DeepBench
DeepBench 是由百度研究院推出的开源基准测试工具,专注于评估不同硬件平台上深度学习核心算子的性能表现。尽管深度学习的基础计算原理已十分成熟,但在实际应用中,矩阵乘法、卷积等关键操作会因参数规模、内核实现及硬件特性的不同,呈现出计算受限、带宽受限或占用率受限等多种瓶颈。DeepBench 正是为了解决这一“优化空间巨大且定义模糊”的难题而生,它通过底层标准化的测试用例,回答“哪种硬件在深度学习基础操作上表现最佳”这一核心问题。
该工具主要面向硬件厂商、芯片架构师以及系统软件开发者。与直接测试完整模型的上层框架不同,DeepBench 不依赖具体的深度学习应用模型,而是直接调用 NVIDIA cuDNN、Intel MKL 等底层神经网络库,对训练和推理过程中的密集矩阵运算、卷积及通信操作进行独立评测。其独特亮点在于提供了详尽的训练与推理测试尺寸集合,并坚持使用厂商官方提供的库进行测试,从而最真实地反映广大用户的实际体验。通过量化这些基础算子的性能,DeepBench 帮助开发者精准定位硬件与软件协同优化中的瓶颈,为新一代深度学习处理器的设计与调优提供可靠的数据支撑。
使用场景
某芯片初创公司的架构团队正在研发一款专为深度学习训练定制的 AI 加速器,急需验证其核心计算单元在不同矩阵规模下的实际效能。
没有 DeepBench 时
- 评估依据模糊:团队只能依赖完整的深度学习框架(如 TensorFlow)进行端到端测试,无法剥离出矩阵乘法或卷积等底层算子的独立性能,难以定位是硬件缺陷还是软件调度问题。
- 优化方向迷失:面对计算受限、带宽受限或占用率受限等不同瓶颈,缺乏标准化的基准数据来判断当前硬件在特定算子尺寸下究竟卡在哪里。
- 竞品对比困难:由于缺乏统一的低层级操作标准,很难将自研芯片与 NVIDIA TitanX 或 Intel Xeon Phi 等成熟平台在同等细粒度下进行公平的性能对标。
使用 DeepBench 后
- 精准定位瓶颈:DeepBench 直接对稠密矩阵乘法、卷积及通信等基础操作进行微基准测试,帮助团队迅速识别出在特定矩阵尺寸下硬件是受限于算力还是显存带宽。
- 指导架构迭代:基于训练和推理场景下不同精度的详细测试数据,架构师能针对性地调整计算单元比例或内存层级设计,避免盲目优化。
- 建立客观标尺:利用 DeepBench 预定义的标准化算子集,团队成功将自研芯片与主流 GPU 在同一维度上进行量化对比,用确凿的数据证明了新架构在特定负载下的优势。
DeepBench 通过剥离框架干扰、聚焦底层算子,为硬件研发者提供了一把衡量深度学习基础性能的精确标尺。
运行环境要求
- Linux
- 必需
- 支持 NVIDIA GPU (TitanX, M40, TitanX Pascal, TitanXp, 1080 Ti, P100) 和 Intel Xeon Phi (Knights Landing)
- 需安装厂商提供的底层库(如 NVIDIA cuDNN, NCCL)
- 未明确具体显存大小和 CUDA 版本,但需匹配对应硬件的驱动和库版本
未说明

快速开始

DeepBench
DeepBench 的主要目的是在不同硬件平台上对深度学习中重要的操作进行基准测试。尽管深度学习背后的基本计算原理已被充分理解,但在实际应用中,这些计算的使用方式却可能出人意料地多样化。例如,矩阵乘法可能是计算受限、带宽受限或占用率受限,具体取决于所乘矩阵的大小以及内核实现方式。由于每个深度学习模型都会以不同的参数使用这些操作,因此面向深度学习的硬件和软件优化空间非常大且尚未完全明确。
DeepBench 试图回答这样一个问题:“哪种硬件在用于深度神经网络的基本操作上能够提供最佳性能?”我们以适合用于构建针对深度学习的新处理器的硬件模拟器使用的低级别形式来定义这些操作。DeepBench 包含对训练和推理都至关重要的操作和工作负载。
DeepBench 在整个生态体系中的定位是?
深度学习生态系统由多个不同的组成部分构成。我们希望阐明 DeepBench 在这一生态体系中的位置。下图描述了深度学习涉及的软硬件组件。最顶层是深度学习框架,如百度的 PaddlePaddle、Theano、TensorFlow、Torch 等。这些框架允许深度学习研究人员构建模型,它们包含诸如层等基本构建模块,可以通过不同的连接方式组合成一个完整的模型。为了训练深度学习模型,这些框架会与底层的神经网络库协同工作,例如 NVIDIA 的 cuDNN 和 Intel 的 MKL。这些库实现了诸如矩阵乘法等对深度学习模型至关重要的操作。最后,模型会在 NVIDIA GPU 或 Intel Xeon Phi 处理器等硬件上进行训练。
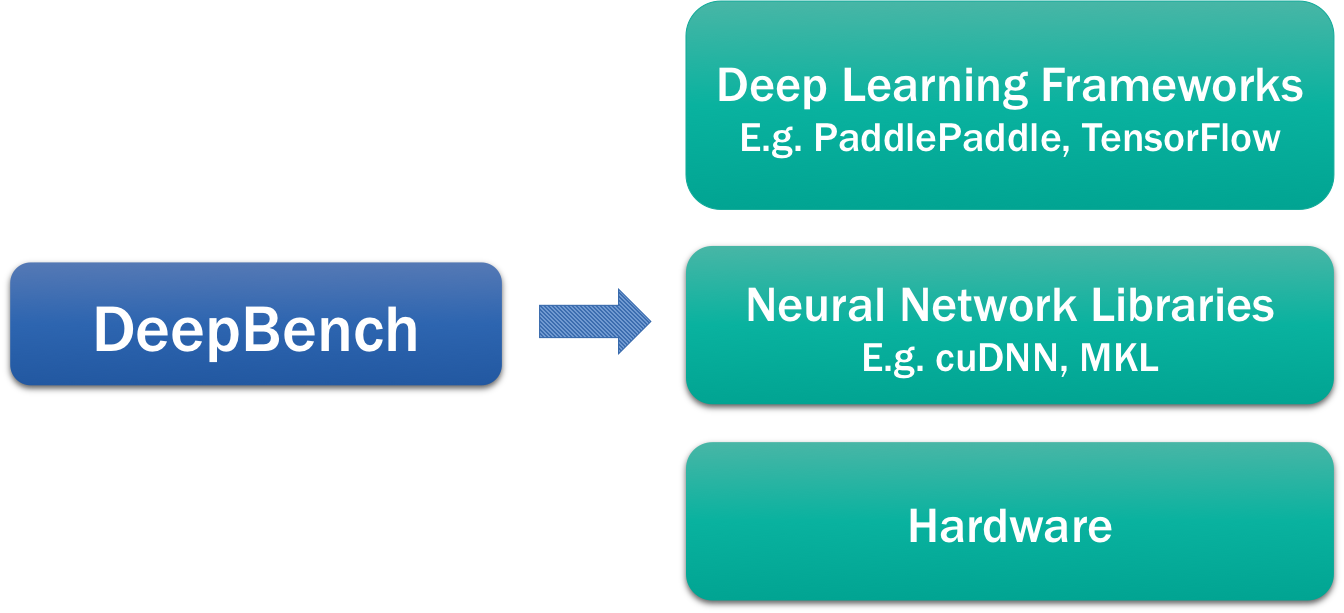
DeepBench 利用这些神经网络库来评估不同硬件上基本操作的性能。它不直接与深度学习框架或为特定应用构建的深度学习模型交互。我们无法通过 DeepBench 测量训练整个模型所需的时间。针对不同应用构建的模型其性能特征差异很大,因此我们专注于对深度学习模型中涉及的底层操作进行基准测试。对这些操作的基准测试将有助于提高硬件供应商和软件开发者对深度学习训练和推理过程中瓶颈的认识。
方法论
DeepBench 包含一组基本操作(密集矩阵乘法、卷积和通信)以及一些循环层类型。本仓库中提供了两个 Excel 表格(DeepBenchKernels_train.xlsx 和 DeepBenchKernels_inference.xlsx),分别详细列出了用于训练和推理的所有尺寸配置。
对于训练,正向和反向操作都会被测试。训练和推理所需的精度要求将在下文讨论。
我们将使用厂商提供的库,即使存在更快的独立库或已发表过更快的结果。大多数用户默认会使用厂商提供的库,因此这些库更能代表用户的实际体验。
入场
