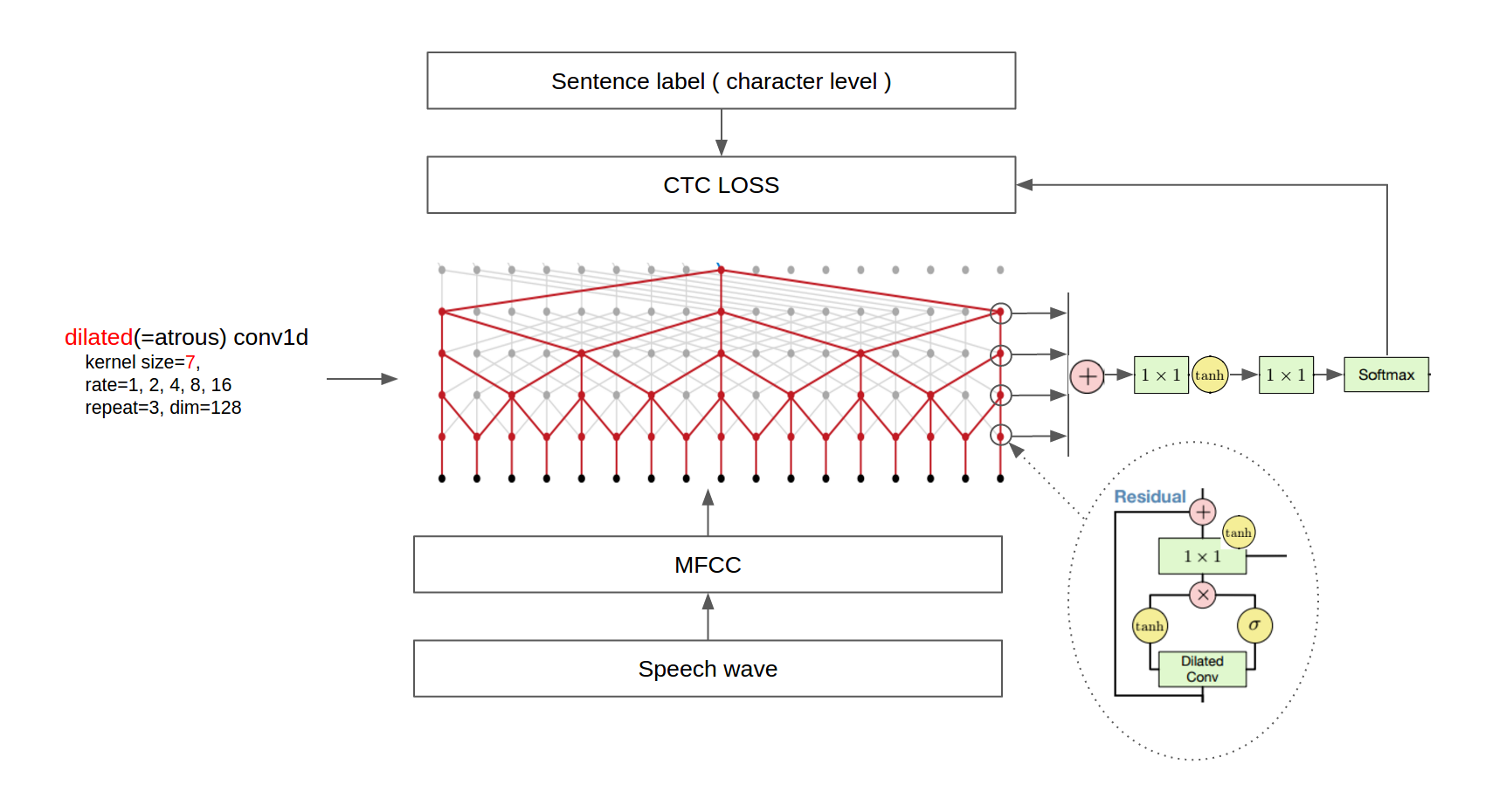
其次,论文在膨胀卷积层(dilated convolution layer)后添加了一个平均池化层(mean-pooling layer)用于下采样。我们从 wav 文件中提取了 MFCC(梅尔频率倒谱系数),并移除了最终的平均池化层,因为原始设置在我们的 TitanX GPU 上无法运行。
第三,由于 TIMIT 数据集具有音素标签,论文使用两个损失项训练模型:音素分类和下一个音素预测。相反,我们使用了单一的 CTC 损失(Connectionist Temporal Classification Loss),因为 VCTK 提供句子级标签。因此,我们仅使用了膨胀卷积 1D 层,而没有使用任何池化层。
最后,由于时间限制,我们没有进行诸如 BLEU 分数(BLEU Score)之类的定量分析,也没有结合语言模型进行后处理。
最终架构如下图所示。
版本
当前版本:0.0.0.2
依赖项(版本号必须完全匹配!)
