NCRF
NCRF 是一款基于深度学习的开源工具,专为癌症转移检测而设计。它源自百度研究院的研究成果,核心目标是解决病理全切片图像(WSI)中微小肿瘤病灶难以精准定位的难题。通过引入“神经条件随机场”(Neural Conditional Random Field)这一独特技术,NCRF 不仅能识别图像中的肿瘤区域,还能有效整合上下文空间信息,显著降低误报率,提升检测的准确性与鲁棒性。
该工具主要面向医学影像领域的研究人员、AI 开发者以及生物信息学专家。用户需要具备一定的编程基础(特别是 Python 和 PyTorch),并拥有相应的病理数据集(如 Camelyon16 挑战赛数据)才能运行训练与测试流程。NCRF 提供了从数据预处理、模型训练到结果可视化(如生成概率图、肿瘤定位及 FROC 评估)的完整代码框架,复现了相关学术论文的核心实验结果。对于致力于探索深度学习在数字病理诊断中应用的专业人士而言,NCRF 是一个极具参考价值的研究基线与实践平台。
使用场景
某三甲医院病理科正在处理数百张来自 Camelyon16 挑战赛的乳腺淋巴结全切片图像(WSI),急需精准定位其中的癌症转移灶以辅助医生确诊。
没有 NCRF 时
- 漏诊风险高:面对每张高达 10 万像素级的巨幅切片,病理医生肉眼排查极易疲劳,导致微小转移灶被遗漏。
- 上下文缺失:传统深度学习模型仅基于独立图像块(Patch)判断,忽略了组织块之间的空间关联,导致大量假阳性误报。
- 标注效率低:缺乏自动化的概率热力图引导,医生需在整张切片上盲目搜索肿瘤区域,耗时数小时才能完成一张片的初筛。
- 结果不一致:不同医生或同一医生在不同时间段的判读标准存在波动,难以形成标准化的定量评估报告。
使用 NCRF 后
- 精度显著提升:NCRF 引入神经条件随机场,有效建模了图像块间的空间依赖关系,大幅降低了孤立噪声点的干扰,提高了检测特异性。
- 智能定位引导:工具自动生成高精度的肿瘤概率热力图和定位掩膜,将医生注意力直接聚焦到可疑区域,筛查速度提升数倍。
- 标准化输出:基于 FROC 曲线评估的算法提供了客观、一致的检测结果,消除了人为主观因素带来的诊断差异。
- 全流程自动化:从组织掩膜提取到最终肿瘤定位,NCRF 实现了端到端的自动化处理,让医生只需专注于最终复核而非初步搜索。
NCRF 通过融合深度学习特征与空间上下文信息,将癌症转移检测从“大海捞针”转变为“精准制导”,显著提升了病理诊断的效率与可靠性。
运行环境要求
- Linux
需要 NVIDIA GPU,提供 GTX 1080Ti 测试案例,需 CUDA 8.0
未说明(生成训练数据需约 202GB 磁盘空间)
快速开始

NCRF
本仓库包含用于复现论文主要结果的代码和数据:
Yi Li 和 Wei Ping. 基于神经条件随机场的癌症转移检测。医学影像与深度学习(MIDL),2018年。
如果您觉得这些代码或数据有用,请引用上述论文:
@inproceedings{li2018cancer,
