Awesome-Controllable-Diffusion
Awesome-Controllable-Diffusion 是一个专注于扩散模型可控生成技术的开源资源库。在 AIGC 蓬勃发展的当下,基础的文本生成图像往往难以精确满足用户对构图、姿态或特定主体的精细控制需求。该项目旨在解决这一痛点,系统性地收集并整理了相关学术论文与实用资源,涵盖了 ControlNet、DreamBooth、IP-Adapter 等主流技术,以及 IFAdapter、CSGO 等前沿研究成果。
通过按年份分类的论文列表和详细的技术标签(如布局控制、风格迁移、3D 场景生成等),Awesome-Controllable-Diffusion 帮助用户快速定位如何利用草图、深度图、参考图像等多种条件来引导 AI 创作,实现从“随机生成”到“精准控制”的跨越。
这份资源库特别适合 AI 研究人员、算法开发者以及希望深入理解生成式 AI 底层逻辑的设计师使用。对于研究者,它是追踪最新学术动态的绝佳索引;对于开发者,它提供了丰富的代码链接和项目主页,便于复现与创新;对于高级创作者,它则揭示了更多定制化生成的可能性。无论你是想探索如何将随意涂鸦转化为互动 3D 游戏场景,还是希望精确控制画面中的人物姿态与风格组合,Awesome-Controllable-Diffusion 都能为你提供坚实的技术指引和丰富的学习素材。
使用场景
某独立游戏开发者试图将手绘的草图快速转化为风格统一、布局可控的 3D 游戏场景概念图,以加速前期美术设计流程。
没有 Awesome-Controllable-Diffusion 时
- 布局失控:直接使用基础扩散模型生成图像时,AI 完全忽略草图中的建筑位置和道路走向,导致生成的场景构图与原始设计意图严重偏离。
- 风格割裂:难以在保持特定像素艺术或赛博朋克风格的同时,精准植入自定义的角色或道具,每次调整都需要重新训练模型,耗时数小时。
- 资源分散:需要在 GitHub、ArXiv 和各类论坛中盲目搜索 ControlNet、IP-Adapter 等最新控制技术,缺乏系统整理,极易错过如 Sketch2Scene 这类针对 3D 场景生成的关键论文。
- 迭代低效:修改局部细节(如更换窗户样式)往往引发整体画面崩坏,无法实现“指哪打哪”的精细化控制,导致废稿率极高。
使用 Awesome-Controllable-Diffusion 后
- 精准还原布局:通过列表中集成的 Sketch2Scene 和 IFAdapter 技术,开发者能直接将粗糙草图转化为结构严谨的 3D 场景,完美保留原始设计的空间逻辑。
- 灵活风格组合:利用 CSGO 等资源,轻松实现内容与风格的解耦控制,既能固定角色形象,又能一键切换多种美术风格,无需重复训练。
- 前沿技术直达:依托该清单对 2024-2025 年最新论文(如 Generative Photomontage)的系统收录,开发者能迅速定位并应用最适合场景合成的 SOTA 算法。
- 高效局部编辑:借助成熟的条件控制方案,可单独调整场景中的光照、材质或物体位置,大幅降低试错成本,将概念图产出效率提升数倍。
Awesome-Controllable-Diffusion 将零散的前沿控制技术转化为系统化的生产力,让创作者从“抽卡式”生成进化为真正的“导演式”创作。
运行环境要求
未说明
未说明
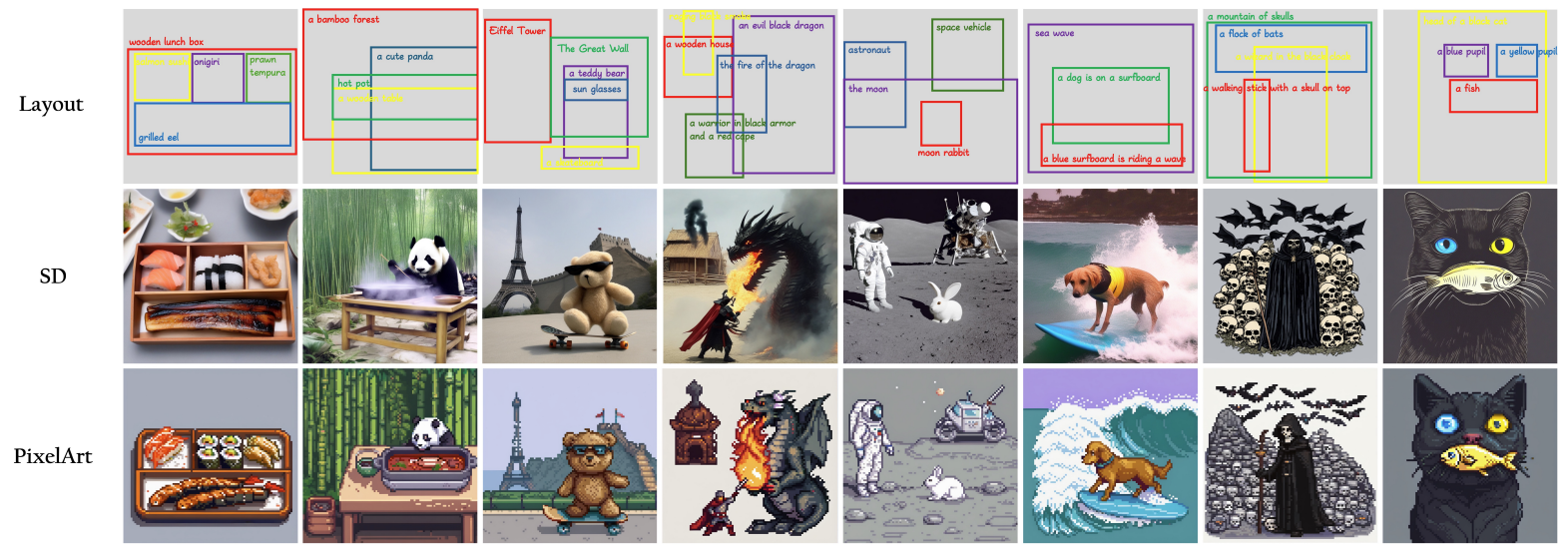
快速开始
强大的可控扩散模型
在 AIGC 时代,为扩散模型添加条件控制的相关论文与资源。
📝 论文
2024 年
IFAdapter:用于接地文本到图像生成的实例特征控制。 🔥 [项目] [论文] [代码]
吴银伟、周先潘、马冰、苏雪峰、马凯、王新超。 预印本 2024 年。


