bedrock-access-gateway
bedrock-access-gateway 是一个开源桥梁,旨在让开发者能够直接使用 OpenAI 格式的 API 来调用亚马逊 Bedrock 上的各类大模型。它主要解决了应用迁移与测试中的兼容性问题:如果你已有的项目是基于 OpenAI SDK 构建的,无需修改任何代码,即可通过此网关无缝切换至 Bedrock 提供的丰富模型资源进行实验或部署。
这款工具非常适合正在开发生成式 AI 应用的工程师、希望评估不同模型能力的研究人员,以及需要在 AutoGen 等框架中快速集成多模型支持的技术团队。其核心亮点在于全面兼容 OpenAI 标准接口,不仅支持聊天补全、工具调用、嵌入和多模态处理,还特别优化了流式响应体验。最新升级更原生支持 Amazon API Gateway 的流式传输,显著降低了延迟并优化了成本。此外,它还率先支持了包括 Claude 4.5 系列、Amazon Nova、DeepSeek-R1 及通义千问等前沿模型的推理能力,甚至涵盖了思维链(Reasoning)和交错思考等高级特性,让用户能轻松探索最顶尖的 AI 能力。
使用场景
某初创团队正在开发一款基于 AutoGen 框架的多智能体代码辅助平台,希望快速接入 Amazon Bedrock 上最新的 Claude 4.5 和 Qwen3-Coder 模型以提升推理能力。
没有 bedrock-access-gateway 时
- 代码重构成本高:现有系统完全基于 OpenAI SDK 构建,若要切换至 Bedrock,需重写所有 API 调用逻辑并修改底层通信协议。
- 流式响应延迟大:直接集成 Bedrock 原生接口难以在 Serverless 架构下实现低延迟的 SSE(服务器发送事件)流式输出,导致用户等待首字时间过长。
- 新模型适配慢:面对 Bedrock 上新发布的 DeepSeek-R1 或 Nova 系列模型,每次都需要单独开发适配器,无法通过统一接口即时调用。
- 高级功能缺失:难以在不改动业务代码的前提下,利用 Bedrock 特有的思维链(Reasoning)或多模态处理能力。
使用 bedrock-access-gateway 后
- 零代码迁移:bedrock-access-gateway 提供了兼容 OpenAI 的 RESTful API,团队无需修改任何一行业务代码,仅需更换 Endpoint 即可无缝调用 Bedrock 模型。
- 极致流式体验:借助 API Gateway 的原生流式支持,bedrock-access-gateway 实现了真正的低延迟字符级流式输出,显著提升了多智能体对话的流畅度。
- 即时模型迭代:只需运行一次模型刷新指令,AutoGen 框架即可立即识别并调用最新的 Claude 4.5 或 Qwen3-Coder 模型,大幅缩短测试周期。
- 高级特性开箱即用:通过标准 OpenAI 参数格式,直接开启了模型的深度推理(Extended Thinking)和工具调用(Tool Call)功能,释放了 Bedrock 的全部潜力。
bedrock-access-gateway 充当了通用的“翻译官”,让开发者能以最小的成本将成熟的 OpenAI 生态应用平滑迁移至更具性价比和模型多样性的 Amazon Bedrock 平台。
运行环境要求
- 未说明 (基于 AWS Lambda/Fargate 容器化部署,宿主系统无特定限制)
不需要 (基于 AWS Bedrock 云端推理,本地/容器端无需 GPU)
未说明 (取决于所选部署架构:Lambda 默认内存或 Fargate 任务定义配置)

快速开始
床岩访问网关
适用于亚马逊 Bedrock 的 OpenAI 兼容 RESTful API
最新动态 🔥
API 网关响应流式传输支持 - 您现在可以使用 Amazon API 网关 REST API 而不是 ALB 进行部署,从而实现真正的响应流式传输,以获得更低的延迟并优化成本。有关详细信息,请参阅部署选项。
最新支持的模型:
- Claude 4.5 系列:Opus 4.5、Sonnet 4.5、Haiku 4.5 - Anthropic 最智能的模型,具备增强的编码和代理能力
- Amazon Nova:Nova Micro、Nova Lite、Nova Pro、Nova Premier - Amazon 原生的基础模型,支持多模态
- DeepSeek:DeepSeek-R1(推理)、DeepSeek-V3.1 - 先进的推理和通用模型
- 通义千问 3:Qwen3-32B、Qwen3-235B、Qwen3-Coder-30B、Qwen3-Coder-480B - 阿里巴巴最新的语言和编码模型
- OpenAI 开源模型:gpt-oss-20b、gpt-oss-120b - 可通过 Bedrock 使用的开源 GPT 模型
它还支持 Claude 4/4.5(扩展思维和交错思维)以及 DeepSeek R1 的推理功能。更多详情请参阅使用方法。您需要先运行 Models API 来刷新模型列表。
概述
