Wan2.2
Wan2.2 是一套开源的大规模视频生成模型,能把文字或图片一键变成 720P、24fps 的高清短片。它解决了传统模型画面模糊、动作僵硬、风格不可控等痛点,让开发者、科研人员、视频设计师乃至普通爱好者都能在消费级显卡(如 RTX 4090)上快速产出电影级质感的视频。
亮点在于:采用“专家混合”架构,把去噪任务拆给不同专家,算力不变但容量更大;训练数据量相比上一代提升 65% 图像、83% 视频,复杂动作和语义理解显著增强;自带精细美学标签,可精准控制光影、色调、构图;还提供 14B 角色动画与语音驱动版本,可直接做人物替换或口播视频。
使用场景
一家独立游戏工作室正在为新品宣传片制作一段主角在雨夜街头奔跑的高清过场动画,要求画面具有电影级光影且动作流畅自然。
没有 Wan2.2 时
- 画质与成本难以兼得:生成 720P 高清视频通常需要昂贵的企业级显卡集群,普通消费级显卡(如 RTX 4090)无法运行或显存爆满,导致渲染成本极高。
- 动作僵硬不自然:旧模型在处理“雨中奔跑”这种复杂动态时,人物肢体容易扭曲变形,缺乏真实的物理惯性,看起来像“纸片人”在滑动。
- 光影缺乏电影感:生成的视频光线平淡,无法精准控制雨夜的霓虹反射、对比度和色调,后期需要花费大量时间手动调色才能达到预期效果。
- 迭代效率低下:由于推理速度慢且失败率高,团队一天只能尝试寥寥几次提示词调整,严重拖慢了创意验证和成片产出的进度。
使用 Wan2.2 后
- 平民硬件跑通高清:凭借高效的混合专家(MoE)架构和先进的 VAE 压缩技术,Wan2.2 能在单张 RTX 4090 上流畅生成 720P@24fps 的视频,大幅降低了硬件门槛。
- 复杂运动逼真还原:基于扩大 83.2% 的视频数据训练,Wan2.2 精准捕捉了人物奔跑时的肌肉起伏和雨水飞溅的细节,动作连贯且符合物理规律。
- 原生电影级美学:利用其内置的美学标签控制,团队直接通过提示词即可锁定“赛博朋克雨夜”的特定布光与色调,直出画面即具备大片质感。
- 快速创意迭代:作为目前最快的开源模型之一,Wan2.2 将单次生成时间显著缩短,让团队能在半天内完成数十种不同镜头语言的测试与优选。
Wan2.2 通过突破性的架构优化,让中小团队也能以低成本在消费级显卡上高效产出具有电影级质感和复杂动态的高清视频内容。
运行环境要求
- 未说明
- 必需 NVIDIA GPU
- 运行 5B 模型推荐消费级显卡(如 RTX 4090)
- 运行 14B 模型单卡推理至少需要 80GB 显存
- 若显存不足,可使用 --offload_model True、--convert_model_dtype 和 --t5_cpu 选项降低显存占用
未说明

快速开始
Wan2.2

💜 Wan | 🖥️ GitHub | 🤗 Hugging Face | 🤖 ModelScope | 📑 论文 | 📑 博客 | 💬 Discord
📕 使用指南(中文) | 📘 User Guide(English) | 💬 WeChat(微信)
{kind=link}
我们很高兴地推出Wan2.2,这是我们基础视频模型的一次重大升级。在Wan2.2中,我们重点引入了以下创新:
👍 高效的MoE架构:Wan2.2将专家混合模型(MoE)架构引入视频扩散模型。通过将去噪过程按时间步分离,并采用专门的高性能专家模型,这一设计在保持相同计算成本的同时,显著提升了整体模型容量。
👍 电影级美学效果:Wan2.2整合了精心筛选的美学数据,包含光照、构图、对比度、色调等详细标注。这使得电影风格的生成更加精准可控,便于创作出具有可定制美学偏好的视频。
👍 复杂运动生成:与Wan2.1相比,Wan2.2在训练数据上有了大幅扩展,图像数量增加了65.6%,视频数量增加了83.2%。这种扩展显著增强了模型在运动、语义和美学等多个维度上的泛化能力,使其在所有开源及闭源模型中均处于顶尖水平。
👍 高效的高清混合TI2V:Wan2.2开源了一款基于我们先进Wan2.2-VAE构建的5B模型,其压缩比达到16×16×4。该模型支持文本到视频和图像到视频生成,分辨率为720P、帧率24fps,并且可在消费级显卡如4090上运行。它是目前最快的720P@24fps模型之一,能够同时服务于工业界和学术界。
视频演示
🔥 最新消息!!
2025年11月13日:👋 Wan2.2-Animate-14B已集成至Diffusers(PR,权重)。感谢所有社区贡献者!尽情体验吧!
2025年9月19日:💃 我们推出了**Wan2.2-Animate-14B**,一款用于角色动画与替换的统一模型,具备全面的动作与表情复制能力。我们已发布模型权重和推理代码。您可以在wan.video、ModelScope Studio或HuggingFace Space上试用!
2025年8月26日:🎵 我们推出了**Wan2.2-S2V-14B**,一款基于音频驱动的电影级视频生成模型,包括推理代码、模型权重以及技术报告!现在您可以在wan.video、ModelScope Gradio或HuggingFace Gradio上试用!
2025年7月28日:👋 我们已开放一个使用TI2V-5B模型的HF空间。尽情体验吧!
2025年7月28日:👋 Wan2.2的T2V、I2V和TI2V均已集成至Diffusers(T2V-A14B | I2V-A14B | TI2V-5B)。欢迎随时尝试!
