ghostwriter
Ghostwriter 是一款将手写输入与AI生成结合的创意工具,通过reMarkable2平板实现手写内容与视觉大模型(如ChatGPT、Claude、Gemini)的互动。用户在平板上书写后,通过触控触发,AI会根据手写内容生成文本或图像回应,形成手写+屏幕的双向交流。例如用户手写提示,AI可绘制图像,实现“我写提示,AI画图”的创意流程。
该工具解决了传统输入方式的局限性,让手写成为与AI对话的自然媒介。适合需要手写创作的设计师、开发者及研究人员,尤其适合探索人机交互新形式的创意工作者。其技术亮点在于将手写输入与AI生成结合,支持多模型调用,且能通过触控触发实现动态响应。用户可自定义触发区域、启用图像分割等高级功能,同时支持跨平台部署与调试。工具通过Docker和Rust开发,兼顾灵活性与实用性,为手写与AI的融合提供了新可能。
使用场景
一位高中数学老师正在使用 reMarkable2 平板批改学生作业,学生通过手写笔迹提交解题过程。老师希望快速获得作业批改结果并提供个性化反馈。
没有 ghostwriter 时
- 手写批改需要逐题计算得分,遇到复杂解题步骤时容易漏看关键错误
- 遇到模糊解题思路时,需手动查阅教材或在线资源验证解法正确性
- 无法即时生成标准的数学公式标注,手写批注常因字迹潦草影响学生理解
- 批改后需额外整理典型错误案例,耗时整理成电子文档供后续复习
使用 ghostwriter 后
- 在作业末尾画个圈触发 AI 评估,10 秒内自动生成得分和错题定位标注
- 通过
--web-search参数自动联网验证解题方法的通用性,标记非常规解法 - 调用 LaTeX 公式引擎生成标准数学符号批注,覆盖在原始手写笔迹上方
- 批改完成自动生成带标签的 PDF 文件,通过 SSH 直接传输到教学云盘
核心价值:将传统手写批改效率提升 300%,实现智能评分、精准纠错和结构化知识沉淀的三位一体教学辅助。
运行环境要求
- Linux
- macOS
未说明
未说明

快速开始
主要概念
一个在 reMarkable 上运行的实验项目,它会观察你的书写内容,并在通过手势或屏幕内容触发时,向屏幕回写内容。这是对通过手写+屏幕媒介进行交互的探索。


我手写输入提示词,GPT-4o 绘制了这只吉娃娃犬!!!

设置/安装
需要设置 OPENAI_API_KEY(或其他模型对应的密钥)环境变量。我在 reMarkable 的 ~/.bashrc 文件中添加了该变量:
# 在 reMarkable 的 ~/.bashrc 文件中或运行 ghostwriter 前设置密钥
export OPENAI_API_KEY=your-key-here
export ANTHROPIC_API_KEY=your-key-here
export GOOGLE_API_KEY=your-key-here
通过将二进制文件传输到 reMarkable 进行安装。在非 reMarkable 设备(如笔记本电脑)上执行:
# 针对 reMarkable2
wget -O ghostwriter https://github.com/awwaiid/ghostwriter/releases/latest/download/ghostwriter-rm2
# 针对 reMarkable Paper Pro
wget -O ghostwriter https://github.com/awwaiid/ghostwriter/releases/latest/download/ghostwriter-rmpp
# 将IP地址替换为你的 reMarkable IP 地址
scp ghostwriter root@192.168.1.117:
然后需要通过 SSH 登录并运行它。以下是安装和运行方法(在 reMarkable 上执行):
# 首次运行时赋予执行权限
chmod +x ./ghostwriter
./ghostwriter --help # 查看选项并验证是否能正常运行
使用方法
首先需要在 reMarkable 上启动 ghostwriter。通过 SSH 登录后运行:
# 使用默认模型 claude-sonnet-4-0
./ghostwriter
# 使用 gpt-4o-mini 模型
./ghostwriter --model gpt-4o-mini
在屏幕上绘制内容后,用手指轻触右上角触发助手。在 SSH 会话中可以看到触摸检测日志和处理过程。处理时会显示点状进度,最终会显示打字或手绘的响应结果!
CLI 选项
模型与引擎:
--model MODEL- 使用的模型(默认:claude-sonnet-4-0)--engine ENGINE- 引擎:openai, anthropic, google(根据模型自动检测)--engine-api-key KEY- API 密钥(或使用环境变量)--engine-base-url URL- 自定义 API 基础地址
行为控制:
--prompt PROMPT- 使用的提示文件(默认:general.json)--trigger-corner CORNER- 触发区域:UR(右上), UL(左上), LR(右下), LL(左下)(默认:UR)
工具选项:
--no-svg- 禁用 SVG 绘图工具--no-keyboard- 禁用文本输出--thinking- 启用模型思考模式(Anthropic)--web-search- 启用网络搜索(Anthropic)
测试/调试/实验:
--log-level LEVEL- 设置日志级别(info, debug, trace)--no-loop- 执行一次后退出--input-png FILE- 使用 PNG 文件代替截图--output-file FILE- 输出结果保存到文件--save-screenshot FILE- 保存截图--save-bitmap FILE- 保存渲染位图--no-submit- 不提交给模型--no-draw- 不绘制输出--no-trigger- 禁用触摸触发--apply-segmentation- 启用图像分割以实现空间感知
后台运行
在 reMarkable 上使用 nohup 后台运行:
nohup ./ghostwriter --model gpt-4o-mini &
(TODO:研究如何设置开机自启!)
开发指南
我在 Ubuntu 上开发,但也在 OSX 上验证过。基本流程是:(1) 安装依赖,(2) 本地构建但交叉编译 reMarkable 版本,(3) 传输并测试。
- 安装 Docker 用于交叉编译
- 安装 Rust
- 可参考 rustup 安装指南
- 或使用 asdf 管理版本
- apt 或 brew 也可能可用?
- Ubuntu
sudo apt-get install gcc-arm-linux-gnueabihf
- OSX
brew install arm-linux-gnueabihf-binutils
- 配置 cross-rs 和目标平台
- 建议使用 git 最新版本,特别是 OSX 用户
cargo install cross --git https://github.com/cross-rs/crossrustup target add armv7-unknown-linux-gnueabihf aarch64-unknown-linux-gnu
- 构建并传输到 reMarkable
- rm2
cross build --release --target=armv7-unknown-linux-gnueabihfscp target/armv7-unknown-linux-gnueabihf/release/ghostwriter root@remarkable:
- rmpp
cross build --release --target=aarch64-unknown-linux-gnuscp target/aarch64-unknown-linux-gnu/release/ghostwriter root@remarkable:
- rm2
- 我将上述步骤封装到
build.sh中./build.sh构建并传输到 rm2./build.sh rmpp构建并传输到 rmpp
我通常保持一个 SSH 终端连接到 reMarkable,先用 Ctrl-C 停止当前运行的 ghostwriter,然后在主机运行构建脚本,最后在 reMarkable shell 中重新启动程序。
当需要为他人构建发布版本时,我会给 main 分支打标签(如 v2026.09.21-01),这会触发 GitHub Action 自动创建最新发布版本。
状态 / 日志
- 2024-10-06 - 引导(Bootstrapping)
- 基本概念验证已实现!!!
