echomimic_v3
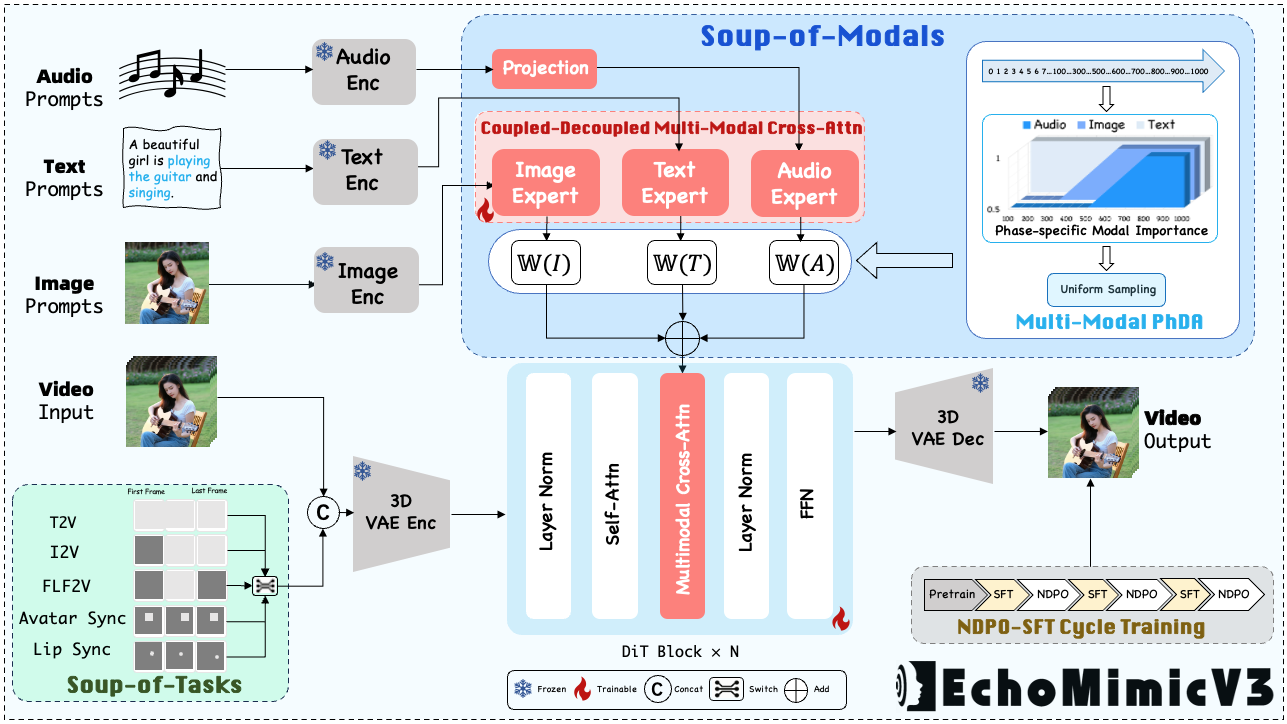
EchoMimicV3 是一款由蚂蚁集团开源的高效人物动画生成模型,旨在通过统一的架构实现多模态、多任务的人体动态驱动。它解决了传统方案中模型庞大、功能单一以及硬件门槛高的问题,仅需 13 亿参数即可同时支持音频驱动、姿态控制等多种输入方式,生成逼真且连贯的全身或半身人物视频。
这款工具特别适合开发者、AI 研究人员以及数字内容创作者使用。对于希望低成本部署高质量动画生成的团队,EchoMimicV3 提供了极佳的性价比;对于设计师而言,它能快速将静态形象转化为生动的动态内容,大幅提升创作效率。
其核心技术亮点在于“小而美”的设计理念。最新的 EchoMimicV3-Flash 版本进一步优化了性能,仅需 12GB 显存即可运行,支持最高 768×768 分辨率的视频生成,并将生成步数压缩至 8 步,显著提升了推理速度。此外,新版本无需面部遮罩处理即可实现自然的面部表情同步,简化了预处理流程。作为 AAAI 2026 的接收论文成果,EchoMimicV3 在保持轻量级的同时,实现了业界领先的生成质量与灵活性,是当前人物动画领域值得关注的开源项目。
使用场景
某短视频 MCN 机构急需为旗下多位知识类博主快速批量生产“口播 + 手势”的真人驱动视频,以应对每日高频的内容更新需求。
没有 echomimic_v3 时
- 多任务流程割裂:制作半身视频需分别调用不同模型处理面部表情和肢体动作,工作流繁琐且容易出错。
- 硬件门槛极高:传统高精度动画方案往往需要 24G 甚至更高显存的顶级显卡,导致中小团队无法本地部署。
- 画面瑕疵明显:生成视频中人物手部与身体连接处常出现断裂或模糊,必须依赖后期手动添加遮罩(Face Mask)进行修补。
- 渲染耗时过长:为了获得清晰画质,通常需要数百步的采样迭代,单条视频生成等待时间长达数分钟。
使用 echomimic_v3 后
- 统一多模态驱动:凭借 1.3B 参数量的统一架构,仅需一次推理即可同时实现精准的面部表情同步与自然流畅的半身手势动画。
- 低显存轻松部署:优化后的架构将显存需求降至 12G,使得主流消费级显卡也能流畅运行,大幅降低了算力成本。
- 原生高质量输出:内置的先进生成机制无需额外添加面部遮罩,直接消除了颈部和手部的拼接瑕疵,画面干净完整。
- 极速高清生成:支持 8 步快速采样即可输出 768×768 分辨率的高清视频,将单条内容的生产时间从分钟级压缩至秒级。
echomimic_v3 通过极低资源消耗实现了多任务统一的高质量人体动画生成,让个人开发者和小团队也能拥有电影级的数字人视频生产能力。
运行环境要求
- Linux
- Windows
- 必需 NVIDIA GPU
- 测试型号:A100 (80G), RTX4090D (24G), V100 (16G)
- 最低显存需求:12GB (Flash 版本/量化 GradioUI),16GB (ComfyUI 预览版)
- CUDA 版本要求:>= 12.1
未说明

