Chatbot
Chatbot 是一款基于 Python 的开源聊天机器人框架,旨在帮助开发者以极少的代码量快速构建功能丰富的智能对话应用。它不仅仅是一个简单的问答引擎,更提供了一个完整的对话管理系统,能够处理记忆保持、条件判断、话题切换及递归逻辑等复杂交互场景,有效解决了传统脚本式机器人灵活性差、难以维护上下文的问题。
该工具特别适合 Python 开发者、AI 爱好者以及需要快速原型验证的研究人员使用。其核心亮点在于强大的扩展能力:支持通过装饰器轻松注册 Python 函数或集成 REST API,让机器人能实时调用外部数据(如维基百科搜索)或执行具体任务。此外,Chatbot 最新集成了 Ollama 与 Llama 3.2 模型,用户无需训练即可在本地部署具备类人对话能力的先进 AI,既保证了回复的连贯性,又避免了云端 API 的成本开销。无论是打造客服助手、个人提醒工具,还是探索复杂的对话逻辑,Chatbot 都提供了简洁而高效的解决方案。
使用场景
一家小型电商初创团队希望为其网站快速构建一个能回答商品库存、处理售后咨询并支持多轮对话的智能客服系统。
没有 Chatbot 时
- 开发人员需从零编写复杂的正则匹配逻辑来识别用户意图,代码冗长且难以维护。
- 实现“查询库存”或“订单状态”等功能时,必须手动编写大量样板代码来调用外部 REST API,集成效率极低。
- 对话缺乏上下文记忆能力,用户一旦切换话题或进行多轮追问,机器人就会“失忆”并重复询问基础信息。
- 无法灵活定义对话流程,遇到条件分支(如区分 VIP 与普通用户)时,逻辑硬编码导致扩展性差。
- 部署成本高,若要获得类人回复往往需要接入昂贵的云端大模型 API,且数据隐私难以保障。
使用 Chatbot 后
- 利用模板化配置即可定义对话逻辑,通过简单的标签语法实现条件判断和话题切换,开发工作量减少 80%。
- 直接注册 Python 函数(如
@register_call)即可无缝对接内部库存数据库或第三方物流 API,功能扩展仅需几行代码。 - 内置的记忆模块自动保存会话状态,支持基于上下文的自然多轮交互,用户体验流畅自然。
- 结合最新集成的 Ollama 与 Llama 3.2 模型,可在本地运行获得高质量拟人回复,既节省了 API 成本又确保了数据安全。
- 提供现成的 Facebook Messenger 和 Microsoft Bot 集成示例,团队可在一天内将原型转化为全渠道客服应用。
Chatbot 通过极简的代码封装和强大的本地 AI 集成,让开发者能以最低成本快速构建具备记忆、逻辑判断及 API 调用能力的专业级智能助手。
运行环境要求
- 未说明
不需要专用 GPU(基于 Ollama 的本地推理,支持 CPU 运行,若有 GPU 可加速)
未说明(建议至少 8GB 以流畅运行 Llama 3.2 模型)
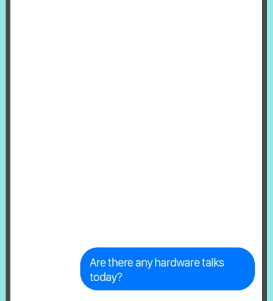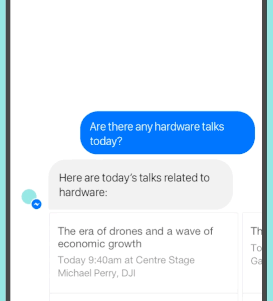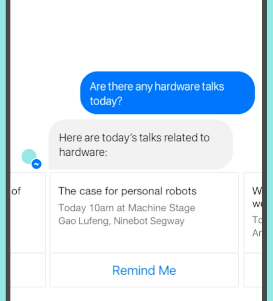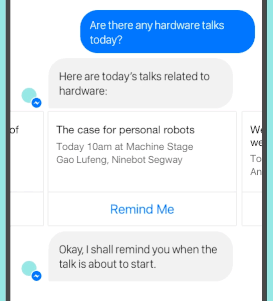
快速开始

![]()
![]()
![]()
ChatBotAI
一款基于 Python 的聊天机器人 AI,能够以最少的代码帮助用户创建 Python 聊天机器人。它不仅提供了 AI 引擎和对话处理器,还支持轻松集成 REST API 和 Python 函数调用,这使得它在功能上更加独特且强大。该 AI 具备学习、记忆、条件切换、基于主题的对话处理等多种功能。
🚀 新增:Ollama 集成
现已支持 Ollama 与 Llama 3.2,提供最先进的 AI 回答!