- 屏幕回绘功能效果不佳:它将ChatGPT生成的SVG输出进行光栅化处理,然后尝试绘制大量独立点。reMarkable设备有些崩溃……当整个屏幕变成巨大的黑色方块时,设备会完全卡住无法完成绘制
- 至少成功过的内容:
- 书写"Fill in the answer to this math problem... 3 + 7 ="
- "Draw a picture of a chihuahua. Use simple line-art"
- 2024-10-07 - 循环即灵魂
- 已实现基础的手势和状态显示功能!
- 现在触摸屏幕右上角会出现一个"X"标记。当处理输入时,会继续在X上叠加十字线。不过需要自己手动擦除 :)
- 2024-10-10 - 初始虚拟键盘设置
- 开始学习使用键盘操作reMarkable设备(此前从未尝试过)。发现其功能相当有限...每个页面只有一个大型文本区域,仅支持非常基础的格式
- 需要创建虚拟键盘(通过rM-input-devices实现),已完成基本功能验证!
- 现在想引入一种模式:所有输入都写入文本层,自动区分机器文本和手写内容。不确定这种模式是否实用
- 2024-10-20 - 文本输出和其他模式
- 开始逐步重构代码,使其更规范
- 新增
./ghostwriter text-assist模式,通过虚拟键盘响应!
- 2024-10-21 - 二进制发布构建
- 已配置GitHub Action实现二进制构建
- 2024-10-23 - 代码整理
- 进行了一些重构,将工具函数归类到单独文件
- 昨天Anthropic新发布了3.5-sonnet模型,可能在屏幕空间感知方面表现更好,接下来将在绘图模式中测试
- 接下来计划集成
tools功能,使其能根据上下文返回SVG、文本或触发外部脚本(如TODO列表管理)
- 2024-11-02 - 工具时代
- 开始提供基础工具--draw_text和draw_svg
- 这应该能提升与Anthropic的兼容性?
- 更重要的是,现在只有一个统一助手,它会决定返回键盘文本还是SVG绘图
- 2024-11-07 - Claude!(Anthropic)
- 进行代码重构以隔离API
- ...现已集成Claude/Anthropic!
- 使用几乎相同的工具调用配置,应该可以合并两个模型
- 目前看来更擅长绘图,但空间感知能力仍不理想
- 下一步可能通过图像预处理和结果定位增强空间感知能力。比如检测边界框、分段等,将这些信息输入模型,让模型返回SVG数组及其定位坐标
- 2024-11-22 - 人工评估
- 开始设计评估框架
- 首先添加了输入/输出记录参数
- 然后使用这些参数记录设备上的示例输入输出
- 新增支持在笔记本电脑上运行预捕获输入的ghostwriter(通过