快速开始
简体中文 | English

EchoMimicV3: 13亿参数足以实现统一的多模态和多任务人体动画
1核心贡献者 2通讯作者

🌟 EchoMimic系列
- EchoMimicV1:通过可编辑的关键点条件控制,实现逼真的音频驱动肖像动画。GitHub
- EchoMimicV2:迈向震撼、简化且半身的人体动画。GitHub
- EchoMimicV3:13亿参数足以实现统一的多模态和多任务人体动画。GitHub
📢 更新
- [2026.01.22] 🔥 我们在Huggingface上更新了EchoMimicV3-Flash版本。
- 🚀 8步高质量生成。
- 🧩 无需面部遮罩。
- 💾 需要12G显存。
- ✅ 最高支持768×768分辨率。
- [2025.11.09] 🔥 EchoMimicV3已被AAAI 2026接收。
- [2025.08.21] 🔥 EchoMimicV3的Gradio演示已在ModelScope上线。
- [2025.08.12] 🔥🚀 仅需12G显存即可生成视频。请使用此GradioUI。请查看来自@gluttony-10的教程。感谢您的贡献。
- [2025.08.12] 🔥 EchoMimicV3可在16G显存下使用ComfyUI运行。感谢@smthemex的贡献。
- [2025.08.09] 🔥 我们在ModelScope上发布了我们的模型。
- [2025.08.08] 🔥 我们在GitHub上发布了代码echomimic_v3,并在Huggingface上发布了模型[BadToBest/EchoMimicV3]。
- [2025.07.08] 🔥 我们的论文已在arXiv上公开。
🎨 画廊