亚马逊 Bedrock 提供了广泛的基础模型(如 Claude 3 Opus/Sonnet/Haiku、Llama 2/3、Mistral/Mixtral 等)以及丰富的功能,帮助您构建生成式 AI 应用程序。有关更多信息,请访问 亚马逊 Bedrock 官方页面。
有时,您可能已经使用 OpenAI 的 API 或 SDK 开发了应用程序,并希望在不修改代码库的情况下尝试亚马逊 Bedrock。或者您只是想在 AutoGen 等工具中评估这些基础模型的能力。那么,这个仓库可以让您通过 OpenAI 的 API 和 SDK 无缝访问亚马逊 Bedrock 的模型,从而无需更改代码即可测试这些模型。
如果您觉得这个 GitHub 仓库很有用,请考虑免费给它点个星 ⭐,以表达您对该项目的支持与感谢。
功能特性:
- 支持通过服务器发送事件 (SSE) 进行流式响应
- 支持 Models API
- 支持 Chat Completion API
- 支持工具调用
- 支持 Embedding API
- 支持 Multimodal API
- 支持跨区域推理
- 支持应用推理配置文件(新)
- 支持推理(新)
- 支持交错思维(新)
- 支持提示缓存(新)
有关如何使用新 API 的更多详细信息,请查看使用指南。
开始使用
前提条件
请确保您已满足以下前提条件:
- 拥有亚马逊 Bedrock 基础模型的访问权限。
有关如何申请模型访问权限的更多信息,请参阅 亚马逊 Bedrock 用户指南(设置 > 模型访问)
架构
下图展示了参考架构。它使用 Amazon API 网关响应流式传输 结合 Lambda 实现 SSE 支持。
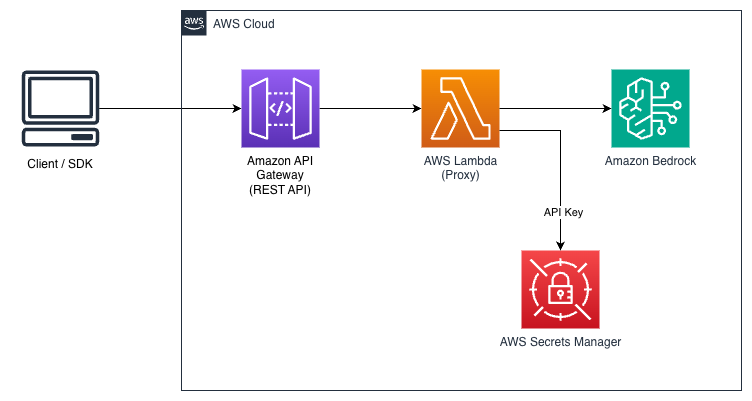
部署选项
| 选项 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| API 网关 + Lambda | 无需 VPC,按需付费,原生流式支持,较低的运维开销 | 可能存在冷启动 | 多数用例,成本敏感型部署 |
| ALB + Fargate | 流式传输延迟最低,无冷启动 | 成本较高,需要 VPC | 高吞吐量、对延迟敏感的工作负载 |
您也可以使用 Lambda 函数 URL 作为替代方案,详见示例
部署
请按照以下步骤将 Bedrock 代理 API 部署到您的 AWS 账户中。仅支持 Amazon Bedrock 可用的区域(例如 us-west-2)。部署大约需要 10–15 分钟 🕒。
步骤 1:在 Secrets Manager 中创建您自己的 API 密钥(必须)
注意:此步骤是为了使用任意不含空格的字符串创建一个自定义 API 密钥(凭据),该密钥将在后续用于访问代理 API。此密钥无需与您的实际 OpenAI 密钥匹配,您也不需要拥有 OpenAI API 密钥。请务必妥善保管并确保密钥的私密性。
打开 AWS 管理控制台,导航至 AWS Secrets Manager 服务。
单击“存储新密钥”按钮。
在“选择密钥类型”页面中,选择:
密钥类型:其他类型的密钥
键/值对:- 键:api_key
- 值:输入您的 API 密钥值
单击“下一步”
在“配置密钥”页面中: 密钥名称:输入一个名称(例如“BedrockProxyAPIKey”) 描述:(可选)添加关于此密钥的描述
单击“下一步”,检查所有设置并单击“存储”。
创建完成后,您将在 Secrets Manager 控制台中看到您的密钥。请记下密钥的 ARN。
步骤 2:构建并推送容器镜像至 ECR
克隆此仓库:
git clone https://github.com/aws-samples/bedrock-access-gateway.git cd bedrock-access-gateway运行构建和推送脚本:
cd scripts bash ./push-to-ecr.sh按照提示进行配置:
- ECR 存储库名称(或使用默认值)
- 镜像标签(或使用默认值:
latest) - AWS 区域(或使用默认值:
us-east-1)
脚本将构建并分别将 Lambda 和 ECS/Fargate 的镜像推送到您的 ECR 存储库中。
重要提示:请复制脚本输出末尾显示的镜像 URI。您将在下一步中用到这些 URI。
步骤 3:部署 CloudFormation 堆栈
下载您想要使用的 CloudFormation 模板:
- 对于 API Gateway + Lambda:
deployment/BedrockProxy.template - 对于 ALB + Fargate:
deployment/BedrockProxyFargate.template
- 对于 API Gateway + Lambda:
登录 AWS 管理控制台,在目标区域导航至 CloudFormation 服务。
单击“创建堆栈”→“使用新资源(标准)”。
上传您下载的模板文件。
在“指定堆栈详细信息”页面中,提供以下信息:
- 堆栈名称:输入一个堆栈名称(例如“BedrockProxyAPI”)
- ApiKeySecretArn:输入步骤 1 中获得的密钥 ARN
- ContainerImageUri:输入步骤 2 输出中的 ECR 镜像 URI
- DefaultModelId:(可选)根据需要更改默认模型
单击“下一步”。
