Alink
Alink 是由阿里巴巴计算平台 PAI 团队研发的开源机器学习算法平台,基于强大的 Flink 计算引擎构建。它旨在解决大规模数据处理场景下,机器学习算法难以高效运行和扩展的痛点,让用户能够轻松在分布式环境中完成从数据预处理、特征工程到模型训练与预测的全流程任务。
Alink 特别适合数据工程师、算法开发者及科研人员使用。无论是需要处理海量日志的互联网从业者,还是希望快速验证算法模型的研究者,都能通过 Alink 获得稳定的算力支持。其核心亮点在于提供了丰富的通用算法组件库,涵盖分类、回归、聚类等多种主流机器学习任务,并完美支持 Java 和 Python(PyAlink)双语言接口。
借助 PyAlink,用户可以在熟悉的 Jupyter Notebook 环境中以交互式方式编写代码,既能享受 Python 生态的便捷,又能底层调用 Flink 的高性能分布式计算能力,无需关心复杂的集群部署细节。此外,Alink 还配套了详尽的中文教程与插件下载器,大幅降低了学习门槛,帮助用户快速上手并构建高效的机器学习流水线。
使用场景
某电商数据团队需要基于 Flink 构建实时用户行为分析系统,以快速迭代推荐算法模型。
没有 Alink 时
- 开发门槛高:数据科学家需手动编写大量 Java/Scala 代码调用 Flink ML 底层 API,难以发挥 Python 生态优势。
- 算法复用难:缺乏统一的算法组件库,每次新需求都要重复造轮子,特征工程与模型训练逻辑耦合严重。
- 调试周期长:本地模拟大规模流式数据极其困难,代码上线前无法有效验证逻辑,排查错误耗时耗力。
- 运维成本高:自定义算子缺乏标准化监控指标,任务失败时难以快速定位是数据倾斜还是算法收敛问题。
使用 Alink 后
- Python 友好:通过 PyAlink 直接使用 Python 编写流批一体的机器学习管道,无缝衔接 Pandas 与 Jupyter 工作流。
- 组件丰富:直接调用 Alink 内置的数十种标准化算法组件(如特征标准化、随机森林),像搭积木一样构建复杂链路。
- 即时反馈:利用
useLocalEnv在本地轻松模拟并行环境,秒级预览中间结果,大幅缩短从想法到验证的闭环时间。 - 生产就绪:依托 Flink 原生能力,一键将本地调试好的脚本部署为高可用集群任务,自动处理容错与状态管理。
Alink 让算法工程师能专注于业务逻辑创新,而非底层分布式框架的繁琐实现,真正实现了机器学习的高效落地。
运行环境要求
- 未说明
未说明
未说明

快速开始
English| 简体中文
Alink
Alink是基于Flink的通用算法平台,由阿里巴巴计算平台PAI团队研发,欢迎大家加入Alink开源用户钉钉群进行交流。

- Alink组件列表:http://alinklab.cn/manual/index.html
- Alink教程:http://alinklab.cn/tutorial/index.html
- Alink插件下载器:https://www.yuque.com/pinshu/alink_guide/plugin_downloader
Alink教程

- Alink教程(Java版):http://alinklab.cn/tutorial/book_java.html
- Alink教程(Python版):http://alinklab.cn/tutorial/book_python.html
- 源代码地址:https://github.com/alibaba/Alink/tree/master/tutorial
- Java版的数据和资料链接:http://alinklab.cn/tutorial/book_java_00_reference.html
