weight-loss
weight-loss 是一个结合数据分析与生酮饮食理念的开源项目,旨在帮助用户通过量化个人健康数据实现有效减重。面对市面上众说纷纭的饮食建议和难以长期坚持的传统节食方案,weight-loss 提倡回归身体本能,利用真实数据分离信号与噪音,找到适合自己的可持续生活方式。
weight-loss 适合希望用科学方法追踪身体状况的普通用户,同时也为熟悉 R 语言的开发者和研究人员提供了可复用的代码框架。其核心亮点在于提供了完整的脚本(如 date-weight.r)和示例数据集,用户只需导入自己的体重记录,即可借助 ggplot2 生成直观的体重变化趋势图。
不同于严格的临床实验,weight-loss 更强调个人化的探索与发现。它不依赖专家权威,而是鼓励用户建立属于自己的数据信任体系。通过可视化代谢过程与饮食干预的关系,weight-loss 让健康管理变得透明且可控,帮助你在纷繁的信息中做出明智决策,轻松开启减重之旅。
使用场景
某互联网公司产品经理张伟长期受肥胖困扰,尝试多种减重方法均未成功。他每日记录饮食和体重却无法发现规律,频繁反弹的体重数据让他陷入迷茫。
没有 weight-loss 时
- 缺乏有效数据可视化手段,手动整理的体重曲线难以发现趋势
- 无法区分饮食调整与偶然波动的因果关系,常因短期数据波动放弃计划
- 无个性化生酮方案指导,盲目限制碳水导致营养失衡
- 无法持续跟踪代谢状态变化,难以调整饮食策略
- 依赖传统节食方法,易陷入"节食-暴食"循环
使用 weight-loss 后
- 通过自动化图表生成清晰看到16个月体重变化趋势,识别出关键转折点
- 利用机器学习算法分离饮食干预与自然波动,确认生酮饮食有效性
- 根据代谢数据动态调整碳水摄入比例,避免营养失衡
- 实时监控酮体水平变化,及时优化饮食结构
- 建立可持续的生酮生活方式,体重稳定下降12公斤
weight-loss 通过机器学习分析代谢数据,将模糊的减重经验转化为可执行的科学方案,帮助用户突破传统节食的局限性。
运行环境要求
- 未说明
未说明
未说明
快速开始
发现酮症:如何有效减肥
以下是过去约16个月我的体重随时间变化的图表:

该图表由本Git仓库中的脚本date-weight.r基于数据集weight.2015.csv生成。它需要安装R和ggplot2。
以下我将描述自己的思考过程、他人的相关见解,以及用于从杂乱数据中提取有效信号的代码。这一“去噪”步骤至关重要,帮助我找到了正确的方向。
本GitHub仓库包含我的代码、问答部分,以及更多阅读资源的链接。
免责声明:
以下内容仅适用于我个人的情况。每个人的身体状况不同,请倾听自己身体的声音。此处提供的代码是为处理您自己的数据而设计的,而非我的数据。
另外,这并非科学实验或研究,而是一次个人的探索与实践之旅。
在说明了这些前提后,我想借用伽利略面对宗教裁判时的态度来表达:进化已在过去的20亿年里不断塑造着所有真核生物、多细胞生物,乃至哺乳动物的代谢机制。三羧酸循环、葡萄糖代谢、胰岛素波动、肝脏中的糖原储存、肉碱、脂肪酶等生理过程,对我和您来说都同样真实。尽管我们的基因和体质可能存在差异——例如有些人胰岛素抵抗更严重——但在最基本的代谢化学层面,我们并不会有太大区别。正是这些化学反应驱动着脂肪的合成与分解。
关键事实与初步观察
- 我曾经相当瘦削。下图是我的第一张DMV驾照照片,上面显示体重为143磅。
- 不幸的是,自从移居美国后,我的体重不断增加。到2015年时,我达到了峰值,比原来重了50多磅。
- 美国正面临肥胖症的流行问题。
- 在美国,经济条件较差的人群中,肥胖率更高。

那么,典型的美国生活方式是否与这场肥胖流行有关呢?经过查阅相关资料,我发现以下几个主要嫌疑因素:
- 快餐随处可见,且价格远低于大多数其他选择。
