ACE-Step
ACE-Step 是一款开源的音乐生成基础模型,旨在成为音乐 AI 领域的"Stable Diffusion"。它致力于解决现有技术在生成速度、音乐连贯性与可控性之间难以兼顾的痛点:传统基于大语言模型的方案虽擅长歌词对齐但推理缓慢且结构生硬,而扩散模型虽快却往往缺乏长程结构逻辑。
通过创新性地融合扩散生成机制、深度压缩自动编码器(DCAE)及轻量级线性 Transformer,ACE-Step 实现了显著突破。它能在单张 A100 GPU 上仅用 20 秒即可合成高达 4 分钟的高品质音乐,速度比同类基线快 15 倍,同时在旋律、和声与节奏上保持卓越的连贯性。此外,模型支持声音克隆、歌词编辑、混音及分轨生成等细粒度控制功能,并针对消费级显卡进行了内存优化,最低仅需 8GB 显存即可运行。
这款工具非常适合音乐制作人、内容创作者探索创意灵感,同时也为开发者和研究人员提供了一个高效、灵活的基础架构,便于在其之上训练人声转换、伴奏生成等特定子任务,轻松融入各类音乐创作工作流。
使用场景
一位独立游戏开发者需要在 48 小时的游戏开发马拉松(Game Jam)中,为包含多段剧情和不同角色对话的场景快速生成高质量且风格统一的背景音乐与人声演唱。
没有 ACE-Step 时
- 生成效率极低:使用传统的基于大语言模型的音乐生成工具,合成一段 4 分钟的完整曲目往往需要数分钟甚至更久,严重拖慢开发迭代节奏。
- 结构连贯性差:生成的音乐容易出现段落断裂或节奏混乱,缺乏长程结构的逻辑性,难以直接作为游戏背景循环播放。
- 歌词与旋律对位不准:在需要角色演唱的剧情中,现有工具常出现歌词发音模糊或与旋律节奏不匹配的情况,导致听感生硬。
- 细粒度控制缺失:若想修改某一句歌词或替换特定乐器音色,通常需要重新生成整首曲子,无法进行局部微调或“人声克隆”式编辑。
- 硬件门槛高:高性能模型往往需要显存巨大的专业显卡,普通开发者的消费级电脑难以运行,限制了创作自由度。
使用 ACE-Step 后
- 极速推理响应:ACE-Step 利用扩散架构与轻量级线性 Transformer,在 A100 上仅需 20 秒即可合成 4 分钟音乐,比传统方法快 15 倍,让开发者能实时试听多种方案。
- 卓越的结构连贯性:得益于深度压缩自编码器(DCAE)与语义对齐技术,生成的乐曲在旋律、和声与节奏上高度统一,完美适配长场景需求。
- 精准的歌词对齐:通过 MERT 和 m-hubert 强化语义表示,ACE-Step 能确保歌词发音清晰且严格贴合旋律节奏,直接产出可用的角色演唱片段。
- 灵活的局部编辑能力:支持人声克隆、歌词编辑及分轨生成(如从清唱生成伴奏),开发者可单独调整某句台词或复用角色音色,无需重头再来。
- 亲民的资源占用:经过内存优化,ACE-Step 最低仅需 8GB 显存即可运行,让普通游戏开发者也能在本地设备上流畅部署和使用。
ACE-Step 通过兼顾极速生成、结构连贯与精细控制,真正成为了音乐创作领域的"Stable Diffusion",让非音乐专业的创作者也能高效实现复杂的音频构想。
运行环境要求
- Linux
- macOS
- Windows
- NVIDIA GPU 必需(支持 CUDA),推荐 RTX 3090/4090 或 A100
- 经内存优化后最低显存需求为 8GB
- MacBook (M2 Max) 可运行但速度较慢
未说明(建议 16GB+ 以配合大模型运行)
快速开始
ACE-Step
迈向音乐生成基础模型的一步
项目 | Hugging Face | ModelScope | Space Demo | Discord | 技术报告 | ACE-Step v1.5

目录
📝 摘要
我们推出了ACE-Step,这是一种新颖的开源音乐生成基础模型,它克服了现有方法的关键局限性,并通过整体架构设计实现了最先进的性能。当前的方法在生成速度、音乐连贯性和可控性之间存在固有的权衡。例如,基于LLM的模型(如Yue、SongGen)在歌词对齐方面表现出色,但推理速度较慢且容易出现结构上的瑕疵。而扩散模型(如DiffRhythm)则能够实现更快的合成,但往往缺乏长距离的结构连贯性。
ACE-Step通过将基于扩散的生成与Sana的深度压缩自编码器(DCAE)以及轻量级线性Transformer相结合,弥合了这一差距。此外,它还利用MERT和m-hubert在训练过程中对齐语义表示(REPA),从而实现快速收敛。因此,我们的模型仅需20秒即可在A100 GPU上合成长达4分钟的音乐——比基于LLM的基线快15倍——同时在旋律、和声和节奏等指标上实现了更优的音乐连贯性和歌词对齐。更重要的是,ACE-Step能够保留精细的声学细节,从而支持高级控制机制,如语音克隆、歌词编辑、混音以及音轨生成(例如,lyric2vocal、singing2accompaniment)。
我们并非要构建又一个端到端的文本到音乐流水线,而是希望建立一个音乐AI的基础模型:一种快速、通用、高效且灵活的架构,便于在其之上训练子任务。这将为开发能够无缝融入音乐艺术家、制作人和内容创作者创作流程的强大工具铺平道路。简而言之,我们的目标是打造音乐领域的Stable Diffusion时刻。
📢 新闻与更新
🎉 2026.01.28: 发布了ACE-Step v1.5 - 我们的最新、最先进的模型现已上线!