2025年7月28日:👋 我们已发布Wan2.2的推理代码和模型权重。
2025年9月5日:👋 我们为语音到视频生成任务新增了基于CosyVoice的文本转语音合成支持。
社区成果
如果您在研究或项目中基于Wan2.1或Wan2.2开展工作,并希望让更多人了解您的成果,请告知我们。
- Prompt Relay,一种即插即用、推理阶段实现视频生成时间控制的方法。Prompt Relay能够提升视频质量,并让用户对视频中每一时刻的内容进行精准控制。更多详情请访问其网页。
- Helios,一款基于Wan2.1的突破性视频生成模型,能够在单张H100 GPU上以19.5 FPS的速度实现分钟级高质量视频合成(而在单张Ascend NPU上约为10 FPS)——且无需依赖传统的长视频防漂移策略或标准的视频加速技术。更多详情请访问其网页。
- LightX2V,一个轻量高效的视频生成框架,集成了Wan2.1和Wan2.2,支持多种工程加速技术以实现快速推理。LightX2V-HuggingFace提供了多种基于Wan的步进蒸馏模型、量化模型以及轻量级VAE模型。
- HuMo提出了一种基于Wan的统一、以人为中心的框架,能够从多模态输入——包括文本、图像和音频——生成高质量、精细可控的人体视频。更多详情请访问其网页。
- FastVideo包含经过蒸馏的Wan模型,采用稀疏注意力机制,显著加快了推理速度。
- Cache-dit为Wan2.2 MoE提供全缓存加速支持,结合DBCache、TaylorSeer和Cache CFG。更多详情请访问其示例。
- Kijai's ComfyUI WanVideoWrapper是ComfyUI的Wan模型替代实现。由于其专注于Wan本身,因此能够第一时间获得前沿优化与热门研究功能,而这些功能往往因ComfyUI结构较为 rigid 而难以快速集成。
- DiffSynth-Studio为Wan 2.2提供全面支持,包括低GPU内存逐层卸载、FP8量化、序列并行、LoRA训练以及完整训练等。
📑 待办事项清单
- Wan2.2 文本转视频
- A14B和14B模型的多GPU推理代码
- A14B和14B模型的检查点
- ComfyUI集成
- Diffusers集成
- Wan2.2 图像转视频
- A14B模型的多GPU推理代码
- A14B模型的检查点
- ComfyUI集成
- Diffusers集成
- Wan2.2 文本-图像转视频
- 5B模型的多GPU推理代码
- 5B模型的检查点
- ComfyUI集成
- Diffusers集成
- Wan2.2-S2V 语音转视频
- Wan2.2-S2V的推理代码
- Wan2.2-S2V-14B的检查点
- ComfyUI集成
- Diffusers集成
- Wan2.2-动画角色动画与替换
- Wan2.2-Animate的推理代码
- Wan2.2-Animate的检查点
- ComfyUI集成
- Diffusers集成
运行Wan2.2
安装
克隆仓库:
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
安装依赖:
# 确保torch >= 2.4.0
# 如果`flash_attn`安装失败,可先安装其他包再最后安装`flash_attn`
pip install -r requirements.txt
# 如果想使用CosyVoice为语音转视频生成合成语音,请额外安装requirements_s2v.txt
pip install -r requirements_s2v.txt
模型下载
| 模型 | 下载链接 | 描述 |
|---|---|---|
| T2V-A14B | 🤗 Huggingface 🤖 ModelScope | 文本转视频MoE模型,支持480P与720P |
| I2V-A14B | 🤗 Huggingface 🤖 ModelScope | 图像转视频MoE模型,支持480P与720P |
| TI2V-5B | 🤗 Huggingface 🤖 ModelScope | 高压缩VAE,T2V+I2V,支持720P |
| S2V-14B | 🤗 Huggingface 🤖 ModelScope | 语音转视频模型,支持480P与720P |
| Animate-14B | 🤗 Huggingface 🤖 ModelScope | 角色动画与替换 |
💡注意: TI2V-5B模型支持以24 FPS生成720P视频。
使用huggingface-cli下载模型:
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B
使用modelscope-cli下载模型:
pip install modelscope
modelscope download Wan-AI/Wan2.2-T2V-A14B --local_dir ./Wan2.2-T2V-A14B
运行文本转视频生成
