SimGNN
SimGNN 是一个基于 PyTorch 开发的开源项目,旨在利用神经网络技术快速计算图结构之间的相似度。在传统应用中,如化学化合物检索或分子结构分析,精确计算图编辑距离(GED)等指标往往耗时巨大,难以满足大规模数据处理的实时性需求。SimGNN 正是为了解决这一计算瓶颈而生,它能在保持高精度的同时,显著降低计算成本。
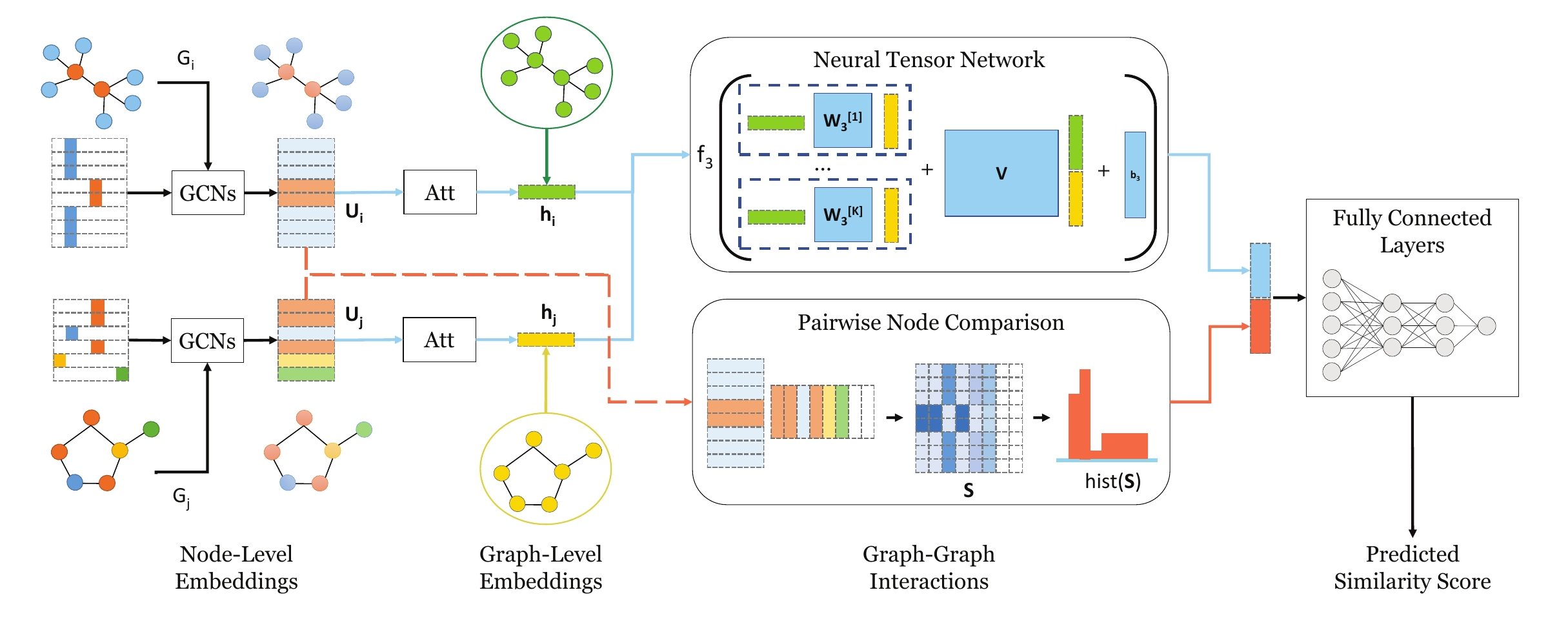
该工具特别适合从事图数据挖掘、化学信息学研究的科研人员,以及需要高效处理图相似度任务的算法开发者。其核心技术亮点在于创新性地结合了两种策略:首先,设计了一种可学习的嵌入函数,将每个图映射为向量以获取全局摘要,并引入注意力机制来突出对相似度判断至关重要的节点;其次,通过成对节点比较方法,补充了细粒度的节点级信息。这种“全局 + 局部”的双重架构,使得 SimGNN 在面对未见过的图数据时具有出色的泛化能力,且在最坏情况下的运行时间仅与节点数量的平方成正比。相比传统的近似算法和其他图神经网络模型,SimGNN 在多个真实数据集上均展现了更低的误差率和极高的运行效率,为图相似度计算领域提供了新的研究方向。
使用场景
某制药公司的 AI 研发团队正在构建一个大规模化合物筛选系统,需要从数百万种分子结构中快速找出与目标药物最相似的候选分子。
没有 SimGNN 时
- 计算耗时极长:传统图编辑距离(GED)算法在处理复杂分子图时复杂度极高,单次比对可能需要数秒,导致全库筛选需耗费数周甚至更久。
- 难以实时响应:研究人员无法在交互式环境中即时获取相似性结果,严重拖慢了新药发现的迭代节奏。
- 资源消耗巨大:为了加速计算,团队不得不投入昂贵的分布式集群资源,运维成本高昂且扩展性差。
- 精度与速度难兼得:现有的近似算法虽然提升了速度,但往往以牺牲匹配精度为代价,导致漏掉关键的潜在药物分子。
使用 SimGNN 后
- 推理速度飞跃:SimGNN 利用神经网络将分子映射为嵌入向量,将比对时间从秒级降低至毫秒级,实现了近乎实时的查询响应。
- 保持高准确度:通过结合全局图嵌入与细粒度的节点注意力机制,SimGNN 在大幅提速的同时,误差率反而低于传统近似算法,确保不遗漏重要候选物。
- 降低硬件门槛:高效的计算模式使得单台普通 GPU 服务器即可承担海量比对任务,显著降低了基础设施投入。
- 泛化能力强:模型在面对训练集中未出现过的新颖分子结构时,依然能保持稳定的相似度评估性能,适应不断更新的化合物库。
SimGNN 通过将昂贵的图相似度计算转化为高效的神经推理,成功打破了大规模分子筛选中的速度与精度瓶颈。
运行环境要求
未说明(基于 PyTorch 和 torch-geometric,通常建议使用支持 CUDA 的 NVIDIA GPU 以加速训练,但 README 未明确强制要求)
未说明
快速开始
SimGNN
![]()
 ⠀
⠀
一种基于 PyTorch 的 SimGNN:一种用于快速图相似性计算的神经网络方法(WSDM 2019) 实现。
摘要
