Light-A-Video
Light-A-Video 是一款无需重新训练即可实现视频重光照(Relighting)的开源框架,旨在让用户轻松调整视频中任意片段的光照效果。传统方法若直接将图像重光照模型逐帧应用于视频,常因光源不一致或画面闪烁导致生成结果不自然,且高质量视频数据集稀缺、训练成本高昂。Light-A-Video 巧妙解决了这一痛点,它能在保持单帧图像重光照质量的同时,确保视频在时间维度上的光照过渡平滑连贯。
该工具特别适合视频创作者、视觉设计师以及希望快速验证光照效果的 AI 研究人员使用。其核心亮点在于两项创新技术:一是“一致光注意力”(CLA)模块,通过增强帧间交互来稳定背景光源的生成;二是基于光线传输独立物理原理的“渐进式光融合”(PLF)策略,通过将原始视频外观与重光照结果进行线性混合,有效消除了画面闪烁。作为 ICCV 2025 的收录成果,Light-A-Video 已支持 CogVideoX 和 Wan2.1 等主流管线,并提供在线演示,让用户能以零样本(Zero-shot)方式即刻体验专业的视频布光控制。
使用场景
某独立游戏开发者正在制作一款 2D 横版动作游戏的宣传短片,需要将白天拍摄的绿幕角色素材合成到夜晚的赛博朋克城市背景中,并确保角色身上的光影随镜头移动自然变化。
没有 Light-A-Video 时
- 光影闪烁严重:逐帧使用图像重照明模型处理,导致每一帧的光源位置和强度微小抖动,播放时角色身上出现高频闪烁。
- 光源逻辑混乱:背景是动态变化的霓虹灯,但角色身上的高光点固定不变,无法随背景光源移动而实时响应,显得非常虚假。
- 后期成本高昂:为了修复闪烁和不一致,美术人员不得不手动在合成软件中逐帧绘制遮罩和调整曲线,耗时数天。
- 训练数据缺失:市面上缺乏高质量的“视频重照明”数据集,无法微调专用模型来适配这种特定的风格化场景。
使用 Light-A-Video 后
- 时间维度平滑:利用渐进式光融合(PLF)策略,自动计算帧间线性混合,消除了光照突变,生成的视频光影过渡如丝绸般顺滑。
- 跨帧光源一致:通过一致性光注意力(CLA)模块,让模型“记住”背景光源在连续帧中的位置,角色高光和阴影随镜头运动精准同步。
- 零样本即时可用:无需收集数据或训练模型,直接加载预训练的图像重照明模型即可处理视频,将原本几天的工作缩短至几分钟。
- 物理真实感强:基于光传输独立性原理,完美保留了原始视频的纹理细节,仅改变光照分布,避免了生成式模型常见的画面崩坏。
Light-A-Video 通过无需训练的渐进式融合技术,彻底解决了视频重照明中的时序闪烁难题,让单帧图像模型也能产出电影级的动态光影效果。
运行环境要求
- 未说明
需要 NVIDIA GPU(基于扩散模型和 AnimateDiff/CogVideoX/Wan2.1 架构推断),具体显存和 CUDA 版本未说明
未说明

快速开始

⭐️ 我们团队的作品: [HiFlow] [MotionClone] [ByTheWay]
Light-A-Video:基于渐进式光照融合的无训练视频重打光
本仓库是 Light-A-Video 的官方实现。它是一个无需训练的框架,能够对任意给定的视频序列或前景序列进行零样本光照控制。
点击查看 Light-A-Video 的完整摘要
近年来,得益于大规模数据集和预训练扩散模型的发展,图像重打光技术取得了显著进展,实现了光照的一致性控制。然而,视频重打光仍相对滞后,主要原因在于高昂的训练成本以及缺乏多样化、高质量的视频重打光数据集。如果简单地将图像重打光模型逐帧应用于视频,就会出现光源不一致和重打光后外观不一致等问题,从而导致生成的视频中出现闪烁现象。在本工作中,我们提出了 Light-A-Video,这是一种无需训练的方法,用于实现时序平滑的视频重打光。Light-A-Video 借鉴了图像重打光模型,并引入了两项关键技术来提升光照一致性。首先,我们设计了一个一致光照注意力(CLA)模块,在图像重打光模型的自注意力层中增强了跨帧交互,以稳定背景光源的生成。其次,基于光线传输独立性的物理原理,我们在源视频的外观与重打光后的外观之间采用线性混合,并通过渐进式光照融合(PLF)策略确保光照的时序过渡平滑。实验结果表明,Light-A-Video 在保持重打光图像质量的同时,显著提升了重打光视频的时序一致性,确保各帧之间的光照过渡连贯。
Light-A-Video:基于渐进式光照融合的无训练视频重打光
Yujie Zhou*,
Jiazi Bu*,
Pengyang Ling*,
Pan Zhang†,
Tong Wu,
Qidong Huang,
Jinsong Li,
Xiaoyi Dong,
Yuhang Zang,
Yuhang Cao,
Anyi Rao,
Jiaqi Wang,
Li Niu†
(*贡献相等)(†通讯作者)
![]()
💡 演示
📜 新闻
[2025/6/26] 很高兴宣布,Light-A-Video 已被 ICCV 2025 接收!