- tensorflow == 1.0.0
- sugartensor == 1.0.0.2
- pandas >= 0.19.2
- librosa == 0.5.0
- scikits.audiolab==0.11.0
如果您在使用 librosa 库时遇到问题,请尝试通过以下命令安装 ffmpeg。(Ubuntu 14.04)
sudo add-apt-repository ppa:mc3man/trusty-media
sudo apt-get update
sudo apt-get dist-upgrade -y
sudo apt-get -y install ffmpeg
数据集
我们使用了 VCTK、LibriSpeech 和 TEDLIUM release 2 语料库。 由上述三个语料库组成的训练集中的句子总数为 240,612。 验证集和测试集仅使用 LibriSpeech 和 TEDLIUM 语料库构建,因为 VCTK 语料库没有验证集和测试集。 下载每个语料库后,将它们解压到 'asset/data/VCTK-Corpus'、'asset/data/LibriSpeech' 和 'asset/data/TEDLIUM_release2' 目录中。
音频增强方案参考了 Tom Ko 等人 的论文。 (感谢 @migvel 提供的信息)
数据集预处理
TEDLIUM release 2 数据集提供的是 SPH 格式的音频数据,因此我们需要将其转换为 librosa 库可以处理的格式。在 'asset/data' 目录下运行以下命令将 SPH 转换为 WAV 格式。
find -type f -name '*.sph' | awk '{printf "sox -t sph %s -b 16 -t wav %s\n", $0, $0".wav" }' | bash
如果您尚未安装 sox,请先安装它。
sudo apt-get install sox
我们发现训练时的主要瓶颈是磁盘读取时间,因此我们决定将整个音频数据预处理为小得多的 MFCC 特征文件。我们强烈建议使用 SSD 而不是机械硬盘。
在控制台运行以下命令以预处理整个数据集。
python preprocess.py
训练网络
执行以下命令来训练网络。
python train.py ( <== 使用所有可用的 GPU )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== 仅使用 GPU 0, 1 )
您可以在 'asset/train' 目录中看到结果 ckpt 文件和日志文件。
启动 tensorboard --logdir asset/train/log 以监控训练过程。
我们在 3 块 Nvidia 1080 Pascal GPU 上训练此模型,耗时 40 小时,达到 50 个 epoch,并选择了验证损失最小的那个 epoch。在我们的案例中,它是第 40 个 epoch。如果遇到内存不足错误,请将 train.py 文件中的 batch_size 从 16 减少到 4。
每个 epoch 的 CTC 损失如下表所示:
| epoch | train set | valid set | test set |
|---|---|---|---|
| 20 | 79.541500 | 73.645237 | 83.607269 |
| 30 | 72.884180 | 69.738348 | 80.145867 |
| 40 | 69.948266 | 66.834316 | 77.316114 |
| 50 | 69.127240 | 67.639895 | 77.866674 |
测试网络
训练完成后,您可以通过以下命令检查验证集或测试集的 CTC 损失。
python test.py --set train|valid|test --frac 1.0(0.01~1.0)
如果您只想测试数据集的一部分以进行快速评估,frac 选项将很有用。
将语音波形文件转换为英文文本
执行
python recognize.py --file
将语音波形文件转换为英文句子。结果将打印在控制台上。
例如,尝试以下命令。