DeepBench 包含七个硬件平台的训练结果:NVIDIA 的 TitanX、M40、TitanX Pascal、TitanXp、1080 Ti、P100 以及 Intel 的 Knights Landing。推理结果则涵盖三个服务器平台:NVIDIA 的 TitanX Pascal、TitanXp 和 1080 Ti。此外,还包含了三个移动设备的推理结果:iPhone 6 和 7 以及 Raspberry Pi 3。我们提供了结果概览,所有结果均可在 results 文件夹中找到。我们也欢迎针对新硬件平台的拉取请求。
操作类型
密集矩阵乘法
如今,几乎所有的深度神经网络中都存在密集矩阵乘法。它们用于实现全连接层和普通的 RNN,并且是其他类型循环层的基础构建模块。有时,它们也被用作一种快速实现新型层的方式,尤其是在没有相应自定义代码的情况下。
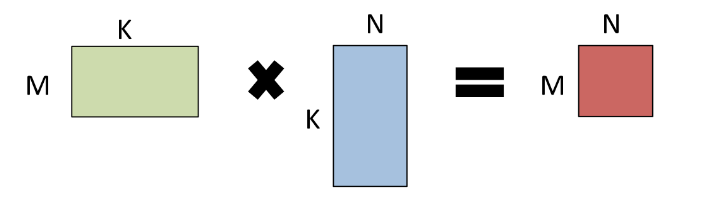
在执行 GEMM 操作 A * B = C 时,A 和 B 中的任意一个或两个都可以选择转置。描述矩阵问题的常用术语是三元组 (M, N, K),它表示参与运算的矩阵大小,而“op”则告诉我们哪些矩阵(如果有的话)需要转置。下图展示了三元组 (M, N, K) 如何对应于待乘矩阵的大小。
其中两个矩阵都转置的情况在神经网络中并不常见。另外三种情况则会被使用,但并不一定需要通过带有相应转置描述符的 SGEMM 调用来实现。有时,先就地转置一次,再进行适当的乘法运算,最后再转置回来,反而会更高效。这类优化应在电子表格中详细说明。
常数系数 alpha 和 beta 均应设为 1.0,以确保不会省略任何计算步骤。
卷积
卷积占据了处理图像和视频的网络中绝大多数的浮点运算量,同时也是语音和自然语言建模等网络的重要组成部分,因此从性能角度来看,它们或许是最重要的层。
卷积的输入和输出具有 4 或 5 维,这导致这些维度存在大量的排列组合可能性。在基准测试的第一个版本中,我们仅关注 NCHW 格式下的性能,即数据以图像、特征图、行和列的形式呈现。
有许多计算卷积的技术,它们针对不同大小的滤波器和图像各有优势,包括直接计算、基于矩阵乘法、基于 FFT 以及基于 Winograd 的方法。在本次基准测试的第一个版本中,我们并不关心不同方法的精确性,因为普遍认为 32 位浮点数对于这些方法来说已经足够准确了。我们在电子表格中记录了每种尺寸所采用的方法。
循环层
循环层通常由上述操作的某种组合以及一些更简单的操作(如一元或二元操作)构成。这些简单操作的计算量不大,通常只占总运行时间的一小部分。然而,在循环层中,GEMM和卷积操作所占的比例相对较小,因此这些小型操作的成本可能会变得显著。特别是在启动计算时存在较高固定开销的情况下,这种影响尤为明显。此外,还可以为循环矩阵使用替代存储格式,因为转换到新存储格式的开销可以在循环计算的多个步骤中分摊。如果采用这种方法,则自定义格式与常规格式之间的转换时间也应计入总时间。
这些因素导致了在单个时间步长内以及整个序列中的多种优化可能性,因此单纯测量操作的原始性能并不一定能反映整个循环层的实际性能。在本基准测试中,我们仅关注一个循环层,尽管如果考虑多个循环层的堆叠,优化机会会更多。
输入的计算不应计入循环层的计算时间,因为它可以作为一个大型乘法运算完成,随后被实际的循环计算所消耗。例如,在公式 h_t = g(Wx_t + Uh_t-1) 中,所有 t 对应的 Wx_t 的计算时间都不应计入循环层的时间。
反向传播计算应仅计算相对于权重的更新,而不应计算相对于输入的更新。循环层的所有工作都是为了计算权重更新,因此同时计算输入的更新只会掩盖我们想要测量的内容。
DeepBench 支持三种类型的循环单元:普通 RNN、LSTM 和 GRU。普通 RNN 的非线性激活函数应为 ReLU。LSTM 的内部非线性操作应遵循标准设置——门控使用 sigmoid 函数,而状态更新使用 tanh 函数。LSTM 不应包含窥视连接。GRU 的内部结构应使用 sigmoid 函数作为重置门和更新门的激活函数,而输出门的非线性激活函数则应为 ReLU。
All-Reduce
如今,神经网络训练常常跨多个 GPU 甚至多个系统进行,每个系统可能配备多个 GPU。实现这一目标的主要技术分为同步和异步两类。同步方法依赖于保持模型所有实例的参数一致,通常通过确保所有实例拥有相同的梯度副本后再执行优化步骤来实现。用于执行此操作的 消息传递接口 (MPI) 原语称为 All-Reduce。All-Reduce 的具体实现方式因进程数、数据规模及网络拓扑的不同而有多种选择。本基准测试对实现方式没有限制,只要求其具有确定性即可。异步方法则更加多样化,在本版本的基准测试中,我们暂不对其性能进行评估。
为了评估 All-Reduce 性能,我们使用以下库和基准测试:
- NVIDIA 的 NCCL
- 俄亥俄州立大学 (OSU) 基准测试
- 百度的 Allreduce
- 英特尔的 MLSL
NCCL 库既可以不使用 MPI(适用于单节点场景),也可以使用 MPI(适用于多节点场景),具体可参考 https://github.com/NVIDIA/nccl-tests。因此,在单节点实验中,我们使用两种不同配置的 NCCL;而在多节点实验中,则仅使用带有 MPI 的 NCCL、OSU 基准测试以及百度的 Allreduce 实现。对于每种配置,我们报告所有实现中取得的最短延迟。
英特尔(R) 机器学习扩展库(Intel(R) MLSL)是一个提供深度学习中常用通信模式高效实现的库。为了评估 All-Reduce 性能,我们使用 OSU 提供的 All-Reduce 基准测试。
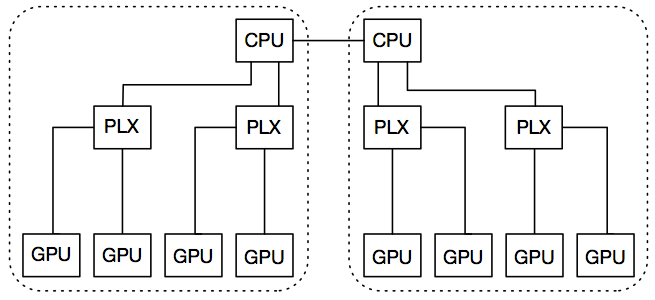
NVIDIA 8 GPU 系统的拓扑结构
每个节点配备两个 CPU 插槽(双根拓扑),每个插槽都连接着一个 PCIe 根复合体。每个插槽还配有两台 PLX 交换机,每台交换机通过 16 条 PCIe v3 链路与 CPU 插槽相连。每台 PLX 交换机上安装有两个 GPU,任意一对 GPU 都可通过 16 条 PCIe v3 链路同时进行通信。两个 CPU 插槽之间通过 Intel QPI 连接,节点间的互连则采用 InfiniBand FDR。下图展示了一个节点的示意图,其中所有由同一 PCI 根复合体连接的设备都被框在一个虚线框内。在我们的实验中,P100、TitanX Maxwell 和 M40 就属于此类系统。
