gpt_academic
gpt_academic 是一款专为学术科研场景打造的大语言模型交互工具,旨在让论文阅读、润色与写作变得更加高效流畅。它解决了研究人员在面对长篇文献时难以快速提炼核心观点、跨语言理解困难以及代码项目剖析复杂等痛点。无论是需要深入研读 PDF 论文的学者,还是希望借助 AI 辅助编写和调试 Python、C++ 代码的开发者,都能从中获益。
该工具的最大亮点在于其高度的灵活性与广泛的兼容性。它不仅支持通义千问、智谱 GLM、讯飞星火、Llama2 等国内外主流大模型,还允许用户并行对比多个模型的回复效果。独特的模块化设计让用户可以自定义快捷按钮和功能插件,甚至能一键生成项目的自我解析报告。此外,gpt_academic 特别优化了本地部署体验,支持在个人电脑上运行 ChatGLM3 等模型,有效保护数据隐私。对于需要处理 LaTeX 文档或进行多语言翻译的用户,它也提供了便捷的专用功能。整体而言,这是一个功能强大且易于上手的助手,能帮助各类用户更专注于创新与研究本身。
使用场景
某高校研究生李明正在撰写一篇关于深度学习的英文期刊论文,急需阅读大量前沿文献并优化自己的初稿,但受限于英语水平和繁琐的格式调整,进度严重滞后。
没有 gpt_academic 时
- 文献阅读效率低:面对几十页的英文 PDF 论文,只能依靠词典逐段查词,难以快速把握核心逻辑和创新点。
- 写作润色困难:自己写的英文句子语法错误多、表达不地道,手动修改耗时且无法保证学术规范性。
- 多模型对比缺失:仅能使用单一模型获取建议,无法同时对比不同大模型(如 Claude2 与通义千问)对同一问题的见解。
- 代码与论文割裂:项目中包含复杂的 Python 代码,需要单独复制代码去询问逻辑,再手动将解释整合回论文,流程断裂。
使用 gpt_academic 后
- 论文秒级总结:直接上传 PDF 文件,利用内置的翻译与总结功能,几分钟内即可生成中文核心观点摘要,大幅缩短文献调研时间。
- 一键学术润色:选中写得生硬的段落,点击自定义快捷按钮,gpt_academic 立即调用大模型进行符合学术规范的润色和语法修正。
- 并行问询决策:配置多个 API Key 后,同时向 Qwen2.5-max 和 Llama2 发起提问,直接在界面对比不同模型的回答质量,择优采纳。
- 代码自译解联动:针对论文中的算法部分,直接加载项目文件夹,gpt_academic 自动剖析 Python 代码逻辑并生成详细注释,辅助完成方法论章节的撰写。
gpt_academic 通过深度融合文献处理、多模型协作与代码解析能力,将科研工作者从繁琐的语言障碍和工具切换中解放出来,实现了学术创作效率的质的飞跃。
运行环境要求
- Windows
- Linux
- macOS
- 非必需
- 仅在使用本地大模型(如 ChatGLM3/4, MOSS)时需要:ChatGLM4 至少需要 24GB 显存
- 其他模型建议使用支持 CUDA 的 NVIDIA GPU,需手动安装 torch+cuda 版本
未说明(运行本地大模型时建议高内存,具体取决于模型大小)

快速开始
[!IMPORTANT]
master主分支最新动态(2026.1.25): 新GUI前端测试中,Coming Soon
master主分支最新动态(2025.8.23): Dockerfile构建效率大幅优化
2025.2.2: 三分钟快速接入最强qwen2.5-max视频
2025.2.1: 支持自定义字体
2024.10.10: 突发停电,紧急恢复了提供whl包的文件服务器