📃 2025.06.02: 发布了ACE-Step技术报告(PDF)。
🎮 2025.05.14: 添加了
Stable Audio Open Small采样器pingpong。使用SDE来实现更好的音乐一致性和质量,包括歌词对齐和风格对齐。采用更好的方法重新实现了Audio2Audio。🎤 2025.05.12: 发布了RapMachine并修复了LoRA训练问题
- 详情请参阅ZH_RAP_LORA.md。音频示例:https://ace-step.github.io/#RapMachine
- 详细训练说明请参阅TRAIN_INSTRUCTION.md。
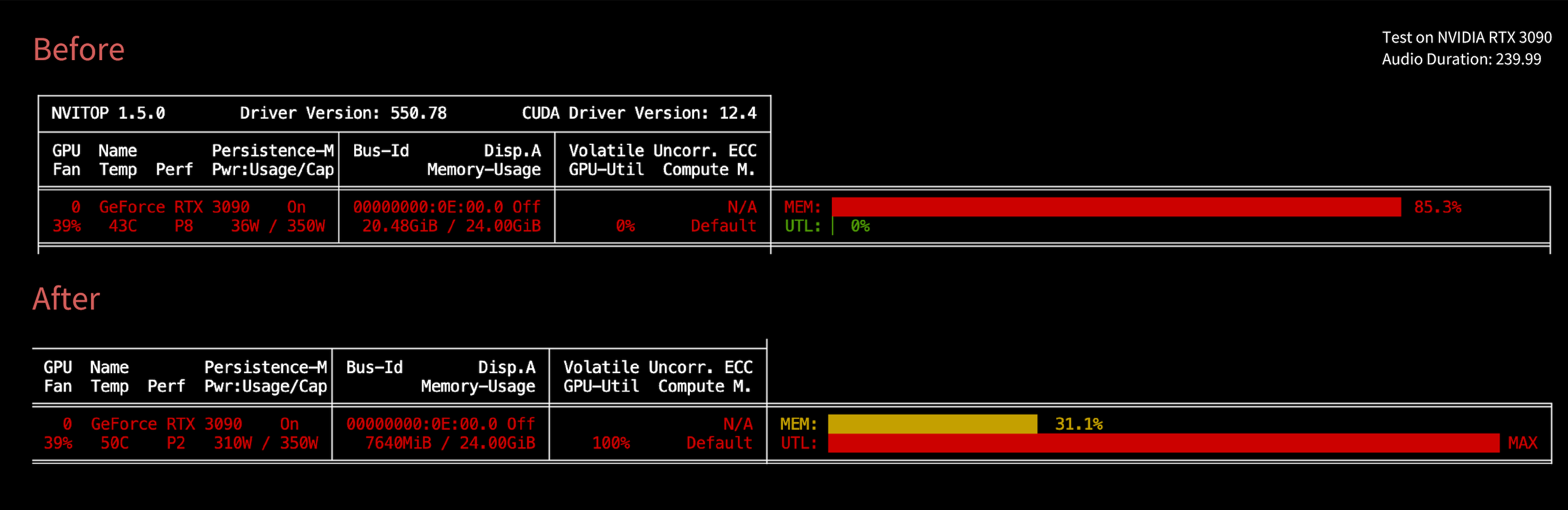
- 🔥 2025.05.10: 内存优化更新
- 最大显存需求降低至8GB,使其更兼容消费级设备
- 推荐启动选项:
Windows用户需要安装triton:acestep --torch_compile true --cpu_offload true --overlapped_decode truepip install triton-windows
- 📢 2025.05.09: Graidio演示支持Audio2Audio。ComfyUI:Ace_Step_4x_a2a.json
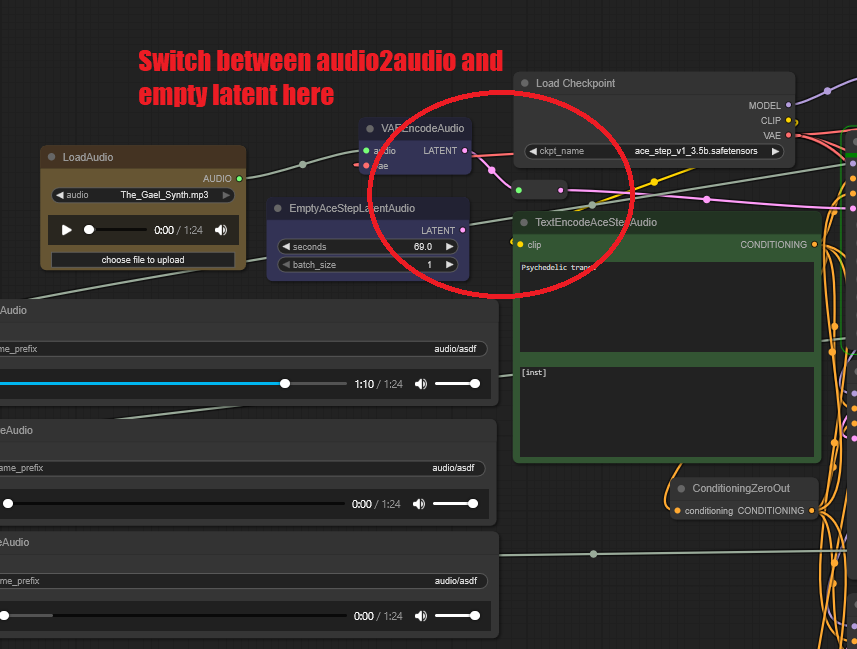
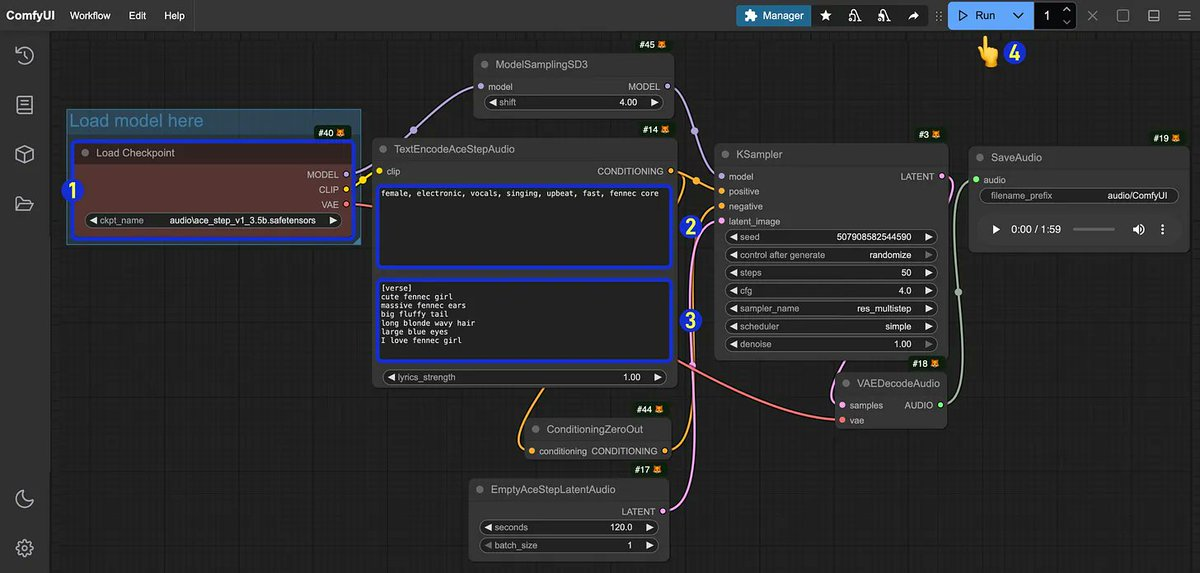
🚀 2025.05.08: ComfyUI_ACE-Step节点现已可用!在ComfyUI中探索ACE-Step的强大功能。🎉
🚀 2025.05.06: 开源演示代码和模型
✨ 特性
🎯 基线质量
🌈 多样化风格与流派
- 🎸 支持所有主流音乐风格,提供多种描述格式,包括简短标签、描述性文字或具体使用场景
- 🎷 能够根据不同流派生成具有适当乐器编配和风格特征的音乐
🌍 多语言支持
- 🗣️ 支持19种语言,其中表现最佳的前10种语言包括:
- 🇺🇸 英语、🇨🇳 中文、🇷🇺 俄语、🇪🇸 西班牙语、🇯🇵 日语、🇩🇪 德语、🇫🇷 法语、🇵🇹 葡萄牙语、🇮🇹 意大利语、🇰🇷 韩语
- ⚠️ 由于数据不平衡,较少使用的语言可能表现欠佳
🎻 乐器风格
- 🎹 支持不同流派和风格下的各种乐器音乐生成
- 🎺 能够生成逼真的乐器音轨,为每种乐器赋予恰当的音色和表现力
- 🎼 可以生成包含多种乐器的复杂编曲,同时保持音乐的连贯性
🎤 人声技巧
- 🎙️ 能够高质量地呈现各种人声风格和技巧
- 🗣️ 支持不同的人声表达方式,包括多种演唱技巧和风格
🎛️ 可控性
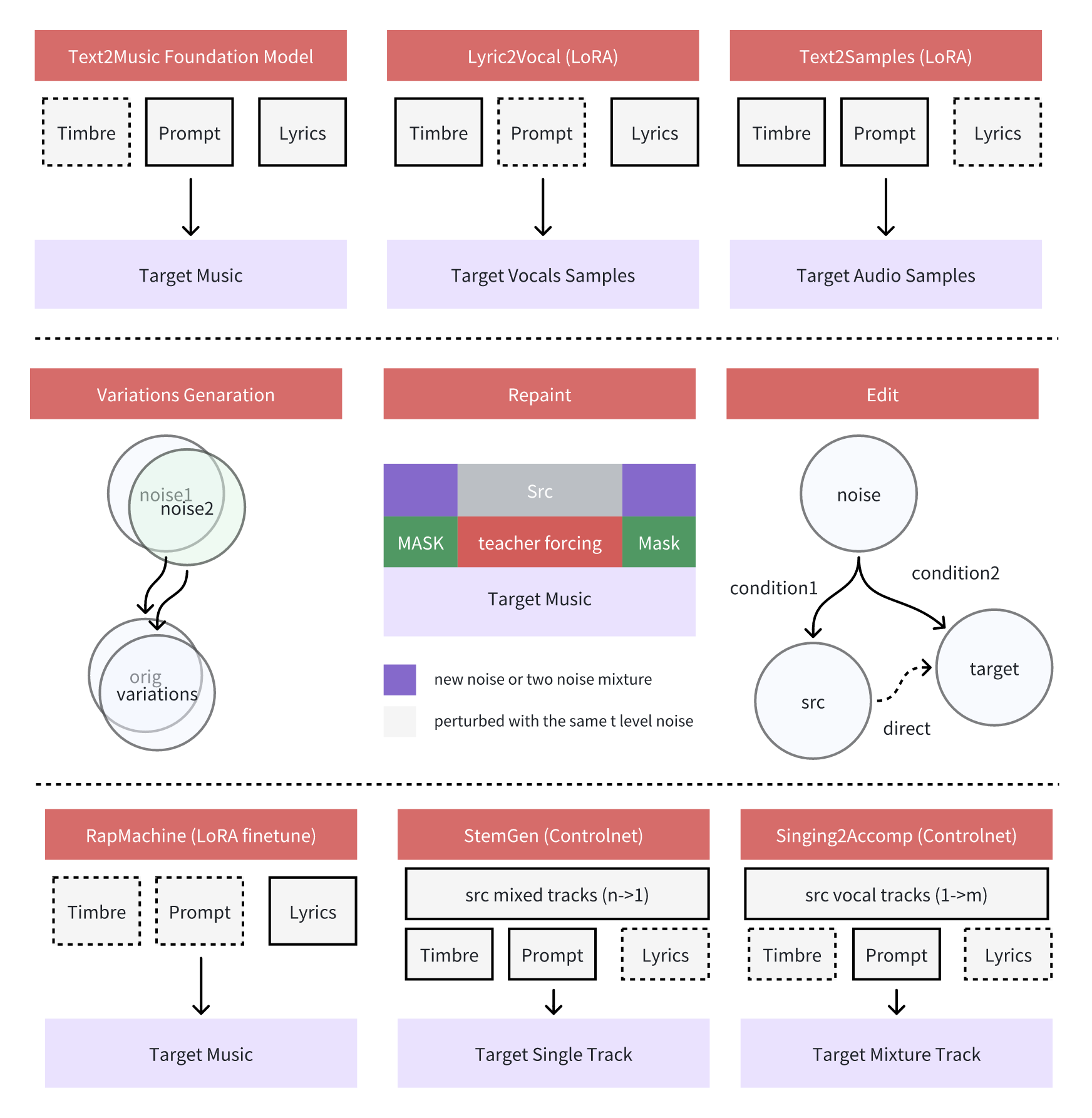
🔄 变体生成
- ⚙️ 采用无需训练、仅在推理时优化的技术实现