CSGO:文本到图像生成中的内容-风格组合。 [项目] [论文] [代码]
邢鹏、王浩凡、孙延鹏、王奇勋、白旭、艾浩、黄仁远、李泽超。 预印本 2024 年。



-
刘Sean J.、库玛丽·努普尔、沙米尔·阿里埃尔、朱俊彦。 预印本 2024 年。
Sketch2Scene:根据用户随意草图自动生成交互式 3D 游戏场景。 [项目] [论文]
徐永志、吴勇汉、王义夫、萨英奎、段云飞、李阳、季攀、李洪东。 预印本 2024 年。

IPAdapter-Instruct:利用指令提示解决基于图像的条件模糊性。 [项目] [论文] [代码]
西阿拉·罗尔斯、希蒙·韦纳、丹特·德尼格里斯、斯拉瓦·埃利扎罗夫、康斯坦丁·库茨伊、西蒙·多内。 预印本 2024 年。
ViPer:通过个体偏好学习对生成模型进行视觉个性化。 [项目] [论文] [代码]
索甘德·萨莱希、马赫迪·沙菲伊、特蕾莎·叶欧、罗曼·巴赫曼、阿米尔·扎米尔。 ECCV'24。
无需训练的复合场景生成用于布局到图像合成。 [论文] [代码]
刘佳琪、黄涛、许昌。 ECCV'24。
SEED-Story:使用大型语言模型进行多模态长篇故事生成。 [论文] [代码]
杨帅、葛宇莹、李阳、陈宇康、葛一肖、山英、陈英聪。 预印本 2024 年。

-
张天宇、谢晓轩、杜旭升、谢浩然。 预印本 2024 年。
使用图像扩散模型即时生成 3D 人体化身。 [项目] [论文]
尼科斯·科洛托罗斯、蒂莫·阿尔迪克、恩里克·科罗纳、爱德华·加布里埃尔·巴扎万、克里斯蒂安·斯明奇塞斯库。 ECCV'24。
Ctrl-X:无需指导的文本到图像生成中的结构与外观控制。 🔥 [项目] [论文] [代码]
林宽衡、莫思成、本·克林格、穆方舟、周博磊。 预印本 2024年。