- 我们购买和食用的食品大多高度加工——可观看纪录片《食品公司》(Food, Inc.)。
- 超市货架上随处可见“无脂肪”和“低脂肪”的标签。
- 许多食品都添加了高果糖玉米糖浆以增甜——可观看纪录片《甜蜜陷阱》(Sugar Coated)。
如同许多其他情况一样,我意识到必须独立思考,摒弃所有所谓的“专家”建议,质疑那些广为接受的观点,比如FDA的“食物金字塔”。我开始倾听自己的身体,依据自己的逻辑和亲自收集的数据做出判断。
一旦我这样做了,效果便随之而来。
哪些方法没有奏效
过去,我曾多次尝试改变饮食习惯。读过阿特金斯的书籍后,我清楚地认识到:过量的碳水化合物确实是导致体重增加的主要因素之一。然而,仅仅意识到这一点,并不足以让我成功。
显然,我的意志力不够强大。我对披萨和面包情有独钟。每次减少碳水化合物摄入,我确实会减掉几磅(通常约5磅),但很快就会崩溃,重新大量进食碳水化合物,结果不仅把减掉的体重全部反弹回来,甚至还更多。我坚持最久的一次饮食调整也只持续了几个月。
很明显,我的方法中缺少某些关键要素。我必须找到它们。虽然我可以增加体育锻炼,比如开始为迷你马拉松训练,但这并不是我真正愿意长期坚持的事情。
我很快意识到,我需要采取一种既能减少碳水化合物摄入、又能融入日常生活的健康方式,而且这种生活方式还应该是可持续的,甚至令人愉悦的,从而成为一种毫不费力的习惯。具体来说,它应该具备以下特点:
- 可以坚持多年
- 不会让人产生打破习惯的冲动
- 对我而言并不困难或令人不快
早期洞见与顿悟时刻
在项目初期,我意识到可以利用机器学习来识别影响体重增减的因素。我采用了一种简单的方法:每天早晨称重,并记录当天的体重以及过去约24小时内所做的一切——不仅包括饮食,还包括是否锻炼、睡眠时间过长或过短等。
我保存的数据文件非常简洁,是一个包含三列的CSV文件:
日期, 晨间体重, 昨日生活方式/食物/行为
最后一列是一个任意长度的列表,由形如单词[:权重]的条目组成。
冒号后面的可选数值权重表示该因素的影响程度高低。若未指定权重,则默认为1:
#
# -- 注释行(忽略)
#
日期,晨间体重,昨日因素
2012-06-10,185.0,
2012-06-11,182.6,沙拉 睡眠 培根 奶酪 茶 半奶油 冰淇淋
2012-06-12,181.0,睡眠 鸡蛋
2012-06-13,183.6,motts水果零食:2 披萨:0.5 面包:0.5 枣:3 减肥苹果 Splenda 牛奶 不睡觉
2012-06-14,183.6,咖啡 糖果:2 鸡蛋 蛋黄酱 奶酪:2 米饭 肉类 面包:0.5 花生:0.4
2012-06-15,183.4,肉类 无糖糖果 沙拉 樱桃:4 面包:0 减肥苹果:0.5 鸡蛋 蛋黄酱 橄榄油
2012-06-16,183.6,凯撒沙拉 面包 葡萄:0.2 帕萨迪纳甜酸奶 减肥苹果:0.5 花生:0.4 热狗
2012-06-17,182.6,葡萄 肉类 开心果:5 花生:5 奶酪 冰糕:5 橙汁:2
# 以此类推 ...
随后,我编写了一个脚本,将该文件转换为vowpal-wabbit训练集的回归格式。在转换后的训练集中,标签(目标特征)是过去24小时内的体重变化量(delta),而输入特征则是导致这一变化的过去约24小时内所做的事情或所吃的食物——直接复制自第三列的内容。
当时我并没有刻意节食,只是在收集数据。
经过对数据按abs(delta)降序部分排序以平滑数据并尝试放大其中微弱信号,再进行四次遍历后,机器学习过程中的误差收敛情况如下所示:

你可以通过整理自己的数据文件、安装所有依赖项,并在此目录下运行make命令来复现我的工作。我还编写了一份包含更详细说明的指南。如果遇到任何问题,请提交issue。
当你在这个目录下输入make时,就会发生一些神奇的事情。
以下是一个典型的输出结果:
$ make
... (为简洁起见,省略了部分输出) ...
