stockpredictionai
stockpredictionai 是一个基于先进人工智能技术的开源项目,旨在构建一套完整的股票价格波动预测流程。它致力于解决金融时间序列预测中数据复杂、噪声大以及传统模型难以捕捉深层规律的问题,通过融合多维度信息来提升预测准确性。
该项目非常适合具备一定机器学习基础的开发者、量化研究人员以及对深度学习在金融领域应用感兴趣的数据科学家使用。其核心技术亮点在于创新性地结合了生成对抗网络(GAN)与长短期记忆网络(LSTM),利用 LSTM 作为生成器处理时间序列,卷积神经网络(CNN)作为判别器进行校验。为了克服 GAN 训练难的痛点,项目引入了贝叶斯优化和强化学习(如 Rainbow、PPO 算法)来动态调整超参数。此外,它还广泛整合了自然语言处理(BERT 情感分析)、傅里叶变换趋势提取、堆叠自编码器特征识别以及 ARIMA 等多种前沿技术,全方位挖掘市场数据中的潜在模式。基于 MXNet 框架开发的 stockpredictionai,为探索复杂的股市预测提供了极具参考价值的技术实践方案。
使用场景
某量化对冲基金的分析团队正试图构建一个能融合历史行情、新闻舆情及宏观趋势的高精度股价预测模型,以辅助短线交易决策。
没有 stockpredictionai 时
- 模型架构单一,仅依赖 LSTM 处理时间序列,难以捕捉数据中复杂的非线性特征和潜在分布模式。
- 超参数调整依靠人工经验试错,耗时数周仍难以找到最优解,导致模型收敛慢且容易陷入局部最优。
- 数据来源局限在传统技术指标,无法有效整合 BERT 情感分析、傅里叶变换趋势提取等多模态信息,预测视角片面。
- 缺乏对抗训练机制,生成的预测路径过于平滑,无法模拟真实市场中剧烈的波动和异常情况。
使用 stockpredictionai 后
- 构建了基于 LSTM 生成器与 CNN 判别器的 GAN 架构,不仅能预测点位,还能生成逼真的股价波动分布,显著提升泛化能力。
- 引入贝叶斯优化结合强化学习(Rainbow/PPO 算法)自动动态调整超参数,将调优周期从数周缩短至数天,并确保持续探索最优策略。
- 一站式集成多源数据管道,自动融合 BERT 舆情情绪、堆叠自编码器高阶特征及 ARIMA 近似函数,全方位捕捉市场信号。
- 利用特征重要性分析和统计检验自动清洗数据,有效识别相关性资产与异常值,大幅降低了过拟合风险。
stockpredictionai 通过融合前沿的生成式对抗网络与自动化超参数调优技术,将多维异构数据转化为高鲁棒性的交易信号,彻底改变了传统量化建模的效率与精度瓶颈。
运行环境要求
- 未说明
需要多块 GPU 进行训练 (MXNet/Gluon),具体型号、显存大小及 CUDA 版本未说明
未说明
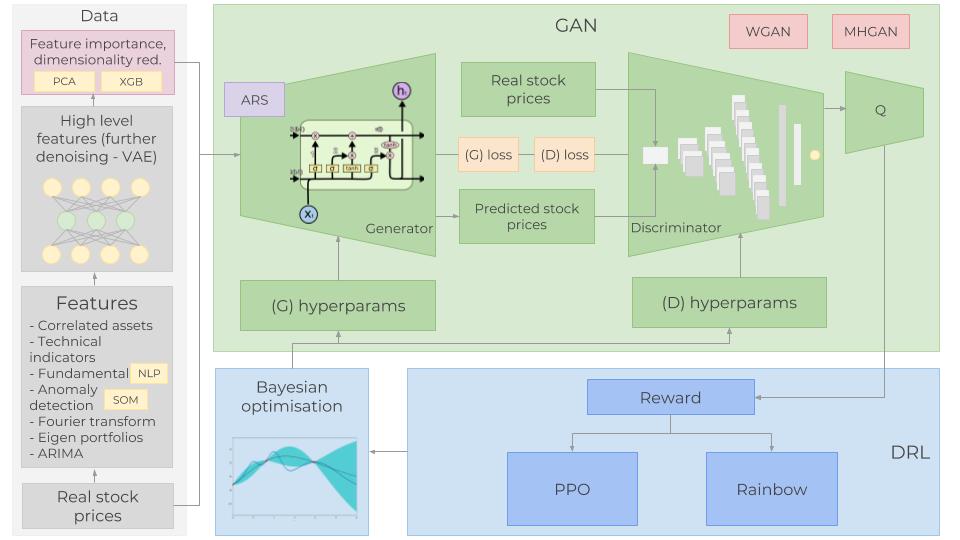
快速开始
利用人工智能的最新进展预测股市走势
在本笔记本中,我将构建一个完整的股票价格走势预测流程。跟随我的步骤,我们将取得相当不错的效果。为此,我们将使用一种生成对抗网络(GAN),其中以LSTM——一种循环神经网络——作为生成器,并以卷积神经网络(CNN)作为判别器。之所以选择LSTM,是因为我们要预测的是时间序列数据。那么,为什么我们要使用GAN,尤其是CNN作为判别器呢?这是一个好问题,我们将在后面专门讨论。
当然,我们会对每一步进行更详细的说明,但最困难的部分在于GAN:成功训练GAN的关键之一是找到合适的超参数组合。因此,我们将采用贝叶斯优化(结合高斯过程)和强化学习(RL),来决定何时以及如何调整GAN的超参数(即探索与利用之间的权衡)。在构建强化学习模型时,我们将使用该领域的最新进展,例如Rainbow和PPO。
我们将使用多种不同类型的数据作为输入。除了股票的历史交易数据和技术指标外,我们还将利用自然语言处理(NLP)领域的最新成果(如“来自Transformer的双向嵌入表示”——BERT,一种NLP中的迁移学习方法)来进行情感分析(作为基本面分析的一部分);使用傅里叶变换提取整体趋势方向;利用堆叠自编码器识别其他高层次特征;通过主成分分析构建特征投资组合以发现相关资产;并使用自回归积分滑动平均模型(ARIMA)对股票价格函数进行近似。此外,我们还会采用更多方法,以便尽可能全面地捕捉关于股票的各种信息、模式、依赖关系等。众所周知,数据越多越好。预测股票价格走势是一项极其复杂的任务,因此我们从不同角度掌握的信息越多,预测成功的可能性就越大。
为了构建所有神经网络,我们将使用MXNet及其高级API——Gluon,并在多块GPU上进行训练。
注: 尽管我会尽量详细解释几乎所有算法和技术背后的数学原理和机制,但本笔记本并非旨在明确阐述机器学习/深度学习或股票市场的运作方式。其主要目的是展示如何利用不同的技术和算法来准确预测股票价格走势,并为每一步所采用的技术及其合理性提供依据。
笔记本创建日期:2019年1月9日。
图1 - 我们工作的整体架构
目录
1. 引言
准确预测股市走势是一项复杂的任务,因为影响某只股票朝特定方向变动的因素多达数百万种。因此,我们需要尽可能多地捕捉这些先决条件。同时,我们也需要做出几个重要的假设:1) 市场并非完全随机;2) 历史会重演;3) 市场遵循人们的理性行为;4) 市场是“完美的”。请务必阅读位于页面底部的免责声明。
我们将尝试预测高盛集团(NYSE: GS)的价格走势。为此,我们将使用2010年1月1日至2018年12月31日的每日收盘价(其中七年用于训练,两年用于验证)。在本文中,“高盛集团”和“GS”这两个术语可以互换使用。
2. 致谢
在继续之前,我要感谢我的朋友Nuwan和Thomas,没有他们的想法和支持,我不可能完成这项工作。
3. 数据
我们需要弄清楚哪些因素会影响高盛股价的涨跌。归根结底,这取决于市场整体的看法。因此,我们需要尽可能地纳入更多信息(从不同方面和角度刻画股票)。我们将使用每日数据——1,585天用于训练各种算法(占我们现有数据的70%),并预测接下来的680天(测试数据)。随后,我们会将预测结果与独立的测试集进行对比。每种类型的数据(我们称之为“特征”)将在后续章节中更详细地说明,但作为高层次的概述,我们将使用的特征包括:
- 相关资产——这些是其他资产(任何类型,不一定是股票,例如大宗商品、外汇、指数,甚至固定收益证券)。像高盛这样的大型公司显然并非孤立存在,它依赖并受到许多外部因素的影响,包括竞争对手、客户、全球经济、地缘政治局势、财政和货币政策、资本获取等。具体细节将在后面列出。
- 技术指标——许多投资者会关注技术指标。我们将把最流行的技术指标作为独立特征纳入模型,其中包括7日和21日移动平均线、指数移动平均线、动量指标、布林带、MACD等。
- 基本面分析——这是判断股票可能上涨或下跌的一个非常重要的特征。在基本面分析中,有两种方法:1)通过10-K和10-Q报告分析公司业绩,如ROE和P/E等指标(我们暂不采用);2)新闻——新闻可能会预示未来可能推动股价朝某一方向变动的事件。我们将读取所有关于高盛的每日新闻,并提取当天关于高盛的整体情绪是正面、中性还是负面(以0到1之间的分数表示)。由于许多投资者密切关注新闻,并据此做出投资决策,因此如果今天关于高盛的消息极其积极,那么明天其股价很可能大幅上涨。需要注意的是,我们稍后会对每一个特征(包括这一项)进行特征重要性分析,以确定是否将其纳入模型,具体内容将在后面详述。 为了准确预测情绪,我们将使用神经语言处理(NLP)。具体来说,我们将采用谷歌最近推出的用于情感分类和股票新闻情感提取的迁移学习NLP方法——BERT。
- 傅里叶变换——除了每日收盘价外,我们还将计算傅里叶变换,以便概括长短期趋势。通过这些变换,我们可以消除大量噪声(随机游走),并构建对真实股价走势的近似。有了趋势近似,LSTM网络就能更准确地捕捉预测趋势。
- 自回归积分滑动平均模型(ARIMA)——在神经网络出现之前,ARIMA曾是预测时间序列数据未来值的最受欢迎的方法之一。我们将尝试加入这一方法,看看它是否能成为重要的预测特征。
- 堆叠自编码器——上述大多数特征(基本面分析、技术分析等)都是经过数十年研究才被人们发现的。但也许我们遗漏了某些内容。或许存在一些隐藏的相关性,由于数据点、事件、资产、图表等数量庞大,人类难以理解。借助堆叠自编码器(一种神经网络),我们可以利用计算机的强大能力,或许能找到影响股价的新特征。即使我们无法用人类语言理解这些特征,也可以在GAN中加以应用。
- 深度无监督学习用于期权定价中的异常检测——我们还将引入一项新特征:为每一天添加高盛股票90天看涨期权的价格。期权定价本身涉及大量数据。期权合约价格取决于股票未来的价值(分析师也会尝试预测该价值,以得出最准确的看涨期权价格)。通过深度无监督学习(自组织映射),我们将尝试识别每日定价中的异常情况。这种异常(如价格的剧烈变化)可能预示着某种事件,有助于LSTM网络学习整体的股价模式。
接下来,在拥有如此多特征的情况下,我们需要执行几个关键步骤:
- 对数据的“质量”进行统计检验。如果数据本身存在问题,那么无论我们的算法多么复杂,最终的结果都不会理想。这些检验包括确保数据不存在异方差性、多重共线性或序列相关性。
- 计算特征重要性。如果某个特征(例如另一只股票或某个技术指标)对我们想要预测的股票没有解释力,则无需将其用于神经网络的训练。我们将使用XGBoost(极端梯度提升)——一种基于树的增强回归算法。
作为数据准备的最后一步,我们还将利用主成分分析(PCA)创建特征组合,以降低自编码器生成的特征维度。
from utils import *
import time
import numpy as np
from mxnet import nd, autograd, gluon
from mxnet.gluon import nn, rnn
import mxnet as mx
import datetime
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.decomposition import PCA
import math