- 无需训练——直接使用预训练模型
- 对话连贯、接近人类表达
- 本地推理(无 API 费用)
- 请参阅
OLLAMA_SETUP.md获取安装说明
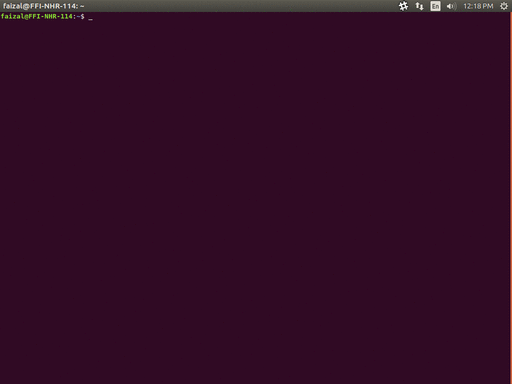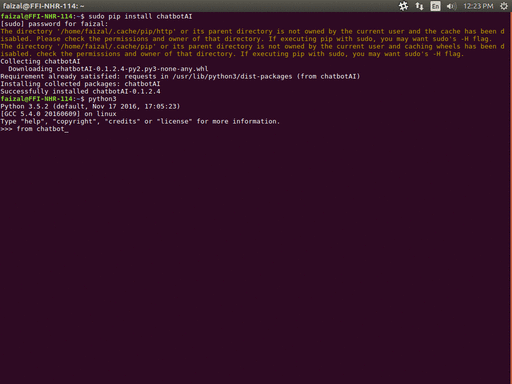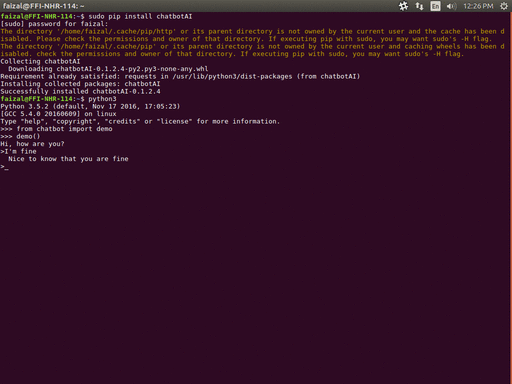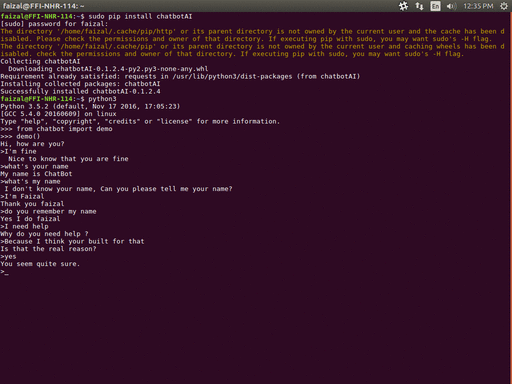
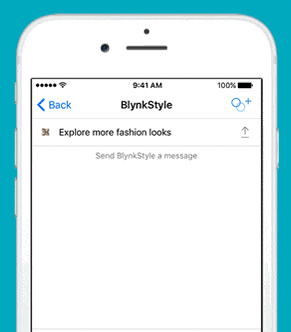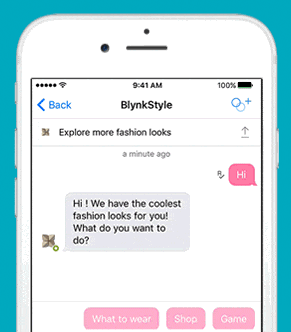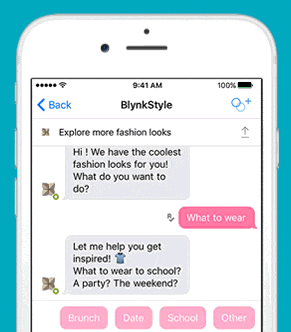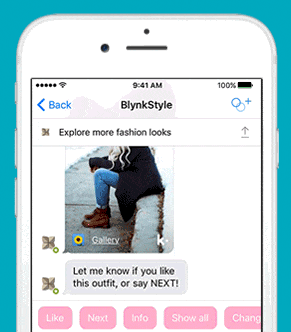
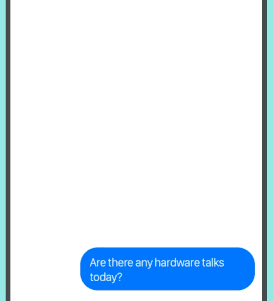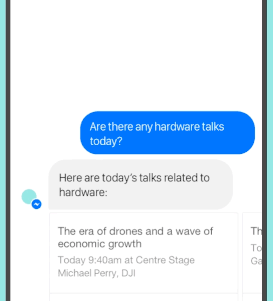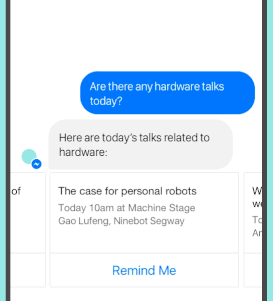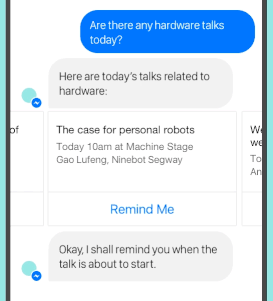
安装
从 PyPI 安装(包含 Ollama 设置):
pip install chatbotAI
安装过程中,系统会提示您安装 Ollama 以获取 AI 回答。
从 GitHub 安装(源码)
- 克隆仓库:
git clone https://github.com/ahmadfaizalbh/Chatbot.git
cd Chatbot
- 安装依赖项:
pip install -r requirement.txt
- 安装包:
python setup.py install
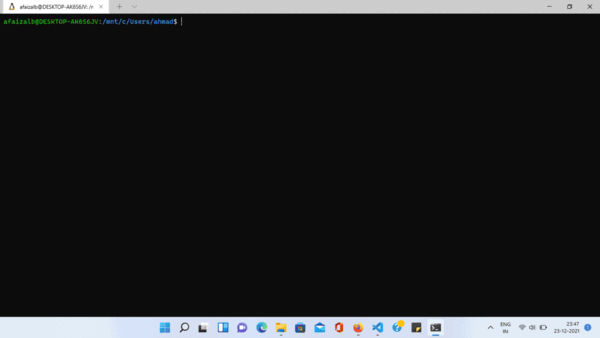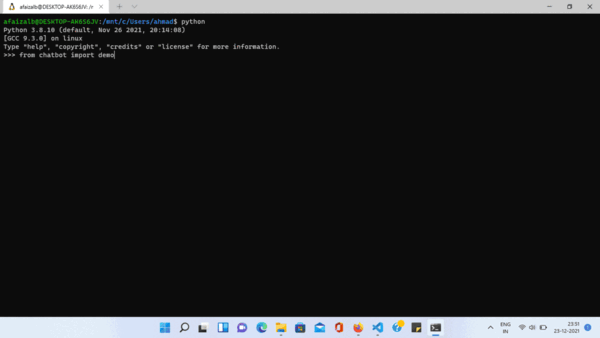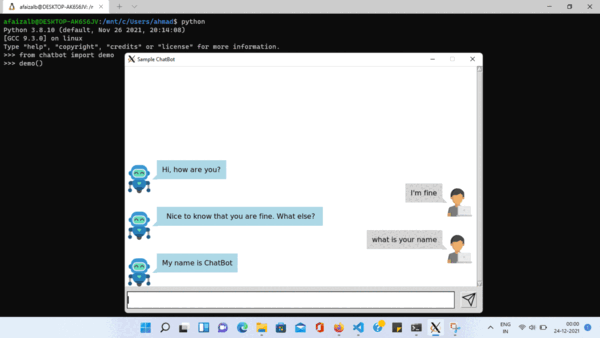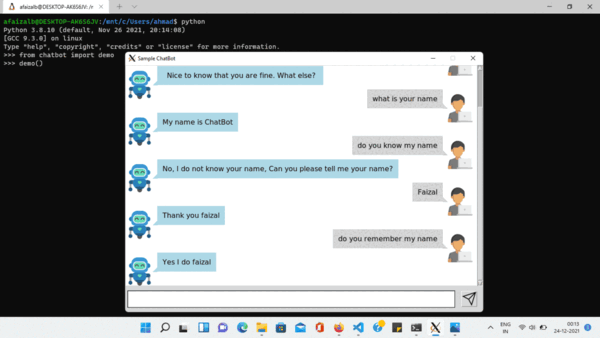