title={Cancer Metastasis Detection With Neural Conditional Random Field},
booktitle={Medical Imaging with Deep Learning},
author={Li, Yi and Ping, Wei},
year={2018}
}
如有任何问题,请在 GitHub 问题页面留言,或发送邮件至 yil8@uci.edu
前提条件
Python (3.6)
Numpy (1.14.3)
Scipy (1.0.1)
PyTorch (0.3.1)/CUDA 8.0 具体的二进制 wheel 文件为 cu80/torch-0.3.1-cp36-cp36m-linux_x86_64.whl。我尚未在其他版本上进行测试,尤其是 0.4 及以上版本,因此不建议使用其他版本。
torchvision (0.2.0)
PIL (5.1.0)
scikit-image (0.13.1)
OpenSlide 3.4.1(请勿使用 3.4.0 版本,因为该版本存在一些潜在问题)/openslide-python (1.1.0)
matplotlib (2.2.2)
tensorboardX 这是一个与 TensorBoard 兼容且适用于 PyTorch 的工具,主要用于监控训练曲线。
QuPath 虽然与模型的训练和测试没有直接关系,但我发现它非常有助于可视化全切片图像。
大多数依赖项都可以通过 pip 安装指定版本,例如:
pip install 'numpy==1.14.3'
或者简单地:
pip install numpy
我们还提供了一个 requirements.txt 文件,以便您可以一次性安装大部分依赖项:
pip install -r requirements.txt -i https://pypi.python.org/simple/
对于 PyTorch,请考虑下载特定的 wheel 二进制文件并使用以下命令:
pip install torch-0.3.1-cp36-cp36m-linux_x86_64.whl
数据
全切片图像
主要数据是来自 Camelyon16 挑战赛的 *.tif 格式全切片图像(WSI)。您需要向 Camelyon16 申请数据访问权限,获批后可以从 Google Drive 或百度网盘下载。请注意,一张切片在第 0 层通常约为 10 万 x 10 万像素,占用磁盘空间超过 1GB。总共有 400 张切片,合计约 700GB 以上,因此请确保您有足够的磁盘空间。用于训练的肿瘤切片命名为 Tumor_XXX.tif,其中 XXX 从 001 到 110;用于训练的正常切片命名为 Normal_XXX.tif,其中 XXX 从 001 到 160。用于测试的切片命名为 Test_XXX.tif,其中 XXX 从 001 到 130。
下载所有切片后,请将用于训练的所有肿瘤切片和正常切片放在同一个目录下,例如 /WSI_TRAIN/。
更新
目前,全切片图像 *tif 文件已可在 GigaDB 上免费下载。但为了规范数据使用,请仍与 Camelyon16 组织者联系。