./build.sh local构建) - 接下来将开发针对不同提示词/预处理的迭代工具
- 如果积累足够示例,可能需要构建AI评估系统
- 为此...一个想法是将原始输入与输出叠加显示,通过不同颜色区分评估结果
- 目前该技术对SVG输出效果良好,但本地渲染键盘输出较困难(因为键盘输入渲染由reMarkable应用处理)
- 2024-12-02 - 初始分割器
- 在Claude/copilot帮助下添加了基础图像分割步骤
- 该步骤进行基础分割后将分段坐标提供给视觉大模型(Vision-LLM)参考
- 目前仅与Claude集成,需要合并两个模型
- ...这对在方框中定位X的帮助极大!!
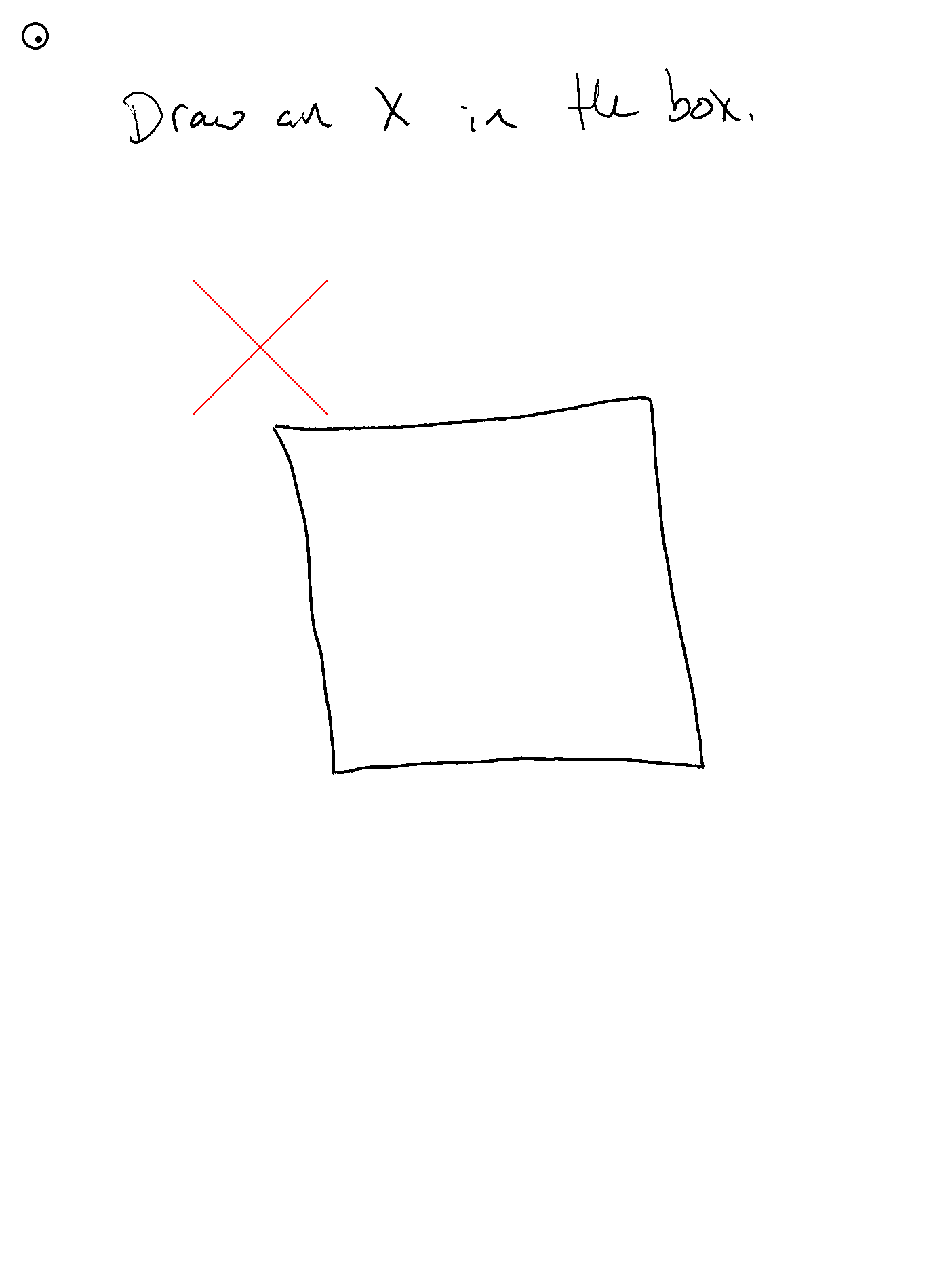
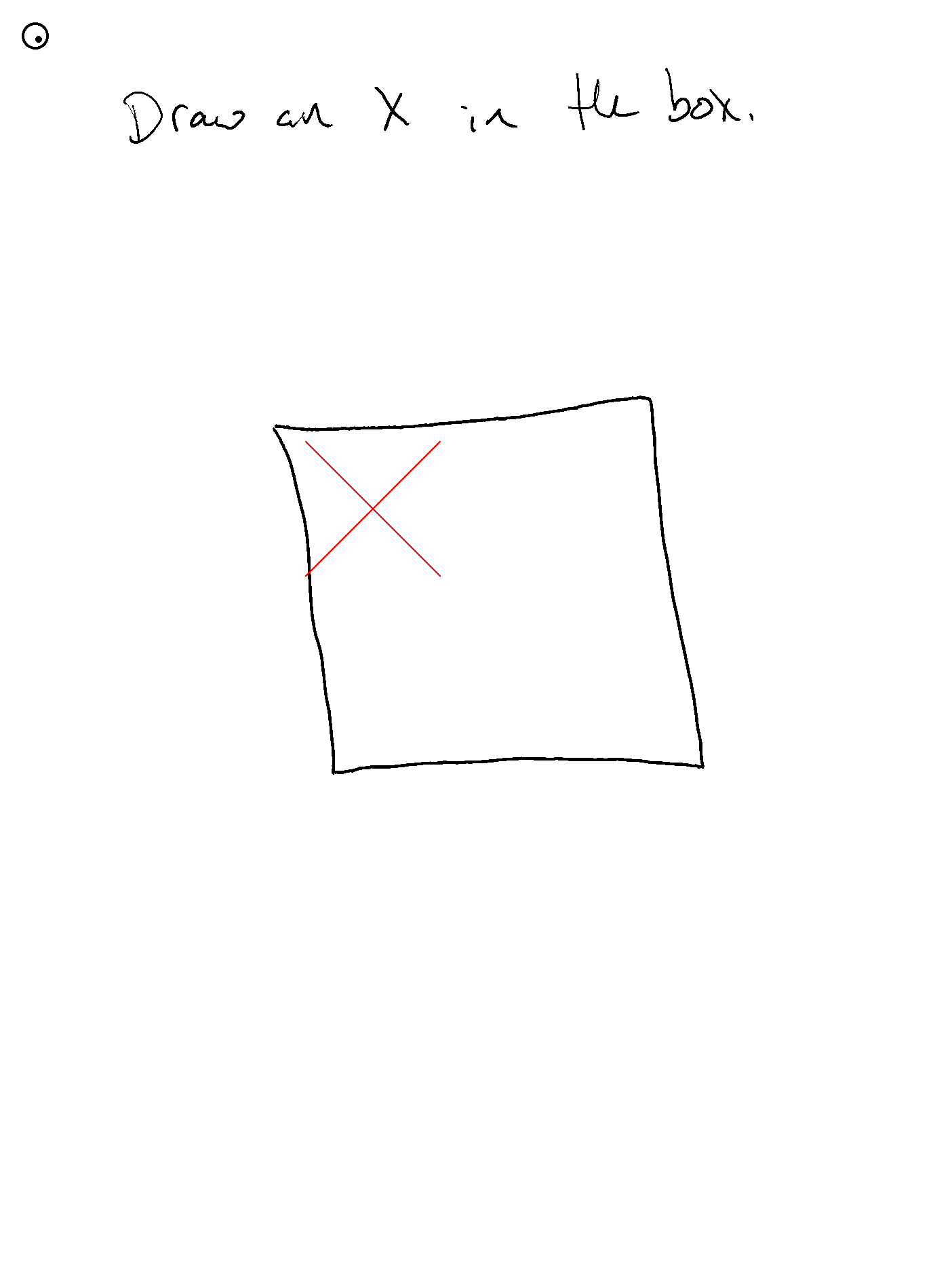
- 需要为评估添加自动化
- 分割器需通过
--apply-segmentation显式启用,并假设使用--input-png或--save-screenshot(因为它会重新解析PNG文件) - 天啊!这是数学题提示首次正确输出答案位置!之前虽然答案正确,但通常用键盘输入
10或放在错误位置。这次终于正确放置了!
- 2024-12-15 - 引擎统一
- 在Claude/copilot和教程帮助下,为OpenAI和Anthropic后端提取出多态引擎层
- 现在可以传递引擎和模型参数
- 其他代码库通常通过模型名映射,可能后续也采用该方式
- 已将提示词和工具定义外部化(到
prompts/目录)并统一处理,每个引擎根据API需求调整 - 理论上
prompts/文件既打包在可执行文件中,又可通过本地目录在运行时覆盖,但尚未充分验证
- 2024-12-18 - 系统升级恐慌
- 我的reMarkable自动升级,通常没问题
- 但升级到3.16.2.3后...截图功能失效!
- 使用codexctl降级。出现可怕的"SystemError: Update failed!"后系统锁死!
- ...但重启后成功降级到3.14.1.9
- 所以...我会持续关注新版本的其他问题报告
- 对了,现在可以把prompts/general.json重命名为
james.json,添加"Your name is James"到提示词。然后复制到reMarkable设备 - 运行
./remarkable --prompt james.json即可使用本地修改的提示词!
- 2024-12-19 -- 非完全本地
- 网友建议增加本地网络视觉大模型模式
- Ollama支持该功能!于是尝试...
- 但llama3.2-vision不支持工具 :(
- Groq的llama-3.2支持!
- ...但它的井字棋表现不佳(虽然是90b模型)。尽管响应速度很快!