- 🌊 流匹配模型生成初始噪声,随后使用 trigFlow 的噪声公式添加额外的高斯噪声
- 🎚️ 可调节原始初始噪声与新高斯噪声之间的混合比例,以控制变体的程度
🎨 重绘
- 🖌️ 通过向目标音频输入添加噪声,并在 ODE 过程中施加掩码约束来实现
- 🔍 当输入条件不同于原始生成内容时,可以仅修改特定部分,同时保留其余内容
- 🔀 可与变体生成技术结合,创造出风格、歌词或人声的局部变化
✏️ 歌词编辑
- 💡 创新性地应用流编辑技术,实现在保留旋律、人声和伴奏的同时对歌词进行局部修改
- 🔄 既适用于生成内容,也适用于上传的音频,极大地提升了创作可能性
- ℹ️ 目前的限制是每次只能修改小段歌词以避免失真,但可以通过多次编辑逐步完成
🚀 应用场景
🎤 Lyric2Vocal (LoRA)
- 🔊 基于纯人声数据微调的 LoRA 模型,可以直接从歌词生成人声音轨
- 🛠️ 具有众多实用场景,如人声演示、指导音轨、歌曲创作辅助以及人声编排实验
- ⏱️ 提供了一种快速测试歌词演唱效果的方式,帮助创作者更快地迭代
📝 Text2Samples (LoRA)
- 🎛️ 类似于 Lyric2Vocal,但基于纯乐器和采样数据进行微调
- 🎵 能够根据文本描述生成概念性的音乐制作样本
- 🧰 对于快速创建乐器循环、音效及制作所需的音乐元素非常有用
🔮 即将推出
🎤 RapMachine
- 🔥 基于纯说唱数据微调,打造专门用于说唱生成的 AI 系统
- 🏆 预期功能包括 AI 说唱对决以及通过说唱进行叙事表达
- 📚 说唱具有卓越的叙事和表现力,拥有非凡的应用潜力
🎛️ StemGen
- 🎚️ 基于多轨数据训练的 ControlNet-LORA,用于生成独立的乐器音轨
- 🎯 输入为参考音轨及指定乐器(或乐器参考音频)
- 🎹 输出与参考音轨相辅相成的乐器音轨,例如为长笛旋律创作钢琴伴奏,或为吉他主音添加爵士鼓点
🎤 Singing2Accompaniment
- 🔄 是 StemGen 的逆过程,从单一人声音轨生成混音母带
- 🎵 输入为人声音轨及指定风格,输出完整的伴奏音轨
- 🎸 生成能够完美衬托输入人声的完整乐器伴奏,轻松为任何人声录音添加专业级伴奏
📋 路线图
- 发布训练代码 🔥
- 发布 LoRA 训练代码 🔥
- 发布 RapMachine LoRA 🎤
- 发布评估性能与技术报告 📄
- 训练并发布 ACE-Step V1.5
- 发布 ControlNet 训练代码 🔥
- 发布 Singing2Accompaniment ControlNet 🎮
🖥️ 硬件性能
我们已在不同硬件配置上对 ACE-Step 进行了评估,得出以下吞吐量结果:
| 设备 | RTF (27 步) | 渲染 1 分钟音频所需时间 (27 步) | RTF (60 步) | 渲染 1 分钟音频所需时间 (60 步) |
|---|---|---|---|---|
