custom-diffusion
Custom Diffusion 是一个用于个性化文本到图像生成的开源工具,源自 CVPR 2023 的研究成果。它允许用户仅用 4 到 20 张图片,快速微调 Stable Diffusion 等扩散模型,让模型学会新概念(如特定物品、宠物或艺术风格),并能将这些概念灵活组合使用——例如同时生成“某只猫坐在某把椅子上”或“用特定画风绘制新物体”。
传统方法往往需要大量数据或完整模型重训,而 Custom Diffusion 通过仅微调交叉注意力层中的键(key)和值(value)投影矩阵,在约 6 分钟内完成训练(使用 2 块 A100 GPU),每个新概念仅增加约 75MB 存储开销,并配合少量正则化图像防止过拟合。
该工具适合 AI 研究人员、开发者及创意工作者使用,尤其适用于希望高效定制多概念图像生成能力的场景。目前官方已集成至 Hugging Face 的 diffusers 库,支持包括 SDXL 在内的主流模型,降低了使用门槛。
使用场景
一位独立游戏开发者正在制作一款以“会说话的复古玩具”为主题的冒险游戏,需要为多个原创角色(如一只穿背带裤的机械兔子、一个戴礼帽的木制小熊)生成大量不同场景下的高质量插图。
没有 custom-diffusion 时
- 只能依赖通用文生图模型(如 Stable Diffusion),但无法准确还原自己设计的独特玩具外观,每次生成的角色细节差异大,风格不统一。
- 若使用 DreamBooth 等全模型微调方法,每新增一个角色需训练整个模型,耗时数小时且显存占用高,难以在消费级 GPU 上完成。
- 每个角色模型体积超过 2GB,存储和管理多个角色定制模型成本高,项目扩展性差。
- 无法在同一画面中同时调用两个自定义角色(如“机械兔子坐在木制小熊旁边”),因为现有方法不支持多概念组合生成。
使用 custom-diffusion 后
- 仅用 4~6 张角色参考图,6 分钟内即可完成单个角色的轻量微调,精准保留原创设计特征。
- 仅更新交叉注意力层中的键值矩阵,每个角色新增参数仅 75MB,可在普通 24GB 显存 GPU 上高效训练与推理。
- 所有定制角色可共用同一个基础模型,极大简化版本管理和部署流程。
- 支持多概念联合提示,例如输入“V* rabbit playing chess with V* bear in a steampunk library”,即可生成两个自定义角色互动的连贯画面。
custom-diffusion 让小型团队也能高效、低成本地实现高度个性化的视觉内容生产,真正将创意控制权交还给创作者。
运行环境要求
- Linux
需要 NVIDIA GPU,推荐 2 张 A100(训练需约 30GB 显存),显存至少 8GB+,CUDA 版本未明确说明但需支持 PyTorch
未说明

快速开始
Custom Diffusion(自定义扩散)
网站 | 论文
[新功能!] Custom Diffusion 现已支持 Hugging Face 的 diffusers 库。训练和推理的详细信息请参见此处。
[新功能!] CustomConcept101 数据集。我们发布了一个包含 101 个概念及其评估提示(evaluation prompts)的新数据集。更多详情请参见此处。
[新功能!] 支持 SDXL 的 Custom Diffusion。diffusers 代码现已更新至 diffusers==0.21.4 版本。

Custom Diffusion 允许你使用少量(约 4–20 张)新概念的图像对文本到图像扩散模型(如 Stable Diffusion)进行微调(fine-tune)。我们的方法速度很快(在 2 块 A100 GPU 上仅需约 6 分钟),因为它只微调模型参数的一个子集,即交叉注意力(cross-attention)层中的键(key)和值(value)投影矩阵。这也使得每个新增概念所需的额外存储空间仅为 75MB。
我们的方法还支持组合多个概念,例如新物体 + 新艺术风格、多个新物体、新物体 + 新类别等。更多可视化结果请参见多概念结果部分。
文本到图像扩散模型的多概念定制化
Nupur Kumari、Bingliang Zhang、Richard Zhang、Eli Shechtman、Jun-Yan Zhu
CVPR 2023
结果
我们所有的结果均基于对 stable-diffusion-v1-4 模型的微调。