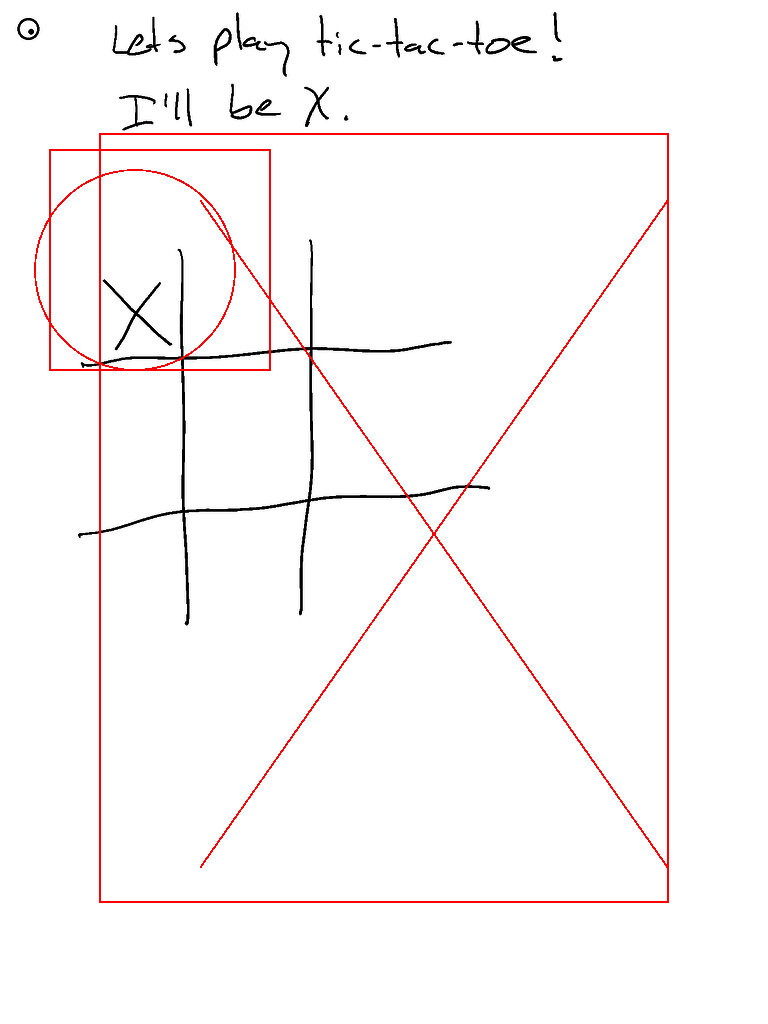
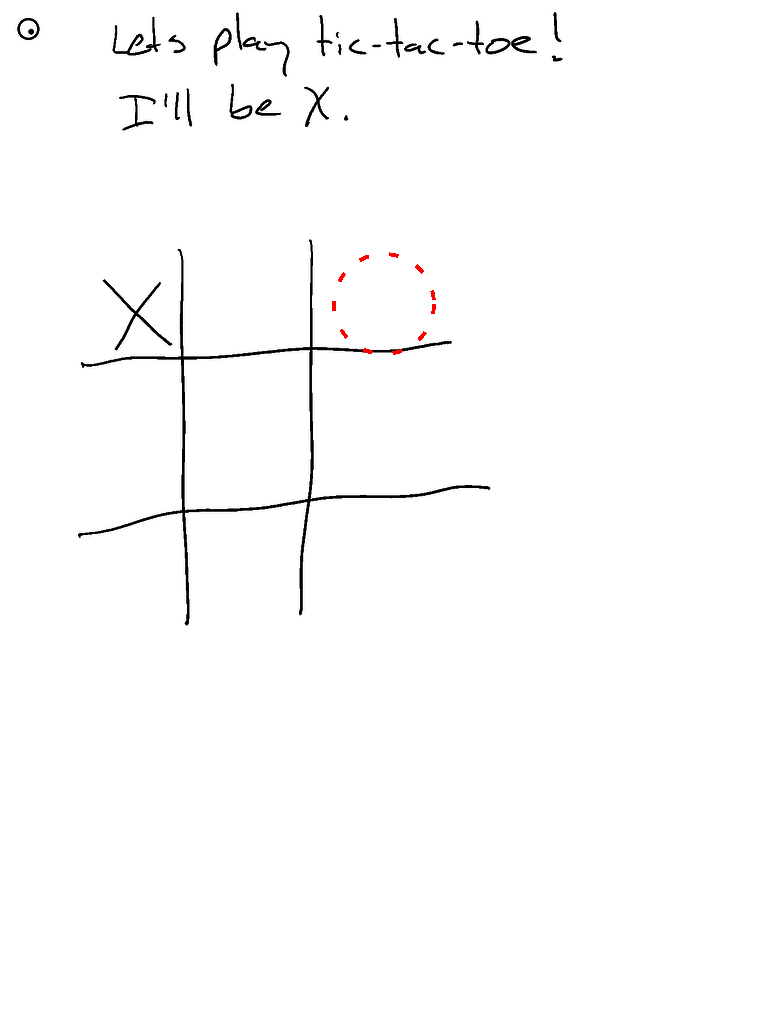
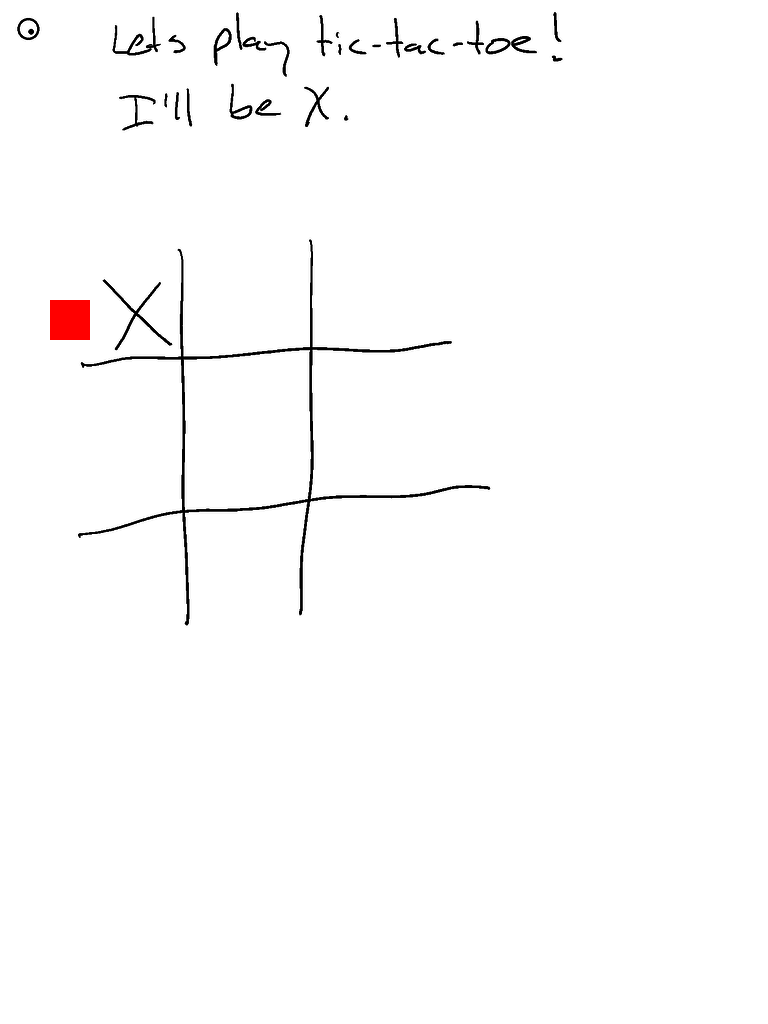
- 啊!忘记启用分割功能。启用后空间感知应该更好...