2024.5.1: 加入Doc2x翻译PDF论文的功能,查看详情
2024.3.11: 全力支持Qwen、GLM、DeepseekCoder等中文大语言模型! SoVits语音克隆模块,查看详情
2024.1.17: 安装依赖时,请选择requirements.txt中指定的版本。 安装命令:pip install -r requirements.txt。
 GPT 学术优化 (GPT Academic)
GPT 学术优化 (GPT Academic)
![]()


如果喜欢这个项目,请给它一个Star;如果您发明了好用的快捷键或插件,欢迎发pull requests!
If you like this project, please give it a Star.
Read this in English | 日本語 | 한국어 | Русский | Français. All translations have been provided by the project itself. To translate this project to arbitrary language with GPT, read and run multi_language.py (experimental).
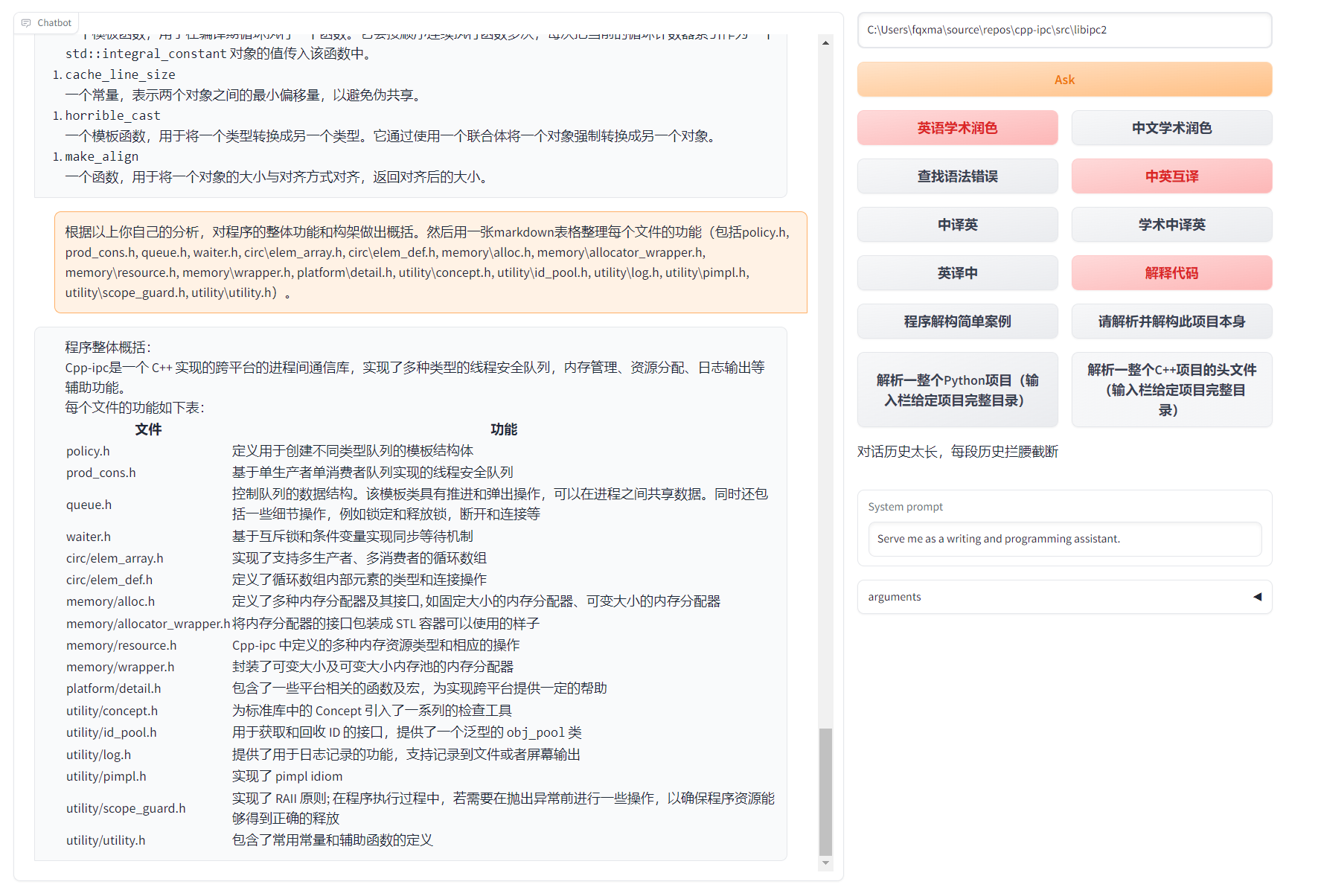
[!NOTE] 1.本项目中每个文件的功能都在自译解报告
self_analysis.md详细说明。随着版本的迭代,您也可以随时自行点击相关函数插件,调用GPT重新生成项目的自我解析报告。常见问题请查阅wiki。


2.本项目兼容并鼓励尝试国内中文大语言基座模型如通义千问,智谱GLM等。支持多个api-key共存,可在配置文件中填写如
API_KEY="openai-key1,openai-key2,azure-key3,api2d-key4"。需要临时更换API_KEY时,在输入区输入临时的API_KEY然后回车键提交即可生效。

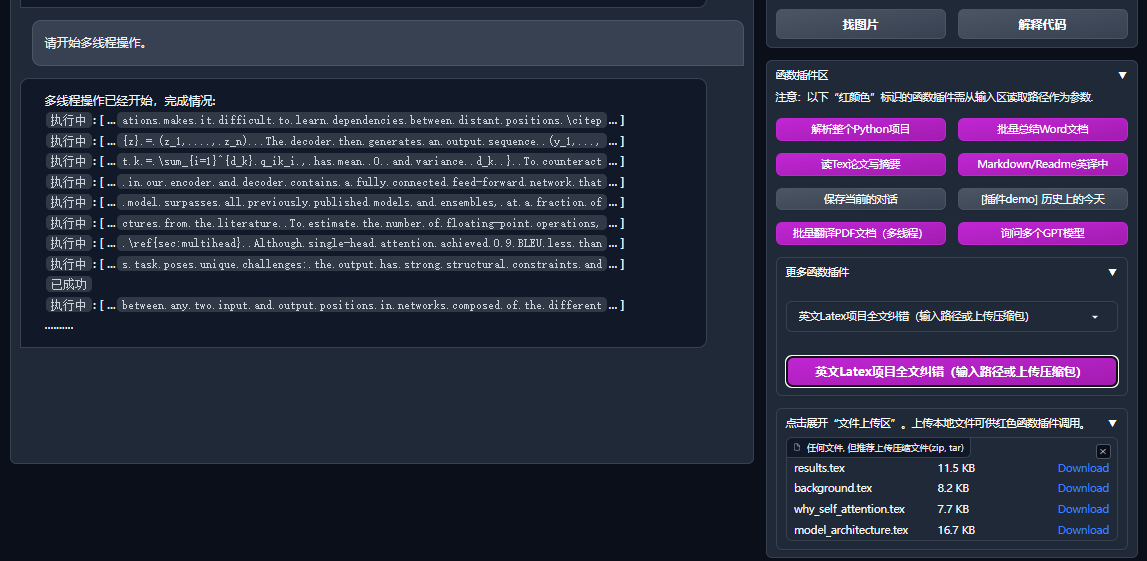
| 功能(⭐= 近期新增功能) | 描述 |
|---|---|
| ⭐接入新模型 | 百度千帆与文心一言, 通义千问Qwen,上海AI-Lab书生,讯飞星火,LLaMa2,智谱GLM4,DALLE3, DeepseekCoder |
| ⭐支持mermaid图像渲染 | 支持让GPT生成流程图、状态转移图、甘特图、饼状图、GitGraph等等(3.7版本) |
| ⭐Arxiv论文精细翻译 (Docker) | [插件] 一键以超高质量翻译arxiv论文,目前最好的论文翻译工具 |
| ⭐实时语音对话输入 | [插件] 异步监听音频,自动断句,自动寻找回答时机 |
| ⭐虚空终端插件 | [插件] 能够使用自然语言直接调度本项目其他插件 |
| 润色、翻译、代码解释 | 一键润色、翻译、查找论文语法错误、解释代码 |
| 自定义快捷键 | 支持自定义快捷键 |
| 模块化设计 | 支持自定义强大的插件,插件支持热更新 |
| 程序剖析 | [插件] 一键剖析Python/C/C++/Java/Lua/...项目树 或 自我剖析 |
| 读论文、翻译论文 | [插件] 一键解读latex/pdf论文全文并生成摘要 |
| Latex全文翻译、润色 | [插件] 一键翻译或润色latex论文 |
| 批量注释生成 | [插件] 一键批量生成函数注释 |
| Markdown中英互译 | [插件] 看到上面5种语言的README了吗?就是出自他的手笔 |