Zero-Painter:用于文本到图像合成的免训练布局控制。 [论文] [代码]
玛丽安娜·奥哈尼扬、海克·马努基扬、张阳王、桑特·纳瓦萨尔迪扬、亨弗莱·施伊。 CVPR'24。
pOps:受照片启发的扩散算子。 🔥 [项目] [论文] [代码]
埃拉德·理查森、尤瓦尔·阿拉卢夫、阿里·马赫达维-阿米里、丹尼尔·科恩-奥尔。 预印本 2024年。


RB调制:利用随机最优控制对扩散模型进行免训练个性化。 [项目] [论文] [代码]
利图·劳特、陈宇佳、纳塔尼尔·鲁伊斯、阿比舍克·库马尔、康斯坦丁·卡拉马尼斯、桑杰·沙科泰、朱文生。 预印本 2024年。🔥


FreeCustom:用于多概念组合的免调优定制化图像生成。 [项目] [论文] [代码]
丁刚贵、赵灿宇、王文、杨振、刘子德、陈浩、沈春华。 CVPR'24。
面向概念驱动的文本到图像生成的个性化残差。 [项目] [论文]
库苏·哈姆、马修·费舍尔、詹姆斯·海斯、尼古拉斯·科尔金、刘雨辰、理查德·张、托比亚斯·欣茨。 CVPR'24。
基于密集块表示的组合式文本到图像生成。 🔥 [项目] [论文]
聂伟力、刘思飞、莫特扎·马尔达尼、刘超、本杰明·埃卡特、阿拉什·瓦赫达特。 ICML'24。

仅用一对图像即可定制文本到图像模型。 [项目] [论文] [代码]
麦克斯韦尔·琼斯、王圣宇、努普尔·库玛丽、大卫·鲍、朱俊彦。 预印本 2024年。
StoryDiffusion:用于长序列图像和视频生成的一致性自注意力机制。 [论文]
周宇鹏、周大泉、程明明、冯家世、侯启斌。 预印本 2024年。


InstantFamily:基于掩码注意力的零样本多身份图像生成。 [论文]
金婵兰、李正仁、郑始昌、金奉模、白悦敏。 预印本 2024年。
PuLID:通过对比对齐实现纯净且快速的身份定制。 [论文] [代码]
郭子楠、吴言泽、陈卓伟、陈朗、何倩。 技术报告 2024年。
MultiBooth:从文本生成包含所有概念的图像。 [项目] [论文] [代码]
朱晨阳、李凯、马月、何春明、修丽。 预印本 2024年。
StyleBooth:通过多模态指令编辑图像风格。 [项目] [论文] [代码]
韩震、毛超杰、蒋泽音、潘玉琳、张景峰。 预印本 2024年。
MoMA:用于快速个性化图像生成的多模态LLM适配器。 🔥 [项目] [论文] [代码]
Kunpeng Song, Yizhe Zhu, Bingchen Liu, Qing Yan, Ahmed Elgammal, Xiao Yang. ECCV'24。

-
Zezhong Fan, Xiaohan Li, Chenhao Fang, Topojoy Biswas, Kaushiki Nag, Jianpeng Xu, Kannan Achan. WWW'24。

MoA:用于个性化图像生成中主体与上下文解耦的注意力混合机制。 [项目] [论文] [代码]
Kuan-Chieh Wang, Daniil Ostashev, Yuwei Fang, Sergey Tulyakov, Kfir Aberman. 2024年预印本。
MaxFusion:文生图扩散模型中的即插即用多模态生成。 [项目] [论文] [代码]
Nithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, Vishal M Patel. ECCV'24。
Ctrl-Adapter:一种高效且通用的框架,可将多种控制方式适配到任何扩散模型。 [项目] [论文] [代码]
Han Lin, Jaemin Cho, Abhay Zala, Mohit Bansal. 2024年预印本。
ControlNet++:通过高效的连贯性反馈改进条件控制。 [项目] [论文] [代码]
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, Chen Chen. ECCV'24。
面向多主体个性化的文生图模型身份解耦技术。 [项目] [论文]
Sangwon Jang, Jaehyeong Jo, Kimin Lee, Sung Ju Hwang. 2024年预印本。
Concept Weaver:实现文生图模型中的多概念融合。 [论文]
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron. CVPR'24。
FlashFace:高保真度身份保留的人像个性化生成。 [项目] [论文] [代码]
Shilong Zhang, Lianghua Huang, Xi Chen, Yifei Zhang, Zhi-Fan Wu, Yutong Feng, Wei Wang, Yujun Shen, Yu Liu, Ping Luo. 2024年预印本。
做你自己:用于多主体文生图生成的有界注意力机制。 [项目] [论文] [代码]
Omer Dahary, Or Patashnik, Kfir Aberman, Daniel Cohen-Or. ECCV'24。
通过识别语义方向实现T2I模型中的连续主体特异性属性控制。 [项目] [论文] [代码]
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Vincent Tao Hu, Björn Ommer. 2024年预印本。