图相似性搜索是最重要的图应用之一,例如查找与查询化合物最相似的化学化合物。图相似性/距离计算,如图编辑距离(GED)和最大公共子图(MCS),是图相似性搜索及其他许多应用的核心操作,但在实际应用中计算成本非常高。受近年来神经网络方法在节点分类、图分类等图应用中取得成功的启发,我们提出了一种新颖的基于神经网络的方法来解决这一经典但极具挑战性的图问题,旨在减轻计算负担,同时保持良好的性能。所提出的 SimGNN 方法结合了两种策略。首先,我们设计了一个可学习的嵌入函数,将每张图映射为一个嵌入向量,该向量能够提供图的全局摘要信息。此外,我们还提出了一种新的注意力机制,以突出显示与特定相似度度量相关的关键节点。其次,我们设计了一种成对节点比较方法,用细粒度的节点级信息补充图级别的嵌入表示。我们的模型在未见过的图上表现出更好的泛化能力,并且在最坏情况下,其运行时间与两图节点数的平方成正比。以图编辑距离计算为例,在三个真实图数据集上的实验结果表明,我们的方法既有效又高效。具体而言,与一系列基线方法相比,包括多种图编辑距离近似算法以及现有的基于图神经网络的模型,我们的模型不仅误差率更低,而且显著缩短了计算时间。我们的研究提示,SimGNN 为未来图相似性计算和图相似性搜索的研究提供了新的方向。
本仓库提供了论文中描述的 SimGNN 的 PyTorch 实现:
SimGNN:一种用于快速图相似性计算的神经网络方法。 白云生、丁浩、卞松、陈婷、孙义周、王伟。 WSDM, 2019。 [论文]
参考的 TensorFlow 实现可在 [这里] 获取,另一份实现则位于 [这里]。
需求
代码库使用 Python 3.5.2 编写。开发过程中使用的包版本如下:
networkx 2.4
tqdm 4.28.1
numpy 1.15.4
pandas 0.23.4
texttable 1.5.0
scipy 1.1.0
argparse 1.1.0
torch 1.1.0
torch-scatter 1.4.0
torch-sparse 0.4.3
torch-cluster 1.4.5
torch-geometric 1.3.2
torchvision 0.3.0
scikit-learn 0.20.0
数据集
代码从输入文件夹中读取用于训练的图对,每个图对以 JSON 格式存储。用于测试的图对同样以 JSON 文件形式存储。每个节点的 ID 和标签必须从 0 开始编号。字典的键采用字符串形式存储,以便进行 JSON 序列化。
每个 JSON 文件具有以下键值结构:
{"graph_1": [[0, 1], [1, 2], [2, 3], [3, 4]],
"graph_2": [[0, 1], [1, 2], [1, 3], [3, 4], [2, 4]],
"labels_1": [2, 2, 2, 2, 2],
"labels_2": [2, 3, 2, 2, 2],
"ged": 1}
键 `graph_1` 和 `graph_2` 对应边列表,用于描述图的连通性结构。类似地,键 `labels_1` 和 `labels_2` 存储每个节点的标签,标签按列表中的位置对应节点标识符。键 `ged` 则包含整数值,表示该图对的原始图编辑距离。