NVIDIA 10 GPU 系统的拓扑结构
每个节点配备一个 CPU 插槽(单根拓扑),并连接着两台 PLX 交换机,每台交换机又连接着 5 个 GPU。位于同一 PLX 交换机上的 GPU 之间可以直接通信,而与其他 PLX 交换机上的 GPU 通信则需要依次经过两台 PLX 交换机以及连接它们的 PCIe 桥。在我们的实验中,TitanX Pascal 和 1080Ti 属于此类系统。
英特尔 Xeon Phi 和 Omni-Path 系统的拓扑结构
阻塞式 All-Reduce 延迟是在英特尔内部 Endeavor 集群上,使用英特尔® Omni-Path 架构(Intel® OPA)系列 100 脂肪树拓扑结构,搭载英特尔 Xeon Phi 处理器 7250,并采用 Intel MPI 2017 Update 3 和 Intel MLSL 2017 Update 2 Preview 版本进行测量的。
训练基准测试
训练基准测试支持上述讨论的所有操作。DeepBenchKernels_train.xlsx 文件包含了训练基准测试中的全部内核列表。
训练精度
在训练深度学习模型时,大多数研究者通常对所有计算内核使用单精度浮点数。学术研究表明,在有限数据集上训练的多种模型可以采用低精度训练。根据我们的经验,16位半精度浮点数足以可靠地训练大型深度学习模型和大规模数据集。使用半精度数值进行训练可以使硬件供应商更好地利用现有计算资源。此外,参数所需的存储空间仅为全模型的一半。
DeepBench 规定了训练的最低精度要求。我们为所有操作指定了乘法和加法的精度。乘法和加法的最低精度分别设定为16位和32位。 目前没有任何可用的硬件支持16位乘法和32位累加。我们将接受任何满足此最低精度要求的硬件平台上的结果。所有结果都将包含用于基准测试的精度设置。
推理基准测试
推理性能的基准测试是一项极具挑战性的任务。深度学习已经催生了众多应用,而每种应用都有其独特的性能特征和需求。我们选择的基准测试应用均具有较高的用户流量。此外,我们还纳入了在多个不同应用中广泛使用的深度学习模型中的内核。
对于推理内核,我们涵盖了与训练部分相同的运算类型,即矩阵乘法、卷积和循环神经网络运算。这些内核与训练用内核存在一些差异。在接下来的几节中,我们将讨论针对推理工作负载进行基准测试所需的变化。DeepBenchKernels_inference.xlsx 文件包含了训练基准测试的完整内核列表。
部署平台
像图像搜索、语言翻译和语音识别这样的大规模实际应用,通常部署在数据中心的服务器上。客户端通过互联网发送请求,由托管深度学习模型的远程服务器进行处理。远程服务器通常是配备多处理器的强大机器,其内存和计算能力足以运行非常庞大的深度学习模型。然而,将模型部署在服务器上的缺点是延迟取决于客户端与服务器之间的网络带宽,并且需要用户保持联网状态。为了解决这些问题,许多模型开始被部署到终端设备上。在设备端部署可以降低延迟,并且无论是否连接互联网都能随时使用。不过,为了适应移动和嵌入式设备的功耗及内存限制,这些模型必须更加精简小巧。
在 DeepBench 中,我们同时测量推理内核在服务器和移动平台上的性能。硬件厂商或用户可以运行相应的基准测试,并将结果提交到代码库中。以下是对结果的概述,详细结果则可在 results/inference 文件夹中找到。我们欢迎针对新硬件平台的拉取请求。
推理批大小
为了满足用户请求的延迟要求,大多数互联网应用会在请求到达数据中心后逐一处理。这种方式实现起来较为简单,每个请求由一个线程单独处理。然而,这种做法存在两个弊端:首先,逐个处理请求会导致带宽受限,因为处理器需要频繁加载网络权重,从而难以有效利用片上缓存;其次,用于处理单个请求的并行度有限,难以充分利用 SIMD 或多核并行性。尤其是 RNN 模型,由于其逐样本评估依赖于矩阵向量乘法,而这类运算同样受带宽限制且难以并行化,因此部署起来尤为困难。
为了解决这些问题,我们开发了一个名为 Batch Dispatch 的批处理调度器,它会将来自用户请求的数据流汇集为批次,然后再对这些批次执行前向传播。在这种情况下,批大小的增加虽然能提升效率,却也会导致延迟上升。我们缓冲的用户请求越多、批次越大,用户等待结果的时间就越长,这就限制了我们可以进行的批处理规模。
实践中,我们发现对于数据中心部署而言,将请求批量控制在4至5个左右,能够在效率和延迟之间取得较好的平衡。而在设备端部署时,批大小则通常限制为1。
推理精度
深度神经网络通常使用单精度或半精度浮点数进行训练。而推理阶段的精度要求则显著低于训练阶段。许多不同的模型在推理时采用8位表示即可,且与浮点模型相比几乎不会损失精度。因此,对于推理内核,我们规定了乘法和累加的最低精度分别为8位和32位。 由于并非所有硬件平台都支持这一精度要求,我们将接受任何满足该最低要求的平台上的结果。所有结果都将注明用于基准测试的具体精度。
为了在 ARM 处理器上对8位输入的矩阵乘法进行基准测试,我们使用 Gemmlowp 库。卷积基准测试则采用 ARM Compute Library 中的卷积内核。需要注意的是,ARM Compute Library 目前仅支持单精度卷积,低精度卷积的支持预计很快就会推出。此外,ARM Compute Library 尚未提供 RNN 支持,因此 DeepBench 不包含 ARM 设备上的 RNN 结果。我们欢迎其他能够支持 ARM 设备 RNN 运算的库贡献相关内容。
对于服务器部署,我们使用 NVIDIA GPU 上的 cuDNN 和 cuBLAS 库。在 NVIDIA GPU 上,RNN 内核仅支持单精度运算,相关结果也以单精度形式报告。关于不同处理器支持的具体运算类型,更多细节将在后续章节中介绍。
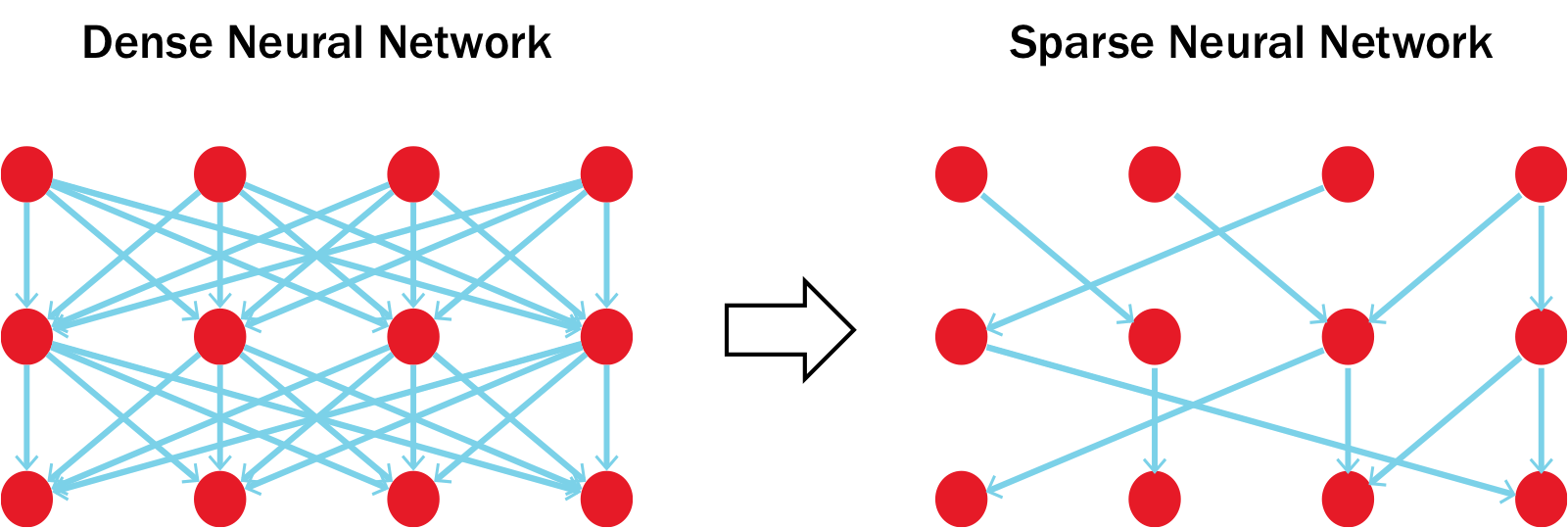
稀疏运算