本仓库支持Wan2.2-T2V-A14B文本转视频模型,并可同时支持480P与720P分辨率的视频生成。
(1) 不使用提示扩展
为便于实施,我们将从一个基础版本的推理流程开始,跳过提示扩展步骤。
- 单GPU推理
python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --prompt "两只穿着舒适拳击装备、戴着亮色手套的人形猫在聚光灯下的舞台上激烈搏斗。"
💡 此命令可在至少拥有80GB显存的GPU上运行。
💡若遇到OOM(显存不足)问题,可使用
--offload_model True、--convert_model_dtype以及--t5_cpu选项来降低显存占用。
- 使用FSDP + DeepSpeed Ulysses的多GPU推理
我们使用 PyTorch FSDP 和 DeepSpeed Ulysses 来加速推理。
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "两只穿着舒适拳击装备、戴着亮色手套的人形猫在聚光灯下的舞台上激烈搏斗。"
(2) 使用提示扩展
扩展提示可以有效丰富生成视频的细节,进一步提升视频质量。因此,我们建议启用提示扩展。我们提供以下两种提示扩展方法:
- 使用 Dashscope API 进行扩展。
- 提前申请
dashscope.api_key(英文 | 中文)。 - 配置环境变量
DASH_API_KEY以指定 Dashscope API 密钥。对于阿里云国际站用户,还需将环境变量DASH_API_URL设置为 'https://dashscope-intl.aliyuncs.com/api/v1'。更多详细说明请参阅 dashscope 文档。 - 文本转视频任务使用
qwen-plus模型,图像转视频任务使用qwen-vl-max模型。 - 可通过参数
--prompt_extend_model修改用于扩展的模型。例如:
- 提前申请
DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "两只穿着舒适拳击装备、戴着亮色手套的人形猫在聚光灯下的舞台上激烈搏斗" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'zh'
使用本地模型进行扩展。
- 默认情况下,此扩展使用 HuggingFace 上的 Qwen 模型。用户可根据可用显存大小选择 Qwen 模型或其他模型。
- 对于文本转视频任务,可使用
Qwen/Qwen2.5-14B-Instruct、Qwen/Qwen2.5-7B-Instruct和Qwen/Qwen2.5-3B-Instruct等模型。 - 对于图像转视频任务,可使用
Qwen/Qwen2.5-VL-7B-Instruct和Qwen/Qwen2.5-VL-3B-Instruct等模型。 - 较大的模型通常能提供更好的扩展效果,但需要更多的显存。
- 可通过参数
--prompt_extend_model修改用于扩展的模型,允许指定本地模型路径或 HuggingFace 模型。例如:
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "两只穿着舒适拳击装备、戴着亮色手套的人形猫在聚光灯下的舞台上激烈搏斗" --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_target_lang 'zh'
运行图像转视频生成
本仓库支持 Wan2.2-I2V-A14B 图像转视频模型,并可同时支持 480P 和 720P 分辨率的视频生成。
- 单 GPU 推理
python generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --offload_model True --convert_model_dtype --image examples/i2v_input.JPG --prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上。毛茸茸的猫咪以轻松的表情直视镜头。模糊的海滩风景作为背景,呈现出清澈见底的海水、远处的绿丘和点缀着白云的蓝天。猫咪摆出自然放松的姿势,仿佛在享受海风与温暖的阳光。特写镜头突出了猫咪的细腻毛发和海滨的清新氛围。"
此命令可在至少配备 80GB 显存的 GPU 上运行。
💡对于图像转视频任务,
size参数表示生成视频的区域,长宽比遵循原始输入图像的比例。
- 使用 FSDP + DeepSpeed Ulysses 的多 GPU 推理
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上。毛茸茸的猫咪以轻松的表情直视镜头。模糊的海滩风景作为背景,呈现出清澈见底的海水、远处的绿丘和点缀着白云的蓝天。猫咪摆出自然放松的姿势,仿佛在享受海风与温暖的阳光。特写镜头突出了猫咪的细腻毛发和海滨的清新氛围。"