选项
SimGNN 模型的训练由 `src/main.py` 脚本负责,该脚本提供以下命令行参数。
输入输出选项
--training-graphs STR 训练图文件夹。默认为 `dataset/train/`。
--testing-graphs STR 测试图文件夹。默认为 `dataset/test/`。
模型选项
--filters-1 INT 第一层 GCN 的滤波器数量。默认为 128。
--filters-2 INT 第二层 GCN 的滤波器数量。默认为 64。
--filters-3 INT 第三层 GCN 的滤波器数量。默认为 32。
--tensor-neurons INT 张量网络层的神经元数量。默认为 16。
--bottle-neck-neurons INT 瓶颈层的神经元数量。默认为 16。
--bins INT 直方图的 bin 数量。默认为 16。
--batch-size INT 每批处理的图对数量。默认为 128。
--epochs INT SimGNN 的训练轮数。默认为 5。
--dropout FLOAT Dropout 概率。默认为 0.5。
--learning-rate FLOAT 学习率。默认为 0.001。
--weight-decay FLOAT 权重衰减。默认为 10^-5。
--histogram BOOL 是否包含直方图特征。默认为 False。
示例
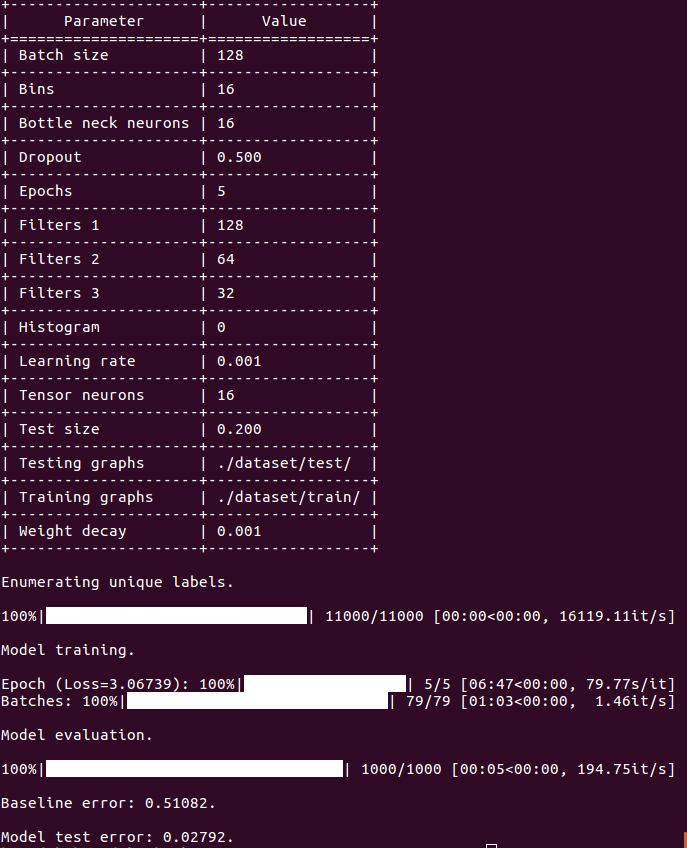
以下命令用于训练神经网络并在测试集上进行评分。在默认数据集上训练 SimGNN 模型。
python src/main.py
使用批大小为 512、训练 100 个 epoch 的 SimGNN 模型。
python src/main.py --epochs 100 --batch-size 512
使用直方图特征训练 SimGNN。
python src/main.py --histogram
使用直方图特征并设置较大的 bin 数量训练 SimGNN。
python src/main.py --histogram --bins 32
提高学习率和丢弃率。
python src/main.py --learning-rate 0.01 --dropout 0.9
可以通过添加 --save-path 参数来保存训练好的模型。
python src/main.py --save-path /path/to/model-name
然后可以使用 --load-path 参数加载预训练模型;请注意,加载的模型将按原样使用,不会进行进一步训练。
python src/main.py --load-path /path/to/model-name
许可证
版本历史
v_000012021/05/14常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。