我们在多种类别的图像上展示了结果,包括场景、宠物、个人玩具和艺术风格,并使用了不同数量的训练样本。
如需查看更多生成结果以及与同期方法的对比,请访问我们的项目网页和图库。
单概念结果


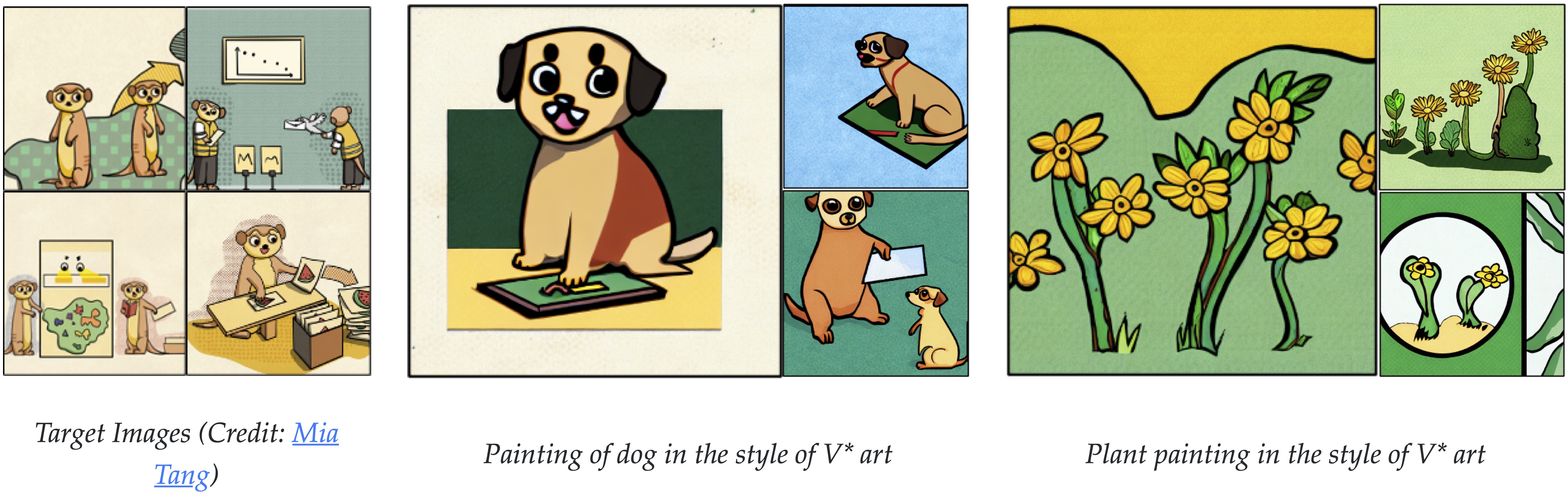
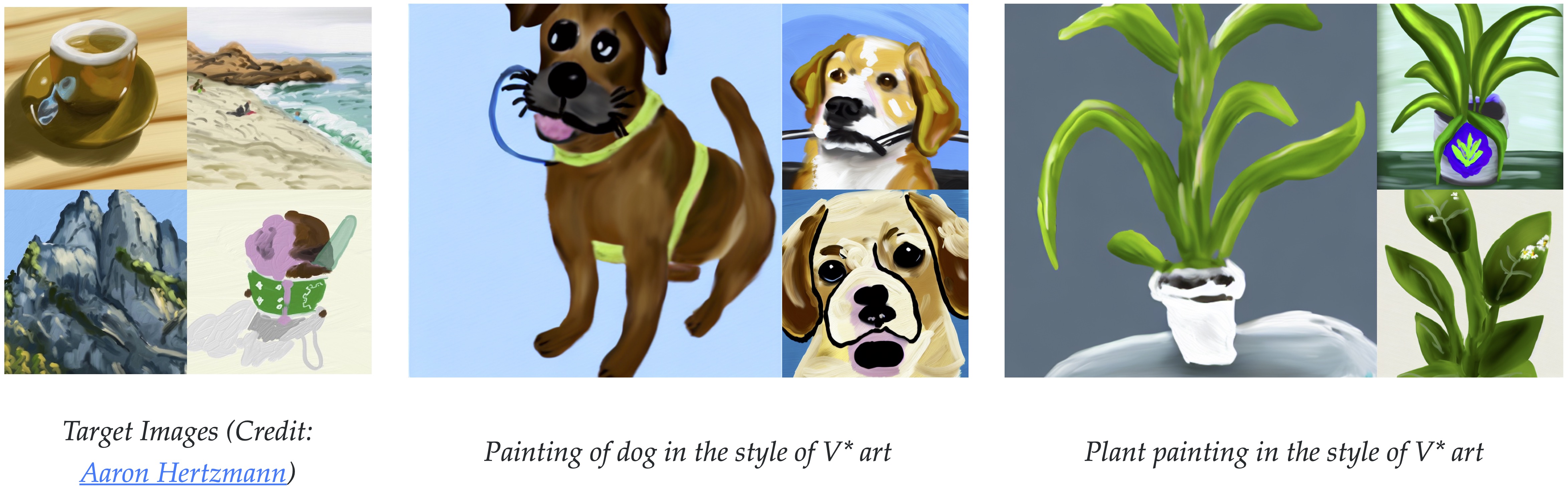




多概念结果




方法细节
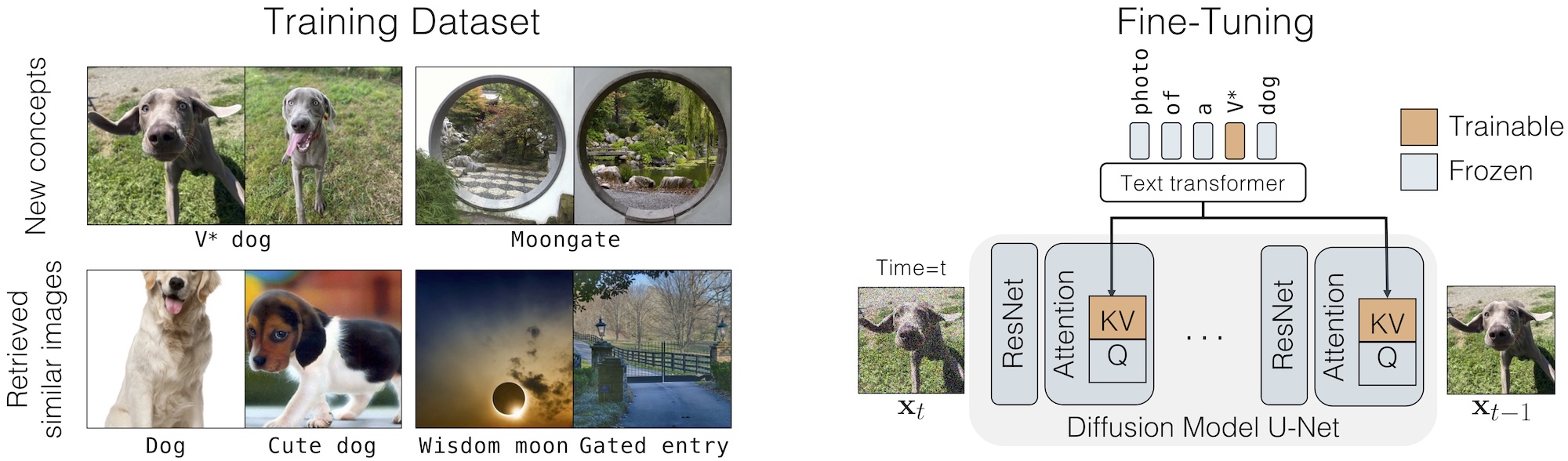
给定用户提供的少量某概念图像,我们的方法对预训练的文本到图像扩散模型进行增强,使其能够在未见过的上下文中生成该新概念。
我们仅微调模型权重的一小部分,即扩散模型交叉注意力层中从文本到潜在特征(latent features)的键(key)和值(value)映射。
我们的方法还使用一小批正则化图像(200 张)来防止过拟合。对于个人类别,我们在类别名称前添加一个新的修饰符 token V*,例如 V* dog。对于多个概念,我们在两个概念的数据集上联合训练。我们的方法还支持通过优化合并两个微调后的模型。更多细节请参阅我们的论文。
快速开始
git clone https://github.com/adobe-research/custom-diffusion.git
cd custom-diffusion
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip install clip-retrieval tqdm
我们的代码基于 stable-diffusion 的以下提交版本开发:#21f890f9da3cfbeaba8e2ac3c425ee9e998d5229。
下载 Stable Diffusion 模型检查点:
wget https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
更多详情请参见此处。
数据集: 我们在此处发布了论文中使用的一些数据集。
其中来自 UnSplash 的图像遵循 UnSplash 许可证。
模型: 所有我们的模型均可从此处下载。
单概念微调
使用真实图像作为正则化样本
## 下载数据集
wget https://www.cs.cmu.edu/~custom-diffusion/assets/data.zip
unzip data.zip
## 开始训练(占用 2 块 GPU 共 30 GB 显存)
bash scripts/finetune_real.sh "cat" data/cat real_reg/samples_cat cat finetune_addtoken.yaml <pretrained-model-path>
## 保存更新后的模型权重
python src/get_deltas.py --path logs/<folder-name> --newtoken 1
## 生成图像
python sample.py --prompt "<new1> cat playing with a ball" --delta_ckpt logs/<folder-name>/checkpoints/delta_epoch\=000004.ckpt --ckpt <pretrained-model-path>
<pretrained-model-path> 是预训练模型 sd-v1-4.ckpt 的路径。我们论文中的结果并未使用 clip-retrieval 来检索真实图像作为正则化样本,但使用该方法也能得到类似效果。
使用生成图像作为正则化样本
bash scripts/finetune_gen.sh "cat" data/cat gen_reg/samples_cat cat finetune_addtoken.yaml <pretrained-model-path>
多概念微调
联合训练
## 开始训练(占用 2 块 GPU 共 30 GB 显存)
bash scripts/finetune_joint.sh "wooden pot" data/wooden_pot real_reg/samples_wooden_pot \
"cat" data/cat real_reg/samples_cat \
wooden_pot+cat finetune_joint.yaml <pretrained-model-path>