- 无提示的图像转视频生成
DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --prompt '' --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --use_prompt_extend --prompt_extend_method 'dashscope'
💡该模型仅根据输入图像即可生成视频。您可以通过提示扩展从图像中生成提示。
提示扩展的过程可参考 这里。
运行文本-图像转视频生成
本仓库支持 Wan2.2-TI2V-5B 文本-图像转视频模型,并可支持 720P 分辨率的视频生成。
- 单 GPU 文本转视频推理
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "两只穿着舒适拳击装备、戴着亮色手套的人形猫在聚光灯下的舞台上激烈搏斗"
💡与其他任务不同,文本-图像转视频任务的 720P 分辨率是
1280*704或704*1280。
此命令可在至少配备 24GB 显存的 GPU 上运行(例如 RTX 4090 GPU)。
💡如果您使用的 GPU 至少配备 80GB 显存,可以去掉
--offload_model True、--convert_model_dtype和--t5_cpu选项以加快执行速度。
- 单 GPU 图像转视频推理
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上。毛茸茸的猫咪以轻松的表情直视镜头。模糊的海滩风景作为背景,呈现出清澈见底的海水、远处的绿丘和点缀着白云的蓝天。猫咪摆出自然放松的姿势,仿佛在享受海风与温暖的阳光。特写镜头突出了猫咪的细腻毛发和海滨的清新氛围。"
💡如果配置了图像参数,则为图像转视频生成;否则,默认为文本转视频生成。
💡与图像转视频类似,
size参数表示生成视频的区域大小,其宽高比遵循原始输入图像的宽高比。
- 使用FSDP + DeepSpeed Ulysses进行多GPU推理
torchrun --nproc_per_node=8 generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --dit_fsdp --t5_fsdp --ulysses_size 8 --image examples/i2v_input.JPG --prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上。毛茸茸的猫咪以轻松的表情直视镜头。背景是模糊的海滩景色,包括清澈见底的海水、远处的绿丘和点缀着白云的蓝天。猫咪的姿态自然放松,仿佛在享受海风与温暖的阳光。特写镜头突出了猫咪的细腻毛发与海滨的清新氛围。"
提示词扩展的过程可参考此处。
运行语音转视频生成
本仓库支持“Wan2.2-S2V-14B”语音转视频模型,并可同时支持480P和720P分辨率的视频生成。
- 单GPU语音转视频推理
python generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --offload_model True --convert_model_dtype --prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上。" --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
# 如果不设置--num_clip,生成的视频长度将根据输入音频的长度自动调整
# 可以使用CosyVoice通过--enable_tts生成音频
python generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --offload_model True --convert_model_dtype --prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上。" --image "examples/i2v_input.JPG" --enable_tts --tts_prompt_audio "examples/zero_shot_prompt.wav" --tts_prompt_text "希望你以后能够做的比我还好呦。" --tts_text "收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。"
💡该命令可在至少配备80GB显存的GPU上运行。
- 使用FSDP + DeepSpeed Ulysses进行多GPU推理
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上。" --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