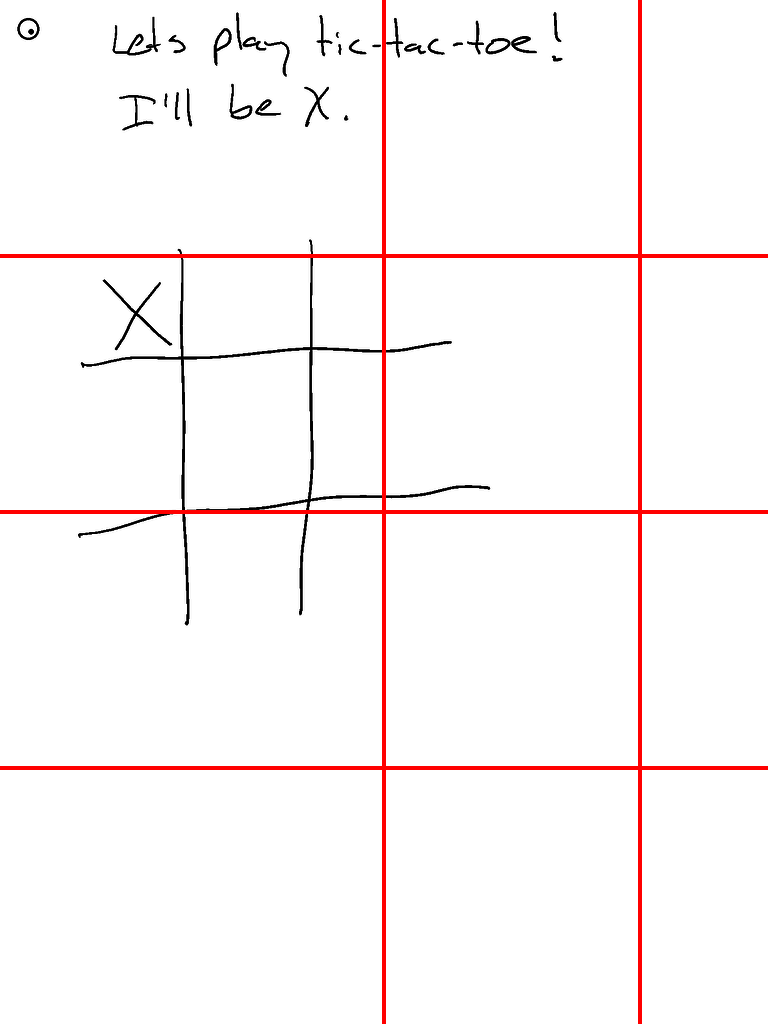
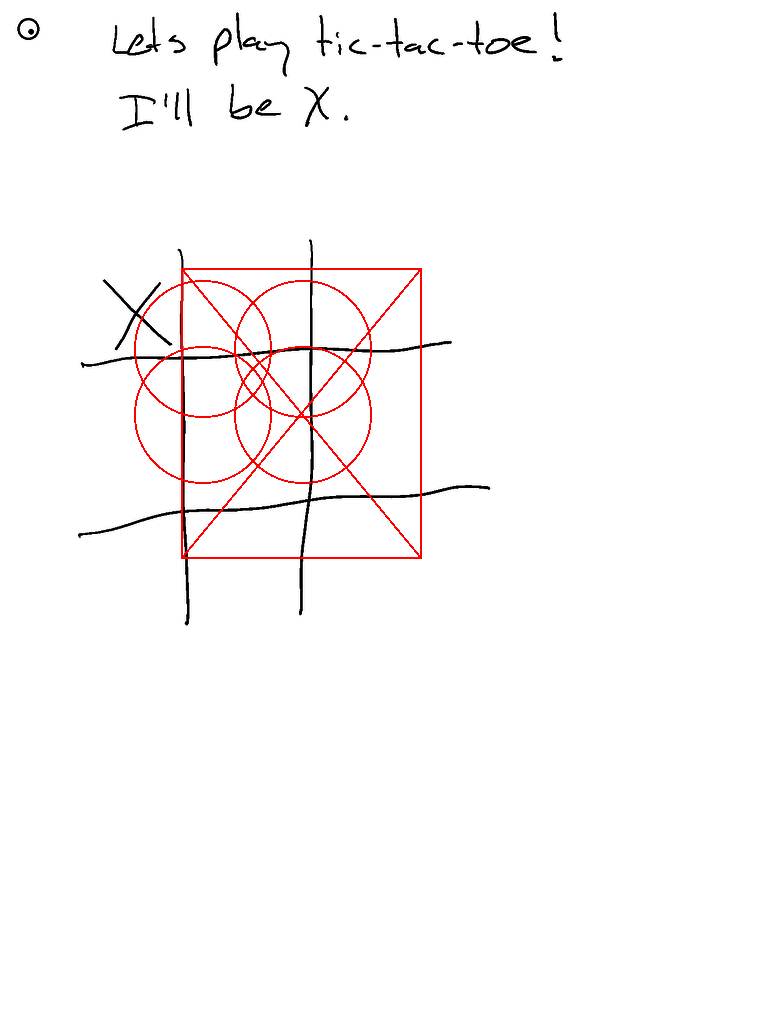
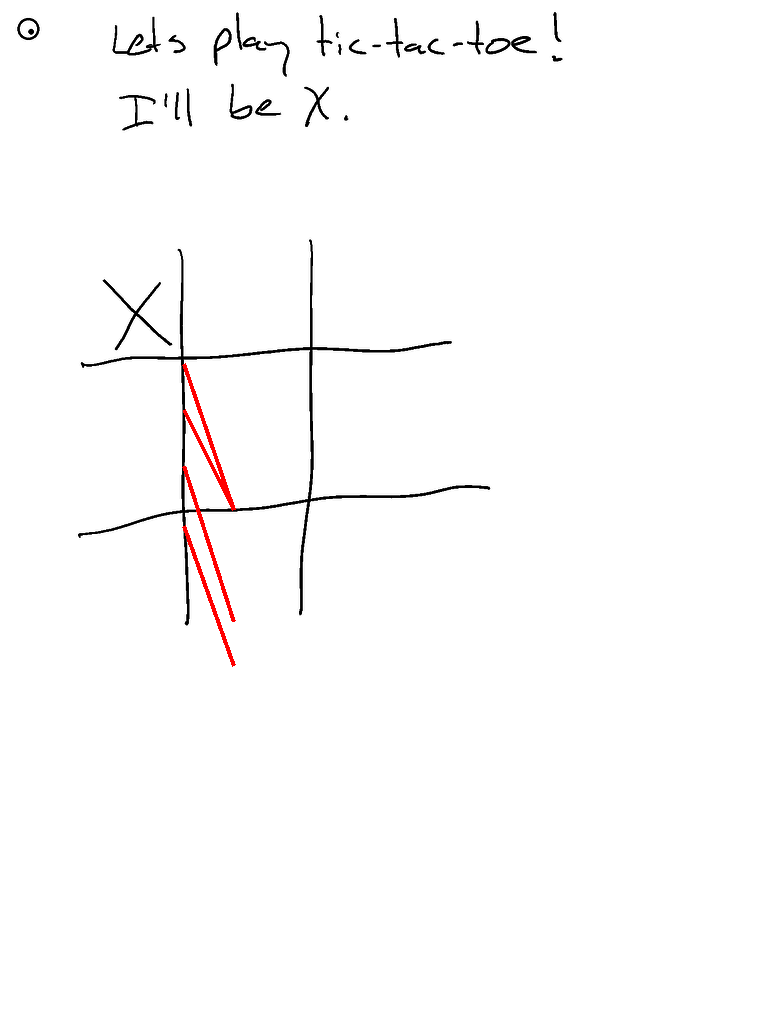
- 这是Claude的三次运行对比
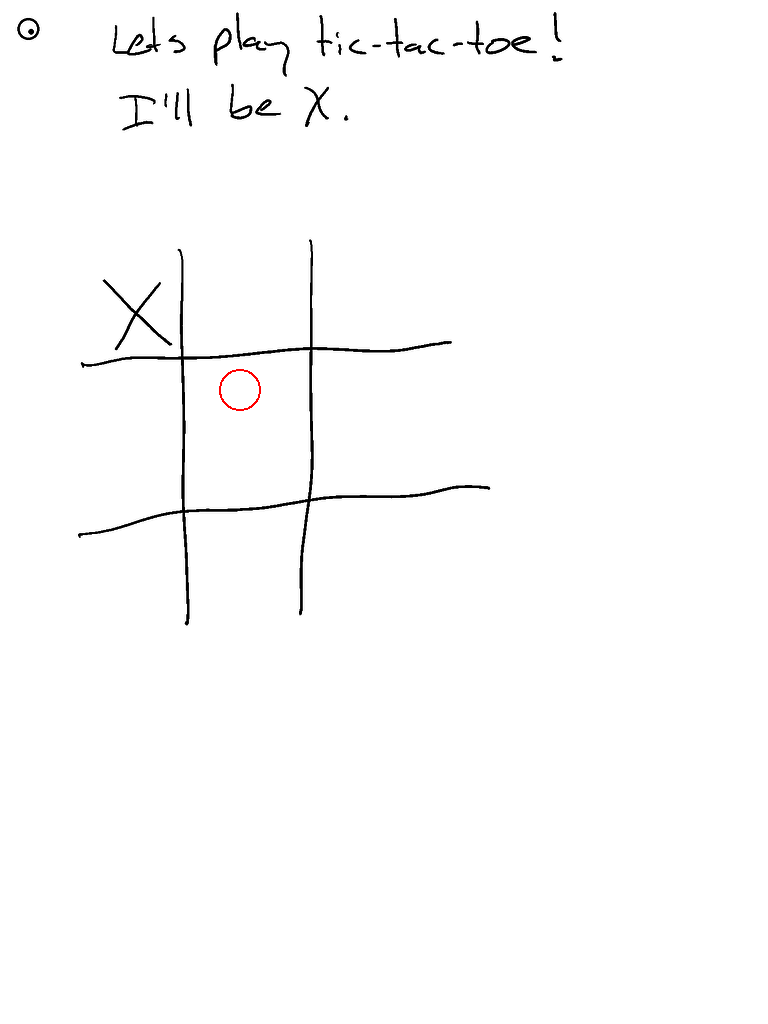
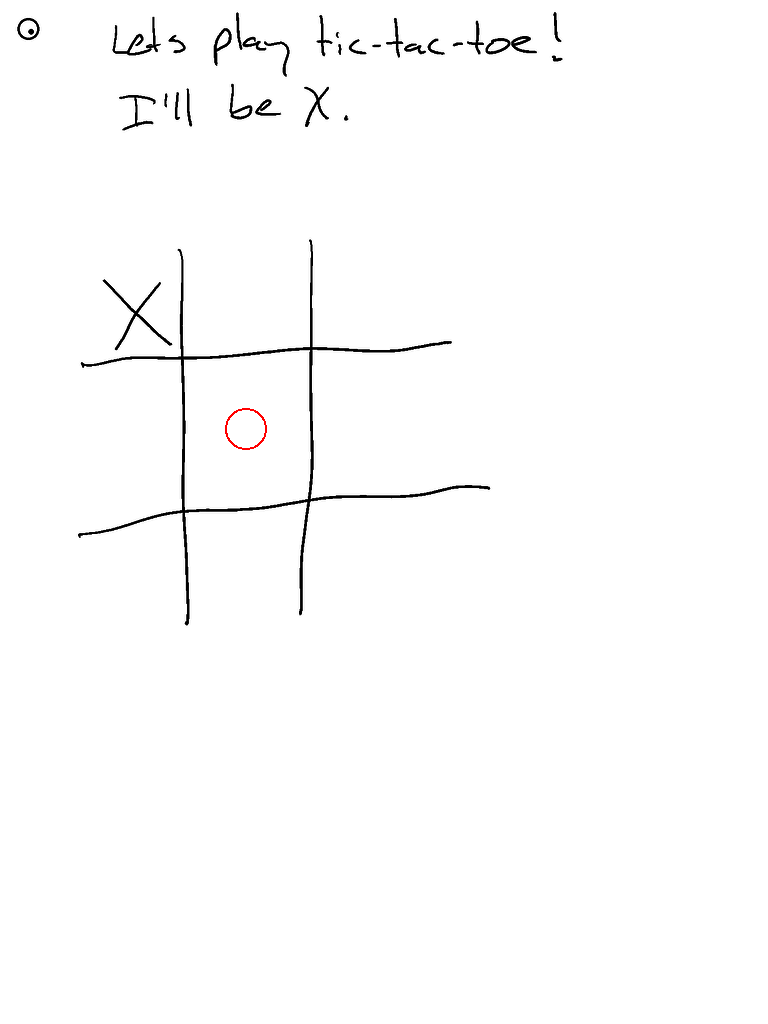
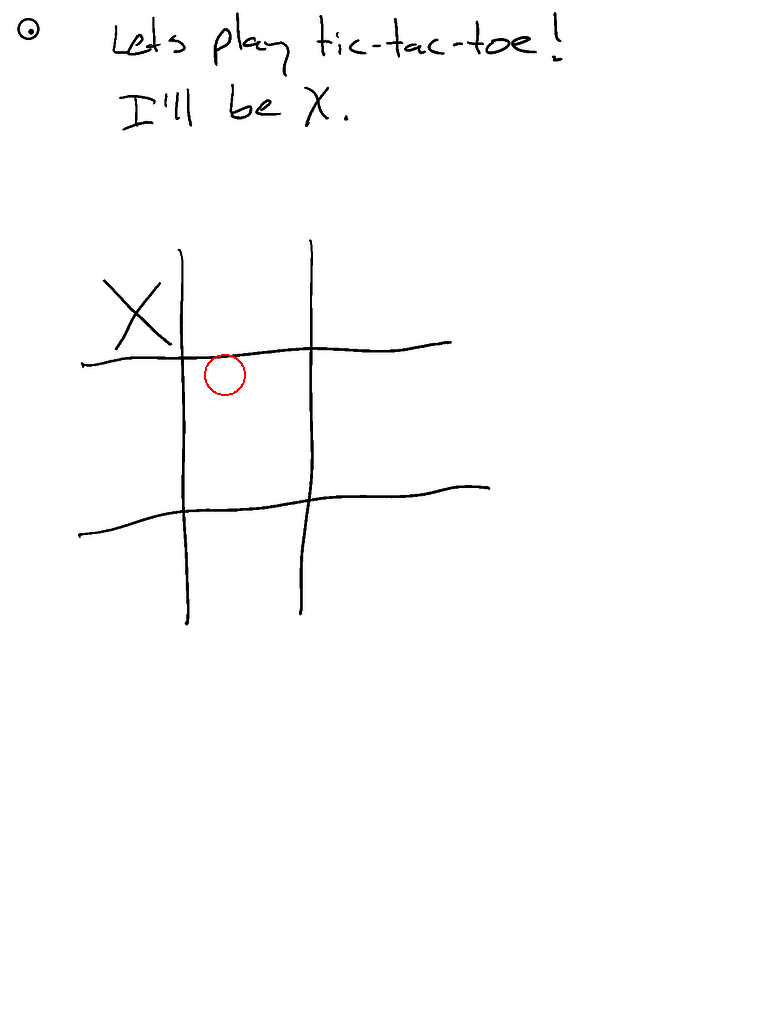
- 新增环境变量
OPENAI_BASE_URL,例如:OPENAI_BASE_URL=https://api.groq.com/openai ./ghostwriter --engine openai --model llama-3.2-90b-vision-preview
- 2024-12-22 -- 开始评估
- 2024-12-25 -- CLI简化与扩展
- 现在只需
-m gpt-4o-mini即可自动识别引擎为openai - 支持传递
--engine-api-key和--engine-url-base - 使用Groq示例:
./ghostwriter -m llama-3.2-90b-vision-preview --engine-api-key $GROQ_API_KEY --engine openai --engine-base-url https://api.groq.com/openai - ...但Llama 3.2 90b视觉模型在此接口表现仍不理想
- 关闭了大量调试信息。需要后续引入日志级别控制
- 彩蛋:现已添加Google Gemini支持!使用
-m gemini-2.0-flash-exp并设置GOOGLE_API_KEY!
- 现在只需