- Python版的数据和资料链接:http://alinklab.cn/tutorial/book_python_00_reference.html
- Alink教程(Java版)代码的运行攻略 http://alinklab.cn/tutorial/book_java_00_code_help.html
- Alink教程(Python版)代码的运行攻略 http://alinklab.cn/tutorial/book_python_00_code_help.html
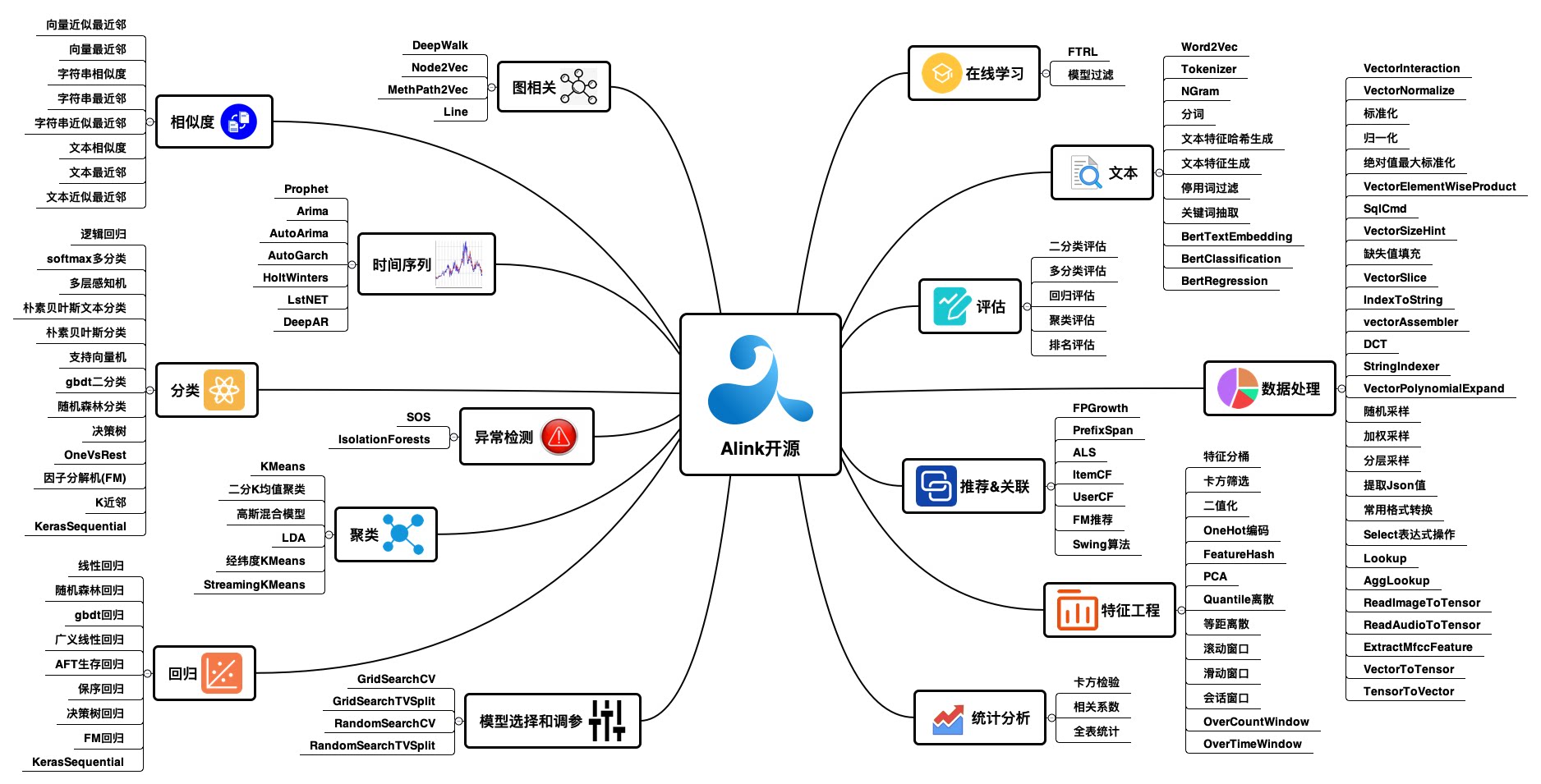
开源算法列表
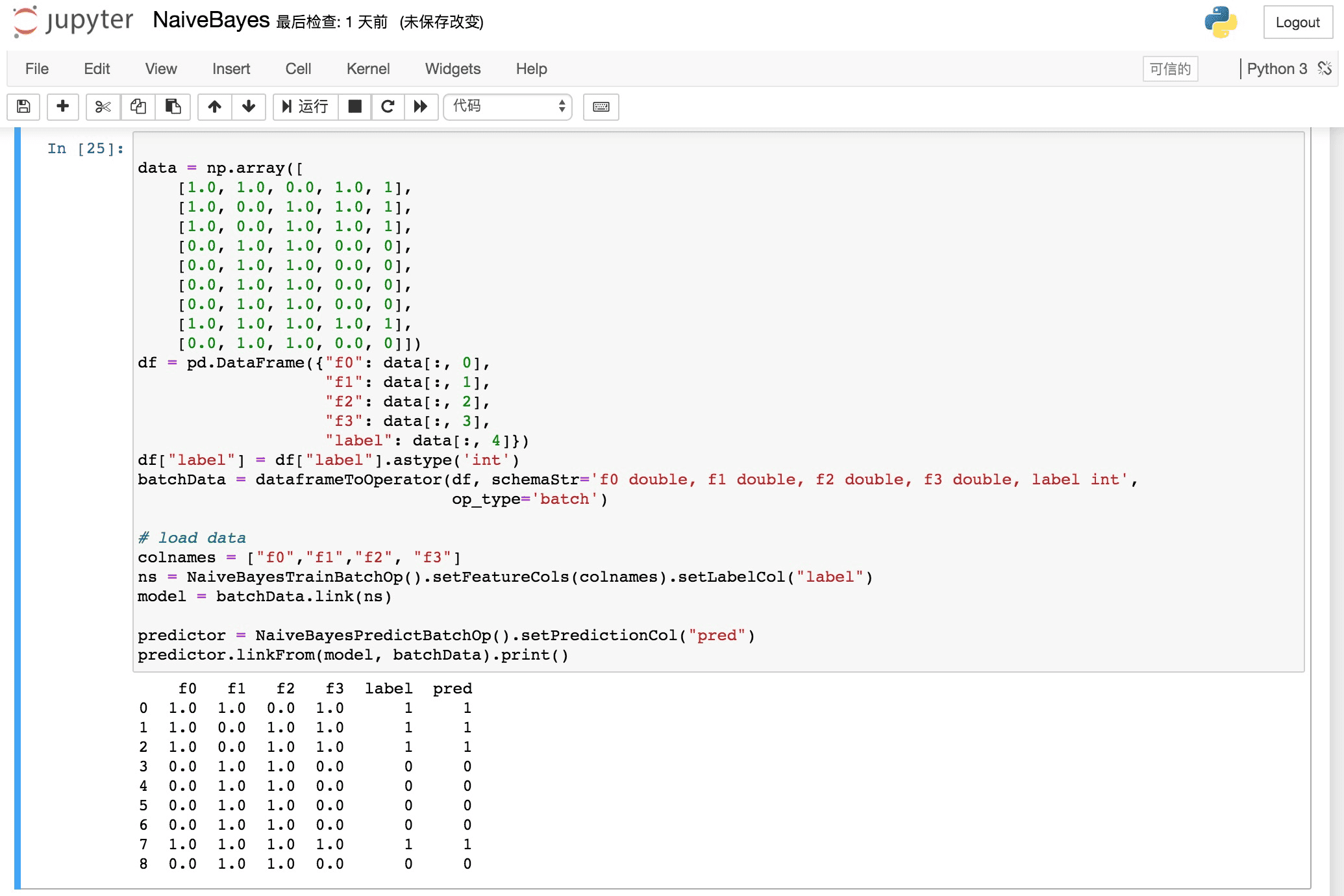
PyAlink 使用截图
快速开始
PyAlink 使用介绍
使用前准备:
包名和版本说明:
- PyAlink 根据 Alink 所支持的 Flink 版本提供不同的 Python 包:
其中,
pyalink包对应为 Alink 所支持的最新 Flink 版本,当前为 1.13,而pyalink-flink-***为旧版本的 Flink 版本,当前提供pyalink-flink-1.12,pyalink-flink-1.11,pyalink-flink-1.10和pyalink-flink-1.9。 - Python 包的版本号与 Alink 的版本号一致,例如
1.6.2。
####安装步骤:
- 确保使用环境中有Python3,版本限于 3.6,3.7 和 3.8。
- 确保使用环境中安装有 Java 8。
- 使用 pip 命令进行安装:
pip install pyalink、pip install pyalink-flink-1.12、pip install pyalink-flink-1.11、pip install pyalink-flink-1.10或者pip install pyalink-flink-1.9。
安装注意事项:
pyalink和pyalink-flink-***不能同时安装,也不能与旧版本同时安装。 如果之前安装过pyalink或者pyalink-flink-***,请使用pip uninstall pyalink或者pip uninstall pyalink-flink-***卸载之前的版本。- 出现
pip安装缓慢或不成功的情况,可以参考这篇文章修改pip源,或者直接使用下面的链接下载 whl 包,然后使用pip安装: - 如果有多个版本的 Python,可能需要使用特定版本的
pip,比如pip3;如果使用 Anaconda,则需要在 Anaconda 命令行中进行安装。
开始使用:
可以通过 Jupyter Notebook 来开始使用 PyAlink,能获得更好的使用体验。
使用步骤:
- 在命令行中启动Jupyter:
jupyter notebook,并新建 Python 3 的 Notebook 。 - 导入 pyalink 包:
from pyalink.alink import *。 - 使用方法创建本地运行环境:
useLocalEnv(parallism, flinkHome=None, config=None)。 其中,参数parallism表示执行所使用的并行度;flinkHome为 flink 的完整路径,一般情况不需要设置;config为Flink所接受的配置参数。运行后出现如下所示的输出,表示初始化运行环境成功:
JVM listening on ***
- 开始编写 PyAlink 代码,例如:
source = CsvSourceBatchOp()\
.setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string")\