中文驱动音频
更多演示视频,请参阅项目页面
快速入门
环境搭建
- 测试系统环境:CentOS 7.2/Ubuntu 22.04,CUDA ≥ 12.1
- 测试GPU:A100(80G) / RTX4090D (24G) / V100(16G)
- 测试Python版本:3.10 / 3.11
🛠️Windows安装
请使用一键安装包(提取码:glut)快速开始量化版本。
🛠️Linux安装
1. 创建conda环境
conda create -n echomimic_v3 python=3.10
conda activate echomimic_v3
2. 其他依赖
pip install -r requirements.txt
🧱模型准备
| 模型 | 下载链接 | 备注 |
|---|---|---|
| Wan2.1-Fun-V1.1-1.3B-InP | 🤗 Huggingface | 基础模型 |
| wav2vec2-base | 🤗 Huggingface | 预览用音频编码器 |
| chinese-wav2vec2-base | 🤗 Huggingface | 闪电版音频编码器 |
| EchoMimicV3-preview | 🤗 Huggingface | 预览权重 |
| EchoMimicV3-preview | 🤗 ModelScope | 预览权重 |
| EchoMimicV3-Flash | 🤗 Huggingface | 闪电版权重 |
-- EchoMimicV3-flash-pro的权重组织如下。
./flash/
├── Wan2.1-Fun-V1.1-1.3B-InP
├── chinese-wav2vec2-base
└── transformer
└── diffusion_pytorch_model.safetensors
-- EchoMimicV3-preview的权重组织如下。
./preview/
├── Wan2.1-Fun-V1.1-1.3B-InP
├── wav2vec2-base-960h
└── transformer
└── diffusion_pytorch_model.safetensors
🔑 EchoMimicV3-flash-pro快速推理
bash run_flash.sh
🔑 EchoMimicV3-preview快速推理
python infer_preview.py
对于量化后的EchoMimicV3-preview GradioUI版本:
python app_mm.py
图片、音频、掩码和提示词均在datasets/echomimicv3_demos中提供
小贴士
- 音频CFG:音频CFG
audio_guidance_scale在1.8~2之间效果最佳。提高音频CFG值可以改善唇形同步,而降低音频CFG值则能提升视觉质量。 - 文本CFG:文本CFG
guidance_scale在3~6之间效果最佳。提高文本CFG值有助于更好地遵循提示词,而降低文本CFG值则能提升视觉质量。 - 茶缓存:
teacache_threshold的最佳范围是0~0.1。 - 采样步数:说话头部使用5步,说话全身使用15~25步。
- 长视频生成:若要生成超过138帧的视频,可使用长视频CFG。
- 可尝试将
partial_video_length设置为81、65或更小,以减少显存占用。
📒 引用
若您认为我们的工作对您的研究有帮助,请考虑引用以下论文:
@article{meng2024echomimicv2,
title={EchoMimicV2: 向着引人注目、简化且半身的人体动画迈进},
author={孟朗、张星宇、李宇明、马晨光},
journal={arXiv预印本 arXiv:2411.10061},
year={2024}
}
@article{meng2025echomimicv3,
title={Echomimicv3: 1.3B参数足以实现统一的多模态与多任务人体动画},
author={孟朗、王燕、吴伟鹏、郑若冰、李宇明、马晨光},
journal={arXiv预印本 arXiv:2507.03905},
year={2025}
}
@article{meng2026echotorrent,
title={EchoTorrent: 向着快速、持续且流式的多模态视频生成迈进},
author={孟朗、吴伟鹏、尹英杰、李宇明、马晨光},
journal={arXiv预印本 arXiv:2602.13669},
year={2026}
}
参考文献
- Wan2.1: https://github.com/Wan-Video/Wan2.1/
- VideoX-Fun: https://github.com/aigc-apps/VideoX-Fun/
📜 许可证
本仓库中的模型采用Apache 2.0许可证授权。我们不主张对您生成的内容拥有任何权利,赋予您自由使用这些内容的权利,同时确保您的使用符合本许可证的规定。您需对模型的使用承担全部责任,不得分享任何违反适用法律、伤害个人或群体、传播旨在造成伤害的个人信息、散布虚假信息或针对弱势群体的内容。
🌟 星标历史

常见问题
相似工具推荐
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
GPT-SoVITS
GPT-SoVITS 是一款强大的开源语音合成与声音克隆工具,旨在让用户仅需极少量的音频数据即可训练出高质量的个性化语音模型。它核心解决了传统语音合成技术依赖海量录音数据、门槛高且成本大的痛点,实现了“零样本”和“少样本”的快速建模:用户只需提供 5 秒参考音频即可即时生成语音,或使用 1 分钟数据进行微调,从而获得高度逼真且相似度极佳的声音效果。 该工具特别适合内容创作者、独立开发者、研究人员以及希望为角色配音的普通用户使用。其内置的友好 WebUI 界面集成了人声伴奏分离、自动数据集切片、中文语音识别及文本标注等辅助功能,极大地降低了数据准备和模型训练的技术门槛,让非专业人士也能轻松上手。 在技术亮点方面,GPT-SoVITS 不仅支持中、英、日、韩、粤语等多语言跨语种合成,还具备卓越的推理速度,在主流显卡上可实现实时甚至超实时的生成效率。无论是需要快速制作视频配音,还是进行多语言语音交互研究,GPT-SoVITS 都能以极低的数据成本提供专业级的语音合成体验。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。