稀疏神经网络是指神经网络中大部分权重为零的网络。这些零权重在决定神经网络的预测结果时不起作用。稀疏神经网络可以减少内存和计算开销,从而使深度学习模型能够在移动设备上部署。RNN 的推理性能主要受硬件内存带宽的限制,因为大多数工作只是在每个时间步读取参数。从密集计算转向稀疏计算会带来一定的开销,但如果稀疏因子足够大,则稀疏算法所需的数据量较少,反而会带来优势。
数据中心使用的更强大的服务器级处理器通常能够以足够快的速度完成推理,从而服务一位用户,但在数据中心环境中,每美元的性能非常重要。诸如稀疏化等技术能够加快模型的评估速度,从而使得每块 GPU 可以服务更多用户,提高单位成本的性能。
过去几年里,稀疏神经网络的发展取得了很大进展。DeepBench 包含稀疏矩阵向量乘和稀疏矩阵乘核。根据我们的研究,我们了解到,稀疏度达到 90% 至 95% 的神经网络,与对应的密集基线相比,仍能获得相对较好的性能。然而,目前稀疏矩阵乘的实现往往针对更高的稀疏度(约 99% 或更高)进行了优化。通过包含稀疏核,我们希望激励硬件厂商和软件开发者构建能够在 90% 至 95% 稀疏度范围内提供良好性能的库。
我们在 ARM 设备上使用 Eigen 库来基准测试稀疏运算。对于 GPU 基准测试,我们则使用 NVIDIA 的 cuSparse 库。
延迟的测量
许多推理应用都有实时延迟要求。例如,语音交互界面要求语音识别模型在用户可察觉的时间内返回结果。DeepBench 核可以作为起点,用于测量单个操作的最佳情况延迟。然而,鉴于 DeepBench 此次发布侧重于基础操作而非完整应用,测量整个系统的延迟超出了本次范围。例如,在移动设备上运行的完整应用可能需要在启动时调整系统的功耗状态。又如,一个完整的服务器应用可能会有显著的延迟成分,这部分延迟由用户与服务器之间的网络连接决定。我们可能会在 DeepBench 的未来版本中考虑处理操作延迟的问题。
支持的运算与精度
在本节中,我们记录了不同处理器对各种运算在不同精度下的支持情况。在可能的情况下,我们会选择最接近最低要求精度的精度。以下再次列出精度要求。不过,在某些情况下,我们也需要对更高精度的运算进行基准测试。下表展示了各处理器所基准测试的具体运算。
训练的最低精度:16 位乘法,32 位累加
推理的最低精度:8 位乘法,32 位累加
训练
单精度结果适用于 5 款 NVIDIA GPU 和 Intel 的 Xeon Phi 处理器。目前没有可用的处理器支持 16 位乘法和 32 位加法。因此,我们对 NVIDIA 的伪 FP16 模式进行了基准测试,该模式下输入/输出为 16 位,但计算仍以单精度进行。混合精度训练的支持将在未来的硬件处理器中实现。
| 处理器 | 单精度 | FP16 输入/FP32 计算 | FP16 输入 / 混合精度计算 |
|---|---|---|---|
| NVIDIA TitanX Maxwell | GEMM、卷积、RNN | ||
| NVIDIA Tesla M40 | GEMM、卷积、RNN | ||
| NVIDIA 1080Ti | GEMM、卷积、RNN | ||
| NVIDIA TitanX Pascal | GEMM、卷积、RNN | ||
| NVIDIA TitanXp | GEMM、卷积、RNN | ||
| NVIDIA Tesla P100 | GEMM、卷积、RNN | GEMM、卷积、RNN | |
| NVIDIA Tesla V100 | GEMM、卷积、RNN | GEMM、卷积、RNN | |
| Intel Xeon Phi 7250 | GEMM、卷积 |
服务器部署
在 NVIDIA 处理器上,GEMM 和卷积基准测试采用 8 位乘法和 32 位累加的方式进行。然而,NVIDIA GPU 并不支持该精度模式下的所有输入尺寸。在这种精度模式下,输入尺寸必须是 4 的倍数。为此,我们已将所有核的输入维度填充为 4 的倍数。与运算本身的开销相比,填充和丢弃多余输出的成本微不足道。结果表格中标明了哪些核需要填充。稀疏运算和循环核的结果以单精度报告,因为相关库尚不支持低精度。
| 处理器 | 单精度 | Int8 乘法/32 位累加 |
|---|---|---|
| NVIDIA 1080Ti | RNN、稀疏 GEMM | GEMM、卷积 |
| NVIDIA TitanX Pascal | RNN、稀疏 GEMM | GEMM、卷积 |
| NVIDIA TitanXp | RNN、稀疏 GEMM | GEMM、卷积 |
设备部署
下表描述了不同处理器、运算和精度下可用的推理设备核结果。我们没有 RNN 的结果,因为没有任何 ARM 库支持 RNN。ARM Compute 库目前尚未在 iPhone 上得到支持。
| 处理器 | 单精度 | Int8 输入/32 位计算 |
|---|---|---|
| Raspberry Pi 3 | 卷积 | GEMM、稀疏 GEMM |
| iPhone 6 | GEMM、稀疏 GEMM | |
| iPhone 7 | GEMM、稀疏 GEMM |
结果
在这一部分,我们记录了几种操作的性能表现。这些结果是随机选取的,仅用于展示几种应用的性能。
以下结果仅包含特定操作和参数下最快处理器的时间和 TeraFLOPS 值。完整结果可在 results 文件夹中找到。
用于基准测试训练和推理处理器的精度列于结果文件的顶部。
训练结果位于 results/training 文件夹中,包含以下文件:
DeepBench_IA_KNL7250.xlsx:英特尔至强融核处理器上的训练结果DeepBench_NV_TitanX.xlsx:英伟达 TitanX 显卡上的训练结果DeepBench_NV_M40.xlsx:英伟达 M40 显卡上的训练结果DeepBench_NV_TitanX_Pascal.xlsx:英伟达 TitanX Pascal 显卡上的训练结果DeepBench_NV_TitanXp.xlsx:英伟达 TitanXp Pascal 显卡上的训练结果DeepBench_NV_1080Ti.xlxs:英伟达 1080 Ti 显卡上的训练结果DeepBench_NV_P100.xlsx:英伟达 P100 显卡上的训练结果DeepBench_NV_V100.xlsx:英伟达 V100 显卡上的训练结果