| NVIDIA RTX 4090 | 34.48 × | 1.74 s | 15.63 × | 3.84 s |
| NVIDIA A100 | 27.27 × | 2.20 s | 12.27 × | 4.89 s |
| NVIDIA RTX 3090 | 12.76 × | 4.70 s | 6.48 × | 9.26 s |
| MacBook M2 Max | 2.27 × | 26.43 s | 1.03 × | 58.25 s |
我们使用 RTF(实时因子)来衡量 ACE-Step 的性能。数值越高,表示生成速度越快。例如,27.27×意味着生成1分钟音乐只需2.2秒(60/27.27)。性能是在单个 GPU 上,批次大小为1,步数为27的情况下测得的。
📦 安装
1. 克隆仓库
首先,将 ACE-Step 仓库克隆到本地,并进入项目目录:
git clone https://github.com/ace-step/ACE-Step.git
cd ACE-Step
2. 前置条件
请确保已安装以下内容:
Python:建议使用 3.10 或更高版本。可从 python.org 下载。Conda或venv:用于创建虚拟环境(推荐使用 Conda)。
3. 设置虚拟环境
强烈建议使用虚拟环境来管理项目依赖,避免冲突。您可以选择以下任一方法:
选项 A:使用 Conda
创建名为
ace_step的环境,使用 Python 3.10:conda create -n ace_step python=3.10 -y激活环境:
conda activate ace_step
选项 B:使用 venv
进入克隆的 ACE-Step 目录。
创建虚拟环境(通常命名为
venv):python -m venv venv激活环境:
- Windows (cmd.exe):
venv\Scripts\activate.bat - Windows (PowerShell):
(如果遇到执行策略错误,可能需要先运行.\venv\Scripts\Activate.ps1Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process) - Linux / macOS (bash/zsh):
source venv/bin/activate
- Windows (cmd.exe):
4. 安装依赖
虚拟环境激活后: a. (仅限 Windows)如果您使用的是 NVIDIA 显卡,请先安装支持 CUDA 的 PyTorch:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
(请根据您的 CUDA 版本调整 cu126。更多 PyTorch 安装选项,请参阅 PyTorch 官方网站)。
b. 安装 ACE-Step 及其核心依赖:
pip install -e .
至此,ACE-Step 应用程序已成功安装。GUI 支持 Windows、macOS 和 Linux。有关如何运行的说明,请参阅 使用指南 部分。
🚀 使用指南
🔍 基本使用
acestep --port 7865
⚙️ 高级用法
acestep --checkpoint_path /path/to/checkpoint --port 7865 --device_id 0 --share true --bf16 true
- 如果设置了
--checkpoint_path并且该路径下存在模型,则从checkpoint_path加载模型。 - 如果设置了
--checkpoint_path但该路径下不存在模型,则会自动下载模型到checkpoint_path。 - 如果未设置
--checkpoint_path,则会自动下载模型到默认路径~/.cache/ace-step/checkpoints。
如果您使用的是 macOS,请使用 --bf16 false 以避免出现错误。
🔍 API 使用
如果您打算将 ACE-Step 作为库集成到您自己的 Python 项目中,可以通过以下 pip 命令直接从 GitHub 安装最新版本。
通过 pip 直接安装:
- 确保已安装 Git: 此方法需要在您的系统上安装 Git,并且 Git 能够在系统的 PATH 中被访问。
- 执行安装命令:
建议在虚拟环境中使用此命令,以避免与其他包发生冲突。pip install git+https://github.com/ace-step/ACE-Step.git
🛠️ 命令行参数
--checkpoint_path: 模型检查点的路径(默认:自动下载)--server_name: Gradio 服务器绑定的 IP 地址或主机名(默认:'127.0.0.1')。使用 '0.0.0.0' 可使网络中的其他设备访问。--port: 运行 Gradio 服务器的端口(默认:7865)--device_id: 要使用的 GPU 设备 ID(默认:0)--share: 启用 Gradio 分享链接(默认:False)--bf16: 使用 bfloat16 精度以加快推理速度(默认:True)--torch_compile: 使用torch.compile()优化模型,从而加速推理(默认:False)。- Windows 需要安装 triton:
pip install triton-windows
- Windows 需要安装 triton:
--cpu_offload: 将模型权重卸载到 CPU 以节省 GPU 内存(默认:False)--overlapped_decode: 使用重叠解码以加快推理速度(默认:False)
📱 用户界面指南
ACE-Step 的界面提供了多个选项卡,用于不同的音乐生成和编辑任务:
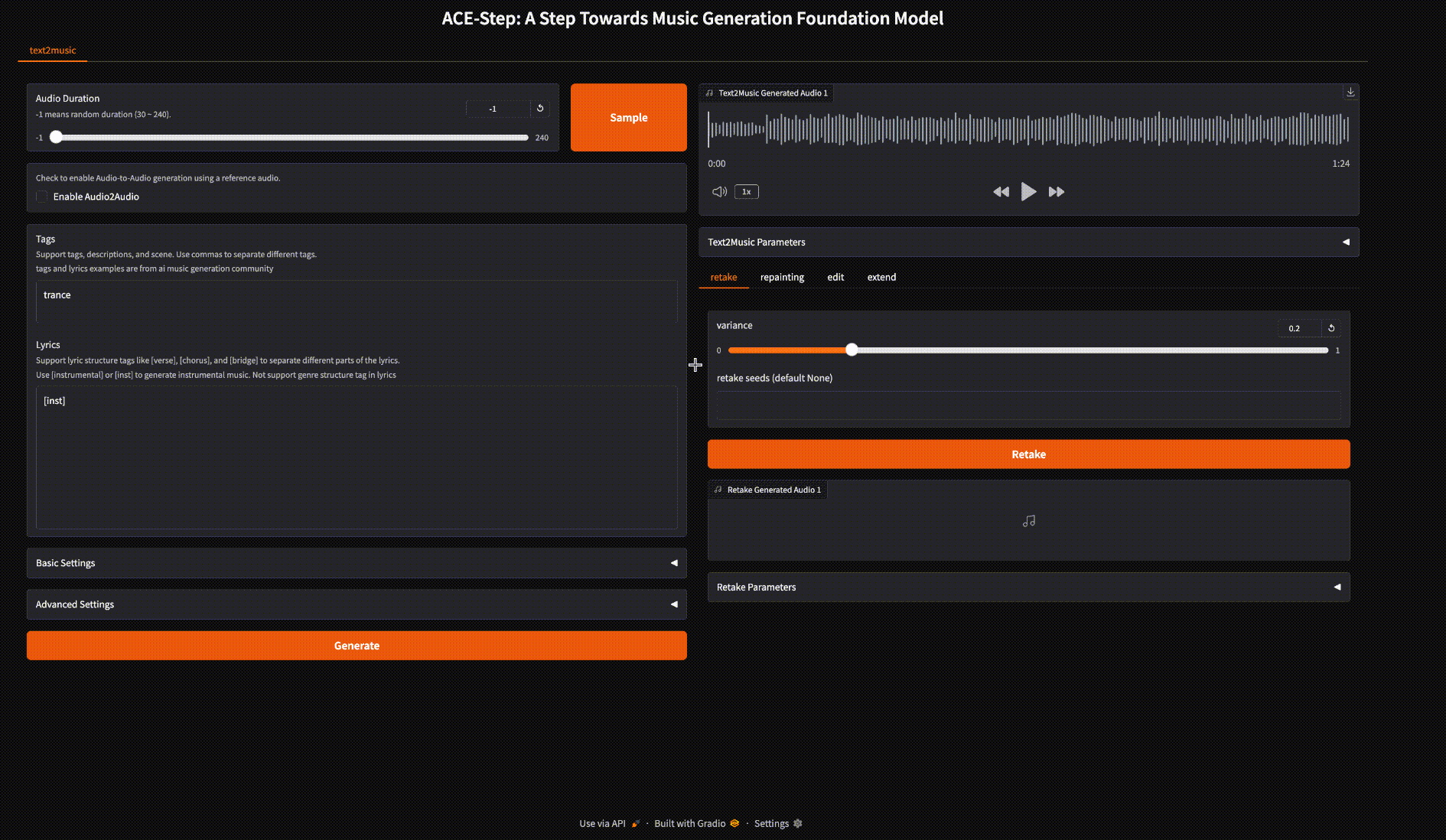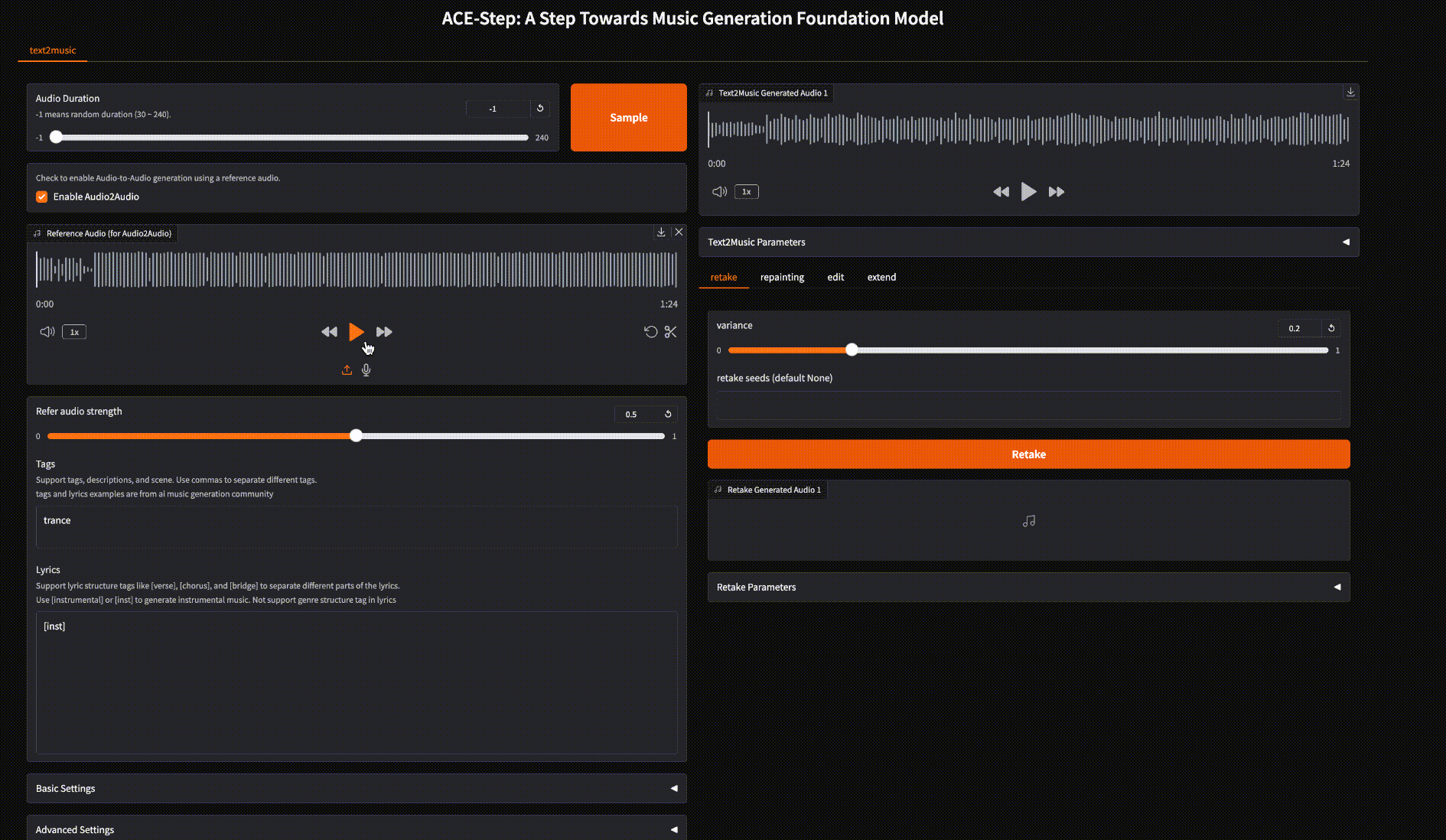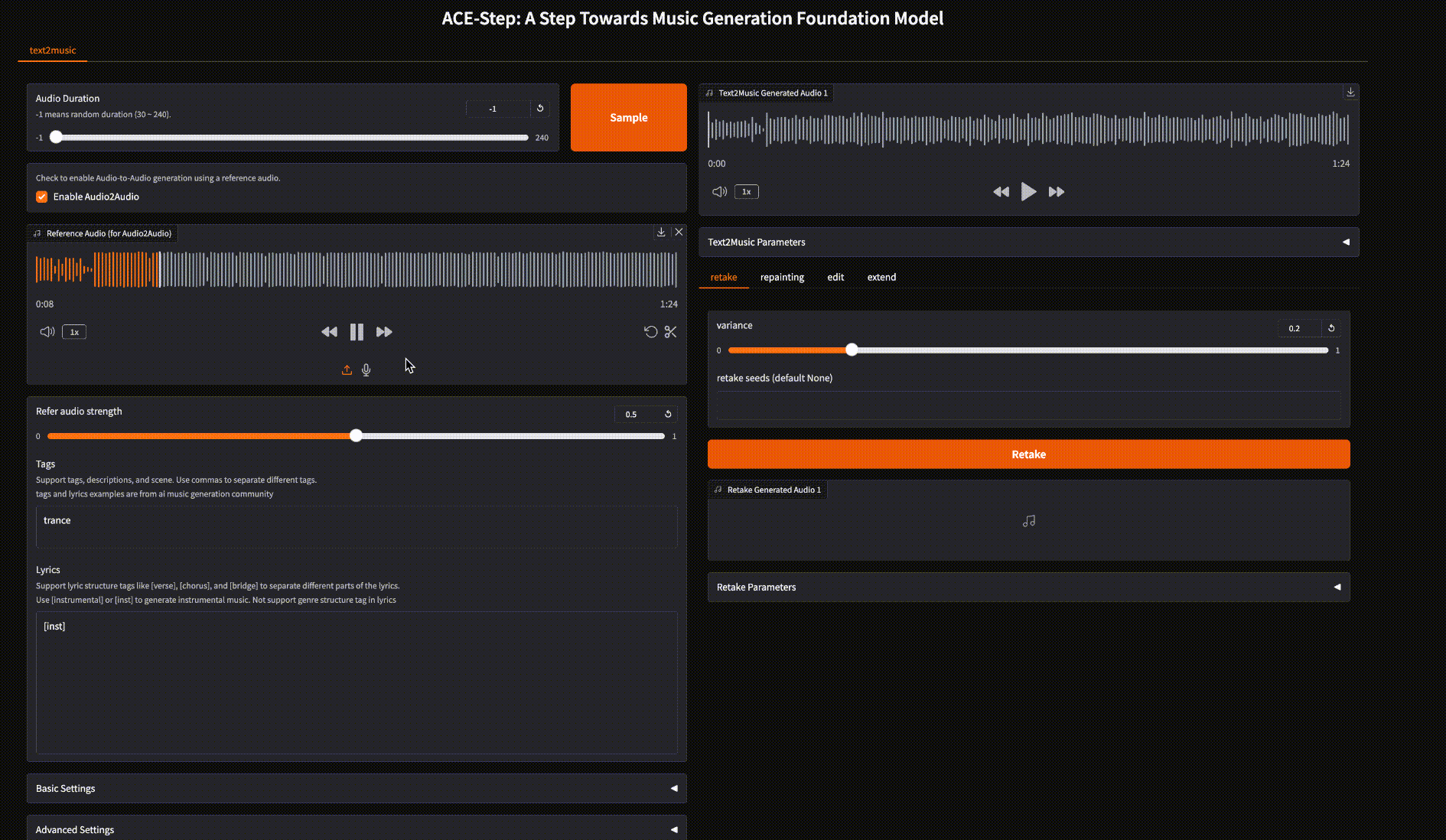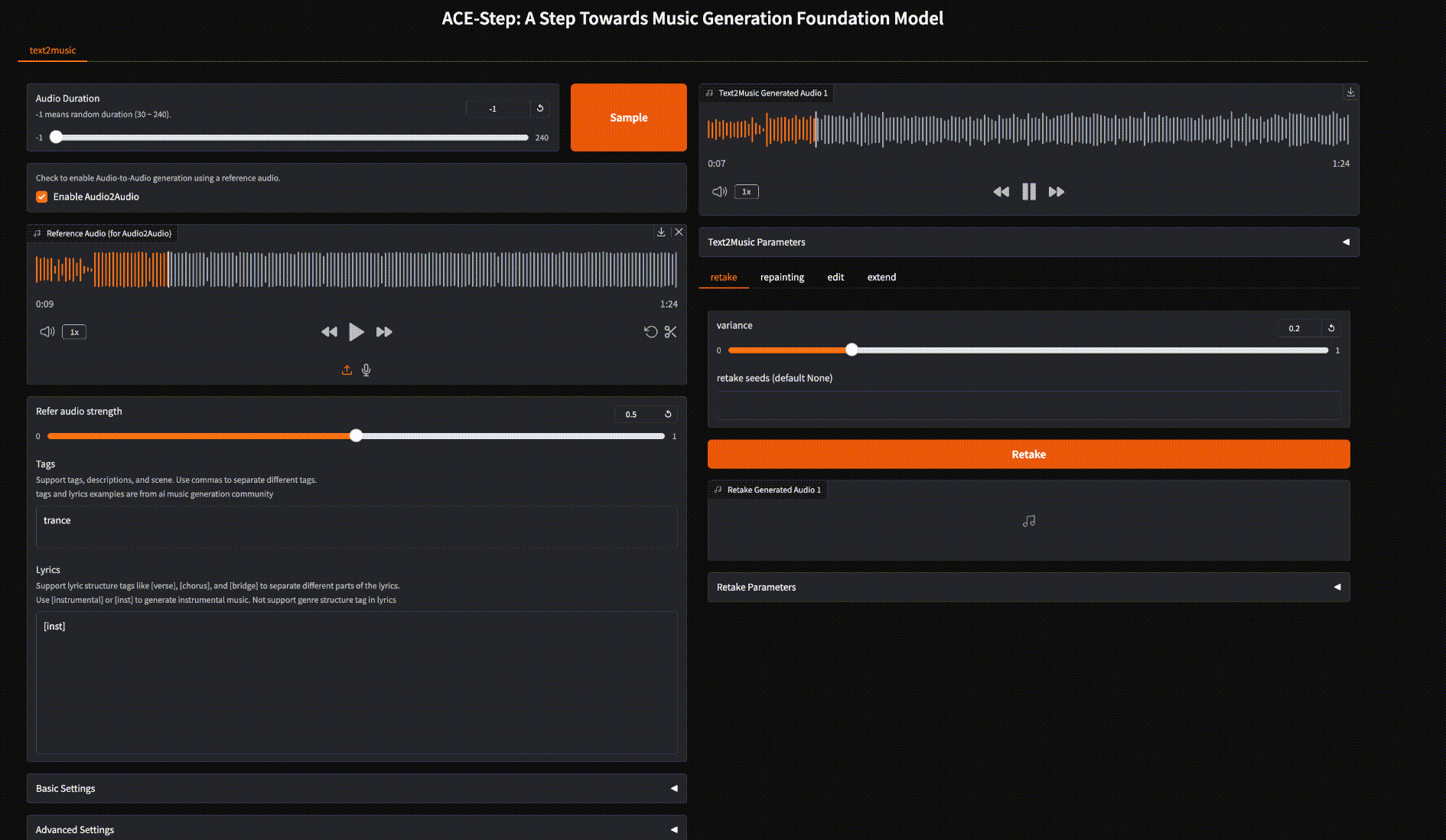
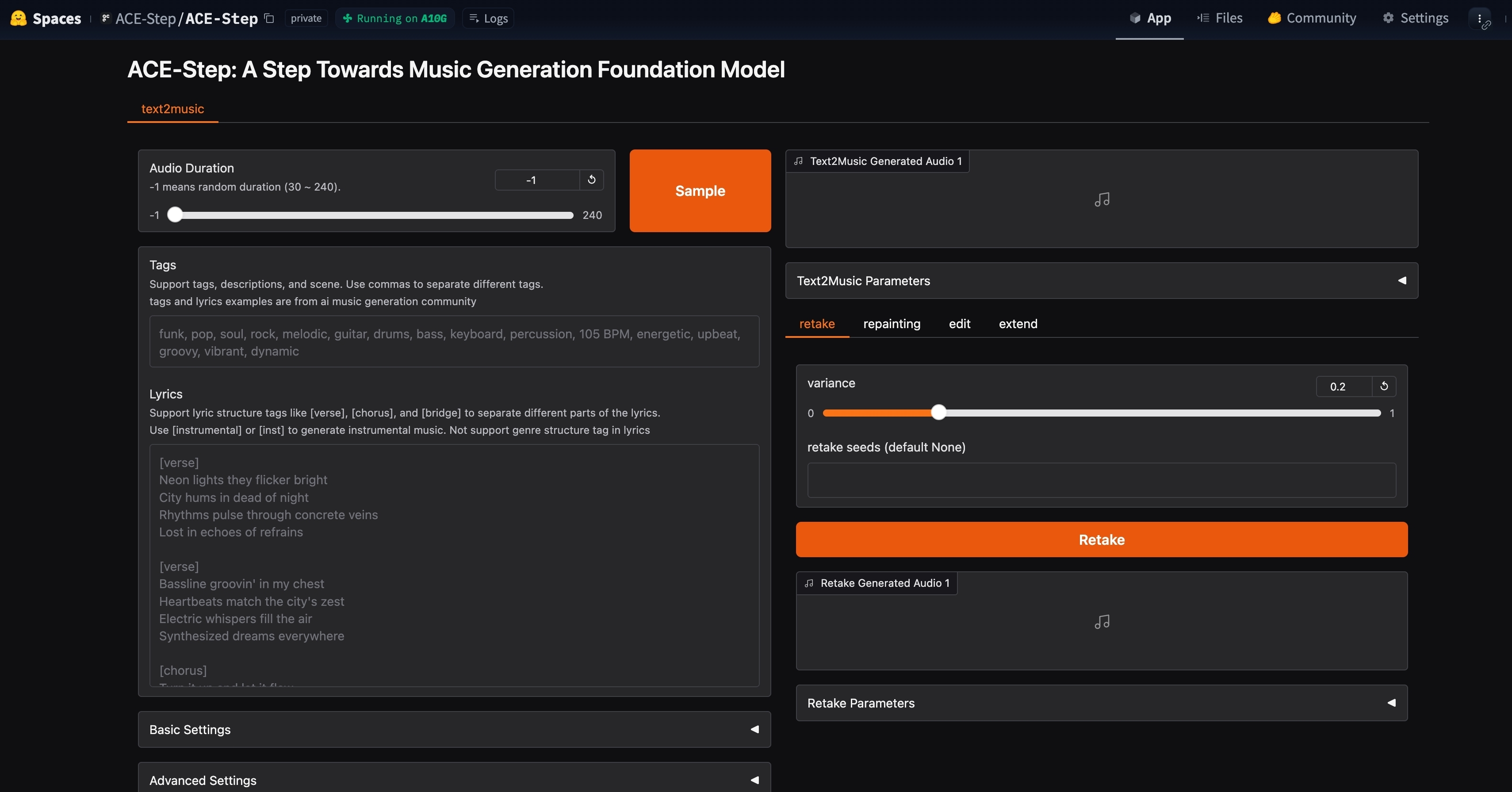
📝 Text2Music 选项卡
📋 输入字段:
- 🏷️ 标签: 输入描述性标签、流派或场景描述,用逗号分隔。
- 📜 歌词: 输入带有结构标记的歌词,如 [verse]、[chorus] 和 [bridge]。
- ⏱️ 音频时长: 设置生成音频的期望时长(-1 表示随机)。
⚙️ 设置:
- 🔧 基本设置: 调整推理步数、引导尺度和种子。
- 🔬 高级设置: 微调调度器类型、CFG 类型、ERG 设置等。
🚀 生成: 点击“生成”按钮,根据您的输入创建音乐。
🔄 重做 选项卡
- 🎲 使用不同的种子重新生成略有变化的音乐。
- 🎚️ 调整方差以控制重做与原作品的差异程度。
🎨 重绘 选项卡
- 🖌️ 选择性地重新生成音乐的特定部分。
- ⏱️ 指定要重绘部分的开始和结束时间。
- 🔍 选择源音频(Text2Music 输出、上次重绘或上传的音频)。
✏️ 编辑 选项卡
- 🔄 修改现有音乐,更改标签或歌词。
- 🎛️ 选择“only_lyrics”模式(保留旋律)或“remix”模式(改变旋律)。
- 🎚️ 调整编辑参数以控制保留原始内容的程度。
📏 扩展 选项卡
- ➕ 在现有作品的开头或结尾添加音乐。
- 📐 指定左右扩展的长度。
- 🔍 选择要扩展的源音频。
📂 示例
examples/input_params 目录包含示例输入参数,可作为生成音乐的参考。
🏗️ 架构
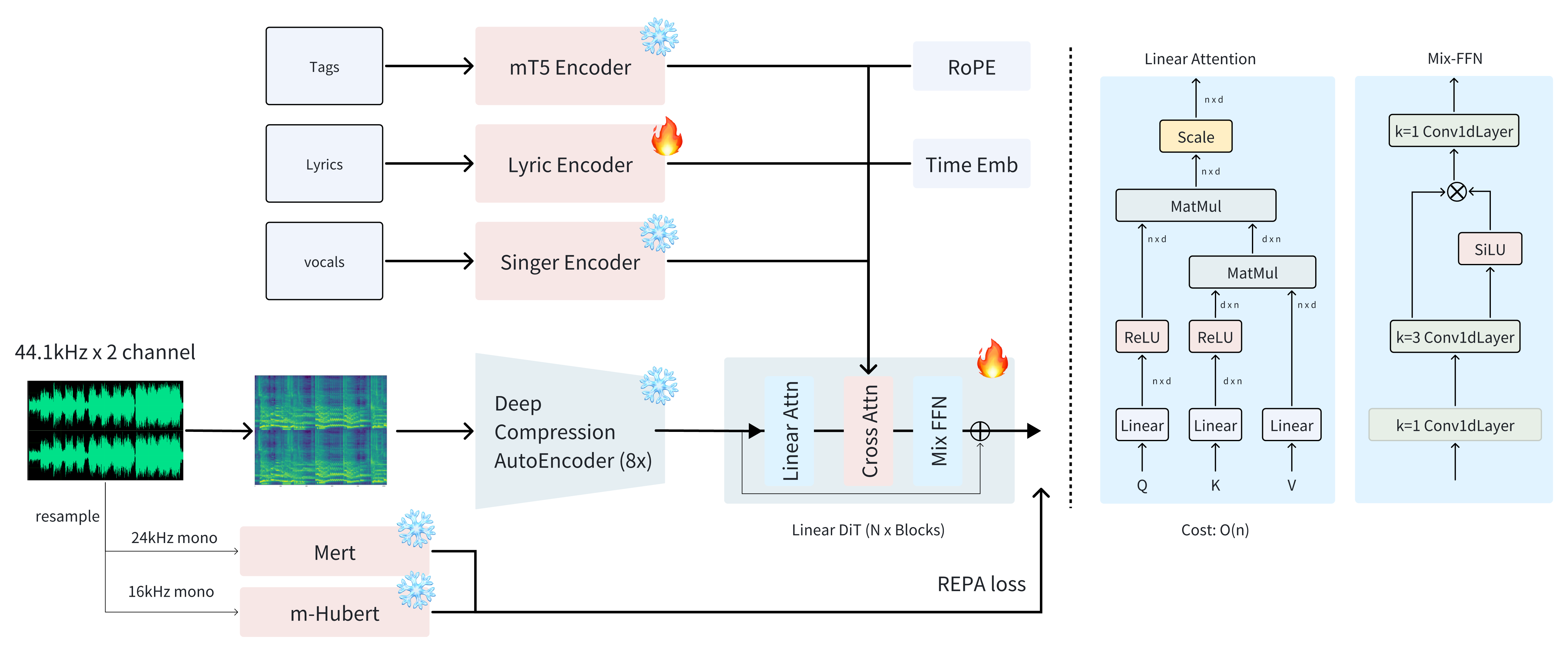
🔨 训练
详细的训练说明请参阅 TRAIN_INSTRUCTION.md。
📜 许可与免责声明
本项目采用 Apache License 2.0 许可。
ACE-Step 能够生成涵盖多种流派的原创音乐,适用于创意制作、教育和娱乐等领域。尽管设计初衷是支持积极和艺术性的应用场景,但我们承认可能存在一些潜在风险,例如由于风格相似而导致的无意版权侵权、文化元素的不当融合以及被滥用于生成有害内容等。为确保负责任地使用,我们鼓励用户验证生成作品的原创性,明确披露人工智能的参与,并在改编受保护的风格或素材时获得相应许可。使用 ACE-Step 即表示您同意遵守这些原则,尊重艺术完整性、文化多样性和法律合规性。作者对任何滥用该模型的行为不承担任何责任,包括但不限于版权侵权、文化敏感性问题或生成有害内容等。
🔔 重要提示