Make-Your-3D:快速且一致的主体驱动型3D内容生成。 [项目] [论文] [代码]
Fangfu Liu, Hanyang Wang, Weiliang Chen, Haowen Sun, Yueqi Duan. ECCV'24。
FeedFace:基于扩散模型的高效推理式人脸个性化。 [论文] [代码]
Chendong Xiang, Armando Fortes, Khang Hui Chua, Hang Su, Jun Zhu. Tiny Papers @ ICLR'24。
用于图像生成的多LoRA组合。 [项目] [论文] [代码]
钟明、沈烨龙、王硕航、陆亚东、焦一竹、欧阳思儒、于东汉、韩家伟、陈伟柱。 预印本 2024年。
Gen4Gen:面向生成式多概念组合的生成式数据流水线。 [项目] [论文] [代码]
叶春孝、程大英、谢荷妍、林传恩、马毅、安德鲁·马卡姆、尼基·特里戈尼、H.T. 康格、陈宇贝。 技术报告 2024年。

通过交换式自注意力进行视觉风格提示。 [项目] [论文] [代码]
郑在锡、金俊浩、崔允洁、李佳莹、禹英中。 预印本 2024年。
RealCompo:现实感与构图之间的动态平衡提升文本到图像扩散模型。 [论文] [代码]
张新晨、杨凌、蔡雅琪、俞兆辰、谢嘉克、田野、徐敏凯、唐勇、杨宇久、崔斌。 预印本 2024年。
用于组合型文本到图像个性化的直接一致性优化。 [项目] [论文] [代码]
李京民、郭尚京、孙基赫、申振宇。 预印本 2024年。
InstanceDiffusion:图像生成中的实例级控制。 [项目] [论文] [代码]
王旭东、特雷弗·达雷尔、赛·萨凯斯·兰巴特拉、罗希特·吉达尔、伊山·米斯拉。 CVPR'24。
无需训练的一致性文本到图像生成。 [项目] [论文]
约阿德·特韦尔、奥姆里·卡杜里、里农·加尔、约尼·卡斯滕、利奥尔·沃尔夫、加尔·切奇克、尤瓦尔·阿茨蒙。 SIGGRAPH'24。
UNIMO-G:通过多模态条件扩散实现统一的图像生成。 🔥 [项目] [论文]
李伟、许雪、刘嘉晨、肖欣燕。 ACL'24。

掌握文本到图像扩散:利用多模态LLM进行重新描述、规划和生成。 🔥 [论文] [代码]
杨凌、俞兆辰、孟晨琳、徐敏凯、斯特凡诺·埃尔蒙、崔斌。 ICML'24。

InstantID:零样本身份保留生成,几秒钟内完成。 [项目] [论文] [代码]
王启勋、白旭、王浩帆、秦泽奎、安东尼·陈、李华夏、唐旭、胡耀。 技术报告 2024年。🔥

PALP:文本到图像模型的提示对齐个性化。 [项目] [论文]
王启勋、白旭、王浩帆、秦泽奎、安东尼·陈。 预印本 2024年。
SCEdit:通过跳过连接编辑实现高效可控的图像扩散生成。 [项目] [论文] [代码]
蒋泽音、毛超杰、潘玉林、韩震、张景峰。 CVPR'24。
PhotoMaker:通过堆叠ID嵌入定制逼真的人像照片。 [项目] [论文] [代码]
李振、曹明登、王新涛、齐仲刚、程明明、单颖。 CVPR'24。🔥