详细的推理结果位于 results/inference 文件夹中,包含以下文件:
server/DeepBench_NV_TitanXp.xlsx:英伟达 TitanXp 显卡上的推理结果server/DeepBench_NV_TitanXp.xlsx:英伟达 TitanXp Pascal 显卡上的推理结果server/DeepBench_NV_1080Ti.xlxs:英伟达 1080 Ti 显卡上的推理结果device/DeepBench_iPhone_7.xlsx:iPhone 7 上的推理结果device/DeepBench_iPhone_6.xlsx:iPhone 6 上的推理结果device/DeepBench_Raspberry_Pi_3.xlsx:树莓派 3 上的推理结果
用于基准测试性能的软件库(如 cuDNN、OpenMPI)在每个 Excel 工作簿的 Specs 表中均有提及。
如有任何疑问,请随时向我们咨询。
更多硬件平台的结果将在可用时陆续添加。我们欢迎所有硬件厂商的贡献。
训练结果
GEMM 结果
| 内核 | A 转置 | B 转置 | 应用 | 时间 (ms) | TeraFLOPS | 处理器 |
|---|---|---|---|---|---|---|
| M=1760, N=128, K=1760 | 否 | 否 | 语音识别 | 0.07 | 10.72 | Tesla V100 混合精度 |
| M=7860, N=64, K=2560 | 否 | 否 | 语音识别 | 0.10 | 25.94 | Tesla V100 混合精度 |
| M=2560, N=64, K=2560 | 否 | 否 | 语音识别 | 0.08 | 10.11 | Tesla V100 混合精度 |
| M=5124, N=9124, K=2560 | 是 | 否 | 语音识别 | 8.73 | 27.43 | Tesla V100 混合精度 |
| M=3072, N=128, K=1024 | 是 | 否 | 语音识别 | 0.04 | 18.73 | Tesla V100 混合精度 |
卷积结果
| 输入大小 | 滤波器大小 | 滤波器数量 | 填充 (h, w) | 步幅 (h, w) | 应用 | 总时间 (ms) | Fwd TeraFLOPS | 处理器 |
|---|---|---|---|---|---|---|---|---|
| W = 700, H = 161, C = 1, N = 32 | R = 5, S = 20 | 32 | 0, 0 | 2, 2 | 语音识别 | 1.53 | 7.75 | Tesla V100 FP32 |
| W = 54, H = 54, C = 64, N = 8 | R = 3, S = 3 | 64 | 1, 1 | 1, 1 | 人脸识别 | 0.55 | 10.12 | Tesla V100 FP32 |
| W = 224, H = 224, C = 3, N = 16 | R = 3, S = 3 | 64 | 1, 1 | 1, 1 | 计算机视觉 | 2.40 | 1.40 | Tesla V100 FP32 |
| W = 7, H = 7, C = 512, N = 16 | R = 3, S = 3 | 512 | 1, 1 | 1, 1 | 计算机视觉 | 0.70 | 14.56 | Tesla V100 混合精度 |
| W = 28, H = 28, C = 192, N = 16 | R = 5, S = 5 | 32 | 2, 2 | 1, 1 | 计算机视觉 | 0.93 | 16.90 | Tesla V100 FP32 |
循环运算结果
循环运算内核仅在英伟达硬件上运行。
| 隐藏单元数 | 批量大小 | 时间步数 | 循环类型 | 应用 | 总时间 (ms) | Fwd TeraFLOPS | 处理器 |
|---|---|---|---|---|---|---|---|
| 1760 | 16 | 50 | Vanilla | 语音识别 | 8.21 | 1.19 | Tesla V100 混合精度 |
| 2560 | 32 | 50 | Vanilla | 语音识别 | 10.50 | 4.08 | Tesla V100 混合精度 |
| 1024 | 128 | 25 | LSTM | 机器翻译 | 5.56 | 10.91 | Tesla V100 混合精度 |
| 2816 | 32 | 1500 | GRU | 语音识别 | 380.04 | 11.85 | Tesla V100 混合精度 |
全归约结果
| 大小 (# of floats) | 处理器数量 | 应用 | 时间 (ms) | 带宽 (GB/s) | 处理器 |
|---|---|---|---|---|---|
| 16777216 | 8 | 语音识别 | 8.66 | 61.99 | 至强融核 7250 配备 Intel® Omni-Path |
| 16777216 | 16 | 语音识别 | 14.72 | 72.94 | 至强融核 7250 配备 Intel® Omni-Path |
| 16777216 | 32 | 语音识别 | 19 | 113.03 | 至强融核 7250 配备 Intel® Omni-Path |
| 64500000 | 32 | 语音识别 | 76.68 | 107.67 | 至强融核 7250 配备 Intel® Omni-Path |
推理服务器结果
接下来的部分提供了服务器平台上 GEMM、卷积和循环运算的推理内核的一些结果。英特尔平台的结果将很快公布。
GEMM 结果
| 内核 | 应用 | 结果 (ms) | TeraFLOPS | 处理器 |
|---|---|---|---|---|
| M=5124, N=700, K=2048 | 语音识别 | 0.46 | 31.94 | 1080 Ti |