## 保存更新后的模型权重
python src/get_deltas.py --path logs/<folder-name> --newtoken 2
示例
python sample.py --prompt "the <new2> cat sculpture in the style of a <new1> wooden pot" --delta_ckpt logs/<folder-name>/checkpoints/delta_epoch\=000004.ckpt --ckpt <pretrained-model-path>
基于优化的权重融合
给定任意两个类别对应的微调模型权重 delta_ckpt1 和 delta_ckpt2,可以按如下方式将它们融合为一个单一模型:
python src/composenW.py --paths <delta_ckpt1>+<delta_ckpt2> --categories "wooden pot+cat" --ckpt <pretrained-model-path>
## 示例
python sample.py --prompt "the <new2> cat sculpture in the style of a <new1> wooden pot" --delta_ckpt optimized_logs/<folder-name>/checkpoints/delta_epoch\=000000.ckpt --ckpt <pretrained-model-path>
使用 Diffusers 库进行训练
[新增功能!] Custom Diffusion 现已支持 diffusers。有关训练和推理的详细信息,请参阅此处。
## 安装依赖
pip install accelerate>=0.24.1
pip install modelcards
pip install transformers>=4.31.0
pip install deepspeed
pip install diffusers==0.21.4
accelerate config
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
单概念微调(Single-Concept fine-tuning)
## 启动训练脚本(推荐使用 2 块 GPU;若仅使用 1 块 GPU,请将 --max_train_steps 增加至 500)
accelerate launch src/diffusers_training.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=./data/cat \
--class_data_dir=./real_reg/samples_cat/ \
--output_dir=./logs/cat \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--instance_prompt="photo of a <new1> cat" \
--class_prompt="cat" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=250 \
--num_class_images=200 \
--scale_lr --hflip \
--modifier_token "<new1>"
## 生成示例
python src/diffusers_sample.py --delta_ckpt logs/cat/delta.bin --ckpt "CompVis/stable-diffusion-v1-4" --prompt "<new1> cat playing with a ball"
你也可以在 accelerate config 配置中启用 --enable_xformers_memory_efficient_attention 和 fp16,以降低显存占用并加速训练。若要使用 SDXL 进行训练,请使用 diffusers_training_sdxl.py 并设置 MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"。
多概念微调(Multi-Concept fine-tuning)
提供一个包含每个概念信息的 json 文件,格式参考 DreamBooth 示例。