特征名称 哈希值 ... 权重 相对得分
不睡觉 143407 ... +0.6654 90.29%
甜瓜 234655 ... +0.4636 62.91%
加糖柠檬水 203375 ... +0.3975 53.94%
跑步混合坚果 174671 ... +0.3362 45.63%
面包 135055 ... +0.3345 45.40%
焦糖核桃 148079 ... +0.3316 44.99%
小圆面包 1791 ... +0.3094 41.98%
... (为简洁起见,省略了部分内容。需要注意的是,数据本身过于嘈杂) ...
待在家 148879 ... -0.2690 -36.50%
培根 64431 ... -0.2998 -40.69%
鸡蛋 197743 ... -0.3221 -43.70%
帕尔马干酪 3119 ... -0.3385 -45.94%
橄榄油 156831 ... -0.3754 -50.95%
半奶油 171855 ... -0.4673 -63.41%
睡眠 127071 ... -0.7369 -100.00%
正数(顶部)的相对得分代表那些会让你增加体重的生活方式选择,而负数(底部)则代表那些会让你减轻体重的选择。
这里是一张基于类似数据集生成的重要性图表:
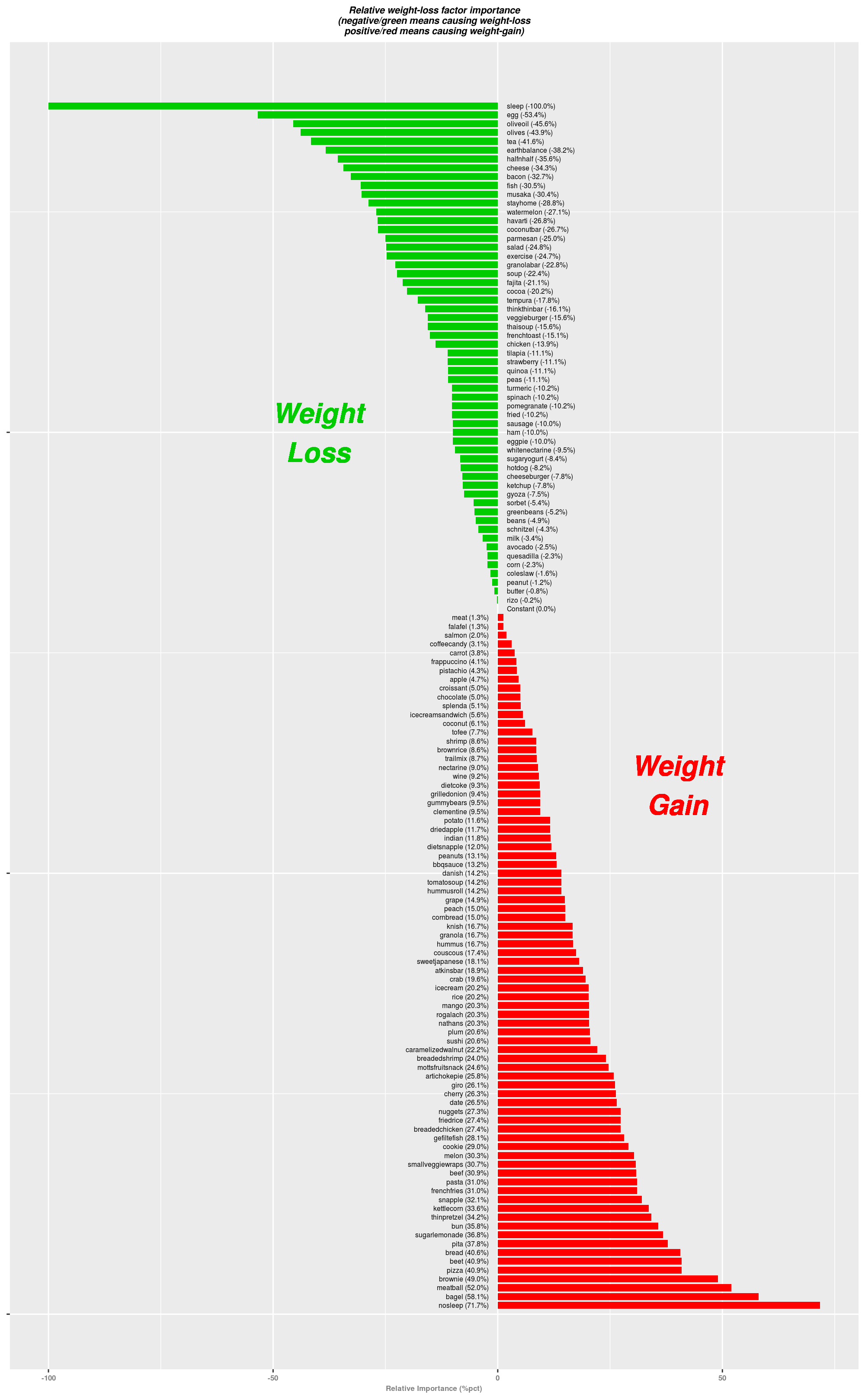
免责声明:请勿过度解读这些数据的具体细节。使用这套特定的数据集进行分析颇具挑战性,原因如下:
- 原始数据点数量(略多于100天)可能太少,难以得出具有统计显著性的结论。
- 日常体重变化通常非常小,往往只有约0.1磅。
- 我的体重秤精度不足:你可能会注意到我的数据分辨率是0.2磅,这并不理想。强烈建议使用分辨率为0.1磅的体重秤。
- 你也可能注意到,即使多次遍历数据(过度拟合训练集),损失收敛曲线也会在约0.2处达到平台期,这也是同样的原因。
- 导致体重增加和减少的因素常常出现在同一行中,从而相互抵消,这会使自动学习过程偏离方向。
- 原始数据中存在一些拼写错误(我希望现在已经全部修正了)。
