lama
LaMa是一款开源的图像修复工具,专攻填补照片中大面积缺失或损坏区域的任务。它解决了传统方法在高分辨率图像(如2000像素以上)或大块缺失区域(比如移除物体后留下的空白)时效果不佳的痛点——许多工具只能处理小范围修复,而LaMa凭借独特的傅里叶卷积技术,即使在训练时仅接触256x256小图,也能在超高分辨率下精准还原细节,尤其擅长修复栅栏、纹理等周期性结构。开发者可轻松集成它到应用中;研究人员能用于图像生成领域的创新实验;设计师可快速清理照片瑕疵;普通用户则能通过Cleanup.pictures等第三方工具一键体验。作为WACV 2022的学术成果,LaMa以高效、易用的特性,为各类用户提供了专业级的图像修复方案,让复杂修复变得简单可靠。
使用场景
一位历史档案馆的数字化专员正在修复一张2000×3000像素的1940年代老照片,照片因潮湿导致右下角50%区域布满霉斑和划痕,需快速恢复原貌用于博物馆线上展览。
没有 lama 时
- 传统修复工具(如Photoshop内容识别)处理高分辨率图像时频繁崩溃,强行操作后修复区域模糊失真,细节严重丢失。
- 大面积霉斑(覆盖人物主体)导致背景生成断裂,出现明显拼接痕迹,需手动逐像素修补耗时超3小时。
- 老照片特有的纸张网格纹理属于周期性结构,修复后网格错位不连贯,破坏历史真实性。
- 商业软件授权费用高昂(单套年费超万元),且对超大遮罩支持薄弱,反复调整参数仍难达专业要求。
- 修复结果无法通过博物馆质检,常需返工重做,延误展览上线进度。
使用 lama 后
- lama的分辨率鲁棒性直接处理2K图像,修复区域清晰锐利,保留原始照片的胶片颗粒质感。
- 傅里叶卷积技术无缝融合霉斑区域,人物与背景自然过渡,5分钟内完成高质量修复。
- 周期性网格纹理修复连贯精准,纸张褶皱和印刷图案完全复原,符合历史档案标准。
- 开源免费集成到工作流,零成本替代商业软件,单张照片处理效率提升36倍。
- 修复结果一次性通过质检,确保展览按时上线,避免项目延期损失。
lama让高分辨率历史影像的大面积修复从耗时费力的难题变为高效精准的标准化流程。
运行环境要求
- Linux
- macOS
推荐 NVIDIA GPU,CUDA 10.2(非必需,支持 CPU 模式)
未说明

快速开始
🦙 LaMa:基于傅里叶卷积(Fourier Convolutions)的分辨率鲁棒大遮罩修复
作者:Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, Victor Lempitsky.
🔥🔥🔥
LaMa 能出人意料地良好泛化到远高于训练分辨率(256x256)的场景(~2k❗️),即使在复杂场景(如周期性结构修复)中也表现出色。
[项目主页] [论文] [补充材料] [BibTeX] [Casual GAN Papers 摘要]
![]()
在 Google Colab 中体验
所有 Yandex 分发链接已失效,可从 https://drive.google.com/drive/folders/1B2x7eQDgecTL0oh3LSIBDGj0fTxs6Ips?usp=sharing 下载模型


LaMa 开发进展
(欢迎通过创建 issue 分享您的论文)
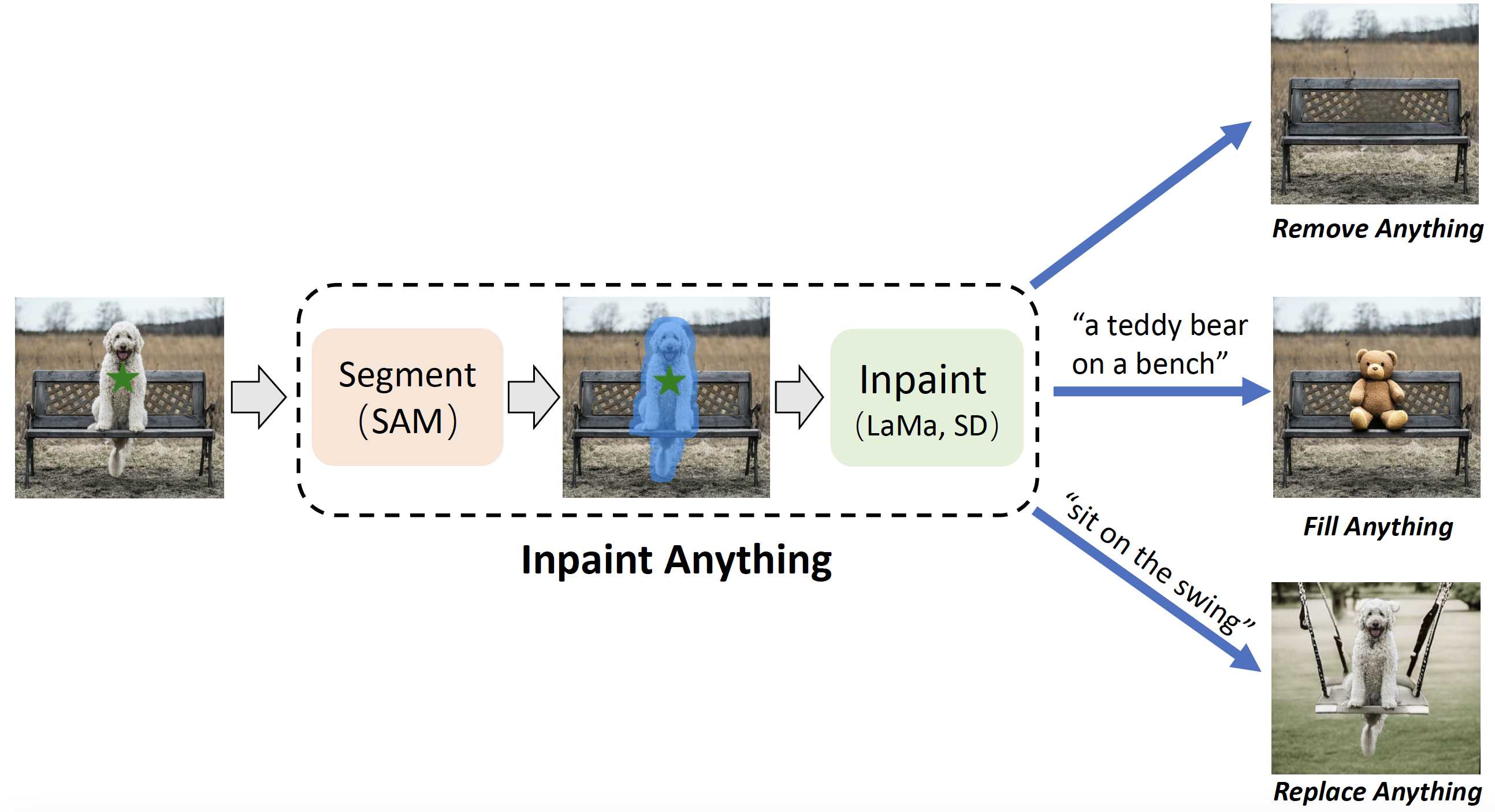
- https://github.com/geekyutao/Inpaint-Anything --- Inpaint Anything:Segment Anything 与图像修复的结合