- 姿势+音频驱动生成
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "一个人在唱歌" --image "examples/pose.png" --audio "examples/sing.MP3" --pose_video "./examples/pose.mp4"
💡对于语音转视频任务,
size参数表示生成视频的区域大小,其宽高比遵循原始输入图像的宽高比。
💡该模型可以根据音频输入结合参考图像以及可选的文本提示生成视频。
💡
--pose_video参数启用姿势驱动生成,使模型能够在生成与音频输入同步的视频时遵循特定的姿势序列。
💡
--num_clip参数控制生成的视频片段数量,有助于以较短的生成时间进行快速预览。
请访问我们的项目页面,查看更多示例并了解该模型适用的场景。
运行Wan-Animate
Wan-Animate以视频和人物图像作为输入,生成“动画”或“替换”模式的视频。
- 动画模式:模型生成的人物图像视频会模仿输入视频中的人类动作。
- 替换模式:模型用输入视频替换人物图像。
请访问我们的项目页面,查看更多示例并了解该模型适用的场景。
(1) 预处理
输入视频应在进入推理流程前被预处理成若干素材。请参考以下处理流程,更多关于预处理的细节可在用户指南中找到。
- 对于动画
python ./wan/modules/animate/preprocess/preprocess_data.py \
--ckpt_path ./Wan2.2-Animate-14B/process_checkpoint \
--video_path ./examples/wan_animate/animate/video.mp4 \
--refer_path ./examples/wan_animate/animate/image.jpeg \
--save_path ./examples/wan_animate/animate/process_results \
--resolution_area 1280 720 \
--retarget_flag \
--use_flux
- 对于替换
python ./wan/modules/animate/preprocess/preprocess_data.py \
--ckpt_path ./Wan2.2-Animate-14B/process_checkpoint \
--video_path ./examples/wan_animate/replace/video.mp4 \
--refer_path ./examples/wan_animate/replace/image.jpeg \
--save_path ./examples/wan_animate/replace/process_results \
--resolution_area 1280 720 \
--iterations 3 \
--k 7 \
--w_len 1 \
--h_len 1 \
--replace_flag
(2) 在动画模式下运行
- 单GPU推理
python generate.py --task animate-14B --ckpt_dir ./Wan2.2-Animate-14B/ --src_root_path ./examples/wan_animate/animate/process_results/ --refert_num 1
- 使用FSDP + DeepSpeed Ulysses进行多GPU推理
python -m torch.distributed.run --nnodes 1 --nproc_per_node 8 generate.py --task animate-14B --ckpt_dir ./Wan2.2-Animate-14B/ --src_root_path ./examples/wan_animate/animate/process_results/ --refert_num 1 --dit_fsdp --t5_fsdp --ulysses_size 8
- Diffusers流水线
from diffusers import WanAnimatePipeline
from diffusers.utils import export_to_video, load_image, load_video
device = "cuda:0"
dtype = torch.bfloat16
model_id = "Wan-AI/Wan2.2-Animate-14B-Diffusers"
pipe = WanAnimatePipeline.from_pretrained(model_id torch_dtype=dtype)
pipe.to(device)
seed = 42
prompt = "视频中的人正在做各种动作。"
# 动画
image = load_image("/path/to/animate/reference/image/src_ref.png")