- 2024-12-28 -- 可用性改进
- 使用带电源的USB集线器连接外接键盘,测试键盘快捷键
- 进一步明确了键盘输入的定位逻辑
- 现在在屏幕底部中央发送额外触摸事件,确保下一个键盘输入始终位于最低元素下方。之前会放在最近输入文本下方,若下方有手绘内容会混淆。现在"你最喜欢的颜色?"的答案会整洁地放在更下方!可能还画了个羊的梦?

- 2025-03-03 -- reMarkaple Paper Pro!!!
- 本项目登上hackernews和reddit r/remarkableTablet
- 收到反馈...请求支持reMarkable Paper Pro
- 虽然之前没有该设备
- 但在BestBuy体验后决定购买
- 现在Ghostwriter也支持该设备!
- 屏幕和输入差异是预期中的
- 意外的是设备未包含
uinput内核模块。使用reMarkable官方Linux源码编译并打包 - 现在运行ghostwriter时若未加载uinput模块会自动加载
- 这将是个大麻烦,因为不同Linux版本不兼容,而每次reMarkable更新通常会升级Linux...
- 2025-04-26 -- 更多Paper Pro改进,尝试笔SVG绘图
uinput模块仍未默认编译,但已解决加载问题- 现在包含3.16、3.17、3.18版本模块
- 在分支中尝试使用uSVG和svg2polylines改进SVG绘图体验;当前使用光栅化点绘(stipple)效果不理想且方向错误
- 2025-05-10 -- Anthropic
thinking和web_search!- 添加Anthropic的思考过程和思考tokens功能!
- 支持显示思考过程的新响应格式,但不发送到屏幕
- 同时添加Anthropic的网页搜索功能(服务器端实现)!
- 默认未启用,可通过