| M=35, N=700, K=2048 | 语音识别 | 0.05 | 2.09 | 1080 Ti |
| M=3072, N=3000, K=1024 | 语音识别 | 0.49 | 38.36 | Titan Xp |
| M=512, N=6000, K=2816 | 语音识别 | 0.43 | 40.71 | Titan Xp |
稀疏 GEMM 结果
| 内核 | 稀疏度 | 应用 | 结果 (ms) | 相对于密集的加速比 | TeraFLOPS | 处理器 |
|---|---|---|---|---|---|---|
| M=7680, N=1, K=2560 | 0.95 | 语音识别 | 0.03 | 6.56 | 1.10 | 1080 Ti |
| M=7680, N=2, K=2560 | 0.95 | 语音识别 | 0.04 | 5.93 | 1.74 | 1080 Ti |
| M=7680, N=1500, K=2560 | 0.95 | 语音识别 | 29.81 | 0.16 | 1.88 | TitanXp |
| M=10752, N=1, K=3584 | 0.9 | 语音识别 | 0.1 | 4 | 0.72 | TitanXp |
卷积结果
| 输入大小 | 滤波器大小 | 滤波器数量 | 填充 (h, w) | 步幅 (h, w) | 应用 | 时间 (ms) | TeraFLOPS | 处理器 |
|---|---|---|---|---|---|---|---|---|
| W = 341, H = 79, C = 32, N = 4 | R = 5, S = 10 | 32 | 0,0 | 2,2 | 语音识别 | 0.29 | 9.03 | TitanXp |
| W = 224, H = 224, C = 3, N = 1 | R = 7, S = 7 | 64 | 3, 3 | 2, 2 | 计算机视觉 | 0.14 | 1.64 | TitanXp |
| W = 56, H = 56, C = 256, N = 1 | R = 1, S = 1 | 128 | 0, 0 | 2, 2 | 计算机视觉 | 0.015 | 3.43 | TitanX Pascal |
| W = 7, H = 7, C = 512, N = 2 | R = 1, S = 1 | 2048 | 0, 0 | 1, 1 | 计算机视觉 | 0.018 | 11.42 | 1080 Ti |
RNN 结果
| 隐藏单元数 | 批量大小 | 时间步长 | 循环类型 | 应用 | 结果 (ms) | Fwd TeraFLOPS | 处理器 |
|---|---|---|---|---|---|---|---|
| 1536 | 4 | 50 | LSTM | 语言建模 | 6.93 | 0.55 | TitanXp |
| 256 | 4 | 150 | LSTM | 字符语言建模 | 1.63 | 0.19 | 1080 Ti |
| 2816 | 1 | 1500 | GRU | 语音识别 | 350.62 | 0.20 | TitanXp |
| 2560 | 2 | 375 | GRU | 语音识别 | 75.02 | 0.39 | TitanXp |
推理设备结果
GEMM 结果
| 内核 | 应用 | 结果 (ms) | GigaFLOPS | 处理器 |
|---|---|---|---|---|
| M=5124, N=700, K=2048 | 语音识别 | 212.84 | 69.03 | iPhone 7 |
| M=35, N=700, K=2048 | 语音识别 | 1.94 | 51.69 | iPhone 7 |
| M=3072, N=1500, K=1024 | 语音识别 | 136.63 | 69.07 | iPhone 7 |
稀疏 GEMM 结果
| 内核 | 稀疏度 | 应用 | 结果 (ms) | 相对于密集的加速比 | GigaFLOPS | 处理器 |
|---|---|---|---|---|---|---|
| M=7680, N=1, K=2560 | 0.95 | 语音识别 | 1.01 | 15.55 | 18.55 | iPhone 7 |
| M=7680, N=1500, K=2560 | 0.95 | 语音识别 | 1677.36 | 5.46 | 16.70 | iPhone 7 |
| M=7680, N=1, K=2560 | 0.9 | 语音识别 | 2.1 | 8.02 | 8.41 | iPhone 7 |
卷积结果
| 输入大小 | 滤波器大小 | 滤波器数量 | 填充 (h, w) | 步幅 (h, w) | 应用 | 时间 (ms) | GigaFLOPS | 处理器 |
|---|---|---|---|---|---|---|---|---|
| W = 112, H = 112, C = 64, N = 1 | R = 1, S = 1 | 64 | 0, 0 | 1, 1 | 计算机视觉 | 670.75 | 0.15 | Raspberry Pi 3 |
| W = 56, H = 56, C = 256, N = 1 | R = 1, S = 1 | 128 | 0, 0 | 2, 2 | 计算机视觉 | 185.87 | 0.28 | Raspberry Pi 3 |
| W = 7, H = 7, C = 512, N = 1 | R = 1, S = 1 | 2048 | 0, 0 | 1, 1 | 计算机视觉 | 735.28 | 0.14 | Raspberry Pi 3 |
参与进来
我们欢迎社区为 DeepBench 做出贡献。您可以通过两种方式参与:
- 深度学习研究人员/工程师:如果您是从事新型深度学习应用的研究人员或工程师,您的模型训练可能涉及不同的操作和/或工作负载。我们希望了解那些对模型性能(速度)产生负面影响的基本操作。请贡献这些操作和工作负载!