演示
>>> from chatbot import demo
>>> demo()
你好,最近怎么样?
> 我很好
很高兴你一切顺利
> 退出
谢谢你和我聊天。
>>>
示例代码(集成维基百科搜索 API)
from chatbot import Chat, register_call
import wikipedia
@register_call("whoIs")
def who_is(session, query):
try:
return wikipedia.summary(query)
except Exception:
for new_query in wikipedia.search(query):
try:
return wikipedia.summary(new_query)
except Exception:
pass
return "我不太清楚关于 "+query
first_question="你好,最近怎么样?"
Chat("examples/Example.template").converse(first_question)
有关如何构建 Facebook Messenger 机器人,请查看 Facebook Integration.ipynb。
如需 Jupyter Notebook 聊天机器人示例,请参阅 使用 NLTK 聊天机器人构建的 Infobot。
示例应用
- 使用 messengerbot、Django 和 NLTK 聊天机器人 构建的 Facebook Messenger 示例机器人可在 Facebook Messenger 机器人 中找到。
- 使用 Microsoft Bot Connector Rest API - v3.0、Django 和 NLTK 聊天机器人 构建的 Microsoft 示例机器人可在 Microsoft 聊天机器人 中找到。
机器人模板支持的功能列表
记忆
设置记忆
{ 变量 : 值 }
在思考模式下:
{! 变量 : 值 }
获取记忆
{ 变量 }
匹配分组
关于正则表达式中的分组,请参考 Python 正则表达式文档。
获取客户端模式的第 N 个匹配分组
%N
例如,获取第一个匹配:
%1
获取客户端模式的命名分组
%Client_pattern_group_name
例如,获取名为 person 的命名分组:
%person
获取机器人消息模式的第 N 个匹配分组
%!N
例如,获取第一个匹配:
%!1
获取机器人消息模式的命名分组
%!Bot_pattern_group_name
例如,获取名为 region 的命名分组:
%!region
递归
根据客户的新陈述生成响应:
{% chat 陈述 %}
它将对陈述进行模式匹配。
条件
{% if 条件 %} 先执行这个 {% elif 条件 %} 再执行那个 {% else %} 执行其他 {% endif %}
切换主题
{% topic 主题名称 %}
与 Python 函数交互
在 Python 中
@register_call("functionName")
def function_name(session, query):
return "响应字符串"
在模板中
{% call functionName: 值 %}
REST API 集成
在 API.json 文件中
{
"APIName":{
"auth" : {
"url":"https://your_rest_api_url/login.json",
"method":"POST",
"data":{
"user":"Your_Username",
"password":"Your_Password"
}
},
"MethodName" : {
"url":"https://your_rest_api_url/GET_method_Example.json",
"method":"GET",
"params":{
"key1":"value1",
"key2":"value2",
...