| PDF论文全文翻译功能 | [插件] PDF论文提取题目&摘要+翻译全文(多线程) |
| Arxiv小助手 | [插件] 输入arxiv文章url即可一键翻译摘要+下载PDF |
| Latex论文一键校对 | [插件] 仿Grammarly对Latex文章进行语法、拼写纠错+输出对照PDF |
| 谷歌学术统合小助手 | [插件] 给定任意谷歌学术搜索页面URL,让gpt帮你写relatedworks |
| 互联网信息聚合+GPT | [插件] 一键让GPT从互联网获取信息回答问题,让信息永不过时 |
| 公式/图片/表格显示 | 可以同时显示公式的tex形式和渲染形式,支持公式、代码高亮 |
| 启动暗色主题 | 在浏览器url后面添加/?__theme=dark可以切换dark主题 |
| 多LLM模型支持 | 同时被GPT3.5、GPT4、清华ChatGLM2、复旦MOSS伺候的感觉一定会很不错吧? |
| 更多LLM模型接入,支持huggingface部署 | 加入Newbing接口(新必应),引入清华Jittorllms支持LLaMA和盘古α |
| ⭐void-terminal pip包 | 脱离GUI,在Python中直接调用本项目的所有函数插件(开发中) |
| 更多新功能展示 (图像生成等) …… | 见本文档结尾处 …… |
- 新界面(修改
config.py中的LAYOUT选项即可实现“左右布局”和“上下布局”的切换)
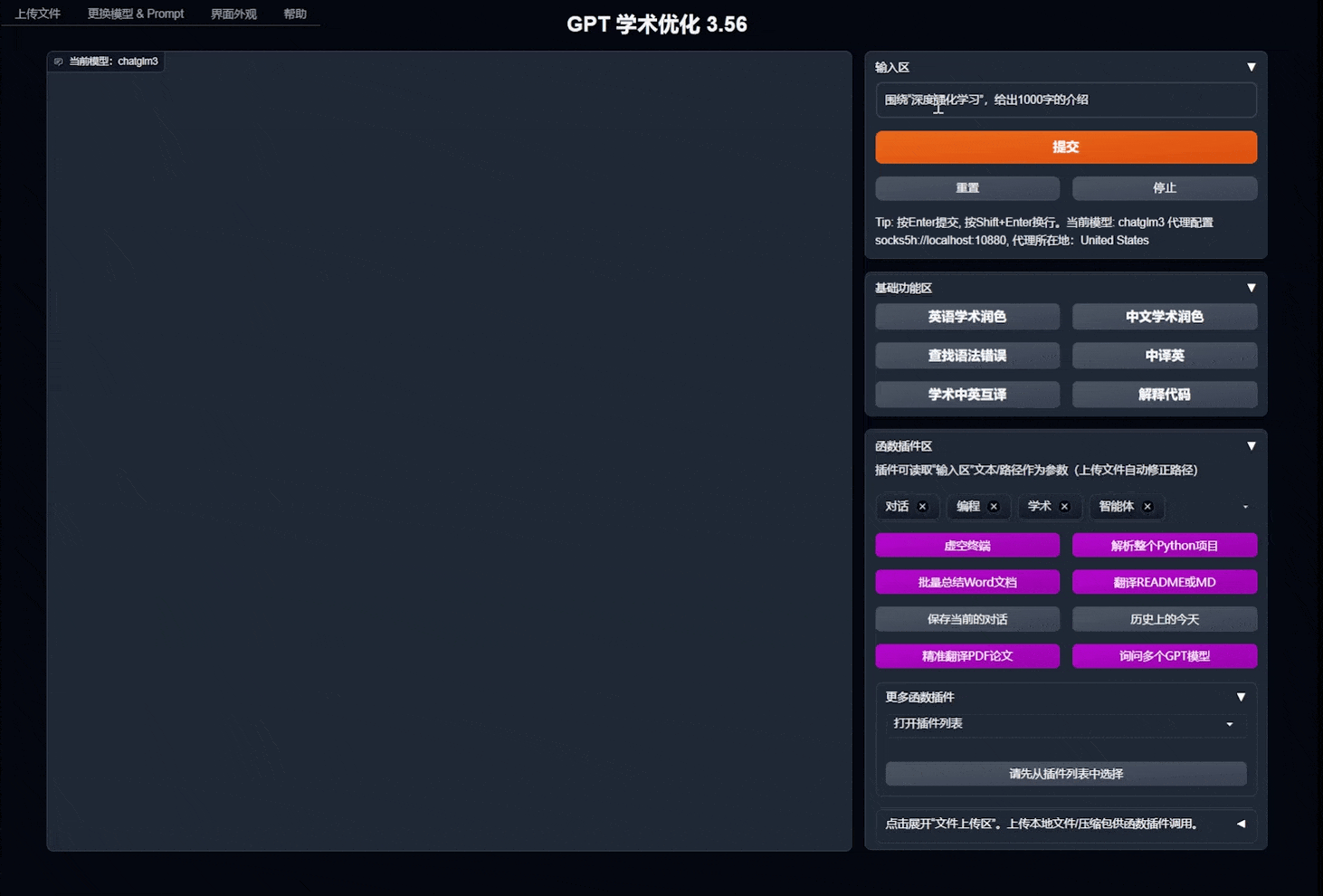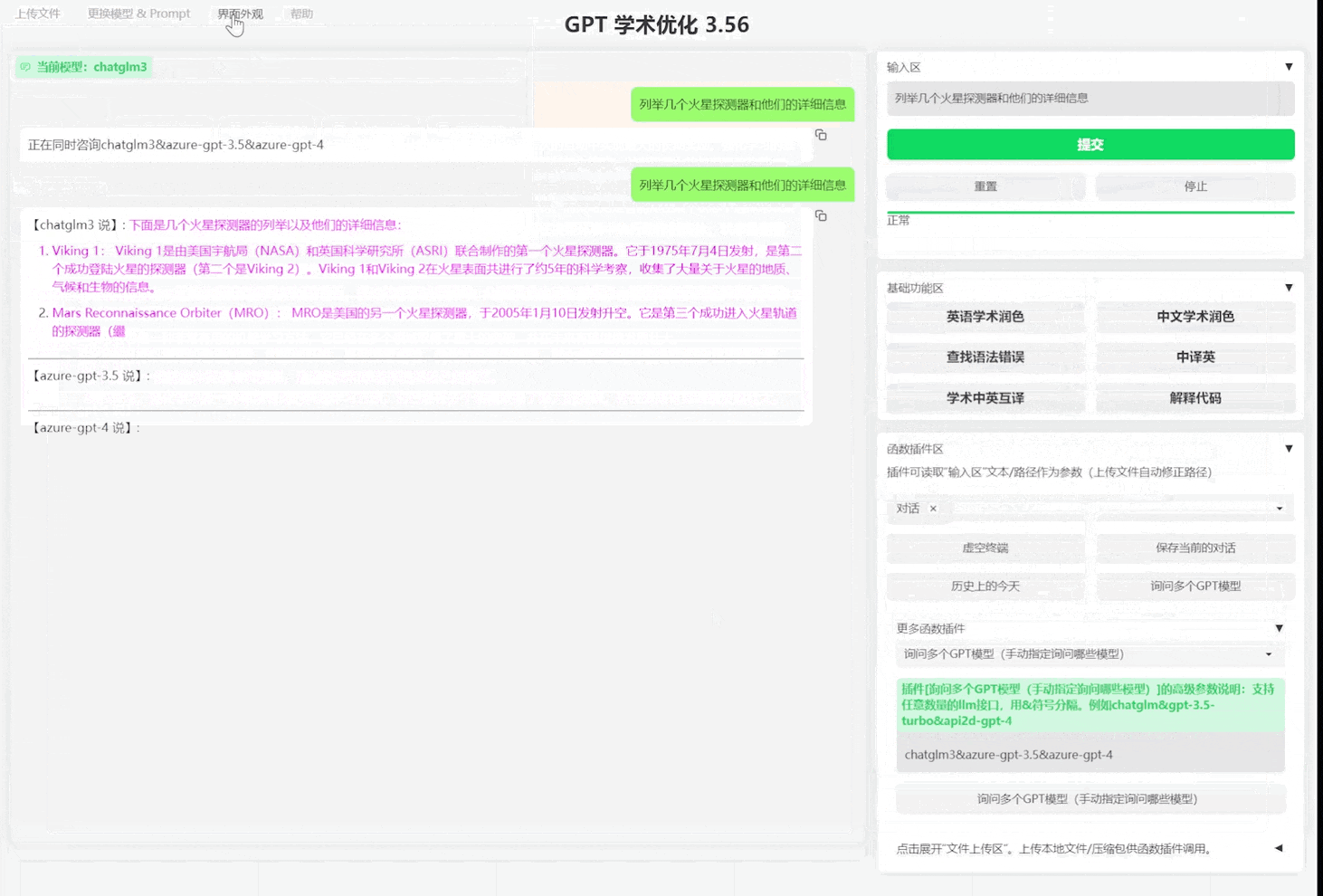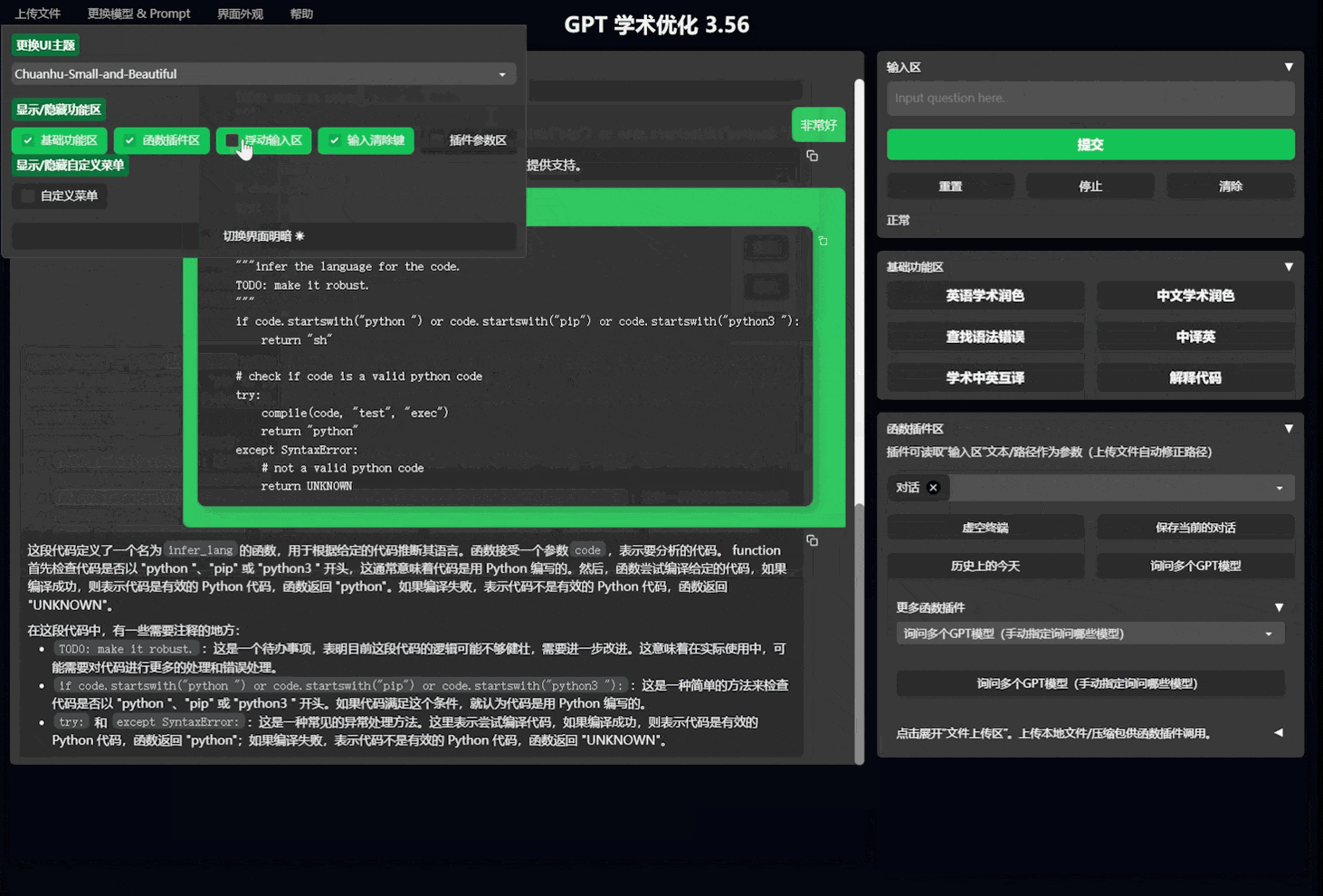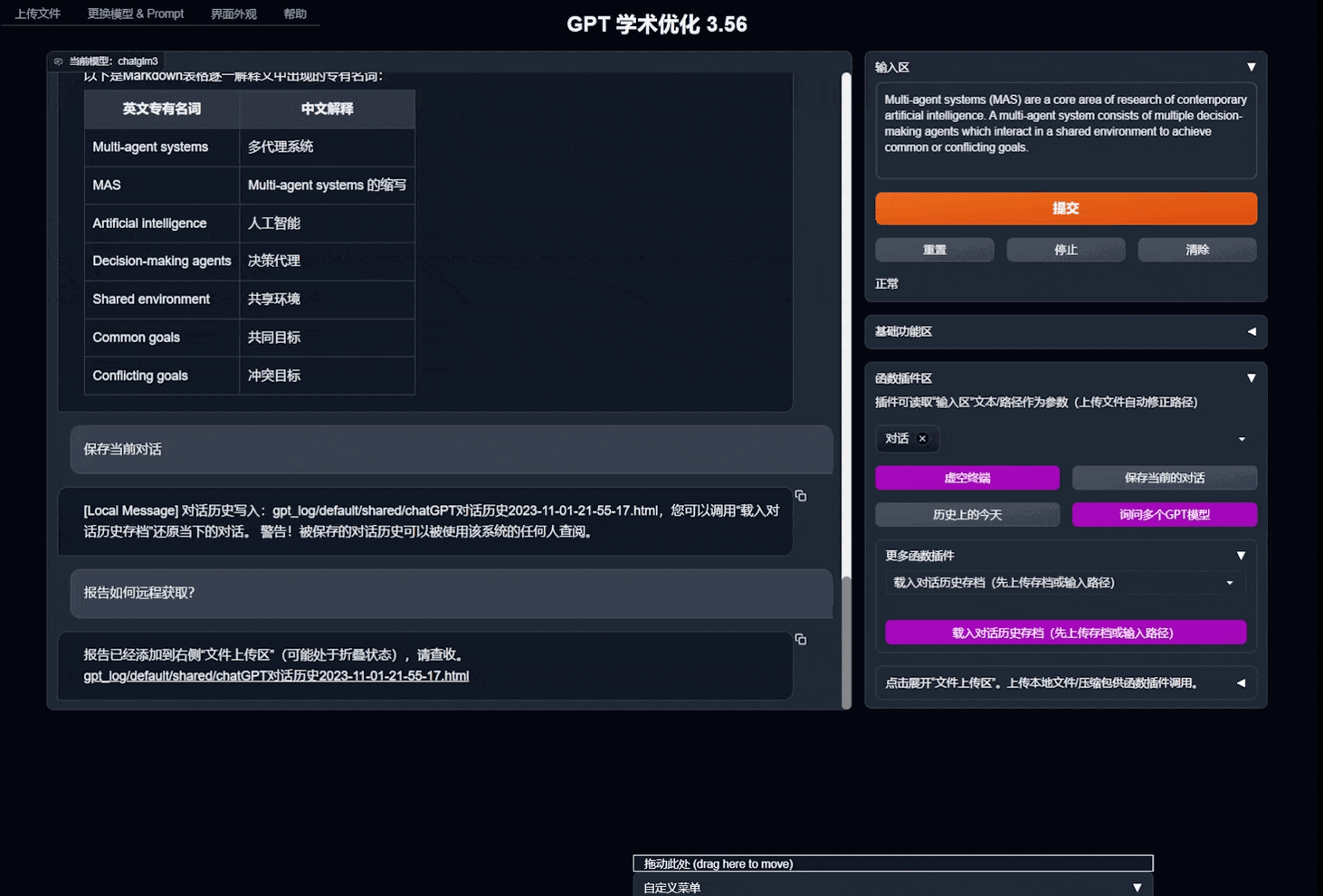

- 所有按钮都通过读取functional.py动态生成,可随意加自定义功能,解放剪贴板
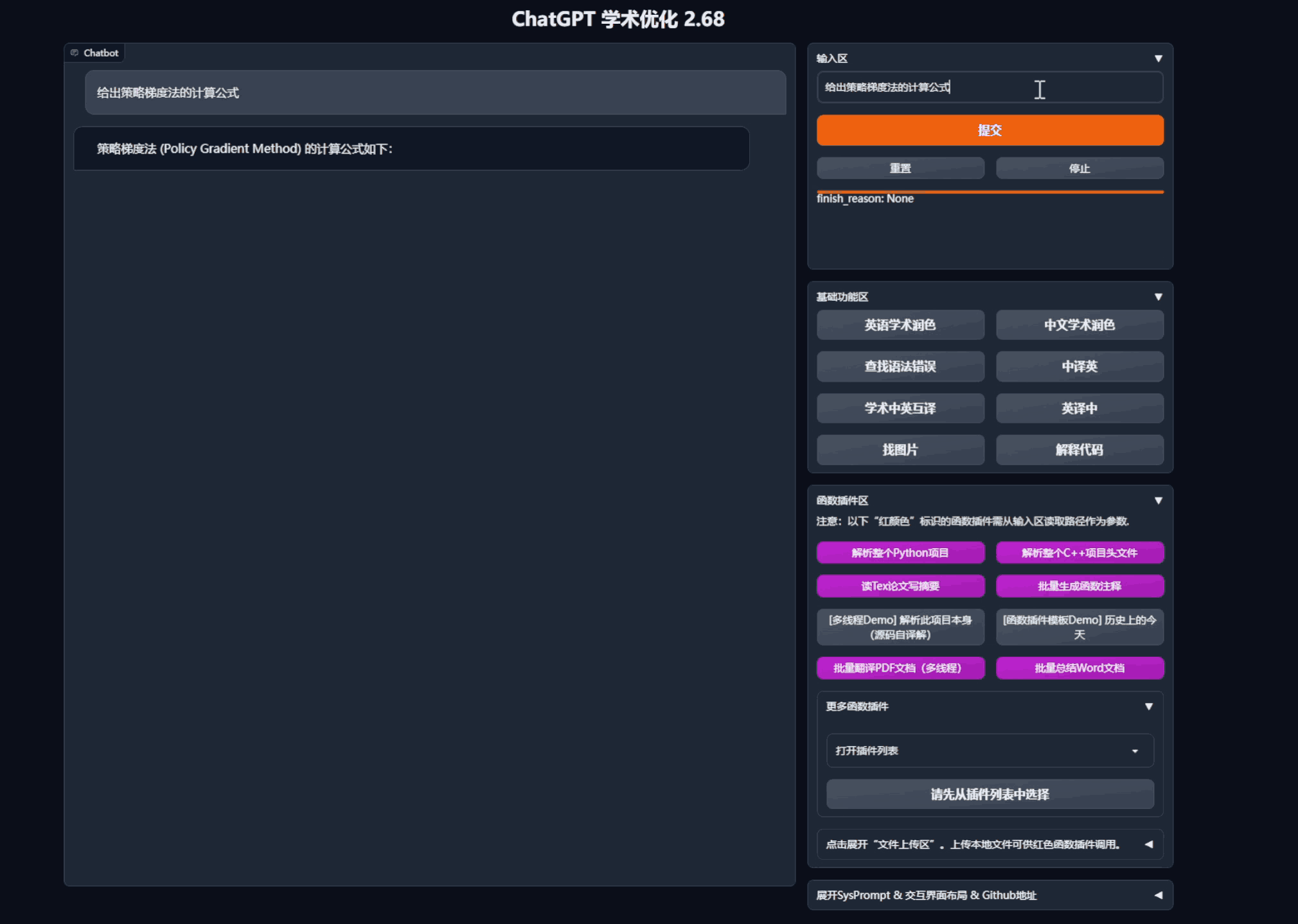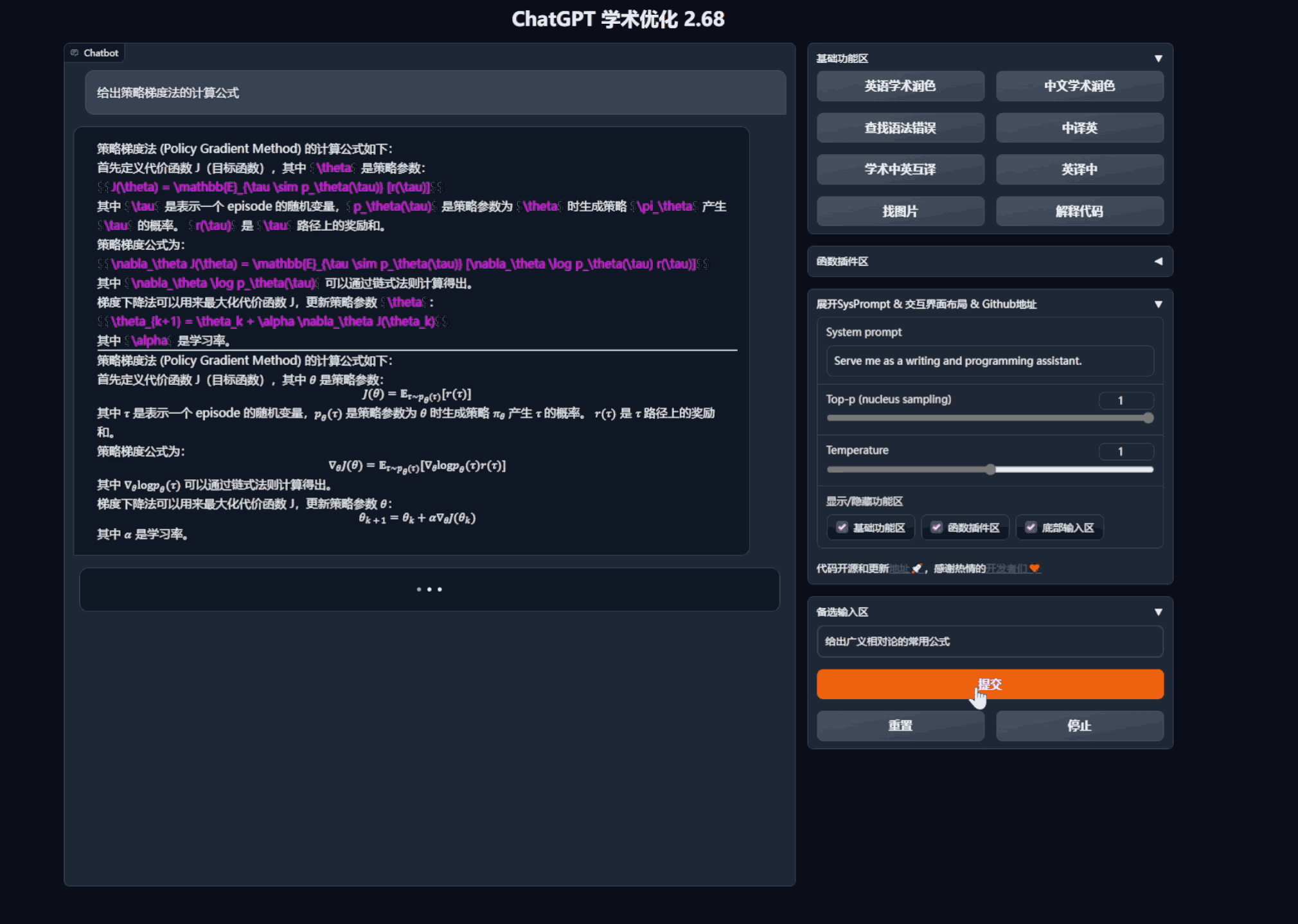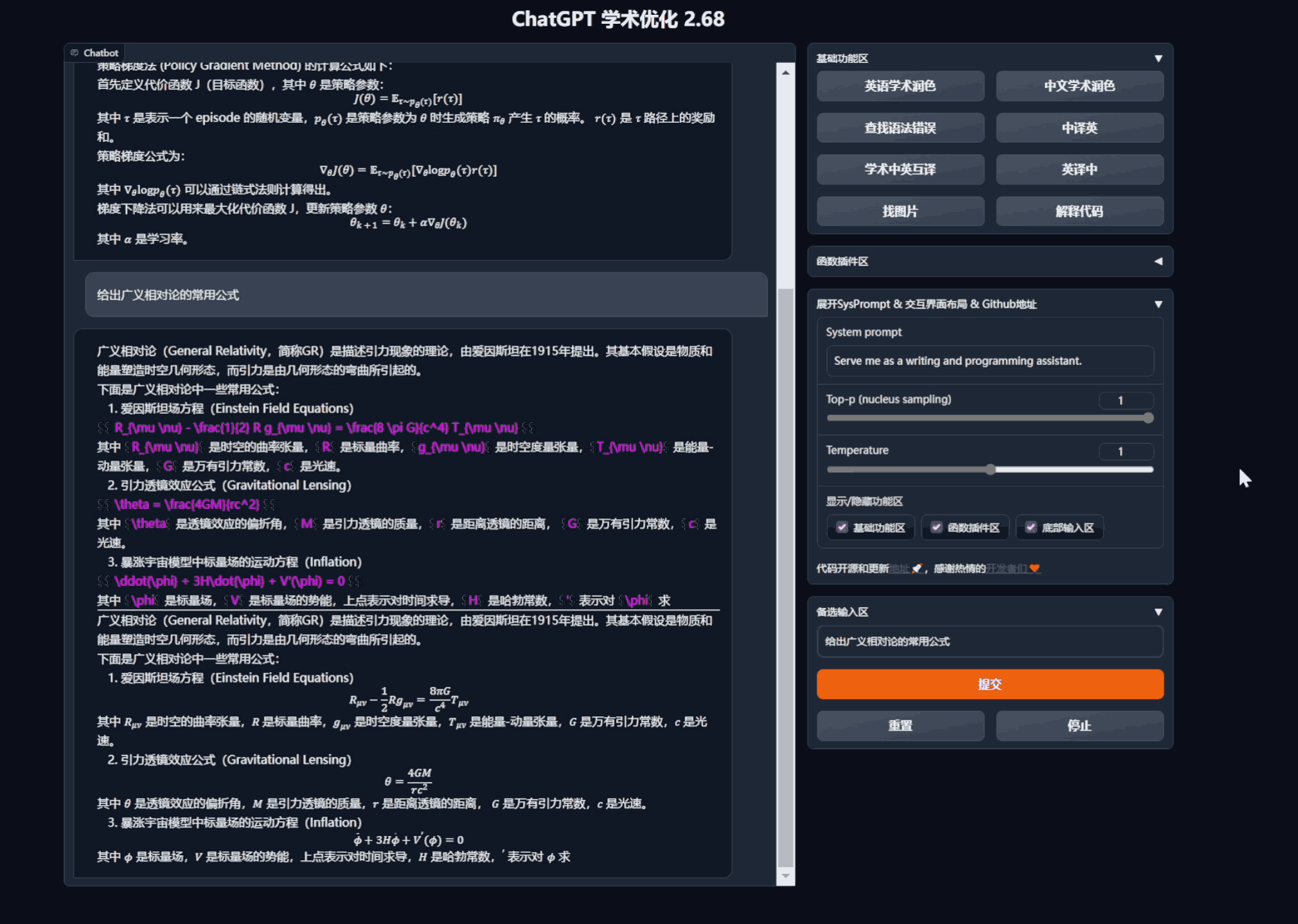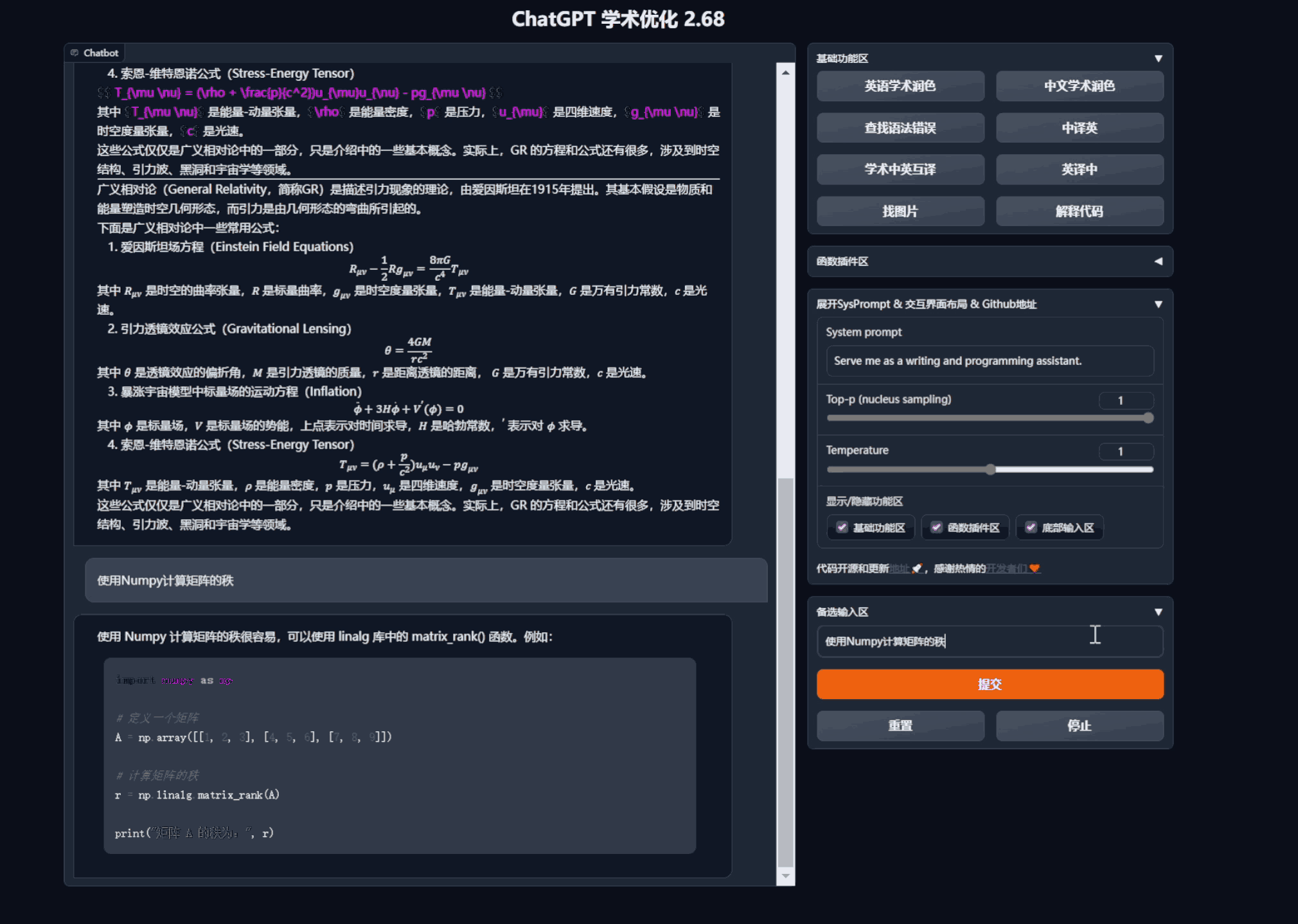
- 润色/纠错

- 如果输出包含公式,会以tex形式和渲染形式同时显示,方便复制和阅读
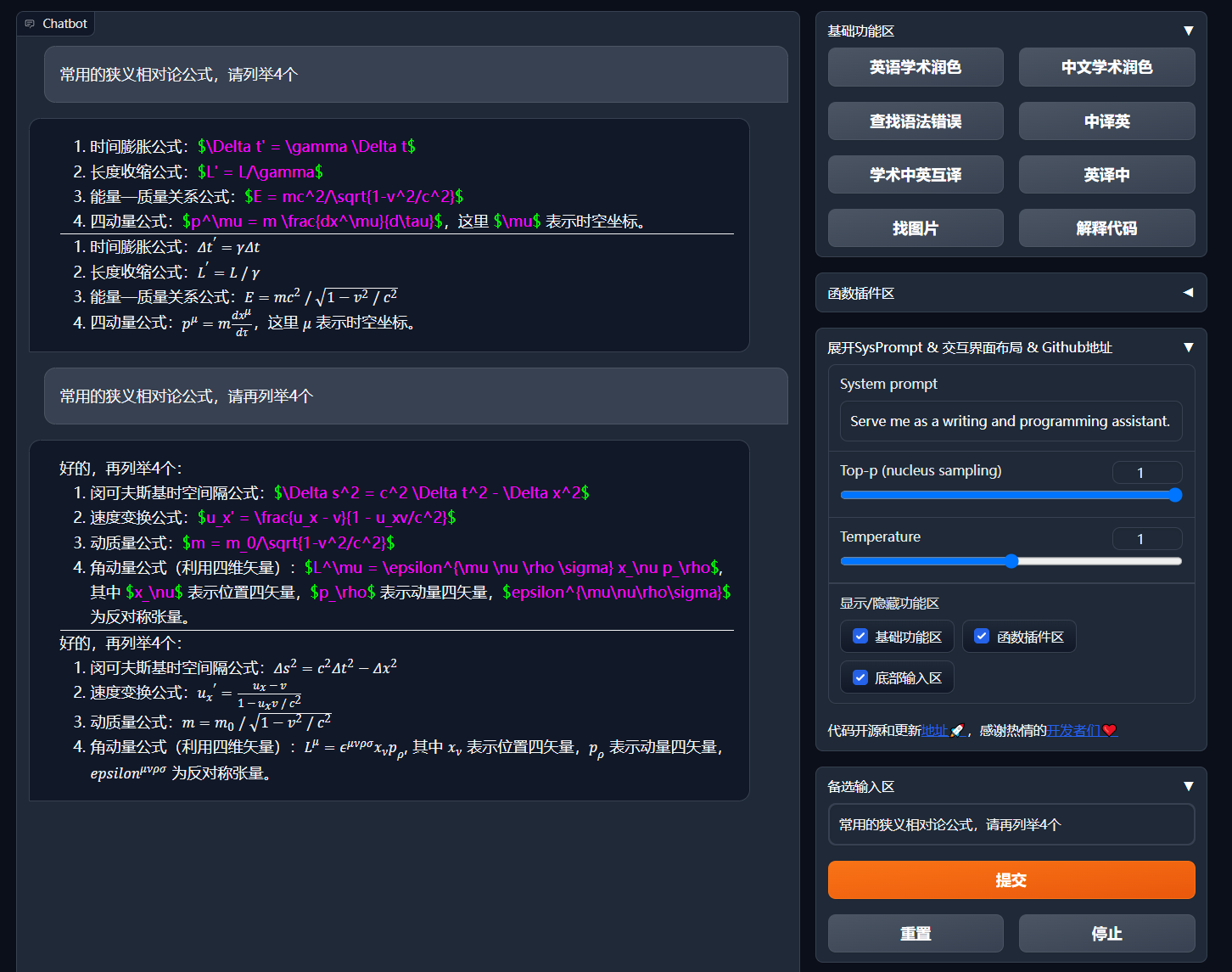
- 懒得看项目代码?直接把整个工程炫ChatGPT嘴里
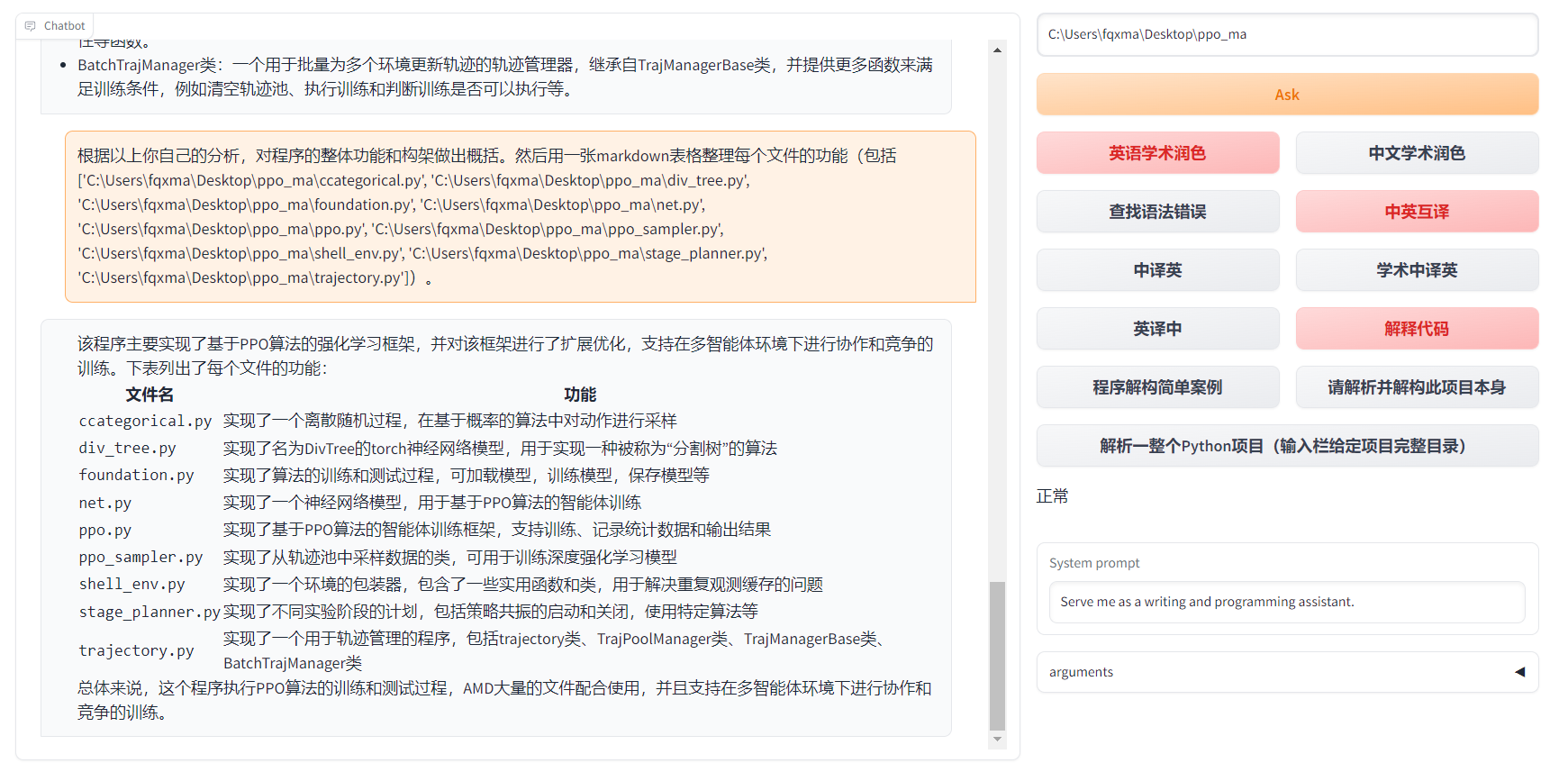
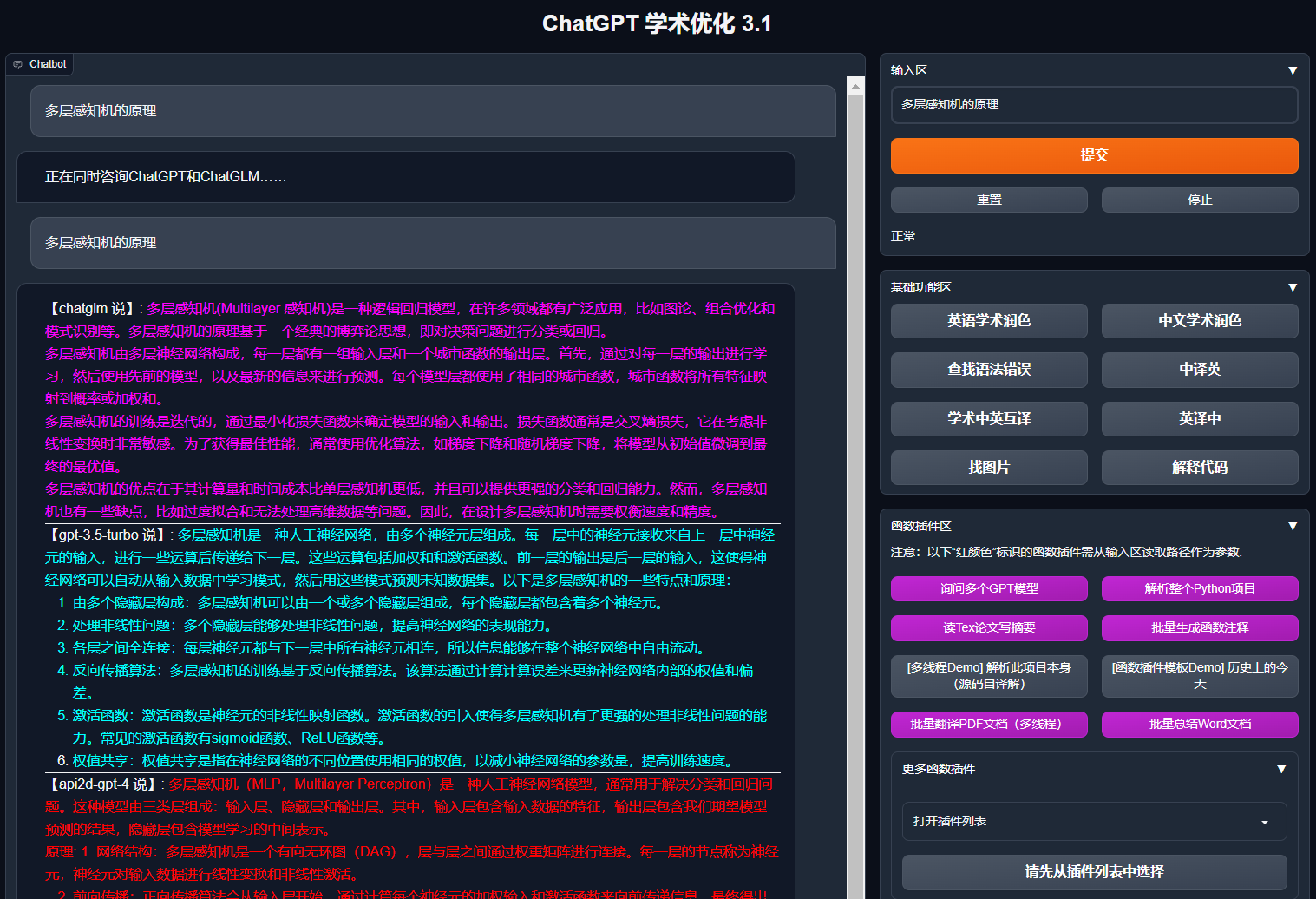
- 多种大语言模型混合调用(ChatGLM + OpenAI-GPT3.5 + GPT4)
安装
flowchart TD
A{"安装方法"} --> W1("I 🔑直接运行 (Windows, Linux or MacOS)")
W1 --> W11["1 Python pip包管理依赖"]
W1 --> W12["2 Anaconda包管理依赖(推荐⭐)"]
A --> W2["II 🐳使用Docker (Windows, Linux or MacOS)"]
W2 --> k1["1 部署项目全部能力的大镜像(推荐⭐)"]
W2 --> k2["2 仅在线模型(GPT, GLM4等)镜像"]