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")
context = mx.cpu(); model_ctx=mx.cpu()
mx.random.seed(1719)
注:本节(第3节:数据)旨在展示数据预处理过程,并说明使用不同数据来源的理由,因此我仅会使用完整数据集的一部分(即用于训练的数据)来演示。
def parser(x):
return datetime.datetime.strptime(x,'%Y-%m-%d')
dataset_ex_df = pd.read_csv('data/panel_data_close.csv', header=0, parse_dates=[0], date_parser=parser)
dataset_ex_df[['Date', 'GS']].head(3)
| 日期 | GS | |
|---|---|---|
| 0 | 2009-12-31 | 168.839996 |
| 1 | 2010-01-04 | 173.080002 |
| 2 | 2010-01-05 | 176.139999 |
print('数据集中共有{}天的数据。'.format(dataset_ex_df.shape[0]))
数据集中共有2265天的数据。
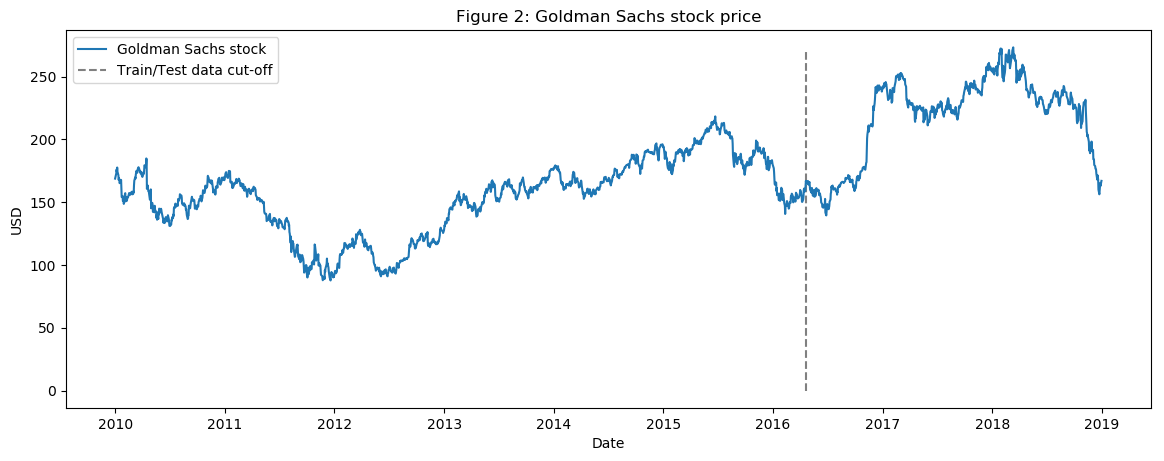
让我们可视化过去九年的股票走势。虚线表示训练集和测试集的分界线。
plt.figure(figsize=(14, 5), dpi=100)
plt.plot(dataset_ex_df['Date'], dataset_ex_df['GS'], label='高盛股票')
plt.vlines(datetime.date(2016,4, 20), 0, 270, linestyles='--', colors='gray', label='训练/测试数据分割线')
plt.xlabel('日期')
plt.ylabel('美元')
plt.title('图2:高盛股价')
plt.legend()
plt.show()
num_training_days = int(dataset_ex_df.shape[0]*.7)
print('训练天数:{}。测试天数:{}。'.format(num_training_days, \
dataset_ex_df.shape[0]-num_training_days))
训练天数:1585。测试天数:680。
3.1. 相关资产
如前所述,我们不仅会使用GS的股票作为目标变量,还会引入其他资产作为特征。
那么,还有哪些资产会影响GS的股价波动呢?要选择合适的相关资产,必须深入了解公司的业务领域、竞争格局、依赖关系、供应商及客户类型等:
- 首先是与GS业务相似的公司,例如摩根大通和摩根士丹利等。
- 作为一家投资银行,高盛的业绩高度依赖于全球经济状况。经济低迷或波动剧烈时,企业并购、首次公开募股等活动减少,自营交易收益也可能受限。因此,我们将纳入全球经济指数,并加入以美元和英镑计价的LIBOR利率,因为这些利率往往反映了经济环境的变化;此外,我们还将引入其他金融行业的相关证券。
- VIX指数——原因同上。
- 综合股指——例如美国的纳斯达克指数和纽约证券交易所指数、英国的富时100指数、日本的日经225指数以及亚太地区的恒生指数和孟买敏感30指数。
- 货币汇率——全球贸易活动常常反映在汇率波动中,因此我们将选取一篮子货币对(如USDJPY、GBPUSD等)作为特征。
总之,我们的数据集中包含了72种其他资产的每日价格数据。
3.2. 技术指标
我们已经介绍了什么是技术指标以及为什么使用它们,因此现在直接进入代码部分。我们将只为GS创建技术指标。
def get_technical_indicators(dataset):
# 计算7日和21日移动平均线
dataset['ma7'] = dataset['price'].rolling(window=7).mean()
dataset['ma21'] = dataset['price'].rolling(window=21).mean()
# 计算MACD
dataset['26ema'] = pd.ewma(dataset['price'], span=26)
dataset['12ema'] = pd.ewma(dataset['price'], span=12)
dataset['MACD'] = (dataset['12ema']-dataset['26ema'])
# 计算布林带
dataset['20sd'] = pd.stats.moments.rolling_std(dataset['price'],20)
dataset['upper_band'] = dataset['ma21'] + (dataset['20sd']*2)
dataset['lower_band'] = dataset['ma21'] - (dataset['20sd']*2)
# 计算指数移动平均线
dataset['ema'] = dataset['price'].ewm(com=0.5).mean()
# 计算动量
dataset['momentum'] = dataset['price']-1
return dataset
dataset_TI_df = get_technical_indicators(dataset_ex_df[['GS']])
dataset_TI_df.head()
| Date | price | ma7 | ma21 | 26ema | 12ema | MACD | 20sd | upper_band | lower_band | ema | momentum | log_momentum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2010-02-01 | 153.130005 | 152.374285 | 164.220476 | 160.321839 | 156.655072 | -3.666767 | 9.607375 | 183.435226 | 145.005726 | 152.113609 | 152.130005 | 5.024735 |
| 1 | 2010-02-02 | 156.940002 | 152.777143 | 163.653809 | 160.014868 | 156.700048 | -3.314821 | 9.480630 | 182.615070 | 144.692549 | 155.331205 | 155.940002 | 5.049471 |
| 2 | 2010-02-03 | 157.229996 | 153.098572 | 162.899047 | 160.729523 | 158.967168 | -2.982871 | 9.053702 | 181.006450 | 144.791644 | 156.597065 | 156.229996 | 5.051329 |
| 3 | 2010-02-04 | 150.679993 | 153.069999 | 161.686666 | 158.967168 | 155.827031 | -3.140137 | 8.940246 | 179.567157 | 143.806174 | 152.652350 | 149.679993 | 5.008500 |
| 4 | 2010-02-05 | 154.160004 | 153.449999 | 160.729523 | 158.550196 | 155.566566 | -2.983631 | 8.151912 | 177.033348 | 144.425699 | 153.657453 | 153.160004 | 5.031483 |
这样,我们就得到了每个交易日的技术指标(包括MACD、布林带等),总共有12个技术指标。
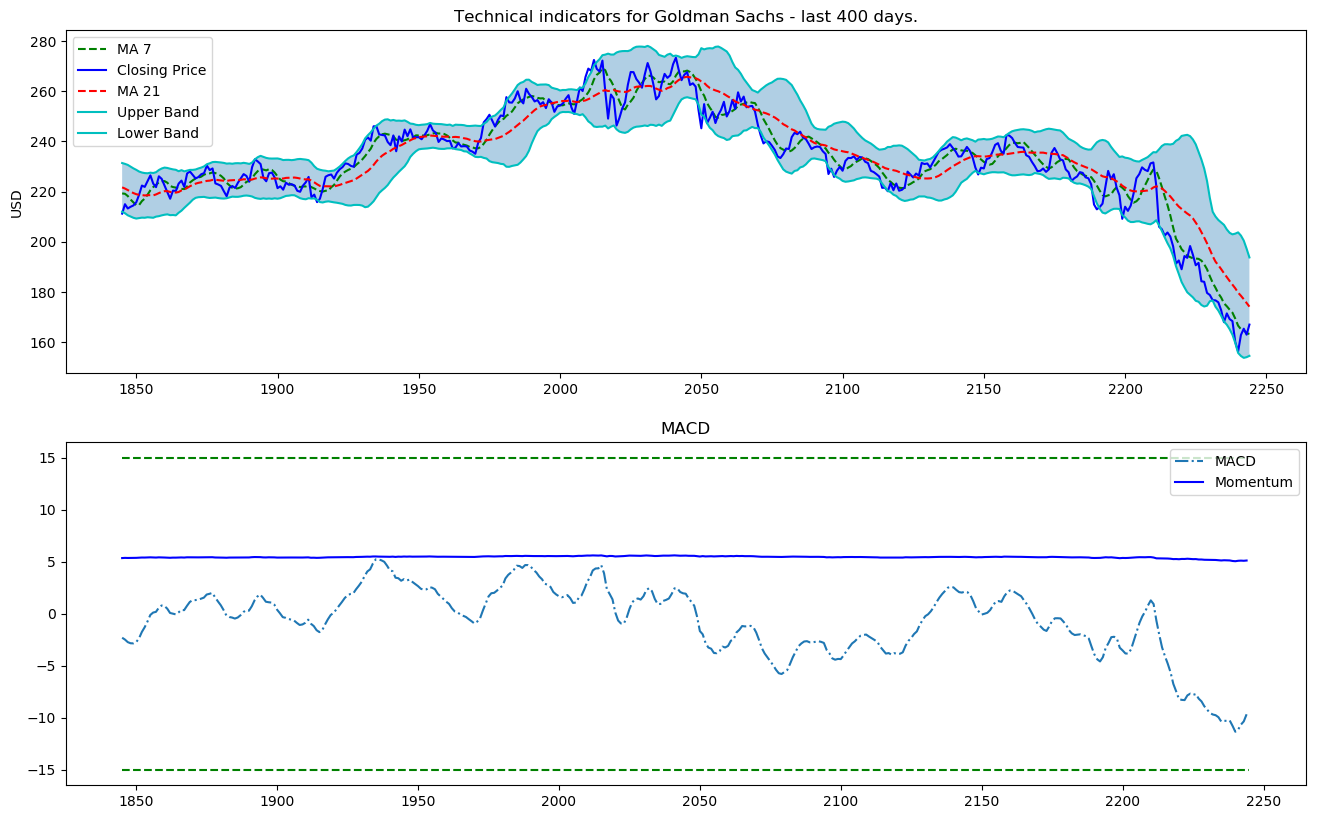
让我们可视化这些指标的最后400天数据。
def plot_technical_indicators(dataset, last_days):
plt.figure(figsize=(16, 10), dpi=100)
shape_0 = dataset.shape[0]
xmacd_ = shape_0-last_days
dataset = dataset.iloc[-last_days:, :]
x_ = range(3, dataset.shape[0])
x_ =list(dataset.index)
# 绘制第一个子图
plt.subplot(2, 1, 1)
plt.plot(dataset['ma7'],label='MA 7', color='g',linestyle='--')
plt.plot(dataset['price'],label='收盘价', color='b')
plt.plot(dataset['ma21'],label='MA 21', color='r',linestyle='--')
plt.plot(dataset['upper_band'],label='上轨', color='c')
plt.plot(dataset['lower_band'],label='下轨', color='c')
plt.fill_between(x_, dataset['lower_band'], dataset['upper_band'], alpha=0.35)
plt.title('高盛公司技术指标——最近{}天'.format(last_days))
plt.ylabel('美元')
plt.legend()
# 绘制第二个子图
plt.subplot(2, 1, 2)
plt.title('MACD')
plt.plot(dataset['MACD'],label='MACD', linestyle='-.')