./ghostwriter --thinking --web-search开启
- 2025-05-17 -- 修复rm2
- 感谢YOUSY0US3F修复rm2屏幕捕获问题!
- 2025-09-21 -- 修复rmpp,代码格式化,新增功能
- 间隔一段时间后更新,发现一些异常响应。调试内部对话发现截图异常
- 原来3.20版本更改了屏幕分辨率?goRemarkableStream的PR描述了该问题,修复简单
- 应用户请求添加
--no-svg完全禁用SVG工具(也可通过自定义提示词实现) - 考虑到自定义提示词设置繁琐,正在构思Web界面管理API密钥、提示词和调试功能
- 上次开发是在使用claude-code之前。现在让它协助开发
- 新增
--trigger-corner LR(及其他)设置激活角落参数
设想
- [已完成] Matt向我展示了他刚推出的iOS超级计算器,可以从中获取灵感!
- 这个功能已经初步可用,尝试编写一个公式看看
- [已完成] 通过手势或特定内容触发请求
- 比如在特定位置画一个X
- 或者画一个悬浮圆圈——不一定要实际触摸事件
- [已完成] 截取屏幕截图,将其输入视觉模型,获取输出结果,并以某种方式将结果重新呈现在屏幕上
- [已完成] 就像实际书写一样;或者干脆让它快速在屏幕上画满点
- [已完成] 更棒的是...我们还可以发送键盘事件!这意味着我们可以使用Remarkable的文本区域。这是一个笨拙的文本区域,与绘图层不在同一个层级
- 所以我们可以认为:绘图=人类,文本=机器
- 删除操作也会更简单...
- [已完成] 基础评估
- 创建一组输入用的截图
- 代表不同的使用场景
- 其中一些(如TODO提取)可能对输出有特定预期,但大多数没有
- 运行系统获取示例输出——文本、SVG、操作指令
- 编写测试套件评估结果...可能需要人工参与?或者使用视觉-LLM评估器?