ACE-Step 项目的唯一官方网站是我们 GitHub Pages 网站。
我们并未运营任何其他网站。
🚫 仿冒域名包括但不限于:
ac**p.com, a**p.org, a***c.org
⚠️ 请务必谨慎,切勿访问、信任或向这些网站进行任何支付。
🙏 致谢
本项目由 ACE Studio 和 StepFun 共同领导。
📖 引用
如果您认为本项目对您的研究有所帮助,请考虑引用:
@misc{gong2025acestep,
title={ACE-Step: A Step Towards Music Generation Foundation Model},
author={Junmin Gong, Wenxiao Zhao, Sen Wang, Shengyuan Xu, Jing Guo},
howpublished={\url{https://github.com/ace-step/ACE-Step}},
year={2025},
note={GitHub repository}
}
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
GPT-SoVITS
GPT-SoVITS 是一款强大的开源语音合成与声音克隆工具,旨在让用户仅需极少量的音频数据即可训练出高质量的个性化语音模型。它核心解决了传统语音合成技术依赖海量录音数据、门槛高且成本大的痛点,实现了“零样本”和“少样本”的快速建模:用户只需提供 5 秒参考音频即可即时生成语音,或使用 1 分钟数据进行微调,从而获得高度逼真且相似度极佳的声音效果。 该工具特别适合内容创作者、独立开发者、研究人员以及希望为角色配音的普通用户使用。其内置的友好 WebUI 界面集成了人声伴奏分离、自动数据集切片、中文语音识别及文本标注等辅助功能,极大地降低了数据准备和模型训练的技术门槛,让非专业人士也能轻松上手。 在技术亮点方面,GPT-SoVITS 不仅支持中、英、日、韩、粤语等多语言跨语种合成,还具备卓越的推理速度,在主流显卡上可实现实时甚至超实时的生成效率。无论是需要快速制作视频配音,还是进行多语言语音交互研究,GPT-SoVITS 都能以极低的数据成本提供专业级的语音合成体验。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。
LocalAI
LocalAI 是一款开源的本地人工智能引擎,旨在让用户在任意硬件上轻松运行各类 AI 模型,包括大语言模型、图像生成、语音识别及视频处理等。它的核心优势在于彻底打破了高性能计算的门槛,无需昂贵的专用 GPU,仅凭普通 CPU 或常见的消费级显卡(如 NVIDIA、AMD、Intel 及 Apple Silicon)即可部署和运行复杂的 AI 任务。 对于担心数据隐私的用户而言,LocalAI 提供了“隐私优先”的解决方案,确保所有数据处理均在本地基础设施内完成,无需上传至云端。