W2 --> k3["3 在线模型 + Latex的大镜像"]
A --> W4["IV 🚀其他部署方法"]
W4 --> C1["1 Windows/MacOS 一键安装运行脚本(推荐⭐)"]
W4 --> C2["2 Huggingface, Sealos远程部署"]
W4 --> C4["3 其他 ..."]
安装方法I:直接运行 (Windows, Linux or MacOS)
下载项目
git clone --depth=1 https://github.com/binary-husky/gpt_academic.git cd gpt_academic配置API_KEY等变量
在
config.py中,配置API KEY等变量。特殊网络环境设置方法、Wiki-项目配置说明。「 程序会优先检查是否存在名为
config_private.py的私密配置文件,并用其中的配置覆盖config.py的同名配置。如您能理解以上读取逻辑,我们强烈建议您在config.py同路径下创建一个名为config_private.py的新配置文件,并使用config_private.py配置项目,从而确保自动更新时不会丢失配置 」。「 支持通过
环境变量配置项目,环境变量的书写格式参考docker-compose.yml文件或者我们的Wiki页面。配置读取优先级:环境变量>config_private.py>config.py」。安装依赖
# (选择I: 如熟悉python, python推荐版本 3.9 ~ 3.11)备注:使用官方pip源或者阿里pip源, 临时换源方法:python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ python -m pip install -r requirements.txt # (选择II: 使用Anaconda)步骤也是类似的 (https://www.bilibili.com/video/BV1rc411W7Dr): conda create -n gptac_venv python=3.11 # 创建anaconda环境 conda activate gptac_venv # 激活anaconda环境 python -m pip install -r requirements.txt # 这个步骤和pip安装一样的步骤 # (选择III: 使用uv): uv venv --python=3.11 # 创建虚拟环境 source ./.venv/bin/activate # 激活虚拟环境 uv pip install --verbose -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ # 安装依赖
如果需要支持清华ChatGLM系列/复旦MOSS/RWKV作为后端,请点击展开此处
【可选步骤】如果需要支持清华ChatGLM系列/复旦MOSS作为后端,需要额外安装更多依赖(前提条件:熟悉Python + 用过Pytorch + 电脑配置够强):
# 【可选步骤I】支持清华ChatGLM3。清华ChatGLM备注:如果遇到"Call ChatGLM fail 不能正常加载ChatGLM的参数" 错误,参考如下: 1:以上默认安装的为torch+cpu版,使用cuda需要卸载torch重新安装torch+cuda; 2:如因本机配置不够无法加载模型,可以修改request_llm/bridge_chatglm.py中的模型精度, 将 AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) 都修改为 AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
python -m pip install -r request_llms/requirements_chatglm.txt