在“配置堆栈选项”页面中,您可以保留默认设置,也可以根据需求进行自定义。单击“下一步”。
在“审核”页面中,仔细检查所有详细信息。勾选底部的“我确认 AWS CloudFormation 可能会创建 IAM 资源”复选框。单击“提交”。
就完成了!🎉 部署完成后,单击 CloudFormation 堆栈并进入 Outputs 选项卡,您可以在 APIBaseUrl 中找到 API 基础 URL,其值应类似于 http://xxxx.xxx.elb.amazonaws.com/api/v1。
故障排除
如果您遇到任何问题,请查看 故障排除指南 以获取更多详细信息。
SDK/API 使用
您只需要 API 密钥和 API 基础 URL 即可。如果您未按照步骤 1 设置自己的密钥,则应用程序将无法启动,并会显示一条错误消息,指出未配置 API 密钥。
现在,您可以试用代理 API。假设您想测试 Claude 3 Sonnet 模型(模型 ID:anthropic.claude-3-sonnet-20240229-v1:0)……
API 使用示例
export OPENAI_API_KEY=<API 密钥>
export OPENAI_BASE_URL=<API 基础 URL>
# 对于旧版本
# https://github.com/openai/openai-python/issues/624
export OPENAI_API_BASE=<API 基础 URL>
curl $OPENAI_BASE_URL/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "anthropic.claude-3-sonnet-20240229-v1:0",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
SDK 使用示例
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="anthropic.claude-3-sonnet-20240229-v1:0",
messages=[{"role": "user", "content": "Hello!"}],
)
print(completion.choices[0].message.content)
有关如何使用嵌入 API、多模态 API 和工具调用的更多详细信息,请参阅 使用指南。
应用推理配置文件
此代理现支持 应用推理配置文件,允许您跟踪模型调用的使用情况和成本。您可以使用在 AWS 账户中创建的应用推理配置文件来进行成本跟踪和监控。
使用应用推理配置文件:
# 将应用推理配置文件 ARN 用作模型 ID
curl $OPENAI_BASE_URL/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "arn:aws:bedrock:us-west-2:123456789012:application-inference-profile/your-profile-id",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
使用应用推理配置文件的 SDK 示例:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="arn:aws:bedrock:us-west-2:123456789012:application-inference-profile/your-profile-id",
messages=[{"role": "user", "content": "Hello!"}],
)
print(completion.choices[0].message.content)
应用推理配置文件的优势:
- 成本跟踪:跟踪特定应用或用例的使用情况和成本
- 使用监控:通过 CloudWatch 监控模型调用指标
- 基于标签的成本分配:使用 AWS 成本分配标签进行详细的账单分析
有关创建和管理应用推理配置文件的更多信息,请参阅 Amazon Bedrock 用户指南。
提示缓存
此代理现支持 Claude 和 Nova 模型的 提示缓存,对于具有重复提示的工作负载,提示缓存可以将成本降低多达 90%,并将延迟降低多达 85%。
支持的模型:
- Claude 模型(Claude 3.5 Haiku、Claude 4、Claude 4.5 等)
- Nova 模型(Nova Micro、Nova Lite、Nova Pro、Nova Premier)
启用提示缓存的方法:
您可以通过两种方式启用提示缓存:
- 通过环境变量全局启用(在 ECS 任务定义或 Lambda 中设置):
ENABLE_PROMPT_CACHING=true
- 通过
extra_body进行每请求配置:
Python SDK 示例:
from openai import OpenAI
client = OpenAI()
# 缓存系统提示
response = client.chat.completions.create(
model="global.anthropic.claude-haiku-4-5-20251001-v1:0",