plt.hlines(15, xmacd_, shape_0, colors='g', linestyles='--')
plt.hlines(-15, xmacd_, shape_0, colors='g', linestyles='--')
plt.plot(dataset['log_momentum'],label='动量', color='b',linestyle='-')
plt.legend()
plt.show()
plot_technical_indicators(dataset_TI_df, 400)
3.3. 基本面分析
对于基本面分析,我们将对所有关于GS的每日新闻进行情感分析。在最后使用Sigmoid函数,结果将介于0到1之间。分数越接近0,表示新闻越负面;越接近1,则表示正面情感。对于每一天,我们将计算其平均每日得分(一个介于0到1之间的数字),并将其作为特征添加进去。
3.3.1. 双向Transformer嵌入表示——BERT
为了将新闻分类为正面、负面或中性,我们将使用BERT,这是一种预训练的语言表示模型。
MXNet/Gluon中已经提供了预训练的BERT模型。我们只需实例化它们,并添加两个任意数量的Dense层,然后通过softmax输出,最终得到一个介于0到1之间的得分。
# 直接导入BERT
import bert
关于BERT和自然语言处理的详细内容不在本笔记本的讨论范围内,但如果你感兴趣,请告诉我——我会专门创建一个新的仓库来介绍BERT,因为它在语言处理任务中确实非常有前景。
3.4. 用于趋势分析的傅里叶变换
傅里叶变换将一个函数分解为一系列正弦波(具有不同的振幅和频率)。这些正弦波组合起来可以近似原函数。从数学上看,傅里叶变换的形式如下:
$$G(f) = \int_{-\infty}^\infty g(t) e^{-i 2 \pi f t} dt$$
我们将使用傅里叶变换来提取高盛股票的全局和局部趋势,并对其进行一定程度的去噪处理。下面我们来看看它是如何工作的。
data_FT = dataset_ex_df[['Date', 'GS']]
close_fft = np.fft.fft(np.asarray(data_FT['GS'].tolist()))
fft_df = pd.DataFrame({'fft':close_fft})
fft_df['absolute'] = fft_df['fft'].apply(lambda x: np.abs(x))
fft_df['angle'] = fft_df['fft'].apply(lambda x: np.angle(x))
plt.figure(figsize=(14, 7), dpi=100)
fft_list = np.asarray(fft_df['fft'].tolist())
for num_ in [3, 6, 9, 100]:
fft_list_m10= np.copy(fft_list); fft_list_m10[num_:-num_]=0
plt.plot(np.fft.ifft(fft_list_m10), label='包含 {} 个分量的傅里叶变换'.format(num_))
plt.plot(data_FT['GS'], label='真实值')
plt.xlabel('天数')
plt.ylabel('美元')
plt.title('图3:高盛(收盘价)股价与傅里叶变换')
plt.legend()
plt.show()
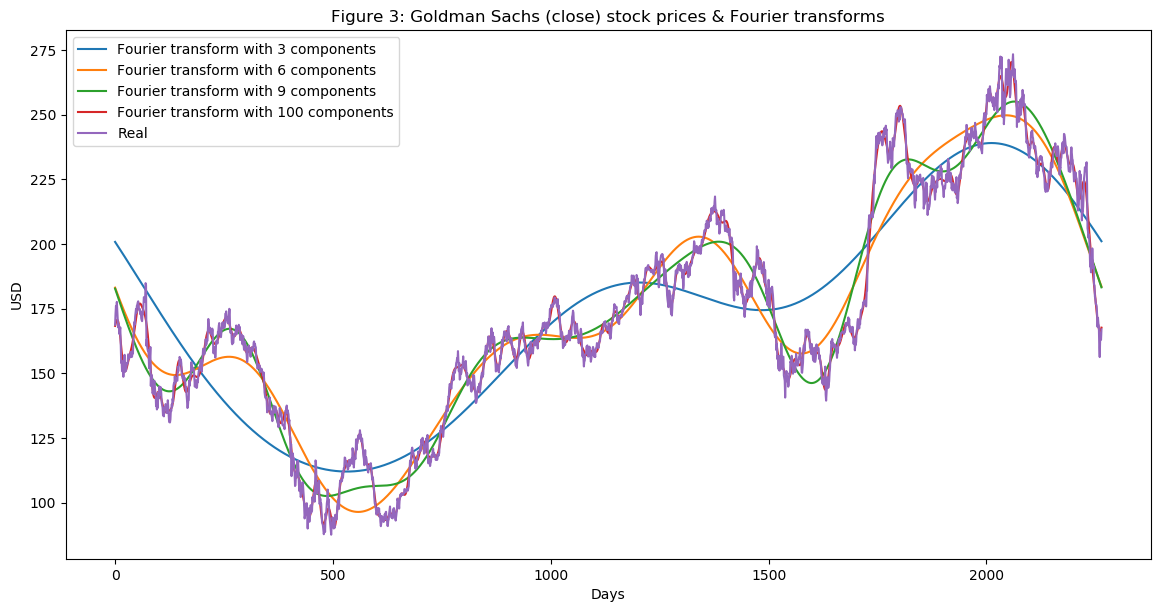
如图3所示,我们使用的傅里叶变换分量越多,近似函数就越接近真实的股票价格(使用100个分量的变换几乎与原始函数完全重合——红色和紫色线条几乎重叠在一起)。由于我们的目的是提取长期和短期趋势,因此我们将使用包含3、6和9个分量的傅里叶变换。可以推断出,包含3个分量的变换代表了长期趋势。
另一种用于数据去噪的技术是小波变换。小波变换和傅里叶变换的结果相似,因此我们只使用傅里叶变换。
from collections import deque
items = deque(np.asarray(fft_df['absolute'].tolist()))
items.rotate(int(np.floor(len(fft_df)/2)))
plt.figure(figsize=(10, 7), dpi=80)
plt.stem(items)
plt.title('图4:傅里叶变换的各分量')
plt.show()
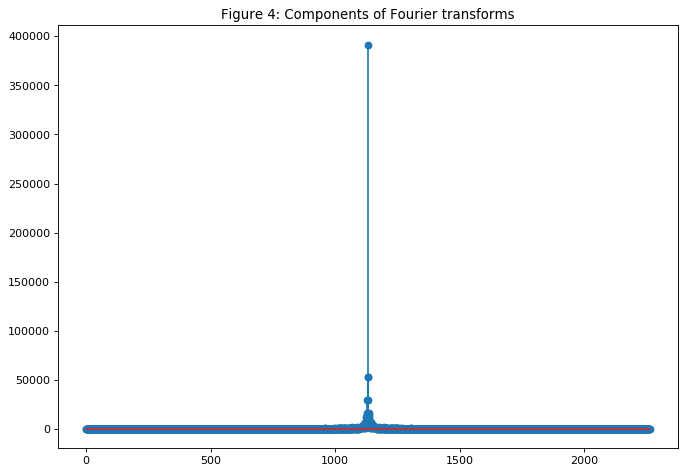
3.5. ARIMA作为特征
ARIMA是一种用于预测时间序列数据的技术。我们将展示如何使用它,尽管ARIMA不会作为最终的预测模型,但我们会将其用作一种对股票数据进行去噪并可能提取一些新模式或特征的方法。
from statsmodels.tsa.arima_model import ARIMA
from pandas import DataFrame
from pandas import datetime
series = data_FT['GS']
model = ARIMA(series, order=(5, 1, 0))
model_fit = model.fit(disp=0)
print(model_fit.summary())
ARIMA Model Results
==============================================================================
Dep. Variable: D.GS No. Observations: 2264
Model: ARIMA(5, 1, 0) Log Likelihood -5465.888
Method: css-mle S.D. of innovations 2.706
Date: Wed, 09 Jan 2019 AIC 10945.777
Time: 10:28:07 BIC 10985.851
Sample: 1 HQIC 10960.399
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const -0.0011 0.054 -0.020 0.984 -0.106 0.104
ar.L1.D.GS -0.0205 0.021 -0.974 0.330 -0.062 0.021
ar.L2.D.GS 0.0140 0.021 0.665 0.506 -0.027 0.055
ar.L3.D.GS -0.0030 0.021 -0.141 0.888 -0.044 0.038
ar.L4.D.GS 0.0026 0.021 0.122 0.903 -0.039 0.044
ar.L5.D.GS -0.0522 0.021 -2.479 0.013 -0.093 -0.011
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 -1.7595 -0.0000j 1.7595 -0.5000
AR.2 -0.5700 -1.7248j 1.8165 -0.3008
AR.3 -0.5700 +1.7248j 1.8165 0.3008
AR.4 1.4743 -1.0616j 1.8168 -0.0993
AR.5 1.4743 +1.0616j 1.8168 0.0993
-----------------------------------------------------------------------------
from pandas.tools.plotting import autocorrelation_plot
autocorrelation_plot(series)
plt.figure(figsize=(10, 7), dpi=80)
plt.show()
<Figure size 800x560 with 0 Axes>
from pandas import read_csv
from pandas import datetime
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error
X = series.values
size = int(len(X) * 0.66)
train, test = X[0:size], X[size:len(X)]
history = [x for x in train]
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=(5,1,0))
model_fit = model.fit(disp=0)
output = model_fit.forecast()
yhat = output[0]
predictions.append(yhat)
obs = test[t]
history.append(obs)
error = mean_squared_error(test, predictions)
print('Test MSE: %.3f' % error)
Test MSE: 10.151
# 绘制ARIMA模型预测的价格与实际价格
plt.figure(figsize=(12, 6), dpi=100)
plt.plot(test, label='实际')
plt.plot(predictions, color='red', label='预测')
plt.xlabel('天数')
plt.ylabel('美元')
plt.title('图5:GS股票的ARIMA模型')
plt.legend()
plt.show()
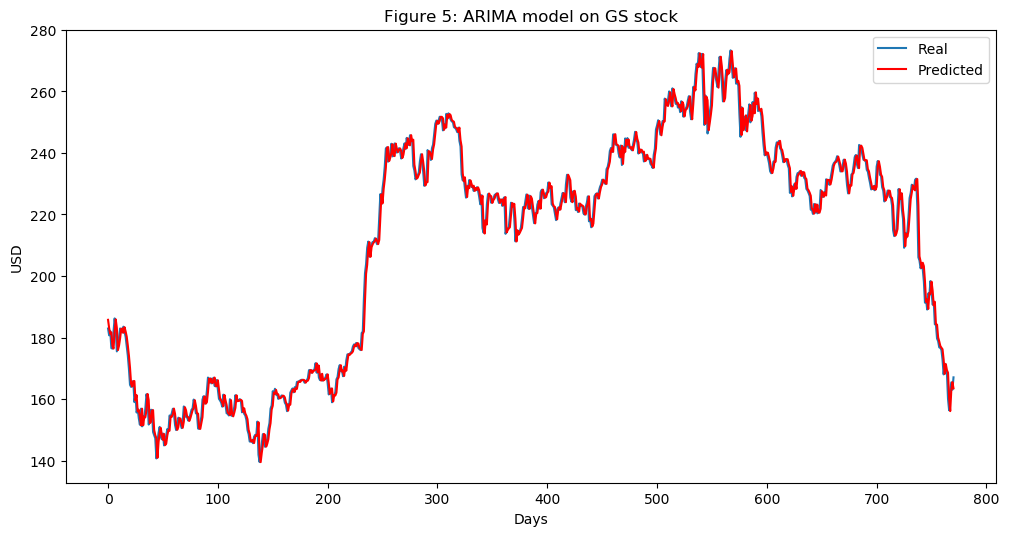
从图5可以看出,ARIMA模型对实际股价的拟合效果非常好。我们将使用ARIMA预测的价格作为LSTM模型的一个输入特征,因为如前所述,我们希望尽可能地捕捉关于高盛公司的各种特征和模式。我们计算得到的均方误差(MSE)为10.151,这个结果本身并不算差(考虑到我们的测试数据量较大),但我们仍然只将其作为LSTM模型的一个特征来使用。
3.6. 统计检验
确保数据质量对于我们的模型至关重要。为了确认我们的数据是可靠的,我们将进行一些简单的检查,以保证我们所获得和观察到的结果是真实的,而不是由于底层数据分布存在根本性错误而导致的偏差。
3.6.1. 异方差性、多重共线性、序列相关性
- 条件异方差性是指误差项(回归预测值与真实值之间的差异)依赖于数据本身——例如,随着数据点(沿x轴方向)增大,误差项也会增大。
- 多重共线性是指误差项(也称为残差)彼此相互依赖。
- 序列相关性是指一个数据(特征)完全由另一个特征决定或通过某种公式计算得出。
这里我们不再详细展开代码,因为实现起来较为简单,而我们的重点在于深度学习部分,但可以确定的是,数据质量是合格的。
3.7. 特征工程
print('总数据集共有{}个样本,{}个特征。'.format(dataset_total_df.shape[0], \
dataset_total_df.shape[1]))
总数据集共有2265个样本,112个特征。
因此,在整合了各类数据(相关资产、技术指标、基本面分析、傅里叶变换以及ARIMA预测)之后,我们得到了总共112个特征,覆盖2,265天的数据(不过正如之前提到的,只有1,585天用于训练)。
此外,我们还将利用自编码器生成更多的特征。
3.7.1. 使用XGBoost进行特征重要性分析
面对如此多的特征,我们需要判断它们是否都能有效反映高盛股票的走势。例如,我们在数据集中加入了以美元计价的LIBOR利率,因为我们认为LIBOR的变化可能预示着经济形势的变动,进而影响高盛股票的表现。但这一点仍需验证。评估特征重要性的方法有很多,我们选择使用XGBoost,因为它在分类和回归问题中都能取得较好的效果。
由于特征数据集规模较大,此处为了演示目的,我们仅以技术指标为例。在实际的特征重要性测试中,所有选定的特征都被证明具有一定的参考价值,因此在训练GAN时我们不会排除任何特征。
def get_feature_importance_data(data_income):
data = data_income.copy()
y = data['price']
X = data.iloc[:, 1:]
train_samples = int(X.shape[0] * 0.65)