# 【可选步骤II】支持清华ChatGLM4 注意:此模型至少需要24G显存
python -m pip install -r request_llms/requirements_chatglm4.txt
# 可使用modelscope下载ChatGLM4模型
# pip install modelscope
# modelscope download --model ZhipuAI/glm-4-9b-chat --local_dir ./THUDM/glm-4-9b-chat
# 【可选步骤III】支持复旦MOSS
python -m pip install -r request_llms/requirements_moss.txt
git clone --depth=1 https://github.com/OpenLMLab/MOSS.git request_llms/moss # 注意执行此行代码时,必须处于项目根路径
# 【可选步骤IV】支持RWKV Runner
参考wiki:https://github.com/binary-husky/gpt_academic/wiki/%E9%80%82%E9%85%8DRWKV-Runner
# 【可选步骤V】确保config.py配置文件的AVAIL_LLM_MODELS包含了期望的模型,目前支持的全部模型如下(jittorllms系列目前仅支持docker方案):
AVAIL_LLM_MODELS = ["gpt-3.5-turbo", "api2d-gpt-3.5-turbo", "gpt-4", "api2d-gpt-4", "chatglm", "moss"] # + ["jittorllms_rwkv", "jittorllms_pangualpha", "jittorllms_llama"]
# 【可选步骤VI】支持本地模型INT8,INT4量化(这里所指的模型本身不是量化版本,目前deepseek-coder支持,后面测试后会加入更多模型量化选择)
pip install bitsandbyte
# windows用户安装bitsandbytes需要使用下面bitsandbytes-windows-webui
python -m pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui
pip install -U git+https://github.com/huggingface/transformers.git
pip install -U git+https://github.com/huggingface/accelerate.git
pip install peft
- 运行
python main.py
安装方法II:使用Docker
部署项目的全部能力(这个是包含cuda和latex的大型镜像。但如果您网速慢、硬盘小,则不推荐该方法部署完整项目)