messages=[
{"role": "system", "content": "你是一位在…方面具有专业知识的专家助手"},
{"role": "user", "content": "帮我完成这项任务"}
],
extra_body={
"prompt_caching": {"system": True}
}
)
# 检查缓存命中情况
if response.usage.prompt_tokens_details:
cached_tokens = response.usage.prompt_tokens_details.cached_tokens
print(f"缓存的 token 数量:{cached_tokens}")
cURL:
curl $OPENAI_BASE_URL/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "global.anthropic.claude-haiku-4-5-20251001-v1:0",
"messages": [
{"role": "system", "content": "长篇系统提示..."},
{"role": "user", "content": "问题"}
],
"extra_body": {
"prompt_caching": {"system": true}
}
}'
缓存选项:
"prompt_caching": {"system": true}- 缓存系统提示"prompt_caching": {"messages": true}- 缓存用户消息"prompt_caching": {"system": true, "messages": true}- 同时缓存系统提示和用户消息
要求:
- 提示必须至少包含 1,024 个 token 才能启用缓存
- 缓存的 TTL 为 5 分钟(每次缓存命中都会重置)
- Nova 系列模型的缓存上限为 20,000 个 token
更多信息请参阅 Amazon Bedrock 提示缓存指南。
其他示例
LangChain
请确保使用 ChatOpenAI(...) 而不是 OpenAI(...)
# 安装 langchain-openai
import os
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(
model="anthropic.claude-3-sonnet-20240229-v1:0",
temperature=0,
openai_api_key=os.environ['OPENAI_API_KEY'],
openai_api_base=os.environ['OPENAI_BASE_URL'],
)
template = """问题:{question}
答案:让我们一步步思考。"""
prompt = PromptTemplate.from_template(template)
llm_chain = LLMChain(prompt=prompt, llm=chat)
question = "贾斯汀·比伯出生那年,哪支球队赢得了超级碗?"
response = llm_chain.invoke(question)
print(response)
常见问题解答
关于隐私
本应用不会收集您的任何数据。此外,默认情况下也不会记录任何请求或响应。
为什么选择 API Gateway 而不是 ALB?
API Gateway + Lambda 使用 API Gateway 响应流式传输 结合 Lambda Web Adapter,可在无需 VPC 的情况下支持 SSE 流式传输。这是一种经济高效的无服务器方案,超时时间最长可达 10 分钟。
ALB + Fargate 则提供最低的流式传输延迟且无冷启动问题,非常适合高吞吐量的工作负载。
支持哪些区域?
一般来说,所有 Amazon Bedrock 支持的区域都适用;如果未涵盖,请在 Github 上提交问题。请注意,并非所有模型在这些区域都可用。
支持哪些模型?
您可以使用 Models API 获取或刷新当前区域支持的模型列表。
是否可以在本地运行?
是的,您可以在本地运行,例如在 src 文件夹下执行以下命令:
uvicorn api.app:app --host 0.0.0.0 --port 8000
此时 API 的基础 URL 应为 http://localhost:8000/api/v1。
使用代理 API 是否会牺牲性能或增加延迟?
与直接调用 AWS SDK 相比,代理架构会引入一定的延迟。默认的 API Gateway + Lambda 部署通过 Lambda 响应流式传输,能够提供良好的流式传输性能。若希望获得最低的流式响应延迟,建议采用 ALB + Fargate 部署方案,该方案可消除冷启动并提供一致的性能。
是否计划支持 SageMaker 模型?
目前暂无支持 SageMaker 模型的计划。不过,若客户有需求,未来可能会考虑添加此功能。
是否计划支持 Bedrock 自定义模型?
目前不支持微调模型或具有预置吞吐量的模型。如果您有定制需求,可以克隆仓库自行实现。
如何升级?