X_train = X.iloc[:train_samples]
X_test = X.iloc[train_samples:]
y_train = y.iloc[:train_samples]
y_test = y.iloc[train_samples:]
return (X_train, y_train), (X_test, y_test)
# 获取训练和测试数据
(X_train_FI, y_train_FI), (X_test_FI, y_test_FI) = get_feature_importance_data(dataset_TI_df)
regressor = xgb.XGBRegressor(gamma=0.0,n_estimators=150,base_score=0.7,colsample_bytree=1,learning_rate=0.05)
xgbModel = regressor.fit(X_train_FI,y_train_FI, \
eval_set = [(X_train_FI, y_train_FI), (X_test_FI, y_test_FI)], \
verbose=False)
eval_result = regressor.evals_result()
training_rounds = range(len(eval_result['validation_0']['rmse']))
让我们绘制训练和验证误差曲线,以便观察训练过程并检查是否存在过拟合现象(从图中可以看出,并没有过拟合)。
plt.scatter(x=training_rounds,y=eval_result['validation_0']['rmse'],label='训练误差')
plt.scatter(x=training_rounds,y=eval_result['validation_1']['rmse'],label='验证误差')
plt.xlabel('迭代次数')
plt.ylabel('RMSE')
plt.title('训练误差与验证误差对比')
plt.legend()
plt.show()
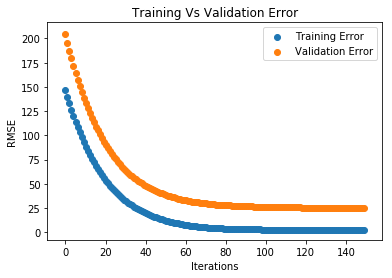
fig = plt.figure(figsize=(8,8))
plt.xticks(rotation='vertical')
plt.bar([i for i in range(len(xgbModel.feature_importances_))], xgbModel.feature_importances_.tolist(), tick_label=X_test_FI.columns)
plt.title('图6:技术指标的特征重要性')
plt.show()
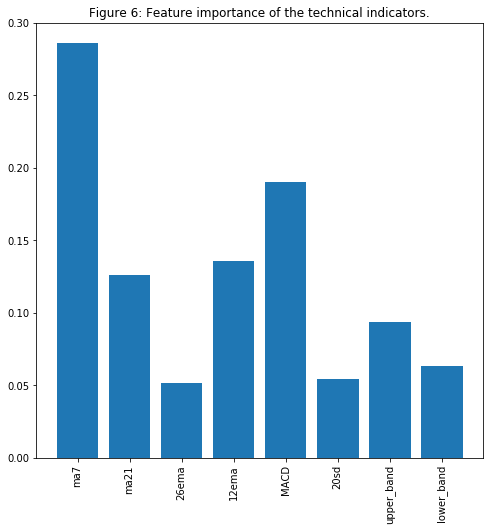
毫不意外的是(对于有股票交易经验的人来说),MA7、MACD和BB等指标被证明是重要的特征之一。
我采用同样的逻辑对整个数据集进行了特征重要性分析——只是训练时间更长,且结果相对复杂,不如仅针对少数几个特征时那么直观易读。
3.8. 使用堆叠自编码器提取高层次特征
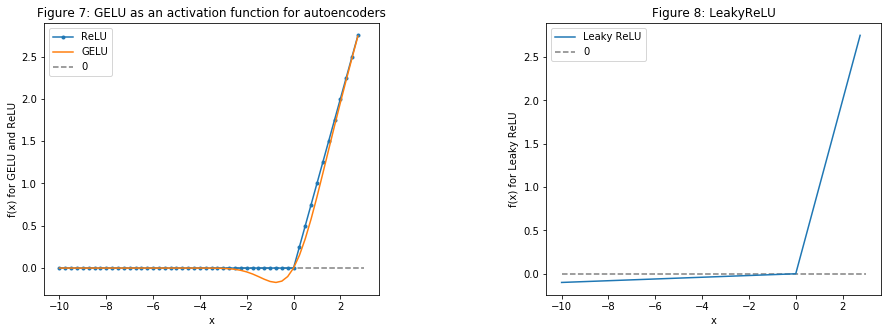
在进入自编码器部分之前,我们先探讨一种替代的激活函数。
3.8.1. 激活函数——GELU(高斯误差线性单元)
GELU——高斯误差线性单元最近被提出——链接。论文作者指出,在多个实验中,使用GELU作为激活函数的神经网络表现优于使用ReLU的网络。gelu也被用于BERT,即我们用来进行新闻情感分析的自然语言处理方法。
我们将在自编码器中使用GELU。
注意:下面的单元格展示了 GELU 数学公式的逻辑推导过程,但它并不是作为激活函数的实际实现。我必须在 MXNet 中重新实现 GELU。如果你直接修改代码,将 act_type='relu' 改为 act_type='gelu',是不会生效的,除非你更改 MXNet 的实现。你可以向整个项目提交一个 Pull Request 来访问 MXNet 中 GELU 的实现。
def gelu(x):
return 0.5 * x * (1 + math.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * math.pow(x, 3))))
def relu(x):
return max(x, 0)
def lrelu(x):
return max(0.01*x, x)
让我们可视化一下 GELU, ReLU 和 LeakyReLU(后者主要用于生成对抗网络——我们也会用到它)。
plt.figure(figsize=(15, 5))
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=.5, hspace=None)
ranges_ = (-10, 3, .25)
plt.subplot(1, 2, 1)
plt.plot([i for i in np.arange(*ranges_)], [relu(i) for i in np.arange(*ranges_)], label='ReLU', marker='.')
plt.plot([i for i in np.arange(*ranges_)], [gelu(i) for i in np.arange(*ranges_)], label='GELU')
plt.hlines(0, -10, 3, colors='gray', linestyles='--', label='0')
plt.title('图7:自编码器中的 GELU 激活函数')
plt.ylabel('GELU 和 ReLU 的 f(x)')
plt.xlabel('x')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot([i for i in np.arange(*ranges_)], [lrelu(i) for i in np.arange(*ranges_)], label='Leaky ReLU')
plt.hlines(0, -10, 3, colors='gray', linestyles='--', label='0')
plt.ylabel('Leaky ReLU 的 f(x)')
plt.xlabel('x')
plt.title('图8:LeakyReLU')
plt.legend()
plt.show()
注意:在本笔记本的未来版本中,我将尝试使用 U-Net(链接),并利用卷积层来提取(甚至创建)更多关于股票底层运动模式的特征。目前,我们仍将只使用由 Dense 层构成的简单自编码器。
好了,回到自编码器,如下所示(图片仅为示意图,并不反映实际的层数、单元数等)。
注意:我在后续版本中会探索的一个做法是移除解码器的最后一层。通常情况下,自编码器的编码器和解码器层数相同。然而,我们希望提取更高层次的特征(而不是重建与输入完全相同的输出),因此可以跳过解码器的最后一层。我们在训练时仍然保持编码器和解码器具有相同的层数,但在生成最终输出时,则使用倒数第二层的输出,因为它包含了更高层次的特征。
batch_size = 64
n_batches = VAE_data.shape[0]/batch_size
VAE_data = VAE_data.values
train_iter = mx.io.NDArrayIter(data={'data': VAE_data[:num_training_days,:-1]}, \
label={'label': VAE_data[:num_training_days, -1]}, batch_size = batch_size)
test_iter = mx.io.NDArrayIter(data={'data': VAE_data[num_training_days:,:-1]}, \
label={'label': VAE_data[num_training_days:,-1]}, batch_size = batch_size)
model_ctx = mx.cpu()
class VAE(gluon.HybridBlock):
def __init__(self, n_hidden=400, n_latent=2, n_layers=1, n_output=784, \
batch_size=100, act_type='relu', **kwargs):
self.soft_zero = 1e-10
self.n_latent = n_latent
self.batch_size = batch_size
self.output = None
self.mu = None
super(VAE, self).__init__(**kwargs)
with self.name_scope():
self.encoder = nn.HybridSequential(prefix='encoder')
for i in range(n_layers):
self.encoder.add(nn.Dense(n_hidden, activation=act_type))
self.encoder.add(nn.Dense(n_latent*2, activation=None))
self.decoder = nn.HybridSequential(prefix='decoder')
for i in range(n_layers):
self.decoder.add(nn.Dense(n_hidden, activation=act_type))
self.decoder.add(nn.Dense(n_output, activation='sigmoid'))
def hybrid_forward(self, F, x):
h = self.encoder(x)
#print(h)
mu_lv = F.split(h, axis=1, num_outputs=2)
mu = mu_lv[0]
lv = mu_lv[1]
self.mu = mu
eps = F.random_normal(loc=0, scale=1, shape=(self.batch_size, self.n_latent), ctx=model_ctx)
z = mu + F.exp(0.5*lv)*eps
y = self.decoder(z)
self.output = y
KL = 0.5*F.sum(1+lv-mu*mu-F.exp(lv),axis=1)
logloss = F.sum(x*F.log(y+self.soft_zero)+ (1-x)*F.log(1-y+self.soft_zero), axis=1)
loss = -logloss-KL
return loss
n_hidden=400 # 每层的神经元数量
n_latent=2
n_layers=3 # 编码器和解码器中各有多少个全连接层
n_output=VAE_data.shape[1]-1
net = VAE(n_hidden=n_hidden, n_latent=n_latent, n_layers=n_layers, n_output=n_output, batch_size=batch_size, act_type='gelu')
net.collect_params().initialize(mx.init.Xavier(), ctx=mx.cpu())
net.hybridize()
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': .01})
print(net)
VAE(
(encoder): HybridSequential(
(0): Dense(None -> 400, Activation(relu))
(1): Dense(None -> 400, Activation(relu))
(2): Dense(None -> 400, Activation(relu))
(3): Dense(None -> 4, linear)
)
(decoder): HybridSequential(
(0): Dense(None -> 400, Activation(relu))
(1): Dense(None -> 400, Activation(relu))