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0000.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0001.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0002.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0003.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0004.flac
结果如下:
he hoped there would be stoo for dinner turnips and charrats and bruzed patatos and fat mutton pieces to be ladled out in th thick peppered flower fatan sauce
stuffid into you his belly counsiled him
after early night fall the yetl lampse woich light hop here and there on the squalled quarter of the browfles
o berty and he god in your mind
numbrt tan fresh nalli is waiting on nou cold nit husband
真实标签 (Ground Truth) 如下:
HE HOPED THERE WOULD BE STEW FOR DINNER TURNIPS AND CARROTS AND BRUISED POTATOES AND FAT MUTTON PIECES TO BE LADLED OUT IN THICK PEPPERED FLOUR FATTENED SAUCE
STUFF IT INTO YOU HIS BELLY COUNSELLED HIM
AFTER EARLY NIGHTFALL THE YELLOW LAMPS WOULD LIGHT UP HERE AND THERE THE SQUALID QUARTER OF THE BROTHELS
HELLO BERTIE ANY GOOD IN YOUR MIND
NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND
如前所述,没有语言模型 (Language Model),因此存在大写字母、标点和单词拼写错误的情况。
预训练模型 (Pre-trained Models)
您可以使用 VCTK 语料库 (Corpus) 上的预训练模型将语音波形文件转换为英文文本。 提取 以下 zip 文件 到 'asset/train/' 目录中。
Docker 支持
请查看 docker README.md。
未来工作
- 语言模型 (Language Model)
- 多语言(多语种)模型 (Polyglot/Multi-lingual Model)
我们认为应该用实用的语言模型替换 CTC 束解码器 (CTC Beam Decoder),而多语言语音识别模型将是未来工作的良好候选方案。
其他资源
Namju 的其他仓库
- SugarTensor
- EBGAN TensorFlow 实现
- 时间序列 GAN TensorFlow 实现
- 监督 InfoGAN TensorFlow 实现
- AC-GAN TensorFlow 实现
- SRGAN TensorFlow 实现
- ByteNet-快速神经机器翻译
引用
如果您发现此代码有用,请在您的工作中引用我们:
Kim and Park. Speech-to-Text-WaveNet. 2016. GitHub repository. https://github.com/buriburisuri/.
作者
Namju Kim (namju.kim@kakaocorp.com) at KakaoBrain Corp.
Kyubyong Park (kbpark@jamonglab.com) at KakaoBrain Corp.