pose_video = load_video("/path/to/animate/pose/video/src_pose.mp4")
face_video = load_video("/path/to/animate/face/video/src_face.mp4")
animate_video = pipe(
image=image,
pose_video=pose_video,
face_video=face_video,
prompt=prompt,
mode="animate",
segment_frame_length=77, # 原代码中的 clip_len
prev_segment_conditioning_frames=1, # 原代码中的 refert_num
guidance_scale=1.0,
num_inference_steps=20,
generator=torch.Generator(device=device).manual_seed(seed),
).frames[0]
export_to_video(animate_video, "diffusers_animate.mp4", fps=30)
(3) 替换模式运行
- 单GPU推理
python generate.py --task animate-14B --ckpt_dir ./Wan2.2-Animate-14B/ --src_root_path ./examples/wan_animate/replace/process_results/ --refert_num 1 --replace_flag --use_relighting_lora
- 使用FSDP + DeepSpeed Ulysses的多GPU推理
python -m torch.distributed.run --nnodes 1 --nproc_per_node 8 generate.py --task animate-14B --ckpt_dir ./Wan2.2-Animate-14B/ --src_root_path ./examples/wan_animate/replace/process_results/src_pose.mp4 --refert_num 1 --replace_flag --use_relighting_lora --dit_fsdp --t5_fsdp --ulysses_size 8
- Diffusers Pipeline
# 创建管道,与动画代码中一致 ☝️
# 替换
image = load_image("/path/to/replace/reference/image/src_ref.png")
pose_video = load_video("/path/to/replace/pose/video/src_pose.mp4")
face_video = load_video("/path/to/replace/face/video/src_face.mp4")
background_video = load_video("/path/to/replace/background/video/src_bg.mp4")
mask_video = load_video("/path/to/replace/mask/video/src_mask.mp4")
replace_video = pipe(
image=image,
pose_video=pose_video,
face_video=face_video,
background_video=background_video,
mask_video=mask_video,
prompt=prompt,
mode="replace",
segment_frame_length=77, # 原代码中的 clip_len
prev_segment_conditioning_frames=1, # 原代码中的 refert_num
guidance_scale=1.0,
num_inference_steps=20,
generator=torch.Generator(device=device).manual_seed(seed),
).frames[0]
export_to_video(replace_video, "diffusers_replace.mp4", fps=30)
💡 如果您使用的是 Wan-Animate,我们不建议使用在
Wan2.2上训练的 LoRA 模型,因为训练过程中权重的变化可能导致意外行为。
不同GPU上的计算效率
我们在下表中测试了不同 Wan2.2 模型在不同GPU上的计算效率。结果以 总时间(秒)/ GPU峰值显存(GB) 的形式呈现。
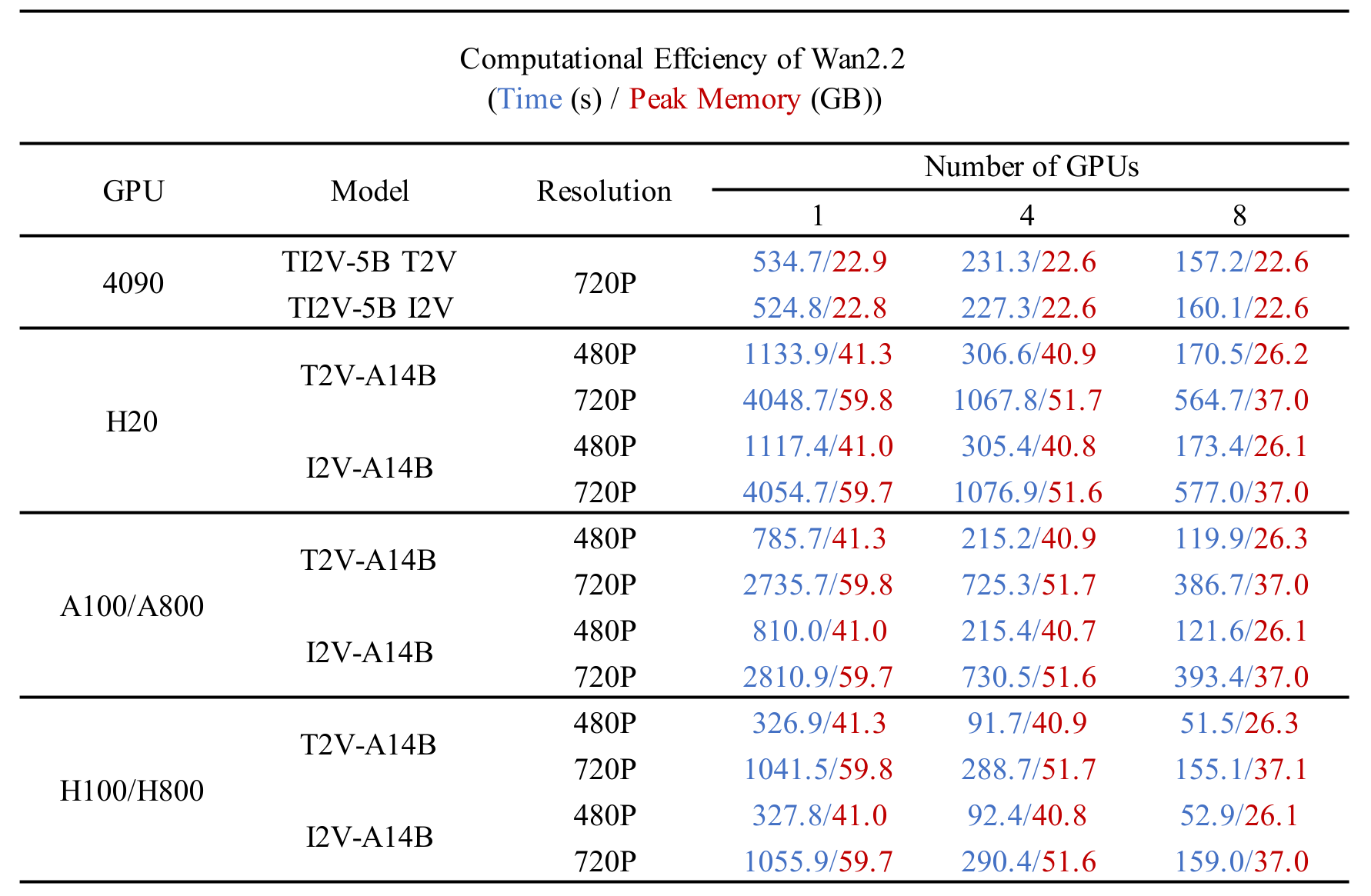
本表中所展示测试的参数设置如下: (1) 多GPU:14B:
--ulysses_size 4/8 --dit_fsdp --t5_fsdp,5B:--ulysses_size 4/8 --offload_model True --convert_model_dtype --t5_cpu;单GPU:14B:--offload_model True --convert_model_dtype,5B:--offload_model True --convert_model_dtype --t5_cpu(--convert_model_dtype将模型参数类型转换为 config.param_dtype); (2) 分布式测试采用内置的 FSDP 和 Ulysses 实现,并在 Hopper 架构的 GPU 上部署 FlashAttention3; (3) 测试未启用--use_prompt_extend标志; (4) 报告的结果为预热阶段后多次采样的平均值。
Wan2.2 简介
Wan2.2 在 Wan2.1 的基础上进行了重大升级,显著提升了生成质量和模型能力。此次升级得益于一系列关键技术革新,主要包括混合专家(MoE)架构、训练数据的优化以及高压缩率视频生成技术。
(1) 混合专家(MoE)架构
Wan2.2 将混合专家(MoE)架构引入了视频生成扩散模型。MoE 在大型语言模型中已被广泛验证,是一种在保持推理成本几乎不变的同时有效提升模型总参数量的方法。在 Wan2.2 中,A14B 系列模型采用了专为扩散模型去噪过程量身定制的双专家设计:早期阶段使用高噪声专家,侧重于整体布局;后期阶段则切换为低噪声专家,专注于细化视频细节。每个专家模型约有 140 亿参数,因此总参数量达到 270 亿,但每一步仅激活 140 亿个参数,从而将推理计算量和 GPU 显存占用基本维持在原有水平。

两组专家之间的切换点由信噪比(SNR)决定,而信噪比会随着去噪步骤 $t$ 的增加而单调下降。在去噪过程的初始阶段,$t$ 较大且噪声水平较高,因此信噪比处于最低值,记为 ${SNR}{min}$。在此阶段,高噪声专家被激活。我们定义一个对应于 ${SNR}{min}$ 一半的阈值步数 ${t}{moe}$,当 $t<{t}{moe}$ 时,便切换至低噪声专家。
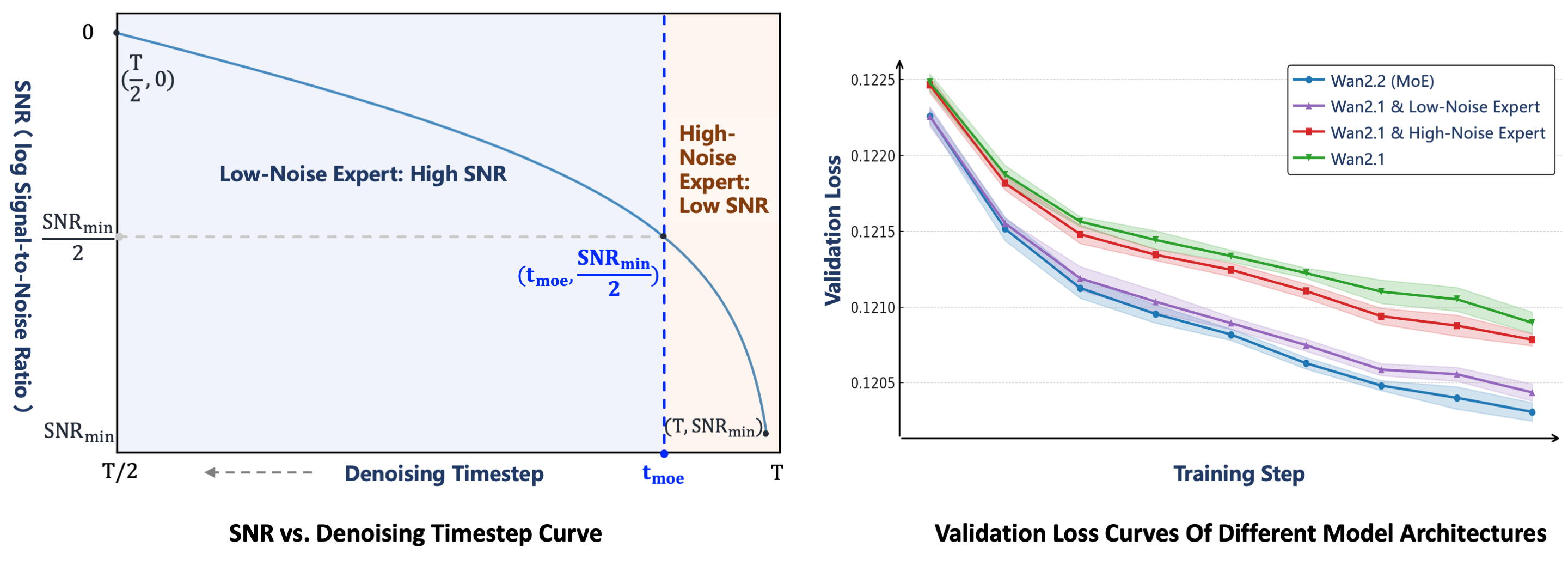
为了验证 MoE 架构的有效性,我们基于其验证损失曲线对比了四种设置。基准模型 Wan2.1 并未采用 MoE 架构。在基于 MoE 的变体中,Wan2.1 & 高噪声专家 以 Wan2.1 模型作为低噪声专家,同时使用 Wan2.2 的高噪声专家;而 Wan2.1 & 低噪声专家 则以 Wan2.1 作为高噪声专家,并采用 Wan2.2 的低噪声专家。最终版本 Wan2.2 (MoE) 的验证损失最低,表明其生成的视频分布最接近真实数据,且具有更优的收敛性能。
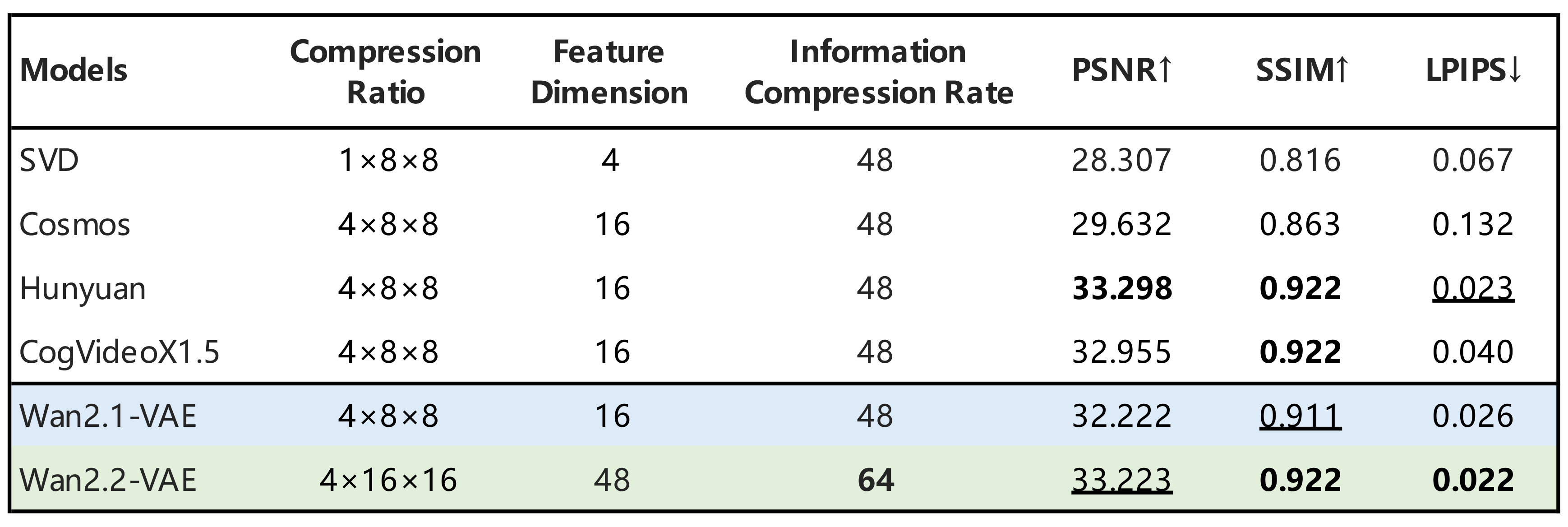
(2) 高效高清混合 TI2V
为实现更高效的部署,Wan2.2 还探索了一种高压缩设计。除了 270 亿参数的 MoE 模型外,我们还发布了一个 50 亿参数的稠密模型——TI2V-5B。该模型由一个高压缩比的 Wan2.2-VAE 支持,可实现 $T\times H\times W$ 压缩比为 $4\times16\times16$,使整体压缩率提升至 64,同时保持高质量的视频重建效果。此外,通过添加一个补丁化层,TI2V-5B 的总压缩比可达 $4\times32\times32$。在无需特殊优化的情况下,TI2V-5B 单独在消费级 GPU 上即可在不到 9 分钟内生成一段 5 秒的 720P 视频,跻身最快的 720P@24fps 视频生成模型之列。此外,该模型原生支持文本到视频与图像到视频两类任务,统一在一个框架内完成,既适用于学术研究,也满足实际应用需求。
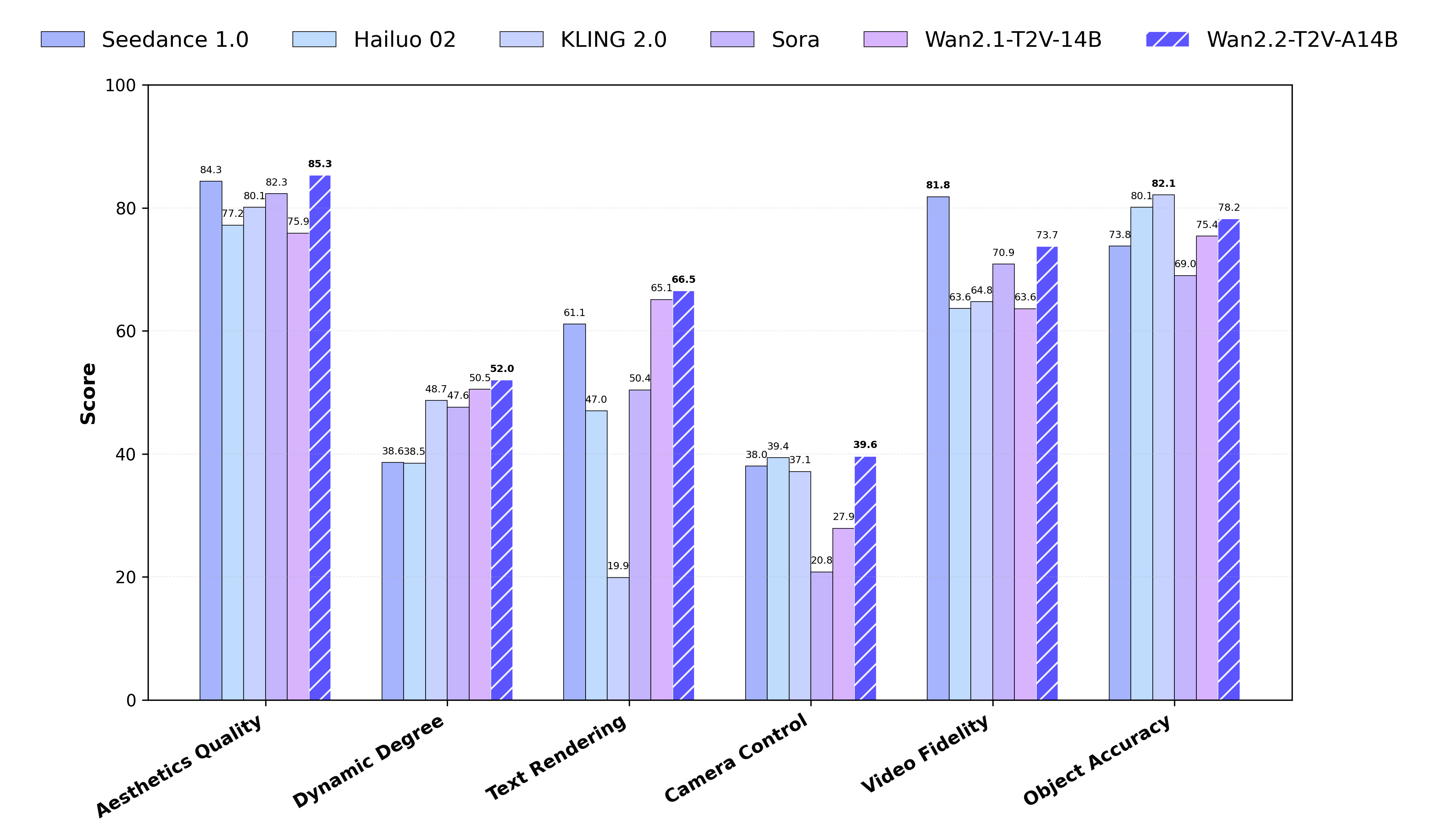
与 SOTA 的对比
我们在全新的 Wan-Bench 2.0 上将 Wan2.2 与领先的闭源商业模型进行了对比,从多个关键维度评估了性能。结果表明,Wan2.2 的表现优于这些领先模型。
引用
如果您觉得我们的工作有所帮助,请引用我们。
@article{wan2025,
title={Wan: 开放且先进的大规模视频生成模型},