上下文扩散:上下文感知的图像生成。 [项目] [论文]
IFAdapter:用于接地文本到图像生成的实例特征控制。 🔥 [项目] [论文] [代码]
吴银伟、周先潘、马冰、苏雪峰、马凯、王新超。 预印本 2024 年。
CSGO:文本到图像生成中的内容-风格组合。 [项目] [论文] [代码]
邢鹏、王浩凡、孙延鹏、王奇勋、白旭、艾浩、黄仁远、李泽超。 预印本 2024 年。
刘Sean J.、库玛丽·努普尔、沙米尔·阿里埃尔、朱俊彦。 预印本 2024 年。
Sketch2Scene:根据用户随意草图自动生成交互式 3D 游戏场景。 [项目] [论文]
徐永志、吴勇汉、王义夫、萨英奎、段云飞、李阳、季攀、李洪东。 预印本 2024 年。
IPAdapter-Instruct:利用指令提示解决基于图像的条件模糊性。 [项目] [论文] [代码]
西阿拉·罗尔斯、希蒙·韦纳、丹特·德尼格里斯、斯拉瓦·埃利扎罗夫、康斯坦丁·库茨伊、西蒙·多内。 预印本 2024 年。
ViPer:通过个体偏好学习对生成模型进行视觉个性化。 [项目] [论文] [代码]
索甘德·萨莱希、马赫迪·沙菲伊、特蕾莎·叶欧、罗曼·巴赫曼、阿米尔·扎米尔。 ECCV'24。
无需训练的复合场景生成用于布局到图像合成。 [论文] [代码]
刘佳琪、黄涛、许昌。 ECCV'24。
SEED-Story:使用大型语言模型进行多模态长篇故事生成。 [论文] [代码]
杨帅、葛宇莹、李阳、陈宇康、葛一肖、山英、陈英聪。 预印本 2024 年。
张天宇、谢晓轩、杜旭升、谢浩然。 预印本 2024 年。
使用图像扩散模型即时生成 3D 人体化身。 [项目] [论文]
尼科斯·科洛托罗斯、蒂莫·阿尔迪克、恩里克·科罗纳、爱德华·加布里埃尔·巴扎万、克里斯蒂安·斯明奇塞斯库。 ECCV'24。
Ctrl-X:无需指导的文本到图像生成中的结构与外观控制。 🔥 [项目] [论文] [代码]
林宽衡、莫思成、本·克林格、穆方舟、周博磊。 预印本 2024年。
Zero-Painter:用于文本到图像合成的免训练布局控制。 [论文] [代码]
玛丽安娜·奥哈尼扬、海克·马努基扬、张阳王、桑特·纳瓦萨尔迪扬、亨弗莱·施伊。 CVPR'24。
pOps:受照片启发的扩散算子。 🔥 [项目] [论文] [代码]
埃拉德·理查森、尤瓦尔·阿拉卢夫、阿里·马赫达维-阿米里、丹尼尔·科恩-奥尔。 预印本 2024年。
RB调制:利用随机最优控制对扩散模型进行免训练个性化。 [项目] [论文] [代码]
利图·劳特、陈宇佳、纳塔尼尔·鲁伊斯、阿比舍克·库马尔、康斯坦丁·卡拉马尼斯、桑杰·沙科泰、朱文生。 预印本 2024年。🔥
FreeCustom:用于多概念组合的免调优定制化图像生成。 [项目] [论文] [代码]
丁刚贵、赵灿宇、王文、杨振、刘子德、陈浩、沈春华。 CVPR'24。
面向概念驱动的文本到图像生成的个性化残差。 [项目] [论文]
库苏·哈姆、马修·费舍尔、詹姆斯·海斯、尼古拉斯·科尔金、刘雨辰、理查德·张、托比亚斯·欣茨。 CVPR'24。
基于密集块表示的组合式文本到图像生成。 🔥 [项目] [论文]
聂伟力、刘思飞、莫特扎·马尔达尼、刘超、本杰明·埃卡特、阿拉什·瓦赫达特。 ICML'24。
仅用一对图像即可定制文本到图像模型。 [项目] [论文] [代码]
麦克斯韦尔·琼斯、王圣宇、努普尔·库玛丽、大卫·鲍、朱俊彦。 预印本 2024年。
StoryDiffusion:用于长序列图像和视频生成的一致性自注意力机制。 [论文]
周宇鹏、周大泉、程明明、冯家世、侯启斌。 预印本 2024年。
InstantFamily:基于掩码注意力的零样本多身份图像生成。 [论文]
金婵兰、李正仁、郑始昌、金奉模、白悦敏。 预印本 2024年。
PuLID:通过对比对齐实现纯净且快速的身份定制。 [论文] [代码]
郭子楠、吴言泽、陈卓伟、陈朗、何倩。 技术报告 2024年。
MultiBooth:从文本生成包含所有概念的图像。 [项目] [论文] [代码]
朱晨阳、李凯、马月、何春明、修丽。 预印本 2024年。
StyleBooth:通过多模态指令编辑图像风格。 [项目] [论文] [代码]
韩震、毛超杰、蒋泽音、潘玉琳、张景峰。 预印本 2024年。
MoMA:用于快速个性化图像生成的多模态LLM适配器。 🔥 [项目] [论文] [代码]
Kunpeng Song, Yizhe Zhu, Bingchen Liu, Qing Yan, Ahmed Elgammal, Xiao Yang. ECCV'24。
Zezhong Fan, Xiaohan Li, Chenhao Fang, Topojoy Biswas, Kaushiki Nag, Jianpeng Xu, Kannan Achan. WWW'24。
MoA:用于个性化图像生成中主体与上下文解耦的注意力混合机制。 [项目] [论文] [代码]
Kuan-Chieh Wang, Daniil Ostashev, Yuwei Fang, Sergey Tulyakov, Kfir Aberman. 2024年预印本。
MaxFusion:文生图扩散模型中的即插即用多模态生成。 [项目] [论文] [代码]
Nithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, Vishal M Patel. ECCV'24。
Ctrl-Adapter:一种高效且通用的框架,可将多种控制方式适配到任何扩散模型。 [项目] [论文] [代码]
Han Lin, Jaemin Cho, Abhay Zala, Mohit Bansal. 2024年预印本。
ControlNet++:通过高效的连贯性反馈改进条件控制。 [项目] [论文] [代码]
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, Chen Chen. ECCV'24。
面向多主体个性化的文生图模型身份解耦技术。 [项目] [论文]
Sangwon Jang, Jaehyeong Jo, Kimin Lee, Sung Ju Hwang. 2024年预印本。
Concept Weaver:实现文生图模型中的多概念融合。 [论文]
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron. CVPR'24。
FlashFace:高保真度身份保留的人像个性化生成。 [项目] [论文] [代码]
Shilong Zhang, Lianghua Huang, Xi Chen, Yifei Zhang, Zhi-Fan Wu, Yutong Feng, Wei Wang, Yujun Shen, Yu Liu, Ping Luo. 2024年预印本。
做你自己:用于多主体文生图生成的有界注意力机制。 [项目] [论文] [代码]
Omer Dahary, Or Patashnik, Kfir Aberman, Daniel Cohen-Or. ECCV'24。
通过识别语义方向实现T2I模型中的连续主体特异性属性控制。 [项目] [论文] [代码]
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Vincent Tao Hu, Björn Ommer. 2024年预印本。
Make-Your-3D:快速且一致的主体驱动型3D内容生成。 [项目] [论文] [代码]
Fangfu Liu, Hanyang Wang, Weiliang Chen, Haowen Sun, Yueqi Duan. ECCV'24。
FeedFace:基于扩散模型的高效推理式人脸个性化。 [论文] [代码]
Chendong Xiang, Armando Fortes, Khang Hui Chua, Hang Su, Jun Zhu. Tiny Papers @ ICLR'24。
用于图像生成的多LoRA组合。 [项目] [论文] [代码]
钟明、沈烨龙、王硕航、陆亚东、焦一竹、欧阳思儒、于东汉、韩家伟、陈伟柱。 预印本 2024年。
Gen4Gen:面向生成式多概念组合的生成式数据流水线。 [项目] [论文] [代码]
叶春孝、程大英、谢荷妍、林传恩、马毅、安德鲁·马卡姆、尼基·特里戈尼、H.T. 康格、陈宇贝。 技术报告 2024年。
通过交换式自注意力进行视觉风格提示。 [项目] [论文] [代码]
郑在锡、金俊浩、崔允洁、李佳莹、禹英中。 预印本 2024年。
RealCompo:现实感与构图之间的动态平衡提升文本到图像扩散模型。 [论文] [代码]
张新晨、杨凌、蔡雅琪、俞兆辰、谢嘉克、田野、徐敏凯、唐勇、杨宇久、崔斌。 预印本 2024年。
用于组合型文本到图像个性化的直接一致性优化。 [项目] [论文] [代码]
李京民、郭尚京、孙基赫、申振宇。 预印本 2024年。
InstanceDiffusion:图像生成中的实例级控制。 [项目] [论文] [代码]
王旭东、特雷弗·达雷尔、赛·萨凯斯·兰巴特拉、罗希特·吉达尔、伊山·米斯拉。 CVPR'24。
无需训练的一致性文本到图像生成。 [项目] [论文]
约阿德·特韦尔、奥姆里·卡杜里、里农·加尔、约尼·卡斯滕、利奥尔·沃尔夫、加尔·切奇克、尤瓦尔·阿茨蒙。 SIGGRAPH'24。
UNIMO-G:通过多模态条件扩散实现统一的图像生成。 🔥 [项目] [论文]
李伟、许雪、刘嘉晨、肖欣燕。 ACL'24。
掌握文本到图像扩散:利用多模态LLM进行重新描述、规划和生成。 🔥 [论文] [代码]
杨凌、俞兆辰、孟晨琳、徐敏凯、斯特凡诺·埃尔蒙、崔斌。 ICML'24。
InstantID:零样本身份保留生成,几秒钟内完成。 [项目] [论文] [代码]
王启勋、白旭、王浩帆、秦泽奎、安东尼·陈、李华夏、唐旭、胡耀。 技术报告 2024年。🔥
PALP:文本到图像模型的提示对齐个性化。 [项目] [论文]
王启勋、白旭、王浩帆、秦泽奎、安东尼·陈。 预印本 2024年。
SCEdit:通过跳过连接编辑实现高效可控的图像扩散生成。 [项目] [论文] [代码]
蒋泽音、毛超杰、潘玉林、韩震、张景峰。 CVPR'24。
PhotoMaker:通过堆叠ID嵌入定制逼真的人像照片。 [项目] [论文] [代码]
李振、曹明登、王新涛、齐仲刚、程明明、单颖。 CVPR'24。🔥
上下文扩散:上下文感知的图像生成。 [项目] [论文]
伊沃娜·纳杰登科斯卡、阿尼梅什·辛哈、阿比曼纽·杜贝、德鲁夫·马哈詹、维格内什·拉马纳坦、菲利普·拉德诺维奇。 ECCV'24。