[2025/3/14] 支持 CogVideoX!
[2025/3/11] 支持 Wan2.1!
[2025/2/11] 代码现已发布!
[2025/2/10] 论文和项目主页已上线!
🏗️ 待办事项
发布 Gradio 演示。
发布包含 CogVideoX-2B 流程的 Light-A-Video 代码。
📚 图库
更多结果请参见项目主页。
……,红蓝霓虹灯 |
……,海上日落 |
 |
 |
……,阳光透过百叶窗 |
……,森林中,神奇的金色光芒 |
 |
 |
🚀 方法概述
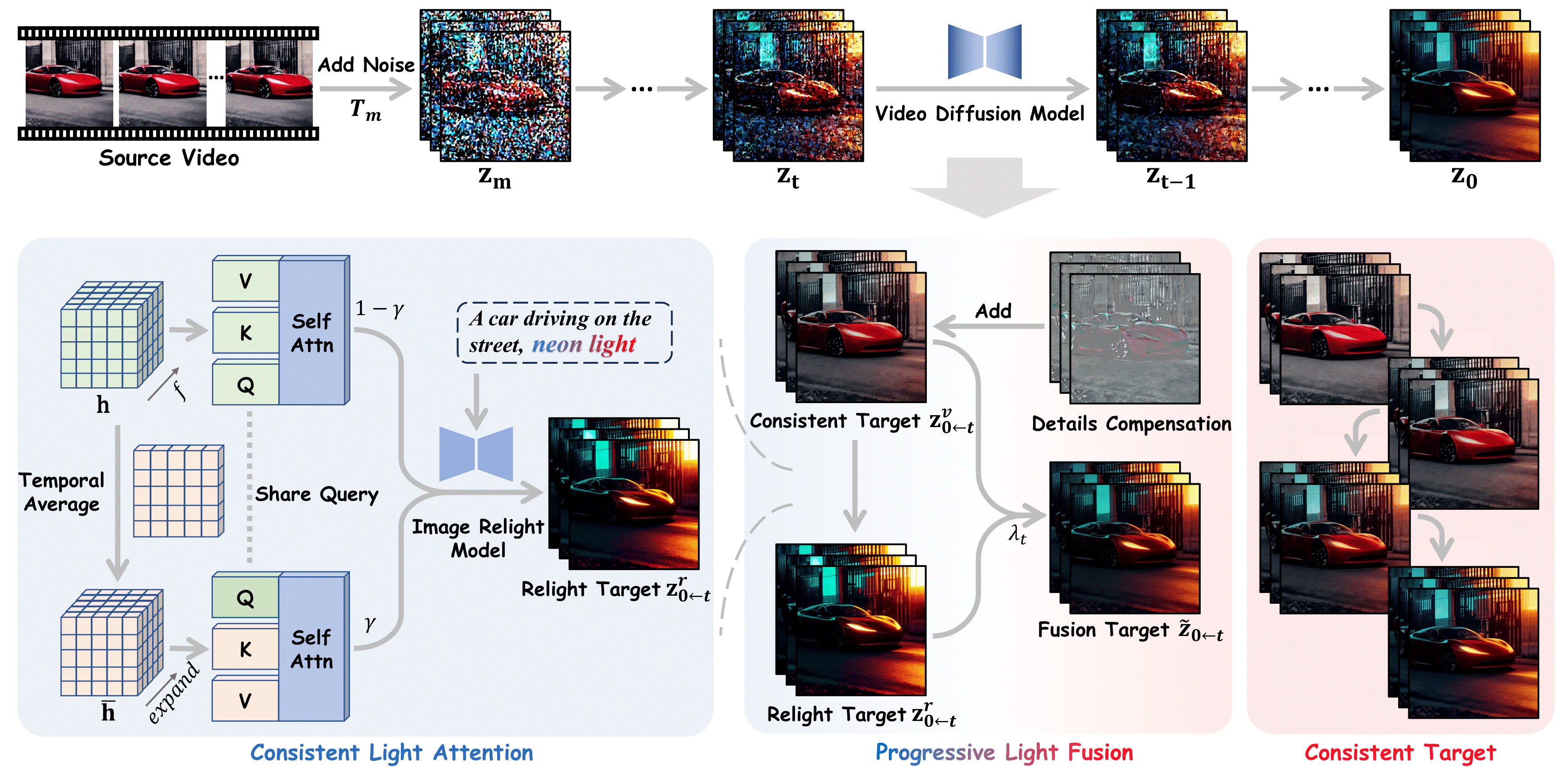
Light-A-Video 利用图像重打光模型和 VDM 运动先验的能力,实现时序一致的视频重打光。通过集成一致光照注意力模块来稳定光源生成,并采用渐进式光照融合策略以实现外观的平滑过渡。
🔧 安装步骤
克隆仓库并设置 Conda 环境
git clone https://github.com/bcmi/Light-A-Video.git
cd Light-A-Video
conda create -n lav python=3.10
conda activate lav
pip install -r requirements.txt
🔑 预训练模型准备
- IC-Light:Hugging Face
- SD RealisticVision:Hugging Face
- Animatediff Motion-Adapter-V-1.5.3:Hugging Face
模型下载将自动完成。
🎈 快速入门
使用自定义光照控制进行视频重打光
# 重打光
python lav_relight.py --config "configs/relight/car.yaml"
对前景序列进行重打光并生成背景
我们提供了一个基于 SAM2 的脚本,用于从视频中提取前景序列。
# 提取前景序列
python sam2.py --video_name car --x 255 --y 255
# 上色并重打光
python lav_paint.py --config "configs/relight_inpaint/car.yaml"
🚝 更多视频扩散模型支持
Light-A-Video 现在支持 Wan2.1 主干网络,这是一款领先的基于 DiT 的视频基础模型。现在可以处理更长的视频,并支持多种分辨率。
从源码更新 Diffusers
conda activate lav
git clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install .