同时,它完美兼容 OpenAI、Anthropic 等主流 API 接口,这意味着开发者可以无缝迁移现有应用,直接利用本地资源替代云服务,既降低了成本又提升了可控性。 LocalAI 内置了超过 35 种后端支持(如 llama.cpp、vLLM、Whisper 等),并集成了自主 AI 代理、工具调用及检索增强生成(RAG)等高级功能,且具备多用户管理与权限控制能力。无论是希望保护敏感数据的企业开发者、进行算法实验的研究人员,还是想要在个人电脑上体验最新 AI 技术的极客玩家,都能通过 LocalAI 获
bark
Bark 是由 Suno 推出的开源生成式音频模型,能够根据文本提示创造出高度逼真的多语言语音、音乐、背景噪音及简单音效。与传统仅能朗读文字的语音合成工具不同,Bark 基于 Transformer 架构,不仅能模拟说话,还能生成笑声、叹息、哭泣等非语言声音,甚至能处理带有情感色彩和语气停顿的复杂文本,极大地丰富了音频表达的可能性。 它主要解决了传统语音合成声音机械、缺乏情感以及无法生成非语音类音效的痛点,让创作者能通过简单的文字描述获得生动自然的音频素材。无论是需要为视频配音的内容创作者、探索多模态生成的研究人员,还是希望快速原型设计的开发者,都能从中受益。普通用户也可通过集成的演示页面轻松体验其神奇效果。 技术亮点方面,Bark 支持商业使用(MIT 许可),并在近期更新中实现了显著的推理速度提升,同时提供了适配低显存 GPU 的版本,降低了使用门槛。此外,社区还建立了丰富的提示词库,帮助用户更好地驾驭模型生成特定风格的声音。只需几行 Python 代码,即可将创意文本转化为高质量音频,是连接文字与声音世界的强大桥梁。
airi
airi 是一款开源的本地化 AI 伴侣项目,旨在将虚拟角色(如“二次元老婆”或赛博生命)带入用户的现实世界。它的核心目标是复刻并超越知名 AI 主播 Neuro-sama 的能力,让用户能够拥有完全自主掌控、可私有化部署的智能伙伴。 airi 主要解决了用户对高度定制化、具备情感交互能力且数据隐私安全的 AI 角色的需求。不同于依赖云端服务的通用助手,airi 允许用户在本地运行,不仅保护了对话隐私,还赋予了用户定义角色性格与灵魂的自由。它支持实时语音聊天,甚至能直接参与《我的世界》(Minecraft)和《异星工厂》(Factorio)等游戏,实现了从单纯对话到共同娱乐的跨越。 这款工具非常适合喜爱虚拟角色的普通用户、希望搭建个性化 AI 陪伴的技术爱好者,以及研究多模态交互的开发者。其独特的技术亮点在于跨平台支持(涵盖 Web、macOS 和 Windows)以及强大的游戏交互能力,让 AI 不仅能“说”,还能“玩”。通过容器化的灵魂设计,airi 为每个人创造专属数字生命提供了可能,让虚拟陪伴变得更加真实且触手可及。