- 提升高分辨率图像修复的特征优化方法 / 视频 / 代码 https://github.com/advimman/lama/pull/112 / 作者 Geomagical Labs (geomagical.com)

非官方第三方应用:
(欢迎通过创建 issue 分享您的应用/实现/演示)
- https://github.com/enesmsahin/simple-lama-inpainting - LaMa 修复的简易 pip 包
- https://github.com/mallman/CoreMLaMa - 苹果 Core ML 模型格式(Core ML model format)
- https://cleanup.pictures - @cyrildiagne 开发的简易交互式物体移除工具
- lama-cleaner 由 @Sanster 开发,是 https://cleanup.pictures 的自托管版本
- 集成至 Huggingface Spaces 平台,基于 Gradio。查看演示:
作者 @AK391
- Telegram 机器人 @MagicEraserBot 作者 @Moldoteck,代码
- Auto-LaMa = DE:TR 物体检测 + LaMa 修复 作者 @andy971022
- LAMA-Magic-Eraser-Local = 基于 PyQt5 构建的独立修复应用 作者 @zhaoyun0071
- Hama - 采用智能画笔简化遮罩绘制的物体移除工具
- ModelScope = 中文最大模型社区 作者 @chenbinghui1
- LaMa with MaskDINO = MaskDINO 物体检测 + 带优化的 LaMa 修复 作者 @qwopqwop200
- CoreMLaMa - 将 Lama Cleaner 移植的 LaMa 转换为苹果 Core ML 模型格式的脚本
环境配置
❗️❗️❗️ 所有 Yandex 分发链接已失效,可从 Google Drive 下载模型 ❗️❗️❗️
克隆仓库:
git clone https://github.com/advimman/lama.git
提供三种环境配置选项:
Python 虚拟环境(virtualenv):
virtualenv inpenv --python=/usr/bin/python3 source inpenv/bin/activate pip install torch==1.8.0 torchvision==0.9.0 cd lama pip install -r requirements.txtConda
% 安装适用于 Linux 的 conda,其他操作系统请从 https://docs.conda.io/en/latest/miniconda.html 下载 miniconda wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda $HOME/miniconda/bin/conda init bash cd lama conda env create -f conda_env.yml conda activate lama conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch -y pip install pytorch-lightning==1.2.9Docker:无需额外操作 🎉.