标注
Camelyon16 组织者还提供了每张肿瘤切片的肿瘤区域标注,格式为 XML。我已将其转换为更为简单的 JSON 格式,位于 NCRF/jsons 目录下。每个标注都是一个多边形列表,每个多边形由其顶点表示。其中,正多边形表示肿瘤区域,负多边形表示正常区域。您也可以使用以下命令将 XML 格式转换为 JSON 格式:
python NCRF/wsi/bin/camelyon16xml2json.py Tumor_001.xml Tumor_001.json
补丁图像
尽管原始的 400 张 WSI 文件包含了所有必要信息,但它们并不适合直接用于训练深度 CNN。因此,我们需要采样更小的图像补丁,例如 256x256,这是典型的深度 CNN 所能处理的尺寸。高效地采样具有信息量且具有代表性的补丁,是实现良好肿瘤检测性能的关键环节之一。 为了简化这一过程,我在本仓库中包含了论文中用于训练的预采样补丁坐标,位于 NCRF/coords 目录下。每个文件都是 CSV 格式,每行的格式类似于 Tumor_024,25417,127565,其中最后两个数字分别是补丁中心在第 0 层的 (x, y) 坐标。tumor_train.txt 和 normal_train.txt 分别包含 20 万个坐标,而 tumor_valid.txt 和 normal_valid.txt 分别包含 2 万个坐标。需要注意的是,硬负样本的坐标,通常位于组织边界区域,也包含在 normal_train.txt 和 normal_valid.txt 中。借助原始 WSI 和预采样的坐标,我们现在可以生成用于训练深度 CNN 模型的图像补丁。运行以下四条命令以生成相应的补丁:
python NCRF/wsi/bin/patch_gen.py /WSI_TRAIN/ NCRF/coords/tumor_train.txt /PATCHES_TUMOR_TRAIN/
python NCRF/wsi/bin/patch_gen.py /WSI_TRAIN/ NCRF/coords/normal_train.txt /PATCHES_NORMAL_TRAIN/
python NCRF/wsi/bin/patch_gen.py /WSI_TRAIN/ NCRF/coords/tumor_valid.txt /PATCHES_TUMOR_VALID/
python NCRF/wsi/bin/patch_gen.py /WSI_TRAIN/ NCRF/coords/normal_valid.txt /PATCHES_NORMAL_VALID/
其中,/WSI_TRAIN/ 是您存放所有用于训练的 WSI 文件的目录路径,如上所述;/PATCHES_TUMOR_TRAIN/ 是用于存储生成的肿瘤训练补丁的目录路径。其他目录命名规则与此类似:/PATCHES_NORMAL_TRAIN/、/PATCHES_TUMOR_VALID/ 和 /PATCHES_NORMAL_VALID/。默认情况下,每条命令会使用 5 个进程生成 768x768 大小的第 0 层补丁,补丁中心对应于提供的坐标。每个 768x768 的补丁将进一步分割成 3x3 的 256x256 小补丁,以便在利用 CRF 的训练算法时使用。