.setFilePath("https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/iris.csv")
res = source.select(["sepal_length", "sepal_width"])
df = res.collectToDataframe()
print(df)
编写代码:
在 PyAlink 中,算法组件提供的接口基本与 Java API 一致,即通过默认构造方法创建一个算法组件,然后通过 setXXX 设置参数,通过 link/linkTo/linkFrom 与其他组件相连。
这里利用 Jupyter Notebook 的自动补全机制可以提供书写便利。
对于批式作业,可以通过批式组件的 print/collectToDataframe/collectToDataframes 等方法或者 BatchOperator.execute() 来触发执行;对于流式作业,则通过 StreamOperator.execute() 来启动作业。
更多用法:
Java 接口使用介绍
示例代码
String URL = "https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/iris.csv";
String SCHEMA_STR = "sepal_length double, sepal_width double, petal_length double, petal_width double, category string";
BatchOperator data = new CsvSourceBatchOp()
.setFilePath(URL)
.setSchemaStr(SCHEMA_STR);
VectorAssembler va = new VectorAssembler()
.setSelectedCols(new String[]{"sepal_length", "sepal_width", "petal_length", "petal_width"})
.setOutputCol("features");
KMeans kMeans = new KMeans().setVectorCol("features").setK(3)
.setPredictionCol("prediction_result")
.setPredictionDetailCol("prediction_detail")
.setReservedCols("category")
.setMaxIter(100);
Pipeline pipeline = new Pipeline().add(va).add(kMeans);
pipeline.fit(data).transform(data).print();
Flink-1.13 的 Maven 依赖
<dependency>
<groupId>com.alibaba.alink</groupId>
<artifactId>alink_core_flink-1.13_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.13.0</version>
</dependency>
Flink-1.12 的 Maven 依赖
<dependency>
<groupId>com.alibaba.alink</groupId>
<artifactId>alink_core_flink-1.12_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.12.1</version>
</dependency>
Flink-1.11 的 Maven 依赖
<dependency>