通过共享注意力实现风格对齐的图像生成。 🔥 [项目] [论文] [代码]
阿米尔·赫兹、安德烈·沃伊诺夫、什洛米·弗鲁赫特、丹尼尔·科恩-奥尔。 CVPR'24。

视觉字谜:利用扩散模型生成多视角光学幻象。 [项目] [论文] [代码]
丹尼尔·耿、朴仁范、安德鲁·欧文斯。 CVPR'24。
MagicPose:基于身份感知扩散模型的真实人体姿态与面部表情重定向。 [项目] [论文] [代码]
迪昌、史一春、高权凯、杰西卡·傅、徐宏毅、宋国贤、严青、杨晓、穆罕默德·索莱曼尼。 ICML'24。
被选中的人:文本到图像扩散模型中的一致性角色。 [项目] [论文] [代码]
奥姆里·阿夫拉米、阿米尔·赫兹、雅埃尔·温克尔、摩阿布·阿拉尔、什洛米·弗鲁赫特、欧哈德·弗里德、丹尼尔·科恩-奥尔、丹尼·利希金斯基。 SIGGRAPH'24。
用于零样本外观迁移的跨图像注意力。 [项目] [论文] [代码]
尤瓦尔·阿拉卢夫、丹尼尔·加里比、奥尔·帕塔什尼克、哈达尔·阿韦尔布赫-埃洛尔、丹尼尔·科恩-奥尔。 SIGGRAPH'24。
Kosmos-G:利用多模态大型语言模型在上下文中生成图像 🔥 [项目] [论文] [代码]
潘熙晨、董力、黄绍涵、彭志良、陈文虎、魏福儒。 ICLR'24。

InstantBooth:无需测试时微调的个性化文本到图像生成。 [论文]
石静、熊伟、林哲、郑贤俊。 CVPR'24。
2023年
ZipLoRA:通过有效合并LoRA实现任意主题、任意风格的生成。 [项目] [论文]
维拉吉·沙阿、纳塔尼尔·鲁伊斯、福雷斯特·科尔、艾丽卡·卢、斯维特兰娜·拉泽布尼克、李元振、瓦伦·詹帕尼。 2023年预印本。
IP-Adapter:兼容文本的图像提示适配器,用于文本到图像扩散模型。 🔥 [项目] [论文] [代码]
胡叶、张军、刘思博、韩晓、杨伟。 2023年技术报告。
-
纪尧姆·库瓦龙、玛琳·卡雷尔、马蒂厄·科尔德、斯蒂芬·拉图耶尔、雅各布·费尔贝克。 ICCV'23。
通过正交微调控制文本到图像扩散。 [项目] [论文] [代码]
邱泽宇、刘伟阳、冯海文、薛宇轩、冯瑶、刘震、张丹、阿德里安·韦勒、伯恩哈德·舍尔科普夫。 NeurIPS'23。
Face0:将文本到图像模型瞬间条件化为一张人脸。 [论文]
达尼·瓦列夫斯基、丹尼·瓦瑟曼、约西·马蒂亚斯、亚尼夫·列维坦。 SIGGRAPH Asia'23。
StyleDrop:以任意风格生成文本到图像。 🔥 [项目] [论文]
苏基赫、纳塔尼尔·鲁伊斯、金民李、丹尼尔·卡斯特罗·钦、伊琳娜·布洛克、常慧雯、贾瑞德·巴伯、江璐、格伦·恩蒂斯、李元振、袁浩、伊尔凡·埃萨、迈克尔·鲁宾斯坦、迪利普·克里希南。 NeurIPS'23。