因此,我主要关注上述列表中的极端情况(开头和结尾),并将这些提示作为进一步研究、实验和行动的总体指导。
尽管数据嘈杂且不充分,权重标注也存在误差,但机器学习实验还是在早期就清晰地揭示了四个事实:
- 长时间睡眠始终被确认为减轻体重的第一重要因素。
- 缺乏睡眠则相反:睡眠不足会导致体重增加。
- 碳水化合物会让我体重增加,尤其是高淀粉和含糖食物。
- 脂肪和油腻食物则倾向于产生相反的效果:它们与体重减轻呈正相关。
“待在家”这种生活方式主要发生在周末,可能只是一个误导性因素:我不用通勤上班时确实睡得更久;另一方面,我在家里的饮食习惯也可能有所不同。
关于睡眠这一点,我花了一段时间才弄明白。当我们睡觉时,我们不会进食。就这么简单。
此外,我们在并不特别饥饿的时候往往会暴饮暴食或零食不断,但在睡眠期间却绝不会如此。
我们的睡眠时间实际上是我们每日最长的禁食时段。
请注意,我对这些效应的解释未必准确或具备深厚的科学依据。 这一切的目标都是逐步发现:实验、观察效果、重复操作。
更进一步的进展
你可能会注意到,在上方的图表(日期对比体重)中,减重速度出现了显著加快。其原因在于,随着我对问题理解的加深,我获得了更深入的洞察,并且更有能力坚持饮食计划。
延长空腹时间是加速减重的一个重要因素。我是通过以下方式做到的:
- 跳过早餐,
- 并在晚上睡前更早停止进食。
这样一来,我每天的空腹时间达到了14到16小时,而通常的空腹时间仅为10到12小时。
第二个加速因素是摄入富含脂肪的食物(而非碳水化合物),以帮助自己保持饱腹感。
第三个加速因素则是对血糖指数和血糖负荷概念的理解,并在我选择食物时尽量偏向低血糖负荷的选项。
我现在相信并希望,自己能够完全恢复到刚踏上美国土地时的初始体重。
如果我能维持目前的减重速度,大约需要1到2年的时间,就能彻底扭转过去近20年造成的身体负担。
需要强调的是,随着体重的减轻,我的整体感觉也变得更好。作为一项令人欣喜的副作用,在我减重的过程中,血液检查中原本处于临界值或偏高水平的几项指标,已经显著向正常范围靠拢。
我的数据与明显的健康改善说明了什么?