需要注意的是,使用 5 个进程生成 20 万个 768x768 补丁大约耗时 4.5 小时,生成的文件大小约为 202GB。
模型
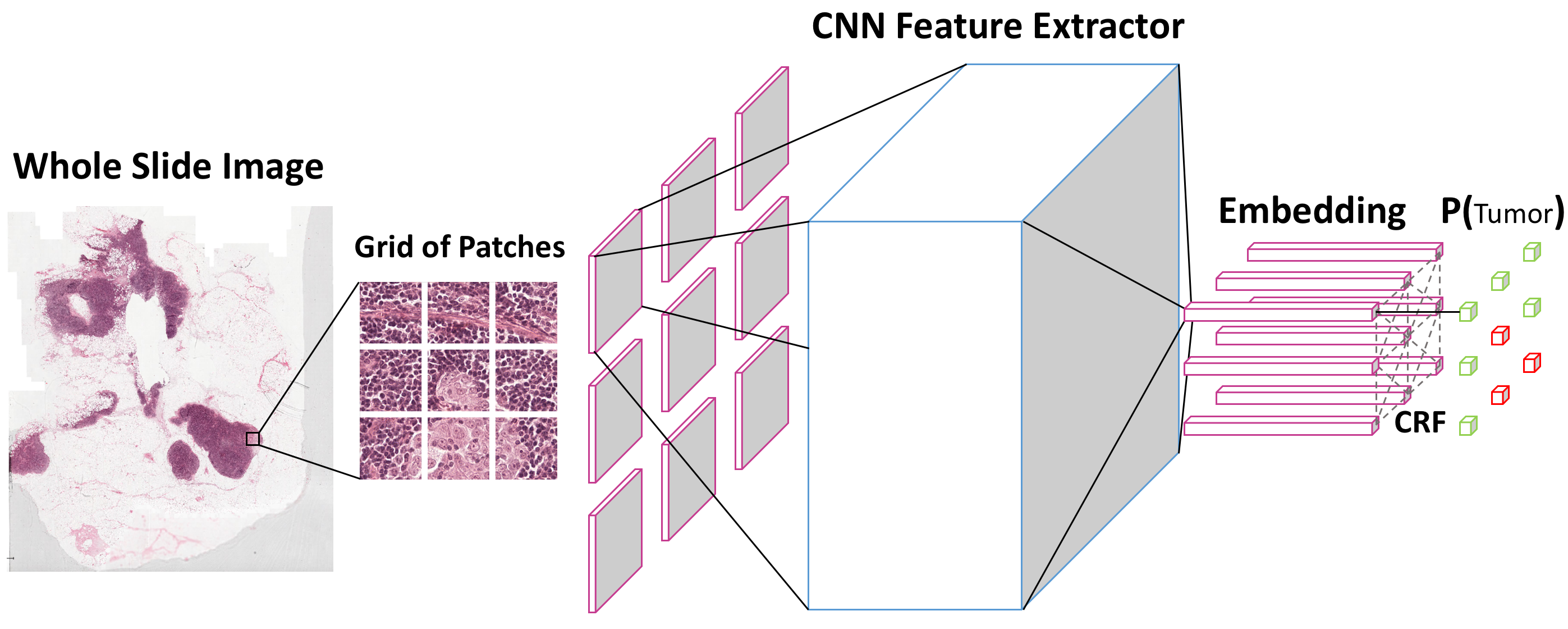 NCRF 的核心思想是将一个由补丁组成的网格作为输入,例如 3x3 网格,使用 CNN 模块提取补丁的嵌入表示,并利用 CRF 模块建模这些补丁之间的空间相关性。CNN 模块源自 torchvision 发布的标准 ResNet(https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py)。主要区别在于前向传播过程中:1. 输入张量多了一个维度;2. 使用 CRF 模块通过补丁的嵌入表示对每个补丁的 logits 进行平滑处理。
NCRF 的核心思想是将一个由补丁组成的网格作为输入,例如 3x3 网格,使用 CNN 模块提取补丁的嵌入表示,并利用 CRF 模块建模这些补丁之间的空间相关性。CNN 模块源自 torchvision 发布的标准 ResNet(https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py)。主要区别在于前向传播过程中:1. 输入张量多了一个维度;2. 使用 CRF 模块通过补丁的嵌入表示对每个补丁的 logits 进行平滑处理。
def forward(self, x):
"""
Args:
x: 5D 张量,形状为
[batch_size, grid_size, 3, crop_size, crop_size],
其中 grid_size 是网格内补丁的数量(例如 3x3 网格为 9);crop_size 默认为 ResNet 输入的 224;
Returns:
logits,2D 张量,形状为 [batch_size, grid_size],表示网格内每个补丁属于肿瘤的 logits
"""
batch_size, grid_size, _, crop_size = x.shape[0:4]
# 将 grid_size 维度展平并合并到 batch 维度中
x = x.view(-1, 3, crop_size, crop_size)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
# feats 表示特征,即来自 ResNet 的补丁嵌入
feats = x.view(x.size(0), -1)
logits = self.fc(feats)
# 恢复 grid_size 维度以便进行 CRF 处理
feats = feats.view((batch_size, grid_size, -1))
logits = logits.view((batch_size, grid_size, -1))