},
"value_getter":[从 JSON 响应中提取数据的顺序]
},
"MethodName1" : {
"url":"https://your_rest_api_url/GET_method_Example.json",
"method":"POST",
"data":{
"key1":"value1",
"key2":"value2",
...
},
"value_getter":[从 JSON 响应中提取数据的顺序]
},
"MethodName2" : {
...
},
...
},
"APIName2":{
...
},
...
}
仅当需要身份验证时才需使用 auth 方法。pi.json 文件中定义的 data 和 params 作为默认值,而模板文件中定义的所有键值对都会覆盖这些默认值。value_getter 是一个按顺序排列的键列表,用于从 JSON 响应中提取信息。
在模板文件中
[ API名称:方法名,键1:值1 (,键*:值*) ]
你可以有任意数量的键值对,所有键值对会根据 method 的值来覆盖 data 或 params。如果 method 是 POST,则覆盖 data;如果 method 是 GET,则覆盖 params。
基于主题的分组
{% group 主题名称 %}
{% block %}
{% client %}客户端说 {% endclient %}
{% response %}响应文本{% endresponse %}
{% endblock %}
...
{% endgroup %}
学习
{% learn %}
{% group 主题名称 %}
{% block %}
{% client %}客户端说 {% endclient %}
{% response %}响应文本{% endresponse %}
{% endblock %}
...
{% endgroup %}
...
{% endlearn %}
转为大写
{% up 字符串 %}
转为小写
{% low 字符串 %}
首字母大写
{% cap 字符串 %}
上一条
{% block %}
{% client %}客户端的语句模式{% endclient %}
{% prev %}上一条机器人回复的语句模式{% endprev %}
{% response %}回复字符串{% endresponse %}
{% endblock %}
AI 框架
该库现在使用 Ollama 和 Llama 3.2 来提供最先进的 AI 回答。
特性
- 预训练模型: 无需训练,直接使用先进的语言模型。
- 本地推理: 可在本地运行,无需支付 API 费用,也不依赖互联网。
- 微调: 使用您自己的训练数据创建自定义模型。
- 在线学习: 机器人可以动态学习特定的回复。
- 回退机制: 如果没有匹配的模板模式,Ollama 会生成智能回复。
使用方法
训练
您可以使用文本文件或 URL 对机器人进行训练:
chat = Chat()
# 从书籍或网站训练
chat.train("https://www.gutenberg.org/files/11/11-0.txt", epochs=10)
自我学习
机器人可以从交互中学习:
chat.learn_response("火星的首都是哪里?", "埃隆·马斯克的未来家园。")
AI 回退
AI 集成是自动的。如果用户的问题与任何已定义的模板模式都不匹配,则 converse 方法会调用 ai_converse。
- 如果模型未经过训练,它会回复:“我还没有足够的数据来回答这个问题,请给我训练一下!”
- 一旦经过训练,它就会根据自身的词汇和训练内容生成回复。
 -0.txt", epochs=10)
-0.txt", epochs=10)
#### 自我学习
机器人可以从交互中学习:
```python
chat.learn_response("火星的首都是哪里?", "埃隆·马斯克的未来家园。")
AI 回退
AI 集成是自动的。如果用户的问题与任何已定义的模板模式都不匹配,则 converse 方法会调用 ai_converse。
- 如果模型未经过训练,它会回复:“我还没有足够的数据来回答这个问题,请给我训练一下!”
- 一旦经过训练,它就会根据自身的词汇和训练内容生成回复。
版本历史
v0.3.1.3-beta2021/12/23v0.3.1.2-beta2021/12/16v0.3.1.1-beta2021/11/14v0.3.1.0-beta2021/03/08v0.3.0.0-beta2020/11/05v0.2.2.1-beta2020/08/03v0.2.1.2-beta2020/08/01v0.2.1.1-beta2020/03/10v0.2.1.0-beta2019/12/22v0.2.0.8-beta2019/02/21v0.2.0.7-beta2019/02/18v0.2.0.3-beta2018/05/31v0.1.2.1-beta2017/03/10v0.1.0.2-alpha2016/06/27常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。