# 修改docker-compose.yml,保留方案0并删除其他方案。然后运行: docker-compose up仅ChatGPT + GLM4 + 文心一言+spark等在线模型(推荐大多数人选择)



# 修改docker-compose.yml,保留方案1并删除其他方案。然后运行: docker-compose up
P.S. 如果需要依赖Latex的插件功能,请见Wiki。另外,您也可以直接使用方案4或者方案0获取Latex功能。
ChatGPT + GLM3 + MOSS + LLAMA2 + 通义千问(需要熟悉Nvidia Docker运行时)

# 修改docker-compose.yml,保留方案2并删除其他方案。然后运行: docker-compose up
安装方法III:其他部署方法
Windows一键运行脚本。 完全不熟悉python环境的Windows用户可以下载Release中发布的一键运行脚本安装无本地模型的版本。脚本贡献来源:oobabooga。
使用第三方API、Azure等、文心一言、星火等,见Wiki页面
云服务器远程部署避坑指南。 请访问云服务器远程部署wiki
在其他平台部署&二级网址部署
- 使用Sealos一键部署。
- 使用WSL2(Windows Subsystem for Linux 子系统)。请访问部署wiki-2
- 如何在二级网址(如
http://localhost/subpath)下运行。请访问FastAPI运行说明
高级使用
I:自定义新的便捷按钮(学术快捷键)
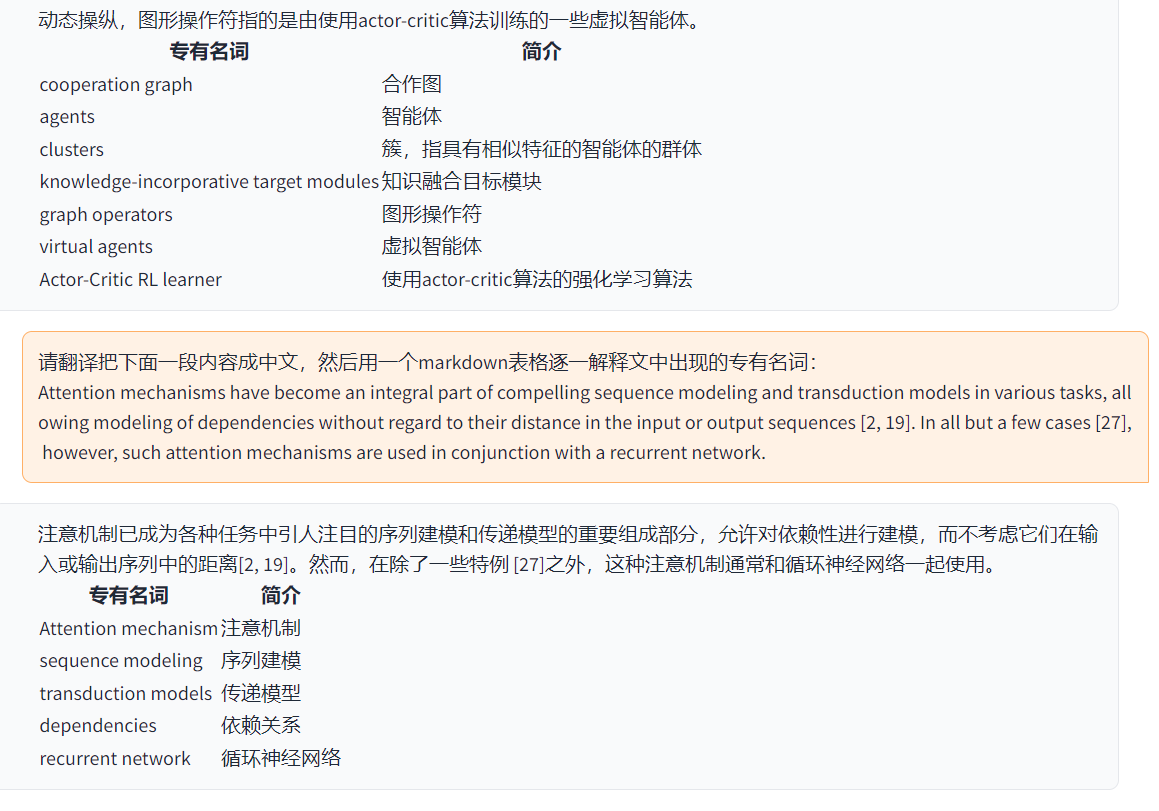
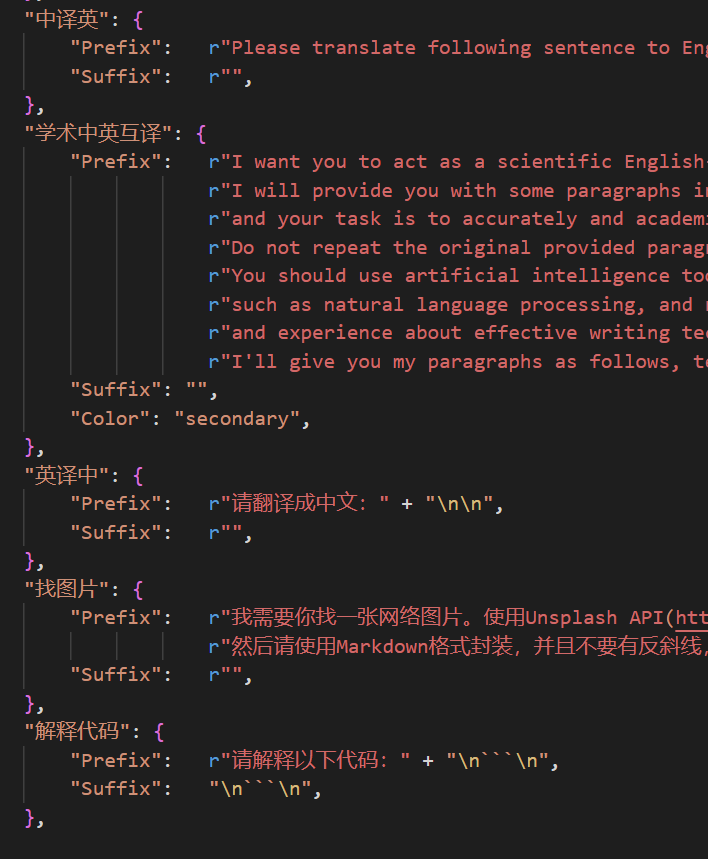
现在已可以通过UI中的界面外观菜单中的自定义菜单添加新的便捷按钮。如果需要在代码中定义,请使用任意文本编辑器打开core_functional.py,添加如下条目即可:
"超级英译中": {
# 前缀,会被加在你的输入之前。例如,用来描述你的要求,例如翻译、解释代码、润色等等
"Prefix": "请翻译把下面一段内容成中文,然后用一个markdown表格逐一解释文中出现的专有名词:\n\n",
# 后缀,会被加在你的输入之后。例如,配合前缀可以把你的输入内容用引号圈起来。
"Suffix": "",
},
II:自定义函数插件
编写强大的函数插件来执行任何你想得到的和想不到的任务。 本项目的插件编写、调试难度很低,只要您具备一定的python基础知识,就可以仿照我们提供的模板实现自己的插件功能。 详情请参考函数插件指南。
更新
I:动态
- 对话保存功能。在函数插件区调用
保存当前的对话即可将当前对话保存为可读+可复原的html文件, 另外在函数插件区(下拉菜单)调用载入对话历史存档,即可还原之前的会话。 Tip:不指定文件直接点击载入对话历史存档可以查看历史html存档缓存。
- ⭐Latex/Arxiv论文翻译功能⭐
 ===>
===>

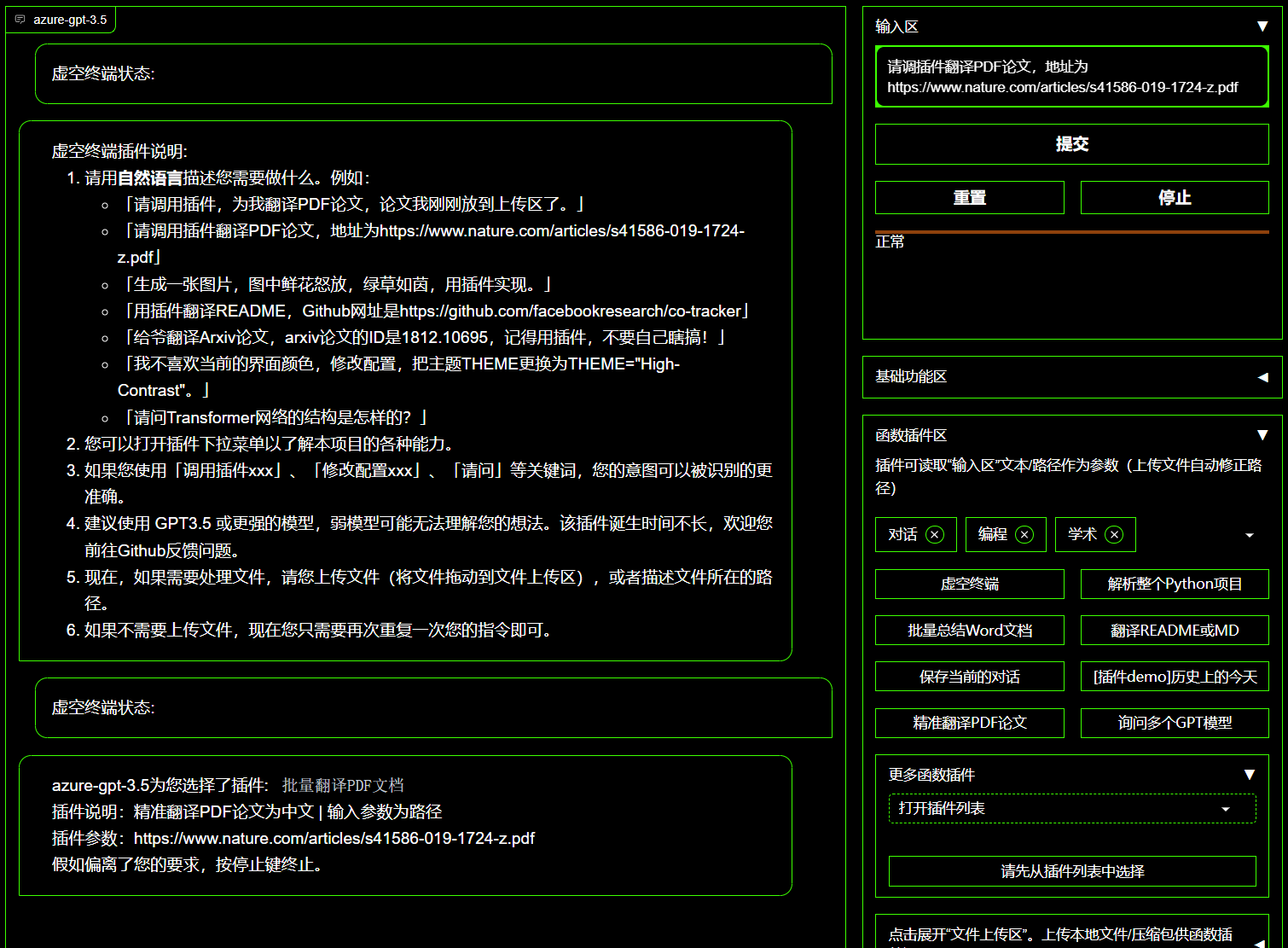
- 虚空终端(从自然语言输入中,理解用户意图+自动调用其他插件)
- 步骤一:输入 “ 请调用插件翻译PDF论文,地址为https://openreview.net/pdf?id=rJl0r3R9KX ”
- 步骤二:点击“虚空终端”
- 模块化功能设计,简单的接口却能支持强大的功能
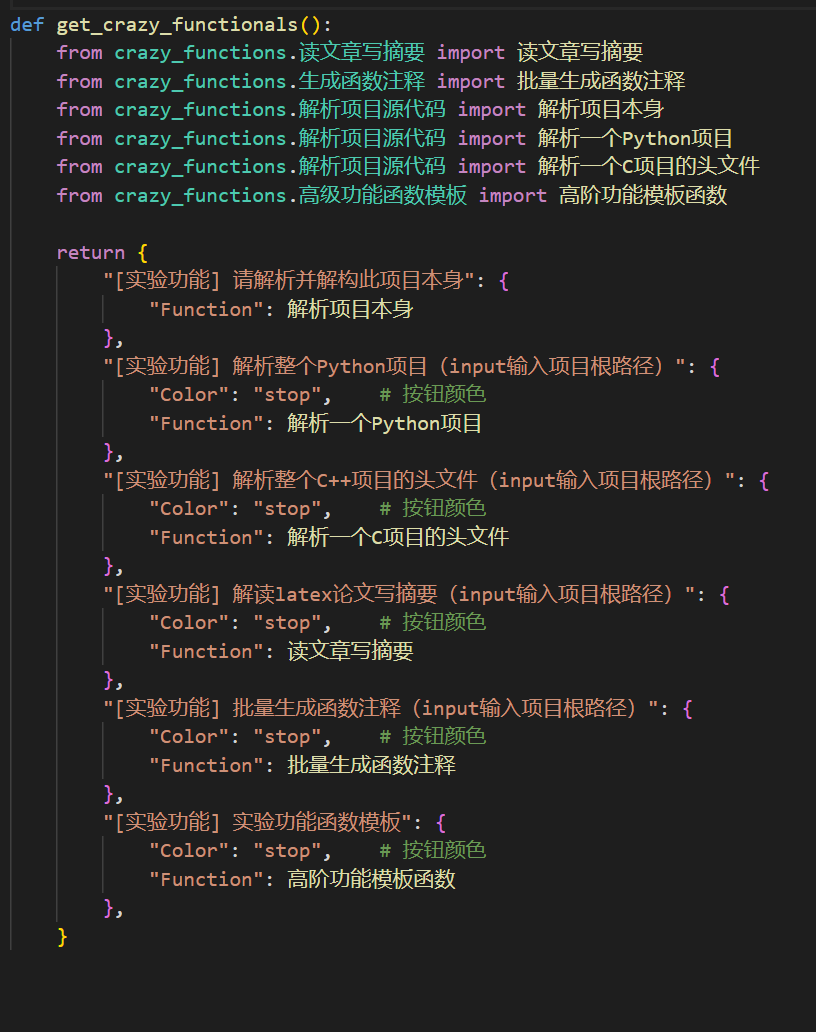
- 译解其他开源项目
- 装饰live2d的小功能(默认关闭,需要修改
config.py)
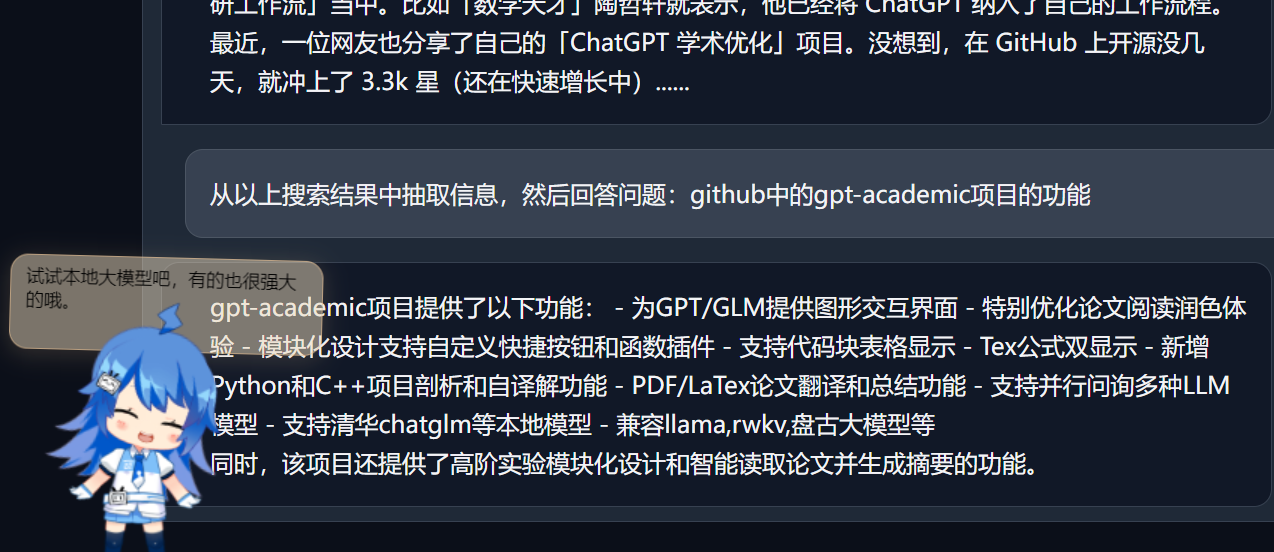
- OpenAI图像生成