使用 Wan2.1 进行视频重打光
Wan2.1 配合 Flow-Matching 调度器使用。该 VDM 检查点为 Wan2.1-T2V-1.3B-Diffusers,并将自动下载。
python lav_wan_relight.py --config "configs/wan_relight/bear.yaml"
使用 CogVideoX 进行视频重光照
CogVideoX 配合 DDIM 调度器。 VDM 检查点为 THUDM/CogVideoX-2b,它将自动下载。
python lav_cog_relight.py --config "configs/cog_relight/bear.yaml"
📎 引用
如果您认为我们的工作对您的研究有所帮助,请考虑给项目点赞 ⭐ 并引用 📝
@InProceedings{Zhou_2025_ICCV,
author = {周宇杰、卜佳姿、凌鹏洋、张攀、吴桐、黄启东、李劲松、董晓毅、臧宇航、曹宇航、饶安怡、王佳琪、牛力},
title = {Light-A-Video:通过渐进式光照融合实现无需训练的视频重光照},
booktitle = {IEEE/CVF 国际计算机视觉会议(ICCV)论文集},
month = {十月},
year = {2025},
pages = {13315-13325}
}
📣 免责声明
这是 Light-A-Video 的官方代码。 演示图片和音频的所有版权均来自社区用户。如果您希望移除这些内容,请随时与我们联系。
💞 致谢
本代码基于以下仓库构建,我们感谢所有开源贡献者。
非常感谢社区为 Light-A-Video 贡献了多种扩展功能。
相似工具推荐
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
onlook
Onlook 是一款专为设计师打造的开源 AI 优先设计工具,被誉为“设计师版的 Cursor”。它旨在打破设计与开发之间的壁垒,让用户能够以可视化的方式直接构建、样式化和编辑 React 应用。通过 Onlook,用户无需深入编写复杂代码,即可在类似 Figma 的直观界面中完成网页原型的搭建与调整,并实时预览最终效果。 这款工具主要解决了传统工作流中设计稿到代码转换效率低、沟通成本高的问题。以往,设计师使用 Figma 等工具完成设计后,需要开发人员手动将其转化为代码,过程繁琐且容易出错。Onlook 允许用户直接在浏览器 DOM 中进行可视化编辑,底层自动生成基于 Next.js 和 TailwindCSS 的高质量代码,实现了“所见即所得”的开发体验。它不仅支持从文本或图像快速生成应用,还具备分支管理、资源管理及一键部署等功能,极大地简化了从创意到成品的流程。 Onlook 特别适合前端开发者、UI/UX 设计师以及希望快速验证产品创意的独立开发者使用。对于设计师而言,它降低了参与前端开发的门槛;对于开发者来说,它提供了一个高效的视觉化调试和原型构建环境。其核心技术亮点在于
serena
Serena 是一款专为编程智能体(Coding Agent)打造的强大工具包,被誉为“智能体的集成开发环境(IDE)”。它通过模型上下文协议(MCP)与各类大语言模型及客户端无缝集成,旨在解决传统 AI 在复杂代码库中因依赖行号或简单文本搜索而导致的效率低下和准确性不足的问题。 与传统方法不同,Serena 采用“智能体优先”的设计理念,提供基于语义的代码检索、编辑和重构能力。它能像资深开发者使用 IDE 一样,深入理解代码的符号层级和关联结构,从而让智能体在大型项目中运行得更快、更稳、更可靠。无论是终端用户(如 Claude Code)、IDE 插件(VSCode、Cursor)还是桌面应用,都能轻松接入 Serena 以扩展功能。 Serena 特别适合需要处理大规模代码项目的开发者、研究人员以及希望提升 AI 编码能力的技术团队。其核心技术亮点在于灵活的后端支持:既默认集成了基于语言服务器协议(LSP)的开源方案,支持超过 40 种编程语言;也可选配强大的 JetBrains 插件,利用专业 IDE 的深度分析能力。这让 Serena 成为连接人工智能与复杂软件工程的高效桥