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。
LocalAI
LocalAI 是一款开源的本地人工智能引擎,旨在让用户在任意硬件上轻松运行各类 AI 模型,包括大语言模型、图像生成、语音识别及视频处理等。它的核心优势在于彻底打破了高性能计算的门槛,无需昂贵的专用 GPU,仅凭普通 CPU 或常见的消费级显卡(如 NVIDIA、AMD、Intel 及 Apple Silicon)即可部署和运行复杂的 AI 任务。 对于担心数据隐私的用户而言,LocalAI 提供了“隐私优先”的解决方案,确保所有数据处理均在本地基础设施内完成,无需上传至云端。同时,它完美兼容 OpenAI、Anthropic 等主流 API 接口,这意味着开发者可以无缝迁移现有应用,直接利用本地资源替代云服务,既降低了成本又提升了可控性。 LocalAI 内置了超过 35 种后端支持(如 llama.cpp、vLLM、Whisper 等),并集成了自主 AI 代理、工具调用及检索增强生成(RAG)等高级功能,且具备多用户管理与权限控制能力。无论是希望保护敏感数据的企业开发者、进行算法实验的研究人员,还是想要在个人电脑上体验最新 AI 技术的极客玩家,都能通过 LocalAI 获
bark
Bark 是由 Suno 推出的开源生成式音频模型,能够根据文本提示创造出高度逼真的多语言语音、音乐、背景噪音及简单音效。与传统仅能朗读文字的语音合成工具不同,Bark 基于 Transformer 架构,不仅能模拟说话,还能生成笑声、叹息、哭泣等非语言声音,甚至能处理带有情感色彩和语气停顿的复杂文本,极大地丰富了音频表达的可能性。 它主要解决了传统语音合成声音机械、缺乏情感以及无法生成非语音类音效的痛点,让创作者能通过简单的文字描述获得生动自然的音频素材。无论是需要为视频配音的内容创作者、探索多模态生成的研究人员,还是希望快速原型设计的开发者,都能从中受益。普通用户也可通过集成的演示页面轻松体验其神奇效果。 技术亮点方面,Bark 支持商业使用(MIT 许可),并在近期更新中实现了显著的推理速度提升,同时提供了适配低显存 GPU 的版本,降低了使用门槛。此外,社区还建立了丰富的提示词库,帮助用户更好地驾驭模型生成特定风格的声音。只需几行 Python 代码,即可将创意文本转化为高质量音频,是连接文字与声音世界的强大桥梁。
airi
airi 是一款开源的本地化 AI 伴侣项目,旨在将虚拟角色(如“二次元老婆”或赛博生命)带入用户的现实世界。它的核心目标是复刻并超越知名 AI 主播 Neuro-sama 的能力,让用户能够拥有完全自主掌控、可私有化部署的智能伙伴。 airi 主要解决了用户对高度定制化、具备情感交互能力且数据隐私安全的 AI 角色的需求。不同于依赖云端服务的通用助手,airi 允许用户在本地运行,不仅保护了对话隐私,还赋予了用户定义角色性格与灵魂的自由。它支持实时语音聊天,甚至能直接参与《我的世界》(Minecraft)和《异星工厂》(Factorio)等游戏,实现了从单纯对话到共同娱乐的跨越。 这款工具非常适合喜爱虚拟角色的普通用户、希望搭建个性化 AI 陪伴的技术爱好者,以及研究多模态交互的开发者。其独特的技术亮点在于跨平台支持(涵盖 Web、macOS 和 Windows)以及强大的游戏交互能力,让 AI 不仅能“说”,还能“玩”。通过容器化的灵魂设计,airi 为每个人创造专属数字生命提供了可能,让虚拟陪伴变得更加真实且触手可及。
MockingBird
MockingBird 是一款开源的实时语音克隆工具,旨在让用户仅需 5 秒的参考音频,即可快速合成任意内容的语音,并实现逼真的音色复刻。它有效解决了传统语音合成技术中数据采集成本高、训练周期长以及难以实时生成的痛点,让个性化语音生成变得触手可及。 这款工具特别适合开发者、AI 研究人员以及对语音技术感兴趣的技术爱好者使用。无论是用于构建交互式语音应用、进行声学模型研究,还是制作创意内容,MockingBird 都能提供强大的支持。普通用户若具备基础的编程环境配置能力,也可通过其提供的 Web 服务或工具箱体验前沿的变声效果。 在技术亮点方面,MockingBird 基于 PyTorch 框架,不仅完美支持中文普通话及多种主流数据集,还实现了跨平台运行,兼容 Windows、Linux 乃至 M1 架构的 macOS。其独特的架构设计允许复用预训练的编码器与声码器,只需微调合成器即可获得出色效果,大幅降低了部署门槛。此外,项目内置了现成的 Web 服务器功能,方便用户通过远程调用快速集成到自己的应用中。尽管原作者已转向云端优化版本,但 MockingBird 作为经典的本地部署方案