author={Wan 团队、Ang Wang、Baole Ai、Bin Wen、Chaojie Mao、Chen-Wei Xie、Di Chen、Feiwu Yu、Haiming Zhao、Jianxiao Yang、Jianyuan Zeng、Jiayu Wang、Jingfeng Zhang、Jingren Zhou、Jinkai Wang、Jixuan Chen、Kai Zhu、Kang Zhao、Keyu Yan、Lianghua Huang、Mengyang Feng、Ningyi Zhang、Pandeng Li、Pingyu Wu、Ruihang Chu、Ruili Feng、Shiwei Zhang、Siyang Sun、Tao Fang、Tianxing Wang、Tianyi Gui、Tingyu Weng、Tong Shen、Wei Lin、Wei Wang、Wei Wang、Wenmeng Zhou、Wente Wang、Wenting Shen、Wenyuan Yu、Xianzhong Shi、Xiaoming Huang、Xin Xu、Yan Kou、Yangyu Lv、Yifei Li、Yijing Liu、Yiming Wang、Yingya Zhang、Yitong Huang、Yong Li、You Wu、Yu Liu、Yulin Pan、Yun Zheng、Yuntao Hong、Yupeng Shi、Yutong Feng、Zeyinzi Jiang、Zhen Han、Zhi-Fan Wu、Ziyu Liu},
journal = {arXiv 预印本 arXiv:2503.20314},
year={2025}
}
许可协议
本仓库中的模型均采用 Apache 2.0 许可协议授权。我们对您生成的内容不主张任何权利,赋予您自由使用这些内容的权利,同时确保您的使用符合本许可协议的规定。您需对模型的使用承担全部责任,不得分享任何违反相关法律、对个人或群体造成伤害、传播用于实施伤害的个人信息、散布虚假信息或针对弱势群体的内容。有关完整限制及您的权利详情,请参阅 许可证 全文。
致谢
我们衷心感谢 SD3、Qwen、umt5-xxl、diffusers 以及 HuggingFace 项目的贡献者们,感谢他们开放的研究成果。
联系我们
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
onlook
Onlook 是一款专为设计师打造的开源 AI 优先设计工具,被誉为“设计师版的 Cursor”。它旨在打破设计与开发之间的壁垒,让用户能够以可视化的方式直接构建、样式化和编辑 React 应用。通过 Onlook,用户无需深入编写复杂代码,即可在类似 Figma 的直观界面中完成网页原型的搭建与调整,并实时预览最终效果。 这款工具主要解决了传统工作流中设计稿到代码转换效率低、沟通成本高的问题。以往,设计师使用 Figma 等工具完成设计后,需要开发人员手动将其转化为代码,过程繁琐且容易出错。Onlook 允许用户直接在浏览器 DOM 中进行可视化编辑,底层自动生成基于 Next.js 和 TailwindCSS 的高质量代码,实现了“所见即所得”的开发体验。它不仅支持从文本或图像快速生成应用,还具备分支管理、资源管理及一键部署等功能,极大地简化了从创意到成品的流程。 Onlook 特别适合前端开发者、UI/UX 设计师以及希望快速验证产品创意的独立开发者使用。对于设计师而言,它降低了参与前端开发的门槛;对于开发者来说,它提供了一个高效的视觉化调试和原型构建环境。其核心技术亮点在于
serena
Serena 是一款专为编程智能体(Coding Agent)打造的强大工具包,被誉为“智能体的集成开发环境(IDE)”。它通过模型上下文协议(MCP)与各类大语言模型及客户端无缝集成,旨在解决传统 AI 在复杂代码库中因依赖行号或简单文本搜索而导致的效率低下和准确性不足的问题。 与传统方法不同,Serena 采用“智能体优先”的设计理念,提供基于语义的代码检索、编辑和重构能力。它能像资深开发者使用 IDE 一样,深入理解代码的符号层级和关联结构,从而让智能体在大型项目中运行得更快、更稳、更可靠。无论是终端用户(如 Claude Code)、IDE 插件(VSCode、Cursor)还是桌面应用,都能轻松接入 Serena 以扩展功能。 Serena 特别适合需要处理大规模代码项目的开发者、研究人员以及希望提升 AI 编码能力的技术团队。其核心技术亮点在于灵活的后端支持:既默认集成了基于语言服务器协议(LSP)的开源方案,支持超过 40 种编程语言;也可选配强大的 JetBrains 插件,利用专业 IDE 的深度分析能力。这让 Serena 成为连接人工智能与复杂软件工程的高效桥
sam2
SAM 2 是 Meta 推出的新一代基础模型,旨在解决图像与视频中的“提示式视觉分割”难题。无论是静态图片还是动态视频,用户只需提供简单的点击、框选等提示,SAM 2 就能精准识别并分割出目标对象。它将单张图像视为单帧视频进行处理,成功打破了以往模型在视频理解上的局限。 这款工具特别适合计算机视觉开发者、AI 研究人员以及需要处理视频内容的设计师使用。对于希望探索多目标跟踪或构建交互式应用的技术团队,SAM 2 提供了强大的底层支持。其核心亮点在于采用了带有流式记忆机制的 Transformer 架构,能够实现实时的视频处理性能。此外,项目配套发布了迄今为止规模最大的视频分割数据集(SA-V),并通过“模型闭环数据引擎”不断自我进化。最新更新的 SAM 2.1 版本不仅提供了更优的预训练权重,还支持全模型编译加速及灵活的多目标独立追踪,让复杂场景下的视频分析变得更加高效与便捷。