if self.crf:
logits = self.crf(feats, logits)
logits = torch.squeeze(logits)
return logits
CRF 模块仅有一个可训练参数 W,用于补丁之间的成对势能。你可以通过以下命令从已训练 CRF 模型的 ckpt 文件中绘制 W(参见下一节):
python NCRF/wsi/bin/plot_W.py /PATH_TO_MODEL/best.ckpt
当 CRF 模型训练良好时,W 通常反映了输入网格中不同补丁之间的相对空间位置。有关模型的更多详细信息,请参阅我们的论文。

训练
有了生成的补丁图像,我们现在可以使用以下命令训练模型:
python NCRF/wsi/bin/train.py /CFG_PATH/cfg.json /SAVE_PATH/
其中 /CFG_PATH/ 是 JSON 格式的配置文件路径,而 /SAVE_PATH/ 是你希望以 checkpoint (ckpt) 格式保存模型的地方。在 NCRF/configs 中提供了两个配置文件,其中一个适用于带有 CRF 的 ResNet-18:
{
"model": "resnet18",
"use_crf": true,
"batch_size": 10,
"image_size": 768,
"patch_size": 256,
"crop_size": 224,
"lr": 0.001,
"momentum": 0.9,
"data_path_tumor_train": "/PATCHES_TUMOR_TRAIN/",
"data_path_normal_train": "/PATCHES_NORMAL_TRAIN/",
"data_path_tumor_valid": "/PATCHES_TUMOR_VALID/",
"data_path_normal_valid": "/PATCHES_NORMAL_VALID/",
"json_path_train": "NCRF/jsons/train",
"json_path_valid": "NCRF/jsons/valid",
"epoch": 20,
"log_every": 100
}
请分别将 /PATCHES_TUMOR_TRAIN/、/PATCHES_NORMAL_TRAIN/、/PATCHES_TUMOR_VALID/ 和 /PATCHES_NORMAL_VALID/ 修改为你自己生成的补丁图像路径。同时,请根据你本地 NCRF 仓库的完整路径修改 NCRF/jsons/train 和 NCRF/jsons/valid。另一个配置文件适用于不带 CRF 的 ResNet-18(基准模型)。
默认情况下,train.py 使用 1 个 GPU (GPU_0) 来训练模型,2 个进程加载肿瘤补丁图像,2 个进程加载正常补丁图像。在一台 GTX 1080Ti 上,训练 1 个 epoch 大约需要 5 小时,完成 20 个 epoch 则需要 4 天。你还可以使用 tensorboard 监控训练过程:
tensorboard --logdir /SAVE_PATH/
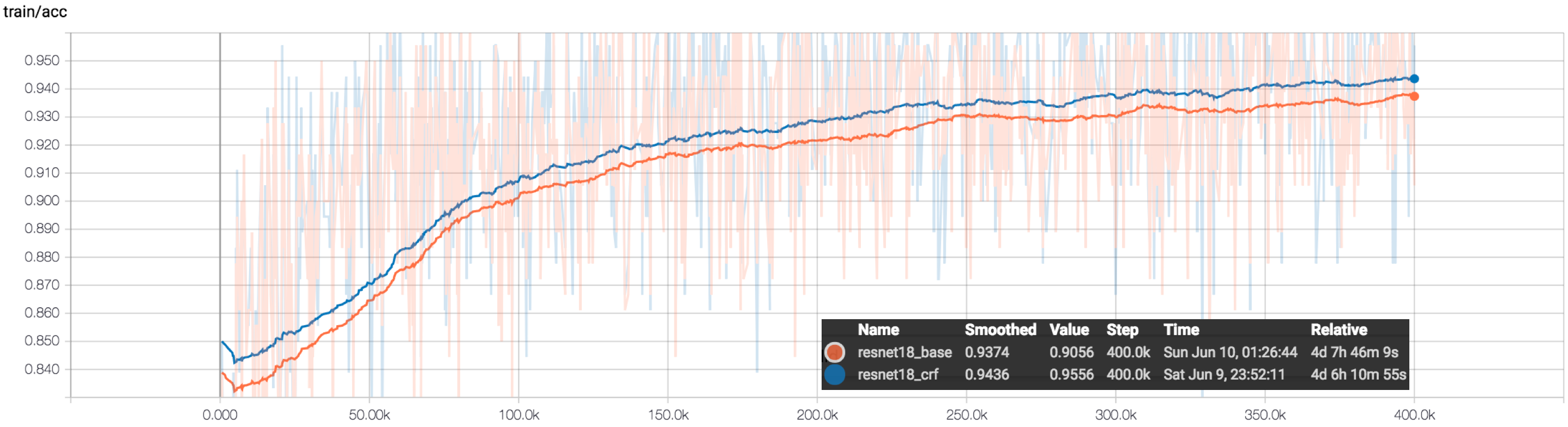 通常,你会观察到 CRF 模型的训练准确率始终高于基准模型。
通常,你会观察到 CRF 模型的训练准确率始终高于基准模型。
train.py 会生成一个 train.ckpt,即最近保存的模型,以及一个 best.ckpt,即验证准确率最高的模型。我们还在 NCRF/ckpt 中提供了预训练的 resnet18_base 和 resnet18_crf 的 best.ckpt。
测试
组织掩膜
经过训练的模型用于 WSI 分析的主要测试结果是概率图,它表示模型认为 WSI 上哪些区域是肿瘤区域。最简单的方法是采用滑动窗口的方式,在整张切片上逐个预测所有补丁是否为肿瘤。但由于 WSI 的大部分区域实际上是白色背景,这种滑动窗口方式会浪费大量计算资源。因此,我们首先计算一个二值组织掩膜,用于标识每个补丁是组织还是背景,然后只在组织区域进行肿瘤预测。典型的 WSI 及其组织掩膜如下所示(Test_026):
 要获取给定输入 WSI 的组织掩膜,例如 Test_026.tif,运行以下命令:
要获取给定输入 WSI 的组织掩膜,例如 Test_026.tif,运行以下命令:
python NCRF/wsi/bin/tissue_mask.py /WSI_PATH/Test_026.tif /MASK_PATH/Test_026.npy
其中 /WSI_PATH/ 是你感兴趣的 WSI 路径,而 /MASK_PATH/ 是你希望以 numpy 格式保存生成的组织掩膜的路径。默认情况下,组织掩膜是在第 6 层生成的,对应于 64 像素的推理步长,即在第 0 层每 64 像素进行一次预测。
这里附上了 Test_026_tissue_mask.npy 在第 6 层的组织掩膜供参考。请注意,使用 matplotlib.pyplot.imshow 绘制时,需先对其进行转置。
概率图
借助生成的组织掩膜,我们现在可以使用训练好的模型为给定的WSI(例如Test_026.tif)获取概率图:
python NCRF/wsi/bin/probs_map.py /WSI_PATH/Test_026.tif /CKPT_PATH/best.ckpt /CFG_PATH/cfg.json /MASK_PATH/Test_026.npy /PROBS_MAP_PATH/Test_026.npy
其中,/WSI_PATH/是您感兴趣的WSI文件路径;/CKPT_PATH/是您保存训练模型的目录,而best.ckpt对应于验证准确率最高的模型;/CFG_PATH/是训练模型配置文件的路径,格式为JSON,通常与/CKPT_PATH/相同;/MASK_PATH/是您保存生成的组织掩膜的路径;/PROBS_MAP_PATH/则是您希望以NumPy格式保存生成的概率图的路径。