推理
运行
cd lama
export TORCH_HOME=$(pwd) && export PYTHONPATH=$(pwd)
1. 下载预训练模型(pre-trained models)
最佳模型(Places数据集和Places Challenge数据集):
curl -LJO https://huggingface.co/smartywu/big-lama/resolve/main/big-lama.zip
unzip big-lama.zip
所有模型(Places数据集和CelebA-HQ数据集):
download [https://drive.google.com/drive/folders/1B2x7eQDgecTL0oh3LSIBDGj0fTxs6Ips?usp=drive_link]
unzip lama-models.zip
2. 准备图像和掩码(masks)
下载测试图像:
unzip LaMa_test_images.zip
或者准备您的数据:
1) 创建掩码文件,命名格式为`[图像名称]_maskXXX[图像后缀]`,将图像和掩码文件放在同一文件夹中。- 可使用脚本生成随机掩码。
- 检查文件格式:
image1_mask001.png image1.png image2_mask001.png image2.png
- 在
configs/prediction/default.yaml中指定image_suffix,例如.png或.jpg或_input.jpg。
3. 预测(Predict)
在主机上运行:
python3 bin/predict.py model.path=$(pwd)/big-lama indir=$(pwd)/LaMa_test_images outdir=$(pwd)/output
或者 在Docker中运行
以下命令将从Docker Hub拉取镜像并执行预测脚本
bash docker/2_predict.sh $(pwd)/big-lama $(pwd)/LaMa_test_images $(pwd)/output device=cpu
Docker CUDA版本:
bash docker/2_predict_with_gpu.sh $(pwd)/big-lama $(pwd)/LaMa_test_images $(pwd)/output
4. 带优化的预测(Predict with Refinement)
在主机上运行:
python3 bin/predict.py refine=True model.path=$(pwd)/big-lama indir=$(pwd)/LaMa_test_images outdir=$(pwd)/output
训练与评估(Train and Eval)
确保已执行:
cd lama
export TORCH_HOME=$(pwd) && export PYTHONPATH=$(pwd)
然后下载用于_感知损失(perceptual loss)_的模型:
mkdir -p ade20k/ade20k-resnet50dilated-ppm_deepsup/
wget -P ade20k/ade20k-resnet50dilated-ppm_deepsup/ http://sceneparsing.csail.mit.edu/model/pytorch/ade20k-resnet50dilated-ppm_deepsup/encoder_epoch_20.pth
Places数据集
⚠️ 注意:我们在LaMa论文中看到的Places数据集FID(Fréchet Inception Distance)/SSIM(结构相似性,Structural Similarity)/LPIPS(学习型感知图像块相似度,Learned Perceptual Image Patch Similarity)指标值,是基于评估部分生成的30000张图像计算得出。 有关评估数据的更多细节,请查阅[附录第3节:数据集划分] ⚠️
在主机上运行:
# 从 http://places2.csail.mit.edu/download.html 下载数据
# Places365-Standard:从高分辨率图像部分下载训练集(105GB)/测试集(19GB)/验证集(2.1GB)
wget http://data.csail.mit.edu/places/places365/train_large_places365standard.tar
wget http://data.csail.mit.edu/places/places365/val_large.tar
wget http://data.csail.mit.edu/places/places365/test_large.tar
# 解压训练/测试/验证数据并创建.yaml配置文件
bash fetch_data/places_standard_train_prepare.sh
bash fetch_data/places_standard_test_val_prepare.sh
# 为测试和每轮次(epoch)结束时的可视化采样图像
bash fetch_data/places_standard_test_val_sample.sh
bash fetch_data/places_standard_test_val_gen_masks.sh
# 启动训练
python3 bin/train.py -cn lama-fourier location=places_standard
# 为评估训练模型并报告论文中的指标
# 需要采样30000张未见过的图像并生成掩码
bash fetch_data/places_standard_evaluation_prepare_data.sh
# 在256和512分辨率的厚/薄/中等掩码上进行推理并运行评估
# 示例:
python3 bin/predict.py \
model.path=$(pwd)/experiments/<user>_<date:time>_lama-fourier_/ \
indir=$(pwd)/places_standard_dataset/evaluation/random_thick_512/ \