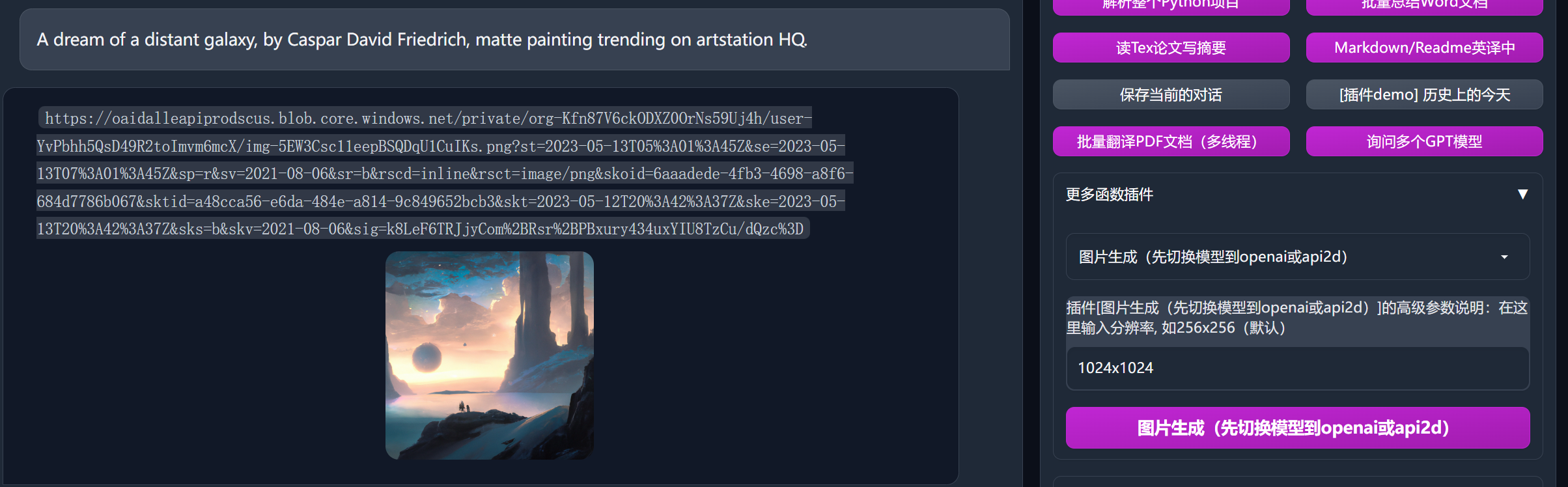
- 基于mermaid的流图、脑图绘制
- Latex全文校对纠错
 ===>
===>

- 语言、主题切换
II:版本:
- version 3.80(TODO): 优化AutoGen插件主题并设计一系列衍生插件
- version 3.70: 引入Mermaid绘图,实现GPT画脑图等功能
- version 3.60: 引入AutoGen作为新一代插件的基石
- version 3.57: 支持GLM3,星火v3,文心一言v4,修复本地模型的并发BUG
- version 3.56: 支持动态追加基础功能按钮,新汇报PDF汇总页面
- version 3.55: 重构前端界面,引入悬浮窗口与菜单栏
- version 3.54: 新增动态代码解释器(Code Interpreter)(待完善)
- version 3.53: 支持动态选择不同界面主题,提高稳定性&解决多用户冲突问题
- version 3.50: 使用自然语言调用本项目的所有函数插件(虚空终端),支持插件分类,改进UI,设计新主题
- version 3.49: 支持百度千帆平台和文心一言
- version 3.48: 支持阿里达摩院通义千问,上海AI-Lab书生,讯飞星火
- version 3.46: 支持完全脱手操作的实时语音对话
- version 3.45: 支持自定义ChatGLM2微调模型
- version 3.44: 正式支持Azure,优化界面易用性
- version 3.4: +arxiv论文翻译、latex论文批改功能
- version 3.3: +互联网信息综合功能
- version 3.2: 函数插件支持更多参数接口 (保存对话功能, 解读任意语言代码+同时询问任意的LLM组合)
- version 3.1: 支持同时问询多个gpt模型!支持api2d,支持多个apikey负载均衡
- version 3.0: 对chatglm和其他小型llm的支持
- version 2.6: 重构了插件结构,提高了交互性,加入更多插件
- version 2.5: 自更新,解决总结大工程源代码时文本过长、token溢出的问题
- version 2.4: 新增PDF全文翻译功能; 新增输入区切换位置的功能
- version 2.3: 增强多线程交互性
- version 2.2: 函数插件支持热重载
- version 2.1: 可折叠式布局
- version 2.0: 引入模块化函数插件
- version 1.0: 基础功能
GPT Academic开发者QQ群:610599535
- 已知问题
- 某些浏览器翻译插件干扰此软件前端的运行
- 官方Gradio目前有很多兼容性问题,请务必使用
requirement.txt安装Gradio
timeline LR
title GPT-Academic项目发展历程
section 2.x
1.0~2.2: 基础功能: 引入模块化函数插件: 可折叠式布局: 函数插件支持热重载
2.3~2.5: 增强多线程交互性: 新增PDF全文翻译功能: 新增输入区切换位置的功能: 自更新
2.6: 重构了插件结构: 提高了交互性: 加入更多插件
section 3.x
3.0~3.1: 对chatglm支持: 对其他小型llm支持: 支持同时问询多个gpt模型: 支持多个apikey负载均衡
3.2~3.3: 函数插件支持更多参数接口: 保存对话功能: 解读任意语言代码: 同时询问任意的LLM组合: 互联网信息综合功能