通过分析自己的数据并进一步学习,我更加确信,应当警惕那些推荐他汀类药物却不愿建议改善饮食的医生。我也开始质疑任何告诉我需要“减少”脂肪摄入的人。如今,只要有人再跟我说“饮食中的高胆固醇”很危险,我就会立刻远离他们。
顺便一提,胆固醇是许多重要体内代谢产物不可或缺的原料。肝脏会根据我们的需求自行合成所需的胆固醇量。
人体是一台极其精密而神奇的机器。经过数十亿年的进化,它具备极强的适应性。
真正导致我们体内脂肪堆积、健康受损的,并不是高脂肪摄入,而是脂肪储存的过程。
一种名为脂肪酶的酶能够分解脂肪。提高脂肪酶的水平,就能让体内的脂肪更快地被消耗掉。要做到这一点,我们需要为身体提供脂肪作为碳水化合物的替代来源。当血液中的糖分以及肝脏内储存的糖原缓冲耗尽后,身体别无选择,只能适应并进行补偿。此时,我们的能量来源——ATP的合成——会从依赖碳水化合物转向利用脂肪,同时增加脂肪分解酶的分泌。可以说,人体就像一台“柔性燃料”发动机,只不过将一种燃料(碳水化合物)替换成了另一种燃料(脂肪)。
当脂肪转化为ATP的整个化学途径中的关键酶,包括脂肪酶在内的各种分解酶被充分动员并提升活性时,我们就能持续燃烧更多脂肪,从而实现长期的减重效果。
在低碳高脂(LCHF)的饮食模式下,夜晚的睡眠时间(即空腹时间)反而成了我们的朋友。因为在睡眠期间,脂肪分解酶仍在持续工作,不断分解体内储存的脂肪。这不仅有助于减重,还能使身体更加健康。
而如果我们进一步降低碳水化合物的摄入量,使其降至极低水平,就有可能进入一种新的稳定状态——酮症。在这种状态下,我们几乎所有的能量都来源于脂肪,而这正是我们在减重之战中取得重大胜利的关键时刻。
以上内容是对一些饮食书籍用数百页篇幅所阐述内容的高度简化版本,希望能让大家更容易理解和接受。
我的终极饮食法则:
最难的部分(尤其是刚开始时)就是减少碳水化合物的摄入。最糟糕的是富含淀粉的食物(披萨、意大利面、面包等),其次是含糖量高的加工食品(甜饮料、无果肉果汁等)。但这并不意味着完全不吃碳水化合物。你可以偶尔允许自己摄入一些碳水化合物(比如每周吃一次披萨)。事实证明,偶尔的放纵并不会完全逆转你已经建立起来的稳定状态。不过,你需要确保现在的碳水化合物摄入量要比以前少得多,而且频率也要低得多。尤其要避免暴饮暴食薯片、披萨、甜甜圈、意大利面和面包等零食,或者饮用含糖量高的饮料。
在维基百科上查阅血糖指数和血糖负荷。尽量避免高血糖负荷的食物。这样可以防止血糖急剧升高,从而避免胰岛素飙升,并阻止身体的代谢循环从酮症或接近酮症状态重新转回脂肪储存模式。如果你特别喜欢甜食,不妨吃一个橙子,而不是喝橙汁。两者的血糖负荷差异巨大,效果也大不相同。如果一定要在茶或咖啡中加甜味,可以使用一粒Splenda(三氯蔗糖+葡萄糖)甜味剂,或者一滴/一片甜菊糖,其重量通常只有约0.1克,而不是用一茶匙糖(约4.2克,是前者的40倍)。结果是:甜度相似,但血糖负荷和随之而来的血糖水平要低得多。
高脂肪:我已将牛奶换成半奶油,并且正在考虑使用浓稠的(无糖)鲜奶油。它不仅碳水化合物(乳糖)含量更低,脂肪含量更高,而且味道也更好。多吃牛油果、橄榄油、蛋黄酱、椰子油和坚果。对于天然脂肪,我从来不用担心,想吃多少就吃多少。这样做能更容易地控制碳水化合物的摄入。当我摄入足够多的脂肪时,饥饿感会明显减轻,对碳水化合物的渴望也会减少。身体非常善于自我调节:“血液中的脂肪过多,那就增加分解脂肪的酶的分泌”,这样一来,长期来看体重就会下降。最重要的是,我始终避免任何标有‘低脂’或‘脱脂’的产品。食品工业通常会用糖来替代脂肪,这样食物才会更好吃——否则味道会非常糟糕。人们经常提到“坏脂肪”和“好脂肪”的区别。我的观点是:只要是天然的,就没问题。最糟糕的反式脂肪是由食品工业为了延长保质期而人工氢化产生的。饱和脂肪越少越好。单不饱和脂肪(植物油)是最好的,其次是多不饱和脂肪,最后才是动物来源的接近饱和但未完全饱和的脂肪。在我常用的涂抹类食品中:人造黄油:不行;黄油:可以;Earth Balance:没问题。无论如何,即使是饱和度最高的脂肪,最终也会被人体内的自然代谢过程分解并消耗掉。