默认情况下,probs_map.py会使用GPU_0进行推理,并启用5个进程加载数据。需要注意的是,尽管我们会加载一个补丁网格(例如3×3),但为了便于实现,仅保留中心补丁的预测概率。由于计算开销较大,生成一张WSI的概率图通常需要0.5至1小时。我们正在考虑开发更高效的推理算法来生成概率图。
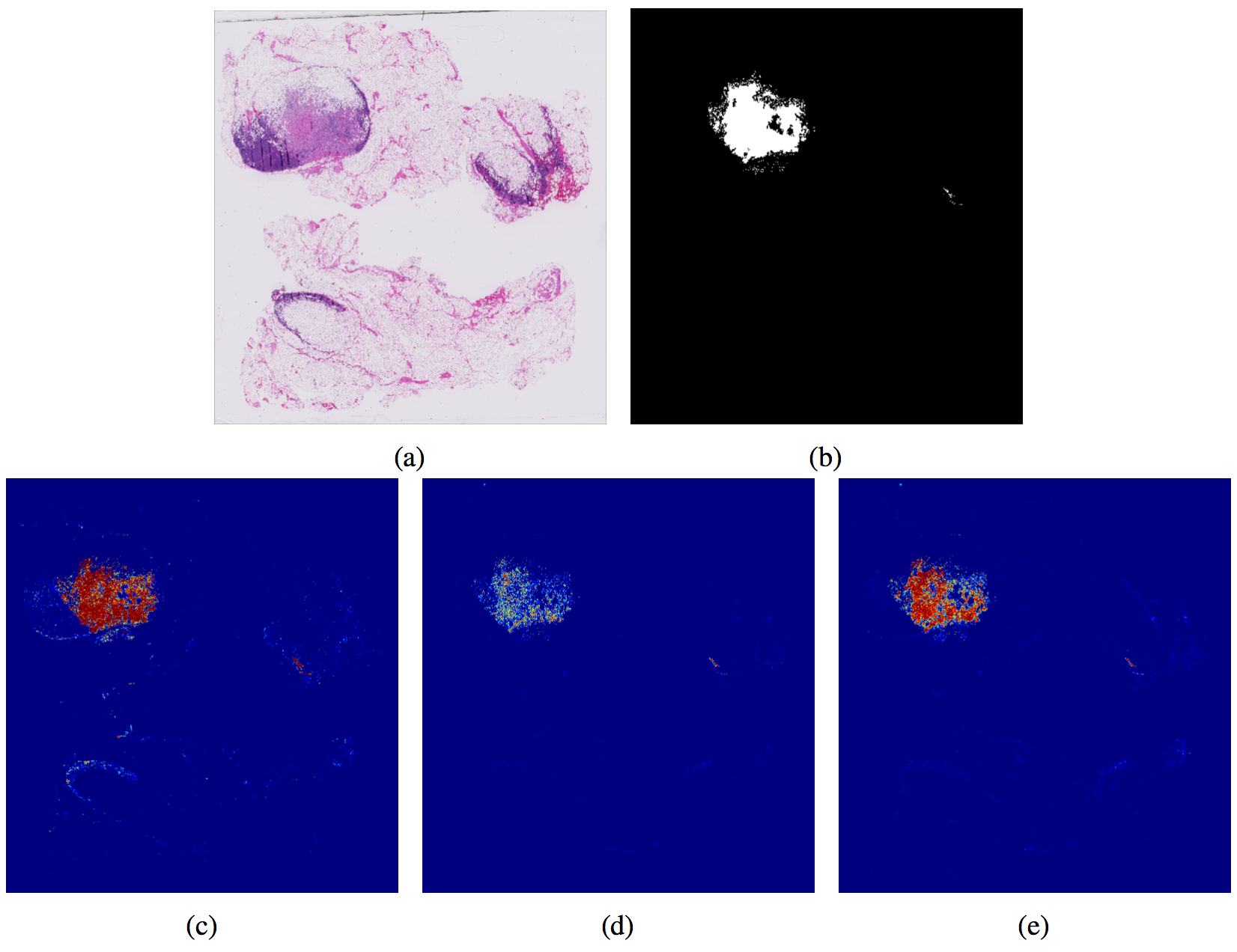 该图展示了Test_026在不同设置下的概率图:(a) 原始WSI,(b) 真实标注,(c) 基线方法,(d) 采用困难负样本挖掘的基线方法,(e) 结合困难负样本挖掘的NCRF。我们可以看到,基线方法生成的概率图通常存在大量孤立的假阳性区域。通过引入困难负样本挖掘,基线方法的假阳性数量显著减少,但同时真实肿瘤区域内的概率密度也随之降低,从而削弱了模型的敏感性。相比之下,结合困难负样本挖掘的NCRF不仅能够有效降低假阳性,还能在真实肿瘤区域内保持较高的概率密度,且边界更加清晰。
该图展示了Test_026在不同设置下的概率图:(a) 原始WSI,(b) 真实标注,(c) 基线方法,(d) 采用困难负样本挖掘的基线方法,(e) 结合困难负样本挖掘的NCRF。我们可以看到,基线方法生成的概率图通常存在大量孤立的假阳性区域。通过引入困难负样本挖掘,基线方法的假阳性数量显著减少,但同时真实肿瘤区域内的概率密度也随之降低,从而削弱了模型的敏感性。相比之下,结合困难负样本挖掘的NCRF不仅能够有效降低假阳性,还能在真实肿瘤区域内保持较高的概率密度,且边界更加清晰。
附上Test_026_probs_map.npy在第6级下的概率图,供对比参考。请注意,使用matplotlib.pyplot.imshow绘制时,需先对其进行转置。
肿瘤定位
我们利用非极大值抑制(NMS)算法,根据概率图在第0级获取每个检测到的肿瘤区域的坐标。
python NCRF/wsi/bin/nms.py /PROBS_MAP_PATH/Test_026.npy /COORD_PATH/Test_026.csv
其中,/PROBS_MAP_PATH/是您保存生成的概率图的路径,而/COORD_PATH/则是您希望以CSV格式保存各肿瘤区域在第0级坐标的路径。该脚本提供了一个可选参数--level,其默认值为6,请确保它与用于生成相应组织掩膜和概率图的级别一致。
FROC评估
有了每张测试WSI中肿瘤区域的坐标后,我们最终可以评估肿瘤定位的平均FROC分数。
python NCRF/wsi/bin/Evaluation_FROC.py /TEST_MASK/ /COORD_PATH/
/TEST_MASK/是存放测试集真实标注TIFF掩膜文件的路径,而/COORD_PATH/则是保存生成的肿瘤坐标文件的路径。Evaluation_FROC.py基于Camelyon16组织方提供的评估代码并进行了少量修改。需要注意的是,根据Camelyon16组织方的说明,Test_049和Test_114不参与本次评估。
版本历史
v1.02018/06/17常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。