## 启动训练脚本(推荐使用 2 块 GPU;若仅使用 1 块 GPU,请将 --max_train_steps 增加至 1000)
accelerate launch src/diffusers_training.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--output_dir=./logs/cat_wooden_pot \
--concepts_list=./assets/concept_list.json \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--num_class_images=200 \
--scale_lr --hflip \
--modifier_token "<new1>+<new2>"
## 生成示例
python src/diffusers_sample.py --delta_ckpt logs/cat_wooden_pot/delta.bin --ckpt "CompVis/stable-diffusion-v1-4" --prompt "<new1> cat sitting inside a <new2> wooden pot and looking up"
多概念的基于优化的权重融合
给定任意两个类别对应的微调模型权重 delta1.bin 和 delta2.bin,可以按如下方式将它们融合为一个单一模型:
python src/diffusers_composenW.py --paths <delta1.bin>+<delta2.bin> --categories "wooden pot+cat" --ckpt "CompVis/stable-diffusion-v1-4"
## 生成示例
python src/diffusers_sample.py --delta_ckpt optimized_logs/<folder-name>/delta.bin --ckpt "CompVis/stable-diffusion-v1-4" --prompt "<new1> cat sitting inside a <new2> wooden pot and looking up"
上述 diffusers 训练代码修改自以下 DreamBooth 和 Textual Inversion 的训练脚本。有关如何配置 accelerate 的更多细节,请参阅此处。
人脸微调
对于人脸微调,我们建议在上述 diffusers 训练脚本中使用 learning_rate=5e-6 和 max_train_steps=750,或在 stable-diffusion 训练脚本中使用 finetune_face.yaml 配置文件。
我们观察到,与论文中展示的其他类别相比,人脸微调需要更低的学习率、更长的训练步数以及更多的图像才能获得更好的效果。当图像数量较少时,对 cross-attention(交叉注意力)层的所有参数进行微调效果略好,可通过添加 --freeze_model "crossattn" 启用该选项。
下图展示了使用 diffusers 训练脚本对 Richard Zhang 的 14 张特写照片进行微调的示例结果。

模型压缩
python src/compress.py --delta_ckpt <finetuned-delta-path> --ckpt <pretrained-model-path>
## 生成示例
python sample.py --prompt "<new1> cat playing with a ball" --delta_ckpt logs/<folder-name>/checkpoints/compressed_delta_epoch\=000004.ckpt --ckpt <pretrained-model-path> --compress
不同压缩级别下的生成示例。默认情况下,我们的代码会保留前 60% 的奇异值进行低秩近似(low-rank approximation),从而生成约 15 MB 大小的模型。

stable-diffusion-v1-4 的检查点转换
- 从 diffusers 的
delta.bin转换为 CompVis 的delta_model.ckpt:
python src/convert.py --delta_ckpt <path-to-folder>/delta.bin --ckpt <path-to-model-v1-4.ckpt> --mode diffuser-to-compvis