(2): Dense(None -> 400, Activation(relu))
(3): Dense(None -> 11, Activation(sigmoid))
)
)
因此,编码器和解码器各有3层,每层包含400个神经元。
n_epoch = 150
print_period = n_epoch // 10
start = time.time()
training_loss = []
validation_loss = []
for epoch in range(n_epoch):
epoch_loss = 0
epoch_val_loss = 0
train_iter.reset()
test_iter.reset()
n_batch_train = 0
for batch in train_iter:
n_batch_train +=1
data = batch.data[0].as_in_context(mx.cpu())
with autograd.record():
loss = net(data)
loss.backward()
trainer.step(data.shape[0])
epoch_loss += nd.mean(loss).asscalar()
n_batch_val = 0
for batch in test_iter:
n_batch_val +=1
data = batch.data[0].as_in_context(mx.cpu())
loss = net(data)
epoch_val_loss += nd.mean(loss).asscalar()
epoch_loss /= n_batch_train
epoch_val_loss /= n_batch_val
training_loss.append(epoch_loss)
validation_loss.append(epoch_val_loss)
"""if epoch % max(print_period, 1) == 0:
print('Epoch {}, Training loss {:.2f}, Validation loss {:.2f}'.\
format(epoch, epoch_loss, epoch_val_loss))"""
end = time.time()
print('训练完成,耗时 {} 秒。'.format(int(end-start)))
训练在62秒内完成。
dataset_total_df['Date'] = dataset_ex_df['Date']
vae_added_df = mx.nd.array(dataset_total_df.iloc[:, :-1].values)
print('新创建的(来自自编码器)特征的形状是 {}。'.format(vae_added_df.shape))
新创建的(来自自编码器)特征的形状是 (2265, 112)。
我们从自编码器中创建了112个额外的特征。由于我们只希望保留高层次特征(整体模式),我们将使用主成分分析(PCA)对这112个新特征构建一个特征组合。这将降低数据的维度(列数)。该特征组合的描述能力将与原始的112个特征相同。
注意 这再次纯属实验性质。我并不完全确定所描述的逻辑是否成立。如同人工智能和深度学习中的其他一切一样,这也是一门艺术,需要通过实验来验证。
3.8.2. 使用PCA的特征组合
# 我们希望PCA生成的新组件能够解释80%的方差
pca = PCA(n_components=.8)
x_pca = StandardScaler().fit_transform(vae_added_df)
principalComponents = pca.fit_transform(x_pca)
principalComponents.n_components_
84
因此,为了解释80%的方差,我们需要84个(总共112个)特征。这仍然很多。所以,目前我们暂不使用自编码器生成的特征。我计划构建一种自编码器架构,在其中从中间层(而非最后一层)获取输出,并将其连接到另一个具有30个神经元的全连接层。这样,我们就可以1) 只提取更高层次的特征,2) 显著减少列数。
3.9. 用于衍生品定价异常检测的深度无监督学习
-- 将于近期添加。
4. 生成对抗网络(GAN)
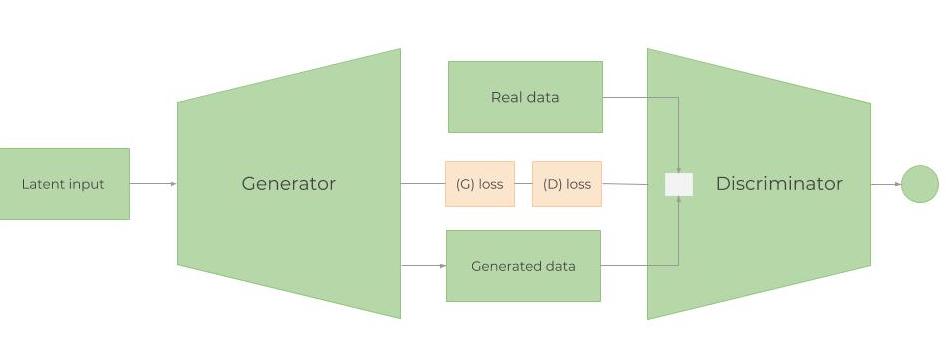
图9:简单的GAN架构
GAN是如何工作的?
如前所述,本笔记本的目的并非详细讲解深度学习背后的数学原理,而是展示其应用。当然,我认为从基础到细节的全面而扎实的理解至关重要。因此,我们将尝试在高屋建瓴的层面概述GAN的工作原理,以便读者充分理解在预测股票价格变动时使用GAN的合理性。如果您对GAN已经很熟悉,请随意跳过本节及下一节(但请务必查看第4.2节“WGAN”)。
GAN网络由两个模型组成——生成器($G$)和判别器($D$)。训练GAN的步骤如下:
- 生成器利用随机数据(噪声$z$)尝试“生成”与真实数据难以区分或极其接近的数据。其目的是学习真实数据的分布。
- 判别器会随机接收真实数据或生成的数据作为输入,它充当分类器,试图判断数据是来自生成器还是真实数据。$D$会估计输入样本属于真实数据集的概率。(关于比较两个分布的更多信息,请参阅下文第4.2节“GAN与WGAN”)。
- 随后,$G$和$D$的损失会被合并,并反向传播回生成器。因此,生成器的损失同时取决于生成器和判别器。这一步有助于生成器学习真实数据的分布。如果生成器生成的数据不够逼真(分布不一致),判别器就能很容易地区分生成数据和真实数据,从而导致判别器的损失非常小。而判别器损失越小,生成器的损失就会越大(见下方$L(D, G)$的公式)。这就使得判别器的设计变得有些棘手,因为过于优秀的判别器总是会导致巨大的生成器损失,从而使生成器无法继续学习。
- 这一过程将持续进行,直到判别器再也无法区分生成数据和真实数据为止。
当$D$和$G$协同工作时,它们实际上是在进行一场“极小化极大”博弈(生成器试图“欺骗”判别器,提高其对虚假样本的判断概率,即最小化$\mathbb{E}{z \sim p{z}(z)} [\log (1 - D(G(z)))]$。而判别器则希望通过最大化$\mathbb{E}{x \sim p{r}(x)} [\log D(x)]$来区分来自生成器的数据$D(G(z))$)。然而,由于损失函数是分开的,尚不清楚两者如何能够共同收敛(这就是为什么我们会使用一些改进版的GAN,例如Wasserstein GAN)。总体而言,联合损失函数如下:
$$L(D, G) = \mathbb{E}{x \sim p{r}(x)} [\log D(x)] + \mathbb{E}_{z \sim p_z(z)} [\log(1 - D(G(z)))]$$
注:有关训练GAN的实用技巧,请参阅此处。
注:在本笔记本中,我不会包含GAN和强化学习部分的完整代码——仅会展示执行结果(单元格输出)。如需代码,请提交拉取请求或与我联系。
4.1. 为什么使用GAN进行股市预测?
生成对抗网络(GAN)最近主要被用于生成逼真的图像、绘画和视频片段。很少有GAN被应用于像我们这样的时间序列数据预测。不过,其核心思想应该是一致的——我们希望预测未来的股票走势。在未来,GS公司的股票走势模式和行为大致应保持不变(除非其运营方式发生根本性变化,或者经济环境发生剧烈改变)。因此,我们希望“生成”未来数据,使其分布与我们已有的历史交易数据相似(当然,不必完全相同)。理论上来说,这应该是可行的。
在我们的案例中,我们将使用LSTM作为时间序列生成器,用CNN作为判别器。
4.2. Metropolis-Hastings GAN与Wasserstein GAN
注: 接下来的几节内容假定读者已具备一定的GAN相关经验。
一、Metropolis-Hastings GAN
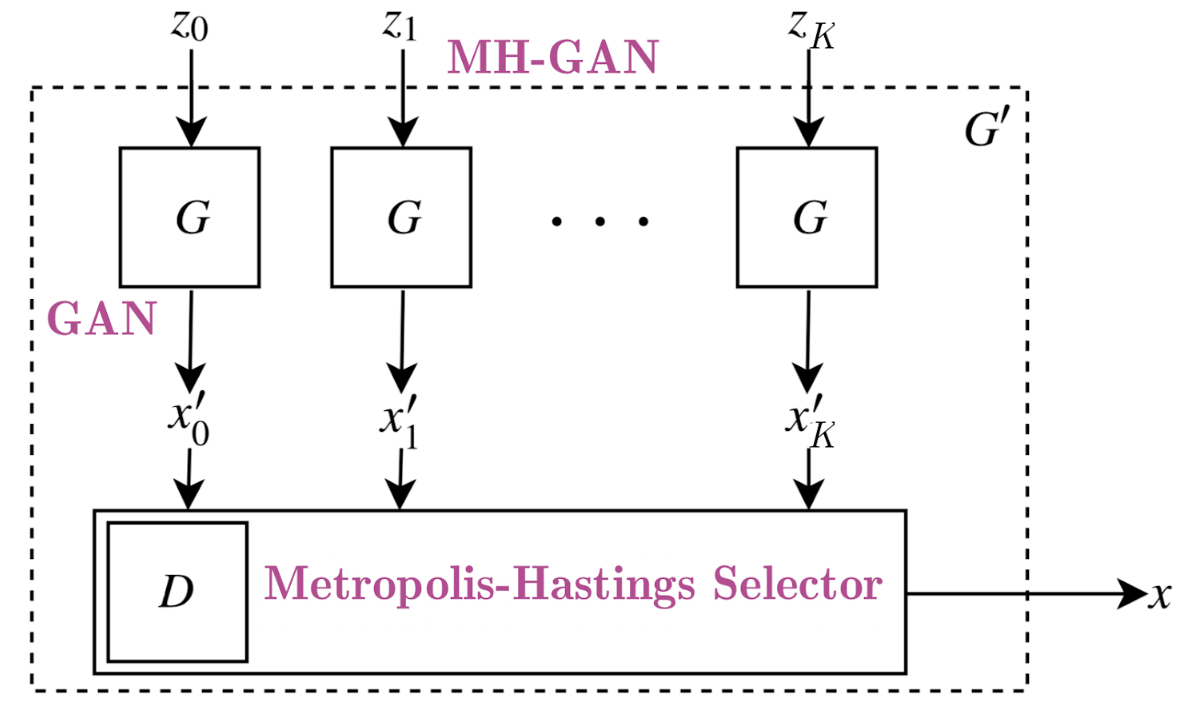
近期,Uber工程团队提出了一种对传统GAN的改进方法,称为Metropolis-Hastings GAN(MHGAN)。Uber团队提出的这一思路与其类似,即由Google和加州大学伯克利分校共同提出的判别器拒绝采样(DRS)。其核心思想在于:在传统的GAN训练中,判别器$D$仅用于指导生成器$G$更好地学习;而在训练完成后,$D$往往不再被使用。然而,MHGAN和DRS则尝试利用$D$来筛选出更接近真实数据分布的生成样本——两者的区别在于,MHGAN采用了马尔可夫链蒙特卡洛(MCMC)进行采样。
MHGAN首先从生成器$G$中生成**K个样本(这些样本由独立的噪声输入$z_0$至$z_K$产生,如图所示)。随后,它依次遍历这K**个输出$x'_0$至$x'_K$,并根据由判别器$D$定义的接受准则,决定是保留当前样本还是继续使用上一个已被接受的样本。最终被保留的输出即被视为$G$的真实生成结果。
注:MHGAN最初由Uber使用PyTorch实现,我仅将其移植到了MXNet/Gluon框架中。
注:我也会在不久的将来将其上传至GitHub。
图10:MHGAN的可视化示意图(摘自Uber的原始文章Uber post)。
二、Wasserstein GAN
GAN的训练过程相当复杂,模型常常难以收敛,并且容易出现模式坍塌现象。为此,我们将采用一种名为Wasserstein GAN的改进版本——WGAN。
此处我们不深入细节,但需要强调以下几点:
- 如前所述,GAN的核心目标是让生成器能够将随机噪声转化为我们希望模仿的真实数据。因此,在GAN中比较两个概率分布之间的相似性至关重要。目前最常用的两种度量方式是:
- KL散度(Kullback–Leibler):$D_{KL}(p | q) = \int_x p(x) \log \frac{p(x)}{q(x)} dx$。当$p(x)$等于$q(x)$时,$D_{KL}$为零;
- JS散度(Jensen–Shannon):$D_{JS}(p | q) = \frac{1}{2} D_{KL}(p | \frac{p + q}{2}) + \frac{1}{2} D_{KL}(q | \frac{p + q}{2})$。JS散度的取值范围在0到1之间,与KL散度不同,它是对称且更为平滑的。在GAN训练中,将损失函数从KL散度切换为JS散度曾取得了显著的成功。
- WGAN则采用Wasserstein距离作为损失函数,公式为:$W(p_r, p_g) = \frac{1}{K} \sup_{| f |L \leq K} \mathbb{E}{x \sim p_r}[f(x)] - \mathbb{E}_{x \sim p_g}[f(x)]$(其中$\sup$表示上确界)。该距离也被称为“地球移动距离”,因为它可以被直观地理解为将一堆沙子(分别服从不同的概率分布)移动到另一堆,同时使整个过程所需的能量最小化。相较于KL和JS散度,Wasserstein距离能够提供更加平滑的度量,避免了散度值的突然跳变,从而使得梯度下降过程更加稳定。
- 此外,与KL和JS散度相比,Wasserstein距离几乎处处可导。在反向传播过程中,我们需要对损失函数求导以计算梯度,进而更新网络权重。因此,拥有一个可导的损失函数显得尤为重要。
毫不夸张地说,这部分内容是本笔记本中最难的部分。将WGAN和MHGAN结合起来,我花了整整三天时间。
4.4. 生成器——单层RNN
4.4.1. LSTM或GRU
如前所述,生成器是一个LSTM网络,属于循环神经网络(RNN)的一种。RNN常用于处理时间序列数据,因为它们能够记住所有历史数据点,并捕捉随时间变化的模式。然而,由于其自身特性,RNN经常面临“梯度消失”问题——即在训练过程中,权重更新的幅度变得极小,以至于无法继续优化,导致网络无法达到最小化损失的目标。有时也会出现相反的情况,即梯度变得过大,这被称为“梯度爆炸”。解决这一问题的方法相对简单:当梯度超过某个阈值时,对其进行裁剪,即梯度裁剪。为了解决梯度消失问题,人们提出了两种改进方案:门控循环单元(GRU)和长短期记忆网络(LSTM)。两者的主要区别在于:1)GRU只有两个门(更新门和重置门),而LSTM则有四个门(更新门、输入门、遗忘门和输出门);2)LSTM会维护内部记忆状态,而GRU则不会;3)LSTM会在输出门之前应用非线性激活函数(sigmoid),而GRU则没有。
在大多数情况下,LSTM和GRU在准确率方面表现相近,但GRU的计算开销要小得多,因为其可训练参数较少。尽管如此,LSTM的应用更为广泛。
严格来说,LSTM单元(即各个门)背后的数学公式如下:
$$g_t = \text{tanh}(X_t W_{xg} + h_{t-1} W_{hg} + b_g),$$
$$i_t = \sigma(X_t W_{xi} + h_{t-1} W_{hi} + b_i),$$
$$f_t = \sigma(X_t W_{xf} + h_{t-1} W_{hf} + b_f),$$
$$o_t = \sigma(X_t W_{xo} + h_{t-1} W_{ho} + b_o),$$
$$c_t = f_t \odot c_{t-1} + i_t \odot g_t,$$
$$h_t = o_t \odot \text{tanh}(c_t),$$
其中$\odot$表示逐元素相乘运算符,对于任意$x = [x_1, x_2, \ldots, x_k]^\top \in R^k$,两种激活函数分别为:
$$\sigma(x) = \left[\frac{1}{1+\exp(-x_1)}, \ldots, \frac{1}{1+\exp(-x_k)}]\right]^\top,$$
$$\text{tanh}(x) = \left[\frac{1-\exp(-2x_1)}{1+\exp(-2x_1)}, \ldots, \frac{1-\exp(-2x_k)}{1+\exp(-2x_k)}\right]^\top$$
4.4.2. LSTM 架构
LSTM 的架构非常简单——一层 LSTM,包含 112 个输入单元(因为数据集中有 112 个特征)和 500 个隐藏单元,以及一层 Dense 层,输出为单个值——即每天的价格。初始化方法采用 Xavier 初始化,并使用 L1 损失函数(即带有 L1 正则化的平均绝对误差损失——有关正则化的更多信息,请参阅第 4.4.5 节)。
注意——在代码中可以看到,我们使用了 Adam 优化器(学习率设为 0.01)。目前不必过于关注这一点——后面有一个专门的章节会解释我们使用的超参数(学习率除外,因为我们使用了学习率调度器——第 4.4.3 节),以及如何对这些超参数进行优化——第 4.6 节)。
gan_num_features = dataset_total_df.shape[1]
sequence_length = 17
class RNNModel(gluon.Block):
def __init__(self, num_embed, num_hidden, num_layers, bidirectional=False, \
sequence_length=sequence_length, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.num_hidden = num_hidden
with self.name_scope():
self.rnn = rnn.LSTM(num_hidden, num_layers, input_size=num_embed, \
bidirectional=bidirectional, layout='TNC')
self.decoder = nn.Dense(1, in_units=num_hidden)
def forward(self, inputs, hidden):
output, hidden = self.rnn(inputs, hidden)
decoded = self.decoder(output.reshape((-1, self.num_hidden)))
return decoded, hidden
def begin_state(self, *args, **kwargs):
return self.rnn.begin_state(*args, **kwargs)
lstm_model = RNNModel(num_embed=gan_num_features, num_hidden=500, num_layers=1)
lstm_model.collect_params().initialize(mx.init.Xavier(), ctx=mx.cpu())
trainer = gluon.Trainer(lstm_model.collect_params(), 'adam', {'learning_rate': .01})
loss = gluon.loss.L1Loss()
我们将 LSTM 层设置为 500 个神经元,并使用 Xavier 初始化。对于正则化,我们采用 L1 正则化。让我们看看 MXNet 打印出的 LSTM 内部结构。
print(lstm_model)
RNNModel(
(rnn): LSTM(112 -> 500, TNC)
(decoder): Dense(500 -> 1, linear)
)
正如我们所见,LSTM 的输入是 112 个特征(dataset_total_df.shape[1]),这些特征随后进入 LSTM 层的 500 个神经元,再被转换为一个单一的输出——即股票价格值。
LSTM 的逻辑是:我们取 17 天(sequence_length)的数据(再次强调,这些数据包括每日 GS 股票的价格以及其他相关特征——如相关资产、情绪等——来预测第 18 天的价格。
在另一篇文章中,我将探讨对标准 LSTM 进行改进是否更有益,例如:
- 使用 双向 LSTM 层——理论上,从数据集末尾向开头反向传递信息,可能有助于 LSTM 更好地捕捉股票走势的模式。
- 使用 堆叠式 RNN 架构——不只是一层 LSTM,而是两层或更多层。然而,这样做可能存在过拟合的风险,因为我们的数据量并不大(只有 1,585 天的数据)。
- 探索 GRU——正如之前所解释的,GRU 的单元结构更为简单。
- 在 RNN 中加入 注意力 向量。
4.4.3. 学习率调度器
学习率是最重要的超参数之一。对于几乎所有的优化器(如 SGD、Adam 或 RMSProp)而言,在训练神经网络时设定合适的学习率至关重要,因为它既决定了收敛的速度,也影响着模型的最终性能。最简单的学习率策略之一就是在整个训练过程中保持固定的学习率。选择较小的学习率有助于优化器找到较好的解,但这也意味着初始收敛速度较慢。通过随时间调整学习率,可以克服这一权衡。
最近的一些论文,比如 这篇, 表明在训练过程中动态调整全局学习率,无论是在收敛速度还是训练时间方面,都有显著的优势。
class TriangularSchedule():
def __init__(self, min_lr, max_lr, cycle_length, inc_fraction=0.5):
self.min_lr = min_lr
self.max_lr = max_lr
self.cycle_length = cycle_length
self.inc_fraction = inc_fraction
def __call__(self, iteration):
if iteration <= self.cycle_length*self.inc_fraction:
unit_cycle = iteration * 1 / (self.cycle_length * self.inc_fraction)
elif iteration <= self.cycle_length:
unit_cycle = (self.cycle_length - iteration) * 1 / (self.cycle_length * (1 - self.inc_fraction))
else:
unit_cycle = 0
adjusted_cycle = (unit_cycle * (self.max_lr - self.min_lr)) + self.min_lr
return adjusted_cycle
class CyclicalSchedule():
def __init__(self, schedule_class, cycle_length, cycle_length_decay=1, cycle_magnitude_decay=1, **kwargs):
self.schedule_class = schedule_class
self.length = cycle_length
self.length_decay = cycle_length_decay
self.magnitude_decay = cycle_magnitude_decay
self.kwargs = kwargs
def __call__(self, iteration):
cycle_idx = 0
cycle_length = self.length
idx = self.length
while idx <= iteration:
cycle_length = math.ceil(cycle_length * self.length_decay)
cycle_idx += 1
idx += cycle_length
cycle_offset = iteration - idx + cycle_length
schedule = self.schedule_class(cycle_length=cycle_length, **self.kwargs)
return schedule(cycle_offset) * self.magnitude_decay**cycle_idx
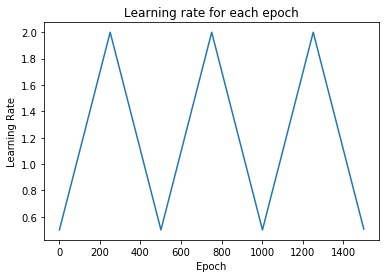
schedule = CyclicalSchedule(TriangularSchedule, min_lr=0.5, max_lr=2, cycle_length=500)
iterations=1500
plt.plot([i+1 for i in range(iterations)],[schedule(i) for i in range(iterations)])
plt.title('每轮迭代的学习率')
plt.xlabel("轮次")
plt.ylabel("学习率")
plt.show()
4.4.4. 如何防止过拟合及偏差-方差权衡
在拥有大量特征和神经网络的情况下,我们需要确保防止过拟合,并关注总损失。
我们使用多种技术来防止过拟合(不仅在LSTM中,也在CNN和自编码器中):
- 确保数据质量。我们已经进行了统计检验,确保数据不存在多重共线性或序列自相关问题。此外,我们还对每个特征进行了重要性检查。最后,初始的特征选择(例如选择相关资产、技术指标等)是基于对股票市场运作机制的领域知识进行的。
- 正则化(或权重惩罚)。最常用的两种正则化技术是LASSO(L1)和Ridge(L2)。L1会在损失函数中加入平均绝对误差,而L2则加入均方误差。不深入数学细节的话,基本区别在于:Lasso回归(L1)同时进行变量选择和参数收缩,而Ridge回归只进行参数收缩,最终会将所有系数纳入模型。当存在相关变量时,Ridge回归可能是更优的选择。此外,Ridge回归在最小二乘估计具有较高方差的情况下表现最佳。因此,具体使用哪种正则化方法取决于我们的模型目标。这两种正则化的效果截然不同。虽然它们都会惩罚较大的权重,但L1正则化在零点处会产生不可导的函数。L2正则化倾向于较小的权重,而L1正则化则倾向于使权重趋近于零。因此,使用L1正则化可能会得到一个稀疏模型——即参数较少的模型。在两种情况下,L1和L2正则化的模型参数都会“收缩”,但在L1正则化的情况下,这种收缩会直接影响模型的复杂度(即参数数量)。确切地说,Ridge回归在最小二乘估计具有较高方差时表现最佳。L1对异常值更具鲁棒性,在数据稀疏时使用,并能生成特征重要性。我们将使用L1。
- Dropout。Dropout层会随机移除隐藏层中的节点。
- 密集-稀疏-密集训练。 - 链接
- 早停法。
在构建复杂的神经网络时,另一个重要的考虑因素是偏差-方差权衡。基本上,我们在训练网络时得到的误差是由偏差、方差以及不可约误差——σ(由噪声和随机性引起的误差)——共同决定的。该权衡关系的最简单公式为:
$$Error = bias^{2} + variance + \sigma$$
- 偏差。偏差衡量的是在训练数据集上训练好的算法在未见数据上的泛化能力。高偏差(欠拟合)意味着模型无法很好地处理未见数据。
- 方差。方差衡量的是模型对数据集变化的敏感程度。高方差即为过拟合。
4.4.5. 自定义权重初始化器和自定义损失函数
即将推出
4.5. 判别器——一维卷积神经网络
4.5.1. 为什么使用CNN作为判别器?