BLIP-Diffusion:用于可控文本到图像生成和编辑的预训练主体表示。 🔥 [项目] [论文] [代码]
李东旭、李俊楠、史蒂文·C·H·霍伊. NeurIPS'23。

-
陈文虎、胡恒祥、李彦东、纳塔尼尔·鲁伊斯、贾旭辉、张明伟、威廉·W·科恩. NeurIPS'23。
T2I-Adapter:学习适配器以挖掘文本到图像扩散模型的更多可控能力。 🔥 [论文] [代码]
牟冲、王新涛、谢良斌、吴延泽、张健、齐中刚、单颖、切晓虎. 2023年技术报告。
向文本到图像扩散模型添加条件控制。 🔥 [论文] [代码]
张吕敏、饶安怡、马尼什·阿格拉瓦拉. ICCV'23。

GLIGEN:开放集接地文本到图像生成。 🔥 [项目] [论文] [代码]
李宇恒、刘浩天、吴庆阳、穆方舟、杨建伟、高建峰、李春元、李永在. CVPR'23。
文本到图像扩散的多概念定制。 [项目] [论文] [代码]
努普尔·库玛丽、张炳亮、理查德·张、埃利·谢赫特曼、朱俊彦. CVPR'23。
DreamBooth:针对主体驱动型生成对文本到图像扩散模型进行微调。 🔥 [项目] [论文]
纳塔尼尔·鲁伊斯、李远振、瓦伦·詹帕尼、雅埃尔·普里奇、迈克尔·鲁宾斯坦、克菲尔·阿伯曼. CVPR'23。

🔗 其他资源#
- 区域提示器 将提示设置到划分的区域。
🌟 其他精彩列表
Awesome-LLM-Reasoning 大型语言模型推理领域的论文与资源合集。
Awesome-Controllable-T2I-Diffusion-Models 文本到图像扩散模型可控生成相关资源合集。
Awesome-LLM-Reasoning 大型语言模型推理领域的论文与资源合集。
Awesome-Controllable-T2I-Diffusion-Models 文本到图像扩散模型可控生成相关资源合集。
✍️ 贡献 #
- 添加一篇新论文或更新现有论文,并思考该工作应归入哪个类别。
- 使用与现有条目相同的格式来描述该工作。
- 添加论文的摘要链接(如果是 arXiv 出版物,则使用
/abs/ 格式)。
/abs/ 格式)。即使你犯了错误,也会有人帮你修正!
贡献者

星标历史

相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
tesseract
Tesseract 是一款历史悠久且备受推崇的开源光学字符识别(OCR)引擎,最初由惠普实验室开发,后由 Google 维护,目前由全球社区共同贡献。它的核心功能是将图片中的文字转化为可编辑、可搜索的文本数据,有效解决了从扫描件、照片或 PDF 文档中提取文字信息的难题,是数字化归档和信息自动化的重要基础工具。 在技术层面,Tesseract 展现了强大的适应能力。从版本 4 开始,它引入了基于长短期记忆网络(LSTM)的神经网络 OCR 引擎,显著提升了行识别的准确率;同时,为了兼顾旧有需求,它依然支持传统的字符模式识别引擎。Tesseract 原生支持 UTF-8 编码,开箱即用即可识别超过 100 种语言,并兼容 PNG、JPEG、TIFF 等多种常见图像格式。输出方面,它灵活支持纯文本、hOCR、PDF、TSV 等多种格式,方便后续数据处理。 Tesseract 主要面向开发者、研究人员以及需要构建文档处理流程的企业用户。由于它本身是一个命令行工具和库(libtesseract),不包含图形用户界面(GUI),因此最适合具备一定编程能力的技术人员集成到自动化脚本或应用程序中