- [进行中] 提示词库
- 已在 prompts/ 开始构建
- 目标是提供一组可配置的工具(可能是实际的LLM"工具")
- 也可以添加其他内容...比如作为工具运行的外部命令
- 示例:一个擅长管理待办事项的提示词。它会查找"todo",提取后运行
add-todo.sh脚本- (该脚本会通过ssh将任务添加到taskwarrior)
- 初始配置
- 首次运行(或带参数时)创建配置文件
- 可提示输入OpenAI密钥并写入文件
- 可能需要自动启动、自动恢复功能?
- 生成图表
- 支持输出plantuml和/或mermaid格式,然后转换为SVG/png并显示
- 外部交互
- 允许联网查询
- 允许发送邮件、Slack消息给我
- 对话模式
- 在单个屏幕中跟踪每次交互的版本变化
- 首次发送是原始屏幕
- 第二次发送包含原始屏幕、响应屏幕(可能用红色显示Claude输出)、新添加内容(可能绿色?)
- 这可以形成完整的页面对话链
- 可能需要两个按钮触发视觉-LLM:一个"新提示",一个"继续"
- 或者每次显示最近三次交互:
- 黑色:原始内容
- 红色:Claude响应
- 绿色:新输入
- 或者使用相同颜色结构但显示完整消息链?
- 切换到新空白页时可能显示异常,看起来像新输入擦除了所有内容
- 这种方式可能更便于处理滚动
- 可能需要两种触发方式——延续触发和全新开始触发
- 使用本地网络的视觉-LLM(如ollama)
- 首次尝试使用兼容OpenAI API的ollama失败;ollama的LLAMA 3.2视觉模型不支持工具
- Groq的改进版llama-3.2-vision支持工具...但效果不如ChatGPT、Claude或Gemini
- 支持中断的流式LLM服务
- 使用异步处理加快反馈速度并实现并行处理
- 测试OpenAI新推出的responses API
- 尝试集成MCP(模型上下文协议)
- 可能需要云托管代理?
- 允许非工具响应被忽略,或转换为常规文本的键盘(draw_text)工具
- 集成Web界面用于配置管理与调试
参考资源
- 主要资源来自 Awesome reMarkable
- 屏幕截图功能改编自 reSnap
- 屏幕绘制技术参考了 rmkit lamp
- 使用 resvg 实现SVG转PNG
- 通过 rM-input-devices 实现无键盘输入
- 最近发现的 reMarkableAI 实现OCR→OpenAI→PDF→设备传输
- 另一个reMarkable-LLM接口 rMAI,使用replicate作为模型服务
- 虽未采用,但 Crazy Cow 是个有趣的工具,可将文本转换为reMarkable1的笔触
临时笔记
# 在设备上记录评估
./ghostwriter --output-file tmp/result.out --model-output-file tmp/result.json --save-screenshot tmp/input.png --no-draw-progress --save-bitmap tmp/result.png claude-assist
# 在本地复制评估结果到本地文件夹
export evaluation_name=tic_tac_toe_1
rm tmp/*
scp -r remarkable:tmp/ ./
mkdir -p evaluations/$evaluation_name
mv tmp/* evaluations/$evaluation_name
# 运行评估
./target/release/ghostwriter --input-png evaluations/$evaluation_name/input.png --output-file tmp/result.out --model-output-file tmp/result.json --save-bitmap tmp/result.png --no-draw --no-draw-progress --no-loop --no-trigger claude-assist
# 叠加输入输出
convert \( evaluations/$evaluation_name/input.png -colorspace RGB \) \( tmp/result.png -type truecolormatte -transparent white -fill red -colorize 100 \) -compose Over -composite tmp/merged-output.png
构建虚拟键盘输入的uinput模块
为了实现反向输入,我们需要插入虚拟USB键盘(与Remarkable Folio键盘同类型)。rm2设备可直接使用,但rmpp设备内核未包含uinput模块,需要自行编译。
如果我已经完成编译则无需操作!
git clone https://github.com/reMarkable/linux-imx-rm- 切换到目标发行分支
- 按照说明提取并启用大Git支持
- 编辑 arch/arm64/configs/ferrari_defconfig
- 添加
CONFIG_INPUT_UINPUT=m - 按照readme构建:
export make=make ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu-
make ferrari_defconfig
make -j$(nproc)
make INSTALL_MOD_STRIP=1 INSTALL_MOD_PATH=./output modules_install
- 将output/lib/modules/.../kernel/drivers/input/misc/uinput.ko复制到utils/rmpp/uinput-VERSION.ko
- 该文件将被打包并自动加载
- ...所以只要我完成编译并提交到仓库,你们就无需重复操作
提示/工具思路:
- 工具(tool)有几种模型——每个工具都可以是可重用且通用的,或者可以包含额外输入参数(extra-inputs)用于链式思考(chain-of-thought),以及参数的提示说明
- 提示应采用纯JSON或YAML格式,并应在视觉/大语言模型(V/LLM models)间保持标准化
- 我正在考虑的一个总体方向是设置顶层"模式(modes)",每个模式包含主提示和可用工具集
- 但或许也可以构建完整状态机流程?
- 例如...数学助手可能有不同于待办助手的状态机
- 状态应包含开始、中间和终止状态
- 终止状态需要产生输出或效果,这些才是真正执行操作的状态
- 初始状态对应初始提示
- 某个中间状态可以是
思考(thinking),这里可以将工具输入作为书写思考过程的区域,工具输出会被忽略 - 总体目标是建立易于编写、易于复制粘贴、易于维护的提示系统
- 然后我们可以为每个提示模式构建可复用的评估集或示例集
- 越来越明显的是,reMarkable用例可能恰好是该系统中配置的特定提示,其余部分可抽象为框架...
- 因此状态机可能如下:
stateDiagram-v2
[*] --> Screenshot
Screenshot --> OutputScreen
Screenshot --> OutputKeyboardText
stateDiagram-v2
[*] --> WaitForTouch
WaitForTouch --> Screenshot
Screenshot --> OutputScreen
Screenshot --> OutputKeyboardText
OutputScreen --> [*]
OutputKeyboardText --> [*]
stateDiagram-v2
[*] --> WaitForTouch
WaitForTouch --> Screenshot
Screenshot --> Thinking
Thinking --> Thinking
Thinking --> OutputScreen
Thinking --> OutputKeyboardText
OutputScreen --> [*]
OutputKeyboardText --> [*]
版本历史
v2025.09.27-012025/09/27v2025.09.21-032025/09/22v2025.09.21-022025/09/21v2025.09.21-012025/09/21v2025.09.17-012025/09/17v2025.05.17-012025/05/17v2025.05.10-012025/05/11v2025.04.26-032025/04/26v2025.04.26-022025/04/26v2025.04.26-012025/04/26v2024.12.292024/12/29v2024.12.25.12024/12/25v2024.12.252024/12/25v2024.12.182024/12/19v2024.12.022024/12/03v2024.11.222024/11/23v2024.11.022024/11/03v2024.10.21.012024/10/21v2024.10.212024/10/21常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。