<groupId>com.alibaba.alink</groupId>
<artifactId>alink_core_flink-1.11_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.0</version>
</dependency>
Flink-1.10 的 Maven 依赖
<dependency>
<groupId>com.alibaba.alink</groupId>
<artifactId>alink_core_flink-1.10_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
Flink-1.9 的 Maven 依赖
<dependency>
<groupId>com.alibaba.alink</groupId>
<artifactId>alink_core_flink-1.9_2.11</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.9.0</version>
</dependency>
快速开始在集群上运行Alink算法
- 准备Flink集群
wget https://archive.apache.org/dist/flink/flink-1.13.0/flink-1.13.0-bin-scala_2.11.tgz
tar -xf flink-1.13.0-bin-scala_2.11.tgz && cd flink-1.13.0
./bin/start-cluster.sh
- 准备Alink算法包
git clone https://github.com/alibaba/Alink.git
# 在 alink_examples 的 pom.xml 中添加 <scope>provided</scope>。
cd Alink && mvn -Dmaven.test.skip=true clean package shade:shade
- 运行Java示例
./bin/flink run -p 1 -c com.alibaba.alink.ALSExample [path_to_Alink]/examples/target/alink_examples-1.5-SNAPSHOT.jar
# ./bin/flink run -p 1 -c com.alibaba.alink.GBDTExample [path_to_Alink]/examples/target/alink_examples-1.5-SNAPSHOT.jar
# ./bin/flink run -p 1 -c com.alibaba.alink.KMeansExample [path_to_Alink]/examples/target/alink_examples-1.5-SNAPSHOT.jar
部署
版本历史
v1.6.22023/11/03v1.6.12023/03/15v1.6.02022/11/08v1.5.82022/09/08v1.5.72022/07/21v1.5.62022/06/17v1.5.52022/05/10v1.5.42022/04/22v1.5.32022/04/02v1.5.22022/01/07v1.5.12021/11/26v1.5.02021/10/09v1.4.02021/06/11v1.3.22021/02/24v1.3.12021/01/07v1.3.02020/11/30v1.2.02020/07/31v1.1.22020/06/08v1.1.12020/04/20v1.1.02020/02/28常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。