3.4: 加入arxiv论文翻译: 加入latex论文批改功能
3.44: 正式支持Azure: 优化界面易用性
3.46: 自定义ChatGLM2微调模型: 实时语音对话
3.49: 支持阿里达摩院通义千问: 上海AI-Lab书生: 讯飞星火: 支持百度千帆平台 & 文心一言
3.50: 虚空终端: 支持插件分类: 改进UI: 设计新主题
3.53: 动态选择不同界面主题: 提高稳定性: 解决多用户冲突问题
3.55: 动态代码解释器: 重构前端界面: 引入悬浮窗口与菜单栏
3.56: 动态追加基础功能按钮: 新汇报PDF汇总页面
3.57: GLM3, 星火v3: 支持文心一言v4: 修复本地模型的并发BUG
3.60: 引入AutoGen
3.70: 引入Mermaid绘图: 实现GPT画脑图等功能
3.80(TODO): 优化AutoGen插件主题: 设计衍生插件
III:主题
可以通过修改THEME选项(config.py)变更主题
Chuanhu-Small-and-Beautiful网址
IV:本项目的开发分支
master分支: 主分支,稳定版frontier分支: 开发分支,测试版- 如何接入其他大模型
V:参考与学习
代码中参考了很多其他优秀项目中的设计,顺序不分先后:
# 清华ChatGLM2-6B:
https://github.com/THUDM/ChatGLM2-6B
# 清华JittorLLMs:
https://github.com/Jittor/JittorLLMs
# ChatPaper:
https://github.com/kaixindelele/ChatPaper
# Edge-GPT:
https://github.com/acheong08/EdgeGPT
# ChuanhuChatGPT:
https://github.com/GaiZhenbiao/ChuanhuChatGPT
# Oobabooga one-click installer:
https://github.com/oobabooga/one-click-installers
# More:
https://github.com/gradio-app/gradio
https://github.com/fghrsh/live2d_demo
版本历史
version3.912024/12/19version3.90patch12024/10/13version3.83-fix-12024/08/02version3.752024/05/04version3.742024/04/08version3.702024/01/18version3.64-12023/12/21version3.60-32023/10/08version3.54-22023/09/19version3.52-12023/09/14version3.50-32023/09/03version3.48-12023/07/09version3.442023/05/27version3.372023/05/27version3.362023/05/22version3.352023/05/19version3.342023/05/07version3.33-22023/05/06version3.332023/05/05version3.322023/04/23常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。