outdir=$(pwd)/inference/random_thick_512 model.checkpoint=last.ckpt
python3 bin/evaluate_predicts.py \
$(pwd)/configs/eval2_gpu.yaml \
$(pwd)/places_standard_dataset/evaluation/random_thick_512/ \
$(pwd)/inference/random_thick_512 \
$(pwd)/inference/random_thick_512_metrics.csv
Docker:待补充
CelebA数据集
在主机上运行:
# 确保在lama目录下
cd lama
export TORCH_HOME=$(pwd) && export PYTHONPATH=$(pwd)
# 下载CelebA-HQ数据集
# 从 https://drive.google.com/drive/folders/11Vz0fqHS2rXDb5pprgTjpD7S2BAJhi1P 下载data256x256.zip
# 解压并拆分为训练/测试/可视化数据集,创建配置文件
bash fetch_data/celebahq_dataset_prepare.sh
# 为测试和可视化测试生成掩码
bash fetch_data/celebahq_gen_masks.sh
# 启动训练
python3 bin/train.py -cn lama-fourier-celeba data.batch_size=10
# 在256分辨率的厚/薄/中等掩码上进行推理并运行评估
# 示例:
python3 bin/predict.py \
model.path=$(pwd)/experiments/<user>_<date:time>_lama-fourier-celeba_/ \
indir=$(pwd)/celeba-hq-dataset/visual_test_256/random_thick_256/ \
outdir=$(pwd)/inference/celeba_random_thick_256 model.checkpoint=last.ckpt
Docker:待补充
Places Challenge数据集
在主机上运行:
# 该脚本并行下载多个.tar文件并解压
# Places365-Challenge:从高分辨率图像下载训练集(476GB)(用于训练Big-Lama)
bash places_challenge_train_download.sh
待补充:数据准备
待补充:训练
待补充:评估
Docker:待补充
创建你的数据
如果在以下步骤中遇到问题,请查看 CelebaHQ(名人面部高清数据集)部分的 bash 脚本,用于数据准备和掩码(mask)生成。
在主机上:
# Make shure you are in lama folder
cd lama
export TORCH_HOME=$(pwd) && export PYTHONPATH=$(pwd)
# You need to prepare following image folders:
$ ls my_dataset
train
val_source # 2000 or more images
visual_test_source # 100 or more images
eval_source # 2000 or more images
# LaMa generates random masks for the train data on the flight,
# but needs fixed masks for test and visual_test for consistency of evaluation.
# Suppose, we want to evaluate and pick best models
# on 512x512 val dataset with thick/thin/medium masks
# And your images have .jpg extention:
python3 bin/gen_mask_dataset.py \
$(pwd)/configs/data_gen/random_<size>_512.yaml \ # thick, thin, medium
my_dataset/val_source/ \
my_dataset/val/random_<size>_512.yaml \# thick, thin, medium
--ext jpg
# So the mask generator will:
# 1. resize and crop val images and save them as .png
# 2. generate masks
ls my_dataset/val/random_medium_512/
image1_crop000_mask000.png
image1_crop000.png
image2_crop000_mask000.png
image2_crop000.png
...
# Generate thick, thin, medium masks for visual_test folder:
python3 bin/gen_mask_dataset.py \
$(pwd)/configs/data_gen/random_<size>_512.yaml \ #thick, thin, medium
my_dataset/visual_test_source/ \
my_dataset/visual_test/random_<size>_512/ \ #thick, thin, medium
--ext jpg
ls my_dataset/visual_test/random_thick_512/
image1_crop000_mask000.png
image1_crop000.png
image2_crop000_mask000.png
image2_crop000.png
...