要使用最新功能,您需要按照部署指南重新部署应用程序。可以通过升级现有的 CloudFormation 堆栈来获取最新更改。
安全性
更多信息请参阅 CONTRIBUTING。
许可证
本库采用 MIT-0 许可证授权。详情请参阅 LICENSE 文件。
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。
gpt4free
gpt4free 是一个由社区驱动的开源项目,旨在聚合多种可访问的大型语言模型(LLM)和媒体生成接口,让用户能更灵活、便捷地使用前沿 AI 能力。它解决了直接调用各类模型时面临的接口分散、门槛高或成本昂贵等痛点,通过统一的标准将不同提供商的资源整合在一起。 无论是希望快速集成 AI 功能的开发者、需要多模型对比测试的研究人员,还是想免费体验最新技术的普通用户,都能从中受益。gpt4free 提供了丰富的使用方式:既包含易于上手的 Python 和 JavaScript 客户端库,也支持部署本地图形界面(GUI),更提供了兼容 OpenAI 标准的 REST API,方便无缝替换现有应用后端。 其技术亮点在于强大的多提供商支持架构,能够动态调度包括 Opus、Gemini、DeepSeek 等多种主流模型资源,并支持 Docker 一键部署及本地推理。项目秉持社区优先原则,在降低使用门槛的同时,也为贡献者提供了扩展新接口的便利框架,是探索和利用多样化 AI 资源的实用工具。
gstack
gstack 是 Y Combinator CEO Garry Tan 亲自开源的一套 AI 工程化配置,旨在将 Claude Code 升级为你的虚拟工程团队。面对单人开发难以兼顾产品战略、架构设计、代码审查及质量测试的挑战,gstack 提供了一套标准化解决方案,帮助开发者实现堪比二十人团队的高效产出。 这套配置特别适合希望提升交付效率的创始人、技术负责人,以及初次尝试 Claude Code 的开发者。gstack 的核心亮点在于内置了 15 个具有明确职责的 AI 角色工具,涵盖 CEO、设计师、工程经理、QA 等职能。用户只需通过简单的斜杠命令(如 `/review` 进行代码审查、`/qa` 执行测试、`/plan-ceo-review` 规划功能),即可自动化处理从需求分析到部署上线的全链路任务。 所有操作基于 Markdown 和斜杠命令,无需复杂配置,完全免费且遵循 MIT 协议。gstack 不仅是一套工具集,更是一种现代化的软件工厂实践,让单人开发者也能拥有严谨的工程流程。
meilisearch
Meilisearch 是一个开源的极速搜索服务,专为现代应用和网站打造,开箱即用。它能帮助开发者快速集成高质量的搜索功能,无需复杂的配置或额外的数据预处理。传统搜索方案往往需要大量调优才能实现准确结果,而 Meilisearch 内置了拼写容错、同义词识别、即时响应等实用特性,并支持 AI 驱动的混合搜索(结合关键词与语义理解),显著提升用户查找信息的体验。 Meilisearch 特别适合 Web 开发者、产品团队或初创公司使用,尤其适用于需要快速上线搜索功能的场景,如电商网站、内容平台或 SaaS 应用。它提供简洁的 RESTful API 和多种语言 SDK,部署简单,资源占用低,本地开发或生产环境均可轻松运行。对于希望在不依赖大型云服务的前提下,为用户提供流畅、智能搜索体验的团队来说,Meilisearch 是一个高效且友好的选择。
awesome-claude-skills
awesome-claude-skills 是一个精心整理的开源资源库,旨在帮助用户挖掘和扩展 Claude AI 的潜力。它不仅仅是一份列表,更提供了实用的“技能(Skills)”模块,让 Claude 从单纯的文本生成助手,进化为能执行复杂工作流的智能代理。 许多用户在使用 AI 时,常受限于其无法直接操作外部软件或处理特定格式文件的痛点。awesome-claude-skills 通过预设的工作流解决了这一问题:它不仅能教会 Claude 专业地处理 Word、PDF 等文档,进行代码开发与数据分析,还能借助 Composio 插件连接 Slack、邮箱及数百种常用应用,实现发送邮件、创建任务等自动化操作。这使得重复性任务变得标准化且可复用,极大提升了工作效率。 无论是希望优化日常办公流程的普通用户、需要处理复杂文档的研究人员,还是寻求将 AI 深度集成到开发管线中的开发者,都能从中找到适合的解决方案。其独特的技术亮点在于“技能”的可定制性与强大的应用连接能力,让用户无需编写复杂代码,即可通过简单的配置让 Claude 具备跨平台执行真实任务的能力。如果你希望让 Claude