我们通常将CNN用于与图像相关的任务(分类、上下文提取等)。它们在逐层提取特征方面非常强大。例如,在一张狗的图片中,第一层卷积会检测边缘,第二层开始检测圆形,第三层则会检测鼻子。而在我们的案例中,数据点形成小趋势,小趋势又形成更大的趋势,这些趋势进一步组合成模式。CNN的特征提取能力可以用来捕捉GS公司股价变动中的模式信息。
使用CNN的另一个原因是,CNN擅长处理空间数据——也就是说,彼此靠近的数据点比分散的数据点之间关联性更强。这一点对于时间序列数据同样适用。在我们的案例中,每个数据点对应连续的一天。很自然地,我们可以假设相邻的两天之间关联性更强。需要注意的一点是(尽管本研究并未涉及),季节性因素可能会如何影响CNN的工作(如果有的话)。
注:如同本笔记本中的许多部分一样,将CNN应用于时间序列数据仍处于实验阶段。我们将观察结果,但不会提供数学或其他形式的证明。而且,使用不同的数据、激活函数等,结果可能会有所不同。
4.5.1. CNN架构
图11:CNN架构的高层次概览。
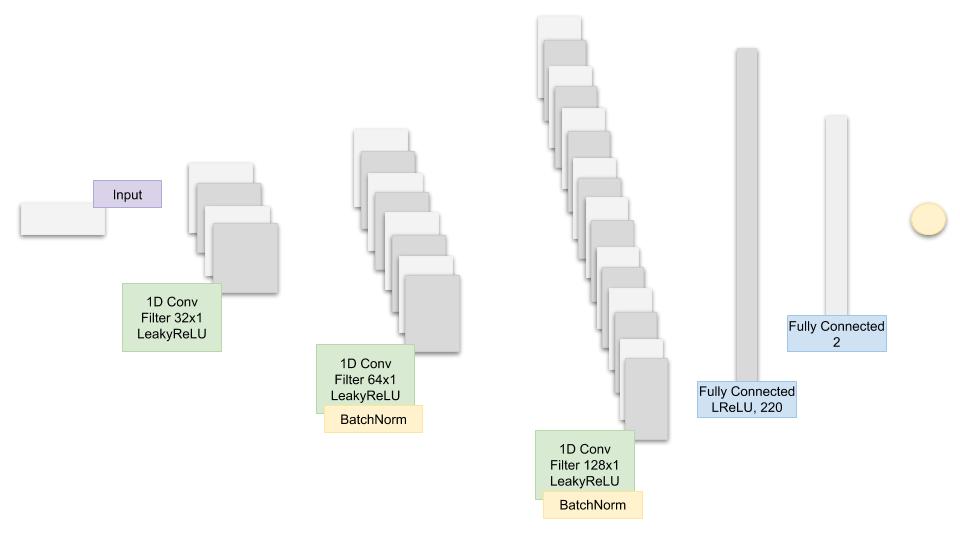
GAN内部的CNN代码如下所示:
num_fc = 512
# ... GAN的其他部分
cnn_net = gluon.nn.Sequential()
with net.name_scope():
# 添加一维卷积层
cnn_net.add(gluon.nn.Conv1D(32, kernel_size=5, strides=2))
cnn_net.add(nn.LeakyReLU(0.01))
cnn_net.add(gluon.nn.Conv1D(64, kernel_size=5, strides=2))
cnn_net.add(nn.LeakyReLU(0.01))
cnn_net.add(nn.BatchNorm())
cnn_net.add(gluon.nn.Conv1D(128, kernel_size=5, strides=2))
cnn_net.add(nn.LeakyReLU(0.01))
cnn_net.add(nn.BatchNorm())
# 添加两个全连接层
cnn_net.add(nn.Dense(220, use_bias=False), nn.BatchNorm(), nn.LeakyReLU(0.01))
cnn_net.add(nn.Dense(220, use_bias=False), nn.Activation(activation='relu'))
cnn_net.add(nn.Dense(1))
# ... GAN的其他部分
让我们打印一下CNN。
print(cnn_net)
Sequential(
(0): Conv1D(None -> 32, kernel_size=(5,), stride=(2,))
(1): LeakyReLU(0.01)
(2): Conv1D(None -> 64, kernel_size=(5,), stride=(2,))
(3): LeakyReLU(0.01)
(4): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(5): Conv1D(None -> 128, kernel_size=(5,), stride=(2,))
(6): LeakyReLU(0.01)
(7): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(8): Dense(None -> 220, linear)
(9): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=None)
(10): LeakyReLU(0.01)
(11): Dense(None -> 220, linear)
(12): Activation(relu)
(13): Dense(None -> 1, linear)
)
4.6. 超参数
我们将跟踪和优化的超参数包括:
batch_size:LSTM 和 CNN 的批量大小cnn_lr:CNN 的学习率strides:CNN 中的步幅数量lrelu_alpha:GAN 中 LeakyReLU 的 alpha 参数batchnorm_momentum:CNN 中批归一化层的动量padding:CNN 中的填充方式kernel_size':1:CNN 中的卷积核大小dropout:LSTM 中的丢弃率filters:初始滤波器的数量
我们将训练 200 个 epochs。
5. 超参数优化
在 GAN 训练完 200 个 epoch 后,它会记录 MAE(即 LSTM 中的误差函数 $G$),并将其作为奖励值传递给强化学习模块。强化学习模块将决定是更改超参数,还是继续使用当前的超参数集进行训练。正如后文所述,这种方法主要用于实验性地探索强化学习的应用。
如果强化学习决定更新超参数,它将调用下面讨论的贝叶斯优化库,以获得下一组预期最优的超参数组合。
5.1. 基于强化学习的超参数优化
为什么要在超参数优化中使用强化学习呢?股票市场瞬息万变。即使我们成功训练出能够生成极其准确结果的 GAN 和 LSTM 模型,这些结果也可能只在特定时期内有效。这意味着我们需要不断地对整个流程进行优化。为了优化这一过程,我们可以:
- 添加或移除特征(例如加入可能具有相关性的新股票或货币)
- 改进我们的深度学习模型。而改进模型最重要的方法之一就是调整超参数(详见第 5 节)。一旦找到一组合适的超参数,我们就需要决定何时更换它们,以及何时继续使用现有的超参数集(即探索与利用之间的权衡)。此外,股票市场是一个连续的状态空间,受到数百万种因素的影响。
注:本笔记本中关于强化学习的部分更多地是为了研究目的。我们将以 GAN 作为环境,尝试不同的强化学习方法。实际上,在不使用强化学习的情况下,也有许多成功的方法可以对深度学习模型的超参数进行优化。不过……为什么不试试呢?
注:接下来的几节内容假设您已经具备一定的强化学习知识——尤其是策略类方法和 Q 学习。
5.1.1. 强化学习理论
在不解释强化学习基本原理的情况下,我们将直接进入此处实现的具体方法细节。由于我们并不了解完整的环境状态,因此无法建立明确的环境模型——如果存在这样的模型,我们就无需预测股票价格走势,因为价格会直接遵循该模型运行。基于这一原因,我们将采用无模型强化学习算法,具体分为策略优化和 Q 学习两类。
- Q 学习:在 Q 学习中,我们学习的是从某一状态下采取行动所获得的价值。“Q 值”是指采取该行动后预期得到的回报。我们将使用 Rainbow 算法,它是七种 Q 学习算法的组合。
- 策略优化:在策略优化中,我们学习的是从某一状态下应采取的动作。(如果我们使用类似 Actor-Critic 的方法)我们还会学习处于某一状态下的价值。我们将使用近端策略优化算法。
构建强化学习算法的一个关键环节是准确设定奖励机制。奖励必须全面反映环境及其与智能体之间的交互关系。我们定义奖励 R 如下:
$$Reward = 2*loss_G + loss_D + accuracy_G,$$
其中 $loss_G$、$accuracy_G$ 和 $loss_D$ 分别表示生成器的损失、生成器的准确率以及判别器的损失。这里的环境是 GAN 及其驱动的 LSTM 训练结果。智能体可采取的动作则是如何调整 GAN 的 $D$ 和 $G$ 网络的超参数。
5.1.1.1. Rainbow
什么是 Rainbow?
Rainbow(链接) 是一种基于 Q 学习的离策略深度强化学习算法,它结合了七种不同的技术:
- DQN。DQN 是 Q 学习算法的扩展,使用神经网络来表示 Q 值。与监督学习(深度学习)类似,在 DQN 中我们训练一个神经网络,并试图最小化损失函数。我们通过随机采样转换(状态、动作、奖励)来训练网络。网络的层不仅可以是全连接层,也可以是卷积层等。
- 双 Q 学习。双 QL 解决了 Q 学习中的一个重要问题,即估值偏高问题。
- 优先回放。在普通的 DQN 中,所有的转换都会被存储在一个回放缓冲区中,并且从该缓冲区中均匀采样。然而,在学习过程中,并非所有转换都同样有益(这也使得学习效率低下,需要更多的回合)。而优先经验回放并不进行均匀采样,而是采用一种分布,对之前迭代中具有较高 Q 损失的样本给予更高的采样概率。
- 对决网络。对决网络通过使用两条独立的流(即两个不同的小型神经网络),稍微改变了 Q 学习的架构。一条流用于计算价值,另一条流用于计算 优势。这两条流共享一个卷积编码器。难点在于如何将两条流合并——这里使用了一种特殊的聚合器(Wang 等,2016)。
- 优势 的公式为 $A(s, a) = Q(s, a) - V(s)$,通常来说,它是比较某个特定状态下某一动作相对于平均动作的好坏程度。当“错误”动作无法通过负奖励惩罚时,有时会用到优势值。因此,优势值会进一步奖励那些优于平均动作的良好行为。
- 多步学习。多步学习的最大区别在于,它使用 N 步回报来计算 Q 值(而不仅仅是下一步的回报),这自然应该更加准确。
- 分布式强化学习。Q 学习以平均估计的 Q 值作为目标值。然而,在许多情况下,不同情境下的 Q 值可能并不相同。分布式强化学习可以直接学习(或近似)Q 值的分布,而不是对其进行平均。当然,其中的数学原理要复杂得多,但对我们而言,其好处在于可以更准确地采样 Q 值。
- 噪声网络。基础的 DQN 使用简单的 ε-贪心机制来进行探索。但这种探索方式有时效率较低。噪声网络则通过添加一个带有噪声的线性层来解决这一问题。随着时间的推移,网络会学会忽略这些噪声(作为一条额外的噪声流)。不过,空间中不同区域的学习速度各不相同,从而实现对状态的探索。
注:敬请关注——我将于 2019 年 2 月初在 GitHub 上上传 Rainbow 的 MXNet/Gluon 实现。
5.1.1.2. PPO
近端策略优化(PPO) 是一种无模型的策略优化型强化学习方法。它比其他算法更容易实现,同时能取得非常好的效果。
我们为什么要使用 PPO?PPO 的一大优势在于,它直接学习策略,而不是像 Q 学习那样通过价值间接学习策略。它可以在连续动作空间中很好地工作,这非常适合我们的应用场景,并且能够通过均值和标准差学习分布概率(如果在输出端加入 softmax 函数)。
策略梯度方法的一个问题是,它们对步长的选择极其敏感:步长太小会导致进展过于缓慢(很可能是因为需要计算二阶导数矩阵);而步长太大则会产生大量噪声,显著降低性能。由于策略的变化,输入数据是非平稳的(奖励和观测的分布也会随之改变)。与监督学习相比,步长选择不当可能会带来更为严重的后果,因为它会影响后续访问的整体分布。PPO 可以解决这些问题。此外,与其他一些方法相比,PPO:
- 更加简单,例如与 ACER 相比,ACER 需要额外的代码来维护离策略相关性以及回放缓冲区;或者与 TRPO 相比,TRPO 对代理目标函数施加了一个约束(旧策略与新策略之间的 KL 散度)。这个约束用于控制策略变化幅度,避免因变化过大而导致不稳定。而 PPO 则通过使用 夹紧在 [1-𝜖, 1+𝜖] 之间的代理目标函数,并引入对更新过大的惩罚项,来减少由该约束带来的计算开销。
- 具有更强的兼容性,能够与那些在价值函数和策略函数之间共享参数,或包含辅助损失的算法配合使用,这一点优于 TRPO(尽管 PPO 同样具备信任域策略优化的优势)。
注:为了本次实验的目的,我们不会深入研究和优化 RL 方法,包括 PPO 等算法。相反,我们将直接采用现有的工具,并尝试将其融入到我们针对 GAN、LSTM 和 CNN 模型的超参数优化流程中。我们将复用并定制的代码由 OpenAI 开发,可在 此处获取。
5.1.2. 强化学习的进一步工作
关于进一步探索强化学习的一些想法:
- 我接下来计划介绍的内容之一是使用 增强随机搜索(链接) 作为替代算法。该算法的作者来自加州大学伯克利分校,他们成功实现了与 PPO 等当前最先进方法相似的奖励效果,但平均速度快了约 15 倍。
- 奖励函数的选择非常重要。我在上面已经说明了目前使用的奖励函数,但我还会尝试使用不同的奖励函数作为替代方案。
- 使用 好奇心驱动的探索策略。
- 构建伯克利人工智能研究团队(BAIR)提出的 多智能体 架构——链接。
5.2. 贝叶斯优化
与耗时较长的网格搜索相比,我们将使用贝叶斯优化来寻找最佳超参数组合。我们使用的库已经实现好——链接。
接下来的代码部分仅展示初始化过程。
# 初始化优化器
from bayes_opt import BayesianOptimization
from bayes_opt import UtilityFunction
utility = UtilityFunction(kind="ucb", kappa=2.5, xi=0.0)
5.2.1. 高斯过程
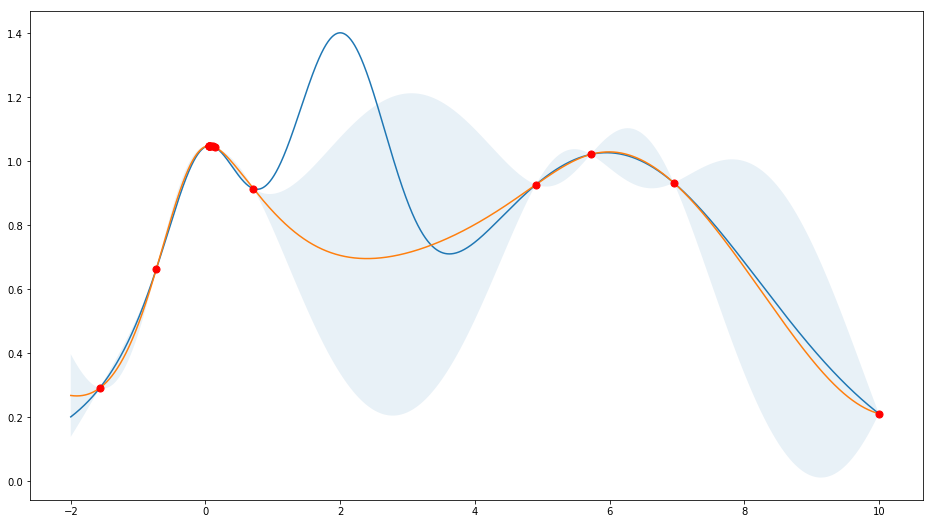
6. 结果
from utils import plot_prediction
最后,我们将比较在流程的不同阶段之后,使用未见过的(测试)数据作为输入时,LSTM 的输出结果。
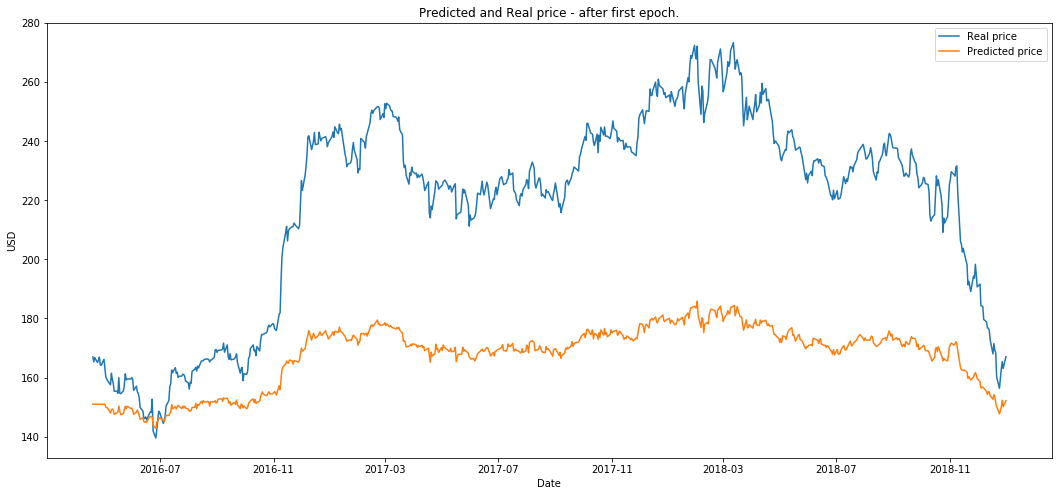
- 第一个 epoch 后的绘图。
plot_prediction('预测价格与真实价格 - 第一个 epoch 后。')
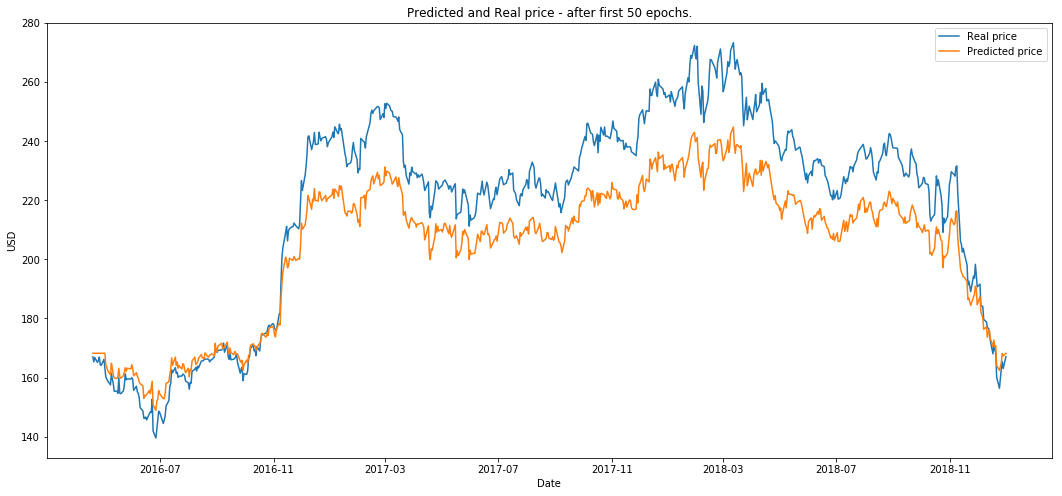
- 50 个 epoch 后的绘图。
plot_prediction('预测价格与真实价格 - 前 50 个 epoch 后。')
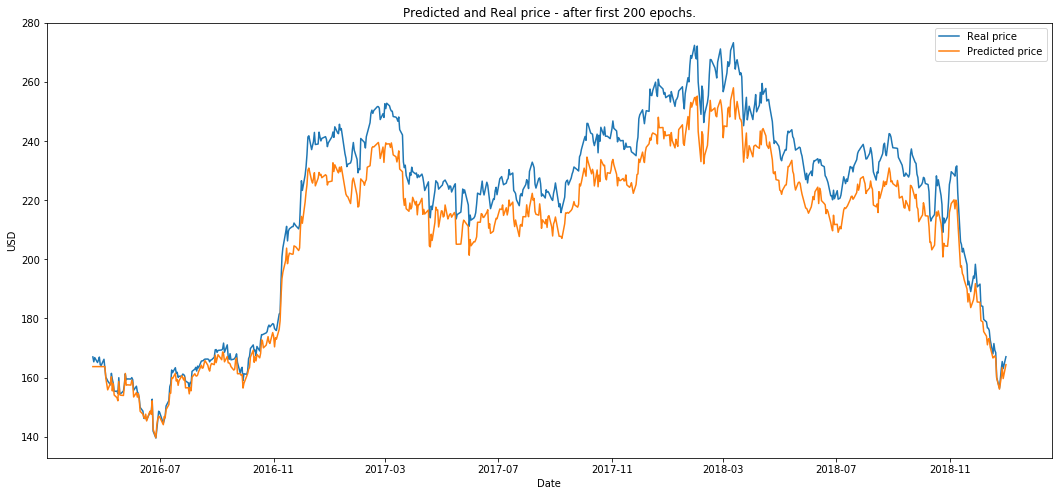
plot_prediction('预测价格与真实价格 - 前 200 个 epoch 后。')
强化学习运行了十个回合(我们定义一个回合为在 200 个 epoch 上进行一次完整的 GAN 训练)。
plot_prediction('最终结果。')
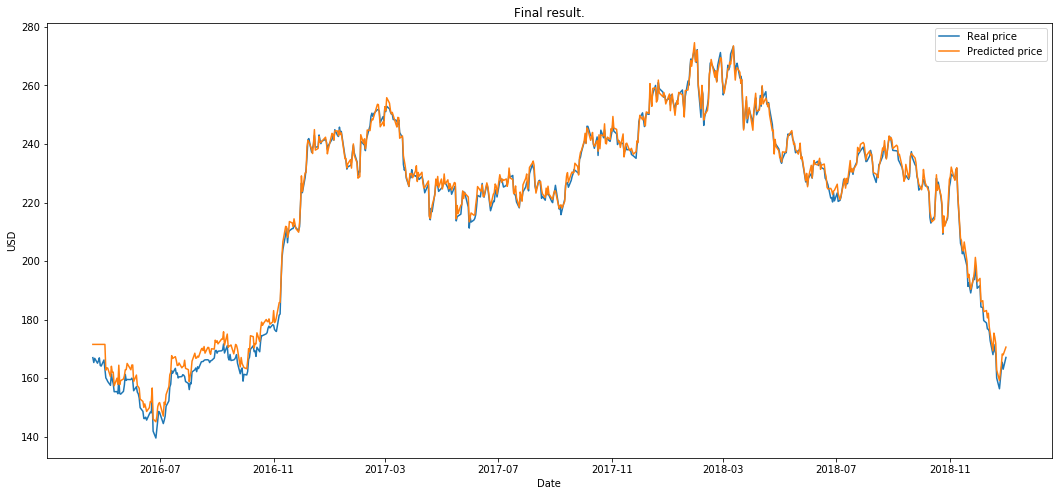
下一步,我将尝试把各个部分单独拆解出来,分析哪些方法有效以及原因。我们为何会得到这些结果?这是否只是巧合?敬请期待。
下一步是什么?
- 接下来,我将尝试构建一个用于测试交易算法的强化学习环境,该算法可以决定何时以及如何进行交易。GAN 的输出将成为该环境中的一项参数。
关于我
www.linkedin.com/in/borisbanushev
免责声明
本笔记本内容仅供参考。其中所包含的任何信息均不构成对任何特定证券、证券组合、交易或投资策略适合特定人士的推荐。期货、股票和期权交易涉及重大亏损风险,并不适合所有投资者。期货、股票和期权的价格可能会波动,因此客户有可能损失超过其初始投资金额。
所有交易策略均由您自行承担风险。
在选择数据特征、算法以及调优算法等方面,还有许多细节值得深入探讨。这个版本的笔记本我自己就花了两周时间才完成。我相信整个过程中仍有许多未解之处。因此,如果您有任何意见或建议,请随时分享。我很乐意在现有流程中加入并测试您的想法。
感谢您的阅读。
此致, 鲍里斯
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。