# Same process for eval_source image folder:
python3 bin/gen_mask_dataset.py \
$(pwd)/configs/data_gen/random_<size>_512.yaml \ #thick, thin, medium
my_dataset/eval_source/ \
my_dataset/eval/random_<size>_512/ \ #thick, thin, medium
--ext jpg
# Generate location config file which locate these folders:
touch my_dataset.yaml
echo "data_root_dir: $(pwd)/my_dataset/" >> my_dataset.yaml
echo "out_root_dir: $(pwd)/experiments/" >> my_dataset.yaml
echo "tb_dir: $(pwd)/tb_logs/" >> my_dataset.yaml
mv my_dataset.yaml ${PWD}/configs/training/location/
# Check data config for consistency with my_dataset folder structure:
$ cat ${PWD}/configs/training/data/abl-04-256-mh-dist
...
train:
indir: ${location.data_root_dir}/train
...
val:
indir: ${location.data_root_dir}/val
img_suffix: .png
visual_test:
indir: ${location.data_root_dir}/visual_test
img_suffix: .png
# Run training
python3 bin/train.py -cn lama-fourier location=my_dataset data.batch_size=10
# Evaluation: LaMa training procedure picks best few models according to
# scores on my_dataset/val/
# To evaluate one of your best models (i.e. at epoch=32)
# on previously unseen my_dataset/eval do the following
# for thin, thick and medium:
# infer:
python3 bin/predict.py \
model.path=$(pwd)/experiments/<user>_<date:time>_lama-fourier_/ \
indir=$(pwd)/my_dataset/eval/random_<size>_512/ \
outdir=$(pwd)/inference/my_dataset/random_<size>_512 \
model.checkpoint=epoch32.ckpt
# metrics calculation:
python3 bin/evaluate_predicts.py \
$(pwd)/configs/eval2_gpu.yaml \
$(pwd)/my_dataset/eval/random_<size>_512/ \
$(pwd)/inference/my_dataset/random_<size>_512 \
$(pwd)/inference/my_dataset/random_<size>_512_metrics.csv
或者 在 Docker 中:
TODO: train
TODO: eval
提示
生成不同类型的掩码(mask)
以下命令将执行一个生成随机掩码(mask)的脚本。
bash docker/1_generate_masks_from_raw_images.sh \
configs/data_gen/random_medium_512.yaml \
/directory_with_input_images \
/directory_where_to_store_images_and_masks \
--ext png
测试数据生成命令以适合 预测 的格式存储图像。
下表描述了我们用于从论文中生成不同测试集的配置。请注意,我们不固定随机种子,因此每次结果会略有不同。
| Places 512x512 | CelebA 256x256 | |
|---|---|---|
| 窄掩码 | random_thin_512.yaml | random_thin_256.yaml |
| 中掩码 | random_medium_512.yaml | random_medium_256.yaml |
| 宽掩码 | random_thick_512.yaml | random_thick_256.yaml |
你可以随意将配置路径(参数 #1)更改为 configs/data_gen 中的任何其他配置,或调整配置文件本身。
覆盖配置中的参数
你也可以像这样覆盖配置中的参数:
python3 bin/train.py -cn <config> data.batch_size=10 run_title=my-title
其中 .yaml 文件扩展名被省略。
模型选项
论文中模型的配置名称(替换到训练命令中):
* big-lama
* big-lama-regular
* lama-fourier
* lama-regular
* lama_small_train_masks
这些配置位于 configs/training/ 文件夹中。
链接
- 所有数据(模型、测试图像等) https://disk.yandex.ru/d/AmdeG-bIjmvSug
- 论文中的测试图像 https://disk.yandex.ru/d/xKQJZeVRk5vLlQ
- 预训练模型 https://disk.yandex.ru/d/EgqaSnLohjuzAg
- 用于感知损失的模型 https://disk.yandex.ru/d/ncVmQlmT_kTemQ
- 我们的训练日志可在 https://disk.yandex.ru/d/9Bt1wNSDS4jDkQ 获取
训练时间与资源
TODO
致谢
- 分割代码和模型来自 CSAILVision。
- LPIPS 指标来自 richzhang
- SSIM 来自 Po-Hsun-Su
- FID 来自 mseitzer
引用
如果本代码对你有所帮助,请考虑引用:
@article{suvorov2021resolution,
title={Resolution-robust Large Mask Inpainting with Fourier Convolutions},
author={Suvorov, Roman and Logacheva, Elizaveta and Mashikhin, Anton and Remizova, Anastasia and Ashukha, Arsenii and Silvestrov, Aleksei and Kong, Naejin and Goka, Harshith and Park, Kiwoong and Lempitsky, Victor},
journal={arXiv preprint arXiv:2109.07161},
year={2021}
}
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。