适量运动。当然,运动越多越好,但对很多人来说可能比较困难。我并没有刻意进行大量运动,只是每天骑自行车上下班,单程大约20分钟,也就是每天40分钟,一周5天。你也可以试着带狗快步遛弯,或者跟着音乐跳尊巴舞。关键是要找到一件你觉得不费力的事情来做,或者找个人一起做,然后每天都坚持一点点。
延长空腹时间: 这是减肥的首要因素。多睡一会儿,在睡前尽早停止进食,醒来后尽量晚一点再开始吃。可以尝试不吃早餐,过一段时间后你会发现早上不再感到饥饿了。经过长时间的空腹,身体的代谢会发生调整。虽然需要ATP能量,但血液中的葡萄糖水平已经很低。肝脏中的糖原也被完全消耗殆尽(这通常需要1到2天几乎不吃或只吃少量碳水化合物),于是身体别无选择,只能开始利用其他能量来源,比如储存的脂肪。这时,分解脂肪的酶活性会提高,而柠檬酸循环的关键路径也会发生逆转。我们不再把多余的碳水化合物转化为脂肪储存起来,而是将储存的脂肪分解为能量。
多吃鸡蛋。它们是脂肪和蛋白质的完美组合,完全不含碳水化合物。我曾读过一篇关于一位活到114岁的日本女性的采访,她保持健康的秘诀之一就是每天吃鸡蛋。我最喜欢的一道菜是炒鸡蛋配烤洋葱(洋葱的碳水化合物含量稍高,但实在太美味了,舍不得放弃)和橄榄。
吃饭时放慢速度,多咀嚼……不要急着吞下去!人类和狗狗一样,往往吃得太快。当你觉得饱了的时候就应该停下来。大脑真正感受到饱腹感通常需要大约20分钟的延迟,所以千万不要暴饮暴食。
更多阅读:
- 克雷布斯循环(又称柠檬酸循环)
- 胰岛素峰值及其影响 -- 身体在糖分过剩与脂肪过剩时的不同反应。
- 血糖指数
- 血糖负荷 -- 比血糖指数更适合用于体重管理的指标。
- 糖原及其在肝脏中的储存
- 酮体
- 酮症 -- 不要与酮症酸中毒混淆
- 生酮饮食
- 我们为什么会发胖:以及该如何应对 / 盖里·陶布斯
- 《好卡路里,坏卡路里》摘要 / 盖里·陶布斯,由Lower Thought整理
- 肥胖密码:解锁减肥的秘密 / 杰森·冯
- 我见过的最佳关于他汀类药物的总结
- 高胆固醇并不会导致心脏病
- 马克·海曼博士对健康饮食的看法(与我的观点略有不同)
纪录片:
更多视频
詹姆斯·麦卡特的一段精彩视频,在“量化自我”活动中拍摄,时长7分41秒,对我启发很大:
问题、解答、评论
致谢
非常感谢以下各位以各种方式为本项目做出贡献,包括评论、参考资料、更正等。
阿纳特·法伊贡、英格丽德·凯恩、汉斯·李、史蒂夫·马姆斯科格、埃亚尔·弗里德曼、希里·肖哈姆、加比·哈雷尔、辛吉、诺亚
更新:2016年8月12日:该项目登上了Hacker News,并一度位居榜首。感谢benkuhn、aab0、zzleeper等人的精彩评论,帮助我进一步完善了内容。
特别感谢约翰·兰福德以及Vowpal Wabbit的众多贡献者。
许可证:
本代码及其他相关材料采用宽松简单的两条款BSD许可证发布。其简要说明为:“只要你不起诉我,也不声称它是你自己的作品,你就没问题。”
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。