- 硬件厂商:我们也非常乐意接受其他硬件厂商的贡献。无论是大型公司还是致力于开发深度学习训练硬件的小型初创企业,我们都欢迎提交基准测试结果。请为您的硬件贡献基准测试结果!
获取代码
要获取代码,只需克隆 GitHub 仓库:
git clone https://github.com/baidu-research/DeepBench
NVIDIA 基准测试
编译
为了构建基准测试,您需要指定以下路径:
MPI_PATH:MPI 库的路径。这些基准测试已在 OpenMPI 1.10.2 版本上进行过测试。
CUDA_PATH:CUDA 库的路径。这些基准测试已在 7.5.18 版本上进行过测试。
CUDNN_PATH:cuDNN 库的路径。这些基准测试已在 5.0 版本上进行过测试。
NCCL_PATH:NCCL 库的路径。NCCL 库可在 https://github.com/NVIDIA/nccl 上获取。这些基准测试已在 commit b3a9e1333d9e2e1b8553b5843ba1ba4f7c79739d 上进行过测试。
要构建所有基准测试,请使用以下命令:
cd code/
make CUDA_PATH=<cuda_path> CUDNN_PATH=<cudnn_path> MPI_PATH=<mpi_path> NCCL_PATH=<nccl_path>
对于将 MPI 头文件和库文件分开存储的发行版(例如 RHEL、Fedora、CentOS),您还应指定包含文件的路径:
MPI_INCLUDE_PATH=<mpi_include_path>
您需要为适当的架构编译代码。默认情况下,架构版本设置为 5.2,这适用于 TitanX 和 Tesla M40 GPU。若要为其他架构(如 Pascal 架构,版本为 6.1)编译基准测试,请在 make 命令中添加以下变量:
ARCH=sm_61 ## Pascal 架构的示例
在某些情况下,为多个架构生成基准测试可执行文件可能会很有用。例如,某些系统可能安装了具有不同架构的多个图形处理器。NVIDIA 编译器 (nvcc) 支持生成“胖二进制文件”,其中包含针对多个目标架构的中间代码和已编译代码。要为多个架构编译,请在 make 命令行中添加一个以逗号分隔的架构列表。
ARCH=sm_30,sm_32,sm_35,sm_50,sm_52,sm_60,sm_61,sm_62,sm_70 # Kepler 以来的所有架构!
请注意,为多个架构编译所需的时间会比为单个架构编译更长。此外,并非所有 CUDA 版本都支持所有架构。例如,对 sm_60(及更高版本)的支持需要 CUDA 8 或更高版本。
对于采用 int8 精度的推理问题,卷积和 GEMM 内核需要填充到 4 的倍数。默认情况下,内核会被填充,并且结果也会以填充后的形式报告。若要禁用填充,请使用以下编译选项。当填充被禁用时,对于不支持的内核,基准测试结果将不会被报告。
make gemm PAD_KERNELS=0
make conv PAD_KERNELS=0
要在 NVIDIA V100 处理器上使用 Tensor Cores,您需要使用 CUDA 9.0 和 cuDNN 7.0 或更高版本。在使用正确的库的情况下,将以下选项添加到 make 命令中:
make USE_TENSOR_CORES=1 ARCH=sm_70
运行 Tensor Cores 的卷积操作要求输入和输出通道数必须是 8 的倍数。目前,基准测试会将输入通道数填充到 8 的倍数,并报告填充后的数值。
运行基准测试
编译成功完成后,可执行文件将在 bin 目录中生成。在运行基准测试之前,正确设置 LD_LIBRARY_PATH 非常重要。对于 bash shell,请使用:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<cuda_path>:<cudnn_path>:<mpi_path>:<nccl_path>
GEMM、卷积、循环运算和稀疏 GEMM 基准测试可以通过调用相应的可执行文件来运行。以下是 GEMM 基准测试的部分输出:
~/DeepBench/code$ bin/gemm_bench
Running training benchmark
Times
----------------------------------------------------------------------------------------
m n k a_t b_t precision time (usec)
1760 16 1760 0 0 float 180
1760 32 1760 0 0 float 182
1760 64 1760 0 0 float 247
1760 128 1760 0 0 float 318
默认情况下,基准测试是针对训练问题运行的。基准测试的默认精度取决于 CUDA 和 cuDNN 库的版本。模式(推理或训练)和精度可以在命令行中通过以下方式指定:
bin/gemm_bench <inference|train> <int8|float|half>
每个基准测试文件都包含注释,说明不同 GPU 支持哪些精度。
要运行 NCCL 单节点 All-Reduce 基准测试,您需要将 GPU 数量作为参数指定。请注意,GPU 数量不得超过系统中可见的 GPU 数量。
bin/nccl_single_all_reduce <num_gpus>
NCCL MPI All-Reduce 基准测试可以使用 mpirun 运行,如下所示:
mpirun -np <num_ranks> bin/nccl_mpi_all_reduce
num_ranks 不能超过系统中的 GPU 数量。
osu_allreduce 基准测试也可以使用 mpirun 运行,如下所示:
mpirun -np <num_processes> bin/osu_allreduce
osu_allreduce 基准测试可以使用多于 GPU 数量的进程运行。然而,我们所有的实验都是在每个进程运行在一个单独 GPU 上的情况下进行的。
百度基准测试
编译
为了构建基准测试,您需要指定以下路径:
MPI_PATH:MPI 库的路径。这些基准测试已在 OpenMPI 2.0.1 版本上进行过测试。
CUDA_PATH:CUDA 库的路径。这些基准测试已在 8.0.61 版本上进行过测试。
BAIDU_ALLREDUCE_PATH:百度 All-Reduce 实现的路径,可在 https://github.com/baidu-research/baidu-allreduce/ 获取。
要构建所有基准测试,请使用以下命令:
cd code/
make CUDA_PATH=<cuda_path> MPI_PATH=<mpi_path> BAIDU_ALLREDUCE_PATH=<baidu_allreduce_path>
对于将 MPI 头文件和库文件分开存储的发行版(例如 RHEL、Fedora、CentOS),您还应指定包含文件的路径:
MPI_INCLUDE_PATH=<mpi_include_path>
请按照上述 NVIDIA 基准测试部分所述,为适当的架构设置 ARCH 参数。
运行基准测试
编译成功完成后,可执行文件将在 bin 目录中生成。在运行基准测试之前,正确设置 LD_LIBRARY_PATH 非常重要。对于 bash shell,请使用:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<cuda_path>:<mpi_path>:<baidu_allreduce_path>
百度 All-Reduce 基准测试可以使用 mpirun 运行,如下所示:
mpirun -np <num_ranks> bin/ring_all_reduce
num_ranks 用于表示系统中 GPU 的总数。
英特尔基准测试
编译和运行基准测试
将所有 Intel 工具(icc、mkl、mpi)的路径添加到环境变量中:
source <icc_installdir>/bin/compilervars.sh intel64
source <mkl_installdir>/bin/mklvars.sh intel64
source <impi_installdir>/bin/mpivars.sh intel64
source <mlsl_installdir>/intel64/bin/mlslvars.sh
运行 Intel GEMM 基准测试(MKL 2017):
code/intel/sgemm/run_mkl_sgemm_ia.sh
运行 Intel 卷积基准测试(MKL 2017 和 libxsmm,一个开源的 KNL 优化卷积实现):
code/intel/convolution/run_conv_ia.sh
Intel All-Reduce 基准测试使用标准的 OSU 基准测试程序,该程序通过 Intel MPI 或 Intel MLSL 进行编译和运行。
为了构建 Intel All-Reduce 基准测试,您需要指定以下路径:
MPI_PATH:Intel MPI 库的路径(默认为 $I_MPI_ROOT)。这些基准测试已在 Intel MPI 2017 Update 3 上进行过测试。
MLSL_PATH:Intel MLSL 库的路径(默认为 $MLSL_ROOT)。这些基准测试已在 Intel MLSL 2017 Update 2 Preview 上进行过测试。
并使用 Makefile_ia 构建文件。
例如(使用默认路径进行构建):
make -f Makefile_ia all
运行 Intel All-Reduce 基准测试:
code/osu_allreduce/run_allreduce_ia.sh <hostfile> <allreduce_binary>
- osu_allreduce:基于 MPI 的阻塞式 All-Reduce 基准测试
- mlsl_osu_allreduce:基于 MLSL 的阻塞式 All-Reduce 基准测试
基于 MLSL 的阻塞式 All-Reduce 性能会记录在 DeepBench 结果文件中。
例如,要运行基于 MLSL 的 All-Reduce 基准测试,请创建一个每行包含一个主机名的 hostfile,并按如下方式运行脚本:
code/osu_allreduce/run_allreduce_ia.sh <hostfile> mlsl_osu_allreduce
脚本将在不同规模(2、4、8、16、32 个节点)以及 DeepBench 特定的消息大小下运行基准测试。基准测试将报告平均延迟指标。
例如,在 32 个 KNL/OPA 节点上的基准测试输出:
# 大小 平均延迟(ms)
100000 0.31
3097600 3.59
4194304 4.67
6553600 7.17
16777217 16.80
38360000 56.65
64500000 75.77
ARM 基准测试
DeepBench 中的 ARM 基准测试是在 64 位 ARM v8 处理器上编译和运行的。code/arm 文件夹中的 Makefile 仅支持此处理器。如果要对其他处理器进行基准测试,您需要修改 Makefile 以支持它们。
GEMM 基准测试
ARM GEMM 基准测试使用 Gemmlowp 库来实现 int8 内核。该库作为子模块包含在 DeepBench 代码库中。要构建并运行该基准测试,只需执行:
./run_gemm_bench.sh
卷积基准测试
ARM 卷积基准测试使用 ARM Compute Library。要构建该基准测试,您需要指定 ARM 计算库的头文件和库文件路径:
ARM_COMPUTE_INCLUDE_PATH:ARM 计算库的头文件路径
ARM_COMPUTE_LIB_PATH:ARM 计算库的二进制文件路径
构建并运行基准测试时,请使用以下命令:
make conv ARM_COMPUTE_INCLUDE_PATH=<path> ARM_COMPUTE_LIB_PATH=<path>
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<ARM 计算库二进制文件路径>
bin/conv_bench
稀疏 GEMM 基准测试
稀疏 GEMM 基准测试使用 Eigen 库。要构建该基准测试,您需要下载 Eigen 库并指定其路径:
EIGEN_PATH:Eigen 库的路径
编译并运行基准测试时,请使用以下命令:
make sparse EIGEN_PATH=<path>
bin/sparse_bench
AMD 基准测试
先决条件
目前仅启用了 fp32 train 基准测试。
编译
code/amd 中的 Makefile 适用于 AMD gfx900 GPU。如果要对其他代的 GPU 进行基准测试,请相应地修改 Makefile。
在编译或运行之前设置环境变量:
export PATH=PATH_TO_ROCM/bin:$PATH
export CPATH=PATH_TO_MIOPEN/include:$CPATH
export LIBRARY_PATH=PATH_TO_MIOPEN/lib:$LIBRARY_PATH
export LD_LIBRARY_PATH=PATH_TO_MIOPEN/lib:PATH_TO_MIOPENGEMM/lib:$LD_LIBRARY_PATH
要编译卷积、RNN 和 GEMM 基准测试,请运行:
make conv rnn gemm
运行基准测试
成功编译后,可执行文件将生成在 bin 目录中。
要运行卷积基准测试:
bin/conv_bench
要运行 RNN 基准测试:
bin/rnn_bench
要运行 GEMM 基准测试:
bin/gemm_bench
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。