# 生成示例
python sample.py --delta_ckpt <path-to-folder>/delta_model.ckpt --ckpt <path-to-model-v1-4.ckpt> --prompt <text-prompt> --config configs/custom-diffusion/finetune_addtoken.yaml
- 从 diffusers 的
delta.bin转换为 stable-diffusion-webui 的检查点:
python src/convert.py --delta_ckpt <path-to-folder>/delta.bin --ckpt <path-to-model-v1-4.ckpt> --mode diffuser-to-webui
# 在 stable-diffusion-webui 目录下启动 UI
bash webui.sh --embeddings-dir <path-to-folder>/webui/embeddings --ckpt <path-to-folder>/webui/model.ckpt
- 从 CompVis 的
delta_model.ckpt转换为 diffusers 的delta.bin:
python src/convert.py --delta_ckpt <path-to-folder>/delta_model.ckpt --ckpt <path-to-model-v1-4.ckpt> --mode compvis-to-diffuser
sample
python src/diffusers_sample.py --delta_ckpt <path-to-folder>/delta.bin --ckpt "CompVis/stable-diffusion-v1-4" --prompt <text-prompt>
- 来自 CompVis 的
delta_model.ckptstable-diffusion-webui checkpoint(检查点)。
python src/convert.py --delta_ckpt <path-to-folder>/delta_model.ckpt --ckpt <path-to-model-v1-4.ckpt> --mode compvis-to-webui
# 在 stable-diffusion-webui 目录下启动 UI
bash webui.sh --embeddings-dir <path-to-folder>/webui/embeddings --ckpt <path-to-folder>/webui/model.ckpt
转换后的 checkpoints(检查点)将保存在原始 checkpoints 所在的 <path-to-folder> 目录中。
References(参考文献)
@article{kumari2022customdiffusion,
title={Multi-Concept Customization of Text-to-Image Diffusion},
author={Kumari, Nupur and Zhang, Bingliang and Zhang, Richard and Shechtman, Eli and Zhu, Jun-Yan},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}
Acknowledgments(致谢)
我们感谢 Nick Kolkin、David Bau、Sheng-Yu Wang、Gaurav Parmar、John Nack 和 Sylvain Paris 提供的宝贵意见和讨论,也感谢 Allie Chang、Chen Wu、Sumith Kulal、Minguk Kang、Yotam Nitzan 和 Taesung Park 对初稿的校对。我们还要感谢 Mia Tang 和 Aaron Hertzmann 分享他们的艺术作品。部分数据集从 Unsplash 下载。本工作部分由 Nupur Kumari 在 Adobe 实习期间完成。该研究部分得到了 Adobe Inc. 的支持。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。